StefanXiepj commented on a change in pull request #2325:
URL: https://github.com/apache/iceberg/pull/2325#discussion_r639376971
##
File path:
hive-metastore/src/main/java/org/apache/iceberg/hive/ClientPoolImpl.java
##
@@ -0,0 +1,145 @@
+/*
+ * Licensed to the Apache Software F
StefanXiepj commented on a change in pull request #2325:
URL: https://github.com/apache/iceberg/pull/2325#discussion_r639376971
##
File path:
hive-metastore/src/main/java/org/apache/iceberg/hive/ClientPoolImpl.java
##
@@ -0,0 +1,145 @@
+/*
+ * Licensed to the Apache Software F
StefanXiepj commented on a change in pull request #2325:
URL: https://github.com/apache/iceberg/pull/2325#discussion_r639376971
##
File path:
hive-metastore/src/main/java/org/apache/iceberg/hive/ClientPoolImpl.java
##
@@ -0,0 +1,145 @@
+/*
+ * Licensed to the Apache Software F
chenjunjiedada commented on pull request #2538:
URL: https://github.com/apache/iceberg/pull/2538#issuecomment-848412266
Thanks @rdblue for reviewing! I addressed your comments.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub
chenjunjiedada commented on a change in pull request #2538:
URL: https://github.com/apache/iceberg/pull/2538#discussion_r639361455
##
File path: orc/src/main/java/org/apache/iceberg/orc/OrcValueReaders.java
##
@@ -233,4 +236,16 @@ public void setBatchContext(long newBatchOffset
jshmchenxi commented on a change in pull request #2582:
URL: https://github.com/apache/iceberg/pull/2582#discussion_r639361400
##
File path: site/docs/configuration.md
##
@@ -40,6 +40,9 @@ Iceberg tables support table properties to configure table
behavior, like the de
| writ
chenjunjiedada commented on a change in pull request #2538:
URL: https://github.com/apache/iceberg/pull/2538#discussion_r639361132
##
File path:
parquet/src/main/java/org/apache/iceberg/parquet/ParquetValueReaders.java
##
@@ -168,6 +172,27 @@ public void setPageSource(PageRead
chenjunjiedada commented on a change in pull request #2538:
URL: https://github.com/apache/iceberg/pull/2538#discussion_r639360875
##
File path: core/src/main/java/org/apache/iceberg/MetadataColumns.java
##
@@ -36,6 +36,8 @@ private MetadataColumns() {
Integer.MAX_VALUE
jshmchenxi commented on pull request #2582:
URL: https://github.com/apache/iceberg/pull/2582#issuecomment-848411249
Thanks for the suggesion, I'll split this into several PRs. @rdblue
@kbendick
--
This is an automated message from the Apache Git Service.
To respond to the message, pleas
aokolnychyi commented on a change in pull request #2415:
URL: https://github.com/apache/iceberg/pull/2415#discussion_r639332007
##
File path:
spark/src/main/java/org/apache/iceberg/spark/actions/BaseRemoveFilesSparkAction.java
##
@@ -0,0 +1,194 @@
+/*
+ * Licensed to the Apach
aokolnychyi commented on a change in pull request #2415:
URL: https://github.com/apache/iceberg/pull/2415#discussion_r639315720
##
File path: api/src/main/java/org/apache/iceberg/actions/RemoveFiles.java
##
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (AS
kbendick commented on a change in pull request #2617:
URL: https://github.com/apache/iceberg/pull/2617#discussion_r639331400
##
File path: core/src/main/java/org/apache/iceberg/StaticTableScan.java
##
@@ -25,16 +25,33 @@
class StaticTableScan extends BaseTableScan {
priva
szehon-ho commented on a change in pull request #2358:
URL: https://github.com/apache/iceberg/pull/2358#discussion_r639319312
##
File path: core/src/main/java/org/apache/iceberg/PartitionsTable.java
##
@@ -80,21 +88,51 @@ private DataTask task(TableScan scan) {
return Stat
szehon-ho commented on a change in pull request #2358:
URL: https://github.com/apache/iceberg/pull/2358#discussion_r639319312
##
File path: core/src/main/java/org/apache/iceberg/PartitionsTable.java
##
@@ -80,21 +88,51 @@ private DataTask task(TableScan scan) {
return Stat
kbendick opened a new issue #2635:
URL: https://github.com/apache/iceberg/issues/2635
BaseAllMetadataTableScan emits a `ScanEvent` during its `planFiles` phase.
However, the `ScanEvent` uses the `tableName` of the table to which the
metadata corresponds, and not the actual metadata t
szehon-ho commented on a change in pull request #2358:
URL: https://github.com/apache/iceberg/pull/2358#discussion_r639319312
##
File path: core/src/main/java/org/apache/iceberg/PartitionsTable.java
##
@@ -80,21 +88,51 @@ private DataTask task(TableScan scan) {
return Stat
szehon-ho commented on a change in pull request #2358:
URL: https://github.com/apache/iceberg/pull/2358#discussion_r639318608
##
File path: core/src/main/java/org/apache/iceberg/PartitionsTable.java
##
@@ -80,21 +88,51 @@ private DataTask task(TableScan scan) {
return Stat
szehon-ho commented on a change in pull request #2358:
URL: https://github.com/apache/iceberg/pull/2358#discussion_r639318512
##
File path: core/src/main/java/org/apache/iceberg/PartitionsTable.java
##
@@ -80,21 +88,51 @@ private DataTask task(TableScan scan) {
return Stat
rdblue commented on pull request #2520:
URL: https://github.com/apache/iceberg/pull/2520#issuecomment-848311406
The situation where we want to use the bulk API is whenever we are going to
make a call to the KMS per file. If we can batch up the files then we can make
a single call to get al
aokolnychyi commented on a change in pull request #2415:
URL: https://github.com/apache/iceberg/pull/2415#discussion_r639220833
##
File path:
spark/src/main/java/org/apache/iceberg/spark/actions/BaseRemoveFilesSparkAction.java
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apach
rdblue commented on a change in pull request #2415:
URL: https://github.com/apache/iceberg/pull/2415#discussion_r639218827
##
File path:
spark/src/main/java/org/apache/iceberg/spark/actions/BaseRemoveFilesSparkAction.java
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apache Sof
aokolnychyi commented on a change in pull request #2415:
URL: https://github.com/apache/iceberg/pull/2415#discussion_r639212335
##
File path:
spark/src/main/java/org/apache/iceberg/spark/actions/BaseRemoveFilesSparkAction.java
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apach
aokolnychyi commented on a change in pull request #2415:
URL: https://github.com/apache/iceberg/pull/2415#discussion_r639212335
##
File path:
spark/src/main/java/org/apache/iceberg/spark/actions/BaseRemoveFilesSparkAction.java
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apach
aokolnychyi commented on a change in pull request #2415:
URL: https://github.com/apache/iceberg/pull/2415#discussion_r639208551
##
File path:
spark/src/main/java/org/apache/iceberg/spark/actions/BaseRemoveFilesSparkAction.java
##
@@ -0,0 +1,220 @@
+/*
+ * Licensed to the Apach
aokolnychyi commented on pull request #2606:
URL: https://github.com/apache/iceberg/pull/2606#issuecomment-848238709
Thanks, @karuppayya!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the spec
aokolnychyi merged pull request #2606:
URL: https://github.com/apache/iceberg/pull/2606
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, pl
rdblue commented on a change in pull request #2358:
URL: https://github.com/apache/iceberg/pull/2358#discussion_r639160362
##
File path: core/src/test/java/org/apache/iceberg/TestMetadataTableScans.java
##
@@ -159,6 +162,105 @@ public void testAllManifestsTableHonorsIgnoreResid
rdblue commented on a change in pull request #2358:
URL: https://github.com/apache/iceberg/pull/2358#discussion_r639158941
##
File path: core/src/main/java/org/apache/iceberg/PartitionsTable.java
##
@@ -80,21 +88,51 @@ private DataTask task(TableScan scan) {
return StaticD
rdblue commented on a change in pull request #2358:
URL: https://github.com/apache/iceberg/pull/2358#discussion_r639155128
##
File path: core/src/main/java/org/apache/iceberg/PartitionsTable.java
##
@@ -80,21 +88,51 @@ private DataTask task(TableScan scan) {
return StaticD
rdblue commented on a change in pull request #2358:
URL: https://github.com/apache/iceberg/pull/2358#discussion_r639155438
##
File path: core/src/main/java/org/apache/iceberg/PartitionsTable.java
##
@@ -80,21 +88,51 @@ private DataTask task(TableScan scan) {
return StaticD
rdblue commented on a change in pull request #2358:
URL: https://github.com/apache/iceberg/pull/2358#discussion_r639149470
##
File path: core/src/main/java/org/apache/iceberg/PartitionsTable.java
##
@@ -80,21 +88,51 @@ private DataTask task(TableScan scan) {
return StaticD
rdblue commented on a change in pull request #2358:
URL: https://github.com/apache/iceberg/pull/2358#discussion_r639147530
##
File path: core/src/main/java/org/apache/iceberg/PartitionsTable.java
##
@@ -80,21 +88,51 @@ private DataTask task(TableScan scan) {
return StaticD
rdblue commented on a change in pull request #2358:
URL: https://github.com/apache/iceberg/pull/2358#discussion_r639147092
##
File path: core/src/main/java/org/apache/iceberg/PartitionsTable.java
##
@@ -80,21 +88,51 @@ private DataTask task(TableScan scan) {
return StaticD
SreeramGarlapati commented on a change in pull request #2611:
URL: https://github.com/apache/iceberg/pull/2611#discussion_r635010805
##
File path:
spark3/src/main/java/org/apache/iceberg/spark/source/SparkScanBuilder.java
##
@@ -159,8 +159,14 @@ private Schema schemaWithMetada
karuppayya closed pull request #2606:
URL: https://github.com/apache/iceberg/pull/2606
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, ple
jackye1995 commented on pull request #2520:
URL: https://github.com/apache/iceberg/pull/2520#issuecomment-848118807
> The main concern that I have is the ability to use the bulk decryption
methods from the manager so planning a scan doesn't necessarily incur repeated
RPCs to a key manager
rdblue commented on a change in pull request #2286:
URL: https://github.com/apache/iceberg/pull/2286#discussion_r639077401
##
File path:
arrow/src/main/java/org/apache/iceberg/arrow/vectorized/ColumnVector.java
##
@@ -0,0 +1,116 @@
+/*
+ * Licensed to the Apache Software Found
jackye1995 commented on issue #2481:
URL: https://github.com/apache/iceberg/issues/2481#issuecomment-848084954
> I think we generally agree that we would want to change it to use
Iceberg-native branching and tagging
That would be great! I also have a few requests on my side regarding
rymurr commented on pull request #2634:
URL: https://github.com/apache/iceberg/pull/2634#issuecomment-847997587
I am happy if @openinx is! Looks great @nastra
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL a
nastra commented on pull request #2634:
URL: https://github.com/apache/iceberg/pull/2634#issuecomment-847967008
@openinx would you mind reviewing this (since you wrote the original Flink
docs)?
@rymurr could you maybe also review this?
--
This is an automated message from the Apache G
nastra opened a new pull request #2634:
URL: https://github.com/apache/iceberg/pull/2634
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, p
lizu18xz opened a new issue #2633:
URL: https://github.com/apache/iceberg/issues/2633
Does spark integrated iceberg support concurrent insert overwrite?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to
szlta commented on pull request #2613:
URL: https://github.com/apache/iceberg/pull/2613#issuecomment-847930235
cc: @rdblue @rymurr
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific c
pvary edited a comment on issue #2481:
URL: https://github.com/apache/iceberg/issues/2481#issuecomment-847869277
I also like the idea of branching / tagging tables.
> And I suppose Hive can support this easily as well then, if it's already
able to parse metadata tables.
AFAIK
pvary commented on issue #2481:
URL: https://github.com/apache/iceberg/issues/2481#issuecomment-847869277
I also like the idea of branching / tagging tables.
> And I suppose Hive can support this easily as well then, if it's already
able to parse metadata tables.
AFAIK we do
coolderli commented on issue #2632:
URL: https://github.com/apache/iceberg/issues/2632#issuecomment-847853988
@caseylucas I have finished the report, and reopen it. Can you take a look
at it for me? Thanks.
--
This is an automated message from the Apache Git Service.
To respond to the me
coolderli commented on issue #2632:
URL: https://github.com/apache/iceberg/issues/2632#issuecomment-847852599
@openinx Could you help me take a look at this problem, please? Thanks.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to G
coolderli commented on issue #2632:
URL: https://github.com/apache/iceberg/issues/2632#issuecomment-847851791
I have another question, I found
`0-3-5b132013-2f36-4a79-9993-3fed0077e5d2-00885.parquet` was only 62kb,
and the
[write.target-file-size-bytes](https://github.com/apache/iceb
coolderli commented on issue #2632:
URL: https://github.com/apache/iceberg/issues/2632#issuecomment-847848818
This is my flink DAG , the parallelism is 1.
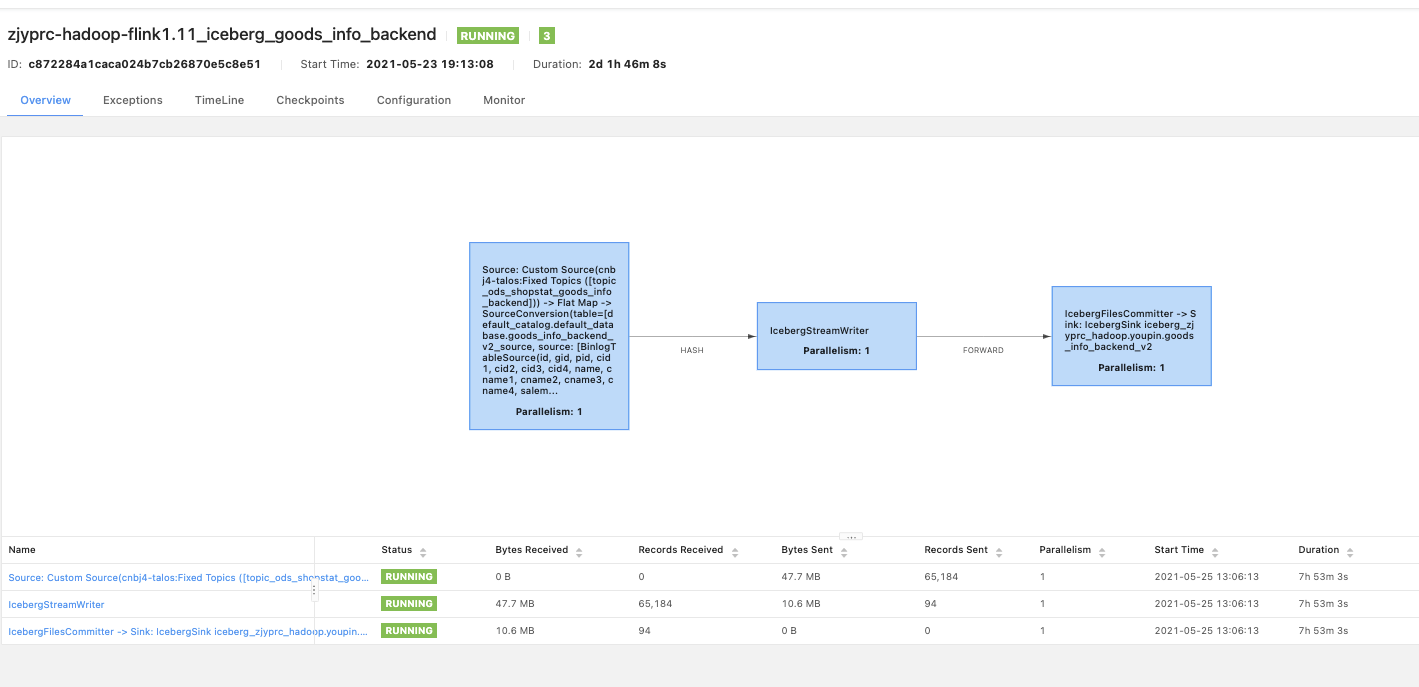
And my table
coolderli commented on issue #2632:
URL: https://github.com/apache/iceberg/issues/2632#issuecomment-847843526
[files.zip](https://github.com/apache/iceberg/files/6539351/files.zip)
There are 11 files in this zip.
**1 snapshot files:**
snap-4839740852915438766-1-1f06a123-f35
caseylucas commented on issue #2632:
URL: https://github.com/apache/iceberg/issues/2632#issuecomment-847834975
@coolderli I noticed you closed this issue. Was there no problem? Do you
mind sharing what you found?
--
This is an automated message from the Apache Git Service.
To respond to
coolderli closed issue #2632:
URL: https://github.com/apache/iceberg/issues/2632
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please co
coolderli opened a new issue #2632:
URL: https://github.com/apache/iceberg/issues/2632
I was trying to write binlog to an iceberg table with Flink SQL.
This is my iceberg table with a primary key `id`.
spark-sql> desc extended goods_info_backend_v2;
**id bigint 主键**
gid big
szehon-ho commented on issue #2481:
URL: https://github.com/apache/iceberg/issues/2481#issuecomment-847818758
> That would also have a cleaner syntax: `catalog.db.table.branch`. That
would prevent us from using some branch names, like `files` but I think overall
it would be okay.
Se
rymurr commented on a change in pull request #2286:
URL: https://github.com/apache/iceberg/pull/2286#discussion_r638553663
##
File path:
arrow/src/main/java/org/apache/iceberg/arrow/vectorized/ColumnVector.java
##
@@ -0,0 +1,116 @@
+/*
+ * Licensed to the Apache Software Found
55 matches
Mail list logo