I'm wondering how I can get better results with Tesseract. Here are a few images I've been testing with + results:
*Image <http://tleyden-misc.s3.amazonaws.com/ocr-test-data/10.jpg>*: <https://lh5.googleusercontent.com/-MwWj-AZZOEo/U6RX1yWJZAI/AAAAAAAAAaU/8N-lWBwBvCc/s1600/10.jpg> *Actual OCR text*: VCZZSWE *Expected OCR text*: VC22500E *Image <http://tleyden-misc.s3.amazonaws.com/ocr-test-data/9.jpg>*: <https://lh4.googleusercontent.com/-GdcSO9f7gZI/U6RXzF77PuI/AAAAAAAAAaM/TnKetG_P9ps/s1600/9.jpg> *Actual OCR text*: ViZZSWE DRIVEWAY *Expected OCR text*: VC22500E DRIVEWAY Any tips on doing pre-processing on the images to improve the recognition? The code I'm using to call tesseract (via go-tesseract) is here: https://github.com/tleyden/open-ocr/blob/master/tesseract_engine.go#L49-L53 Version: I'm using the tesseract-ocr-eng package from Debian Jessie, which looks to be version: 3.02-2 <http://ftp.de.debian.org/debian/pool/main/t/tesseract-eng/tesseract-eng_3.02-2.dsc> (the full build script is available in this Dockerfile <https://registry.hub.docker.com/u/tleyden5iwx/go-tesseract-trusted/dockerfile> ) -- You received this message because you are subscribed to the Google Groups "tesseract-ocr" group. To unsubscribe from this group and stop receiving emails from it, send an email to tesseract-ocr+unsubscr...@googlegroups.com. To post to this group, send email to tesseract-ocr@googlegroups.com. Visit this group at http://groups.google.com/group/tesseract-ocr. To view this discussion on the web visit https://groups.google.com/d/msgid/tesseract-ocr/f38687f5-84cc-4c4b-a7c9-e5e6db6f327b%40googlegroups.com. For more options, visit https://groups.google.com/d/optout.
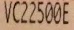{kind=link}
{kind=link}
{kind=link}
{kind=link}