[GitHub] spark pull request #23104: [SPARK-26138][SQL] Cross join requires push Local...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/23104#discussion_r236929433
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -459,6 +459,7 @@ object LimitPushDown extends Rule[LogicalPlan] {
val newJoin = joinType match {
case RightOuter => join.copy(right = maybePushLocalLimit(exp,
right))
case LeftOuter => join.copy(left = maybePushLocalLimit(exp, left))
+case Cross => join.copy(left = maybePushLocalLimit(exp, left),
right = maybePushLocalLimit(exp, right))
--- End diff --
There are two tables as followsï¼
CREATE TABLE `**test1**`(`id` int, `name` int);
CREATE TABLE `**test2**`(`id` int, `name` int);
test1 table data:
2,2
1,1
test2 table data:
2,2
3,3
4,4
Execute sql select * from test1 t1 **left anti join** test2 t2 on
t1.id=t2.id limit 1; The result:
1,1
But
we push the limit 1 on left side, the result is not correct. Result is
empty.
we push the limit 1 on right side, the result is not correct. Result is
empty.
So
left anti join no need to push down limit. Similarly, left semi join is
the same logic.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23104: [SPARK-26138][SQL] Cross join requires push Local...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/23104#discussion_r236589331
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -459,6 +459,7 @@ object LimitPushDown extends Rule[LogicalPlan] {
val newJoin = joinType match {
case RightOuter => join.copy(right = maybePushLocalLimit(exp,
right))
case LeftOuter => join.copy(left = maybePushLocalLimit(exp, left))
+case Cross => join.copy(left = maybePushLocalLimit(exp, left),
right = maybePushLocalLimit(exp, right))
--- End diff --
@cloud-fan
Please give me some advice. Thank you.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23104: [SPARK-26138][SQL] Cross join requires push Local...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/23104#discussion_r236143436
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -459,6 +459,7 @@ object LimitPushDown extends Rule[LogicalPlan] {
val newJoin = joinType match {
case RightOuter => join.copy(right = maybePushLocalLimit(exp,
right))
case LeftOuter => join.copy(left = maybePushLocalLimit(exp, left))
+case Cross => join.copy(left = maybePushLocalLimit(exp, left),
right = maybePushLocalLimit(exp, right))
--- End diff --
I think, if when set spark.sql.crossJoin.enabled=true, if Inner join
without condition, LeftOuter join without condition, RightOuter join without
condition, FullOuter join without condition , limit should be pushed down on
both sides, just like cross join limit in this PR.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23104: [SPARK-26138][SQL] Cross join requires push LocalLimit i...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/23104 > The title has a typo. Sorry, it has been fixed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23104: [SPARK-26138][SQL] LimitPushDown cross join requi...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/23104#discussion_r236137253
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -459,6 +459,7 @@ object LimitPushDown extends Rule[LogicalPlan] {
val newJoin = joinType match {
case RightOuter => join.copy(right = maybePushLocalLimit(exp,
right))
case LeftOuter => join.copy(left = maybePushLocalLimit(exp, left))
+case Cross => join.copy(left = maybePushLocalLimit(exp, left),
right = maybePushLocalLimit(exp, right))
--- End diff --
When set spark.sql.crossJoin.enabled=true,
inner join without condition, LeftOuter without condition, RightOuter
without condition, FullOuter without conditionï¼ all these are iterally cross
join?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23104: [SPARK-26138][SQL] LimitPushDown cross join requi...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/23104#discussion_r236115582
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -459,6 +459,7 @@ object LimitPushDown extends Rule[LogicalPlan] {
val newJoin = joinType match {
case RightOuter => join.copy(right = maybePushLocalLimit(exp,
right))
case LeftOuter => join.copy(left = maybePushLocalLimit(exp, left))
+case Cross => join.copy(left = maybePushLocalLimit(exp, left),
right = maybePushLocalLimit(exp, right))
--- End diff --
A = {(a, 0), (b, 1), (c, 2), (d, 0), **(e, 1), (f, 2)**}
B = {**(e, 1), (f, 2)**}
A inner join B limit 2
If there is limit 2, (a, 0), (b, 1) inner join {(e, 1), (f, 2)}, the result
is empty. But the real result is not empty.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23104: [SPARK-26138][SQL] LimitPushDown cross join requires may...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/23104 @cloud-fan @dongjoon-hyun @gatorsmile Help review the code. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23104: [SPARK-26138][SQL] LimitPushDown cross join requires may...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/23104 Yes I tested and understood, you are right. @mgaido91 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23104: [SPARK-26138][SQL] LimitPushDown cross join requires may...
Github user guoxiaolongzte commented on the issue:
https://github.com/apache/spark/pull/23104
Cartesian product refers to the Cartesian product of two sets X and Y in
mathematics , also known as direct product , expressed as X Ã Y , the first
object is a member of X and the second object is One of all possible ordered
pairs of Y.So cross join mustpush it on the left side.
For example, A={a,b}, B={0,1,2}, then
A Ã B = {(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
BÃA={(0, a), (0, b), (1, a), (1, b), (2, a), (2, b)}
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23104: [SPARK-26138][SQL] LimitPushDown cross join requires may...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/23104 OK, I will add some UTs. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23104: [SPARK-26138][SQL] LimitPushDown cross join requi...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/23104 [SPARK-26138][SQL] LimitPushDown cross join requires maybeBushLocalLimit ## What changes were proposed in this pull request? In LimitPushDown batch, cross join can push down the limit. ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-26138 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23104.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23104 commit deb18093b1a1b1c6b7e6ad1fd148448b761297ea Author: guoxiaolong Date: 2018-11-21T13:36:24Z [SPARK-26138][SQL] LimitPushDown cross join requires maybeBushLocalLimit --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21784: [SPARK-24873][YARN] Turn off spark-shell noisy log outpu...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/21784 We need to listen to @vanzin opinion. Because the relevant code is what he wrote. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21784: [SPARK-24873][YARN] Turn off spark-shell noisy log outpu...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/21784 But for some spark-submit applications, I want these Application report for information. What should I do? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21827: [SPARK-24873]Increase switch to shielding frequent inter...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/21827 Please add a switch. And represented by a constant. This configuration is added to the running-on-yarn.md document. @hejiefang --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21784: [SPARK-24873][YARN] Turn off spark-shell noisy log outpu...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/21784 what? I think we need to add a switch. https://github.com/apache/spark/pull/21827 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21036: [SPARK-23958][CORE] HadoopRdd filters empty files to avo...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/21036 Thank you for your comments, I will close this PR, thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21036: [SPARK-23958][CORE] HadoopRdd filters empty files...
Github user guoxiaolongzte closed the pull request at: https://github.com/apache/spark/pull/21036 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21036: [SPARK-23958][CORE] HadoopRdd filters empty files to avo...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/21036 1.No need to loop twice to filter to determine if the length is greater than 0 2.This feature is to improve performance, the default switch needs to open --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21036: [SPARK-23958][CORE] HadoopRdd filters empty files to avo...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/21036 Thanks, I will try to add test cases. @felixcheung --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21036: [SPARK-23958][CORE] HadoopRdd filters empty files...
Github user guoxiaolongzte commented on a diff in the pull request: https://github.com/apache/spark/pull/21036#discussion_r180655799 --- Diff: core/src/main/scala/org/apache/spark/rdd/HadoopRDD.scala --- @@ -55,7 +56,8 @@ private[spark] class HadoopPartition(rddId: Int, override val index: Int, s: Inp /** * Get any environment variables that should be added to the users environment when running pipes - * @return a Map with the environment variables and corresponding values, it could be empty +* +* @return a Map with the environment variables and corresponding values, it could be empty --- End diff -- Thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21036: [SPARK-23958][CORE] HadoopRdd filters empty files...
Github user guoxiaolongzte commented on a diff in the pull request: https://github.com/apache/spark/pull/21036#discussion_r180652894 --- Diff: core/src/main/scala/org/apache/spark/rdd/HadoopRDD.scala --- @@ -55,7 +56,8 @@ private[spark] class HadoopPartition(rddId: Int, override val index: Int, s: Inp /** * Get any environment variables that should be added to the users environment when running pipes - * @return a Map with the environment variables and corresponding values, it could be empty +* +* @return a Map with the environment variables and corresponding values, it could be empty --- End diff -- what mean? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21036: [SPARK-23958][CORE] HadoopRdd filters empty files...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/21036 [SPARK-23958][CORE] HadoopRdd filters empty files to avoid generating empty tasks that affect the performance of the Spark computing performance. ## What changes were proposed in this pull request? HadoopRdd filter empty files to avoid generating empty tasks that affect the performance of the Spark computing performance. Empty file's length is zero. ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-23958 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21036.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21036 commit e4ccdf913157b45f11efe8b8900d1f805d853278 Author: guoxiaolong <guo.xiaolong1@...> Date: 2018-04-11T02:48:51Z [SPARK-23958][CORE] HadoopRdd filters empty files to avoid generating empty tasks that affect the performance of the Spark computing performance. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20818: [SPARK-23675][WEB-UI]Title add spark logo, use spark log...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20818 @ajbozarth @srowen Help to review the code. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20818: [SPARK-23675][WEB-UI]Title add spark logo, use sp...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/20818 [SPARK-23675][WEB-UI]Title add spark logo, use spark logo image ## What changes were proposed in this pull request? Title add spark logo, use spark logo image. reference other big data system ui, so i think spark should add it. spark fix before:  spark fix after:  reference kafka ui:  reference storm ui:  reference yarn ui:  reference nifi ui:  reference flink ui:  ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-23675 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20818.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20818 commit 964439be7a592b2a94f93008dabc45a18f97c3c6 Author: guoxiaolong <guo.xiaolong1@...> Date: 2018-03-14T07:04:00Z [SPARK-23675][WEB-UI]Title add spark logo, use spark logo image --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20557: [SPARK-23364][SQL]'desc table' command in spark-sql add ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20557 Well, for now, I don't have a better solution. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20543: [SPARK-23357][CORE] 'SHOW TABLE EXTENDED LIKE pattern=ST...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20543 Oh, I just think it adds to make it clearer. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20543: [SPARK-23357][CORE] 'SHOW TABLE EXTENDED LIKE pattern=ST...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20543 @gatorsmile Help to review the code. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20570: [spark-23382][WEB-UI]Spark Streaming ui about the conten...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20570 Okay, I check the other pages again today. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20557: [SPARK-23364][SQL]'desc table' command in spark-sql add ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20557 @srowen @gatorsmile  Can I overload hive's org.apache.hive.beeline.Commands.java in spark sql package, modify the hive's hard-coded statistics rows? 0: jdbc:hive2://localhost:18001> desc cyj.partition_table; +--++--+--+ | col_name | data_type | comment | +--++--+--+ | # col_name | data_type | comment | | id | int| NULL | | name | string | NULL | | age | int| NULL | | dt | string | NULL | | day | string | NULL | | hour | int| NULL | | # Partition Information || | | # col_name | data_type | comment | | dt | string | NULL | | day | string | NULL | | hour | int| NULL | +--++--+--+ **12 rows** selected (0.092 seconds) **| # Partition Information || | | # col_name | data_type | comment | Also counted as two lines. Still in question.** --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20573: [SPARK-23384][WEB-UI]When it has no incomplete(co...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/20573 [SPARK-23384][WEB-UI]When it has no incomplete(completed) applications found, the last updated time is not formatted and client local time zone is not show in history server web ui. ## What changes were proposed in this pull request? When it has no incomplete(completed) applications found, the last updated time is not formatted and client local time zone is not show in history server web ui. It is a bug. fix before:  fix after:  ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-23384 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20573.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20573 commit 0575d5eb402edcca0c67a5fa9001fd5e5183e34e Author: guoxiaolong <guo.xiaolong1@...> Date: 2018-02-11T06:43:20Z [SPARK-23384][WEB-UI]When it has no incomplete(completed) applications found, the last updated time is not formatted and client local time zone is not show in history server web ui. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20557: [SPARK-23364][SQL]'desc table' command in spark-s...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/20557#discussion_r167419765
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -539,15 +539,15 @@ case class DescribeTableCommand(
throw new AnalysisException(
s"DESC PARTITION is not allowed on a temporary view:
${table.identifier}")
}
- describeSchema(catalog.lookupRelation(table).schema, result, header
= false)
+ describeSchema(catalog.lookupRelation(table).schema, result, header
= true)
--- End diff --
The snapshot is correct fix code effect, the statistics rows does not
contain the head

---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20570: [spark-23382][WEB-UI]Spark Streaming ui about the...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/20570 [spark-23382][WEB-UI]Spark Streaming ui about the contents of the for need to have hidden and show features, when the table records very much. ## What changes were proposed in this pull request? Spark Streaming ui about the contents of the for need to have hidden and show features, when the table records very much. please refer to https://github.com/apache/spark/pull/20216 fix after:  ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-23382 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20570.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20570 commit c6ffe3025af5129a807885f9d757d2ddad641b62 Author: guoxiaolong <guo.xiaolong1@...> Date: 2018-02-11T02:13:05Z [spark-23382][WEB-UI]Spark Streaming ui about the contents of the form need to have hidden and show features, when the table records very much. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20557: [SPARK-23364][SQL]'desc table' command in spark-s...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/20557#discussion_r167416457
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -539,15 +539,15 @@ case class DescribeTableCommand(
throw new AnalysisException(
s"DESC PARTITION is not allowed on a temporary view:
${table.identifier}")
}
- describeSchema(catalog.lookupRelation(table).schema, result, header
= false)
+ describeSchema(catalog.lookupRelation(table).schema, result, header
= true)
--- End diff --
# Partition Information
# col_name data_type comment
Partition information also takes up two rows.
I try to keep the head of the case, let rows number is displayed correctly.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20557: [SPARK-23364][SQL]'desc table' command in spark-s...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/20557 [SPARK-23364][SQL]'desc table' command in spark-sql add column head display ## What changes were proposed in this pull request? Use 'desc partition_table' command in spark-sql client, i think it should add column head display. Add 'col_name' âdata_typeâ 'comment' column head display. fix before:  fix after:  ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-23364 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20557.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20557 commit 5699c0dc2810a4500f0ee34414b77b80afd0e9c1 Author: guoxiaolong <guo.xiaolong1@...> Date: 2018-02-09T06:00:40Z [SPARK-23364][SQL]'desc table' command in spark-sql add column head display --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20543: [SPARK-23357][CORE] 'SHOW TABLE EXTENDED LIKE pat...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/20543 [SPARK-23357][CORE] 'SHOW TABLE EXTENDED LIKE pattern=STRING' add âPartitionedâ display similar to hive, and partition is empty, also need to show empty partition field [] ## What changes were proposed in this pull request? 'SHOW TABLE EXTENDED LIKE pattern=STRING' add âPartitionedâ display similar to hive, and partition is empty, also need to show empty partition field [] hive:  sparkSQL Non-partitioned table fix before: 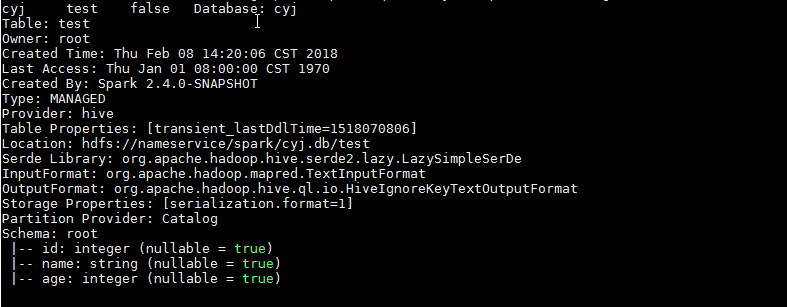 sparkSQL partitioned table fix before: 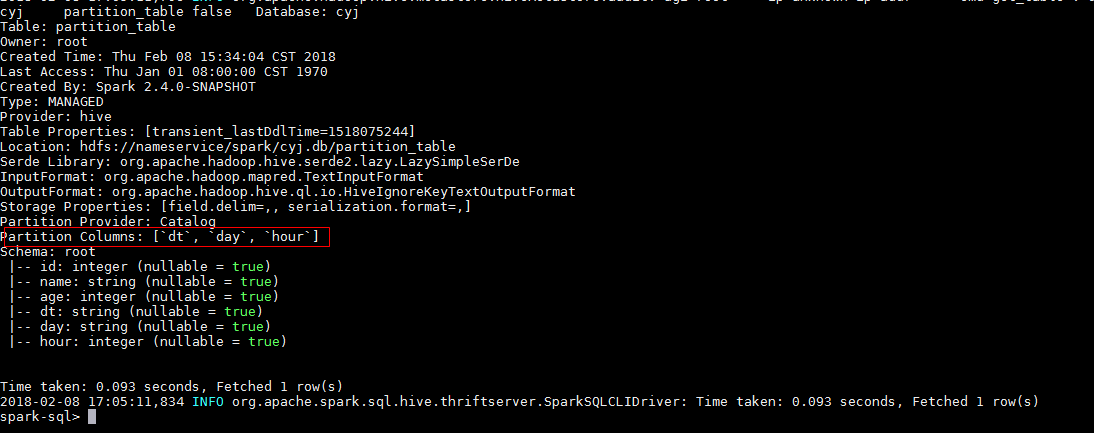 sparkSQL Non-partitioned table fix after: 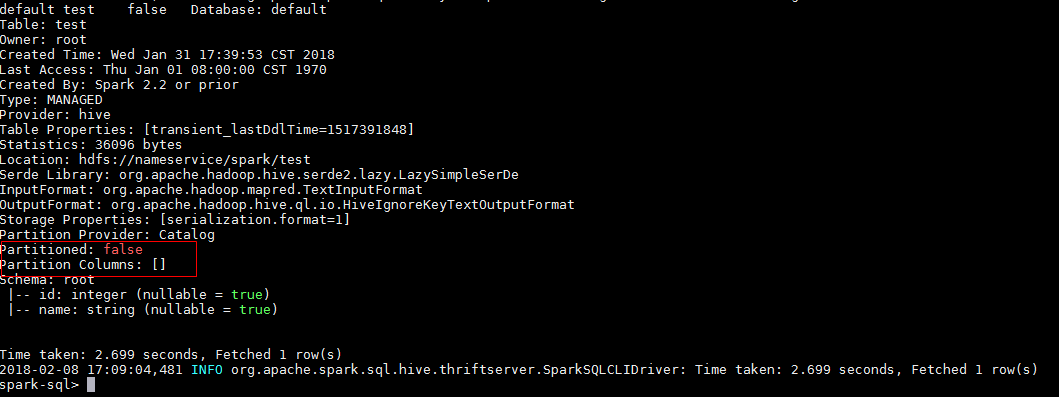 sparkSQL partitioned table fix after: 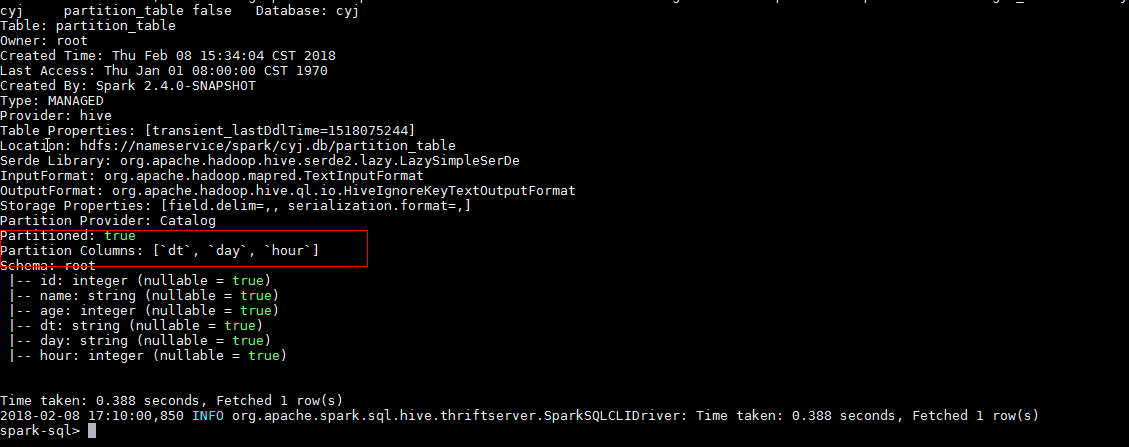 ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-23357 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20543.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20543 commit 073542d7199acddfbb122d28ab5110f638c2ec82 Author: guoxiaolong <guo.xiaolong1@...> Date: 2018-02-08T10:12:22Z [SPARK-23357][CORE] 'SHOW TABLE EXTENDED LIKE pattern=STRING' add âPartitionedâ display similar to hive, and partition is empty, also need to show empty partition field [] --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20437: [SPARK-23270][Streaming][WEB-UI]FileInputDStream ...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/20437#discussion_r165253828
--- Diff:
streaming/src/main/scala/org/apache/spark/streaming/dstream/FileInputDStream.scala
---
@@ -157,7 +157,7 @@ class FileInputDStream[K, V, F <: NewInputFormat[K, V]](
val metadata = Map(
"files" -> newFiles.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> newFiles.mkString("\n"))
-val inputInfo = StreamInputInfo(id, 0, metadata)
+val inputInfo = StreamInputInfo(id, rdds.map(_.count).sum, metadata)
--- End diff --
I am very sad. I'm working on whether there's a better way.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20437: [SPARK-23270][Streaming][WEB-UI]FileInputDStream ...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/20437#discussion_r165251810
--- Diff:
streaming/src/main/scala/org/apache/spark/streaming/dstream/FileInputDStream.scala
---
@@ -157,7 +157,7 @@ class FileInputDStream[K, V, F <: NewInputFormat[K, V]](
val metadata = Map(
"files" -> newFiles.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> newFiles.mkString("\n"))
-val inputInfo = StreamInputInfo(id, 0, metadata)
+val inputInfo = StreamInputInfo(id, rdds.map(_.count).sum, metadata)
--- End diff --
If you can add a switch parameter, the default value is false.
If it is true, then it needs to be count (read the file again) so that the
records can be correctly counted. Of course, it shows that when the parameter
is opened to true, the streaming performance problem will be affected.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20437: [SPARK-23270][Streaming][WEB-UI]FileInputDStream ...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/20437#discussion_r165247567
--- Diff:
streaming/src/main/scala/org/apache/spark/streaming/dstream/FileInputDStream.scala
---
@@ -157,7 +157,7 @@ class FileInputDStream[K, V, F <: NewInputFormat[K, V]](
val metadata = Map(
"files" -> newFiles.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> newFiles.mkString("\n"))
-val inputInfo = StreamInputInfo(id, 0, metadata)
+val inputInfo = StreamInputInfo(id, rdds.map(_.count).sum, metadata)
--- End diff --
Asynchronous processing, does not affect the backbone of the Streaming job,
also can get the number of records.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20437: [SPARK-23270][Streaming][WEB-UI]FileInputDStream ...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/20437#discussion_r165239860
--- Diff:
streaming/src/main/scala/org/apache/spark/streaming/dstream/FileInputDStream.scala
---
@@ -157,7 +157,7 @@ class FileInputDStream[K, V, F <: NewInputFormat[K, V]](
val metadata = Map(
"files" -> newFiles.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> newFiles.mkString("\n"))
-val inputInfo = StreamInputInfo(id, 0, metadata)
+val inputInfo = StreamInputInfo(id, rdds.map(_.count).sum, metadata)
--- End diff --
The number of rows in a file. Is this solution possible?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20437: [SPARK-23270][Streaming][WEB-UI]FileInputDStream ...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/20437#discussion_r164996836
--- Diff:
streaming/src/main/scala/org/apache/spark/streaming/dstream/FileInputDStream.scala
---
@@ -157,7 +157,7 @@ class FileInputDStream[K, V, F <: NewInputFormat[K, V]](
val metadata = Map(
"files" -> newFiles.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> newFiles.mkString("\n"))
-val inputInfo = StreamInputInfo(id, 0, metadata)
+val inputInfo = StreamInputInfo(id, rdds.map(_.count).sum, metadata)
--- End diff --
I would like another from a thread, try hdfs api to count the number of
documents, does not affect the main thread spark jobs, i will try. ok?
@jerryshao
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20437: [SPARK-23270][Streaming][WEB-UI]FileInputDStream ...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/20437#discussion_r164975752
--- Diff:
streaming/src/main/scala/org/apache/spark/streaming/dstream/FileInputDStream.scala
---
@@ -157,7 +157,7 @@ class FileInputDStream[K, V, F <: NewInputFormat[K, V]](
val metadata = Map(
"files" -> newFiles.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> newFiles.mkString("\n"))
-val inputInfo = StreamInputInfo(id, 0, metadata)
+val inputInfo = StreamInputInfo(id, rdds.map(_.count).sum, metadata)
--- End diff --
I see what you mean. I'll try to make it read once. Can you give me some
idea?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20437: [SPARK-23270][Streaming][WEB-UI]FileInputDStream ...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/20437#discussion_r164973156
--- Diff:
streaming/src/main/scala/org/apache/spark/streaming/dstream/FileInputDStream.scala
---
@@ -157,7 +157,7 @@ class FileInputDStream[K, V, F <: NewInputFormat[K, V]](
val metadata = Map(
"files" -> newFiles.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> newFiles.mkString("\n"))
-val inputInfo = StreamInputInfo(id, 0, metadata)
+val inputInfo = StreamInputInfo(id, rdds.map(_.count).sum, metadata)
--- End diff --
Because of this little overhead, that 'Records' is not recorded? This is a
obvious bug.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20437: [SPARK-23270][Streaming][WEB-UI]FileInputDStream Streami...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20437 thanks, Thank you for your review. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20437: [SPARK-23270][Streaming][WEB-UI]FileInputDStream ...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/20437 [SPARK-23270][Streaming][WEB-UI]FileInputDStream Streaming UI 's records should not be set to the default value of 0, it should be the total number of rows of new files. ## What changes were proposed in this pull request? FileInputDStream Streaming UI 's records should not be set to the default value of 0, it should be the total number of rows of new files. --in FileInputDStream.scala start val inputInfo = StreamInputInfo(id, 0, metadata) // set to the default value of 0 ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo) case class StreamInputInfo( inputStreamId: Int, numRecords: Long, metadata: Map[String, Any] = Map.empty) in FileInputDStream.scala end-- --in DirectKafkaInputDStream.scala start val inputInfo = StreamInputInfo(id, rdd.count, metadata) //set to rdd count as numRecords ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo) case class StreamInputInfo( inputStreamId: Int, numRecords: Long, metadata: Map[String, Any] = Map.empty) in DirectKafkaInputDStream.scala end-- test methodï¼ ./bin/spark-submit --class org.apache.spark.examples.streaming.HdfsWordCount examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar /spark/tmp/ fix after: 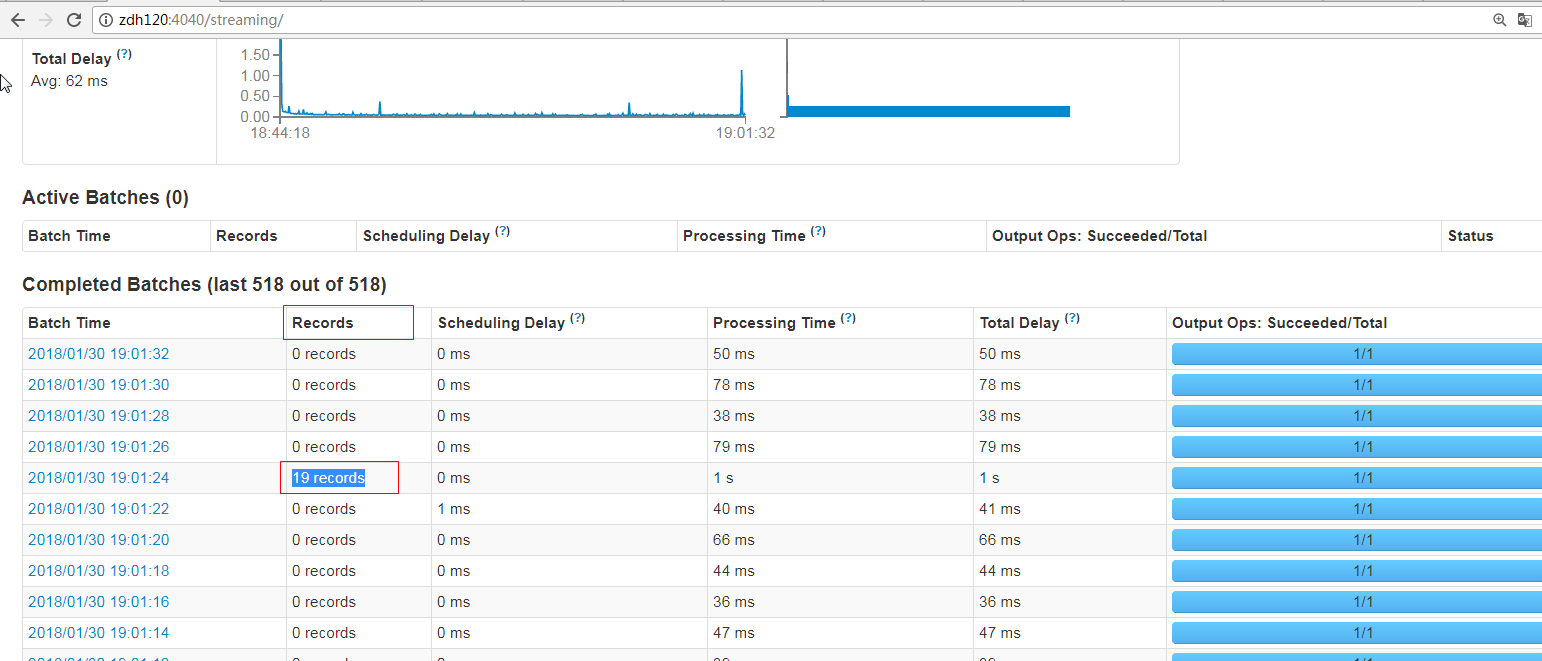 ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-23270 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20437.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20437 commit 41148c605ddf48c155fc03611bca03af9d4e25a3 Author: guoxiaolong <guo.xiaolong1@...> Date: 2018-01-30T11:30:49Z [SPARK-23270][Streaming][WEB-UI]FileInputDStream Streaming UI 's records should not be set to the default value of 0, it should be the total number of rows of new files. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20259: [SPARK-23066][WEB-UI] Master Page increase master start-...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20259 Thank you for review, I will close this list. I'm going to use a script to monitor the health of the Master process. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20259: [SPARK-23066][WEB-UI] Master Page increase master...
Github user guoxiaolongzte closed the pull request at: https://github.com/apache/spark/pull/20259 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20287: [SPARK-23121][WEB-UI] When the Spark Streaming ap...
Github user guoxiaolongzte closed the pull request at: https://github.com/apache/spark/pull/20287 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20287: [SPARK-23121][WEB-UI] When the Spark Streaming app is ru...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20287 @smurakozi @vanzin @srowen Thanks, i will close the PR. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20216: [SPARK-23024][WEB-UI]Spark ui about the contents of the ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20216 Please help merge code, thank you. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20287: [SPARK-23121][WEB-UI] When the Spark Streaming app is ru...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20287 @smurakozi Help review the code, this bug results from your added functionality. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20287: [SPARK-23121][WEB-UI] When the Spark Streaming app is ru...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20287 Well, then you can tell me how specific changes? I do not have a good idea right now. The problem is that the page crashes, it should be a fatal bug. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20216: [SPARK-23024][WEB-UI]Spark ui about the contents of the ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20216 test this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20259: [SPARK-23066][WEB-UI] Master Page increase master...
Github user guoxiaolongzte commented on a diff in the pull request: https://github.com/apache/spark/pull/20259#discussion_r161959792 --- Diff: core/src/main/scala/org/apache/spark/deploy/master/Master.scala --- @@ -179,6 +181,7 @@ private[deploy] class Master( } persistenceEngine = persistenceEngine_ leaderElectionAgent = leaderElectionAgent_ +startupTime = System.currentTimeMillis() --- End diff -- I understand what you mean. I do not always query, but developers occasionally to observe. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20287: [SPARK-23121][WEB-UI] When the Spark Streaming ap...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/20287 [SPARK-23121][WEB-UI] When the Spark Streaming app is running for a period of time, the page is incorrectly reported when accessing '/jobs' or '/jobs/job?id=13' ## What changes were proposed in this pull request? When the Spark Streaming app is running for a period of time, the page is incorrectly reported when accessing '/ jobs /' or '/ jobs / job /? Id = 13' and ui can not be accessed. Test command: ./bin/spark-submit --class org.apache.spark.examples.streaming.HdfsWordCount ./examples/jars/spark-examples_2.11-2.4.0-SNAPSHOT.jar /spark The app is running for a period of time, ui can not be accessed, please see attachment. fix before:   ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-23121 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20287.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20287 commit 03a84436ef2b6227f8bcfdd0b803c9457c8bd5cd Author: guoxiaolong <guo.xiaolong1@...> Date: 2018-01-17T03:26:19Z [SPARK-23121][WEB-UI]When the Spark Streaming app is running for a period of time, the page is incorrectly reported when accessing '/josb' or '/jobs/job?id=13' --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20259: [SPARK-23066][WEB-UI] Master Page increase master...
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/20259#discussion_r161937136
--- Diff: core/src/main/scala/org/apache/spark/deploy/master/Master.scala
---
@@ -125,6 +125,8 @@ private[deploy] class Master(
private var restServer: Option[StandaloneRestServer] = None
private var restServerBoundPort: Option[Int] = None
+ var startupTime: Long = 0
--- End diff --
metricRegistry.register(MetricRegistry.name("startupTime"), new
Gauge[String] {
override def getValue: String = UIUtils.formatDate(master.startupTime)
})
if startupTime is private, master.startupTime is unable to call.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20259: [SPARK-23066][WEB-UI] Master Page increase master...
Github user guoxiaolongzte commented on a diff in the pull request: https://github.com/apache/spark/pull/20259#discussion_r161936082 --- Diff: core/src/main/scala/org/apache/spark/deploy/master/Master.scala --- @@ -179,6 +181,7 @@ private[deploy] class Master( } persistenceEngine = persistenceEngine_ leaderElectionAgent = leaderElectionAgent_ +startupTime = System.currentTimeMillis() --- End diff -- Spark master process zombie, the background has a shell script automatically pull the spark master process to ensure high availability, but the restart process, there may be some applications such as failure. If I look at startup time metric today, if the startup time is ten days ago or a month ago, I would think the system is relatively stable, there is no restart behavior. If I look at the startup time metric today, if startup time was 1 day ago or an hour ago, I would assume that the system is unstable and that a recent reboot has occurred, requiring developers to troubleshoot problems and analyze them. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20216: [SPARK-23024][WEB-UI]Spark ui about the contents of the ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20216 Yes, it makes the Workers / Apps lists collapsible in the same way as other blocks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20216: [SPARK-23024][WEB-UI]Spark ui about the contents of the ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20216 I agree with your second suggestion, before I did not understand what you mean, now I passed the test I understand what you mean. 1.In order for collapsible tables to persist on reload each table much be added to the function at the bottom on web.js. When I refresh the page, if it is hidden, will still be hidden; if it is displayed, will still be displayed. 2.to ensure user interface consistency. @ajbozarth @srowen --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20259: [SPARK-23066][WEB-UI] Master Page increase master start-...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20259 I set the startup time to a metric. The metric instead of the master page display. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20259: [SPARK-23066][WEB-UI] Master Page increase master start-...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20259 OK, i understand your suggestion. Can I set the startup time to a metric? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20216: [SPARK-23024][WEB-UI]Spark ui about the contents of the ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20216 @ajbozarth The first suggestion, I have already fixed it. 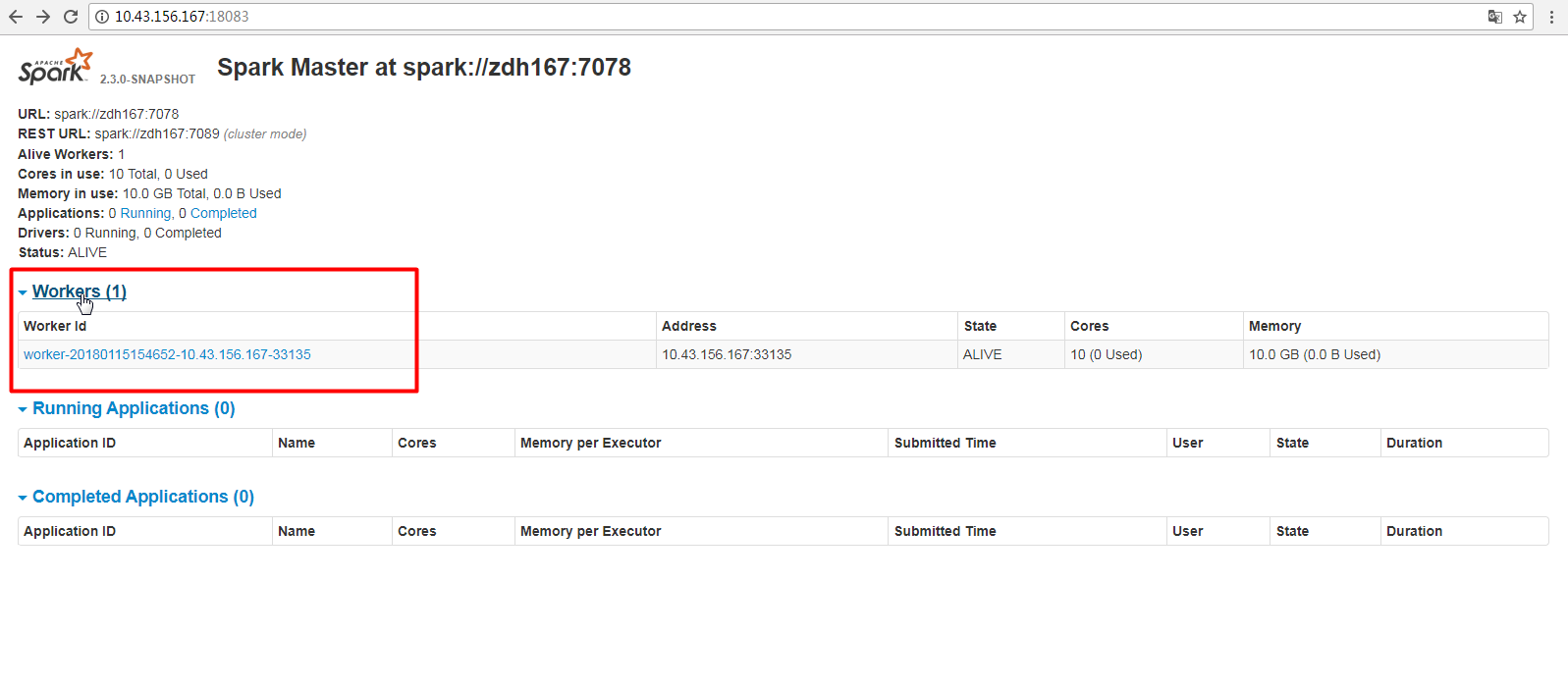 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20259: [SPARK-23066][WEB-UI] Master Page increase master start-...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20259 1. Concerned about the start-up time is to see if the system is stable. 2. Our system has 50,000 + app running every day, maser will generate a lot of app registration, management and other log information, the log volume will be great, all must use log4j, org.apache.log4j.DailyRollingFileAppender rollback log, if not In this way, the log file will bang the local disk. 3. Production environment lunix server user name and password only super managers have, we ordinary developers do not have permission, only through the WEB UI to access. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20259: [SPARK-23066][WEB-UI] Master Page increase master start-...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20259 Sir, I stick to my point for the following reasons: 1.When the spark system is running for some time, the log has been rolled back, because we use log4j, simply do not see the beginning of the start time. 2.lunix server not everyone has permission to visit, I do not have permission to see, but we are very concerned about the start-up time, we can only see the WEB UI. 3. It's already crowded. I can adjust the details, look at the snapshot, what do you think? 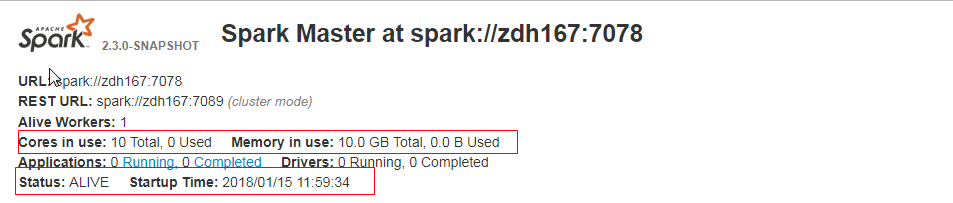 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20216: [SPARK-23024][WEB-UI]Spark ui about the contents of the ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20216 1. The first suggestion, I will fix it. 2. The second suggestion, I think it is not necessary. Because spark system is small, such as 3 workers, do not need to hide the table from the beginning. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20259: [SPARK-23066][WEB-UI] Master Page increase master...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/20259 [SPARK-23066][WEB-UI] Master Page increase master start-up time. ## What changes were proposed in this pull request? When a spark system runs stably for a long time, we do not know how long it actually runs and can not get its startup time from the UI. So, it is necessary to increase the Master start-up time. ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-23066 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20259.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20259 commit b985c0f30081c5fdf93b54cccebb6afad462bde1 Author: guoxiaolong <guo.xiaolong1@...> Date: 2018-01-13T08:52:46Z [SPARK-23066][WEB-UI] Master Page increase master start-up time. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20216: [SPARK-23024][WEB-UI]Spark ui about the contents of the ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20216 @ajbozarth @srowen Fix the code, increase the arrow of the form page, maintain the consistency of the function. after fix: 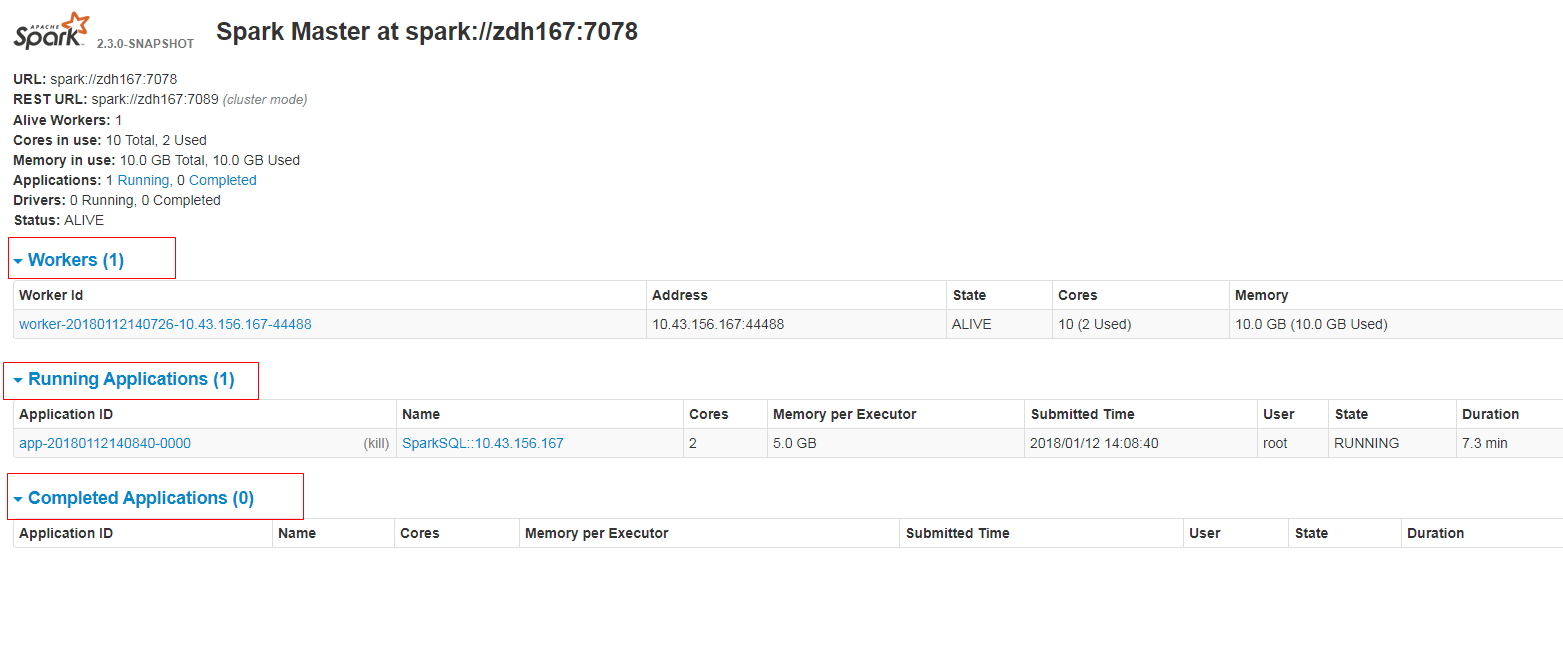 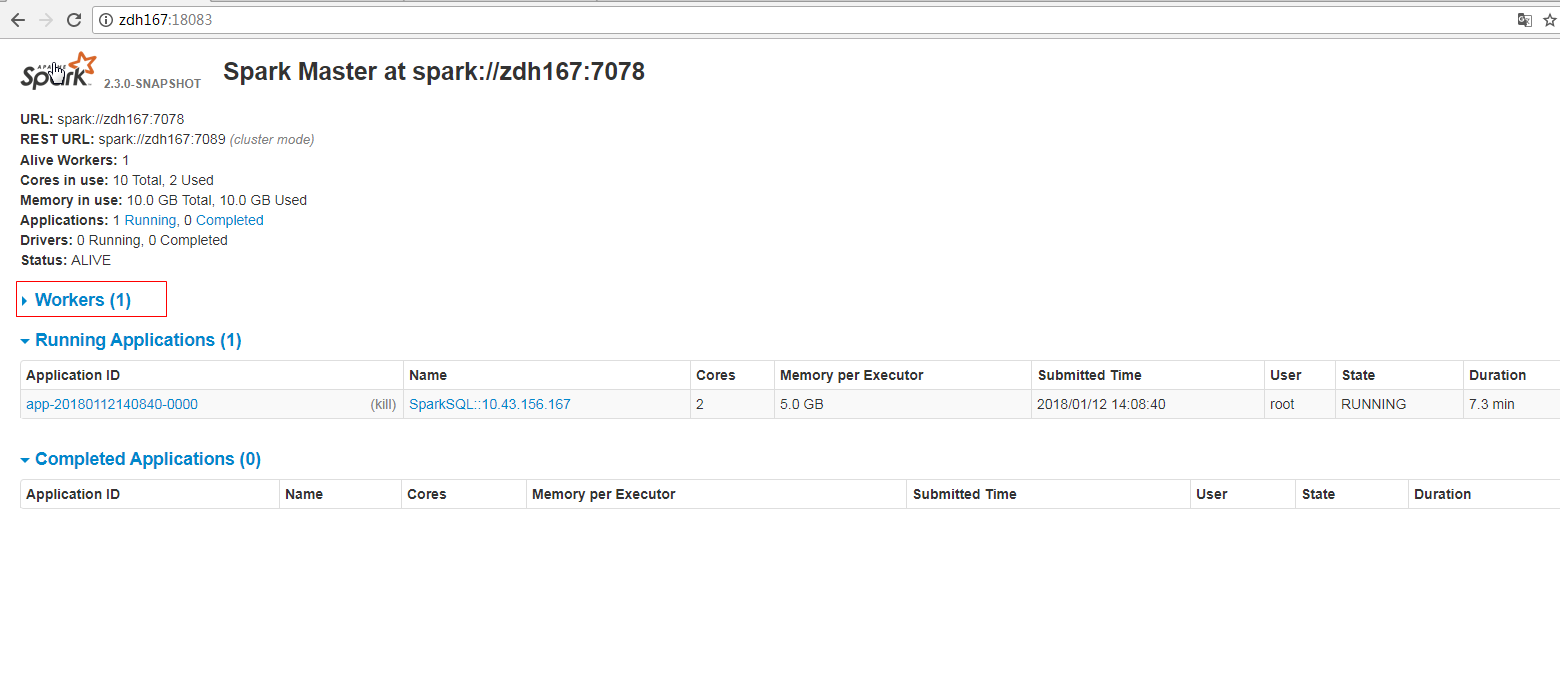 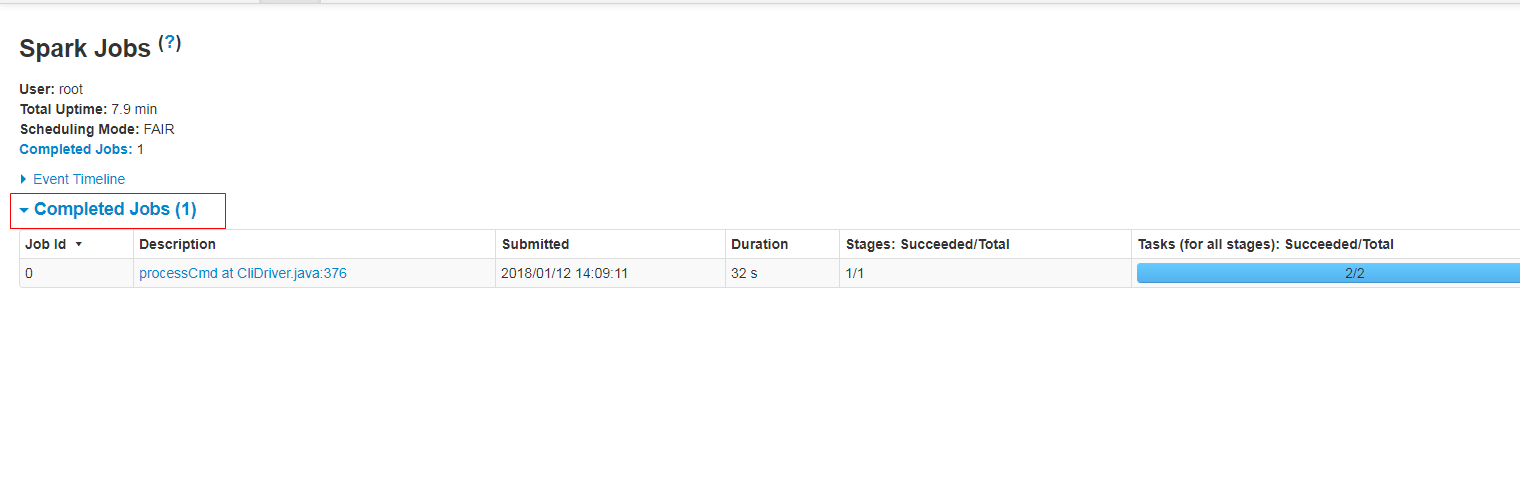  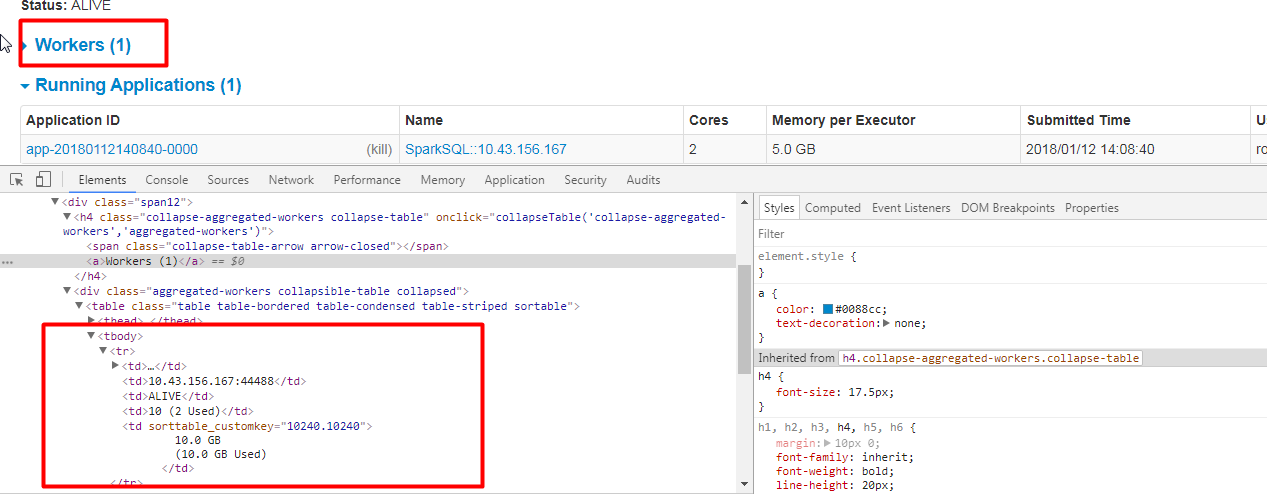 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20194: [SPARK-22999][SQL]'show databases like command' c...
Github user guoxiaolongzte commented on a diff in the pull request: https://github.com/apache/spark/pull/20194#discussion_r161130352 --- Diff: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 --- @@ -141,7 +141,7 @@ statement (LIKE? pattern=STRING)? #showTables | SHOW TABLE EXTENDED ((FROM | IN) db=identifier)? LIKE pattern=STRING partitionSpec? #showTable -| SHOW DATABASES (LIKE pattern=STRING)? #showDatabases +| SHOW DATABASES (LIKE? pattern=STRING)? #showDatabases --- End diff -- @gatorsmile @dongjoon-hyun I think we can make LIKE optional. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20216: [SPARK-23024][WEB-UI]Spark ui about the contents of the ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20216 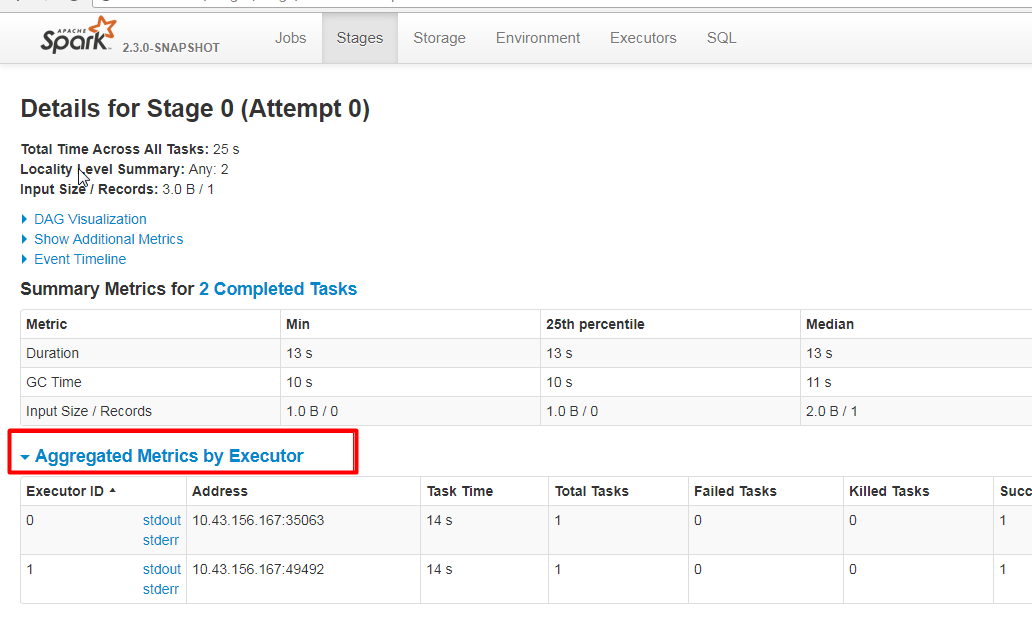 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20216: [SPARK-23024][WEB-UI]Spark ui about the contents of the ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20216 No, just hide the table, in fact, the data is already on the page, but we can not see. When we refresh the page, it will re-show all the data. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20194: [SPARK-22999][SQL]'show databases like command' c...
Github user guoxiaolongzte commented on a diff in the pull request: https://github.com/apache/spark/pull/20194#discussion_r160869162 --- Diff: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 --- @@ -141,7 +141,7 @@ statement (LIKE? pattern=STRING)? #showTables | SHOW TABLE EXTENDED ((FROM | IN) db=identifier)? LIKE pattern=STRING partitionSpec? #showTable -| SHOW DATABASES (LIKE pattern=STRING)? #showDatabases +| SHOW DATABASES (LIKE? pattern=STRING)? #showDatabases --- End diff -- No, I just saw like show tables like can be removed. so I think show databases like can also be removed. Just think it is removed, the operation is more convenient. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20216: [SPARK-23024][WEB-UI]Spark ui about the contents of the ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/20216 Dear Sir, However, the real spark big data environment, a very large number of workers, every day running a very large number of applications, has completed a very large number of applications, there are also some failed applications. When so much data are loaded into the WEB UI, coupled with slow Internet access and other factors, if you have a hidden form of the function, not only for the overall look and feel of the WEB UI neat, more personal feel more convenient than jump access. If you jump to a table and view the table's records, if you want to see the records in other tables, you have to flip it up and down because the jump's link is at the top of the page. Attachment has been uploaded. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20216: [SPARK-23024][WEB-UI]Spark ui about the contents ...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/20216 [SPARK-23024][WEB-UI]Spark ui about the contents of the form need to have hidden and show features, when the table records very much. ## What changes were proposed in this pull request? Spark ui about the contents of the form need to have hidden and show features, when the table records very much. Because sometimes you do not care about the record of the table, you just want to see the contents of the next table, but you have to scroll the scroll bar for a long time to see the contents of the next table. Currently we have about 500 workers, but I just wanted to see the logs for the running applications table. I had to scroll through the scroll bars for a long time to see the logs for the running applications table. In order to ensure functional consistency, I modified the Master Page, Worker Page, Job Page, Stage Page, Task Page, Configuration Page, Storage Page, Pool Page. ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-23024 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20216.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20216 commit 1e4a18616a41dfbb4d6e58134facd5e593846af5 Author: guoxiaolong <guo.xiaolong1@...> Date: 2018-01-10T08:16:40Z [SPARK-23024][WEB-UI]Spark ui about the contents of the form need to have hidden and show features, when the table records very much. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20194: [SPARK-22999][SQL]'show databases like command' c...
Github user guoxiaolongzte commented on a diff in the pull request: https://github.com/apache/spark/pull/20194#discussion_r160313038 --- Diff: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 --- @@ -141,7 +141,7 @@ statement (LIKE? pattern=STRING)? #showTables | SHOW TABLE EXTENDED ((FROM | IN) db=identifier)? LIKE pattern=STRING partitionSpec? #showTable -| SHOW DATABASES (LIKE pattern=STRING)? #showDatabases +| SHOW DATABASES (LIKE? pattern=STRING)? #showDatabases --- End diff -- Hive did not change, but I think spark can change the next. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20194: [SPARK-22999][SQL]'show databases like command' c...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/20194 [SPARK-22999][SQL]'show databases like command' can remove the like keyword ## What changes were proposed in this pull request? SHOW DATABASES (LIKE pattern = STRING)? Can be like the back increase? When using this command, LIKE keyword can be removed. You can refer to the SHOW TABLES command, SHOW TABLES 'test *' and SHOW TABELS like 'test *' can be used. Similarly SHOW DATABASES 'test *' and SHOW DATABASES like 'test *' can be used. ## How was this patch tested? unit tests manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-22999 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20194.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20194 commit 26e7c0d22b07144502eb5e05343d6a78824a1f1b Author: guoxiaolong <guo.xiaolong1@...> Date: 2018-01-09T02:40:39Z [SPARK-22999][SQL]'show databases like command' can remove the like keyword --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19841: [SPARK-22642][SQL] the createdTempDir will not be delete...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19841 +1, avoid unpredictable exceptions that cause the temporary directory or file to be deleted. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19532: [DOC]update the API doc and modify the stage API descrip...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19532 @cloud-fan Help merge the code. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19532: [DOC]update the API doc and modify the stage API descrip...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19532 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19532: [DOC]update the API doc and modify the stage API descrip...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19532 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19532: [DOC]update the API doc and modify the stage API descrip...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19532 I have updated the title and description. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19532: [CORE]Modify the duration real-time calculation and upda...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19532 Thank you for your review comments, I have to restore the code, not running in the code calculation. Now only keep the document changes. Please review again. @srowen @jiangxb1987 @cloud-fan @ajbozarth --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19625: [SPARK-22407][WEB-UI] Add rdd id column on storage page ...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19625 Please upload the screenshot in PR. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19532: [CORE]Modify the duration real-time calculation and upda...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19532 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19532: [CORE]Modify the duration real-time calculation a...
Github user guoxiaolongzte commented on a diff in the pull request: https://github.com/apache/spark/pull/19532#discussion_r147677958 --- Diff: core/src/main/scala/org/apache/spark/ui/SparkUI.scala --- @@ -120,7 +120,7 @@ private[spark] class SparkUI private ( attemptId = None, startTime = new Date(startTime), endTime = new Date(-1), -duration = 0, +duration = System.currentTimeMillis() - startTime, --- End diff -- No effect. In master page, âduration âis calculated using the duration attribute of the ApplicationInfo object. 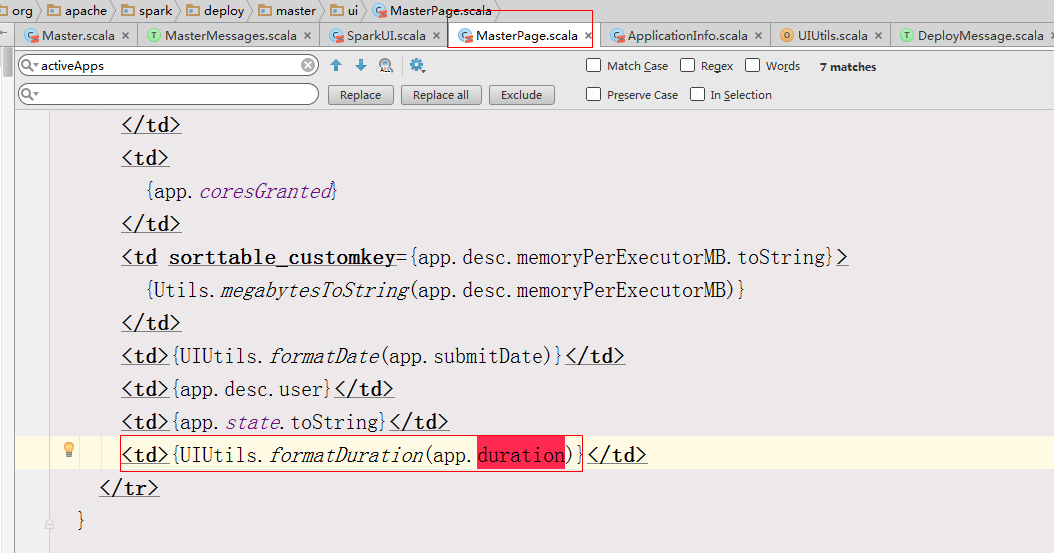 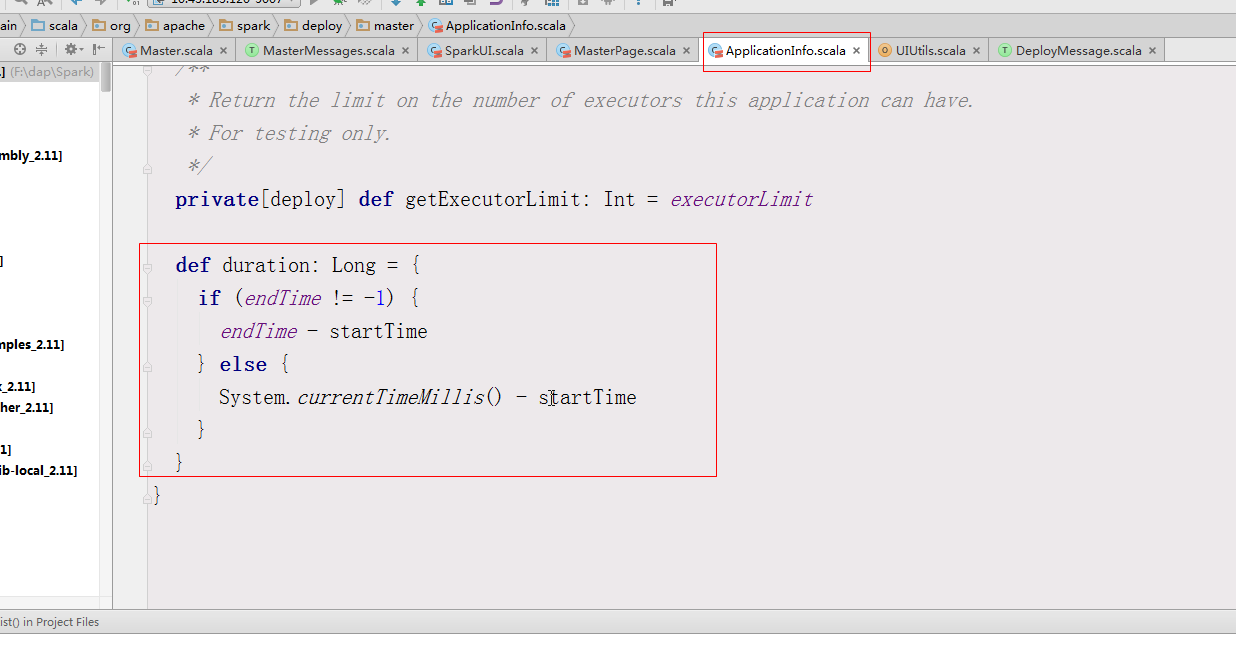 And ApplicationAttemptInfo object does not matter. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19520: [SPARK-22298][WEB-UI] url encode APP id before generatin...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19520 I would like to ask, under what circumstances the application id will contain a forward slash? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19507: [WEB-UI] Add count in fair scheduler pool page
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19507 @srowen Help review the code. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19532: [CORE]Modify the duration real-time calculation and upda...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19532 @jiangxb1987 @srowen Help review the code. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19507: [WEB-UI] Add count in fair scheduler pool page
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19507 Please refer to https://github.com/apache/spark/pull/19346 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19532: [CORE]Modify the duration real-time calculation and upda...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19532 @jiangxb1987 I modified it. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19532: [CORE]stage api modify the description format, ad...
Github user guoxiaolongzte commented on a diff in the pull request: https://github.com/apache/spark/pull/19532#discussion_r145618914 --- Diff: core/src/main/scala/org/apache/spark/ui/SparkUI.scala --- @@ -120,7 +120,7 @@ private[spark] class SparkUI private ( attemptId = None, startTime = new Date(startTime), endTime = new Date(-1), -duration = 0, +duration = System.currentTimeMillis() - startTime, --- End diff -- 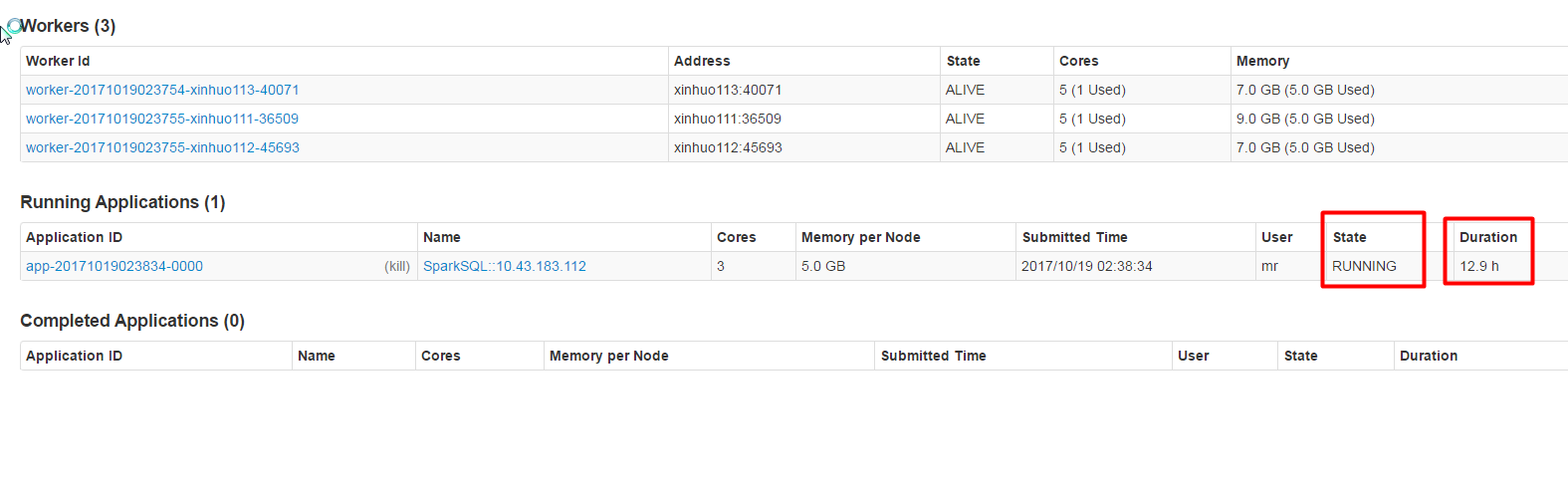 I would like to ask, running the spark application in master ui, why real-time display how long? The logic of these two places I think should be the same. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19532: [CORE]stage api modify the description format, ad...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/19532 [CORE]stage api modify the description format, add version api, modify the duration real-time calculation ## What changes were proposed in this pull request? stage api modify the description format A list of all stages for a given application. ?status=[active|complete|pending|failed] list only stages in the state. content should be included in add version api doc '/api/v1/version' modify the duration real-time calculation in running appcations ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-22311 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19532.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19532 commit 8f53eceb9ed3c33388cef09f628dfb7e4f6de70d Author: guoxiaolong <guo.xiaolo...@zte.com.cn> Date: 2017-10-19T03:15:13Z [CORE]stage api modify the description format, add version api, modify the duration real-time calculation --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19242: [CORE][DOC]Add event log conf.
Github user guoxiaolongzte commented on a diff in the pull request:
https://github.com/apache/spark/pull/19242#discussion_r145346521
--- Diff: docs/configuration.md ---
@@ -740,6 +740,20 @@ Apart from these, the following properties are also
available, and may be useful
+ spark.eventLog.overwrite
+ false
+
+Whether to overwrite any existing files.
+
+
+
+ spark.eventLog.buffer.kb
+ 100
+
+Buffer size to use when writing to output streams.Buffer size in KB.
--- End diff --
I have fixed the description and correction unit.
Please check org.apache.spark.internal.config#EVENT_LOG_OUTPUT_BUFFER_SIZE
private[spark] val EVENT_LOG_OUTPUT_BUFFER_SIZE =
ConfigBuilder("spark.eventLog.buffer.kb")
.bytesConf(ByteUnit.KiB)
.createWithDefaultString("100k")
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19242: [CORE][DOC]Add event log conf.
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19242 @srowen Help to review the code, thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19360: [SPARK-22139][CORE]Remove the variable which is n...
Github user guoxiaolongzte closed the pull request at: https://github.com/apache/spark/pull/19360 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19360: [SPARK-22139][CORE]Remove the variable which is n...
GitHub user guoxiaolongzte reopened a pull request: https://github.com/apache/spark/pull/19360 [SPARK-22139][CORE]Remove the variable which is never used in SparkConf.scala ## What changes were proposed in this pull request? Remove the variable which is never used in SparkConf.scala. val executorClasspathKey = "spark.executor.extraClassPath" val driverOptsKey = "spark.driver.extraJavaOptions" val driverClassPathKey = "spark.driver.extraClassPath" val sparkExecutorInstances = "spark.executor.instances" They variables are never used. Because the implementation code for the validation rule has been removed in SPARK-17979. ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-22139 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19360.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19360 commit f345aa8487a64a0256c6965bc198ba8842cd0a51 Author: guoxiaolong <guo.xiaolo...@zte.com.cn> Date: 2017-09-27T06:58:37Z [SPARK-22139] Remove the variable which is never used in SparkConf.scala --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19507: [WEB-UI] Add count in fair scheduler pool page
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19507 @ajbozarth Sorry, upload the code before I accidentally withdrew the parenthesis. I rejoined the parenthesis. I have fixed it. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19507: add count in fair scheduler pool page
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/19507 add count in fair scheduler pool page ## What changes were proposed in this pull request? Add count in fair scheduler pool page. The purpose is to know the statistics clearly. For specific reasons, please refer to PR of https://github.com/apache/spark/pull/18525 ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark add_count_in_fair_scheduler_pool_page Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19507.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19507 commit 4903200a3bb36ba42e3fb57d4fc160cb637554a3 Author: guoxiaolong <guo.xiaolo...@zte.com.cn> Date: 2017-10-16T11:18:18Z add count in fair scheduler pool page --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19399: [SPARK-22175][WEB-UI] Add status column to history page
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19399 Nice, I think it should be merged. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19360: [SPARK-22139][CORE]Remove the variable which is n...
Github user guoxiaolongzte closed the pull request at: https://github.com/apache/spark/pull/19360 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19360: [SPARK-22139][CORE]Remove the variable which is never us...
Github user guoxiaolongzte commented on the issue: https://github.com/apache/spark/pull/19360 @HyukjinKwon The problem of the PR you follow, I do not care, I will close this PR. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19397: [SPARK-22173] Table CSS style needs to be adjuste...
GitHub user guoxiaolongzte opened a pull request: https://github.com/apache/spark/pull/19397 [SPARK-22173] Table CSS style needs to be adjusted in History Page and in Executors Page. ## What changes were proposed in this pull request? There is a problem with table CSS style. 1. At present, table CSS style is too crowded, and the table width cannot adapt itself. 2. Table CSS style is different from job page, stage page, task page, master page, worker page, etc. The Spark web UI needs to be consistent. ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/guoxiaolongzte/spark SPARK-22173 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19397.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19397 commit ff46aa01208b640cabb897f6d5f7bd1fe2dcbccf Author: guoxiaolong <guo.xiaolo...@zte.com.cn> Date: 2017-09-30T01:35:36Z [SPARK-22173] Table CSS style needs to be adjusted in History Page and in Executors Page. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org