Hello, Seeing this mail thread pop up in my search filter I want to give some insights as one of the Arrow PMCs.
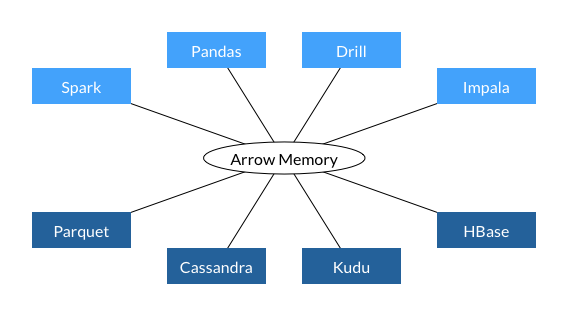
I have not yet heard of anyone currently working on Cassandra + Arrow. This would definitely be a great combination to better support performant clients that send/receive larger chunks of data to/from Cassandra. This has really worked well in the past with PySpark/Scala-Spark, Pandas & ODBC, .. If there are any efforts in the Cassandra ecosystem, please reach out to me. I'm happy to give guidance on that topic. The mention of Cassandra in the diagram on the landing page of Arrow is there for historical reasons. It would be nice to have this integration one day but as mentioned above, this is not there yet. Either we will have that in future or we will replace with another integration that really exists (I would like to see the former). Cheers Uwe > Not sure why they put that in there, it's definitely misleading. There's > nothing arrow related in Cassandra. > > There's an open JIRA, but nothing has been committed yet: > https://issues.apache.org/jira/browse/CASSANDRA-9259 > > On Wed, Jan 9, 2019 at 3:48 PM Tomas Bartalos <tomas.barta...@gmail.com> > wrote: > > > There is a diagram on the homepage displaying Cassandra (with other > > storages) as source of data. > > https://arrow.apache.org/img/shared.png > > > > Which made me think there should be some integration... > > > > On Thu, 10 Jan 2019, 12:38 am Jonathan Haddad <j...@jonhaddad.com wrote: > > > >> Where are you seeing that it works with Cassandra? There's no mention of > >> it under https://arrow.apache.org/powered_by/, and on the homepage it > >> says only says that a Cassandra developer worked on it. > >> > >> We (unfortunately) don't do anything with it at the moment. > >> > >> On Wed, Jan 9, 2019 at 3:24 PM Tomas Bartalos <tomas.barta...@gmail.com> > >> wrote: > >> > >>> I’ve read lot of nice things about Apache Arrow in-memory columnar > >>> format. On their homepage they mention Cassandra as a possible storage > >>> which could interoperate with Arrow. Unfortunately I was not able to find > >>> any working example which would demonstrate their cooperation. > >>> > >>> *My use case:* I’m doing OLAP processing of data stored in Cassandra > >>> with Spark. I need to deduplicate data with Cassandra’s upserts, so other > >>> (more-suitable) storages like HDFS + parquet, ORC didn’t seem like an > >>> option. > >>> *What I’d like to achieve: *speed-up spark’s data ingestion from > >>> Cassandra. > >>> > >>> Is it possible to query data from Cassandra in Arrow format ? > >>> > >> > >> > >> -- > >> Jon Haddad > >> http://www.rustyrazorblade.com > >> twitter: rustyrazorblade > >> > > > > -- > Jon Haddad > http://www.rustyrazorblade.com > twitter: rustyrazorblade --------------------------------------------------------------------- To unsubscribe, e-mail: user-unsubscr...@cassandra.apache.org For additional commands, e-mail: user-h...@cassandra.apache.org
{kind=link}