Hello beam community,
I'm looking for beam api/implementation of joins with asymmetric arrival time.
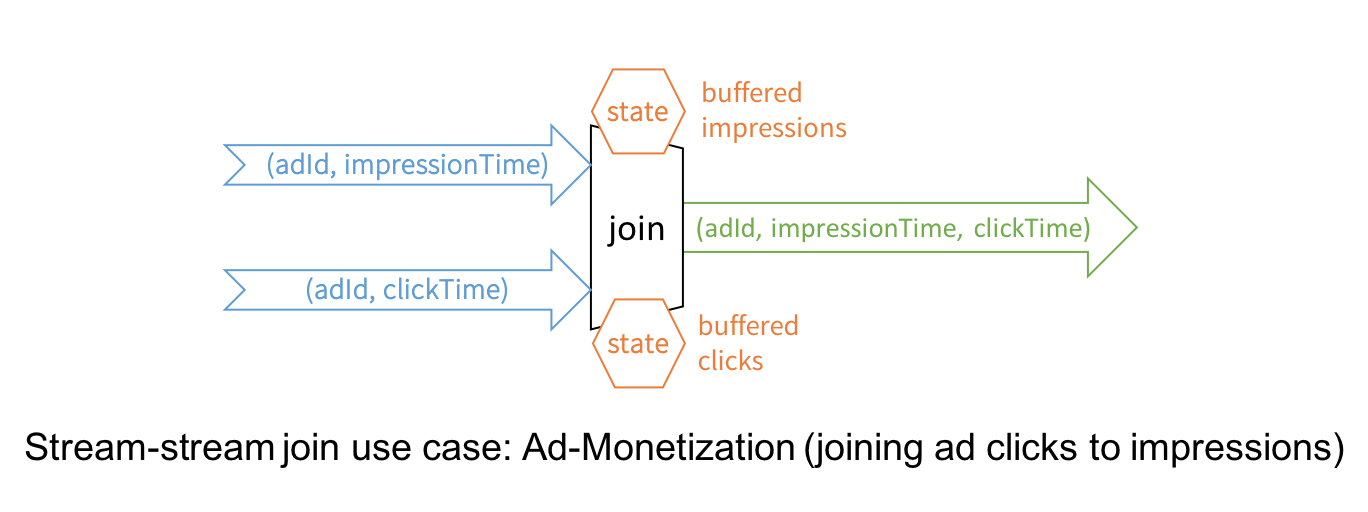
For example, for a same message, a message sent event arrives at 9am, but
message read event may arrive at 11am or even next day. So when joining two
streams of those two kinds of events together, we need to keep the buffer/state
for message sent events long enough to be able to catch late/delayed events of
message read.
Currently with beam, I saw a few example of implementing joins with CoGroupBy
and FixedWindow, so I'm thinking a few options here:
1. Increase the size of fixed windows, however, this will add latency to the
application
2. If I choose early firing to reduce latency, then I would have the
correctness issue
* If I choose to accumulate event, I would end up with duplicated
results each time early firing is triggered/
* If I choose to discard event, then results would miss the late/delayed
scenario described above.
Any comments or suggestions on how to solve this problem? I just found that
Spark Streaming can provide what I need in this blog post:
https://databricks.com/blog/2018/03/13/introducing-stream-stream-joins-in-apache-spark-2-3.html
Thanks,
Khai
[https://databricks.com/wp-content/uploads/2018/03/image5.png]<https://databricks.com/blog/2018/03/13/introducing-stream-stream-joins-in-apache-spark-2-3.html>
Introducing Stream-Stream Joins in Apache Spark 2.3 - The Databricks
Blog<https://databricks.com/blog/2018/03/13/introducing-stream-stream-joins-in-apache-spark-2-3.html>
databricks.com
Since we introduced Structured Streaming in Apache Spark 2.0, it has supported
joins (inner join and some type of outer joins) between a streaming and a
static DataFrame/Dataset.With the release of Apache Spark 2.3.0, now available
in Databricks Runtime 4.0 as part of Databricks Unified Analytics Platform, we
now support stream-stream joins.In this post, we will explore a canonical case
of how ...
{kind=link}