Hello Bill, no real answer, but at least some pointers maybe. There is an older email thread in which Jim Healy looked into the best setup for Stampede2:
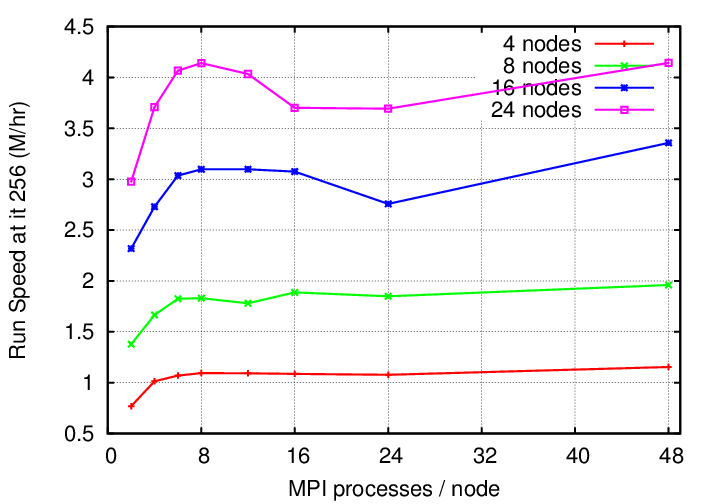
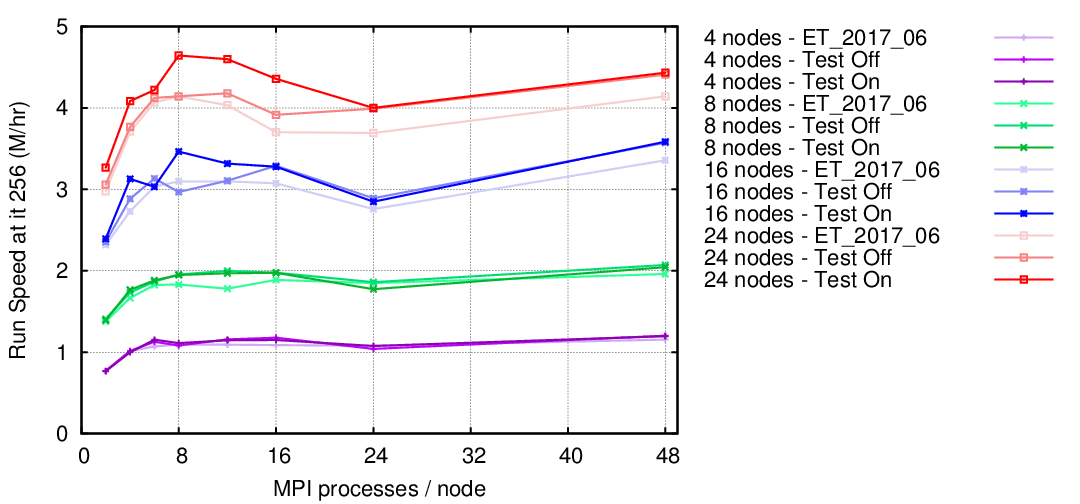
http://lists.einsteintoolkit.org/pipermail/users/2018-January/006007.html where Jim included a nice plot (linked on that page as a "binary attachment") showing speed vs. number of MPI ranks (and thus inverse number of CPUs per task): http://lists.einsteintoolkit.org/pipermail/users/attachments/20180120/e87cdc37/attachment-0001.png He then also tried some of the task-based parallelism that was being explored at that time (they may be in the toolkit by now, but not enabled since they were quite memory hungry), eg: http://lists.einsteintoolkit.org/pipermail/users/2018-January/006032.html with a plot: http://lists.einsteintoolkit.org/pipermail/users/attachments/20180126/681dcd3a/attachment-0001.png showing significant speedup when using the task-based code when using 24 nodes but none when using only 4 nodes. So basically: if you can get away with it, then usually 1 CPU per MPI tasks is fastest, but once you use many nodes you tend to end up in a situation where a handful of MPI ranks per node is often best (~8 or so I'd say for the unmodified ET code on Stampede2 SKX). Though in order to really see that effect you need to use hundreds of nodes. Yours, Roland > Okay just a little advice from the community, running a qc0 BBH merger > example on our HPC at Vanderbilt and trying to tune my parameters. WE > use Slurm / SBATCH and the ones I am working with are: > > o amount of memory per node > > o number of nodes > > o numpy of MPI tasks > > o if more than one cpu per task helps > > One example was 4 GB per node, 4 nodes, 4 MPI tasks, and 2 CPUs per > task. Was a little slower than 1 CPU per task---perhaps memory. I have > learned from you all that ETK is a memory hog more than a CPU hog, ur, > to say lots of memory helps vs lots of cores. > > Any examples you have of simple, vanilla BBH would be good. My SBATCH > script includes > > #SBATCH --mem 4000 # amount of memory per node > #SBATCH --nodes=4 # Like -24, number of nodes on which to run > #SBATCH -n 4 # Total number of mpi tasks requested, def 1 > task/1 cpu > #SBATCH -c 2 # Number of cpus per mpi task > #SBATCH -t 1:00:00 # Run time (d-hh:mm:ss) > > and was told to use srun and not mpirun -np XXXX, > > > myparFile="qc0-mclachlan.par" > myCactusExe="/labs/einstein/20191028/Cactus/exe/cactus_sim" > > ##echo "mpirun -np 4 $myCactusExe $myparFile" > ##mpirun -np 4 $myCactusExe $myparFile > echo "srun $myCactusExe $myparFile" > srun $myCactusExe $myparFile > > Eventually I want to get Simfactory running and see several HPC's that > use Slurm in the machine database directory. Still I think I need to > understand these parameters to tune the scripts Simfactory uses. > > thanks, bill e.g. > -- My email is as private as my paper mail. I therefore support encrypting and signing email messages. Get my PGP key from http://pgp.mit.edu .
{kind=link}
{kind=link}
![]() pgpPZ_qHrISX9.pgp
pgpPZ_qHrISX9.pgp
Description: OpenPGP digital signature
_______________________________________________ Users mailing list [email protected] http://lists.einsteintoolkit.org/mailman/listinfo/users