It helps, at least it's fairly clear now. I am not against storing the state into Flink, but as per your first point, I need to get it persisted, asynchronously, in an external database too to let other possible application/services to retrieve the state. What you are saying is I can either use Flink and forget database layer, or make a java microservice with a database. Mixing Flink with a Database doesn't make any sense. My concerns with the database is how do you work out the previous state to calculate the new one? Is it good and fast? (moving money from account A to B isn't a problem cause you have two separate events).
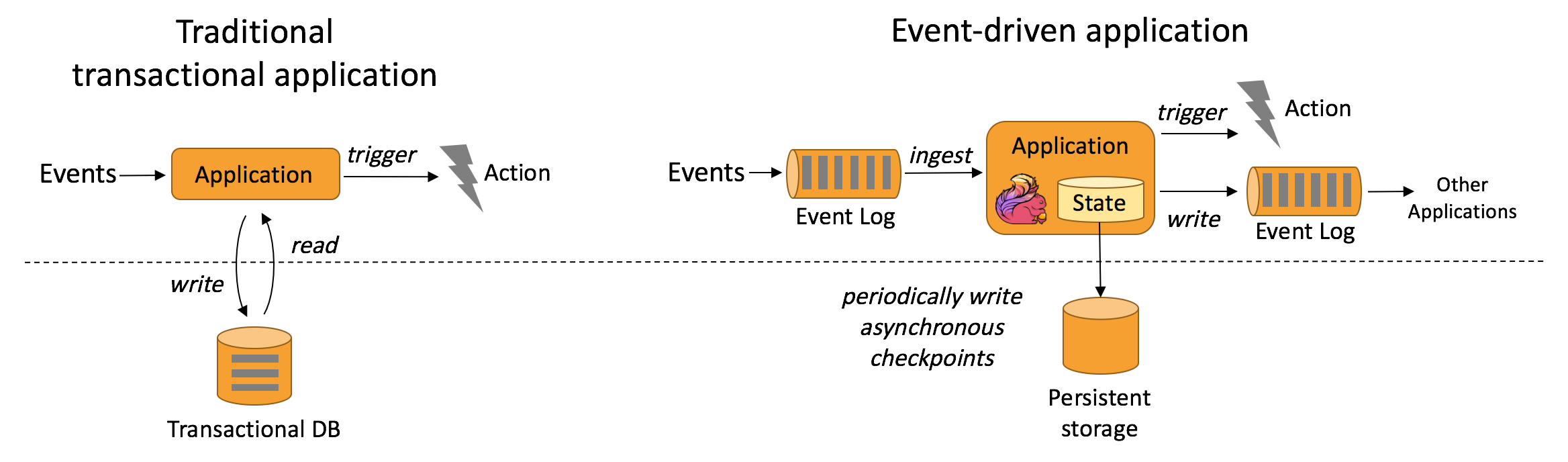
Moreover, a second PoC I was considering is related to Flink CEP. Let's say I am elaborating sensor data, I want to have a rule which is working on the following principle: - If the temperature is more than 40 - If the temperature yesterday at noon was more than 40 - If no one used vents yesterday and two days ago then do something/emit some event. This simple CEP example requires you to mine previous data/states from a DB, right? Can Flink be considered for it without an external DB but only relying on its internal RockDB ? Hope I am not generating more confusion here. Y On Thu, Jul 5, 2018 at 11:21 AM, Fabian Hueske <fhue...@gmail.com> wrote: > Hi Yersinia, > > The main idea of an event-driven application is to hold the state (i.e., > the account data) in the streaming application and not in an external > database like Couchbase. > This design is very scalable (state is partitioned) and avoids look-ups > from the external database because all state interactions are local. > Basically, you are moving the database into the streaming application. > > There are a few things to consider if you maintain the state in the > application: > - You might need to mirror the state in an external database to make it > queryable and available while the streaming application is down. > - You need to have a good design to ensure that your consistency > requirements are met in case of a failure (upsert writes can temporarily > reset the external state). > - The design becomes much more challenging if you need to access the state > of two accounts to perform a transaction (subtract from the first and add > to the second account) because Flink state is distributed per key and does > not support remote lookups. > > If you do not want to store the state in the Flink application, I agree > with Jörn that there's no need for Flink. > > Hope this helps, > Fabian > > 2018-07-05 10:45 GMT+02:00 Yersinia Ruckeri <yersiniaruck...@gmail.com>: > >> My idea started from here: https://flink.apache.org/usecases.html >> First use case describes what I am trying to realise ( >> https://flink.apache.org/img/usecases-eventdrivenapps.png) >> My application is Flink, listening to incoming events, changing the state >> of an object (really an aggregate here) and pushing out another event. >> States can be persisted asynchronously; this is ok. >> >> My point on top to this picture is that the "state" it's not just >> persisting something, but retrieving the current state, manipulate it new >> information and persist the updated state. >> >> >> Y >> >> On Wed, Jul 4, 2018 at 10:16 PM, Mich Talebzadeh < >> mich.talebza...@gmail.com> wrote: >> >>> Looks interesting. >>> >>> As I understand you have a microservice based on ingestion where a topic >>> is defined for streaming messages that include transactional data. These >>> transactions should already exist in your DB. For now we look at DB as part >>> of your microservices and we take a logical view of it. >>> >>> So >>> >>> >>> 1. First microservice M1 provides ingestion of kafka yopic >>> 2. Second microservice M2 deploys Flink or Spark Streaming to >>> manipulate the incoming messages. We can look at this later. >>> 3. Third microservice M3 consist of the database that provides >>> current records for accounts identified by the account number in your >>> message queue >>> 4. M3 will have to validate the incoming account number, update the >>> transaction and provide completion handshake. Effectively you are >>> providing >>> DPaaS >>> >>> >>> So far we have avoided interfaces among these services. But I gather M1 >>> and M2 are well established. Assuming that Couchbase is your choice of DB I >>> believe it provides JDBC drivers of some sort. It does not have to be >>> Couchbase. You can achieve the same with Hbase as well or MongoDB. Anyhow >>> the only challenge I see here is the interface between your Flink >>> application in M2 and M3 >>> >>> HTH >>> >>> Dr Mich Talebzadeh >>> >>> >>> >>> LinkedIn * >>> https://www.linkedin.com/profile/view?id=AAEAAAAWh2gBxianrbJd6zP6AcPCCdOABUrV8Pw >>> <https://www.linkedin.com/profile/view?id=AAEAAAAWh2gBxianrbJd6zP6AcPCCdOABUrV8Pw>* >>> >>> >>> >>> http://talebzadehmich.wordpress.com >>> >>> >>> *Disclaimer:* Use it at your own risk. Any and all responsibility for >>> any loss, damage or destruction of data or any other property which may >>> arise from relying on this email's technical content is explicitly >>> disclaimed. The author will in no case be liable for any monetary damages >>> arising from such loss, damage or destruction. >>> >>> >>> >>> >>> On Wed, 4 Jul 2018 at 17:56, Yersinia Ruckeri <yersiniaruck...@gmail.com> >>> wrote: >>> >>>> Hi all, >>>> >>>> I am working on a prototype which should include Flink in a reactive >>>> systems software. The easiest use-case with a traditional bank system where >>>> I have one microservice for transactions and another one for >>>> account/balances. >>>> Both are connected with Kafka. >>>> >>>> Transactions record a transaction and then send, via Kafka, a message >>>> which include account identifer and the amount. >>>> On the other microservice I want to have Flink consuming this topic and >>>> updating the balance of my account based on the incoming message. it needs >>>> to pull from the DB my data and make the update. >>>> The DB is Couchbase. >>>> >>>> I spent few hours online today, but so far I only found there's no sink >>>> for Couchbase, I need to build one which shouldn't be a big deal. I haven't >>>> found information on how I can make Flink able to interact with a DB to >>>> retrieve information and store information. >>>> >>>> I guess the case is a good case, as updating state in an event sourcing >>>> based application is part of the first page of the manual. I am not looking >>>> to just dump a state into a DB, but to interact with the DB: retrieving >>>> data, elaborating them with the input coming from my queue, and persisting >>>> them (especially if I want to make a second prototype using Flink CEP). >>>> >>>> I probably even read how to do it, but I didn't recognize. >>>> >>>> Can anybody help me to figure out better this part? >>>> >>>> Thanks, >>>> Y. >>>> >>> >> >
{kind=link}