[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231796228
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
I think this issue shall not be in improvement category, it shall be
Critical
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231795771
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
currently our many customer scenarios are getting affected because of this
issue.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231795480
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
if we initialize the stats, then the updateTableStats flow will be executed
where we are also updating the table stats and invalidating the cache. and this
will ensure the consistency in insert flow.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231794961
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
Here one more point i want to mention is in hive by default
hive.stats.autogather is true, so the DML commands in hive tables will make
sure the stats always updated, so i think if we initialize the stats in insert
flow , the problems will be solved.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231791936
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
May be we should fixed it by: https://github.com/apache/spark/pull/20430
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231790964
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
This is the reason i asked why in some flow we are initializing the stats
and for some flow we are not because of which stats will be none and
refreshTable will be never called.
in my PR i told the flow where i saw in insert flow we are not nitializing
the stats because of which refreshTable () flow will never be executed.
But before insert command you execute a select statement where stats will
be intialized and the relation will be cached, now if you execute insert query
refreshTable() will be called as this time the stats will be nonempty
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231789742
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
might be the way i explained was not clear to all
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231789510
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
yep... so it wont execute this flow... this is what i want to say in my PR
https://github.com/apache/spark/pull/22758
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231789027
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
Good catch. new created table's stats is empty, right?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r231785137
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -183,13 +183,14 @@ case class InsertIntoHadoopFsRelationCommand(
refreshUpdatedPartitions(updatedPartitionPaths)
}
- // refresh cached files in FileIndex
- fileIndex.foreach(_.refresh())
- // refresh data cache if table is cached
- sparkSession.catalog.refreshByPath(outputPath.toString)
-
if (catalogTable.nonEmpty) {
+
sparkSession.sessionState.catalog.refreshTable(catalogTable.get.identifier)
--- End diff --
Already in CommandUtils.updateTableStats(sparkSession, catalogTable.get)
flow we are invalidating table relation cache, then do we need to call
invalidate here also? May i know the difference between these two statements
Thanks.
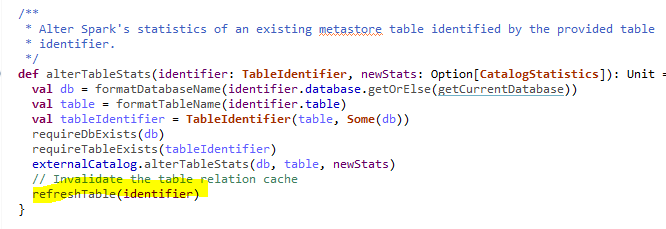
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r226812885
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -189,6 +189,7 @@ case class InsertIntoHadoopFsRelationCommand(
sparkSession.catalog.refreshByPath(outputPath.toString)
if (catalogTable.nonEmpty) {
+
sparkSession.catalog.refreshTable(catalogTable.get.identifier.quotedString)
--- End diff --
OK, Fixed.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r226280121
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -189,6 +189,7 @@ case class InsertIntoHadoopFsRelationCommand(
sparkSession.catalog.refreshByPath(outputPath.toString)
if (catalogTable.nonEmpty) {
+
sparkSession.catalog.refreshTable(catalogTable.get.identifier.quotedString)
--- End diff --
shall we follow `InsertIntoHiveTable` and use
`sparkSession.sessionState.catalog.refreshTable`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r226208576
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -189,6 +189,7 @@ case class InsertIntoHadoopFsRelationCommand(
sparkSession.catalog.refreshByPath(outputPath.toString)
if (catalogTable.nonEmpty) {
+
sparkSession.catalog.refreshTable(catalogTable.get.identifier.quotedString)
--- End diff --
shall we do
```
if (catalogTable.isDefined) {
sparkSession.catalog.refreshTable(catalogTable.get.identifier.quotedString)
} else {
// refresh cached files in FileIndex
fileIndex.foreach(_.refresh())
// refresh data cache if table is cached
sparkSession.catalog.refreshByPath(outputPath.toString)
}
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r226205949
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -189,6 +189,7 @@ case class InsertIntoHadoopFsRelationCommand(
sparkSession.catalog.refreshByPath(outputPath.toString)
if (catalogTable.nonEmpty) {
+
sparkSession.catalog.refreshTable(catalogTable.get.identifier.quotedString)
--- End diff --
It may be high now. it get `sizeInBytes` from:
https://github.com/apache/spark/blob/25c2776dd9ae3f9792048c78be2cbd958fd99841/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/HadoopFsRelation.scala#L88-L91
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r225418234
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -189,6 +189,7 @@ case class InsertIntoHadoopFsRelationCommand(
sparkSession.catalog.refreshByPath(outputPath.toString)
if (catalogTable.nonEmpty) {
+
sparkSession.catalog.refreshTable(catalogTable.get.identifier.quotedString)
--- End diff --
btw, I thought the cost of refreshing the table can be quite high?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22721#discussion_r225092331
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/HiveDDLSuite.scala
---
@@ -2370,4 +2370,26 @@ class HiveDDLSuite
))
}
}
+
+ test("Refresh table after insert into table") {
+withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") {
+ Seq("t1", "t2").foreach { tableName =>
+withTable(tableName) {
+ if (tableName.equals("t1")) {
+sql(s"CREATE TABLE $tableName (a INT) STORED AS parquet")
+ } else {
+sql(s"CREATE TABLE $tableName (a INT) USING parquet")
+ }
+
+ sql(s"INSERT INTO TABLE $tableName VALUES (1)")
+
+ val catalog = spark.sessionState.catalog
+ val qualifiedTableName =
QualifiedTableName(catalog.getCurrentDatabase, tableName)
+ val cachedRelation = catalog.getCachedTable(qualifiedTableName)
+ // cachedRelation should be null after refresh table.
+ assert(cachedRelation === null)
--- End diff --
cachedRelation should be null after refresh table:
https://github.com/apache/spark/blob/01c3dfab158d40653f8ce5d96f57220297545d5b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala#L791
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/22721 [SPARK-25403][SQL] Refreshes the table after inserting the table ## What changes were proposed in this pull request? Refreshes the table after inserting the table, Otherwise, we will encounter inconsistency, such as mentioned in `SPARK-25403`. In fact, the `InsertIntoHiveTable` refreshes the table after inserting the table: https://github.com/apache/spark/blob/f8b4d5aafd1923d9524415601469f8749b3d0811/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/InsertIntoHiveTable.scala#L107-L108 ## How was this patch tested? unit tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark SPARK-25403 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22721.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22721 commit 8a7f4af6b0e02c772f950c9a61e17eec5b988ef2 Author: Yuming Wang Date: 2018-10-15T05:09:58Z Refresh table after insert into table --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org