Also, any contributions to the project via your thesis work would be welcome.
Please do first open a jira and provide a design overview before submitting
code.
From: Bikas Saha [mailto:[email protected]]
Sent: Monday, October 27, 2014 9:47 AM
To: [email protected]
Subject: RE: Questions about Tez under the hood
Answers inline.
From: Fabio C. [mailto:[email protected]]
Sent: Monday, October 27, 2014 7:08 AM
To: [email protected]
Subject: Questions about Tez under the hood
Hi guys, I'm currently working at my master degree thesis on Tez, and I am trying to understand how Tez works under the hood. I have some questions, I hope someone can help with this:
1) How does Tez handle containers for reuse? Are they kept for some seconds
(how long?) in a sort of buffer waiting for tasks which will need them? Or a
container is sent back to the RM if no task is immediately ready to take it?
[Bikas] Yes they wait around for a buffer period of time. Idle containers are
released back the RM randomly between a mix and a max release time until a
minimum held container threshold is met. So the behavior can be customized
using the min/max timeouts and the min held threshold.
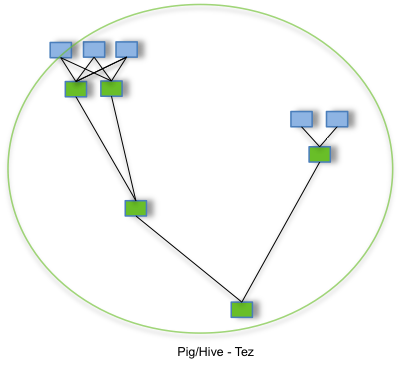
2) Let's say I have a DAG with two branches proceeding in parallel before joining in a
root node (such as the example on the tez home
pagehttp://tez.apache.org/images/PigHiveQueryOnTez.png ). In this case, we will have both
branches running at the same time. At some point we may have the first branch that is
almost complete, while the second is still at an early stage. In this case, does Tez
knows that "soon or later" the two branches will merge, thus there will be a
common consumer waiting for the slower branch to complete? Actually the real question is:
does Tez prioritize the scheduling/resource allocation of tasks belonging to slower
branches? If yes, what kind of policy is adopted? Is it configurable?
[Bikas] Currently the priority of a vertex is the distance from the source of
the DAG. So vertices can run in parallel. On the roadmap are items like
critical path scheduling where the vertex that is holding up the job the most
or that’s going to unblock the most amount of downstream work to be given
higher priority.
3) tez.am.shuffle-vertex-manager.min-src-fraction: if I have a dag made of two
producer vertexes, each one running 10 tasks, and below them a consumer vertex,
let's say running 5 tasks, so if this property is set to 0.2, does it mean that
before running any consumer task we need 2 producer tasks to complete for each
of the producer vertexes? Or are they considered as a whole and we need just 4
tasks completed (even just from one vertex)?
[Bikas] It currently looks at the fraction of the whole (both combined) but we
are going to change it to look at the fraction per source vertex. Again, this
is just a hint. (With auto-parallelism on) the vertex also looks at whether
enough data has been produced before triggering the tasks because the real
intention is to have enough data available for the reduce to pull so that it
can overlap the pull with the completion of the map tasks.
4) As far as I understand, a single Tez Application Master can handle multiple
DAGs at the same time, but only if the user-application has been coded to do so
(for example, if I run two wordcount with the same user, it simply creates two
different Tez App Master). Is this correct?
[Bikas] If the TezClient is started in session mode then it re-uses the App
Master for multiple DAGs. The code is the same in session and non-session mode.
The behavior can be changed via configuration (or hard coded in the code if
desired). So you can use both modes with the same code. To be clear, the
AppMaster does not run dags concurrently. It runs one DAG at a time.
Thanks in advance
Fabio
CONFIDENTIALITY NOTICE
NOTICE: This message is intended for the use of the individual or entity to
which it is addressed and may contain information that is confidential,
privileged and exempt from disclosure under applicable law. If the reader of
this message is not the intended recipient, you are hereby notified that any
printing, copying, dissemination, distribution, disclosure or forwarding of
this communication is strictly prohibited. If you have received this
communication in error, please contact the sender immediately and delete it
from your system. Thank You.
{kind=link}