[GitHub] spark pull request #21648: [SPARK-24665][PySpark] Use SQLConf in PySpark to ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21648#discussion_r199316817 --- Diff: python/pyspark/sql/context.py --- @@ -93,6 +93,10 @@ def _ssql_ctx(self): """ return self._jsqlContext +def conf(self): --- End diff -- Thanks, done in 4fc0ae4. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r184276403
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2399,84 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * This tests the case where origin task success after speculative task
got FetchFailed
+ * before.
+ */
+ test("SPARK-23811: ShuffleMapStage failed by FetchFailed should ignore
following " +
+"successful tasks") {
+// Create 3 RDDs with shuffle dependencies on each other: rddA <---
rddB <--- rddC
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+val shuffleDepB = new ShuffleDependency(rddB, new HashPartitioner(2))
+
+val rddC = new MyRDD(sc, 2, List(shuffleDepB), tracker =
mapOutputTracker)
+
+submit(rddC, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task success
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Check currently missing partition.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+// The second result task self success soon.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
+// Missing partition number should not change, otherwise it will cause
child stage
+// never succeed.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+ }
+
+ test("SPARK-23811: check ResultStage failed by FetchFailed can ignore
following " +
+"successful tasks") {
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+submit(rddB, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task of rddB success
+assert(taskSets(1).tasks(0).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Make sure failedStage is not empty now
+assert(scheduler.failedStages.nonEmpty)
+// The second result task self success soon.
+assert(taskSets(1).tasks(1).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
--- End diff --
Yep, you're right. The success completely event in UT was treated as normal
success task. I fixed this by ignore this event at the beginning of
handleTaskCompletion.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r184260597
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2399,84 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * This tests the case where origin task success after speculative task
got FetchFailed
+ * before.
+ */
+ test("SPARK-23811: ShuffleMapStage failed by FetchFailed should ignore
following " +
+"successful tasks") {
+// Create 3 RDDs with shuffle dependencies on each other: rddA <---
rddB <--- rddC
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+val shuffleDepB = new ShuffleDependency(rddB, new HashPartitioner(2))
+
+val rddC = new MyRDD(sc, 2, List(shuffleDepB), tracker =
mapOutputTracker)
+
+submit(rddC, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task success
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Check currently missing partition.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+// The second result task self success soon.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
+// Missing partition number should not change, otherwise it will cause
child stage
+// never succeed.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+ }
+
+ test("SPARK-23811: check ResultStage failed by FetchFailed can ignore
following " +
+"successful tasks") {
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+submit(rddB, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task of rddB success
+assert(taskSets(1).tasks(0).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Make sure failedStage is not empty now
+assert(scheduler.failedStages.nonEmpty)
+// The second result task self success soon.
+assert(taskSets(1).tasks(1).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
--- End diff --
The success task will be ignored by
`OutputCommitCoordinator.taskCompleted`, in the taskCompleted logic,
stageStates.getOrElse will return because the current stage is in failed set.
The detailed log providing below:
```
18/04/26 10:50:24.524 ScalaTest-run-running-DAGSchedulerSuite INFO
DAGScheduler: Resubmitting ShuffleMapStage 0 (RDD at
DAGSchedulerSuite.scala:74) and ResultStage 1 () due to fetch failure
18/04/26 10:50:24.535 ScalaTest-run-running-DAGSchedulerSuite DEBUG
DAGSchedulerSuite$$anon$6: Increasing epoch to 2
18/04/26 10:50:24.538 ScalaTest-run-running-DAGSchedulerSuite INFO
DAGScheduler: Executor lost: exec-hostA (epoch 1)
18/04/26 10:50:24.540 ScalaTest-run-running-DAGSchedulerSuite INFO
DAGScheduler: Shuffle files lost for execut
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r184274946
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2399,84 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * This tests the case where origin task success after speculative task
got FetchFailed
+ * before.
+ */
+ test("SPARK-23811: ShuffleMapStage failed by FetchFailed should ignore
following " +
+"successful tasks") {
+// Create 3 RDDs with shuffle dependencies on each other: rddA <---
rddB <--- rddC
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+val shuffleDepB = new ShuffleDependency(rddB, new HashPartitioner(2))
+
+val rddC = new MyRDD(sc, 2, List(shuffleDepB), tracker =
mapOutputTracker)
+
+submit(rddC, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task success
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Check currently missing partition.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+// The second result task self success soon.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
+// Missing partition number should not change, otherwise it will cause
child stage
+// never succeed.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+ }
+
+ test("SPARK-23811: check ResultStage failed by FetchFailed can ignore
following " +
+"successful tasks") {
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+submit(rddB, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task of rddB success
+assert(taskSets(1).tasks(0).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Make sure failedStage is not empty now
+assert(scheduler.failedStages.nonEmpty)
+// The second result task self success soon.
+assert(taskSets(1).tasks(1).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
+assertDataStructuresEmpty()
--- End diff --
Ah, it's used for check job successful complete and all temp structure
empty.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20930: [SPARK-23811][Core] FetchFailed comes before Succ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20930#discussion_r184260210
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2399,84 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * This tests the case where origin task success after speculative task
got FetchFailed
+ * before.
+ */
+ test("SPARK-23811: ShuffleMapStage failed by FetchFailed should ignore
following " +
+"successful tasks") {
+// Create 3 RDDs with shuffle dependencies on each other: rddA <---
rddB <--- rddC
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+val shuffleDepB = new ShuffleDependency(rddB, new HashPartitioner(2))
+
+val rddC = new MyRDD(sc, 2, List(shuffleDepB), tracker =
mapOutputTracker)
+
+submit(rddC, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task success
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Check currently missing partition.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+// The second result task self success soon.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
+// Missing partition number should not change, otherwise it will cause
child stage
+// never succeed.
+
assert(mapOutputTracker.findMissingPartitions(shuffleDepB.shuffleId).get.size
=== 1)
+ }
+
+ test("SPARK-23811: check ResultStage failed by FetchFailed can ignore
following " +
+"successful tasks") {
+val rddA = new MyRDD(sc, 2, Nil)
+val shuffleDepA = new ShuffleDependency(rddA, new HashPartitioner(2))
+val shuffleIdA = shuffleDepA.shuffleId
+val rddB = new MyRDD(sc, 2, List(shuffleDepA), tracker =
mapOutputTracker)
+submit(rddB, Array(0, 1))
+
+// Complete both tasks in rddA.
+assert(taskSets(0).stageId === 0 && taskSets(0).stageAttemptId === 0)
+complete(taskSets(0), Seq(
+ (Success, makeMapStatus("hostA", 2)),
+ (Success, makeMapStatus("hostB", 2
+
+// The first task of rddB success
+assert(taskSets(1).tasks(0).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(0), Success, makeMapStatus("hostB", 2)))
+
+// The second task's speculative attempt fails first, but task self
still running.
+// This may caused by ExecutorLost.
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1),
+ FetchFailed(makeBlockManagerId("hostA"), shuffleIdA, 0, 0,
"ignored"),
+ null))
+// Make sure failedStage is not empty now
+assert(scheduler.failedStages.nonEmpty)
+// The second result task self success soon.
+assert(taskSets(1).tasks(1).isInstanceOf[ResultTask[_, _]])
+runEvent(makeCompletionEvent(
+ taskSets(1).tasks(1), Success, makeMapStatus("hostB", 2)))
+assertDataStructuresEmpty()
--- End diff --
I add this test for answering your previous question "Can you simulate what
happens to result task if FechFaileded comes before task success?". This test
can pass without my code changing in DAGScheduler.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21175: [SPARK-24107][CORE] ChunkedByteBuffer.writeFully ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/21175#discussion_r184882396 --- Diff: core/src/test/scala/org/apache/spark/io/ChunkedByteBufferSuite.scala --- @@ -20,12 +20,12 @@ package org.apache.spark.io import java.nio.ByteBuffer import com.google.common.io.ByteStreams --- End diff -- add an empty line behind 22 to separate spark and third-party group. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21175: [SPARK-24107][CORE] ChunkedByteBuffer.writeFully ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21175#discussion_r184882338
--- Diff:
core/src/test/scala/org/apache/spark/io/ChunkedByteBufferSuite.scala ---
@@ -20,12 +20,12 @@ package org.apache.spark.io
import java.nio.ByteBuffer
import com.google.common.io.ByteStreams
-
-import org.apache.spark.SparkFunSuite
+import org.apache.spark.{SparkFunSuite, SharedSparkContext}
--- End diff --
move SharedSparkContext before SparkFunSuite
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21194: [SPARK-24046][SS] Fix rate source when rowsPerSec...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21194#discussion_r185252544
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/RateStreamProvider.scala
---
@@ -101,25 +101,10 @@ object RateStreamProvider {
/** Calculate the end value we will emit at the time `seconds`. */
def valueAtSecond(seconds: Long, rowsPerSecond: Long, rampUpTimeSeconds:
Long): Long = {
-// E.g., rampUpTimeSeconds = 4, rowsPerSecond = 10
-// Then speedDeltaPerSecond = 2
-//
-// seconds = 0 1 2 3 4 5 6
-// speed = 0 2 4 6 8 10 10 (speedDeltaPerSecond * seconds)
-// end value = 0 2 6 12 20 30 40 (0 + speedDeltaPerSecond * seconds) *
(seconds + 1) / 2
-val speedDeltaPerSecond = rowsPerSecond / (rampUpTimeSeconds + 1)
-if (seconds <= rampUpTimeSeconds) {
- // Calculate "(0 + speedDeltaPerSecond * seconds) * (seconds + 1) /
2" in a special way to
- // avoid overflow
- if (seconds % 2 == 1) {
-(seconds + 1) / 2 * speedDeltaPerSecond * seconds
- } else {
-seconds / 2 * speedDeltaPerSecond * (seconds + 1)
- }
-} else {
- // rampUpPart is just a special case of the above formula:
rampUpTimeSeconds == seconds
- val rampUpPart = valueAtSecond(rampUpTimeSeconds, rowsPerSecond,
rampUpTimeSeconds)
- rampUpPart + (seconds - rampUpTimeSeconds) * rowsPerSecond
-}
+val delta = rowsPerSecond.toDouble / rampUpTimeSeconds
+val rampUpSeconds = if (seconds <= rampUpTimeSeconds) seconds else
rampUpTimeSeconds
+val afterRampUpSeconds = if (seconds > rampUpTimeSeconds ) seconds -
rampUpTimeSeconds else 0
+// Use classic distance formula based on accelaration: ut + ½at2
+Math.floor(rampUpSeconds * rampUpSeconds * delta / 2).toLong +
afterRampUpSeconds * rowsPerSecond
--- End diff --
nit: >100 characters
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21194: [SPARK-24046][SS] Fix rate source when rowsPerSec...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21194#discussion_r185252360
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/RateStreamProvider.scala
---
@@ -101,25 +101,10 @@ object RateStreamProvider {
/** Calculate the end value we will emit at the time `seconds`. */
def valueAtSecond(seconds: Long, rowsPerSecond: Long, rampUpTimeSeconds:
Long): Long = {
-// E.g., rampUpTimeSeconds = 4, rowsPerSecond = 10
-// Then speedDeltaPerSecond = 2
-//
-// seconds = 0 1 2 3 4 5 6
-// speed = 0 2 4 6 8 10 10 (speedDeltaPerSecond * seconds)
-// end value = 0 2 6 12 20 30 40 (0 + speedDeltaPerSecond * seconds) *
(seconds + 1) / 2
-val speedDeltaPerSecond = rowsPerSecond / (rampUpTimeSeconds + 1)
-if (seconds <= rampUpTimeSeconds) {
- // Calculate "(0 + speedDeltaPerSecond * seconds) * (seconds + 1) /
2" in a special way to
- // avoid overflow
- if (seconds % 2 == 1) {
-(seconds + 1) / 2 * speedDeltaPerSecond * seconds
- } else {
-seconds / 2 * speedDeltaPerSecond * (seconds + 1)
- }
-} else {
- // rampUpPart is just a special case of the above formula:
rampUpTimeSeconds == seconds
- val rampUpPart = valueAtSecond(rampUpTimeSeconds, rowsPerSecond,
rampUpTimeSeconds)
- rampUpPart + (seconds - rampUpTimeSeconds) * rowsPerSecond
-}
+val delta = rowsPerSecond.toDouble / rampUpTimeSeconds
+val rampUpSeconds = if (seconds <= rampUpTimeSeconds) seconds else
rampUpTimeSeconds
+val afterRampUpSeconds = if (seconds > rampUpTimeSeconds ) seconds -
rampUpTimeSeconds else 0
+// Use classic distance formula based on accelaration: ut + ½at2
--- End diff --
nit: acceleration
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21188: [SPARK-24046][SS] Fix rate source rowsPerSecond <= rampU...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21188 @maasg as comment in #21194, I just consider we should not change the behavior while `seconds > rampUpTimeSeconds`. Maybe it more important than smooth. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21194: [SPARK-24046][SS] Fix rate source when rowsPerSec...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21194#discussion_r185851172
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/streaming/sources/RateStreamProviderSuite.scala
---
@@ -173,55 +173,154 @@ class RateSourceSuite extends StreamTest {
assert(readData.map(_.getLong(1)).sorted == Range(0, 33))
}
- test("valueAtSecond") {
+ test("valueAtSecond without ramp-up") {
import RateStreamProvider._
+val rowsPerSec = Seq(1,10,50,100,1000,1)
+val secs = Seq(1, 10, 100, 1000, 1, 10)
+for {
+ sec <- secs
+ rps <- rowsPerSec
+} yield {
+ assert(valueAtSecond(seconds = sec, rowsPerSecond = rps,
rampUpTimeSeconds = 0) === sec * rps)
+}
+ }
-assert(valueAtSecond(seconds = 0, rowsPerSecond = 5, rampUpTimeSeconds
= 0) === 0)
-assert(valueAtSecond(seconds = 1, rowsPerSecond = 5, rampUpTimeSeconds
= 0) === 5)
+ test("valueAtSecond with ramp-up") {
+import RateStreamProvider._
+val rowsPerSec = Seq(1, 5, 10, 50, 100, 1000, 1)
+val rampUpSec = Seq(10, 100, 1000)
+
+// for any combination, value at zero = 0
+for {
+ rps <- rowsPerSec
+ rampUp <- rampUpSec
+} yield {
+ assert(valueAtSecond(seconds = 0, rowsPerSecond = rps,
rampUpTimeSeconds = rampUp) === 0)
+}
-assert(valueAtSecond(seconds = 0, rowsPerSecond = 5, rampUpTimeSeconds
= 2) === 0)
-assert(valueAtSecond(seconds = 1, rowsPerSecond = 5, rampUpTimeSeconds
= 2) === 1)
-assert(valueAtSecond(seconds = 2, rowsPerSecond = 5, rampUpTimeSeconds
= 2) === 3)
-assert(valueAtSecond(seconds = 3, rowsPerSecond = 5, rampUpTimeSeconds
= 2) === 8)
--- End diff --
I try your implement local and it changes the original behavior
```
valueAtSecond(seconds = 1, rowsPerSecond = 5, rampUpTimeSeconds = 2) = 1
valueAtSecond(seconds = 2, rowsPerSecond = 5, rampUpTimeSeconds = 2) = 5
valueAtSecond(seconds = 3, rowsPerSecond = 5, rampUpTimeSeconds = 2) = 10
valueAtSecond(seconds = 4, rowsPerSecond = 5, rampUpTimeSeconds = 2) = 15
```
I think the bug fix should not change the value on `seconds >
rampUpTimeSeconds`, just my opinion, you can ping other committers to review.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21188: [SPARK-24046][SS] Fix rate source rowsPerSecond <...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21188#discussion_r185852663
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/sources/RateStreamProvider.scala
---
@@ -107,14 +107,25 @@ object RateStreamProvider {
// seconds = 0 1 2 3 4 5 6
// speed = 0 2 4 6 8 10 10 (speedDeltaPerSecond * seconds)
// end value = 0 2 6 12 20 30 40 (0 + speedDeltaPerSecond * seconds) *
(seconds + 1) / 2
-val speedDeltaPerSecond = rowsPerSecond / (rampUpTimeSeconds + 1)
+val speedDeltaPerSecond = math.max(1, rowsPerSecond /
(rampUpTimeSeconds + 1))
--- End diff --
Keep at-least 1 per second and leave other seconds to 0 is ok IMOP.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20150: [SPARK-22956][SS] Bug fix for 2 streams union failover s...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20150 cc @zsxwing --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20150: [SPARK-22956][SS] Bug fix for 2 streams union failover s...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20150 cc @gatorsmile @cloud-fan --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20150: [SPARK-22956][SS] Bug fix for 2 streams union failover s...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20150 Thanks for your review! Shixiong --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17702: [SPARK-20408][SQL] Get the glob path in parallel ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/17702#discussion_r163156332
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala
---
@@ -668,4 +672,31 @@ object DataSource extends Logging {
}
globPath
}
+
+ /**
+ * Return all paths represented by the wildcard string.
+ * Follow [[InMemoryFileIndex]].bulkListLeafFile and reuse the conf.
+ */
+ private def getGlobbedPaths(
+ sparkSession: SparkSession,
+ fs: FileSystem,
+ hadoopConf: SerializableConfiguration,
+ qualified: Path): Seq[Path] = {
+val paths = SparkHadoopUtil.get.expandGlobPath(fs, qualified)
+if (paths.size <=
sparkSession.sessionState.conf.parallelPartitionDiscoveryThreshold) {
+ SparkHadoopUtil.get.globPathIfNecessary(fs, qualified)
+} else {
+ val parallelPartitionDiscoveryParallelism =
+
sparkSession.sessionState.conf.parallelPartitionDiscoveryParallelism
+ val numParallelism = Math.min(paths.size,
parallelPartitionDiscoveryParallelism)
+ val expanded = sparkSession.sparkContext
--- End diff --
Sorry for the late reply, finished in next commit.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20150: [SPARK-22956][SS] Bug fix for 2 streams union fai...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20150#discussion_r161426641
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/memory.scala
---
@@ -122,6 +122,11 @@ case class MemoryStream[A : Encoder](id: Int,
sqlContext: SQLContext)
batches.slice(sliceStart, sliceEnd)
}
+if (newBlocks.isEmpty) {
--- End diff --
DONE
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20150: [SPARK-22956][SS] Bug fix for 2 streams union fai...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20150#discussion_r161426622
--- Diff:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaSourceSuite.scala
---
@@ -318,6 +318,84 @@ class KafkaSourceSuite extends KafkaSourceTest {
)
}
+ test("union bug in failover") {
+def getSpecificDF(range: Range.Inclusive):
org.apache.spark.sql.Dataset[Int] = {
+ val topic = newTopic()
+ testUtils.createTopic(topic, partitions = 1)
+ testUtils.sendMessages(topic, range.map(_.toString).toArray, Some(0))
+
+ val reader = spark
+.readStream
+.format("kafka")
+.option("kafka.bootstrap.servers", testUtils.brokerAddress)
+.option("kafka.metadata.max.age.ms", "1")
+.option("maxOffsetsPerTrigger", 5)
+.option("subscribe", topic)
+.option("startingOffsets", "earliest")
+
+ reader.load()
+.selectExpr("CAST(value AS STRING)")
+.as[String]
+.map(k => k.toInt)
+}
+
+val df1 = getSpecificDF(0 to 9)
+val df2 = getSpecificDF(100 to 199)
+
+val kafka = df1.union(df2)
+
+val clock = new StreamManualClock
+
+val waitUntilBatchProcessed = AssertOnQuery { q =>
+ eventually(Timeout(streamingTimeout)) {
+if (!q.exception.isDefined) {
+ assert(clock.isStreamWaitingAt(clock.getTimeMillis()))
+}
+ }
+ if (q.exception.isDefined) {
+throw q.exception.get
+ }
+ true
+}
+
+testStream(kafka)(
+ StartStream(ProcessingTime(100), clock),
+ waitUntilBatchProcessed,
+ // 5 from smaller topic, 5 from bigger one
+ CheckAnswer(0, 1, 2, 3, 4, 100, 101, 102, 103, 104),
--- End diff --
Cool, this made the code more cleaner.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20150: [SPARK-22956][SS] Bug fix for 2 streams union fai...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20150#discussion_r161426632
--- Diff:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaSourceSuite.scala
---
@@ -318,6 +318,84 @@ class KafkaSourceSuite extends KafkaSourceTest {
)
}
+ test("union bug in failover") {
--- End diff --
DONE
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17702: [SPARK-20408][SQL] Get the glob path in parallel to redu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/17702 ping @vanzin --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20150: [SPARK-22956][SS] Bug fix for 2 streams union failover s...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20150 Hi Shixiong, thanks a lot for your reply. The full stack below can reproduce by running the added UT based on original code base. ``` Assert on query failed: : Query [id = 3421db21-652e-47af-9d54-2b74a222abed, runId = cd8d7c94-1286-44a5-b000-a8d870aef6fa] terminated with exception: Partition topic-0-0's offset was changed from 10 to 5, some data may have been missed. Some data may have been lost because they are not available in Kafka any more; either the data was aged out by Kafka or the topic may have been deleted before all the data in the topic was processed. If you don't want your streaming query to fail on such cases, set the source option "failOnDataLoss" to "false". org.apache.spark.sql.execution.streaming.StreamExecution.org$apache$spark$sql$execution$streaming$StreamExecution$$runStream(StreamExecution.scala:295) org.apache.spark.sql.execution.streaming.StreamExecution$$anon$1.run(StreamExecution.scala:189) Caused by: Partition topic-0-0's offset was changed from 10 to 5, some data may have been missed. Some data may have been lost because they are not available in Kafka any more; either the data was aged out by Kafka or the topic may have been deleted before all the data in the topic was processed. If you don't want your streaming query to fail on such cases, set the source option "failOnDataLoss" to "false". org.apache.spark.sql.kafka010.KafkaSource.org$apache$spark$sql$kafka010$KafkaSource$$reportDataLoss(KafkaSource.scala:332) org.apache.spark.sql.kafka010.KafkaSource$$anonfun$8.apply(KafkaSource.scala:291) org.apache.spark.sql.kafka010.KafkaSource$$anonfun$8.apply(KafkaSource.scala:289) scala.collection.TraversableLike$$anonfun$filterImpl$1.apply(TraversableLike.scala:248) scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59) scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48) scala.collection.TraversableLike$class.filterImpl(TraversableLike.scala:247) scala.collection.TraversableLike$class.filter(TraversableLike.scala:259) scala.collection.AbstractTraversable.filter(Traversable.scala:104) org.apache.spark.sql.kafka010.KafkaSource.getBatch(KafkaSource.scala:289) ``` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20244: [SPARK-23053][CORE] taskBinarySerialization and task par...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20244 reopen this... --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20244: [SPARK-23053][CORE] taskBinarySerialization and t...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20244#discussion_r161141499
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -96,6 +98,22 @@ class MyRDD(
override def toString: String = "DAGSchedulerSuiteRDD " + id
}
+/** Wrapped rdd partition. */
+class WrappedPartition(val partition: Partition) extends Partition {
+ def index: Int = partition.index
+}
+
+/** Wrapped rdd with WrappedPartition. */
+class WrappedRDD(parent: RDD[Int]) extends RDD[Int](parent) {
+ protected def getPartitions: Array[Partition] = {
+parent.partitions.map(p => new WrappedPartition(p))
+ }
+
+ def compute(split: Partition, context: TaskContext): Iterator[Int] = {
+parent.compute(split.asInstanceOf[WrappedPartition].partition, context)
--- End diff --
I think this line is the key point for `WrppedPartition` and `WrappedRDD`,
please give comments for explaining your intention.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20244: [SPARK-23053][CORE] taskBinarySerialization and t...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20244#discussion_r161144809
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2417,93 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * In this test, we simply simulate the scene in concurrent jobs using
the same
+ * rdd which is marked to do checkpoint:
+ * Job one has already finished the spark job, and start the process of
doCheckpoint;
+ * Job two is submitted, and submitMissingTasks is called.
+ * In submitMissingTasks, if taskSerialization is called before
doCheckpoint is done,
+ * while part calculates from stage.rdd.partitions is called after
doCheckpoint is done,
+ * we may get a ClassCastException when execute the task because of some
rdd will do
+ * Partition cast.
+ *
+ * With this test case, just want to indicate that we should do
taskSerialization and
+ * part calculate in submitMissingTasks with the same rdd checkpoint
status.
+ */
+ test("task part misType with checkpoint rdd in concurrent execution
scenes") {
+// set checkpointDir.
+val tempDir = Utils.createTempDir()
+val checkpointDir = File.createTempFile("temp", "", tempDir)
+checkpointDir.delete()
+sc.setCheckpointDir(checkpointDir.toString)
+
+val latch = new CountDownLatch(2)
+val semaphore1 = new Semaphore(0)
+val semaphore2 = new Semaphore(0)
+
+val rdd = new WrappedRDD(sc.makeRDD(1 to 100, 4))
+rdd.checkpoint()
+
+val checkpointRunnable = new Runnable {
+ override def run() = {
+// Simply simulate what RDD.doCheckpoint() do here.
+rdd.doCheckpointCalled = true
+val checkpointData = rdd.checkpointData.get
+RDDCheckpointData.synchronized {
+ if (checkpointData.cpState == CheckpointState.Initialized) {
+checkpointData.cpState =
CheckpointState.CheckpointingInProgress
+ }
+}
+
+val newRDD = checkpointData.doCheckpoint()
+
+// Release semaphore1 after job triggered in checkpoint finished.
+semaphore1.release()
+semaphore2.acquire()
+// Update our state and truncate the RDD lineage.
+RDDCheckpointData.synchronized {
+ checkpointData.cpRDD = Some(newRDD)
+ checkpointData.cpState = CheckpointState.Checkpointed
+ rdd.markCheckpointed()
+}
+semaphore1.release()
+
+latch.countDown()
+ }
+}
+
+val submitMissingTasksRunnable = new Runnable {
+ override def run() = {
+// Simply simulate the process of submitMissingTasks.
+val ser = SparkEnv.get.closureSerializer.newInstance()
+semaphore1.acquire()
+// Simulate task serialization while submitMissingTasks.
+// Task serialized with rdd checkpoint not finished.
+val cleanedFunc = sc.clean(Utils.getIteratorSize _)
+val func = (ctx: TaskContext, it: Iterator[Int]) => cleanedFunc(it)
+val taskBinaryBytes = JavaUtils.bufferToArray(
+ ser.serialize((rdd, func): AnyRef))
+semaphore2.release()
+semaphore1.acquire()
+// Part calculated with rdd checkpoint already finished.
+val (taskRdd, taskFunc) = ser.deserialize[(RDD[Int], (TaskContext,
Iterator[Int]) => Unit)](
+ ByteBuffer.wrap(taskBinaryBytes),
Thread.currentThread.getContextClassLoader)
+val part = rdd.partitions(0)
+intercept[ClassCastException] {
--- End diff --
I think this not a "test", this just a "reproduce" for the problem you want
to fix. We should prove your code added in `DAGScheduler.scala` can fix that
problem and with the original code base, a `ClassCastException` raised.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20244: [SPARK-23053][CORE] taskBinarySerialization and task par...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20244 ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20244: [SPARK-23053][CORE] taskBinarySerialization and t...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20244#discussion_r161141879
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2399,6 +2417,93 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
}
}
+ /**
+ * In this test, we simply simulate the scene in concurrent jobs using
the same
+ * rdd which is marked to do checkpoint:
+ * Job one has already finished the spark job, and start the process of
doCheckpoint;
+ * Job two is submitted, and submitMissingTasks is called.
+ * In submitMissingTasks, if taskSerialization is called before
doCheckpoint is done,
+ * while part calculates from stage.rdd.partitions is called after
doCheckpoint is done,
+ * we may get a ClassCastException when execute the task because of some
rdd will do
+ * Partition cast.
+ *
+ * With this test case, just want to indicate that we should do
taskSerialization and
+ * part calculate in submitMissingTasks with the same rdd checkpoint
status.
+ */
+ test("task part misType with checkpoint rdd in concurrent execution
scenes") {
--- End diff --
maybe "SPARK-23053: avoid CastException in concurrent execution with
checkpoint" better?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20244: [SPARK-23053][CORE] taskBinarySerialization and task par...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20244 test this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20244: [SPARK-23053][CORE] taskBinarySerialization and task par...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20244 @ivoson Tengfei, please post the full stack trace of the `ClassCastException`. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20675: [SPARK-23033][SS][Follow Up] Task level retry for contin...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20675 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20675: [SPARK-23033][SS][Follow Up] Task level retry for...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/20675 [SPARK-23033][SS][Follow Up] Task level retry for continuous processing ## What changes were proposed in this pull request? Here we want to reimplement the task level retry for continuous processing, changes include: 1. Add a new `EpochCoordinatorMessage` named `GetLastEpochAndOffset`, it is used for getting last epoch and offset of particular partition while task restarted. 2. Add function setOffset for `ContinuousDataReader`, it supported BaseReader can restart from given offset. ## How was this patch tested? Add new UT in `ContinuousSuite` and new `StreamAction` named `CheckAnswerRowsContainsOnlyOnce` for more accurate result checking. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-23033 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20675.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20675 commit 21f574e2a3ad3c8e68b92776d2a141d7fcb90502 Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-02-26T07:27:10Z [SPARK-23033][SS][Follow Up] Task level retry for continuous processing --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20675: [SPARK-23033][SS][Follow Up] Task level retry for contin...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20675 cc @tdas and @jose-torres #20225 gives a quickly fix for task level retry, this is just an attempt for a maybe better implementation. Please let me know if I do something wrong or have misunderstandings of Continuous Processing. Thanks :) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20150: [SPARK-22956][SS] Bug fix for 2 streams union fai...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/20150 [SPARK-22956][SS] Bug fix for 2 streams union failover scenario ## What changes were proposed in this pull request? This problem reported by @yanlin-Lynn @ivoson and @LiangchangZ. Thanks! When we union 2 streams from kafka or other sources, while one of them have no continues data coming and in the same time task restart, this will cause an `IllegalStateException`. This mainly cause because the code in [MicroBatchExecution](https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala#L190) , while one stream has no continues data, its comittedOffset same with availableOffset during `populateStartOffsets`, and `currentPartitionOffsets` not properly handled in KafkaSource. Also, maybe we should also consider this scenario in other Source. ## How was this patch tested? Add a UT in KafkaSourceSuite.scala You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-22956 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20150.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20150 commit aa3d7b73ed5221bdc2aee9dea1f6db45b4a626d7 Author: Yuanjian Li <xyliyuanjian@...> Date: 2018-01-04T11:52:23Z SPARK-22956: Bug fix for 2 streams union failover scenario --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20675: [SPARK-23033][SS][Follow Up] Task level retry for...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/20675#discussion_r170830121
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/streaming/continuous/ContinuousSuite.scala
---
@@ -219,18 +219,59 @@ class ContinuousSuite extends ContinuousSuiteBase {
spark.sparkContext.addSparkListener(listener)
try {
testStream(df, useV2Sink = true)(
-StartStream(Trigger.Continuous(100)),
+StartStream(longContinuousTrigger),
+AwaitEpoch(0),
Execute(waitForRateSourceTriggers(_, 2)),
+IncrementEpoch(),
Execute { _ =>
// Wait until a task is started, then kill its first attempt.
eventually(timeout(streamingTimeout)) {
assert(taskId != -1)
}
spark.sparkContext.killTaskAttempt(taskId)
},
-ExpectFailure[SparkException] { e =>
- e.getCause != null &&
e.getCause.getCause.isInstanceOf[ContinuousTaskRetryException]
-})
+Execute(waitForRateSourceTriggers(_, 4)),
+IncrementEpoch(),
+// Check the answer exactly, if there's duplicated result,
CheckAnserRowsContains
+// will also return true.
+CheckAnswerRowsContainsOnlyOnce(scala.Range(0, 20).map(Row(_))),
--- End diff --
Actually I firstly use `CheckAnswer(0 to 19: _*)` here, but I found the
test case failure probably because the CP maybe not stop between Range(0, 20)
every time. See the logs below:
```
== Plan ==
== Parsed Logical Plan ==
WriteToDataSourceV2
org.apache.spark.sql.execution.streaming.sources.MemoryStreamWriter@6435422d
+- Project [value#13L]
+- StreamingDataSourceV2Relation [timestamp#12, value#13L],
org.apache.spark.sql.execution.streaming.continuous.RateStreamContinuousReader@5c5d9c45
== Analyzed Logical Plan ==
WriteToDataSourceV2
org.apache.spark.sql.execution.streaming.sources.MemoryStreamWriter@6435422d
+- Project [value#13L]
+- StreamingDataSourceV2Relation [timestamp#12, value#13L],
org.apache.spark.sql.execution.streaming.continuous.RateStreamContinuousReader@5c5d9c45
== Optimized Logical Plan ==
WriteToDataSourceV2
org.apache.spark.sql.execution.streaming.sources.MemoryStreamWriter@6435422d
+- Project [value#13L]
+- StreamingDataSourceV2Relation [timestamp#12, value#13L],
org.apache.spark.sql.execution.streaming.continuous.RateStreamContinuousReader@5c5d9c45
== Physical Plan ==
WriteToDataSourceV2
org.apache.spark.sql.execution.streaming.sources.MemoryStreamWriter@6435422d
+- *(1) Project [value#13L]
+- *(1) DataSourceV2Scan [timestamp#12, value#13L],
org.apache.spark.sql.execution.streaming.continuous.RateStreamContinuousReader@5c5d9c45
ScalaTestFailureLocation: org.apache.spark.sql.streaming.StreamTest$class
at (StreamTest.scala:436)
org.scalatest.exceptions.TestFailedException:
== Results ==
!== Correct Answer - 20 == == Spark Answer - 25 ==
!struct struct
[0] [0]
[10][10]
[11][11]
[12][12]
[13][13]
[14][14]
[15][15]
[16][16]
[17][17]
[18][18]
[19][19]
[1] [1]
![2] [20]
![3] [21]
![4] [22]
![5] [23]
![6] [24]
![7] [2]
![8] [3]
![9] [4]
![5]
![6]
![7]
![8]
![9]
== Progress ==
StartStream(ContinuousTrigger(360),org.apache.spark.util.SystemClock@343e225a,Map(),null)
AssertOnQuery(, )
AssertOnQuery(, )
AssertOnQuery(, )
AssertOnQuery(, )
AssertOnQuery(, )
AssertOnQuery(, )
=> CheckAnswer:
[0],[1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12],[13],[14],[15],[16],[17],[18],[19]
StopStream
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20675: [SPARK-23033][SS][Follow Up] Task level retry for contin...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/20675 Great thanks for your detailed reply! > The semantics aren't quite right. Task-level retry can happen a fixed number of times for the lifetime of the task, which is the lifetime of the query - even if it runs for days after, the attempt number will never be reset. - I think the attempt number never be reset is not a problem, as long as the task start with right epoch and offset. Maybe I don't understand the meaning of the semantics, could you please give more explain? - As far as I'm concerned, while we have a larger parallel number, whole stage restart is a too heavy operation and will lead a data shaking. - Also want to leave a further thinking, after CP support shuffle and more complex scenario, task level retry need more work to do in order to ensure data is correct. But it maybe still a useful feature? I just want to leave this patch and initiate a discussion about this :) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21945: [SPARK-24989][Core] Add retrying support for OutO...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/21945 [SPARK-24989][Core] Add retrying support for OutOfDirectMemoryError ## What changes were proposed in this pull request? As the detailed description in [SPARK-24989](https://issues.apache.org/jira/browse/SPARK-24989), add retrying support in RetryingBlockFetcher while get io.netty.maxDirectMemory. The failed stages detail attached below: 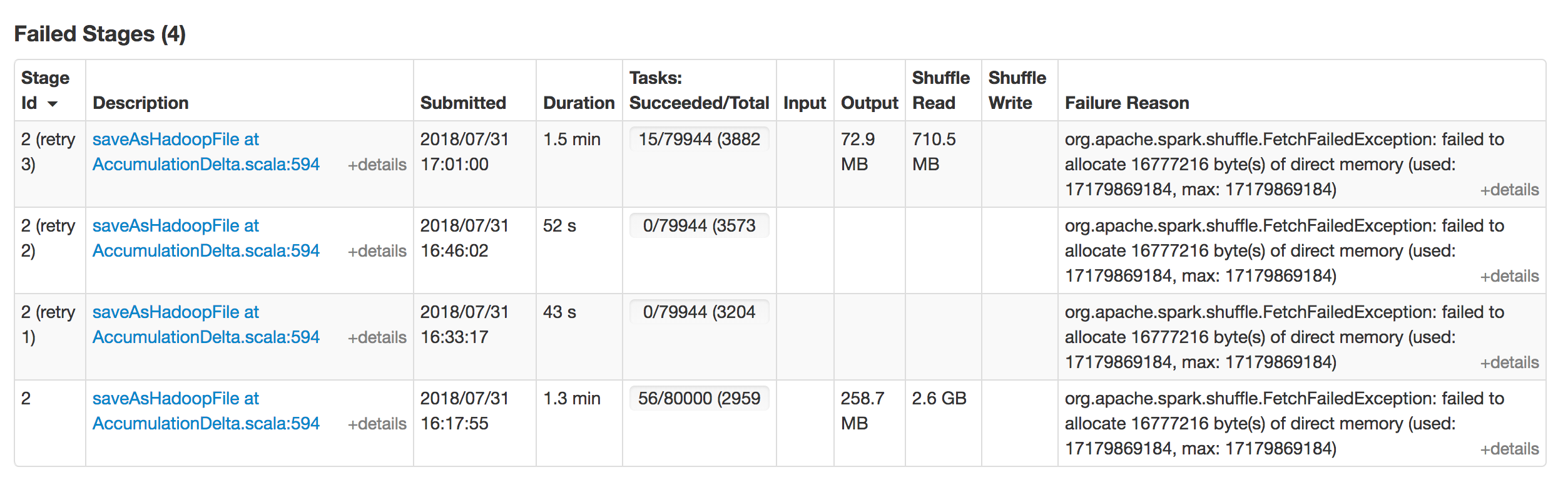 ## How was this patch tested? Add UT in RetryingBlockFetcherSuite.java and test in the job above mentioned. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-24989 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21945.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21945 commit bb6841b3a7a160e252fe35dab82f4ddeb0032591 Author: Yuanjian Li Date: 2018-08-01T16:15:09Z [SPARK-24989][Core] Add retry support for OutOfDirectMemoryError --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21945: [SPARK-24989][Core] Add retrying support for OutOfDirect...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21945 Close this, the param `spark.reducer.maxBlocksInFlightPerAddress` added after version 2.2 can solve my problem. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21945: [SPARK-24989][Core] Add retrying support for OutO...
Github user xuanyuanking closed the pull request at: https://github.com/apache/spark/pull/21945 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21893: [SPARK-24965][SQL] Support selecting from partiti...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r206188190
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/MultiFormatTableSuite.scala
---
@@ -0,0 +1,514 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import java.io.File
+import java.net.URI
+
+import org.scalatest.BeforeAndAfterEach
+import org.scalatest.Matchers
+
+import org.apache.spark.sql.{DataFrame, QueryTest, Row}
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.command.DDLUtils
+import org.apache.spark.sql.hive.test.TestHiveSingleton
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SQLTestUtils
+
+class MultiFormatTableSuite
+ extends QueryTest with SQLTestUtils with TestHiveSingleton with
BeforeAndAfterEach with Matchers {
+ import testImplicits._
+
+ val parser = new SparkSqlParser(new SQLConf())
+
+ override def afterEach(): Unit = {
+try {
+ // drop all databases, tables and functions after each test
+ spark.sessionState.catalog.reset()
+} finally {
+ super.afterEach()
+}
+ }
+
+ val partitionCol = "dt"
+ val partitionVal1 = "2018-01-26"
+ val partitionVal2 = "2018-01-27"
+
+ private case class PartitionDefinition(
+ column: String,
+ value: String,
+ location: URI,
+ format: Option[String] = None
+ ) {
+
+def toSpec: String = {
+ s"($column='$value')"
+}
+def toSpecAsMap: Map[String, String] = {
+ Map(column -> value)
+}
+ }
+
+ test("create hive table with multi format partitions") {
+val catalog = spark.sessionState.catalog
+withTempDir { baseDir =>
+
+ val partitionedTable = "ext_multiformat_partition_table"
+ withTable(partitionedTable) {
+assert(baseDir.listFiles.isEmpty)
+
+val partitions = createMultiformatPartitionDefinitions(baseDir)
+
+createTableWithPartitions(partitionedTable, baseDir, partitions)
+
+// Check table storage type is PARQUET
+val hiveResultTable =
+ catalog.getTableMetadata(TableIdentifier(partitionedTable,
Some("default")))
+assert(DDLUtils.isHiveTable(hiveResultTable))
+assert(hiveResultTable.tableType == CatalogTableType.EXTERNAL)
+assert(hiveResultTable.storage.inputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat")
+)
+assert(hiveResultTable.storage.outputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat")
+)
+assert(hiveResultTable.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check table has correct partititons
+assert(
+ catalog.listPartitions(TableIdentifier(partitionedTable,
+Some("default"))).map(_.spec).toSet ==
partitions.map(_.toSpecAsMap).toSet
+)
+
+// Check first table partition storage type is PARQUET
+val parquetPartition = catalog.getPartition(
+ TableIdentifier(partitionedTable, Some("default")),
+ partitions.head.toSpecAsMap
+)
+assert(
+ parquetPartition.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check second table partition storage type is AVRO
+
[GitHub] spark pull request #21893: [SPARK-24965][SQL] Support selecting from partiti...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r206182473
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/MultiFormatTableSuite.scala
---
@@ -0,0 +1,514 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import java.io.File
+import java.net.URI
+
+import org.scalatest.BeforeAndAfterEach
+import org.scalatest.Matchers
+
+import org.apache.spark.sql.{DataFrame, QueryTest, Row}
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.command.DDLUtils
+import org.apache.spark.sql.hive.test.TestHiveSingleton
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SQLTestUtils
+
+class MultiFormatTableSuite
+ extends QueryTest with SQLTestUtils with TestHiveSingleton with
BeforeAndAfterEach with Matchers {
+ import testImplicits._
+
+ val parser = new SparkSqlParser(new SQLConf())
+
+ override def afterEach(): Unit = {
+try {
+ // drop all databases, tables and functions after each test
+ spark.sessionState.catalog.reset()
+} finally {
+ super.afterEach()
+}
+ }
+
+ val partitionCol = "dt"
+ val partitionVal1 = "2018-01-26"
+ val partitionVal2 = "2018-01-27"
+
+ private case class PartitionDefinition(
+ column: String,
+ value: String,
+ location: URI,
+ format: Option[String] = None
+ ) {
+
+def toSpec: String = {
+ s"($column='$value')"
+}
+def toSpecAsMap: Map[String, String] = {
+ Map(column -> value)
+}
+ }
+
+ test("create hive table with multi format partitions") {
+val catalog = spark.sessionState.catalog
+withTempDir { baseDir =>
+
+ val partitionedTable = "ext_multiformat_partition_table"
+ withTable(partitionedTable) {
+assert(baseDir.listFiles.isEmpty)
+
+val partitions = createMultiformatPartitionDefinitions(baseDir)
+
+createTableWithPartitions(partitionedTable, baseDir, partitions)
+
+// Check table storage type is PARQUET
+val hiveResultTable =
+ catalog.getTableMetadata(TableIdentifier(partitionedTable,
Some("default")))
+assert(DDLUtils.isHiveTable(hiveResultTable))
+assert(hiveResultTable.tableType == CatalogTableType.EXTERNAL)
+assert(hiveResultTable.storage.inputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat")
+)
+assert(hiveResultTable.storage.outputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat")
+)
+assert(hiveResultTable.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check table has correct partititons
+assert(
+ catalog.listPartitions(TableIdentifier(partitionedTable,
+Some("default"))).map(_.spec).toSet ==
partitions.map(_.toSpecAsMap).toSet
+)
+
+// Check first table partition storage type is PARQUET
+val parquetPartition = catalog.getPartition(
+ TableIdentifier(partitionedTable, Some("default")),
+ partitions.head.toSpecAsMap
+)
+assert(
+ parquetPartition.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check second table partition storage type is AVRO
+
[GitHub] spark pull request #21893: [SPARK-24965][SQL] Support selecting from partiti...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r206188295
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/MultiFormatTableSuite.scala
---
@@ -0,0 +1,514 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import java.io.File
+import java.net.URI
+
+import org.scalatest.BeforeAndAfterEach
+import org.scalatest.Matchers
+
+import org.apache.spark.sql.{DataFrame, QueryTest, Row}
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.command.DDLUtils
+import org.apache.spark.sql.hive.test.TestHiveSingleton
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SQLTestUtils
+
+class MultiFormatTableSuite
+ extends QueryTest with SQLTestUtils with TestHiveSingleton with
BeforeAndAfterEach with Matchers {
+ import testImplicits._
+
+ val parser = new SparkSqlParser(new SQLConf())
+
+ override def afterEach(): Unit = {
+try {
+ // drop all databases, tables and functions after each test
+ spark.sessionState.catalog.reset()
+} finally {
+ super.afterEach()
+}
+ }
+
+ val partitionCol = "dt"
+ val partitionVal1 = "2018-01-26"
+ val partitionVal2 = "2018-01-27"
+
+ private case class PartitionDefinition(
+ column: String,
+ value: String,
+ location: URI,
+ format: Option[String] = None
+ ) {
+
+def toSpec: String = {
+ s"($column='$value')"
+}
+def toSpecAsMap: Map[String, String] = {
+ Map(column -> value)
+}
+ }
+
+ test("create hive table with multi format partitions") {
+val catalog = spark.sessionState.catalog
+withTempDir { baseDir =>
+
+ val partitionedTable = "ext_multiformat_partition_table"
+ withTable(partitionedTable) {
+assert(baseDir.listFiles.isEmpty)
+
+val partitions = createMultiformatPartitionDefinitions(baseDir)
+
+createTableWithPartitions(partitionedTable, baseDir, partitions)
+
+// Check table storage type is PARQUET
+val hiveResultTable =
+ catalog.getTableMetadata(TableIdentifier(partitionedTable,
Some("default")))
+assert(DDLUtils.isHiveTable(hiveResultTable))
+assert(hiveResultTable.tableType == CatalogTableType.EXTERNAL)
+assert(hiveResultTable.storage.inputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat")
+)
+assert(hiveResultTable.storage.outputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat")
+)
+assert(hiveResultTable.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check table has correct partititons
+assert(
+ catalog.listPartitions(TableIdentifier(partitionedTable,
+Some("default"))).map(_.spec).toSet ==
partitions.map(_.toSpecAsMap).toSet
+)
+
+// Check first table partition storage type is PARQUET
+val parquetPartition = catalog.getPartition(
+ TableIdentifier(partitionedTable, Some("default")),
+ partitions.head.toSpecAsMap
+)
+assert(
+ parquetPartition.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check second table partition storage type is AVRO
+
[GitHub] spark pull request #21893: [SPARK-24965][SQL] Support selecting from partiti...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r206190334
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/MultiFormatTableSuite.scala
---
@@ -0,0 +1,514 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import java.io.File
+import java.net.URI
+
+import org.scalatest.BeforeAndAfterEach
+import org.scalatest.Matchers
+
+import org.apache.spark.sql.{DataFrame, QueryTest, Row}
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.command.DDLUtils
+import org.apache.spark.sql.hive.test.TestHiveSingleton
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SQLTestUtils
+
+class MultiFormatTableSuite
+ extends QueryTest with SQLTestUtils with TestHiveSingleton with
BeforeAndAfterEach with Matchers {
+ import testImplicits._
+
+ val parser = new SparkSqlParser(new SQLConf())
+
+ override def afterEach(): Unit = {
+try {
+ // drop all databases, tables and functions after each test
+ spark.sessionState.catalog.reset()
+} finally {
+ super.afterEach()
+}
+ }
+
+ val partitionCol = "dt"
+ val partitionVal1 = "2018-01-26"
+ val partitionVal2 = "2018-01-27"
+
+ private case class PartitionDefinition(
+ column: String,
+ value: String,
+ location: URI,
+ format: Option[String] = None
+ ) {
--- End diff --
Do not have to start a new line.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21893: [SPARK-24965][SQL] Support selecting from partiti...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r206184350
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/MultiFormatTableSuite.scala
---
@@ -0,0 +1,514 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import java.io.File
+import java.net.URI
+
+import org.scalatest.BeforeAndAfterEach
+import org.scalatest.Matchers
+
+import org.apache.spark.sql.{DataFrame, QueryTest, Row}
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.command.DDLUtils
+import org.apache.spark.sql.hive.test.TestHiveSingleton
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SQLTestUtils
+
+class MultiFormatTableSuite
+ extends QueryTest with SQLTestUtils with TestHiveSingleton with
BeforeAndAfterEach with Matchers {
+ import testImplicits._
+
+ val parser = new SparkSqlParser(new SQLConf())
+
+ override def afterEach(): Unit = {
+try {
+ // drop all databases, tables and functions after each test
+ spark.sessionState.catalog.reset()
+} finally {
+ super.afterEach()
+}
+ }
+
+ val partitionCol = "dt"
+ val partitionVal1 = "2018-01-26"
+ val partitionVal2 = "2018-01-27"
+
+ private case class PartitionDefinition(
+ column: String,
+ value: String,
+ location: URI,
+ format: Option[String] = None
+ ) {
+
+def toSpec: String = {
+ s"($column='$value')"
+}
+def toSpecAsMap: Map[String, String] = {
+ Map(column -> value)
+}
+ }
+
+ test("create hive table with multi format partitions") {
+val catalog = spark.sessionState.catalog
+withTempDir { baseDir =>
+
+ val partitionedTable = "ext_multiformat_partition_table"
+ withTable(partitionedTable) {
+assert(baseDir.listFiles.isEmpty)
+
+val partitions = createMultiformatPartitionDefinitions(baseDir)
+
+createTableWithPartitions(partitionedTable, baseDir, partitions)
+
+// Check table storage type is PARQUET
+val hiveResultTable =
+ catalog.getTableMetadata(TableIdentifier(partitionedTable,
Some("default")))
+assert(DDLUtils.isHiveTable(hiveResultTable))
+assert(hiveResultTable.tableType == CatalogTableType.EXTERNAL)
+assert(hiveResultTable.storage.inputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat")
+)
+assert(hiveResultTable.storage.outputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat")
+)
+assert(hiveResultTable.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check table has correct partititons
+assert(
+ catalog.listPartitions(TableIdentifier(partitionedTable,
+Some("default"))).map(_.spec).toSet ==
partitions.map(_.toSpecAsMap).toSet
+)
+
+// Check first table partition storage type is PARQUET
+val parquetPartition = catalog.getPartition(
+ TableIdentifier(partitionedTable, Some("default")),
+ partitions.head.toSpecAsMap
+)
+assert(
+ parquetPartition.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check second table partition storage type is AVRO
+
[GitHub] spark pull request #21893: [SPARK-24965][SQL] Support selecting from partiti...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r206188012
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/MultiFormatTableSuite.scala
---
@@ -0,0 +1,514 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import java.io.File
+import java.net.URI
+
+import org.scalatest.BeforeAndAfterEach
+import org.scalatest.Matchers
+
+import org.apache.spark.sql.{DataFrame, QueryTest, Row}
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.command.DDLUtils
+import org.apache.spark.sql.hive.test.TestHiveSingleton
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SQLTestUtils
+
+class MultiFormatTableSuite
+ extends QueryTest with SQLTestUtils with TestHiveSingleton with
BeforeAndAfterEach with Matchers {
+ import testImplicits._
+
+ val parser = new SparkSqlParser(new SQLConf())
+
+ override def afterEach(): Unit = {
+try {
+ // drop all databases, tables and functions after each test
+ spark.sessionState.catalog.reset()
+} finally {
+ super.afterEach()
+}
+ }
+
+ val partitionCol = "dt"
+ val partitionVal1 = "2018-01-26"
+ val partitionVal2 = "2018-01-27"
+
+ private case class PartitionDefinition(
+ column: String,
+ value: String,
+ location: URI,
+ format: Option[String] = None
+ ) {
+
+def toSpec: String = {
+ s"($column='$value')"
+}
+def toSpecAsMap: Map[String, String] = {
+ Map(column -> value)
+}
+ }
+
+ test("create hive table with multi format partitions") {
+val catalog = spark.sessionState.catalog
+withTempDir { baseDir =>
+
+ val partitionedTable = "ext_multiformat_partition_table"
+ withTable(partitionedTable) {
+assert(baseDir.listFiles.isEmpty)
+
+val partitions = createMultiformatPartitionDefinitions(baseDir)
+
+createTableWithPartitions(partitionedTable, baseDir, partitions)
+
+// Check table storage type is PARQUET
+val hiveResultTable =
+ catalog.getTableMetadata(TableIdentifier(partitionedTable,
Some("default")))
+assert(DDLUtils.isHiveTable(hiveResultTable))
+assert(hiveResultTable.tableType == CatalogTableType.EXTERNAL)
+assert(hiveResultTable.storage.inputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat")
+)
+assert(hiveResultTable.storage.outputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat")
+)
+assert(hiveResultTable.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check table has correct partititons
+assert(
+ catalog.listPartitions(TableIdentifier(partitionedTable,
+Some("default"))).map(_.spec).toSet ==
partitions.map(_.toSpecAsMap).toSet
+)
+
+// Check first table partition storage type is PARQUET
+val parquetPartition = catalog.getPartition(
+ TableIdentifier(partitionedTable, Some("default")),
+ partitions.head.toSpecAsMap
+)
+assert(
+ parquetPartition.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check second table partition storage type is AVRO
+
[GitHub] spark pull request #21893: [SPARK-24965][SQL] Support selecting from partiti...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r206184183
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/MultiFormatTableSuite.scala
---
@@ -0,0 +1,514 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import java.io.File
+import java.net.URI
+
+import org.scalatest.BeforeAndAfterEach
+import org.scalatest.Matchers
+
+import org.apache.spark.sql.{DataFrame, QueryTest, Row}
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.command.DDLUtils
+import org.apache.spark.sql.hive.test.TestHiveSingleton
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SQLTestUtils
+
+class MultiFormatTableSuite
+ extends QueryTest with SQLTestUtils with TestHiveSingleton with
BeforeAndAfterEach with Matchers {
+ import testImplicits._
+
+ val parser = new SparkSqlParser(new SQLConf())
+
+ override def afterEach(): Unit = {
+try {
+ // drop all databases, tables and functions after each test
+ spark.sessionState.catalog.reset()
+} finally {
+ super.afterEach()
+}
+ }
+
+ val partitionCol = "dt"
+ val partitionVal1 = "2018-01-26"
+ val partitionVal2 = "2018-01-27"
+
+ private case class PartitionDefinition(
+ column: String,
+ value: String,
+ location: URI,
+ format: Option[String] = None
+ ) {
+
+def toSpec: String = {
+ s"($column='$value')"
+}
+def toSpecAsMap: Map[String, String] = {
+ Map(column -> value)
+}
+ }
+
+ test("create hive table with multi format partitions") {
+val catalog = spark.sessionState.catalog
+withTempDir { baseDir =>
+
+ val partitionedTable = "ext_multiformat_partition_table"
+ withTable(partitionedTable) {
+assert(baseDir.listFiles.isEmpty)
+
+val partitions = createMultiformatPartitionDefinitions(baseDir)
+
+createTableWithPartitions(partitionedTable, baseDir, partitions)
+
+// Check table storage type is PARQUET
+val hiveResultTable =
+ catalog.getTableMetadata(TableIdentifier(partitionedTable,
Some("default")))
+assert(DDLUtils.isHiveTable(hiveResultTable))
+assert(hiveResultTable.tableType == CatalogTableType.EXTERNAL)
+assert(hiveResultTable.storage.inputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat")
+)
+assert(hiveResultTable.storage.outputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat")
+)
+assert(hiveResultTable.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check table has correct partititons
+assert(
+ catalog.listPartitions(TableIdentifier(partitionedTable,
+Some("default"))).map(_.spec).toSet ==
partitions.map(_.toSpecAsMap).toSet
+)
+
+// Check first table partition storage type is PARQUET
+val parquetPartition = catalog.getPartition(
+ TableIdentifier(partitionedTable, Some("default")),
+ partitions.head.toSpecAsMap
+)
+assert(
+ parquetPartition.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check second table partition storage type is AVRO
+
[GitHub] spark pull request #21893: [SPARK-24965][SQL] Support selecting from partiti...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r206188650
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/MultiFormatTableSuite.scala
---
@@ -0,0 +1,514 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import java.io.File
+import java.net.URI
+
+import org.scalatest.BeforeAndAfterEach
+import org.scalatest.Matchers
+
+import org.apache.spark.sql.{DataFrame, QueryTest, Row}
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.command.DDLUtils
+import org.apache.spark.sql.hive.test.TestHiveSingleton
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SQLTestUtils
+
+class MultiFormatTableSuite
+ extends QueryTest with SQLTestUtils with TestHiveSingleton with
BeforeAndAfterEach with Matchers {
+ import testImplicits._
+
+ val parser = new SparkSqlParser(new SQLConf())
+
+ override def afterEach(): Unit = {
+try {
+ // drop all databases, tables and functions after each test
+ spark.sessionState.catalog.reset()
+} finally {
+ super.afterEach()
+}
+ }
+
+ val partitionCol = "dt"
+ val partitionVal1 = "2018-01-26"
+ val partitionVal2 = "2018-01-27"
+
+ private case class PartitionDefinition(
+ column: String,
+ value: String,
+ location: URI,
+ format: Option[String] = None
+ ) {
+
+def toSpec: String = {
+ s"($column='$value')"
+}
+def toSpecAsMap: Map[String, String] = {
+ Map(column -> value)
+}
+ }
+
+ test("create hive table with multi format partitions") {
+val catalog = spark.sessionState.catalog
+withTempDir { baseDir =>
+
+ val partitionedTable = "ext_multiformat_partition_table"
+ withTable(partitionedTable) {
+assert(baseDir.listFiles.isEmpty)
+
+val partitions = createMultiformatPartitionDefinitions(baseDir)
+
+createTableWithPartitions(partitionedTable, baseDir, partitions)
+
+// Check table storage type is PARQUET
+val hiveResultTable =
+ catalog.getTableMetadata(TableIdentifier(partitionedTable,
Some("default")))
+assert(DDLUtils.isHiveTable(hiveResultTable))
+assert(hiveResultTable.tableType == CatalogTableType.EXTERNAL)
+assert(hiveResultTable.storage.inputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat")
+)
+assert(hiveResultTable.storage.outputFormat
+
.contains("org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat")
+)
+assert(hiveResultTable.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check table has correct partititons
+assert(
+ catalog.listPartitions(TableIdentifier(partitionedTable,
+Some("default"))).map(_.spec).toSet ==
partitions.map(_.toSpecAsMap).toSet
+)
+
+// Check first table partition storage type is PARQUET
+val parquetPartition = catalog.getPartition(
+ TableIdentifier(partitionedTable, Some("default")),
+ partitions.head.toSpecAsMap
+)
+assert(
+ parquetPartition.storage.serde
+
.contains("org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe")
+)
+
+// Check second table partition storage type is AVRO
+
[GitHub] spark pull request #21893: [SPARK-24965][SQL] Support selecting from partiti...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r206178526
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/ParserUtils.scala
---
@@ -96,6 +96,9 @@ object ParserUtils {
}
}
+ def extraMethod(s: String): String = {
--- End diff --
what's this used for?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21881: [SPARK-24930][SQL] Improve exception information ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21881#discussion_r206203835
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/tables.scala ---
@@ -337,7 +337,11 @@ case class LoadDataCommand(
new File(file.getAbsolutePath).exists()
}
if (!exists) {
- throw new AnalysisException(s"LOAD DATA input path does not
exist: $path")
+ // If user have no permission to access the given input path,
`File.exists()` return false
+ // , `LOAD DATA input path does not exist` can confuse users.
+ throw new AnalysisException(s"LOAD DATA input path does not
exist: `$path` or current " +
--- End diff --
Nit: no need to print the $path twice.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21893: Support selecting from partitioned tabels with pa...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r205945617
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkSqlParser.scala ---
@@ -857,6 +857,32 @@ class SparkSqlAstBuilder(conf: SQLConf) extends
AstBuilder(conf) {
Option(ctx.partitionSpec).map(visitNonOptionalPartitionSpec))
}
+ /**
+ * Create an [[AlterTableFormatPropertiesCommand]] command.
+ *
+ * For example:
+ * {{{
+ * ALTER TABLE table [PARTITION spec] SET FILEFORMAT format;
+ * }}}
+ */
+ override def visitSetTableFormat(ctx: SetTableFormatContext):
LogicalPlan = withOrigin(ctx) {
+val format = (ctx.fileFormat) match {
+ // Expected format: INPUTFORMAT input_format OUTPUTFORMAT
output_format
+ case (c: TableFileFormatContext) =>
+visitTableFileFormat(c)
+ // Expected format: SEQUENCEFILE | TEXTFILE | RCFILE | ORC | PARQUET
| AVRO
+ case (c: GenericFileFormatContext) =>
+visitGenericFileFormat(c)
+ case _ =>
+throw new ParseException("Expected STORED AS ", ctx)
+}
+AlterTableFormatCommand(
+ visitTableIdentifier(ctx.tableIdentifier),
+ format,
+ // TODO a partition spec is allowed to have optional values. This is
currently violated.
+ Option(ctx.partitionSpec).map(visitNonOptionalPartitionSpec))
--- End diff --
Confused by this todo, as currently implementation, while partition spec is
empty, we change table's catalog?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21893: Support selecting from partitioned tabels with pa...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r205945564
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/MultiFormatTableSuite.scala
---
@@ -0,0 +1,512 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.hive.execution
+
+import java.io.File
+import java.net.URI
+
+import org.scalatest.BeforeAndAfterEach
+import org.scalatest.Matchers
+
+import org.apache.spark.sql.{DataFrame, QueryTest, Row}
+import org.apache.spark.sql.catalyst.TableIdentifier
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.execution._
+import org.apache.spark.sql.execution.command.DDLUtils
+import org.apache.spark.sql.hive.test.TestHiveSingleton
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SQLTestUtils
+
+class MultiFormatTableSuite
+ extends QueryTest with SQLTestUtils with TestHiveSingleton with
BeforeAndAfterEach with Matchers {
+ import testImplicits._
+
+ val parser = new SparkSqlParser(new SQLConf())
+
+ override def afterEach(): Unit = {
+try {
+ // drop all databases, tables and functions after each test
+ spark.sessionState.catalog.reset()
+} finally {
+ super.afterEach()
+}
+ }
+
+ val partitionCol = "dt"
+ val partitionVal1 = "2018-01-26"
+ val partitionVal2 = "2018-01-27"
+ private case class PartitionDefinition(
+ column: String,
--- End diff --
ditto.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21893: Support selecting from partitioned tabels with pa...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r205945559
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/ddl.scala ---
@@ -415,6 +415,51 @@ case class AlterTableSerDePropertiesCommand(
}
+/**
+ * A command that sets the format of a table/view/partition .
+ *
+ * The syntax of this command is:
+ * {{{
+ * ALTER TABLE table [PARTITION spec] SET FILEFORMAT format;
+ * }}}
+ */
+case class AlterTableFormatCommand(
+tableName: TableIdentifier,
--- End diff --
indent nit: 4 space with func param.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21893: Support selecting from partitioned tabels with pa...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21893#discussion_r205945523
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkSqlParser.scala ---
@@ -857,6 +857,32 @@ class SparkSqlAstBuilder(conf: SQLConf) extends
AstBuilder(conf) {
Option(ctx.partitionSpec).map(visitNonOptionalPartitionSpec))
}
+ /**
+ * Create an [[AlterTableFormatPropertiesCommand]] command.
+ *
+ * For example:
+ * {{{
+ * ALTER TABLE table [PARTITION spec] SET FILEFORMAT format;
+ * }}}
+ */
+ override def visitSetTableFormat(ctx: SetTableFormatContext):
LogicalPlan = withOrigin(ctx) {
+val format = (ctx.fileFormat) match {
+ // Expected format: INPUTFORMAT input_format OUTPUTFORMAT
output_format
+ case (c: TableFileFormatContext) =>
+visitTableFileFormat(c)
+ // Expected format: SEQUENCEFILE | TEXTFILE | RCFILE | ORC | PARQUET
| AVRO
+ case (c: GenericFileFormatContext) =>
+visitGenericFileFormat(c)
+ case _ =>
+throw new ParseException("Expected STORED AS ", ctx)
--- End diff --
I think we need a more detailed ParseException message here.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21985: [SPARK-24884][SQL] add regexp_extract_all support
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21985#discussion_r207712639
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
---
@@ -446,3 +448,88 @@ case class RegExpExtract(subject: Expression, regexp:
Expression, idx: Expressio
})
}
}
+
+/**
+ * Extract all specific(idx) groups identified by a Java regex.
+ *
+ * NOTE: this expression is not THREAD-SAFE, as it has some internal
mutable status.
+ */
+@ExpressionDescription(
+ usage = "_FUNC_(str, regexp[, idx]) - Extracts all groups that matches
`regexp`.",
+ examples = """
+Examples:
+ > SELECT _FUNC_('100-200,300-400', '(\\d+)-(\\d+)', 1);
+ [100, 300]
+ """)
+case class RegExpExtractAll(subject: Expression, regexp: Expression, idx:
Expression)
--- End diff --
Add an abstract class to reduce duplicated code between `RegExpExtractAll`
and `RegExpExtract`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21985: [SPARK-24884][SQL] add regexp_extract_all support
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21985#discussion_r207712323
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/regexpExpressions.scala
---
@@ -446,3 +448,88 @@ case class RegExpExtract(subject: Expression, regexp:
Expression, idx: Expressio
})
}
}
+
+/**
+ * Extract all specific(idx) groups identified by a Java regex.
+ *
+ * NOTE: this expression is not THREAD-SAFE, as it has some internal
mutable status.
+ */
+@ExpressionDescription(
+ usage = "_FUNC_(str, regexp[, idx]) - Extracts all groups that matches
`regexp`.",
+ examples = """
+Examples:
+ > SELECT _FUNC_('100-200,300-400', '(\\d+)-(\\d+)', 1);
+ [100, 300]
+ """)
+case class RegExpExtractAll(subject: Expression, regexp: Expression, idx:
Expression)
+ extends TernaryExpression with ImplicitCastInputTypes {
+ def this(s: Expression, r: Expression) = this(s, r, Literal(1))
+
+ // last regex in string, we will update the pattern iff regexp value
changed.
+ @transient private var lastRegex: UTF8String = _
+ // last regex pattern, we cache it for performance concern
+ @transient private var pattern: Pattern = _
+
+ override def nullSafeEval(s: Any, p: Any, r: Any): Any = {
+if (!p.equals(lastRegex)) {
+ // regex value changed
+ lastRegex = p.asInstanceOf[UTF8String].clone()
+ pattern = Pattern.compile(lastRegex.toString)
+}
+val m = pattern.matcher(s.toString)
+var groupArrayBuffer = new ArrayBuffer[UTF8String]();
+
+while (m.find) {
+ val mr: MatchResult = m.toMatchResult
+ val group = mr.group(r.asInstanceOf[Int])
+ if (group == null) { // Pattern matched, but not optional group
+groupArrayBuffer += UTF8String.EMPTY_UTF8
+ } else {
+groupArrayBuffer += UTF8String.fromString(group)
+ }
+}
+
+new GenericArrayData(groupArrayBuffer.toArray.asInstanceOf[Array[Any]])
+ }
+
+ override def dataType: DataType = ArrayType(StringType)
+ override def inputTypes: Seq[AbstractDataType] = Seq(StringType,
StringType, IntegerType)
+ override def children: Seq[Expression] = subject :: regexp :: idx :: Nil
+ override def prettyName: String = "regexp_extract_all"
+
+ override protected def doGenCode(ctx: CodegenContext, ev: ExprCode):
ExprCode = {
+val classNamePattern = classOf[Pattern].getCanonicalName
+val matcher = ctx.freshName("matcher")
+val matchResult = ctx.freshName("matchResult")
+val groupArray = ctx.freshName("groupArray")
+
+val termLastRegex = ctx.addMutableState("UTF8String", "lastRegex")
+val termPattern = ctx.addMutableState(classNamePattern, "pattern")
+
+val arrayClass = classOf[GenericArrayData].getName
+
+nullSafeCodeGen(ctx, ev, (subject, regexp, idx) => {
+ s"""
+ if (!$regexp.equals($termLastRegex)) {
+// regex value changed
+$termLastRegex = $regexp.clone();
+$termPattern =
$classNamePattern.compile($termLastRegex.toString());
+ }
+ java.util.regex.Matcher $matcher =
+$termPattern.matcher($subject.toString());
+ java.util.ArrayList $groupArray =
+new java.util.ArrayList();
+
+ while ($matcher.find()) {
+java.util.regex.MatchResult $matchResult =
$matcher.toMatchResult();
+if ($matchResult.group($idx) == null) {
+ $groupArray.add(UTF8String.EMPTY_UTF8);
+} else {
+ $groupArray.add(UTF8String.fromString($matchResult.group($idx)));
+}
+ }
+ ${ev.value} = new $arrayClass($groupArray.toArray(new
UTF8String[$groupArray.size()]));
--- End diff --
Do we need consider about setting ev.isNull?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21945: [SPARK-24989][Core] Add retrying support for OutOfDirect...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21945 retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21618: [SPARK-20408][SQL] Get the glob path in parallel ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21618#discussion_r205478496
--- Diff: core/src/main/java/org/apache/hadoop/fs/SparkGlobber.java ---
@@ -0,0 +1,293 @@
+/**
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.hadoop.fs;
+
+import java.io.FileNotFoundException;
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.List;
+
+import org.apache.commons.lang3.StringUtils;
+import org.apache.commons.logging.LogFactory;
+import org.apache.commons.logging.Log;
+
+/**
+ * This is based on hadoop-common-2.7.2
+ * {@link org.apache.hadoop.fs.Globber}.
+ * This class exposes globWithThreshold which can be used glob path in
parallel.
+ */
+public class SparkGlobber {
+ public static final Log LOG =
LogFactory.getLog(SparkGlobber.class.getName());
+
+ private final FileSystem fs;
+ private final FileContext fc;
+ private final Path pathPattern;
+
+ public SparkGlobber(FileSystem fs, Path pathPattern) {
+this.fs = fs;
+this.fc = null;
+this.pathPattern = pathPattern;
+ }
+
+ public SparkGlobber(FileContext fc, Path pathPattern) {
+this.fs = null;
+this.fc = fc;
+this.pathPattern = pathPattern;
+ }
+
+ private FileStatus getFileStatus(Path path) throws IOException {
+try {
+ if (fs != null) {
+return fs.getFileStatus(path);
+ } else {
+return fc.getFileStatus(path);
+ }
+} catch (FileNotFoundException e) {
+ return null;
+}
+ }
+
+ private FileStatus[] listStatus(Path path) throws IOException {
+try {
+ if (fs != null) {
+return fs.listStatus(path);
+ } else {
+return fc.util().listStatus(path);
+ }
+} catch (FileNotFoundException e) {
+ return new FileStatus[0];
+}
+ }
+
+ private Path fixRelativePart(Path path) {
+if (fs != null) {
+ return fs.fixRelativePart(path);
+} else {
+ return fc.fixRelativePart(path);
+}
+ }
+
+ /**
+ * Convert a path component that contains backslash ecape sequences to a
+ * literal string. This is necessary when you want to explicitly refer
to a
+ * path that contains globber metacharacters.
+ */
+ private static String unescapePathComponent(String name) {
+return name.replaceAll("(.)", "$1");
+ }
+
+ /**
+ * Translate an absolute path into a list of path components.
+ * We merge double slashes into a single slash here.
+ * POSIX root path, i.e. '/', does not get an entry in the list.
+ */
+ private static List getPathComponents(String path)
+ throws IOException {
+ArrayList ret = new ArrayList();
+for (String component : path.split(Path.SEPARATOR)) {
+ if (!component.isEmpty()) {
+ret.add(component);
+ }
+}
+return ret;
+ }
+
+ private String schemeFromPath(Path path) throws IOException {
+String scheme = path.toUri().getScheme();
+if (scheme == null) {
+ if (fs != null) {
+scheme = fs.getUri().getScheme();
+ } else {
+scheme =
fc.getFSofPath(fc.fixRelativePart(path)).getUri().getScheme();
+ }
+}
+return scheme;
+ }
+
+ private String authorityFromPath(Path path) throws IOException {
+String authority = path.toUri().getAuthority();
+if (authority == null) {
+ if (fs != null) {
+authority = fs.getUri().getAuthority();
+ } else {
+authority =
fc.getFSofPath(fc.fixRelativePart(path)).getUri().getAuthority();
+ }
+}
+return authority ;
+ }
+
+ public FileStatus[] globWithThreshold(int threshold) throws IOException {
+
[GitHub] spark pull request #22057: [SPARK-25077][SQL] Delete unused variable in Wind...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/22057 [SPARK-25077][SQL] Delete unused variable in WindowExec ## What changes were proposed in this pull request? Just delete the unused variable `inputFields` in WindowExec, avoid making others confused while reading the code. ## How was this patch tested? Existing UT. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-25077 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22057.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22057 commit 90513587ed1d48437818e90f58612c344009f563 Author: liyuanjian Date: 2018-08-09T15:57:29Z [SPARK-25077][SQL] Delete unused variable in WindowExec --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22093: [SPARK-25100][CORE] Fix no registering TaskCommitMessage...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22093 `Should I delete current UT from FileSuit?` I think current UT in `FileSuite` is unnecessarily, you can leave it and wait for other reviewer's opinion. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22117: [SPARK-23654][BUILD] remove jets3t as a dependency of sp...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22117 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22122: [SPARK-24665][PySpark][FollowUp] Use SQLConf in P...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/22122 [SPARK-24665][PySpark][FollowUp] Use SQLConf in PySpark to manage all sql configs ## What changes were proposed in this pull request? Follow up for SPARK-24665, find some others hard code during code review. ## How was this patch tested? Existing UT. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-24665-follow Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22122.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22122 commit 8a32e60a7af4f574176366eb057b219cb4511bb6 Author: Yuanjian Li Date: 2018-07-02T07:04:40Z Use SQLConf in session.py and catalog.py --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22122: [SPARK-24665][PySpark][FollowUp] Use SQLConf in PySpark ...
Github user xuanyuanking commented on the issue:
https://github.com/apache/spark/pull/22122
```
Are they all instances to fix?
```
@HyukjinKwon Yep, I grep all `conf.get("spark.sql.xxx")` and make sure for
this. The remaining of hard code config is StaticSQLConf
`spark.sql.catalogImplementation` in session.py, it can't manage by SQLConf.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22122: [SPARK-24665][PySpark][FollowUp] Use SQLConf in PySpark ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22122 Thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22105: [SPARK-25115] [Core] Eliminate extra memory copy ...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/22105#discussion_r210842394 --- Diff: common/network-common/src/main/java/org/apache/spark/network/protocol/MessageWithHeader.java --- @@ -140,8 +140,24 @@ private int copyByteBuf(ByteBuf buf, WritableByteChannel target) throws IOExcept // SPARK-24578: cap the sub-region's size of returned nio buffer to improve the performance // for the case that the passed-in buffer has too many components. int length = Math.min(buf.readableBytes(), NIO_BUFFER_LIMIT); --- End diff -- ``` IIRC socket buffers are 32k by default on Linux, so it seems unlikely you'd be able to write 256k in one call (ignoring what IOUtil does internally). But maybe in practice it works ok. ``` After reading the context in #12083 and this discussion, I want to provide a possibility about 256k in one call can work in practice. As in our scenario, user will change `/proc/sys/net/core/wmem_default` based on their online behavior, generally we'll set this value larger than `wmem_default`.  So maybe 256k of NIO_BUFFER_LIMIT is ok here? We just need add more annotation to remind what params related with this value. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21986: [SPARK-23937][SQL] Add map_filter SQL function
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21986#discussion_r207924294
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/higherOrderFunctions.scala
---
@@ -205,29 +230,82 @@ case class ArrayTransform(
(elementVar, indexVar)
}
- override def eval(input: InternalRow): Any = {
-val arr = this.input.eval(input).asInstanceOf[ArrayData]
-if (arr == null) {
- null
-} else {
- val f = functionForEval
- val result = new GenericArrayData(new Array[Any](arr.numElements))
- var i = 0
- while (i < arr.numElements) {
-elementVar.value.set(arr.get(i, elementVar.dataType))
-if (indexVar.isDefined) {
- indexVar.get.value.set(i)
-}
-result.update(i, f.eval(input))
-i += 1
+ override def nullSafeEval(inputRow: InternalRow, inputValue: Any): Any =
{
+val arr = inputValue.asInstanceOf[ArrayData]
+val f = functionForEval
+val result = new GenericArrayData(new Array[Any](arr.numElements))
+var i = 0
+while (i < arr.numElements) {
+ elementVar.value.set(arr.get(i, elementVar.dataType))
+ if (indexVar.isDefined) {
+indexVar.get.value.set(i)
}
- result
+ result.update(i, f.eval(inputRow))
+ i += 1
}
+result
}
override def prettyName: String = "transform"
}
+/**
+ * Filters entries in a map using the provided function.
+ */
+@ExpressionDescription(
+usage = "_FUNC_(expr, func) - Filters entries in a map using the
function.",
+examples = """
+Examples:
+ > SELECT _FUNC_(map(1, 0, 2, 2, 3, -1), (k, v) -> k > v);
+ [1 -> 0, 3 -> -1]
+ """,
+since = "2.4.0")
+case class MapFilter(
+input: Expression,
+function: Expression)
+ extends MapBasedUnaryHigherOrderFunction with CodegenFallback {
+
+ @transient val (keyType, valueType, valueContainsNull) = input.dataType
match {
--- End diff --
Maybe this should be a function in object MapBasedUnaryHigherOrderFunction,
we can use it in other map based higher order function just like using
ArrayBasedHigherOrderFunction.elementArgumentType.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22017: [SPARK-23938][SQL] Add map_zip_with function
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22017#discussion_r208260664
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/higherOrderFunctions.scala
---
@@ -365,3 +364,101 @@ case class ArrayAggregate(
override def prettyName: String = "aggregate"
}
+
+/**
+ * Merges two given maps into a single map by applying function to the
pair of values with
+ * the same key.
+ */
+@ExpressionDescription(
+ usage =
+"""
+ _FUNC_(map1, map2, function) - Merges two given maps into a single
map by applying
+ function to the pair of values with the same key. For keys only
presented in one map,
+ NULL will be passed as the value for the missing key. If an input
map contains duplicated
+ keys, only the first entry of the duplicated key is passed into the
lambda function.
+""",
+ examples = """
+Examples:
+ > SELECT _FUNC_(map(1, 'a', 2, 'b'), map(1, 'x', 2, 'y'), (k, v1,
v2) -> concat(v1, v2));
+ {1:"ax",2:"by"}
+ """,
+ since = "2.4.0")
+case class MapZipWith(left: Expression, right: Expression, function:
Expression)
+ extends HigherOrderFunction with CodegenFallback {
+
+ @transient lazy val functionForEval: Expression = functionsForEval.head
+
+ @transient lazy val MapType(keyType, leftValueType, _) = getMapType(left)
+
+ @transient lazy val MapType(_, rightValueType, _) = getMapType(right)
+
+ @transient lazy val arrayDataUnion = new ArrayDataUnion(keyType)
+
+ @transient lazy val ordering = TypeUtils.getInterpretedOrdering(keyType)
+
+ override def inputs: Seq[Expression] = left :: right :: Nil
+
+ override def functions: Seq[Expression] = function :: Nil
+
+ override def nullable: Boolean = left.nullable || right.nullable
--- End diff --
`left.nullable && right.nullable`? Because if one side is empty map, NULL
will be passed as the value for each key in other side.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22017: [SPARK-23938][SQL] Add map_zip_with function
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22017#discussion_r208257687
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/complexTypeExtractors.scala
---
@@ -267,22 +267,23 @@ case class GetArrayItem(child: Expression, ordinal:
Expression)
}
}
-/**
- * Common base class for [[GetMapValue]] and [[ElementAt]].
- */
-
-abstract class GetMapValueUtil extends BinaryExpression with
ImplicitCastInputTypes {
+object GetMapValueUtil
+{
--- End diff --
nit: brace should in previous line.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22093: [SPARK-25100][CORE] Fix no registering TaskCommit...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22093#discussion_r209650955
--- Diff: core/src/test/scala/org/apache/spark/FileSuite.scala ---
@@ -424,6 +425,39 @@ class FileSuite extends SparkFunSuite with
LocalSparkContext {
randomRDD.saveAsNewAPIHadoopDataset(jobConfig)
assert(new File(tempDir.getPath +
"/outputDataset_new/part-r-0").exists() === true)
}
+
+ test("SPARK-25100: Using KryoSerializer and" +
+ " setting registrationRequired true can lead job failed") {
+val tempDir = Utils.createTempDir()
+val inputDir = tempDir.getAbsolutePath + "/input"
+val outputDir = tempDir.getAbsolutePath + "/tmp"
+
+val writer = new PrintWriter(new File(inputDir))
+
+for(i <- 1 to 100) {
+ writer.print(i)
+ writer.write('\n')
+}
+
+writer.close()
+
+val conf = new SparkConf(false).setMaster("local").
+set("spark.kryo.registrationRequired", "true").setAppName("test")
+conf.set("spark.serializer", classOf[KryoSerializer].getName)
+conf.set("spark.serializer",
"org.apache.spark.serializer.KryoSerializer")
--- End diff --
Why we need set 'spark.serializer' twice?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22093: [SPARK-25100][CORE] Fix no registering TaskCommitMessage...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22093 Why we should create own SparkContext here? Could we just add a UT like `registration of HighlyCompressedMapStatus` to check `TaskCommitMessage` working? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22140: [SPARK-25072][PySpark] Forbid extra value for custom Row
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22140 cc @HyukjinKwon --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22165: [SPARK-25017][Core] Add test suite for BarrierCoordinato...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22165 retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22165: [SPARK-25017][Core] Add test suite for BarrierCoordinato...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22165 cc @jiangxb1987 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22165: [SPARK-25017][Core] Add test suite for BarrierCoo...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/22165 [SPARK-25017][Core] Add test suite for BarrierCoordinator and ContextBarrierState ## What changes were proposed in this pull request? Currently `ContextBarrierState` and `BarrierCoordinator` are only covered by end-to-end test in `BarrierTaskContextSuite`, add BarrierCoordinatorSuite to test both classes. ## How was this patch tested? UT in BarrierCoordinatorSuite. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-25017 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22165.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22165 commit 21bd1c37f4af6480adfc07130a15f70acdeda378 Author: liyuanjian Date: 2018-08-21T05:24:07Z [SPARK-25017][Core] Add test suite for BarrierCoordinator and ContextBarrierState --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22165: [SPARK-25017][Core] Add test suite for BarrierCoordinato...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22165 cc @gatorsmile @cloud-fan --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22202: [SPARK-25211][Core] speculation and fetch failed ...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22202#discussion_r212365264
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala ---
@@ -2246,58 +2247,6 @@ class DAGSchedulerSuite extends SparkFunSuite with
LocalSparkContext with TimeLi
assertDataStructuresEmpty()
}
- test("Trigger mapstage's job listener in submitMissingTasks") {
--- End diff --
Could you give some explain for deleting this test?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22222: [SPARK-25083][SQL] Remove the type erasure hack i...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/2 [SPARK-25083][SQL] Remove the type erasure hack in data source scan ## What changes were proposed in this pull request? 1. Add function `inputBatchRDDs` and `inputRowRDDs` interface in `ColumnarBatchScan`. 2.rewrite them in physical node which extends `ColumnarBatchScan`. ## How was this patch tested? Refactor work, test with existing UT. You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-25083 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/2.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2 commit 992a08b1d77d59daeac95c67d07e5b8efe20ce20 Author: Yuanjian Li Date: 2018-08-24T15:54:27Z [SPARK-25083][SQL] Remove the type erasure hack in data source scan --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22222: [SPARK-25083][SQL] Remove the type erasure hack i...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/2#discussion_r212784374
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/ColumnarBatchScan.scala
---
@@ -40,6 +42,29 @@ private[sql] trait ColumnarBatchScan extends
CodegenSupport {
"numOutputRows" -> SQLMetrics.createMetric(sparkContext, "number of
output rows"),
"scanTime" -> SQLMetrics.createTimingMetric(sparkContext, "scan time"))
+ /**
+ * Returns all the RDDs of ColumnarBatch which generates the input rows.
+ */
+ def inputBatchRDDs(): Seq[RDD[ColumnarBatch]]
+
+ /**
+ * Returns all the RDDs of InternalRow which generates the input rows.
+ */
+ def inputRowRDDs(): Seq[RDD[InternalRow]]
+
+ /**
+ * Get input RDD depends on supportsBatch.
+ */
+ final def getInputRDDs(): Seq[RDD[InternalRow]] = {
+if (supportsBatch) {
+ inputBatchRDDs().asInstanceOf[Seq[RDD[InternalRow]]]
--- End diff --
Here maybe the last explicitly erasure hack left, please check whether is
it acceptable or not.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22222: [SPARK-25083][SQL] Remove the type erasure hack in data ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/2 cc @cloud-fan and @rdblue have a look when you have time. If this PR doesn't coincide with your expect, I'll close this soon. Thanks! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22198: [SPARK-25121][SQL] Supports multi-part table name...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22198#discussion_r212822215
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/DataFrameJoinSuite.scala ---
@@ -191,6 +195,48 @@ class DataFrameJoinSuite extends QueryTest with
SharedSQLContext {
assert(plan2.collect { case p: BroadcastHashJoinExec => p }.size == 1)
}
+ test("SPARK-25121 Supports multi-part names for broadcast hint
resolution") {
+val (table1Name, table2Name) = ("t1", "t2")
+withTempDatabase { dbName =>
+ withTable(table1Name, table2Name) {
+withSQLConf(SQLConf.AUTO_BROADCASTJOIN_THRESHOLD.key -> "0") {
+ spark.range(50).write.saveAsTable(s"$dbName.$table1Name")
+ spark.range(100).write.saveAsTable(s"$dbName.$table2Name")
+ // First, makes sure a join is not broadcastable
+ val plan = sql(s"SELECT * FROM $dbName.$table1Name,
$dbName.$table2Name " +
+ s"WHERE $table1Name.id = $table2Name.id")
+.queryExecution.executedPlan
+ assert(plan.collect { case p: BroadcastHashJoinExec => p }.size
== 0)
+
+ // Uses multi-part table names for broadcast hints
+ def checkIfHintApplied(tableName: String, hintTableName:
String): Unit = {
--- End diff --
`hintTableName` is never used in this func?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22252: [SPARK-25261][MINOR][DOC] correct the default uni...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/22252#discussion_r213343952 --- Diff: docs/configuration.md --- @@ -152,7 +152,7 @@ of the most common options to set are: spark.driver.memory 1g -Amount of memory to use for the driver process, i.e. where SparkContext is initialized, in MiB +Amount of memory to use for the driver process, i.e. where SparkContext is initialized, in bytes --- End diff -- Check the config code here. https://github.com/apache/spark/blob/99d2e4e00711cffbfaee8cb3da9b6b3feab8ff18/core/src/main/scala/org/apache/spark/internal/config/package.scala#L40-L43 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22140: [SPARK-25072][PySpark] Forbid extra value for cus...
GitHub user xuanyuanking opened a pull request: https://github.com/apache/spark/pull/22140 [SPARK-25072][PySpark] Forbid extra value for custom Row ## What changes were proposed in this pull request? Add value length check in `_create_row`, forbid extra value for custom Row in PySpark. ## How was this patch tested? New UT in pyspark-sql You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuanyuanking/spark SPARK-25072 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22140.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22140 commit b8c6522bccde51584e9878144924fd7b92f8785f Author: liyuanjian Date: 2018-08-18T08:36:53Z Forbidden extra value for custom Row --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22024: [SPARK-25034][CORE] Remove allocations in onBlock...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22024#discussion_r213015245
--- Diff:
core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala ---
@@ -160,7 +160,13 @@ private[spark] class TorrentBroadcast[T:
ClassTag](obj: T, id: Long)
releaseLock(pieceId)
case None =>
bm.getRemoteBytes(pieceId) match {
-case Some(b) =>
+case Some(splitB) =>
+
+ // Checksum computation and further computations require the
data
+ // from the ChunkedByteBuffer to be merged, so we we merge
it now.
--- End diff --
nit of the comment.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22024: [SPARK-25034][CORE] Remove allocations in onBlock...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22024#discussion_r213015113
--- Diff:
core/src/main/scala/org/apache/spark/network/BlockTransferService.scala ---
@@ -101,15 +101,7 @@ abstract class BlockTransferService extends
ShuffleClient with Closeable with Lo
result.failure(exception)
}
override def onBlockFetchSuccess(blockId: String, data:
ManagedBuffer): Unit = {
- data match {
-case f: FileSegmentManagedBuffer =>
- result.success(f)
-case _ =>
- val ret = ByteBuffer.allocate(data.size.toInt)
--- End diff --
The copy behavior was introduced by :
https://github.com/apache/spark/pull/2330/commits/69f5d0a2434396abbbd98886e047bc08a9e65565.
How can you make sure this can be replaced by increasing the reference count?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22024: [SPARK-25034][CORE] Remove allocations in onBlockFetchSu...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22024 retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22149: [SPARK-25158][SQL]Executor accidentally exit because Scr...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22149 ``` Is that possible to add a test case? ``` Thanks for your reply Xiao, we encountered some difficulties during the test case, cause this need mock on speculative behavior. We will keep looking into this. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22149: [SPARK-25158][SQL]Executor accidentally exit because Scr...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22149 retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22165: [SPARK-25017][Core] Add test suite for BarrierCoordinato...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22165 @jiangxb1987 Great thanks for your comment! ``` One general idea is that we don't need to rely on the RPC framework to test ContextBarrierState, just mock RpcCallContexts should be enough. ``` Actually I also want to implement like this at first also as you asked in jira, but `ContextBarrierState` is the private inner class in `BarrierCoordinator`. Could I do the refactor of moving `ContextBarrierState` out of `BarrierCoordinator`? If that is permitted I think we can just mock RpcCallContext to reach this. ``` We shall cover the following scenarios: ``` Pretty cool for the list, the 5 in front scenarios are including in currently implement, I'll add the last checking work of `Make sure we clear all the internal data under each case.` after we reach an agreement. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22140: [SPARK-25072][PySpark] Forbid extra value for custom Row
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22140 AFAIC, the fix should forbid illegal extra value passing. If less values than fields it should get a `AttributeError` while accessing as the currently implement, not ban it here? What do you think :) @HyukjinKwon @BryanCutler Thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22177: stages in wrong order within job page DAG chart
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22177#discussion_r212003441
--- Diff: core/src/main/scala/org/apache/spark/ui/jobs/JobPage.scala ---
@@ -337,7 +337,9 @@ private[ui] class JobPage(parent: JobsTab, store:
AppStatusStore) extends WebUIP
store.executorList(false), appStartTime)
val operationGraphContent =
store.asOption(store.operationGraphForJob(jobId)) match {
- case Some(operationGraph) => UIUtils.showDagVizForJob(jobId,
operationGraph)
+ case Some(operationGraph) => UIUtils.showDagVizForJob(jobId,
operationGraph.sortWith(
+
_.rootCluster.id.replaceAll(RDDOperationGraph.STAGE_CLUSTER_PREFIX, "").toInt
--- End diff --
Add `getStageId` function in `RDDOperationGraph` to do this will be better.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22165: [SPARK-25017][Core] Add test suite for BarrierCoordinato...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22165 My pleasure, just find this during glance over jira in recent days. :) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22180: [SPARK-25174][YARN]Limit the size of diagnostic m...
Github user xuanyuanking commented on a diff in the pull request: https://github.com/apache/spark/pull/22180#discussion_r211996874 --- Diff: resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala --- @@ -143,6 +143,7 @@ private[spark] class ApplicationMaster(args: ApplicationMasterArguments) extends @volatile private var finished = false @volatile private var finalStatus = getDefaultFinalStatus @volatile private var finalMsg: String = "" + private val finalMsgLimitSize = sparkConf.get(AM_FINAL_MSG_LIMIT).toInt --- End diff -- nit: move this to L165? just for code clean. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22180: [SPARK-25174][YARN]Limit the size of diagnostic m...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22180#discussion_r211996461
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala
---
@@ -368,7 +369,11 @@ private[spark] class ApplicationMaster(args:
ApplicationMasterArguments) extends
}
logInfo(s"Final app status: $finalStatus, exitCode: $exitCode" +
Option(msg).map(msg => s", (reason: $msg)").getOrElse(""))
-finalMsg = msg
+finalMsg = if (msg == null || msg.length <= finalMsgLimitSize) {
+ msg
+} else {
+ msg.substring(0, finalMsgLimitSize)
--- End diff --
Maybe the message in last `finalMsgLimitSize` is more useful.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22177: stages in wrong order within job page DAG chart
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22177#discussion_r212002571
--- Diff: core/src/main/scala/org/apache/spark/ui/jobs/JobPage.scala ---
@@ -18,18 +18,18 @@
package org.apache.spark.ui.jobs
import java.util.Locale
+
import javax.servlet.http.HttpServletRequest
import scala.collection.mutable.{Buffer, ListBuffer}
import scala.xml.{Node, NodeSeq, Unparsed, Utility}
-
--- End diff --
revert this changes in import.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22177: stages in wrong order within job page DAG chart
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22177 Please change title to "[SPARK-25199][Web UI] XXX " as we described in http://spark.apache.org/contributing.html. ``` check the DAG chart in job page. ``` Could you also put the DAG chart screenshot after your fix? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22149: [SPARK-25158][SQL]Executor accidentally exit because Scr...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/22149 Gental ping @gatorsmile. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22222: [SPARK-25083][SQL] Remove the type erasure hack i...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/2#discussion_r212820814
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala
---
@@ -307,7 +308,7 @@ case class FileSourceScanExec(
withSelectedBucketsCount
}
- private lazy val inputRDD: RDD[InternalRow] = {
+ private lazy val inputRDD: RDD[Object] = {
--- End diff --
Thanks Sean! Addressed in 7e88599.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22222: [SPARK-25083][SQL] Remove the type erasure hack in data ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/2 @cloud-fan Thanks for your reply Wenchen, I'm trying to achieve this in this commit, please take a look, thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21533: [SPARK-24195][Core] Ignore the files with "local" scheme...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21533 Thanks everyone for your help! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21789: [SPARK-24829][SQL]CAST AS FLOAT inconsistent with...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21789#discussion_r203037295
--- Diff:
sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2Suites.scala
---
@@ -766,6 +774,14 @@ class HiveThriftHttpServerSuite extends
HiveThriftJdbcTest {
assert(resultSet.getString(2) === HiveUtils.builtinHiveVersion)
}
}
+
+ test("Checks cast as float") {
--- End diff --
Duplicated code?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21839: [SPARK-24339][SQL] Prunes the unused columns from...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/21839#discussion_r204447671
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
---
@@ -450,13 +450,16 @@ object ColumnPruning extends Rule[LogicalPlan] {
case d @ DeserializeToObject(_, _, child) if (child.outputSet --
d.references).nonEmpty =>
d.copy(child = prunedChild(child, d.references))
-// Prunes the unused columns from child of Aggregate/Expand/Generate
+// Prunes the unused columns from child of
Aggregate/Expand/Generate/ScriptTransformation
case a @ Aggregate(_, _, child) if (child.outputSet --
a.references).nonEmpty =>
a.copy(child = prunedChild(child, a.references))
case f @ FlatMapGroupsInPandas(_, _, _, child) if (child.outputSet --
f.references).nonEmpty =>
f.copy(child = prunedChild(child, f.references))
case e @ Expand(_, _, child) if (child.outputSet --
e.references).nonEmpty =>
e.copy(child = prunedChild(child, e.references))
+case s @ ScriptTransformation(_, _, _, child, _)
+ if (child.outputSet -- s.references).nonEmpty =>
--- End diff --
Thanks, fix in 2cf131f.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19773: [SPARK-22546][SQL] Supporting for changing column dataTy...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/19773 I'll resolve the conflicts today, thanks for ping me. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21839: [SPARK-24339][SQL] Prunes the unused columns from child ...
Github user xuanyuanking commented on the issue: https://github.com/apache/spark/pull/21839 @gatorsmile Thanks for your advice, added ut in ScriptTransformationSuite. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org