[
https://issues.apache.org/jira/browse/KAFKA-13834?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Luke Chen resolved KAFKA-13834.
-------------------------------
Fix Version/s: 3.3.0
Resolution: Fixed
> batch drain for nodes might have starving issue
> -----------------------------------------------
>
> Key: KAFKA-13834
> URL: https://issues.apache.org/jira/browse/KAFKA-13834
> Project: Kafka
> Issue Type: Bug
> Components: producer
> Affects Versions: 2.5.0, 2.4.1, 2.6.0, 2.5.1, 2.7.0, 2.6.1, 2.8.0, 2.7.1,
> 2.6.2, 3.1.0, 2.6.3, 2.7.2, 2.8.1, 3.0.0, 3.0.1
> Reporter: shizhenzhen
> Assignee: ruanliang
> Priority: Trivial
> Labels: producer
> Fix For: 3.3.0
>
> Attachments: image-2022-04-18-17-36-47-393.png
>
>
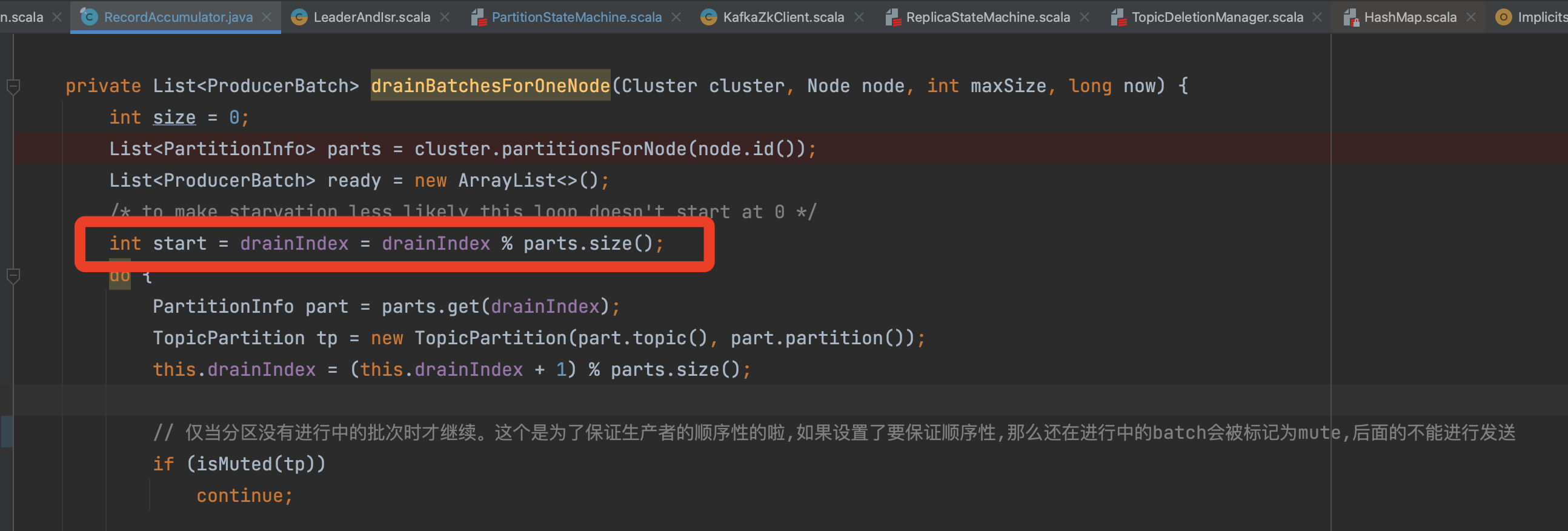
> h3. 问题代码 problem code
> RecordAccumulator#drainBatchesForOneNode
> !https://img-blog.csdnimg.cn/a4e309723c364586a46df8d94e49291f.png|width=786,height=266!
>
> 问题出在这个, private int drainIndex;
> The problem is this,private int drainIndex;
> h3. 代码预期 code expectations
> 这端代码的逻辑, 是计算出发往每个Node的ProducerBatchs,是批量发送。
> 因为发送一次的请求量是有限的(max.request.size), 所以一次可能只能发几个ProducerBatch. 那么这次发送了之后,
> 需要记录一下这里是遍历到了哪个Batch, 下次再次遍历的时候能够接着上一次遍历发送。
> 简单来说呢就是下图这样
>
> The logic of the code at this end is to calculate the ProducerBatchs sent to
> each Node, which is sent in batches.
> Because the amount of requests sent at one time is limited
> (max.request.size), only a few ProducerBatch may be sent at a time. Then
> after sending this time, you need to record which Batch is traversed here,
> and the next time you traverse it again Can continue the last traversal send.
> Simply put, it is as follows
>
> !image-2022-04-18-17-36-47-393.png|width=798,height=526!
>
>
>
> h3. 实际情况 The actual situation
> 但是呢, 因为上面的索引drainIndex 是一个全局变量, 是RecordAccumulator共享的。
> 那么通常会有很多个Node需要进行遍历,
> 上一个Node的索引会接着被第二个第三个Node接着使用,那么也就无法比较均衡合理的让每个TopicPartition都遍历到.
> 正常情况下其实这样也没有事情, 如果不出现极端情况的下,基本上都能遍历到。
> 怕就怕极端情况, 导致有很多TopicPartition不能够遍历到,也就会造成一部分消息一直发送不出去。
> However, because the index drainIndex above is a global variable shared by
> RecordAccumulator.
> Then there are usually many Nodes that need to be traversed, and the index of
> the previous Node will be used by the second and third Nodes, so it is
> impossible to traverse each TopicPartition in a balanced and reasonable
> manner.
> Under normal circumstances, there is nothing wrong with this. If there is no
> extreme situation, it can basically be traversed.
> I'm afraid of extreme situations, which will result in many TopicPartitions
> that cannot be traversed, and some messages will not be sent out all the time.
> h3. 造成的影响 impact
> 导致部分消息一直发送不出去、或者很久才能够发送出去。
> As a result, some messages cannot be sent out, or can take a long time to be
> sent out.
> h3. 触发异常情况的一个Case / A Case that triggers an exception
> 该Case场景如下:
> # 生产者向3个Node发送消息
> # 每个Node都是3个TopicPartition
> # 每个TopicPartition队列都一直源源不断的写入消息、
> # max.request.size 刚好只能存放一个ProdcuerBatch的大小。
> 就是这么几个条件,会造成每个Node只能收到一个TopicPartition队列里面的PrdoucerBatch消息。
> 开始的时候 drainIndex=0. 开始遍历第一个Node-0。 Node-0 准备开始遍历它下面的几个队列中的ProducerBatch,遍历一次
> 则drainIndex+1,发现遍历了一个队列之后,就装满了这一批次的请求。
> 那么开始遍历Node-1,这个时候则drainIndex=1,首先遍历到的是 第二个TopicPartition。然后发现一个Batch之后也满了。
> 那么开始遍历Node-1,这个时候则drainIndex=2,首先遍历到的是 第三个TopicPartition。然后发现一个Batch之后也满了。
> 这一次的Node遍历结束之后把消息发送之后
> 又接着上面的请求流程,那么这个时候的drainIndex=3了。
> 遍历Node-0,这个时候取模计算得到的是第几个TopicPartition呢?那不还是第1个吗。相当于后面的流程跟上面一模一样。
> 也就导致了每个Node的第2、3个TopicPartition队列中的ProducerBatch永远遍历不到。
> 也就发送不出去了。
>
> The case scenario is as follows:
> Producer sends message to 3 Nodes
> Each Node is 3 TopicPartitions
> Each TopicPartition queue has been continuously writing messages,
> max.request.size can only store the size of one ProdcuerBatch.
> It is these conditions that cause each Node to receive only one PrdoucerBatch
> message in the TopicPartition queue.
> At the beginning drainIndex=0. Start traversing the first Node-0. Node-0 is
> ready to start traversing the ProducerBatch in several queues below it. After
> traversing once, drainIndex + 1. After traversing a queue, it is full of
> requests for this batch.
> Then start traversing Node-1. At this time, drainIndex=1, and the second
> TopicPartition is traversed first. Then I found that a Batch was also full.
> Then start traversing Node-1. At this time, drainIndex=2, and the third
> TopicPartition is traversed first. Then I found that a Batch was also full.
> After this Node traversal is over, the message is sent
> Then the above request process is followed, then drainIndex=3 at this time.
> Traversing Node-0, which TopicPartition is obtained by taking the modulo
> calculation at this time? Isn't that the first one? Equivalent to the
> following process is exactly the same as above.
> As a result, the ProducerBatch in the second and third TopicPartition queues
> of each Node can never be traversed.
> It can't be sent.
> !https://img-blog.csdnimg.cn/aa2cc2e7a9ff4536a1800d9117e02555.png#pic_center|width=660,height=394!
>
> h3. 解决方案 solution
> 只需要每个Node,维护一个自己的索引就行了。
>
>
> Only each Node needs to maintain its own index.
>
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
{kind=link}
{kind=link}