Your config indicates some RDFS reasoner, but apparently transitivity as
well as inverse relations both a re part of OWL semantics only (also
indicarted by the owl: prefix of course). And OWL is way more expressive
than RDFS, and inference way more expensive of course.
Thus, you should use an appropriate OWL reasoner, see the coverage of
the existing reasoner profiles:
https://jena.apache.org/documentation/inference/#OWLcoverage
On 08.02.23 17:45, Yang-Min KIM wrote:
Dear Jena community,
As a beginner in Jena (and I do not code in Java), I would like to ask
you a question about ontology integration.
- Data: small test data and corresponding OWL ontology
- Method: put data into GraphDB and Jena servers then run SPARQL query
- Expected result: initial missing information is complemented by
ontology transitivity
I will describe you step by step, the questions will come at the end
of the mail.
///////////////////////////// Report: what I did
/////////////////////////////
1. Test data: pizza!
1.1. Pizza ontology
As example, we use Pizza ontology provided by "OWL Example with RDF
Graph"
<https://www.obitko.com/tutorials/ontologies-semantic-web/owl-example-with-rdf-graph.html>
<https://i.postimg.cc/ZRjJy7XQ/Capture-d-cran-du-2023-02-08-15-07-19.png>
We focus on the inverse relationships: `:isIngredientOf owl:inverseOf
:hasIngredient .` i.e. the property `isIngredientOf` is the inverse of
the property `hasIngredient`.
-------------------------------------------
:isIngredientOf
a owl:TransitiveProperty , owl:ObjectProperty ;
owl:inverseOf :hasIngredient .
-------------------------------------------
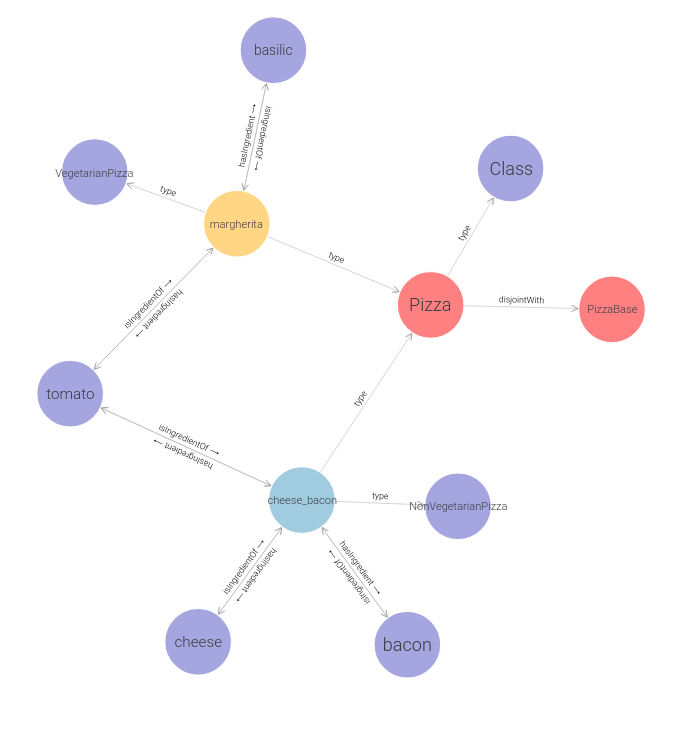
1.2. Pizza data
Two pizza `Margherita` and `Cheese Bacon`: the relationship between a
pizza and an ingredient is declared by the property either
`isIngredientOf` or `hasIngredient`. In summary:
- Margherita contains tomato and basilic
- Cheese Bacon contains cheese, bacon, and tomato
-------------------------------------------
@prefix ex: <<http://example.com/>> .
@prefix pizza: <<http://example.com/pizzas.owl#>> .
@prefix rdf: <<http://www.w3.org/1999/02/22-rdf-syntax-ns#>> .
# Margherita
ex:margherita rdf:type pizza:Pizza .
ex:margherita rdf:type pizza:VegetarianPizza .
ex:tomato pizza:isIngredientOf ex:margherita .
ex:margherita pizza:hasIngredient ex:basilic .
# Cheese Bacon
ex:cheese_bacon rdf:type pizza:Pizza .
ex:cheese_bacon rdf:type pizza:NonVegetarianPizza .
ex:cheese pizza:isIngredientOf ex:cheese_bacon .
ex:cheese_bacon pizza:hasIngredient ex:bacon .
ex:cheese_bacon pizza:hasIngredient ex:tomato .
-------------------------------------------
2. GraphDB
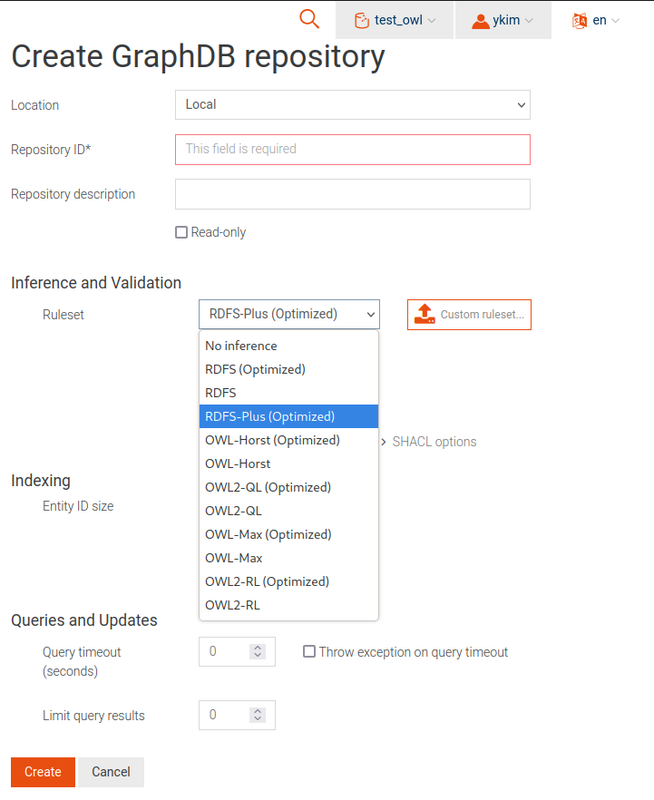
2.1. Dataset (repository) creation:
<https://i.postimg.cc/k5QJ7Xsq/Capture-d-cran-du-2023-02-08-15-09-15.png>
As shown in the image, the `RDFS-Plus (Optimized)` are set up by
default when creating a repository (dataset in Jena term).
2.2. Upload test data
Both test data and ontology are uploaded in a same repository (as
default or named graphes, results are unchanged).
<https://i.postimg.cc/qq501tJX/Capture-d-cran-du-2023-02-08-15-06-01.png>
We can see reciprocal relationships between pizza and ingredients
(`hasIngredient` and `isIngredientOf`).
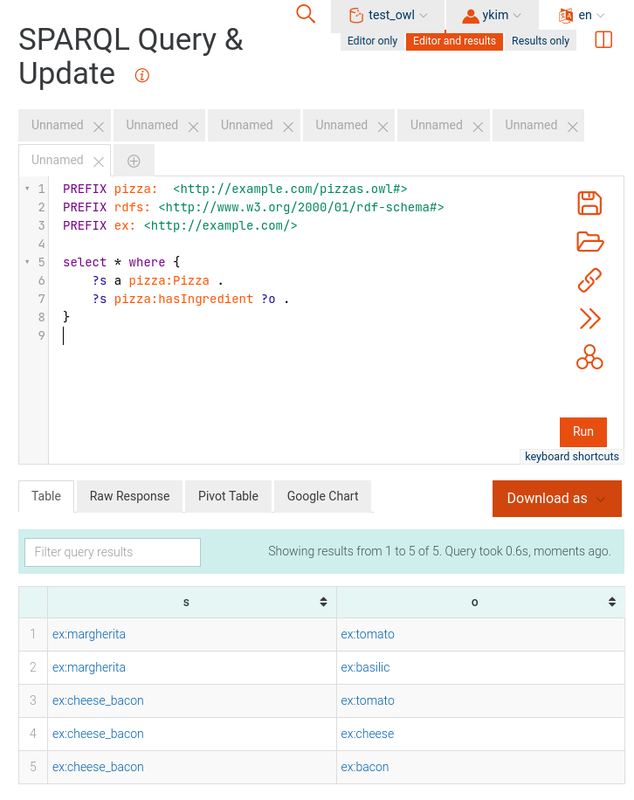
2.3. SPARQL query
<https://i.postimg.cc/KcqZGWPk/Capture-d-cran-du-2023-02-08-15-05-47.png>
Got expected results: all ingredients are presents i.e. initial
missing information is complemented: `ex:tomato pizza:isIngredientOf
ex:margherita` is equivalent to `ex:margherita pizza:hasIngredient
ex:tomato`
3. Jena
3.1. Dataset creation
Fuseki UI does not allow to set default reasoner as seen in 2.1.
It would be awesome if we could specify at this step!
3.2. Upload test data
Each data is uploaded on TDB as default graph into:
- A same dataset
- Separated dataset
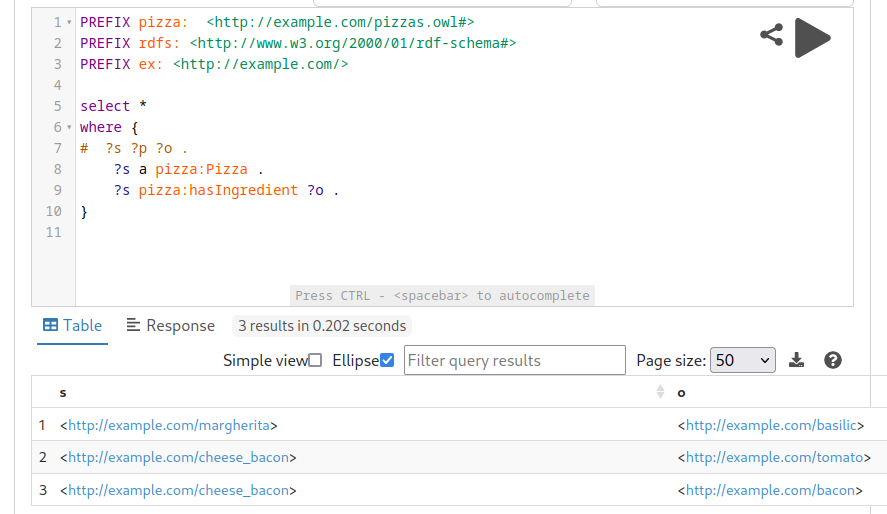
3.3. SPARQL query
<https://i.postimg.cc/Fz0cXJzm/Capture-d-cran-du-2023-02-08-15-38-30.png>
Misisng relationships are still missing, e.g. tomato is missing as
Margherita's ingredient.
3.4. Set inference model via config
According to your previous suggestions (thank you Dave and Lorenz!), I
have tried to follow the configuration steps mentioned in Fuseki's
configuration documentation.
<https://jena.apache.org/documentation/fuseki2/fuseki-configuration.html>
-> section "Inference"
I uploaded ontology file into a separated TDB dataset named
"test_ontology_pizza".
Then I modified Fuseki's `config.ttl` by adding the part after ##
----------- as below.
The results are the same as the previous ones despite restarting the
server.
-------------------------------------------
# Licensed under the terms of
<http://www.apache.org/licenses/LICENSE-2.0>
## Fuseki Server configuration file.
@prefix : <#> .
@prefix fuseki: <<http://jena.apache.org/fuseki#>> .
@prefix rdf: <<http://www.w3.org/1999/02/22-rdf-syntax-ns#>> .
@prefix rdfs: <<http://www.w3.org/2000/01/rdf-schema#>> .
@prefix ja: <<http://jena.hpl.hp.com/2005/11/Assembler#>> .
@prefix tdb2: <<http://jena.apache.org/2016/tdb#>> .
[] rdf:type fuseki:Server ;
# Example::
# Server-wide query timeout.
#
# Timeout - server-wide default: milliseconds.
# Format 1: "1000" -- 1 second timeout
# Format 2: "10000,60000" -- 10s timeout to first result,
# then 60s timeout for the rest of query.
#
# See javadoc for ARQ.queryTimeout for details.
# This can also be set on a per dataset basis in the dataset assembler.
#
# ja:context [ ja:cxtName "arq:queryTimeout" ; ja:cxtValue "30000" ] ;
# Add any custom classes you want to load.
# Must have a "public static void init()" method.
# ja:loadClass "your.code.Class" ;
# End triples.
.
## --------------------------- Added ------------------------------------
# Dataset with only the default graph.
:dataset rdf:type ja:RDFDataset ;
ja:defaultGraph :model_inf ;
.
# The inference model, data is taken from TDB
:model_inf a ja:InfModel ;
ja:baseModel :tdbGraph ;
ja:reasoner [
ja:reasonerURL
<<http://jena.hpl.hp.com/2003/RDFSExptRuleReasoner>>
] .
:tdbGraph rdf:type tdb2:GraphTDB2 ;
tdb2:dataset :tdbDataset .
## Base data in TDB.
:tdbDataset rdf:type tdb2:DatasetTDB2 ;
tdb2:location
"/opt/tomcat/fuseki/base/databases/test_ontology_pizza" ;
# If the unionDefaultGraph is used, then the "update" service
should be removed.
# tdb:unionDefaultGraph true ;
.
-------------------------------------------
///////////////////////////// Questions /////////////////////////////
Q1. Where and how should the data (pizza test data and pizza ontology)
be stored? Separated dataset? As default graph?
Q2. Is it better to configure at the global server level (congif.ttl)
or dataset level (dataset_name.ttl) ?
Q3. Should we restart tomcat or redeploy war each time we update gobal
config or per dataset config ?
Q4. I'm pretty sure there are errors in my configuration..., but where?
Q5. Side question. Is it possible to trigger from command line one of
those predefined rule engine () on a given dataset ?
Thank you for reading my long story and for your insights!
Best Regards,
Min
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}