beliefer commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1459329942
@hvanhovell Do we still need this change ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to
beliefer commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1458193681
> E... SQL/scala/Python all use the analyzer; they are all just
frontends to the same thing.
I found the reason. Although the scala API use analyzer too. `object
ResolveLambda
beliefer commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1458109080
> @beliefer here is the thing. When this was designed it was mainly aimed at
sql, and there we definitely do not generate unique names in lambda functions
either. This is all done in the
beliefer commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1457418420
@hvanhovell Scala also uses
`UnresolvedNamedLambdaVariable.freshVarName("x")` to get the unique names. see:
https://github.com/apache/spark/blob/201e08c03a31c763e3120540ac1b1ca8ef252
beliefer commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1456026258
It seems pyspark supports the nested lambda variables and two PR fix the
issue.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to
beliefer commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1455392063
> I guess we will need to rewrite the lamda function in spark connect
planner.
Yeah.
--
This is an automated message from the Apache Git Service.
To respond to the message, plea
beliefer commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1455390728
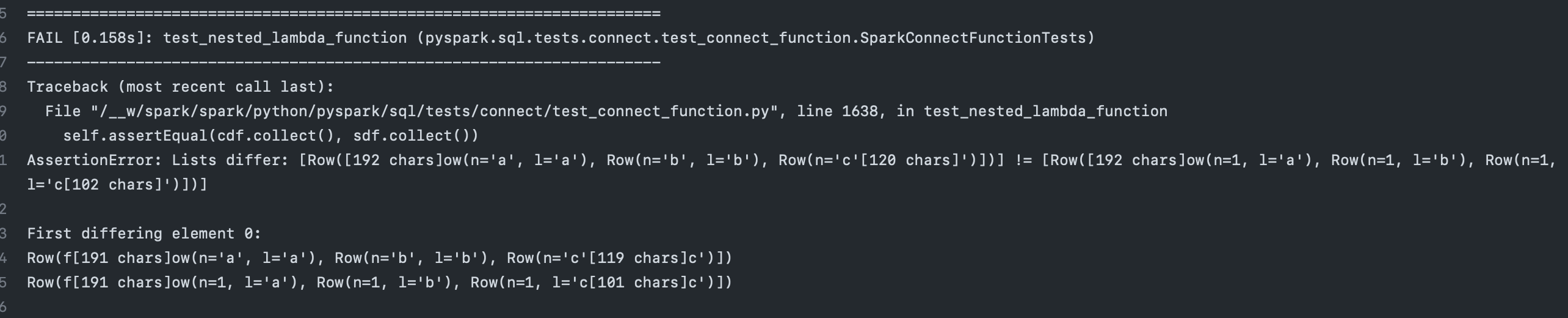
--
This is an automated message from the Apache Git Service.
To respo
beliefer commented on PR #40287:
URL: https://github.com/apache/spark/pull/40287#issuecomment-1455384317
@hvanhovell After my test, `python/run-tests --testnames
'pyspark.sql.connect.dataframe'` will not passed.
--
This is an automated message from the Apache Git Service.
To respond to th