优秀!可以提个improve issue
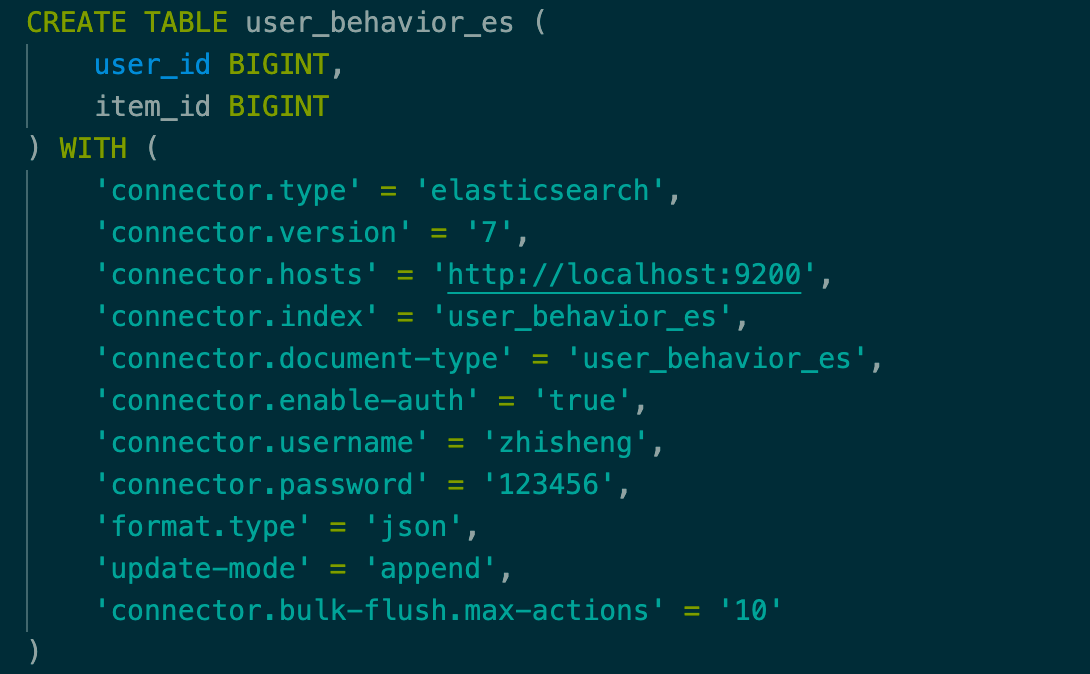
Best Regards jinhai...@gmail.com > 2020年3月25日 下午1:40,zhisheng <zhisheng2...@gmail.com> 写道: > > hi,Leonar Xu > > 官方 ES DDL 现在不支持填写 ES 集群的用户名和密码,我现在在公司已经做了扩展,加了这个功能,请问社区是否需要这个功能?我该怎么贡献呢? > > 效果如图:http://zhisheng-blog.oss-cn-hangzhou.aliyuncs.com/2020-03-25-053948.png > > Best Wishes! > > zhisheng > > Leonard Xu <xbjt...@gmail.com> 于2020年3月24日周二 下午5:53写道: > >> Hi, 出发 >> 看起来是你缺少了依赖es connector的依赖[1],所以只能找到内置的filesystem connector,目前内置的filesystem >> connector只支持csv format,所以会有这个错误。 >> 在项目中加上缺失的依赖即可,如果使用SQL CLI,也需要将依赖的jar包放到 flink的lib目录下。 >> >> <dependency> >> <groupId>org.apache.flink</groupId> >> <artifactId>flink-sql-connector-elasticsearch6_2.11</artifactId> >> <version>${flink.version}</version> >> </dependency> >> <dependency> >> <groupId>org.apache.flink</groupId> >> <artifactId>flink-json</artifactId> >> <version>${flink.version}</version> >> </dependency> >> >> Best, >> Leonard >> [1] >> https://ci.apache.org/projects/flink/flink-docs-master/dev/table/connect.html#elasticsearch-connector >> < >> https://ci.apache.org/projects/flink/flink-docs-master/dev/table/connect.html#elasticsearch-connector >>> >> >> >>> 在 2020年3月23日,23:30,出发 <573693...@qq.com> 写道: >>> >>> >>> 源码如下: >>> CREATE TABLE buy_cnt_per_hour ( >>> hour_of_day BIGINT, >>> buy_cnt BIGINT >>> ) WITH ( >>> 'connector.type' = 'elasticsearch', >>> 'connector.version' = '6', >>> 'connector.hosts' = 'http://localhost:9200', >>> 'connector.index' = 'buy_cnt_per_hour', >>> 'connector.document-type' = 'user_behavior', >>> 'connector.bulk-flush.max-actions' = '1', >>> 'format.type' = 'json', >>> 'update-mode' = 'append' >>> ) >>> import >> org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; >>> import org.apache.flink.table.api.EnvironmentSettings; >>> import org.apache.flink.table.api.Table; >>> import org.apache.flink.table.api.java.StreamTableEnvironment; >>> import org.apache.flink.types.Row; >>> >>> public class ESTest { >>> >>> public static void main(String[] args) throws Exception { >>> >>> //2、设置运行环境 >>> StreamExecutionEnvironment streamEnv = >> StreamExecutionEnvironment.getExecutionEnvironment(); >>> EnvironmentSettings settings = >> EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build(); >>> StreamTableEnvironment tableEnv = >> StreamTableEnvironment.create(streamEnv, settings); >>> streamEnv.setParallelism(1); >>> String sinkDDL = " CREATE TABLE test_es ( hour_of_day BIGINT, >> buy_cnt BIGINT " >>> + ") WITH ( 'connector.type' = 'elasticsearch', >> 'connector.version' = '6'," >>> + " 'connector.hosts' = 'http://localhost:9200', >> 'connector.index' = 'buy_cnt_per_hour'," >>> + " 'connector.document-type' = 'user_behavior'," >>> + " 'connector.bulk-flush.max-actions' = '1',\n" + " >> 'format.type' = 'json'," >>> + " 'update-mode' = 'append' )"; >>> tableEnv.sqlUpdate(sinkDDL); >>> Table table = tableEnv.sqlQuery("select * from test_es "); >>> tableEnv.toRetractStream(table, Row.class).print(); >>> streamEnv.execute(""); >>> } >>> >>> } >>> 具体error >>> The matching candidates: >>> org.apache.flink.table.sources.CsvAppendTableSourceFactory >>> Mismatched properties: >>> 'connector.type' expects 'filesystem', but is 'elasticsearch' >>> 'format.type' expects 'csv', but is 'json' >>> >>> The following properties are requested: >>> connector.bulk-flush.max-actions=1 >>> connector.document-type=user_behavior >>> connector.hosts=http://localhost:9200 >>> connector.index=buy_cnt_per_hour >>> connector.type=elasticsearch >>> connector.version=6 >>> format.type=json >>> schema.0.data-type=BIGINT >>> schema.0.name=hour_of_day >>> schema.1.data-type=BIGINT >>> schema.1.name=buy_cnt >>> update-mode=append >> >>
{kind=link}