[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39401757 @hirakendu Thanks a lot for the detailed comments and feedback. Yes, we have a responsibility to keep improving the trees going forward so getting additional feedback is awesome. The feedback around the current implementation in the 'Miscellaneous' section is around renaming and minor refactoring of code. I agree with most of the feedback and some choices are personal preferences which should discuss and resolve. We should address it soon when we implement the better ```Impurity``` interface that we promised to implement ASAP. I think the "Error" interface you described is very similar to what @mengxr proposed as well. We should discuss the naming convention. Even though I don't feel strongly about "Impurity" but "Error" might not be the best name for the classification scenario. I am open to better names and ready to be convinced otherwise. :-) For 'General Design Notes', I have similar thoughts but I will wait for @etrain's comments since he has thought about it carefully. In general, I like @etrain 's MLI design for Model and Algorithm. I did not tie the current implementation to the existing traits yet since I wanted to have a broader conversation about it after the tree PR. It's straightforward to implement once we agree on the interfaces for mllib algorithms. Finally, and most importantly, thanks a ton for performing such extensive tests on a massive dataset! The results are not too shabby. ;-) --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39396722 Thanks for noticing the typo, it's 500 million examples. Corrected it. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user etrain commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39392123 Hi Hirakendu - thanks for all the detailed suggestions and information. I will reply to that separately. One question - you say there are 500,000 examples and this equates to 90GB of raw data. If that's the case, this works out to ~200KB per example - is that right or are you off by an order of magnitude in either the number of features or the number of data points? Or are we throwing a bunch of data out before fitting? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39390821 Since it's a long review, I have put things together in one place [spark_mllib_tree_pr79_review.md](https://github.com/hirakendu/temp/blob/master/spark_mllib_tree_pr79_review/spark_mllib_tree_pr79_review.md) so that it's easy to track later. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on the pull request:
https://github.com/apache/spark/pull/79#issuecomment-39390268
In terms of running time performance, here are some scalability results for
a large scale dataset. Results look satisfactory :).
The code was tested on a dataset for a binary classification problem. A
regression tree with `Variance` (square loss) was trained because it's
computationally more intensive. The dataset consists of about `500,000`
training instances. There are 20 features, all numeric. Although there are
categorical features in the dataset and the algorithm implementation supports
it, they were not used since the main program doesn't have options.
The dataset is of size about 90 GB in plain text format. It consists of 100
part files, each about 900 MB. To _optimize_ number of tasks to align with
number of workers, the task split size was chosen to be 160 MB to have 300
tasks.
The model training experiements were done on a Yahoo internal Hadoop
cluster. The CPUs are of type Intel Xeon 2.4 GHz. The Spark YARN adaptation was
used to run on Hadoop cluster. Both master-memory and worker-memory were set to
`7500m` and the cluster was under light to moderate load at the time of
experiments. The fraction of memory used for caching was `0.3`,
leading to about `2 GB` of memory per worker for caching. The number of
workers used for various experiments were `20, 30, 60, 100, 150, 300, 600` to
evenly align with 600 tasks. Note that with 20 and 30 workers, only `48%` and
`78%` of the 90 GB data could be cached in memory. The decision tree of depth
10 was trained and minor code changes were made to record the individual level
training times. The training command (with additional JVM settings) used is
time \
SPARK_JAVA_OPTS="${SPARK_JAVA_OPTS} \
-Dspark.hadoop.mapred.min.split.size=167772160 \
-Dspark.hadoop.mapred.max.split.size=167772160" \
-Dspark.storage.memoryFraction=0.3 \
spark-class org.apache.spark.deploy.yarn.Client \
--queue ${QUEUE} \
--num-workers ${NUM_WORKERS} \
--worker-memory 7500m \
--worker-cores 1 \
--master-memory 7500m \
--jar ${JARS}/spark_mllib_tree.jar \
--class org.apache.spark.mllib.tree.DecisionTree \
--args yarn-standalone \
--args --algo --args Regression \
--args --trainDataDir --args ${DIST_WORK}/train_data_lp.txt \
--args --testDataDir --args ${DIST_WORK}/test_data_0p1pc_lp.txt \
--args --maxDepth --args 10 \
--args --impurity --args Variance \
--args --maxBins --args 100
The training times for training each depth and for each choice of number of
workers is in the attachments
[workers_times.txt](https://raw.githubusercontent.com/hirakendu/temp/master/spark_mllib_tree_pr79_review/workers_times.txt).
The attached graphs demonstrate the scalability in terms of
cumulative training times for various depths and various number of workers.
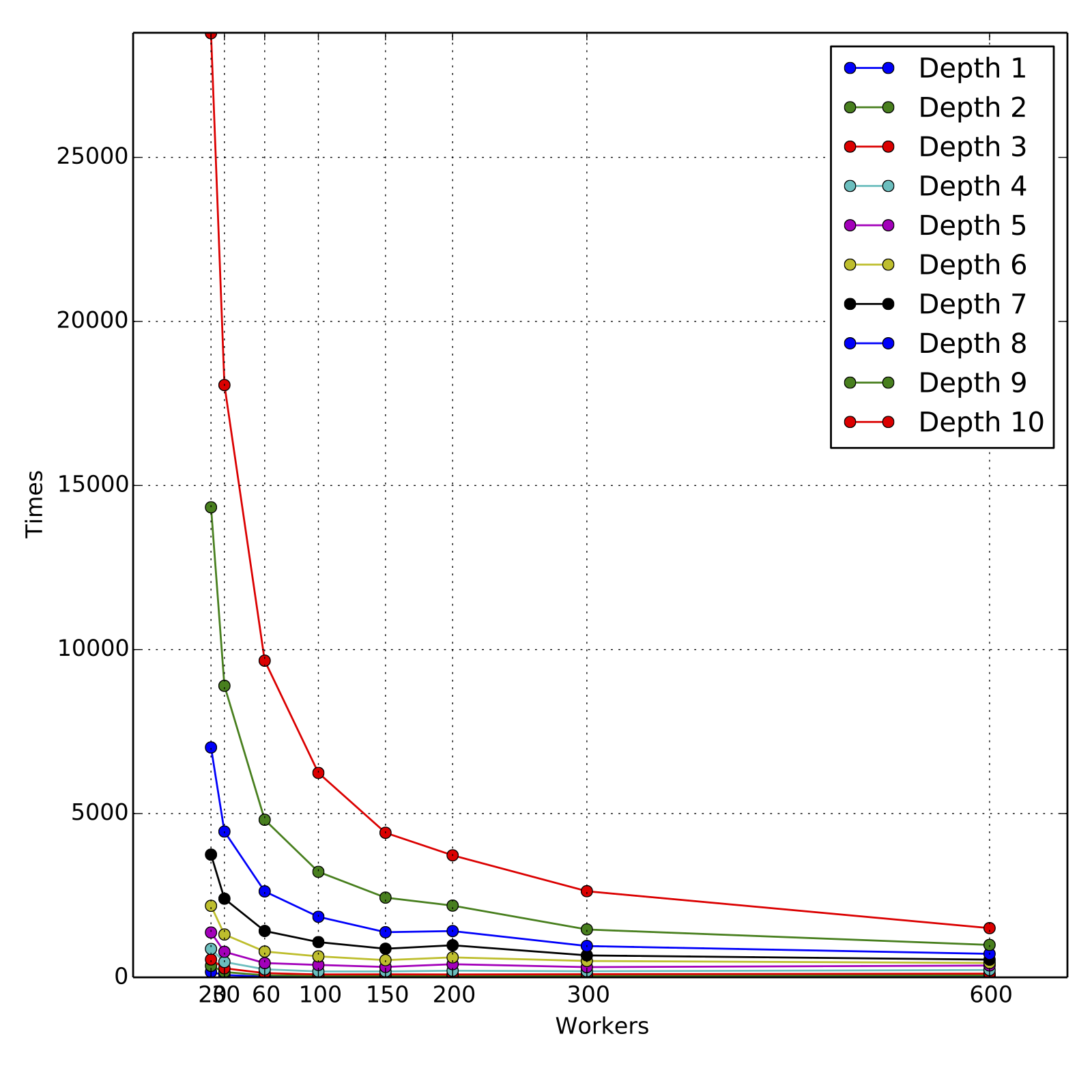
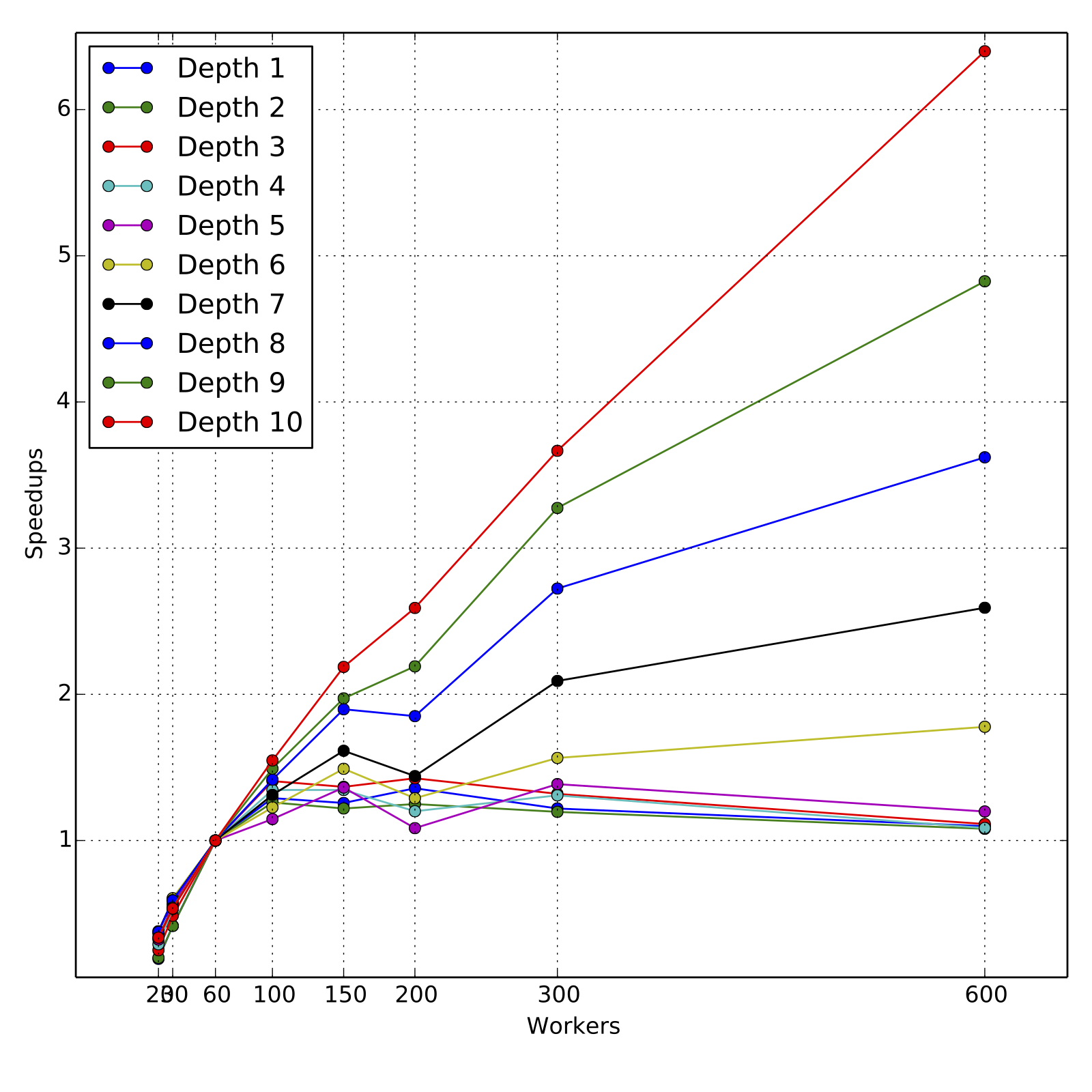
For obtaining the speed-ups, the training times are compared to those for
60 workers, since the data could not be cached completely for 20 and 30
workers. For all experiments, the resources requested
were fully allocated by the cluster and all experiments ran to completion
in their first and only run.
As we can see, the scaling is nearly linear for higher depths 9 and 10,
across the range of 60 workers to 600 workers, although the slope is less than
1 as expected. For such loads, 60 to 100 workers are a reasonable computing
resource and the total training times are about 160 minutes and 100 minutes
respectively. Overall, the performance is satisfactory, in particular when trees
of depth 4 or 5 are trained for boosting models. But clearly, there is room
for improvement in the following sense. The dataset when fully cached takes
about 10s for a count operation, whereas the training time for first level that
involves simple histogram calculation of three error statistics takes roughly
30 seconds.
The error performance in terms of RMSE was verified to be close to that of
alternate implementations.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request: https://github.com/apache/spark/pull/79#discussion_r11229944 --- Diff: mllib/src/main/scala/org/apache/spark/mllib/tree/DecisionTree.scala --- @@ -0,0 +1,1150 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.mllib.tree --- End diff -- A plan should be made to have a consistent hierarchy and organization of various algorithms in the MLLib package. A separate `tree` subpackage seems unnecessary. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11229920
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/DecisionTree.scala ---
@@ -0,0 +1,1150 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree
+
+import scala.util.control.Breaks._
+
+import org.apache.spark.{Logging, SparkContext}
+import org.apache.spark.SparkContext._
+import org.apache.spark.mllib.regression.LabeledPoint
+import org.apache.spark.mllib.tree.configuration.Strategy
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.configuration.FeatureType._
+import org.apache.spark.mllib.tree.configuration.QuantileStrategy._
+import org.apache.spark.mllib.tree.impurity.{Entropy, Gini, Impurity,
Variance}
+import org.apache.spark.mllib.tree.model._
+import org.apache.spark.rdd.RDD
+import org.apache.spark.util.random.XORShiftRandom
+
+/**
+ * A class that implements a decision tree algorithm for classification
and regression. It
+ * supports both continuous and categorical features.
+ * @param strategy The configuration parameters for the tree algorithm
which specify the type
+ * of algorithm (classification, regression, etc.),
feature type (continuous,
+ * categorical), depth of the tree, quantile calculation
strategy, etc.
+ */
+class DecisionTree private(val strategy: Strategy) extends Serializable
with Logging {
+
+ /**
+ * Method to train a decision tree model over an RDD
+ * @param input RDD of
[[org.apache.spark.mllib.regression.LabeledPoint]] used as training data
+ * @return a DecisionTreeModel that can be used for prediction
+ */
+ def train(input: RDD[LabeledPoint]): DecisionTreeModel = {
+
+// Cache input RDD for speedup during multiple passes.
+input.cache()
+logDebug("algo = " + strategy.algo)
+
+// Find the splits and the corresponding bins (interval between the
splits) using a sample
+// of the input data.
+val (splits, bins) = DecisionTree.findSplitsBins(input, strategy)
+logDebug("numSplits = " + bins(0).length)
+
+// depth of the decision tree
+val maxDepth = strategy.maxDepth
+// the max number of nodes possible given the depth of the tree
+val maxNumNodes = scala.math.pow(2, maxDepth).toInt - 1
+// Initialize an array to hold filters applied to points for each node.
+val filters = new Array[List[Filter]](maxNumNodes)
+// The filter at the top node is an empty list.
+filters(0) = List()
+// Initialize an array to hold parent impurity calculations for each
node.
+val parentImpurities = new Array[Double](maxNumNodes)
+// dummy value for top node (updated during first split calculation)
+val nodes = new Array[Node](maxNumNodes)
+
+
+/*
+ * The main idea here is to perform level-wise training of the
decision tree nodes thus
+ * reducing the passes over the data from l to log2(l) where l is the
total number of nodes.
+ * Each data sample is checked for validity w.r.t to each node at a
given level -- i.e.,
+ * the sample is only used for the split calculation at the node if
the sampled would have
+ * still survived the filters of the parent nodes.
+ */
+
+// TODO: Convert for loop to while loop
+breakable {
+ for (level <- 0 until maxDepth) {
+
+logDebug("#")
+logDebug("level = " + level)
+logDebug("#")
+
+// Find best split for all nodes at a level.
+val splitsStatsForLevel = DecisionTree.findBestSplits(input,
parentImpurities, strategy,
+ level, filters, splits, bins)
+
+for ((nodeSplitStats, index) <-
splitsStatsForLevel.view.zipWithIndex) {
+
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11229869
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/configuration/Algo.scala ---
@@ -0,0 +1,26 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.configuration
+
+/**
+ * Enum to select the algorithm for the decision tree
+ */
+object Algo extends Enumeration {
--- End diff --
The various `Enumeration` classes in `mllib.tree.configuration` package are
neat. A uniform _design pattern_ for parameters and options should be used for
MLLib and Spark, and this could be a start. Alternatively, if there is an
existing pattern in use, it should be followed for decision tree as well.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11229453
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/configuration/Algo.scala ---
@@ -0,0 +1,26 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.configuration
+
+/**
+ * Enum to select the algorithm for the decision tree
+ */
+object Algo extends Enumeration {
--- End diff --
The `Algorithm` Enumeration seems redundant given `Impurity` which implies
the `Algorithm` anyway.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11229365
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trait for calculating information gain.
+ */
+trait Impurity extends Serializable {
--- End diff --
`Impurity` should be renamed to `Error` or something more technical and
familiar. Also see the comments earlier for the necessity and example design of
a generic `Error` interface.
The `calculate` method can be renamed to something verbose like `error`.
For a generic interface, an additional `ErrorStats` trait and
`error(errorStats: ErrorStats)` method can be added. For example, `Variance` or
more aptly, `SquareError`, would implement `case class SquareErrorStats(count:
Long, mean: Double, meanSquare: Double)` and `error(errorStats) =
errorStats.meanSquare - errorStats.mean * errorStats.mean / count`. Note that
`ErrorStats` should have aggregation methods, e.g., it's easy to see the
implementation for `SquareErrorStats`.
The `Variance` class should be renamed to `SquareError`, `Entropy` to
`EntropyError` or `KLDivergence`, `Gini` to `GiniError`.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request: https://github.com/apache/spark/pull/79#discussion_r11229274 --- Diff: mllib/src/main/scala/org/apache/spark/mllib/tree/model/Bin.scala --- @@ -0,0 +1,33 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.mllib.tree.model + +import org.apache.spark.mllib.tree.configuration.FeatureType._ + +/** + * Used for "binning" the features bins for faster best split calculation. For a continuous + * feature, a bin is determined by a low and a high "split". For a categorical feature, + * the a bin is determined using a single label value (category). + * @param lowSplit signifying the lower threshold for the continuous feature to be + * accepted in the bin + * @param highSplit signifying the upper threshold for the continuous feature to be + * accepted in the bin + * @param featureType type of feature -- categorical or continuous + * @param category categorical label value accepted in the bin + */ +case class Bin(lowSplit: Split, highSplit: Split, featureType: FeatureType, category: Double) --- End diff -- `Bin` class can be simplified and some members renamed. The `lowSplit`, `highSplit` can be simplified to the single threshold corresponding to the left end of the bin range. This can be named to `leftEnd` or `lowEnd`. It's not clear this class is needed at first place. For categorical variables, the value itself is the bin index, and for continuous variables, bins are simply defined by candidate thresholds, in turn defined by quanties. For every feature id, one can maintain a list of categories and thresholds and be done. In that case, for continuous features, the position of the threshold is the bin index. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request: https://github.com/apache/spark/pull/79#discussion_r11229300 --- Diff: mllib/src/main/scala/org/apache/spark/mllib/tree/model/InformationGainStats.scala --- @@ -0,0 +1,39 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.mllib.tree.model + +/** + * Information gain statistics for each split + * @param gain information gain value + * @param impurity current node impurity + * @param leftImpurity left node impurity + * @param rightImpurity right node impurity + * @param predict predicted value + */ +class InformationGainStats( --- End diff -- `InformationGainStats` and `Split` nicely separate the members of `Node`, but can also be flattened and put at top level. Would make storage and explanation slightly easier, albeit less unstructured. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request: https://github.com/apache/spark/pull/79#discussion_r11229221 --- Diff: mllib/src/main/scala/org/apache/spark/mllib/tree/configuration/Strategy.scala --- @@ -0,0 +1,43 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.mllib.tree.configuration + +import org.apache.spark.mllib.tree.impurity.Impurity +import org.apache.spark.mllib.tree.configuration.Algo._ +import org.apache.spark.mllib.tree.configuration.QuantileStrategy._ + +/** + * Stores all the configuration options for tree construction + * @param algo classification or regression + * @param impurity criterion used for information gain calculation + * @param maxDepth maximum depth of the tree + * @param maxBins maximum number of bins used for splitting features + * @param quantileCalculationStrategy algorithm for calculating quantiles + * @param categoricalFeaturesInfo A map storing information about the categorical variables and the + *number of discrete values they take. For example, an entry (n -> + *k) implies the feature n is categorical with k categories 0, + *1, 2, ... , k-1. It's important to note that features are + *zero-indexed. + */ +class Strategy ( --- End diff -- `Strategy` should be renamed to `Parameters`. Modeling and algorithm parameters can be separate, the latter being part of the model. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request: https://github.com/apache/spark/pull/79#discussion_r11229187 --- Diff: mllib/src/main/scala/org/apache/spark/mllib/tree/model/Node.scala --- @@ -0,0 +1,90 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.mllib.tree.model + +import org.apache.spark.Logging +import org.apache.spark.mllib.tree.configuration.FeatureType._ + +/** + * Node in a decision tree + * @param id integer node id + * @param predict predicted value at the node + * @param isLeaf whether the leaf is a node + * @param split split to calculate left and right nodes + * @param leftNode left child + * @param rightNode right child + * @param stats information gain stats + */ +class Node ( --- End diff -- `Node` should be a recursive/linked structure with references to child nodes and parent node (the latter allows for easy traversal), so I don't see the need for `nodes: Array[Node]` as the model and the `build` method in `Node`. The `DecisionTreeModel` should essentially be the root `Node` with methods like `predict` etc. involving a recursive traversal on child nodes. The method `predictIfleaf` in `Node` should be renamed to simply `predict`. It predicts regardless of whether it's a leaf and does recursive traversal until it hits a leaf child. The prediction value should be renamed to `prediction` instead of `predict`, which would clean up the ambiguity with this `predict` method. Putting things together: `Node` should be simple with a `prediction` and should be a recursive structure. `DecisionTreeModel` should be a wrapper around a root `Node` member and contain methods like `predict`, `save`, `explain`, `load` etc. based on recursive traversal. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request: https://github.com/apache/spark/pull/79#discussion_r11229120 --- Diff: mllib/src/main/scala/org/apache/spark/mllib/tree/model/Split.scala --- @@ -0,0 +1,64 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.mllib.tree.model + +import org.apache.spark.mllib.tree.configuration.FeatureType.FeatureType + +/** + * Split applied to a feature + * @param feature feature index + * @param threshold threshold for continuous feature + * @param featureType type of feature -- categorical or continuous + * @param categories accepted values for categorical variables + */ +case class Split( --- End diff -- The functionality of `Split` can be simplified by a modification. If I understand correctly, `Split` represents the left or right (low or high) branch of the parent node. Instead, it suffices to store the branching condition for each node as a splitting condition. This can be appropriately named as `SplitPredicate` or `SplittingCondition` or branching condition and consist of feature id, feature type (continuous or categorical), threshold, left branch categories and right branch categories. I think depending on the choice here, we require `Filter`, but nonetheless I think it's redundant and we should exploit the recursive/linked structure of tree, which we are doing anyway. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11229035
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/model/Filter.scala ---
@@ -0,0 +1,28 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.model
+
+/**
+ * Filter specifying a split and type of comparison to be applied on
features
+ * @param split split specifying the feature index, type and threshold
+ * @param comparison integer specifying <,=,>
+ */
+case class Filter(split: Split, comparison: Int) {
--- End diff --
`Filter` class is a nice abstraction of branching conditions leading to
current node. There are already references to left and right child nodes, so I
think this is redundant. If need be, a reference to a parent node as an
`Option[Node]` suffices and is more useful. The functionality should be covered
across `Node` and `Split` classes.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11228983
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/DecisionTree.scala ---
@@ -0,0 +1,1150 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree
+
+import scala.util.control.Breaks._
+
+import org.apache.spark.{Logging, SparkContext}
+import org.apache.spark.SparkContext._
+import org.apache.spark.mllib.regression.LabeledPoint
+import org.apache.spark.mllib.tree.configuration.Strategy
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.configuration.FeatureType._
+import org.apache.spark.mllib.tree.configuration.QuantileStrategy._
+import org.apache.spark.mllib.tree.impurity.{Entropy, Gini, Impurity,
Variance}
+import org.apache.spark.mllib.tree.model._
+import org.apache.spark.rdd.RDD
+import org.apache.spark.util.random.XORShiftRandom
+
+/**
+ * A class that implements a decision tree algorithm for classification
and regression. It
+ * supports both continuous and categorical features.
+ * @param strategy The configuration parameters for the tree algorithm
which specify the type
+ * of algorithm (classification, regression, etc.),
feature type (continuous,
+ * categorical), depth of the tree, quantile calculation
strategy, etc.
+ */
+class DecisionTree private(val strategy: Strategy) extends Serializable
with Logging {
--- End diff --
`DecisionTree` class and object should be reorganized and separated into
`DecisionTreeModel` and `DecisionTreeAlgorithm`, with a `Strategy` and root
`Node` as part of `Model` and `train` as part of the `Algorithm`.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11228901
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
Adding to the discussion on the need for a generic interface for
`Impurity`, or more precisely `Error`, I believe we all see that it's good to
have. Ideally I would have preferred a single `Error` trait and that all types
of Error like Square or KL divergence extend it, but the consensus is
that it negatively impacts performance.
In addition to performance-oriented implementations for specific loss
functions, I would still recommend a generic `Error` interface and a generic
implementation of decision-tree based on this interface. One possibility is to
add a third `calculate(stats)`, or more precisely `error(errorStats:
ErrorStats)` to the `Error` interface. I am not sure it will help the signature
collision problem though, unless we just keep the one signature for generic
error statistics.
For reference and example of one such interface and implementations, see
`trait LossStats[S <: LossStats[S]]` and `abstract class Loss[S <:
LossStats[S]:Manifest]` in my previous PR,
[https://github.com/apache/incubator-spark/pull/161/files](https://github.com/apache/incubator-spark/pull/161/files),
that exactly do that and provide interfaces for aggregable error statistics
and calculating error from these statistics. (On second thought, I feel
`ErrorStats` and `Error` are better names.) Also see the generic implementation
`class DecisionTreeAlgorithm[S <: LossStats[S]:Manifest]` and implementations
of specific error functions, `SquareLoss` and `EntropyLoss`.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39385736 Thanks Manish, Evan, Ameet, Ram, and thanks Xiangrui, Matei. It's great to have this PR merged, but I think there is room for a lot of improvement, and I hope this thread is still open for comments. I have some detailed notes from my side, we can track them in a separate place if required. Some design notes to start with: The current design of classes and relationships is good, but I think it would be great if it can be modified slightly to make it similar to the design of other existing algorithms in MLLib and extend the existing interfaces. For example, we can have a `DecisionTreeModel` or that extends the existing `RegressionModel` interface, similar to the existing `RidgeRegressionModel` and `LinearRegressionModel`. Alternatively, we can have separate `ClassificationTreeModel` and `RegressionTreeModel` that extend the existing interfaces `ClassificationModel` and `RegressionModel` respectively. Note that it is important to keep the `Model` as a class, so that we can later compose ensemble and other composite models consisting of multiple `Model` instances. Currently the decision tree `Node` is essentially the `Model`, although I would prefer a wrapper around it and explicitly called `DecisionTreeModel` that implements methods like `predict`, `save`, `explain`, `load` like I remember coming across in MLI. In the file `DecisionTree.scala`, the actual class can be renamed to `DecisionTreeAlgorithm` that extends `Algorithm` interface that implements `train(samples)` and outputs a `RegressionModel`. Note that there is no `Algorithm` interface currently in MLLib, although there may be one in MLI and the closest is `abstract class GeneralizedLinearAlgorithm[M <: GeneralizedLinearModel]`. Modeling `Strategy` should be renamed to `Parameters`. I would prefer a separation between model parameters like depth, minimum gain and algorithm parameters like level-by-level training or caching. The line is blurred for some aspects like quantile strategy, but I am inclined to put those into modeling parameters, so it can be referred to later on. Rule of thumb being that different algorithm parameters should lead to same model (up to randomization effects) for the same model parameters. `Impurity` should be renamed to `Error` or something more technical. Also see my later comments on the need for a generic `Error` Interface that allow easy adaptation of algorithms for specific loss functions. In general, MLLib and MLI should define proper interfaces for `Model`, `Algorithm`, `Parameters` and importantly `Loss` entities, at least for supervised machine learning algorithms and all implementations should adhere to it. Surprisingly, MLLIb or MLI currently doesn't have a `Loss` or `Error` interface, the closest being the `Optimizer` interface. There is also a need for portable model output formats, e.g., JSON, that can be used by other programs, possibly written in other languages outside Scala and Java. Can also use an existing format like PMML (not sure if it's widely used). Lastly, there is a need to support standard data formats with optional delimiter parameters - I am sure this a general need for Spark. I understand there has been significant effort before for standardization, would be good to know about the current status. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/79 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mateiz commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39288342 Excellent, thanks a lot Manish, Ram and others! I've merged this in. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39287513 @mateiz This looks good to me and I will mark some APIs developer/experimental after it gets merged. Please help merge it. Thanks @manishamde , @hirakendu , @etrain , @atalwalkar , and @harsha2010 for the work! --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39169881 All automated tests passed. Refer to this link for build results: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/13623/ --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39169879 Merged build finished. All automated tests passed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39167685 Merged build triggered. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39167697 Merged build started. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39159295 Merged build finished. All automated tests passed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39159296 All automated tests passed. Refer to this link for build results: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/13614/ --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39155725 Merged build started. Build is starting -or- tests failed to complete. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39155715 Merged build triggered. Build is starting -or- tests failed to complete. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39155337 @manishamde Please merge the changes at https://github.com/manishamde/spark/pull/4 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11142394
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/configuration/Strategy.scala
---
@@ -0,0 +1,47 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.configuration
+
+import org.apache.spark.mllib.tree.impurity.Impurity
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.configuration.QuantileStrategy._
+
+/**
+ * Stores all the configuration options for tree construction
+ * @param algo classification or regression
+ * @param impurity criterion used for information gain calculation
+ * @param maxDepth maximum depth of the tree
+ * @param maxBins maximum number of bins used for splitting features
+ * @param quantileCalculationStrategy algorithm for calculating quantiles
+ * @param categoricalFeaturesInfo A map storing information about the
categorical variables and the
+ *number of discrete values they take. For
example, an entry (n ->
+ *k) implies the feature n is categorical
with k categories 0,
+ *1, 2, ... , k-1. It's important to note
that features are
+ *zero-indexed.
+ */
+class Strategy (
+val algo: Algo,
+val impurity: Impurity,
+val maxDepth: Int,
+val maxBins: Int = 100,
+val quantileCalculationStrategy: QuantileStrategy = Sort,
+val categoricalFeaturesInfo: Map[Int,Int] =
Map[Int,Int]()) extends Serializable {
+
+ var numBins: Int = Int.MinValue
--- End diff --
Will do. Thanks!
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11142399
--- Diff:
mllib/src/test/scala/org/apache/spark/mllib/tree/DecisionTreeSuite.scala ---
@@ -0,0 +1,431 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree
+
+import org.scalatest.BeforeAndAfterAll
+import org.scalatest.FunSuite
+
+import org.apache.spark.SparkContext
+import org.apache.spark.mllib.regression.LabeledPoint
+import org.apache.spark.mllib.tree.impurity.{Entropy, Gini, Variance}
+import org.apache.spark.mllib.tree.model.Filter
+import org.apache.spark.mllib.tree.configuration.Strategy
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.configuration.FeatureType._
+
+class DecisionTreeSuite extends FunSuite with BeforeAndAfterAll {
+
+ @transient private var sc: SparkContext = _
+
+ override def beforeAll() {
+sc = new SparkContext("local", "test")
+ }
+
+ override def afterAll() {
+sc.stop()
+System.clearProperty("spark.driver.port")
+ }
+
+ test("split and bin calculation"){
+val arr = DecisionTreeSuite.generateOrderedLabeledPointsWithLabel1()
+assert(arr.length == 1000)
+val rdd = sc.parallelize(arr)
+val strategy = new Strategy(Classification,Gini,3,100)
+val (splits, bins) = DecisionTree.findSplitsBins(rdd,strategy)
+assert(splits.length==2)
+assert(bins.length==2)
+assert(splits(0).length==99)
+assert(bins(0).length==100)
+ }
+
+ test("split and bin calculation for categorical variables"){
+val arr = DecisionTreeSuite.generateCategoricalDataPoints()
+assert(arr.length == 1000)
+val rdd = sc.parallelize(arr)
+val strategy = new
Strategy(Classification,Gini,3,100,categoricalFeaturesInfo = Map(0 -> 2,
+ 1-> 2))
+val (splits, bins) = DecisionTree.findSplitsBins(rdd,strategy)
+assert(splits.length==2)
+assert(bins.length==2)
+assert(splits(0).length==99)
+assert(bins(0).length==100)
+
+//Checking splits
+
+assert(splits(0)(0).feature == 0)
+assert(splits(0)(0).threshold == Double.MinValue)
+assert(splits(0)(0).featureType == Categorical)
+assert(splits(0)(0).categories.length == 1)
+assert(splits(0)(0).categories.contains(1.0))
+
+
+assert(splits(0)(1).feature == 0)
+assert(splits(0)(1).threshold == Double.MinValue)
+assert(splits(0)(1).featureType == Categorical)
+assert(splits(0)(1).categories.length == 2)
+assert(splits(0)(1).categories.contains(1.0))
+assert(splits(0)(1).categories.contains(0.0))
+
+assert(splits(0)(2) == null)
+
+assert(splits(1)(0).feature == 1)
+assert(splits(1)(0).threshold == Double.MinValue)
+assert(splits(1)(0).featureType == Categorical)
+assert(splits(1)(0).categories.length == 1)
+assert(splits(1)(0).categories.contains(0.0))
+
+
+assert(splits(1)(1).feature == 1)
+assert(splits(1)(1).threshold == Double.MinValue)
+assert(splits(1)(1).featureType == Categorical)
+assert(splits(1)(1).categories.length == 2)
+assert(splits(1)(1).categories.contains(1.0))
+assert(splits(1)(1).categories.contains(0.0))
+
+assert(splits(1)(2) == null)
+
+
+// Checks bins
+
+assert(bins(0)(0).category == 1.0)
+assert(bins(0)(0).lowSplit.categories.length == 0)
+assert(bins(0)(0).highSplit.categories.length == 1)
+assert(bins(0)(0).highSplit.categories.contains(1.0))
+
+assert(bins(0)(1).category == 0.0)
+assert(bins(0)(1).lowSplit.categories.length == 1)
+assert(bins(0)(1).lowSplit.categories.contains(1.0))
+assert(bins(0)(1).highSplit.categories.length == 2)
+assert(bins(0)(1).highSplit.categories.contains(1.0))
+assert(bins(0)
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39155083 @mengxr I am not sure the merge of your PR on my repo went through. I might have closed the PR accidentally and I can't find a way to undo it. Could you please re-send your latest PR? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39154884 Merged build finished. All automated tests passed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39154885 All automated tests passed. Refer to this link for build results: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/13609/ --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11141936
--- Diff:
mllib/src/test/scala/org/apache/spark/mllib/tree/DecisionTreeSuite.scala ---
@@ -0,0 +1,431 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree
+
+import org.scalatest.BeforeAndAfterAll
+import org.scalatest.FunSuite
+
+import org.apache.spark.SparkContext
+import org.apache.spark.mllib.regression.LabeledPoint
+import org.apache.spark.mllib.tree.impurity.{Entropy, Gini, Variance}
+import org.apache.spark.mllib.tree.model.Filter
+import org.apache.spark.mllib.tree.configuration.Strategy
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.configuration.FeatureType._
+
+class DecisionTreeSuite extends FunSuite with BeforeAndAfterAll {
+
+ @transient private var sc: SparkContext = _
+
+ override def beforeAll() {
+sc = new SparkContext("local", "test")
+ }
+
+ override def afterAll() {
+sc.stop()
+System.clearProperty("spark.driver.port")
+ }
+
+ test("split and bin calculation"){
+val arr = DecisionTreeSuite.generateOrderedLabeledPointsWithLabel1()
+assert(arr.length == 1000)
+val rdd = sc.parallelize(arr)
+val strategy = new Strategy(Classification,Gini,3,100)
+val (splits, bins) = DecisionTree.findSplitsBins(rdd,strategy)
+assert(splits.length==2)
+assert(bins.length==2)
+assert(splits(0).length==99)
+assert(bins(0).length==100)
+ }
+
+ test("split and bin calculation for categorical variables"){
+val arr = DecisionTreeSuite.generateCategoricalDataPoints()
+assert(arr.length == 1000)
+val rdd = sc.parallelize(arr)
+val strategy = new
Strategy(Classification,Gini,3,100,categoricalFeaturesInfo = Map(0 -> 2,
+ 1-> 2))
+val (splits, bins) = DecisionTree.findSplitsBins(rdd,strategy)
+assert(splits.length==2)
+assert(bins.length==2)
+assert(splits(0).length==99)
+assert(bins(0).length==100)
+
+//Checking splits
+
+assert(splits(0)(0).feature == 0)
+assert(splits(0)(0).threshold == Double.MinValue)
+assert(splits(0)(0).featureType == Categorical)
+assert(splits(0)(0).categories.length == 1)
+assert(splits(0)(0).categories.contains(1.0))
+
+
+assert(splits(0)(1).feature == 0)
+assert(splits(0)(1).threshold == Double.MinValue)
+assert(splits(0)(1).featureType == Categorical)
+assert(splits(0)(1).categories.length == 2)
+assert(splits(0)(1).categories.contains(1.0))
+assert(splits(0)(1).categories.contains(0.0))
+
+assert(splits(0)(2) == null)
+
+assert(splits(1)(0).feature == 1)
+assert(splits(1)(0).threshold == Double.MinValue)
+assert(splits(1)(0).featureType == Categorical)
+assert(splits(1)(0).categories.length == 1)
+assert(splits(1)(0).categories.contains(0.0))
+
+
+assert(splits(1)(1).feature == 1)
+assert(splits(1)(1).threshold == Double.MinValue)
+assert(splits(1)(1).featureType == Categorical)
+assert(splits(1)(1).categories.length == 2)
+assert(splits(1)(1).categories.contains(1.0))
+assert(splits(1)(1).categories.contains(0.0))
+
+assert(splits(1)(2) == null)
+
+
+// Checks bins
+
+assert(bins(0)(0).category == 1.0)
+assert(bins(0)(0).lowSplit.categories.length == 0)
+assert(bins(0)(0).highSplit.categories.length == 1)
+assert(bins(0)(0).highSplit.categories.contains(1.0))
+
+assert(bins(0)(1).category == 0.0)
+assert(bins(0)(1).lowSplit.categories.length == 1)
+assert(bins(0)(1).lowSplit.categories.contains(1.0))
+assert(bins(0)(1).highSplit.categories.length == 2)
+assert(bins(0)(1).highSplit.categories.contains(1.0))
+assert(bins(0)(1).
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11141895
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/configuration/Strategy.scala
---
@@ -0,0 +1,47 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.configuration
+
+import org.apache.spark.mllib.tree.impurity.Impurity
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.configuration.QuantileStrategy._
+
+/**
+ * Stores all the configuration options for tree construction
+ * @param algo classification or regression
+ * @param impurity criterion used for information gain calculation
+ * @param maxDepth maximum depth of the tree
+ * @param maxBins maximum number of bins used for splitting features
+ * @param quantileCalculationStrategy algorithm for calculating quantiles
+ * @param categoricalFeaturesInfo A map storing information about the
categorical variables and the
+ *number of discrete values they take. For
example, an entry (n ->
+ *k) implies the feature n is categorical
with k categories 0,
+ *1, 2, ... , k-1. It's important to note
that features are
+ *zero-indexed.
+ */
+class Strategy (
+val algo: Algo,
+val impurity: Impurity,
+val maxDepth: Int,
+val maxBins: Int = 100,
+val quantileCalculationStrategy: QuantileStrategy = Sort,
+val categoricalFeaturesInfo: Map[Int,Int] =
Map[Int,Int]()) extends Serializable {
+
+ var numBins: Int = Int.MinValue
--- End diff --
Need docs on `numBins` and explain what it means if it is set manually as
in the test suite.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39153779 @manishamde I sent some minor code style updates to your repo. Please take a look and merge it into this PR. Thanks! --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39150614 Merged build triggered. Build is starting -or- tests failed to complete. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39150623 Merged build started. Build is starting -or- tests failed to complete. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-39150548 Jenkins, retest this please. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11103459
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
@mengxr The generic interface you noted is correct. However, I think
implementing this generic interface and the corresponding implementations is
not a minor code change. There are some assumptions in the bin aggregation code
that may need to be updated and it also requires adding partition-wise impurity
calculation and aggregation.
@mateiz As @mengxr noted, it's highly unlikely that a user will write their
own ```Impurity``` implementation. It's mostly an internal API and could be
addressed soon in a different PR.
I think we all agree (please correct me if I am wrong) the ```Impurity```
update belongs to a different PR. I can spend time on it immediately after this
PR is accepted.
Is this the correct method of marking a method as unstable using the
javadoc?
```ALPHA COMPONENT```
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11090794
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
@mateiz A user needs an `Impurity` instance to construct `Strategy`, but
very unlikely they need to call `calculate` directly or implement their own
`Impurity`. I'm okay if we mark the `calculate` method unstable in another PR
later.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mateiz commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11089359
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
BTW I'd also be okay updating this API in a later pull request before we
release 1.0. It's fair game to change new APIs in that time window.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mateiz commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11077636
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
I'm just catching up on this, but is the problem that there will be other
types of Impurity later that calculate different stats (not just variance)? In
that case, maybe we can have Impurity be parameterized (Impurity[T]) where T is
a type it accumulates over. However I'd also be okay with leaving this as is
initially and marking the API unstable if this is an internal API. The question
is how many users will call this directly.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11074467
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
@manishamde Sorry I misunderstood your proposal. I thought `Seq[Double]`
contains the raw labels, like
~~~
0 1 1 0 1 0 0 1
~~~
for classification and
~~~
1.0 2.0 -3.0 5.0
~~~
for regression. You meant that `Seq[Double]` is `Seq(c0, c1)` for
classification and `Seq(n, sum, sumSq)` for regression. I can see this would be
a minor code change but it makes the interface more confusing, IMHO. If my
understanding is correct, Impurity is applied to a sequence of labels. The code
will have better separation if we use the following:
~~~
labels.foreach(impurityAccumulator.accumulate)
impurityAccumulator += anotherImpurityAccumulator
val impurity = impurityAccumulator.get
~~~
I think this is also a minor code change and it gives a cleaner public
interface of `Impurity`. Maybe we can get some suggestions from others. @mateiz
?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11055502
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
@mengxr I am not clear what you meant by the ```accumulate``` and ```get```
methods.
There is no problem in encountering memory issues with
```calculate(Seq[Double])```. The length of the input sequence will be 2 for
classification implementations (Gini, Entropy) and 3 for regression
implementation (Variance). The ```calculate``` method is only used after the
bin aggregation and subsequent bin aggregate to split aggregate conversions.
It's just a minor code change to have a single method signature in the
```Impurity``` trait.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38887410 Merged build finished. Some tests failed or tests have not started running yet. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38887411 Some tests failed or tests have not started running yet. Refer to this link for build results: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/13536/ --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38885625 Merged build triggered. One or more automated tests failed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38885632 Merged build started. One or more automated tests failed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38885583 Merged build finished. One or more automated tests failed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38885584 One or more automated tests failed. Refer to this link for build results: https://amplab.cs.berkeley.edu/jenkins/job/Spark-prb/2/ --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user pwendell commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38885516 Jenkins, this is okay to test. Jenkins, test this please. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38885518 Merged build triggered. One or more automated tests failed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38885522 Merged build started. One or more automated tests failed. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11054196
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
@manishamde I prefer `accumulate(Double)` and `get(): Double`. But if a
single `calculate(Seq[Double])` won't run into memory issues, I'm okay with the
change. Sorry for my late response!
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38881921 Can one of the admins verify this patch? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11047729
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
@mengxr Are we in agreement here for the immediate fix for the PR? I think
we all agree on the final version but wanted to make sure we have consensus for
this PR before I implement your suggestion.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11001627
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
@mengxr Currently, the ```calculate``` method is used on bin aggregated
data after the ```aggregate``` operation. So this change won't require doing
partition-wise merge of impurities. It's just code restructuring without
modifying the implementation.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r11000162
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
@manishamde Do you need to merge two `Impurity` instances (from two
partitions) then?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10998536
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
@mengxr How about a simple temporary fix where we just have one
```calculate``` method in the ```Impurity``` trait that takes a list of Double
as a single parameter?
I prefer to write a generic implementation as discussed soon but it might
take me a few more days and will delay the PR.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10965763
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
@manishamde As you mentioned, we can do partition-wise accumulation and
then merge them without performance loss. It is okay to internally accumulate
`sum` and `sumSquare` in `Variance` and use them to compute variance in this
PR. But I think it is necessary to update the `Impurity` interface in this PR
to make it more general, because it is a public trait.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10959264
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
I agree with @mengxr that the design needs to be made more generic for
extensibility -- the signature collision is an issue we will encounter soon. As
@mengxr mentioned, the impurity class should specify three methods: a) a method
to calculate impurity (or an intermediate value) for a single label, b) the
```binSeqOp``` method and c) the ```binCombOp``` method.
We will encounter a loss in performance if we calculate the stats per
instance and then "merge" them and a loss in precision (as @mengxr pointed out)
if we calculate stats after accumulating large numbers. I wonder whether the
sweet spot is to calculating the stats (impurity) per partition without
encountering a significant loss in performance and precision.
The important question is that whether this issue "blocks" this PR or
belongs to a separate PR. I vote for the postponing it to a future PR. We will
soon encounter more loss functions during ensemble implementations (GBT for
example) so it might be good to handle it then.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10957131
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
The major loss of precision is from `sumSquares - sum*sum/count`, where a
large number subtracts another. Changing the interface to `(count, avg,
avgSquare)` would help avoid overflow but has nothing to do with precision. I
agree with @etrain that we can improve it in a future PR.
The question is whether we should make `calculate(c0, c1)` and
`calculate(count, sum, square)` a public method of `Impurity`. In either
classification or regression, `Impurity` works like an accumulator. What we
need is to describe how to process a label of type Double, how to merge two
`Impurity` instances, and how to get impurity from an instance, which is very
similar to `StatCounter`. It is strange to see Gini only implements the first
but not the second, while Variance only implements the second but not the
first. We probably need to reconsider the design here. For example, if we want
to handle three classes in the future, we will run into a signature collision
with `calculate(count, sum, squareSum)`.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user etrain commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10934747
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
I agree that overflow is an issue here (particularly in the case of
sumSquares), but also agree with Manish/Hirakendu that this algorithm maintains
its ability to generate a tree in a reasonable amount of time based on this
property that we compute statistics for splits and then merge them together.
I actually do think it makes sense to maintain "(count, average,
averageSumSq)" for each partition in a way that's overflow friendly and compute
the combination as count-weighted average of both as Hirakendu suggests. This
will complicate the code but should solve the overflow problem and keep things
pretty efficient.
That said - maybe this could be taken care of in a future PR as a bugfix,
rather than in this one?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user hirakendu commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10926671
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
I agree with Manish.
Numerical stability is the first thing that comes to mind on seeing a large
`avg = sum/count` calculation. In practice, I haven't seen any significant
difference in results or overflows with even billion sample datasets. Also,
features in machine learning are typically normalized and dynamic range is
small (bounded away from 0 and infinity).
We definitely cannot use the methods in DoubleRDDFunctions because we want
to calculate the variance of various splits, which requires the stats to be
"aggregable". But we may be able to modify the api's to use (count, avg,
avgSquares) as the stats and make the calculations more stable. E.g., to merge
(count, avg) of two parts `(c1, a1)`, `(c2, a2)`, we would have `(c1 + c2, a1 *
(c1/(c1+c2)) + a2 * (c2/(c1+c2)))`. Not too keen on that change, but let me
know if that works.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38529295 Merged build finished. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38529297 All automated tests passed. Refer to this link for build results: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/13419/ --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38526805 Merged build started. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38526804 Merged build triggered. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10916114
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
That's a nice observation. However, using the ```variance``` calculation
in ```StatCounter``` might be slow since the merge method recomputes ```n, mu,
m2``` for each value. Also, it won't fit well with the ```binCombOp```
operation in the ```aggregate``` function. One can probably optimize the ```def
merge(values: TraversableOnce[Double]): StatCounter``` method in the
```Variance``` class by doing a batch or mini-batch update for both speed and
precision but that's a separate discussion.
I see your concern with computing ```sumSquares``` for a large fraction of
the instances and I think it will be be best to leverage the ```def
merge(other: StatCounter): StatCounter``` method.
We can calculate StatCounter per partition using ```count, sum,
sumSquares``` and then merge during ```binCombOp``` for numerical stability. I
won't be hard to implement. Let me know what you think.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10871626
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Impurity.scala ---
@@ -0,0 +1,42 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree.impurity
+
+/**
+ * Trail for calculating information gain
+ */
+trait Impurity extends Serializable {
+
+ /**
+ * information calculation for binary classification
+ * @param c0 count of instances with label 0
+ * @param c1 count of instances with label 1
+ * @return information value
+ */
+ def calculate(c0 : Double, c1 : Double): Double
+
+ /**
+ * information calculation for regression
+ * @param count number of instances
+ * @param sum sum of labels
+ * @param sumSquares summation of squares of the labels
+ * @return information value
+ */
+ def calculate(count: Double, sum: Double, sumSquares: Double): Double
--- End diff --
It is easy to loss precision or run into overflow in the computation of
`sumSquares`. Is it only for computing the sample variance? If true, we can
simplify this interface to accept variance directly. We have a more stable
implementation of variance computation in `DoubleRDDFunctions`.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request: https://github.com/apache/spark/pull/79#discussion_r10871549 --- Diff: mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Variance.scala --- @@ -0,0 +1,42 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.mllib.tree.impurity + +import javax.naming.OperationNotSupportedException --- End diff -- Should use `java.lang.UnsupportedOperationException` and organize imports. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request: https://github.com/apache/spark/pull/79#discussion_r10871524 --- Diff: mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Gini.scala --- @@ -0,0 +1,48 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.mllib.tree.impurity + +import javax.naming.OperationNotSupportedException --- End diff -- Should use `java.lang.UnsupportedOperationException`. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request: https://github.com/apache/spark/pull/79#discussion_r10871491 --- Diff: mllib/src/main/scala/org/apache/spark/mllib/tree/impurity/Gini.scala --- @@ -0,0 +1,48 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.mllib.tree.impurity + +import javax.naming.OperationNotSupportedException + +/** + * Class for calculating the [[http://en.wikipedia.org/wiki/Gini_coefficient Gini + * coefficent]] during binary classification --- End diff -- This is the wiki page for `Gini coefficient`, which is different from `Gini impurity`. Should change to http://en.wikipedia.org/wiki/Decision_tree_learning#Gini_impurity --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10871385
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/DecisionTree.scala ---
@@ -0,0 +1,1183 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree
+
+import scala.util.control.Breaks._
+
+import org.apache.spark.SparkContext._
+import org.apache.spark.rdd.RDD
+import org.apache.spark.mllib.tree.model._
+import org.apache.spark.{SparkContext, Logging}
+import org.apache.spark.mllib.regression.LabeledPoint
+import org.apache.spark.mllib.tree.model.Split
+import org.apache.spark.mllib.tree.configuration.Strategy
+import org.apache.spark.mllib.tree.configuration.QuantileStrategy._
+import org.apache.spark.mllib.tree.configuration.FeatureType._
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.impurity.{Variance, Entropy, Gini,
Impurity}
+import java.util.Random
+import org.apache.spark.util.random.XORShiftRandom
+
+/**
+ * A class that implements a decision tree algorithm for classification
and regression. It
+ * supports both continuous and categorical features.
+ * @param strategy The configuration parameters for the tree algorithm
which specify the type
+ * of algorithm (classification, regression, etc.),
feature type (continuous,
+ * categorical),
+ * depth of the tree, quantile calculation strategy, etc.
+ */
+class DecisionTree private(val strategy: Strategy) extends Serializable
with Logging {
+
+ /**
+ * Method to train a decision tree model over an RDD
+ * @param input RDD of
[[org.apache.spark.mllib.regression.LabeledPoint]] used as training data
+ * for DecisionTree
+ * @return a DecisionTreeModel that can be used for prediction
+ */
+ def train(input: RDD[LabeledPoint]): DecisionTreeModel = {
+
+// Cache input RDD for speedup during multiple passes
+input.cache()
+logDebug("algo = " + strategy.algo)
+
+// Finding the splits and the corresponding bins (interval between the
splits) using a sample
+// of the input data.
+val (splits, bins) = DecisionTree.findSplitsBins(input, strategy)
+logDebug("numSplits = " + bins(0).length)
+
+// Noting numBins for the input data
+strategy.numBins = bins(0).length
+
+// The depth of the decision tree
+val maxDepth = strategy.maxDepth
+// The max number of nodes possible given the depth of the tree
+val maxNumNodes = scala.math.pow(2, maxDepth).toInt - 1
+// Initalizing an array to hold filters applied to points for each node
+val filters = new Array[List[Filter]](maxNumNodes)
+// The filter at the top node is an empty list
+filters(0) = List()
+// Initializing an array to hold parent impurity calculations for each
node
+val parentImpurities = new Array[Double](maxNumNodes)
+// Dummy value for top node (updated during first split calculation)
+val nodes = new Array[Node](maxNumNodes)
+
+// The main-idea here is to perform level-wise training of the
decision tree nodes thus
+// reducing the passes over the data from l to log2(l) where l is the
total number of nodes.
+// Each data sample is checked for validity w.r.t to each node at a
given level -- i.e.,
+// the sample is only used for the split calculation at the node if
the sampled would have
+// still survived the filters of the parent nodes.
+
+// TODO: Convert for loop to while loop
+breakable {
+ for (level <- 0 until maxDepth) {
+
+logDebug("#")
+logDebug("level = " + level)
+logDebug("#")
+
+// Find best split for all nodes at a level
+val splitsStatsForLevel = DecisionTree.
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38407632 One or more automated tests failed Refer to this link for build results: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/13378/ --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38407631 Merged build finished. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38407348 Merged build started. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38407347 Merged build triggered. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10871098
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/DecisionTree.scala ---
@@ -0,0 +1,1183 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree
+
+import scala.util.control.Breaks._
+
+import org.apache.spark.SparkContext._
+import org.apache.spark.rdd.RDD
+import org.apache.spark.mllib.tree.model._
+import org.apache.spark.{SparkContext, Logging}
+import org.apache.spark.mllib.regression.LabeledPoint
+import org.apache.spark.mllib.tree.model.Split
+import org.apache.spark.mllib.tree.configuration.Strategy
+import org.apache.spark.mllib.tree.configuration.QuantileStrategy._
+import org.apache.spark.mllib.tree.configuration.FeatureType._
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.impurity.{Variance, Entropy, Gini,
Impurity}
+import java.util.Random
+import org.apache.spark.util.random.XORShiftRandom
+
+/**
+ * A class that implements a decision tree algorithm for classification
and regression. It
+ * supports both continuous and categorical features.
+ * @param strategy The configuration parameters for the tree algorithm
which specify the type
+ * of algorithm (classification, regression, etc.),
feature type (continuous,
+ * categorical),
+ * depth of the tree, quantile calculation strategy, etc.
+ */
+class DecisionTree private(val strategy: Strategy) extends Serializable
with Logging {
+
+ /**
+ * Method to train a decision tree model over an RDD
+ * @param input RDD of
[[org.apache.spark.mllib.regression.LabeledPoint]] used as training data
+ * for DecisionTree
+ * @return a DecisionTreeModel that can be used for prediction
+ */
+ def train(input: RDD[LabeledPoint]): DecisionTreeModel = {
+
+// Cache input RDD for speedup during multiple passes
+input.cache()
+logDebug("algo = " + strategy.algo)
+
+// Finding the splits and the corresponding bins (interval between the
splits) using a sample
+// of the input data.
+val (splits, bins) = DecisionTree.findSplitsBins(input, strategy)
+logDebug("numSplits = " + bins(0).length)
+
+// Noting numBins for the input data
+strategy.numBins = bins(0).length
+
+// The depth of the decision tree
+val maxDepth = strategy.maxDepth
+// The max number of nodes possible given the depth of the tree
+val maxNumNodes = scala.math.pow(2, maxDepth).toInt - 1
+// Initalizing an array to hold filters applied to points for each node
+val filters = new Array[List[Filter]](maxNumNodes)
+// The filter at the top node is an empty list
+filters(0) = List()
+// Initializing an array to hold parent impurity calculations for each
node
+val parentImpurities = new Array[Double](maxNumNodes)
+// Dummy value for top node (updated during first split calculation)
+val nodes = new Array[Node](maxNumNodes)
+
+// The main-idea here is to perform level-wise training of the
decision tree nodes thus
+// reducing the passes over the data from l to log2(l) where l is the
total number of nodes.
+// Each data sample is checked for validity w.r.t to each node at a
given level -- i.e.,
+// the sample is only used for the split calculation at the node if
the sampled would have
+// still survived the filters of the parent nodes.
+
+// TODO: Convert for loop to while loop
+breakable {
+ for (level <- 0 until maxDepth) {
+
+logDebug("#")
+logDebug("level = " + level)
+logDebug("#")
+
+// Find best split for all nodes at a level
+val splitsStatsForLevel = DecisionT
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38377451 Merged build finished. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38377452 One or more automated tests failed Refer to this link for build results: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/13363/ --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38376590 Merged build started. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38376589 Merged build triggered. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38376567 Merged build finished. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38376569 One or more automated tests failed Refer to this link for build results: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/13361/ --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10866028
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/DecisionTree.scala ---
@@ -0,0 +1,1183 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree
+
+import scala.util.control.Breaks._
+
+import org.apache.spark.SparkContext._
+import org.apache.spark.rdd.RDD
+import org.apache.spark.mllib.tree.model._
+import org.apache.spark.{SparkContext, Logging}
+import org.apache.spark.mllib.regression.LabeledPoint
+import org.apache.spark.mllib.tree.model.Split
+import org.apache.spark.mllib.tree.configuration.Strategy
+import org.apache.spark.mllib.tree.configuration.QuantileStrategy._
+import org.apache.spark.mllib.tree.configuration.FeatureType._
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.impurity.{Variance, Entropy, Gini,
Impurity}
+import java.util.Random
+import org.apache.spark.util.random.XORShiftRandom
+
+/**
+ * A class that implements a decision tree algorithm for classification
and regression. It
+ * supports both continuous and categorical features.
+ * @param strategy The configuration parameters for the tree algorithm
which specify the type
+ * of algorithm (classification, regression, etc.),
feature type (continuous,
+ * categorical),
+ * depth of the tree, quantile calculation strategy, etc.
+ */
+class DecisionTree private(val strategy: Strategy) extends Serializable
with Logging {
+
+ /**
+ * Method to train a decision tree model over an RDD
+ * @param input RDD of
[[org.apache.spark.mllib.regression.LabeledPoint]] used as training data
+ * for DecisionTree
+ * @return a DecisionTreeModel that can be used for prediction
+ */
+ def train(input: RDD[LabeledPoint]): DecisionTreeModel = {
+
+// Cache input RDD for speedup during multiple passes
+input.cache()
+logDebug("algo = " + strategy.algo)
+
+// Finding the splits and the corresponding bins (interval between the
splits) using a sample
+// of the input data.
+val (splits, bins) = DecisionTree.findSplitsBins(input, strategy)
+logDebug("numSplits = " + bins(0).length)
+
+// Noting numBins for the input data
+strategy.numBins = bins(0).length
+
+// The depth of the decision tree
+val maxDepth = strategy.maxDepth
+// The max number of nodes possible given the depth of the tree
+val maxNumNodes = scala.math.pow(2, maxDepth).toInt - 1
+// Initalizing an array to hold filters applied to points for each node
+val filters = new Array[List[Filter]](maxNumNodes)
+// The filter at the top node is an empty list
+filters(0) = List()
+// Initializing an array to hold parent impurity calculations for each
node
+val parentImpurities = new Array[Double](maxNumNodes)
+// Dummy value for top node (updated during first split calculation)
+val nodes = new Array[Node](maxNumNodes)
+
+// The main-idea here is to perform level-wise training of the
decision tree nodes thus
+// reducing the passes over the data from l to log2(l) where l is the
total number of nodes.
+// Each data sample is checked for validity w.r.t to each node at a
given level -- i.e.,
+// the sample is only used for the split calculation at the node if
the sampled would have
+// still survived the filters of the parent nodes.
+
+// TODO: Convert for loop to while loop
+breakable {
+ for (level <- 0 until maxDepth) {
+
+logDebug("#")
+logDebug("level = " + level)
+logDebug("#")
+
+// Find best split for all nodes at a level
+val splitsStatsForLevel = DecisionTree.
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38375820 Merged build finished. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38375821 All automated tests passed. Refer to this link for build results: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/13358/ --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38375816 Merged build started. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user AmplabJenkins commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38375815 Merged build triggered. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10865951
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/DecisionTree.scala ---
@@ -0,0 +1,1183 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree
+
+import scala.util.control.Breaks._
+
+import org.apache.spark.SparkContext._
+import org.apache.spark.rdd.RDD
+import org.apache.spark.mllib.tree.model._
+import org.apache.spark.{SparkContext, Logging}
+import org.apache.spark.mllib.regression.LabeledPoint
+import org.apache.spark.mllib.tree.model.Split
+import org.apache.spark.mllib.tree.configuration.Strategy
+import org.apache.spark.mllib.tree.configuration.QuantileStrategy._
+import org.apache.spark.mllib.tree.configuration.FeatureType._
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.impurity.{Variance, Entropy, Gini,
Impurity}
+import java.util.Random
+import org.apache.spark.util.random.XORShiftRandom
+
+/**
+ * A class that implements a decision tree algorithm for classification
and regression. It
+ * supports both continuous and categorical features.
+ * @param strategy The configuration parameters for the tree algorithm
which specify the type
+ * of algorithm (classification, regression, etc.),
feature type (continuous,
+ * categorical),
+ * depth of the tree, quantile calculation strategy, etc.
+ */
+class DecisionTree private(val strategy: Strategy) extends Serializable
with Logging {
+
+ /**
+ * Method to train a decision tree model over an RDD
+ * @param input RDD of
[[org.apache.spark.mllib.regression.LabeledPoint]] used as training data
+ * for DecisionTree
+ * @return a DecisionTreeModel that can be used for prediction
+ */
+ def train(input: RDD[LabeledPoint]): DecisionTreeModel = {
+
+// Cache input RDD for speedup during multiple passes
+input.cache()
+logDebug("algo = " + strategy.algo)
+
+// Finding the splits and the corresponding bins (interval between the
splits) using a sample
+// of the input data.
+val (splits, bins) = DecisionTree.findSplitsBins(input, strategy)
+logDebug("numSplits = " + bins(0).length)
+
+// Noting numBins for the input data
+strategy.numBins = bins(0).length
+
+// The depth of the decision tree
+val maxDepth = strategy.maxDepth
+// The max number of nodes possible given the depth of the tree
+val maxNumNodes = scala.math.pow(2, maxDepth).toInt - 1
+// Initalizing an array to hold filters applied to points for each node
+val filters = new Array[List[Filter]](maxNumNodes)
+// The filter at the top node is an empty list
+filters(0) = List()
+// Initializing an array to hold parent impurity calculations for each
node
+val parentImpurities = new Array[Double](maxNumNodes)
+// Dummy value for top node (updated during first split calculation)
+val nodes = new Array[Node](maxNumNodes)
+
+// The main-idea here is to perform level-wise training of the
decision tree nodes thus
+// reducing the passes over the data from l to log2(l) where l is the
total number of nodes.
+// Each data sample is checked for validity w.r.t to each node at a
given level -- i.e.,
+// the sample is only used for the split calculation at the node if
the sampled would have
+// still survived the filters of the parent nodes.
+
+// TODO: Convert for loop to while loop
+breakable {
+ for (level <- 0 until maxDepth) {
+
+logDebug("#")
+logDebug("level = " + level)
+logDebug("#")
+
+// Find best split for all nodes at a level
+val splitsStatsForLevel = DecisionT
[GitHub] spark pull request: MLI-1 Decision Trees
Github user mengxr commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10865926
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/DecisionTree.scala ---
@@ -0,0 +1,1183 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree
+
+import scala.util.control.Breaks._
+
+import org.apache.spark.SparkContext._
+import org.apache.spark.rdd.RDD
+import org.apache.spark.mllib.tree.model._
+import org.apache.spark.{SparkContext, Logging}
+import org.apache.spark.mllib.regression.LabeledPoint
+import org.apache.spark.mllib.tree.model.Split
+import org.apache.spark.mllib.tree.configuration.Strategy
+import org.apache.spark.mllib.tree.configuration.QuantileStrategy._
+import org.apache.spark.mllib.tree.configuration.FeatureType._
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.impurity.{Variance, Entropy, Gini,
Impurity}
+import java.util.Random
+import org.apache.spark.util.random.XORShiftRandom
+
+/**
+ * A class that implements a decision tree algorithm for classification
and regression. It
+ * supports both continuous and categorical features.
+ * @param strategy The configuration parameters for the tree algorithm
which specify the type
+ * of algorithm (classification, regression, etc.),
feature type (continuous,
+ * categorical),
+ * depth of the tree, quantile calculation strategy, etc.
+ */
+class DecisionTree private(val strategy: Strategy) extends Serializable
with Logging {
+
+ /**
+ * Method to train a decision tree model over an RDD
+ * @param input RDD of
[[org.apache.spark.mllib.regression.LabeledPoint]] used as training data
+ * for DecisionTree
+ * @return a DecisionTreeModel that can be used for prediction
+ */
+ def train(input: RDD[LabeledPoint]): DecisionTreeModel = {
+
+// Cache input RDD for speedup during multiple passes
+input.cache()
+logDebug("algo = " + strategy.algo)
+
+// Finding the splits and the corresponding bins (interval between the
splits) using a sample
+// of the input data.
+val (splits, bins) = DecisionTree.findSplitsBins(input, strategy)
+logDebug("numSplits = " + bins(0).length)
+
+// Noting numBins for the input data
+strategy.numBins = bins(0).length
+
+// The depth of the decision tree
+val maxDepth = strategy.maxDepth
+// The max number of nodes possible given the depth of the tree
+val maxNumNodes = scala.math.pow(2, maxDepth).toInt - 1
+// Initalizing an array to hold filters applied to points for each node
+val filters = new Array[List[Filter]](maxNumNodes)
+// The filter at the top node is an empty list
+filters(0) = List()
+// Initializing an array to hold parent impurity calculations for each
node
+val parentImpurities = new Array[Double](maxNumNodes)
+// Dummy value for top node (updated during first split calculation)
+val nodes = new Array[Node](maxNumNodes)
+
+// The main-idea here is to perform level-wise training of the
decision tree nodes thus
+// reducing the passes over the data from l to log2(l) where l is the
total number of nodes.
+// Each data sample is checked for validity w.r.t to each node at a
given level -- i.e.,
+// the sample is only used for the split calculation at the node if
the sampled would have
+// still survived the filters of the parent nodes.
+
+// TODO: Convert for loop to while loop
+breakable {
+ for (level <- 0 until maxDepth) {
+
+logDebug("#")
+logDebug("level = " + level)
+logDebug("#")
+
+// Find best split for all nodes at a level
+val splitsStatsForLevel = DecisionTree.
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10865814
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/DecisionTree.scala ---
@@ -0,0 +1,1183 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree
+
+import scala.util.control.Breaks._
+
+import org.apache.spark.SparkContext._
+import org.apache.spark.rdd.RDD
+import org.apache.spark.mllib.tree.model._
+import org.apache.spark.{SparkContext, Logging}
+import org.apache.spark.mllib.regression.LabeledPoint
+import org.apache.spark.mllib.tree.model.Split
+import org.apache.spark.mllib.tree.configuration.Strategy
+import org.apache.spark.mllib.tree.configuration.QuantileStrategy._
+import org.apache.spark.mllib.tree.configuration.FeatureType._
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.impurity.{Variance, Entropy, Gini,
Impurity}
+import java.util.Random
+import org.apache.spark.util.random.XORShiftRandom
+
+/**
+ * A class that implements a decision tree algorithm for classification
and regression. It
+ * supports both continuous and categorical features.
+ * @param strategy The configuration parameters for the tree algorithm
which specify the type
+ * of algorithm (classification, regression, etc.),
feature type (continuous,
+ * categorical),
+ * depth of the tree, quantile calculation strategy, etc.
+ */
+class DecisionTree private(val strategy: Strategy) extends Serializable
with Logging {
+
+ /**
+ * Method to train a decision tree model over an RDD
+ * @param input RDD of
[[org.apache.spark.mllib.regression.LabeledPoint]] used as training data
+ * for DecisionTree
+ * @return a DecisionTreeModel that can be used for prediction
+ */
+ def train(input: RDD[LabeledPoint]): DecisionTreeModel = {
+
+// Cache input RDD for speedup during multiple passes
+input.cache()
+logDebug("algo = " + strategy.algo)
+
+// Finding the splits and the corresponding bins (interval between the
splits) using a sample
+// of the input data.
+val (splits, bins) = DecisionTree.findSplitsBins(input, strategy)
+logDebug("numSplits = " + bins(0).length)
+
+// Noting numBins for the input data
+strategy.numBins = bins(0).length
+
+// The depth of the decision tree
+val maxDepth = strategy.maxDepth
+// The max number of nodes possible given the depth of the tree
+val maxNumNodes = scala.math.pow(2, maxDepth).toInt - 1
+// Initalizing an array to hold filters applied to points for each node
+val filters = new Array[List[Filter]](maxNumNodes)
+// The filter at the top node is an empty list
+filters(0) = List()
+// Initializing an array to hold parent impurity calculations for each
node
+val parentImpurities = new Array[Double](maxNumNodes)
+// Dummy value for top node (updated during first split calculation)
+val nodes = new Array[Node](maxNumNodes)
+
+// The main-idea here is to perform level-wise training of the
decision tree nodes thus
+// reducing the passes over the data from l to log2(l) where l is the
total number of nodes.
+// Each data sample is checked for validity w.r.t to each node at a
given level -- i.e.,
+// the sample is only used for the split calculation at the node if
the sampled would have
+// still survived the filters of the parent nodes.
+
+// TODO: Convert for loop to while loop
+breakable {
+ for (level <- 0 until maxDepth) {
+
+logDebug("#")
+logDebug("level = " + level)
+logDebug("#")
+
+// Find best split for all nodes at a level
+val splitsStatsForLevel = DecisionT
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10865809
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/DecisionTree.scala ---
@@ -0,0 +1,1183 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree
+
+import scala.util.control.Breaks._
+
+import org.apache.spark.SparkContext._
+import org.apache.spark.rdd.RDD
+import org.apache.spark.mllib.tree.model._
+import org.apache.spark.{SparkContext, Logging}
+import org.apache.spark.mllib.regression.LabeledPoint
+import org.apache.spark.mllib.tree.model.Split
+import org.apache.spark.mllib.tree.configuration.Strategy
+import org.apache.spark.mllib.tree.configuration.QuantileStrategy._
+import org.apache.spark.mllib.tree.configuration.FeatureType._
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.impurity.{Variance, Entropy, Gini,
Impurity}
+import java.util.Random
+import org.apache.spark.util.random.XORShiftRandom
+
+/**
+ * A class that implements a decision tree algorithm for classification
and regression. It
+ * supports both continuous and categorical features.
+ * @param strategy The configuration parameters for the tree algorithm
which specify the type
+ * of algorithm (classification, regression, etc.),
feature type (continuous,
+ * categorical),
+ * depth of the tree, quantile calculation strategy, etc.
+ */
+class DecisionTree private(val strategy: Strategy) extends Serializable
with Logging {
+
+ /**
+ * Method to train a decision tree model over an RDD
+ * @param input RDD of
[[org.apache.spark.mllib.regression.LabeledPoint]] used as training data
+ * for DecisionTree
+ * @return a DecisionTreeModel that can be used for prediction
+ */
+ def train(input: RDD[LabeledPoint]): DecisionTreeModel = {
+
+// Cache input RDD for speedup during multiple passes
+input.cache()
+logDebug("algo = " + strategy.algo)
+
+// Finding the splits and the corresponding bins (interval between the
splits) using a sample
+// of the input data.
+val (splits, bins) = DecisionTree.findSplitsBins(input, strategy)
+logDebug("numSplits = " + bins(0).length)
+
+// Noting numBins for the input data
+strategy.numBins = bins(0).length
+
+// The depth of the decision tree
+val maxDepth = strategy.maxDepth
+// The max number of nodes possible given the depth of the tree
+val maxNumNodes = scala.math.pow(2, maxDepth).toInt - 1
+// Initalizing an array to hold filters applied to points for each node
+val filters = new Array[List[Filter]](maxNumNodes)
+// The filter at the top node is an empty list
+filters(0) = List()
+// Initializing an array to hold parent impurity calculations for each
node
+val parentImpurities = new Array[Double](maxNumNodes)
+// Dummy value for top node (updated during first split calculation)
+val nodes = new Array[Node](maxNumNodes)
+
+// The main-idea here is to perform level-wise training of the
decision tree nodes thus
+// reducing the passes over the data from l to log2(l) where l is the
total number of nodes.
+// Each data sample is checked for validity w.r.t to each node at a
given level -- i.e.,
+// the sample is only used for the split calculation at the node if
the sampled would have
+// still survived the filters of the parent nodes.
+
+// TODO: Convert for loop to while loop
+breakable {
+ for (level <- 0 until maxDepth) {
+
+logDebug("#")
+logDebug("level = " + level)
+logDebug("#")
+
+// Find best split for all nodes at a level
+val splitsStatsForLevel = DecisionT
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on a diff in the pull request:
https://github.com/apache/spark/pull/79#discussion_r10865810
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/tree/DecisionTree.scala ---
@@ -0,0 +1,1183 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.mllib.tree
+
+import scala.util.control.Breaks._
+
+import org.apache.spark.SparkContext._
+import org.apache.spark.rdd.RDD
+import org.apache.spark.mllib.tree.model._
+import org.apache.spark.{SparkContext, Logging}
+import org.apache.spark.mllib.regression.LabeledPoint
+import org.apache.spark.mllib.tree.model.Split
+import org.apache.spark.mllib.tree.configuration.Strategy
+import org.apache.spark.mllib.tree.configuration.QuantileStrategy._
+import org.apache.spark.mllib.tree.configuration.FeatureType._
+import org.apache.spark.mllib.tree.configuration.Algo._
+import org.apache.spark.mllib.tree.impurity.{Variance, Entropy, Gini,
Impurity}
+import java.util.Random
+import org.apache.spark.util.random.XORShiftRandom
+
+/**
+ * A class that implements a decision tree algorithm for classification
and regression. It
+ * supports both continuous and categorical features.
+ * @param strategy The configuration parameters for the tree algorithm
which specify the type
+ * of algorithm (classification, regression, etc.),
feature type (continuous,
+ * categorical),
+ * depth of the tree, quantile calculation strategy, etc.
+ */
+class DecisionTree private(val strategy: Strategy) extends Serializable
with Logging {
+
+ /**
+ * Method to train a decision tree model over an RDD
+ * @param input RDD of
[[org.apache.spark.mllib.regression.LabeledPoint]] used as training data
+ * for DecisionTree
+ * @return a DecisionTreeModel that can be used for prediction
+ */
+ def train(input: RDD[LabeledPoint]): DecisionTreeModel = {
+
+// Cache input RDD for speedup during multiple passes
+input.cache()
+logDebug("algo = " + strategy.algo)
+
+// Finding the splits and the corresponding bins (interval between the
splits) using a sample
+// of the input data.
+val (splits, bins) = DecisionTree.findSplitsBins(input, strategy)
+logDebug("numSplits = " + bins(0).length)
+
+// Noting numBins for the input data
+strategy.numBins = bins(0).length
+
+// The depth of the decision tree
+val maxDepth = strategy.maxDepth
+// The max number of nodes possible given the depth of the tree
+val maxNumNodes = scala.math.pow(2, maxDepth).toInt - 1
+// Initalizing an array to hold filters applied to points for each node
+val filters = new Array[List[Filter]](maxNumNodes)
+// The filter at the top node is an empty list
+filters(0) = List()
+// Initializing an array to hold parent impurity calculations for each
node
+val parentImpurities = new Array[Double](maxNumNodes)
+// Dummy value for top node (updated during first split calculation)
+val nodes = new Array[Node](maxNumNodes)
+
+// The main-idea here is to perform level-wise training of the
decision tree nodes thus
+// reducing the passes over the data from l to log2(l) where l is the
total number of nodes.
+// Each data sample is checked for validity w.r.t to each node at a
given level -- i.e.,
+// the sample is only used for the split calculation at the node if
the sampled would have
+// still survived the filters of the parent nodes.
+
+// TODO: Convert for loop to while loop
+breakable {
+ for (level <- 0 until maxDepth) {
+
+logDebug("#")
+logDebug("level = " + level)
+logDebug("#")
+
+// Find best split for all nodes at a level
+val splitsStatsForLevel = DecisionT
[GitHub] spark pull request: MLI-1 Decision Trees
Github user manishamde commented on the pull request: https://github.com/apache/spark/pull/79#issuecomment-38375199 @mengxr Thanks a lot! LGTM. Merged. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. ---