AngersZh commented on a change in pull request #28805:
URL: https://github.com/apache/spark/pull/28805#discussion_r446805961
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/PruneFileSourcePartitionsSuite.scala
##
@@ -108,4 +109,54 @@ class PruneFi
SparkQA removed a comment on pull request #28898:
URL: https://github.com/apache/spark/pull/28898#issuecomment-650853588
**[Test build #124616 has
started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124616/testReport)**
for PR 28898 at commit
[`acce8c5`](https://gi
SparkQA commented on pull request #28898:
URL: https://github.com/apache/spark/pull/28898#issuecomment-650965128
**[Test build #124616 has
finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124616/testReport)**
for PR 28898 at commit
[`acce8c5`](https://github.co
LantaoJin commented on a change in pull request #28935:
URL: https://github.com/apache/spark/pull/28935#discussion_r446804385
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
##
@@ -2212,6 +2212,7 @@ class AstBuilder(conf: SQLConf
LantaoJin commented on a change in pull request #28935:
URL: https://github.com/apache/spark/pull/28935#discussion_r446799790
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/types/HiveStringType.scala
##
@@ -47,9 +47,7 @@ object HiveStringType {
case MapTyp
HyukjinKwon commented on pull request #28616:
URL: https://github.com/apache/spark/pull/28616#issuecomment-650950403
LGTM too
This is an automated message from the Apache Git Service.
To respond to the message, please log on
AmplabJenkins removed a comment on pull request #28924:
URL: https://github.com/apache/spark/pull/28924#issuecomment-650949521
This is an automated message from the Apache Git Service.
To respond to the message, please log on
AmplabJenkins commented on pull request #28924:
URL: https://github.com/apache/spark/pull/28924#issuecomment-650949521
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHu
yairogen commented on a change in pull request #28629:
URL: https://github.com/apache/spark/pull/28629#discussion_r446798079
##
File path: core/src/test/scala/org/apache/spark/util/ThreadUtilsSuite.scala
##
@@ -25,11 +25,27 @@ import scala.concurrent.duration._
import scala.ut
igreenfield commented on a change in pull request #28629:
URL: https://github.com/apache/spark/pull/28629#discussion_r446797352
##
File path: core/src/test/scala/org/apache/spark/util/ThreadUtilsSuite.scala
##
@@ -25,11 +25,27 @@ import scala.concurrent.duration._
import scala
SparkQA removed a comment on pull request #28935:
URL: https://github.com/apache/spark/pull/28935#issuecomment-650844766
**[Test build #124614 has
started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124614/testReport)**
for PR 28935 at commit
[`a3a1cef`](https://gi
SparkQA commented on pull request #28935:
URL: https://github.com/apache/spark/pull/28935#issuecomment-650947540
**[Test build #124614 has
finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124614/testReport)**
for PR 28935 at commit
[`a3a1cef`](https://github.co
xianyinxin commented on pull request #28943:
URL: https://github.com/apache/spark/pull/28943#issuecomment-650947651
@cloud-fan @brkyvz , pls take a look.
This is an automated message from the Apache Git Service.
To respond to
xianyinxin commented on a change in pull request #28875:
URL: https://github.com/apache/spark/pull/28875#discussion_r446796512
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
##
@@ -468,13 +458,25 @@ class AstBuilder(conf: SQLCon
cloud-fan commented on a change in pull request #28629:
URL: https://github.com/apache/spark/pull/28629#discussion_r446795038
##
File path: core/src/test/scala/org/apache/spark/util/ThreadUtilsSuite.scala
##
@@ -25,11 +25,27 @@ import scala.concurrent.duration._
import scala.u
SparkQA commented on pull request #28875:
URL: https://github.com/apache/spark/pull/28875#issuecomment-650944873
**[Test build #5047 has
finished](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/5047/testReport)**
for PR 28875 at commit
[`d5edef3`](https://github.com
xianyinxin opened a new pull request #28943:
URL: https://github.com/apache/spark/pull/28943
### What changes were proposed in this pull request?
This pr fix a bug of check rules for MERGE INTO.
### Why are the changes needed?
SPARK-30924 adds some check rules for ME
SparkQA removed a comment on pull request #28875:
URL: https://github.com/apache/spark/pull/28875#issuecomment-650882037
**[Test build #5047 has
started](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/5047/testReport)**
for PR 28875 at commit
[`d5edef3`](https://git
cloud-fan commented on pull request #28916:
URL: https://github.com/apache/spark/pull/28916#issuecomment-650938932
I checked the related code and came up with the same conclusion as @viirya .
Can you elaborate more about how this happens?
--
cloud-fan commented on pull request #28930:
URL: https://github.com/apache/spark/pull/28930#issuecomment-650934435
retest this please
This is an automated message from the Apache Git Service.
To respond to the message, please
HeartSaVioR commented on pull request #27620:
URL: https://github.com/apache/spark/pull/27620#issuecomment-650932618
After looking at a couple of more issues on file stream source, I'm feeling
that we also need to have upper bound of the cache, as file stream source is
already contributing
cloud-fan commented on a change in pull request #28647:
URL: https://github.com/apache/spark/pull/28647#discussion_r446789203
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/ddl.scala
##
@@ -839,6 +839,19 @@ case class AlterTableSetLocationCommand(
cloud-fan commented on a change in pull request #28647:
URL: https://github.com/apache/spark/pull/28647#discussion_r446788640
##
File path: docs/sql-ref-syntax-ddl-create-table-like.md
##
@@ -57,6 +57,8 @@ CREATE TABLE [IF NOT EXISTS] table_identifier LIKE
source_table_identif
cloud-fan commented on pull request #28647:
URL: https://github.com/apache/spark/pull/28647#issuecomment-650925029
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub an
manuzhang commented on pull request #28916:
URL: https://github.com/apache/spark/pull/28916#issuecomment-650925712
@cloud-fan here it is
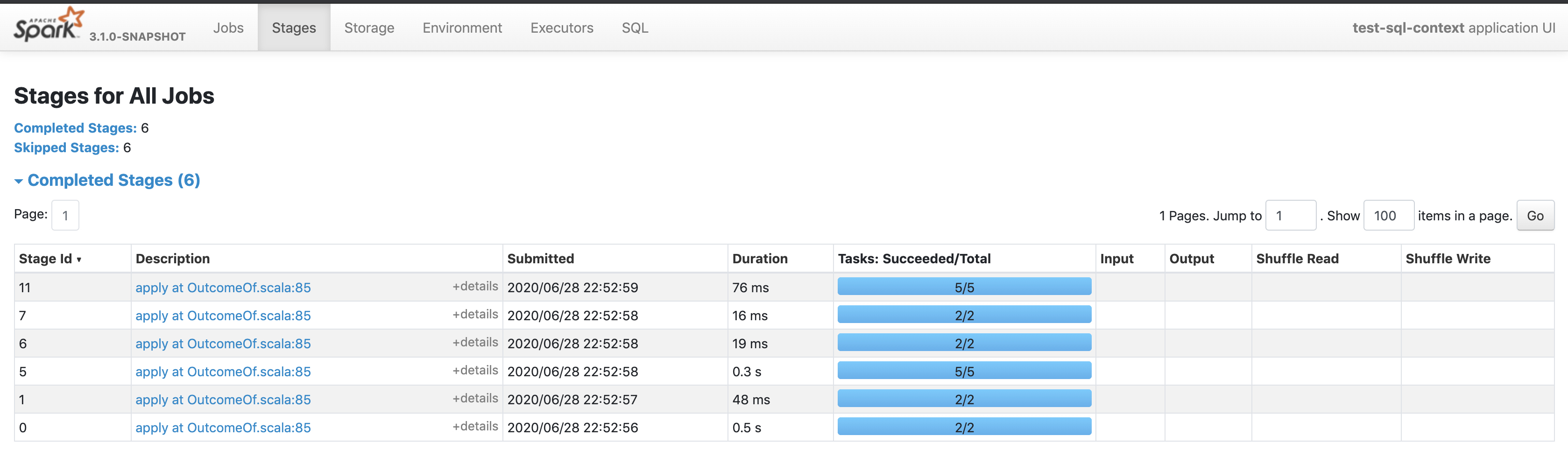
---
HyukjinKwon commented on a change in pull request #28788:
URL: https://github.com/apache/spark/pull/28788#discussion_r446784525
##
File path:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/config.scala
##
@@ -74,10 +76,11 @@ package object config {
.do
sarutak commented on pull request #28942:
URL: https://github.com/apache/spark/pull/28942#issuecomment-650921592
Hi @warrenzhu25 , thank you for your contribution.
This PR seems to add a new feature so could you add a testcase for it?
You can find tests for the status API in `UISeleniu
cloud-fan commented on pull request #28916:
URL: https://github.com/apache/spark/pull/28916#issuecomment-650920696
@manuzhang can you check the web UI as well?
This is an automated message from the Apache Git Service.
To resp
SparkQA removed a comment on pull request #28875:
URL: https://github.com/apache/spark/pull/28875#issuecomment-650882027
**[Test build #5046 has
started](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/5046/testReport)**
for PR 28875 at commit
[`d5edef3`](https://git
SparkQA commented on pull request #28875:
URL: https://github.com/apache/spark/pull/28875#issuecomment-650919677
**[Test build #5046 has
finished](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/5046/testReport)**
for PR 28875 at commit
[`d5edef3`](https://github.com
TJX2014 commented on a change in pull request #28882:
URL: https://github.com/apache/spark/pull/28882#discussion_r446782110
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveExternalCatalog.scala
##
@@ -545,7 +545,11 @@ private[spark] class HiveExternalCatalo
SparkQA removed a comment on pull request #28938:
URL: https://github.com/apache/spark/pull/28938#issuecomment-650870128
**[Test build #124619 has
started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124619/testReport)**
for PR 28938 at commit
[`96dfd17`](https://gi
AmplabJenkins removed a comment on pull request #28939:
URL: https://github.com/apache/spark/pull/28939#issuecomment-650913498
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/124
AmplabJenkins commented on pull request #28939:
URL: https://github.com/apache/spark/pull/28939#issuecomment-650913498
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/124622/
AmplabJenkins removed a comment on pull request #28939:
URL: https://github.com/apache/spark/pull/28939#issuecomment-650913159
Merged build finished. Test FAILed.
This is an automated message from the Apache Git Service.
To r
SparkQA commented on pull request #28938:
URL: https://github.com/apache/spark/pull/28938#issuecomment-650913642
**[Test build #124619 has
finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124619/testReport)**
for PR 28938 at commit
[`96dfd17`](https://github.co
SparkQA removed a comment on pull request #28924:
URL: https://github.com/apache/spark/pull/28924#issuecomment-650870142
**[Test build #124620 has
started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124620/testReport)**
for PR 28924 at commit
[`a09990f`](https://gi
SparkQA removed a comment on pull request #28939:
URL: https://github.com/apache/spark/pull/28939#issuecomment-650912108
**[Test build #124622 has
started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124622/testReport)**
for PR 28939 at commit
[`b571f4c`](https://gi
AmplabJenkins commented on pull request #28939:
URL: https://github.com/apache/spark/pull/28939#issuecomment-650913159
Merged build finished. Test FAILed.
This is an automated message from the Apache Git Service.
To respond t
SparkQA commented on pull request #28924:
URL: https://github.com/apache/spark/pull/28924#issuecomment-650912895
**[Test build #124620 has
finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124620/testReport)**
for PR 28924 at commit
[`a09990f`](https://github.co
SparkQA commented on pull request #28939:
URL: https://github.com/apache/spark/pull/28939#issuecomment-650912866
**[Test build #124622 has
finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124622/testReport)**
for PR 28939 at commit
[`b571f4c`](https://github.co
SparkQA commented on pull request #28939:
URL: https://github.com/apache/spark/pull/28939#issuecomment-650912108
**[Test build #124622 has
started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124622/testReport)**
for PR 28939 at commit
[`b571f4c`](https://github.com
viirya commented on a change in pull request #28761:
URL: https://github.com/apache/spark/pull/28761#discussion_r446778323
##
File path:
sql/core/v2.3/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilterSuite.scala
##
@@ -74,9 +75,9 @@ class OrcFilterSuite e
yairogen commented on a change in pull request #28629:
URL: https://github.com/apache/spark/pull/28629#discussion_r446777693
##
File path: core/src/test/scala/org/apache/spark/util/ThreadUtilsSuite.scala
##
@@ -25,11 +25,27 @@ import scala.concurrent.duration._
import scala.ut
SparkQA commented on pull request #28895:
URL: https://github.com/apache/spark/pull/28895#issuecomment-650910831
**[Test build #5048 has
started](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/5048/testReport)**
for PR 28895 at commit
[`4247fa3`](https://github.com/
manuzhang commented on pull request #28916:
URL: https://github.com/apache/spark/pull/28916#issuecomment-650909946
@cloud-fan Yes, also from the UT log before this change (I enabled the
lineage log)
```
= TEST OUTPUT FOR o.a.s.sql.execution.adaptive.AdaptiveQueryExecSuite:
'
cloud-fan commented on a change in pull request #28805:
URL: https://github.com/apache/spark/pull/28805#discussion_r446776081
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/PruneFileSourcePartitionsSuite.scala
##
@@ -108,4 +109,54 @@ class PruneFileS
HeartSaVioR commented on a change in pull request #28930:
URL: https://github.com/apache/spark/pull/28930#discussion_r446775390
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -55,6 +54,13 @@ object FileStreamSink exten
HeartSaVioR commented on a change in pull request #28930:
URL: https://github.com/apache/spark/pull/28930#discussion_r446775390
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -55,6 +54,13 @@ object FileStreamSink exten
HeartSaVioR commented on a change in pull request #28930:
URL: https://github.com/apache/spark/pull/28930#discussion_r446775390
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -55,6 +54,13 @@ object FileStreamSink exten
HeartSaVioR commented on a change in pull request #28930:
URL: https://github.com/apache/spark/pull/28930#discussion_r446775390
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -55,6 +54,13 @@ object FileStreamSink exten
cloud-fan commented on a change in pull request #28930:
URL: https://github.com/apache/spark/pull/28930#discussion_r446774988
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -55,6 +54,13 @@ object FileStreamSink extends
cloud-fan commented on a change in pull request #28930:
URL: https://github.com/apache/spark/pull/28930#discussion_r446774699
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/FileStreamSink.scala
##
@@ -55,6 +54,13 @@ object FileStreamSink extends
sarutak commented on a change in pull request #28939:
URL: https://github.com/apache/spark/pull/28939#discussion_r446774168
##
File path: core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala
##
@@ -1254,7 +1255,7 @@ class SparkSubmitSuite
|public void ini
sarutak commented on a change in pull request #28939:
URL: https://github.com/apache/spark/pull/28939#discussion_r446774168
##
File path: core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala
##
@@ -1254,7 +1255,7 @@ class SparkSubmitSuite
|public void ini
viirya edited a comment on pull request #28916:
URL: https://github.com/apache/spark/pull/28916#issuecomment-650899063
> It's because `ShuffleRowedRDD` is created with default number of shuffle
partitions here
https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/s
dongjoon-hyun edited a comment on pull request #28919:
URL: https://github.com/apache/spark/pull/28919#issuecomment-650903736
Thank you all. Merged to master/3.0. (The last commit is adding only two
comments)
This is an auto
dongjoon-hyun closed pull request #28919:
URL: https://github.com/apache/spark/pull/28919
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to
dongjoon-hyun commented on pull request #28919:
URL: https://github.com/apache/spark/pull/28919#issuecomment-650903736
Thank you all. Merged to master/3.0.
This is an automated message from the Apache Git Service.
To respond
cloud-fan commented on a change in pull request #28935:
URL: https://github.com/apache/spark/pull/28935#discussion_r446771337
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
##
@@ -2212,6 +2212,7 @@ class AstBuilder(conf: SQLConf
cloud-fan commented on pull request #28916:
URL: https://github.com/apache/spark/pull/28916#issuecomment-650902976
@manuzhang can you check the Spark web UI and make sure AQE does launch
tasks for empty partitions?
This is a
AmplabJenkins removed a comment on pull request #28754:
URL: https://github.com/apache/spark/pull/28754#issuecomment-650902644
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/124
AmplabJenkins commented on pull request #28754:
URL: https://github.com/apache/spark/pull/28754#issuecomment-650902644
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/124611/
dongjoon-hyun closed pull request #28923:
URL: https://github.com/apache/spark/pull/28923
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to
HeartSaVioR commented on pull request #28941:
URL: https://github.com/apache/spark/pull/28941#issuecomment-650902412
Late LGTM. Thanks for taking care of!
This is an automated message from the Apache Git Service.
To respond t
AmplabJenkins removed a comment on pull request #28754:
URL: https://github.com/apache/spark/pull/28754#issuecomment-650902400
Merged build finished. Test PASSed.
This is an automated message from the Apache Git Service.
To r
AmplabJenkins commented on pull request #28754:
URL: https://github.com/apache/spark/pull/28754#issuecomment-650902400
Merged build finished. Test PASSed.
This is an automated message from the Apache Git Service.
To respond t
dongjoon-hyun commented on pull request #28923:
URL: https://github.com/apache/spark/pull/28923#issuecomment-650902382
Thank you, @Ngone51 and all. Today's 3 commits are only test case changes
and I tested locally. The main body is already tested. Merged to master for
Apache Spark 3.1.0.
viirya commented on a change in pull request #28761:
URL: https://github.com/apache/spark/pull/28761#discussion_r446769137
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcTest.scala
##
@@ -78,12 +78,16 @@ abstract class OrcTest extends Q
cloud-fan commented on a change in pull request #28629:
URL: https://github.com/apache/spark/pull/28629#discussion_r446768786
##
File path: core/src/test/scala/org/apache/spark/util/ThreadUtilsSuite.scala
##
@@ -25,11 +25,27 @@ import scala.concurrent.duration._
import scala.u
cchighman commented on pull request #28841:
URL: https://github.com/apache/spark/pull/28841#issuecomment-650900831
> > I wonder though if structured streaming always implied an event source,
particularly when streaming from a file source?
>
> Ideally it should be. It's not 100% reall
cloud-fan commented on a change in pull request #28882:
URL: https://github.com/apache/spark/pull/28882#discussion_r446768236
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveExternalCatalog.scala
##
@@ -545,7 +545,11 @@ private[spark] class HiveExternalCata
dongjoon-hyun closed pull request #28936:
URL: https://github.com/apache/spark/pull/28936
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to
dongjoon-hyun commented on pull request #28936:
URL: https://github.com/apache/spark/pull/28936#issuecomment-650899447
Thanks, @xuanyuanking and @cloud-fan . I created SPARK-32126 and update the
title.
Merged to master/3.0.
--
cchighman edited a comment on pull request #28841:
URL: https://github.com/apache/spark/pull/28841#issuecomment-650899177
@HeartSaVioR
It's in effect no different than a path globular filter except that instead
of my wildcard specifying a file extension, it's a wildcard on other metadat
HeartSaVioR edited a comment on pull request #28841:
URL: https://github.com/apache/spark/pull/28841#issuecomment-650898695
> I wonder though if structured streaming always implied an event source,
particularly when streaming from a file source?
Ideally it should be. It's not 100% re
viirya commented on pull request #28916:
URL: https://github.com/apache/spark/pull/28916#issuecomment-650899063
> It's because `ShuffleRowedRDD` is created with default number of shuffle
partitions here
https://github.com/apache/spark/blob/master/sql/core/src/main/scala/org/apache/spark/sq
cchighman commented on pull request #28841:
URL: https://github.com/apache/spark/pull/28841#issuecomment-650899177
@HeartSaVioR
It's in effect no different than a path globular filter except that instead
instead of my wildcard specifying a file extension, it's a wildcard on other
m
HeartSaVioR commented on pull request #28841:
URL: https://github.com/apache/spark/pull/28841#issuecomment-650898695
> I wonder though if structured streaming always implied an event source,
particularly when streaming from a file source?
Ideally it should be. It's not 100% really fo
dongjoon-hyun commented on a change in pull request #28939:
URL: https://github.com/apache/spark/pull/28939#discussion_r446766094
##
File path: core/src/test/scala/org/apache/spark/deploy/SparkSubmitSuite.scala
##
@@ -1254,7 +1255,7 @@ class SparkSubmitSuite
|public vo
pan3793 commented on a change in pull request #28940:
URL: https://github.com/apache/spark/pull/28940#discussion_r446766066
##
File path:
common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/ExecutorDiskUtils.java
##
@@ -27,7 +27,7 @@
public class ExecutorD
dongjoon-hyun commented on pull request #28938:
URL: https://github.com/apache/spark/pull/28938#issuecomment-650898036
Please put that on the PR description. That will be a commit log permanantly.
This is an automated message
dongjoon-hyun commented on a change in pull request #28935:
URL: https://github.com/apache/spark/pull/28935#discussion_r446765171
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/types/HiveStringType.scala
##
@@ -47,9 +47,7 @@ object HiveStringType {
case Ma
dongjoon-hyun commented on a change in pull request #28935:
URL: https://github.com/apache/spark/pull/28935#discussion_r44676
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/types/HiveStringType.scala
##
@@ -47,9 +47,7 @@ object HiveStringType {
case Ma
dongjoon-hyun commented on pull request #28941:
URL: https://github.com/apache/spark/pull/28941#issuecomment-650893785
SPARK-32124 is assigned to you, @warrenzhu25 .
This is an automated message from the Apache Git Service.
T
HyukjinKwon commented on a change in pull request #28761:
URL: https://github.com/apache/spark/pull/28761#discussion_r446761037
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcTest.scala
##
@@ -78,12 +78,16 @@ abstract class OrcTest exte
dongjoon-hyun closed pull request #28941:
URL: https://github.com/apache/spark/pull/28941
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to
cloud-fan commented on pull request #28895:
URL: https://github.com/apache/spark/pull/28895#issuecomment-650892863
retest this please
This is an automated message from the Apache Git Service.
To respond to the message, please
cloud-fan commented on pull request #28916:
URL: https://github.com/apache/spark/pull/28916#issuecomment-650892593
Ideally we should launch no task for empty partitions. Launching one task is
still not the best solution.
Thi
HyukjinKwon commented on a change in pull request #28761:
URL: https://github.com/apache/spark/pull/28761#discussion_r446759277
##
File path:
sql/core/v2.3/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilterSuite.scala
##
@@ -74,9 +75,9 @@ class OrcFilterSu
HeartSaVioR commented on pull request #28904:
URL: https://github.com/apache/spark/pull/28904#issuecomment-650889370
UPDATE: SPARK-30946 + SPARK-30462 with lower down driver memory to 1.5G now
writes batch 9039 which RES is around 1.3g. I guess the process uses up
available memory if possi
manuzhang edited a comment on pull request #28916:
URL: https://github.com/apache/spark/pull/28916#issuecomment-650888636
@viirya
It's because `ShuffleRowedRDD` is created with default number of shuffle
partitions here
https://github.com/apache/spark/blob/master/sql/core/src/main/s
manuzhang commented on pull request #28916:
URL: https://github.com/apache/spark/pull/28916#issuecomment-650888636
@viirya
It's because of `ShuffleRowedRDD` is created with default number of shuffle
partitions here
https://github.com/apache/spark/blob/master/sql/core/src/main/scala
HyukjinKwon commented on pull request #27983:
URL: https://github.com/apache/spark/pull/27983#issuecomment-650886614
Let's keep the PR description and title up-to-date.
This is an automated message from the Apache Git Servic
HyukjinKwon commented on a change in pull request #27983:
URL: https://github.com/apache/spark/pull/27983#discussion_r446754091
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveStrategies.scala
##
@@ -22,7 +22,7 @@ import java.util.Locale
import org.apach
HyukjinKwon commented on a change in pull request #27983:
URL: https://github.com/apache/spark/pull/27983#discussion_r446753971
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/HiveScriptTransformationExec.scala
##
@@ -0,0 +1,400 @@
+/*
Review comment
AmplabJenkins removed a comment on pull request #28882:
URL: https://github.com/apache/spark/pull/28882#issuecomment-650885129
This is an automated message from the Apache Git Service.
To respond to the message, please log on
AmplabJenkins commented on pull request #28882:
URL: https://github.com/apache/spark/pull/28882#issuecomment-650885129
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHu
SparkQA removed a comment on pull request #28754:
URL: https://github.com/apache/spark/pull/28754#issuecomment-650828437
**[Test build #124611 has
started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124611/testReport)**
for PR 28754 at commit
[`bbf72c4`](https://gi
SparkQA commented on pull request #28754:
URL: https://github.com/apache/spark/pull/28754#issuecomment-650882399
**[Test build #124611 has
finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/124611/testReport)**
for PR 28754 at commit
[`bbf72c4`](https://github.co
1 - 100 of 454 matches
Mail list logo