zsxwing commented on code in PR #38823:
URL: https://github.com/apache/spark/pull/38823#discussion_r1043035473
##
sql/catalyst/src/main/java/org/apache/spark/sql/connector/catalog/TableProvider.java:
##
@@ -93,4 +93,18 @@ default Transform[]
toujours33 commented on code in PR #38711:
URL: https://github.com/apache/spark/pull/38711#discussion_r1043030519
##
core/src/main/scala/org/apache/spark/ExecutorAllocationManager.scala:
##
@@ -643,10 +643,12 @@ private[spark] class ExecutorAllocationManager(
// Should be
toujours33 commented on code in PR #38711:
URL: https://github.com/apache/spark/pull/38711#discussion_r1043028737
##
core/src/main/scala/org/apache/spark/scheduler/SparkListener.scala:
##
@@ -55,7 +55,8 @@ case class SparkListenerTaskGettingResult(taskInfo: TaskInfo)
extends
Ngone51 commented on code in PR #38876:
URL: https://github.com/apache/spark/pull/38876#discussion_r1043027754
##
core/src/main/scala/org/apache/spark/storage/BlockManager.scala:
##
@@ -637,9 +637,11 @@ private[spark] class BlockManager(
def reregister(): Unit = {
//
zhouyifan279 opened a new pull request, #38978:
URL: https://github.com/apache/spark/pull/38978
### What changes were proposed in this pull request?
Remove hive-vector-code-gen and its dependent jars from spark distribution
### Why are the changes needed?
hive-vector-code-gen is
cloud-fan commented on code in PR #38823:
URL: https://github.com/apache/spark/pull/38823#discussion_r1043022539
##
sql/catalyst/src/main/java/org/apache/spark/sql/connector/catalog/TableProvider.java:
##
@@ -93,4 +93,18 @@ default Transform[]
gengliangwang commented on PR #38882:
URL: https://github.com/apache/spark/pull/38882#issuecomment-1342212090
@yabola ok, can you try adding a new test case for it?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
wankunde commented on code in PR #38649:
URL: https://github.com/apache/spark/pull/38649#discussion_r1043018066
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/expressions.scala:
##
@@ -780,6 +780,13 @@ object LikeSimplification extends Rule[LogicalPlan]
mridulm commented on code in PR #38711:
URL: https://github.com/apache/spark/pull/38711#discussion_r1043015456
##
core/src/main/scala/org/apache/spark/scheduler/SparkListener.scala:
##
@@ -55,7 +55,8 @@ case class SparkListenerTaskGettingResult(taskInfo: TaskInfo)
extends
HyukjinKwon commented on code in PR #38883:
URL: https://github.com/apache/spark/pull/38883#discussion_r1043011644
##
python/pyspark/sql/tests/connect/test_connect_basic.py:
##
@@ -21,6 +21,7 @@
import grpc # type: ignore
+from pyspark.sql.connect.column import Column
dongjoon-hyun commented on PR #38976:
URL: https://github.com/apache/spark/pull/38976#issuecomment-1342193784
Thank you!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To
dongjoon-hyun commented on PR #38976:
URL: https://github.com/apache/spark/pull/38976#issuecomment-1342193584
> BTW, I plan to revisit all these stuff to clean up all - we rushed a bit
in Spark Connect Python client. For now, LGTM. I am going to merge this.
Ack. No problem at all,
HyukjinKwon commented on PR #38976:
URL: https://github.com/apache/spark/pull/38976#issuecomment-1342193439
Merged to master.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific
HyukjinKwon closed pull request #38976: [SPARK-41366][CONNECT][FOLLOWUP] Import
`Column` if pandas is available
URL: https://github.com/apache/spark/pull/38976
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL
HyukjinKwon commented on PR #38976:
URL: https://github.com/apache/spark/pull/38976#issuecomment-1342193041
BTW, I plan to revisit all these stuff to clean up all - we rushed a bit in
Spark Connect Python client. For now, LGTM. I am going to merge this.
--
This is an automated message
mridulm commented on code in PR #38876:
URL: https://github.com/apache/spark/pull/38876#discussion_r1043005698
##
core/src/main/scala/org/apache/spark/storage/BlockManager.scala:
##
@@ -637,9 +637,11 @@ private[spark] class BlockManager(
def reregister(): Unit = {
//
MaxGekk commented on PR #38864:
URL: https://github.com/apache/spark/pull/38864#issuecomment-1342185477
@xkrogen After offline discussion with @cloud-fan @srielau, we decided to
change the parameter marker to `:` in the PR.
--
This is an automated message from the Apache Git Service.
To
toujours33 commented on code in PR #38711:
URL: https://github.com/apache/spark/pull/38711#discussion_r104358
##
core/src/main/scala/org/apache/spark/scheduler/SparkListener.scala:
##
@@ -55,7 +55,8 @@ case class SparkListenerTaskGettingResult(taskInfo: TaskInfo)
extends
toujours33 commented on code in PR #38711:
URL: https://github.com/apache/spark/pull/38711#discussion_r1042997408
##
core/src/main/scala/org/apache/spark/scheduler/SparkListener.scala:
##
@@ -55,7 +55,8 @@ case class SparkListenerTaskGettingResult(taskInfo: TaskInfo)
extends
dongjoon-hyun commented on PR #38901:
URL: https://github.com/apache/spark/pull/38901#issuecomment-1342175409
Could you make a backporting PR, @pan3793 ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above
mridulm commented on code in PR #38711:
URL: https://github.com/apache/spark/pull/38711#discussion_r1042993786
##
core/src/main/scala/org/apache/spark/scheduler/SparkListener.scala:
##
@@ -55,7 +55,8 @@ case class SparkListenerTaskGettingResult(taskInfo: TaskInfo)
extends
Ngone51 commented on code in PR #38711:
URL: https://github.com/apache/spark/pull/38711#discussion_r1042993398
##
core/src/main/scala/org/apache/spark/ExecutorAllocationManager.scala:
##
@@ -733,7 +735,7 @@ private[spark] class ExecutorAllocationManager(
// If this
dongjoon-hyun commented on PR #38976:
URL: https://github.com/apache/spark/pull/38976#issuecomment-1342167092
Thank you, @grundprinzip .
Could you review this, @viirya ? This will recover one of Apache Spark Apple
Silicon CI on `Scaleway`.
--
This is an automated message from the
Ngone51 commented on code in PR #38711:
URL: https://github.com/apache/spark/pull/38711#discussion_r1042987205
##
core/src/main/scala/org/apache/spark/ExecutorAllocationManager.scala:
##
@@ -643,10 +643,12 @@ private[spark] class ExecutorAllocationManager(
// Should be 0
HeartSaVioR closed pull request #38880: [SPARK-38277][SS] Clear write batch
after RocksDB state store's commit
URL: https://github.com/apache/spark/pull/38880
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above
Ngone51 commented on code in PR #38711:
URL: https://github.com/apache/spark/pull/38711#discussion_r1042987003
##
core/src/main/scala/org/apache/spark/ExecutorAllocationManager.scala:
##
@@ -643,10 +643,12 @@ private[spark] class ExecutorAllocationManager(
// Should be 0
ulysses-you commented on code in PR #38939:
URL: https://github.com/apache/spark/pull/38939#discussion_r1042986658
##
sql/core/src/main/scala/org/apache/spark/sql/execution/command/createDataSourceTables.scala:
##
@@ -145,6 +145,12 @@ case class
HeartSaVioR commented on PR #38880:
URL: https://github.com/apache/spark/pull/38880#issuecomment-1342158178
Thanks! Merging to master.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the
ulysses-you commented on code in PR #38939:
URL: https://github.com/apache/spark/pull/38939#discussion_r1042983373
##
sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryExecutionErrors.scala:
##
@@ -785,7 +785,7 @@ private[sql] object QueryExecutionErrors extends
amaliujia commented on PR #38977:
URL: https://github.com/apache/spark/pull/38977#issuecomment-1342148963
LGTM!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To
HyukjinKwon opened a new pull request, #38977:
URL: https://github.com/apache/spark/pull/38977
### What changes were proposed in this pull request?
This PR implements `DataFrameReader.parquet` alias in Spark Connect.
### Why are the changes needed?
For API feature
zhengruifeng commented on PR #38975:
URL: https://github.com/apache/spark/pull/38975#issuecomment-1342129557
LGTM
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To
wecharyu commented on PR #38898:
URL: https://github.com/apache/spark/pull/38898#issuecomment-1342127570
@HeartSaVioR yes you are right, the actual problem is that we may fetch
empty partitions unexpectedly in one batch, and in the next batch we fetch the
real partitions again. The new
dongjoon-hyun commented on PR #38976:
URL: https://github.com/apache/spark/pull/38976#issuecomment-1342119648
All tests passed.
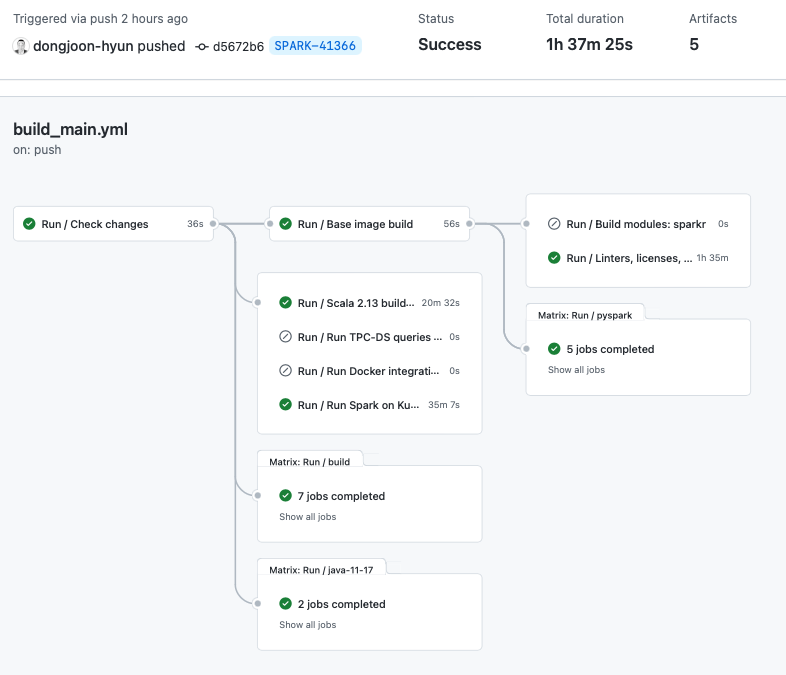
--
This is
HyukjinKwon closed pull request #38975: [SPARK-41284][CONNECT] Support
read.json()
URL: https://github.com/apache/spark/pull/38975
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific
HyukjinKwon commented on PR #38975:
URL: https://github.com/apache/spark/pull/38975#issuecomment-1342110895
Merged to master.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific
HyukjinKwon commented on code in PR #38975:
URL: https://github.com/apache/spark/pull/38975#discussion_r1042962157
##
python/pyspark/sql/tests/connect/test_connect_basic.py:
##
@@ -121,6 +121,23 @@ def test_simple_read(self):
# Check that the limit is applied
gengliangwang commented on PR #38776:
URL: https://github.com/apache/spark/pull/38776#issuecomment-1342094831
LGTM except minor comments. Great work, @anchovYu
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL
LuciferYang commented on code in PR #38940:
URL: https://github.com/apache/spark/pull/38940#discussion_r1042955098
##
sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala:
##
@@ -649,10 +649,10 @@ private[sql] object QueryCompilationErrors
viirya commented on PR #38969:
URL: https://github.com/apache/spark/pull/38969#issuecomment-1342094246
Thank you!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To
LuciferYang commented on code in PR #38940:
URL: https://github.com/apache/spark/pull/38940#discussion_r1042955098
##
sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala:
##
@@ -649,10 +649,10 @@ private[sql] object QueryCompilationErrors
dongjoon-hyun commented on PR #38969:
URL: https://github.com/apache/spark/pull/38969#issuecomment-1342093390
All tests passed. Merged to master. Thank you, @viirya and all!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and
dongjoon-hyun closed pull request #38969: [SPARK-41442][SQL] Only update
SQLMetric value if merging with valid metric
URL: https://github.com/apache/spark/pull/38969
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
gengliangwang commented on code in PR #38776:
URL: https://github.com/apache/spark/pull/38776#discussion_r1042953641
##
sql/core/src/test/scala/org/apache/spark/sql/LateralColumnAliasSuite.scala:
##
@@ -0,0 +1,287 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF)
grundprinzip commented on code in PR #38970:
URL: https://github.com/apache/spark/pull/38970#discussion_r1042952381
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala:
##
@@ -518,9 +518,16 @@ class
gengliangwang commented on code in PR #38776:
URL: https://github.com/apache/spark/pull/38776#discussion_r1042951934
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveLateralColumnAlias.scala:
##
@@ -0,0 +1,222 @@
+/*
+ * Licensed to the Apache
gengliangwang commented on code in PR #38776:
URL: https://github.com/apache/spark/pull/38776#discussion_r1042951497
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveLateralColumnAlias.scala:
##
@@ -0,0 +1,222 @@
+/*
+ * Licensed to the Apache
grundprinzip commented on code in PR #38970:
URL: https://github.com/apache/spark/pull/38970#discussion_r1042950939
##
connector/connect/common/src/main/protobuf/spark/connect/expressions.proto:
##
@@ -43,7 +43,11 @@ message Expression {
Expression expr = 1;
//
LuciferYang commented on PR #38974:
URL: https://github.com/apache/spark/pull/38974#issuecomment-1342081928
https://github.com/LuciferYang/make-distribution.sh/actions/runs/3645502265/jobs/6155706406
LuciferYang commented on code in PR #38960:
URL: https://github.com/apache/spark/pull/38960#discussion_r1042948569
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala:
##
@@ -172,7 +172,7 @@ object CurDateExpressionBuilder extends
amaliujia commented on code in PR #38970:
URL: https://github.com/apache/spark/pull/38970#discussion_r1042945624
##
connector/connect/common/src/main/protobuf/spark/connect/expressions.proto:
##
@@ -43,7 +43,11 @@ message Expression {
Expression expr = 1;
//
LuciferYang commented on PR #38936:
URL: https://github.com/apache/spark/pull/38936#issuecomment-1342060398
@steveloughran maven build spark with hadoop 3.4.0-SNAPSHOT failed not
related to `scala-maven-plugin`, after add the following 2 test dependencies to
`sql/core` as
LuciferYang commented on PR #38974:
URL: https://github.com/apache/spark/pull/38974#issuecomment-1342053776
Downgrading scala-maven-plugin will reach 4.7.2, and the local maven build
will still pass. I will update pr and test the GA compilation
```
[INFO] Reactor Summary for Spark
sharkdtu commented on code in PR #38518:
URL: https://github.com/apache/spark/pull/38518#discussion_r1042926171
##
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/scheduler/cluster/k8s/ExecutorPodsWatchSnapshotSource.scala:
##
@@ -78,6 +80,15 @@ class
amaliujia commented on PR #38975:
URL: https://github.com/apache/spark/pull/38975#issuecomment-1342036106
@zhengruifeng
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To
zsxwing commented on code in PR #38823:
URL: https://github.com/apache/spark/pull/38823#discussion_r1042918249
##
sql/catalyst/src/main/java/org/apache/spark/sql/connector/catalog/TableProvider.java:
##
@@ -93,4 +93,18 @@ default Transform[]
dongjoon-hyun commented on PR #38976:
URL: https://github.com/apache/spark/pull/38976#issuecomment-1342008681
cc @grundprinzip , @hvanhovell , @HyukjinKwon , @cloud-fan , @zhengruifeng ,
@amaliujia
--
This is an automated message from the Apache Git Service.
To respond to the message,
HeartSaVioR commented on PR #38911:
URL: https://github.com/apache/spark/pull/38911#issuecomment-1342007657
cc. @zsxwing @xuanyuanking @viirya Friendly reminder.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL
HeartSaVioR commented on PR #38880:
URL: https://github.com/apache/spark/pull/38880#issuecomment-1342007531
cc. @zsxwing @xuanyuanking @viirya Friendly reminder.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL
dongjoon-hyun commented on code in PR #38883:
URL: https://github.com/apache/spark/pull/38883#discussion_r1042916333
##
python/pyspark/sql/tests/connect/test_connect_basic.py:
##
@@ -21,6 +21,7 @@
import grpc # type: ignore
+from pyspark.sql.connect.column import Column
HeartSaVioR commented on code in PR #38911:
URL: https://github.com/apache/spark/pull/38911#discussion_r1042916237
##
connector/kafka-0-10-sql/src/test/resources/error/kafka-error-classes.json:
##
@@ -0,0 +1,26 @@
+{
+
dongjoon-hyun opened a new pull request, #38976:
URL: https://github.com/apache/spark/pull/38976
### What changes were proposed in this pull request?
This is a follow-up to move `Column` import statement in order to a test
issue
### Why are the changes needed?
`Column`
LuciferYang commented on PR #38936:
URL: https://github.com/apache/spark/pull/38936#issuecomment-1341995325
@HyukjinKwon @srowen @steveloughran In order to not block this pr, I open
another one to investigate the issue mentioned in the dev list : maven build
spark master with hadoop
LuciferYang commented on PR #38974:
URL: https://github.com/apache/spark/pull/38974#issuecomment-1341987449
Run
```
build/mvn clean install -Phadoop-3 -Phadoop-cloud -Pmesos -Pyarn
-Pkinesis-asl -Phive-thriftserver -Pspark-ganglia-lgpl -Pkubernetes -Phive
-DskipTests
HeartSaVioR commented on code in PR #38898:
URL: https://github.com/apache/spark/pull/38898#discussion_r1042911844
##
connector/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaMicroBatchSourceSuite.scala:
##
@@ -627,6 +627,45 @@ abstract class
dongjoon-hyun commented on PR #38862:
URL: https://github.com/apache/spark/pull/38862#issuecomment-1341980674
Thank you for backporting this.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the
HeartSaVioR commented on code in PR #38898:
URL: https://github.com/apache/spark/pull/38898#discussion_r1042910210
##
connector/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaMicroBatchSourceSuite.scala:
##
@@ -627,6 +627,45 @@ abstract class
HeartSaVioR commented on PR #38898:
URL: https://github.com/apache/spark/pull/38898#issuecomment-1341979338
I'm trying to understand the case - if my understanding is correct, the new
test is just to trigger the same behavior rather than reproducing actual
problem, right? In the new test,
cloud-fan commented on code in PR #38776:
URL: https://github.com/apache/spark/pull/38776#discussion_r1042909362
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveLateralColumnAlias.scala:
##
@@ -0,0 +1,222 @@
+/*
+ * Licensed to the Apache Software
beliefer commented on code in PR #38799:
URL: https://github.com/apache/spark/pull/38799#discussion_r1042908731
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/InsertWindowGroupLimit.scala:
##
@@ -0,0 +1,98 @@
+/*
+ * Licensed to the Apache Software
amaliujia commented on PR #38973:
URL: https://github.com/apache/spark/pull/38973#issuecomment-1341969449
Looks pretty good!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
amaliujia commented on code in PR #38973:
URL: https://github.com/apache/spark/pull/38973#discussion_r1042905152
##
python/pyspark/sql/connect/dataframe.py:
##
@@ -824,6 +824,39 @@ def withColumn(self, colName: str, col: Column) ->
"DataFrame":
HeartSaVioR commented on PR #38898:
URL: https://github.com/apache/spark/pull/38898#issuecomment-1341968071
Could you please try to summarize the description of JIRA to PR template,
especially the part of "Root Cause"? Also, is it "known" issue for Kafka
consumer?
Also please note
amaliujia commented on code in PR #38973:
URL: https://github.com/apache/spark/pull/38973#discussion_r1042904415
##
connector/connect/server/src/main/scala/org/apache/spark/sql/connect/planner/SparkConnectPlanner.scala:
##
@@ -309,6 +310,28 @@ class SparkConnectPlanner(session:
amaliujia commented on code in PR #38973:
URL: https://github.com/apache/spark/pull/38973#discussion_r1042904146
##
connector/connect/common/src/main/protobuf/spark/connect/relations.proto:
##
@@ -570,3 +571,21 @@ message Hint {
// (Optional) Hint parameters.
repeated
amaliujia opened a new pull request, #38975:
URL: https://github.com/apache/spark/pull/38975
### What changes were proposed in this pull request?
This PR supports the `json()` API in DataFrameReader. This API is built on
top of the core API of the reader (schema, load,
ulysses-you commented on code in PR #38939:
URL: https://github.com/apache/spark/pull/38939#discussion_r1042862929
##
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkPlan.scala:
##
@@ -223,6 +224,19 @@ abstract class SparkPlan extends QueryPlan[SparkPlan] with
LuciferYang commented on PR #38974:
URL: https://github.com/apache/spark/pull/38974#issuecomment-1341954845
https://github.com/LuciferYang/make-distribution.sh/blob/master/.github/workflows/blank.yml
https://github.com/LuciferYang/make-distribution.sh/actions/runs/3645098350
--
LuciferYang opened a new pull request, #38974:
URL: https://github.com/apache/spark/pull/38974
### What changes were proposed in this pull request?
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
###
pan3793 commented on PR #38901:
URL: https://github.com/apache/spark/pull/38901#issuecomment-1341948947
Thanks @dongjoon-hyun for checking, I think you are right, it should be
ported to 3.2/3.3
--
This is an automated message from the Apache Git Service.
To respond to the message, please
dongjoon-hyun commented on PR #38901:
URL: https://github.com/apache/spark/pull/38901#issuecomment-1341947314
Thank you all.
If this is caused by SPARK-27991 at Spark 3.2.0, do we need to backport to
branch-3.3 and 3.2?
--
This is an automated message from the Apache Git Service.
To
wecharyu commented on PR #38898:
URL: https://github.com/apache/spark/pull/38898#issuecomment-1341944936
@jerrypeng the empty offset will be stored in `committedOffsets`, when we
run next batch, the following code will record an empty map startOffset in
`newBatchesPlan`:
HeartSaVioR commented on code in PR #38911:
URL: https://github.com/apache/spark/pull/38911#discussion_r1042892403
##
connector/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaMicroBatchSourceSuite.scala:
##
@@ -234,6 +235,108 @@ abstract class
LuciferYang commented on code in PR #38960:
URL: https://github.com/apache/spark/pull/38960#discussion_r1042889334
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala:
##
@@ -172,7 +172,7 @@ object CurDateExpressionBuilder extends
LuciferYang commented on code in PR #38960:
URL: https://github.com/apache/spark/pull/38960#discussion_r1042889334
##
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/datetimeExpressions.scala:
##
@@ -172,7 +172,7 @@ object CurDateExpressionBuilder extends
dongjoon-hyun commented on code in PR #38969:
URL: https://github.com/apache/spark/pull/38969#discussion_r1042885426
##
sql/core/src/test/scala/org/apache/spark/sql/execution/adaptive/AdaptiveQueryExecSuite.scala:
##
@@ -2156,8 +2156,15 @@ class AdaptiveQueryExecSuite
LuciferYang commented on code in PR #38940:
URL: https://github.com/apache/spark/pull/38940#discussion_r1042879224
##
sql/catalyst/src/main/scala/org/apache/spark/sql/errors/QueryCompilationErrors.scala:
##
@@ -649,10 +649,10 @@ private[sql] object QueryCompilationErrors
beliefer commented on code in PR #38973:
URL: https://github.com/apache/spark/pull/38973#discussion_r1042865399
##
connector/connect/common/src/main/protobuf/spark/connect/relations.proto:
##
@@ -570,3 +571,21 @@ message Hint {
// (Optional) Hint parameters.
repeated
LuciferYang commented on PR #38960:
URL: https://github.com/apache/spark/pull/38960#issuecomment-1341907393
There are two questions:
1. When `validParametersCount.length == 0`, should an internal exception be
thrown? I think `validParametersCount.length == 0` should only be because it
beliefer commented on code in PR #38973:
URL: https://github.com/apache/spark/pull/38973#discussion_r1042866959
##
python/pyspark/sql/connect/dataframe.py:
##
@@ -824,6 +824,39 @@ def withColumn(self, colName: str, col: Column) ->
"DataFrame":
zhengruifeng commented on code in PR #38973:
URL: https://github.com/apache/spark/pull/38973#discussion_r1042865704
##
connector/connect/common/src/main/protobuf/spark/connect/relations.proto:
##
@@ -570,3 +571,21 @@ message Hint {
// (Optional) Hint parameters.
repeated
zhengruifeng commented on PR #38973:
URL: https://github.com/apache/spark/pull/38973#issuecomment-1341900821
awesome! @beliefer thank you so much
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to
beliefer commented on code in PR #38973:
URL: https://github.com/apache/spark/pull/38973#discussion_r1042865399
##
connector/connect/common/src/main/protobuf/spark/connect/relations.proto:
##
@@ -570,3 +571,21 @@ message Hint {
// (Optional) Hint parameters.
repeated
itholic closed pull request #38664: [SPARK-41147][SQL] Assign a name to the
legacy error class `_LEGACY_ERROR_TEMP_1042`
URL: https://github.com/apache/spark/pull/38664
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
itholic commented on PR #38664:
URL: https://github.com/apache/spark/pull/38664#issuecomment-1341896519
Closing since it's duplicated to #38707
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to
itholic commented on PR #38664:
URL: https://github.com/apache/spark/pull/38664#issuecomment-1341896379
Closing since it's duplicated to #38707
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to
ulysses-you commented on code in PR #38939:
URL: https://github.com/apache/spark/pull/38939#discussion_r1042862929
##
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkPlan.scala:
##
@@ -223,6 +224,19 @@ abstract class SparkPlan extends QueryPlan[SparkPlan] with
beliefer opened a new pull request, #38973:
URL: https://github.com/apache/spark/pull/38973
### What changes were proposed in this pull request?
Implement `DataFrame.melt` with a proto message
1. Implement `DataFrame.melt` for scala API
2. Implement `DataFrame.melt`for python
panbingkun opened a new pull request, #38972:
URL: https://github.com/apache/spark/pull/38972
### What changes were proposed in this pull request?
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch
HeartSaVioR commented on code in PR #38911:
URL: https://github.com/apache/spark/pull/38911#discussion_r1042860224
##
connector/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaMicroBatchStream.scala:
##
@@ -316,6 +320,50 @@ private[kafka010] class
1 - 100 of 294 matches
Mail list logo