Hi All, we are testing performance of our kafka 0.8 release cluster:
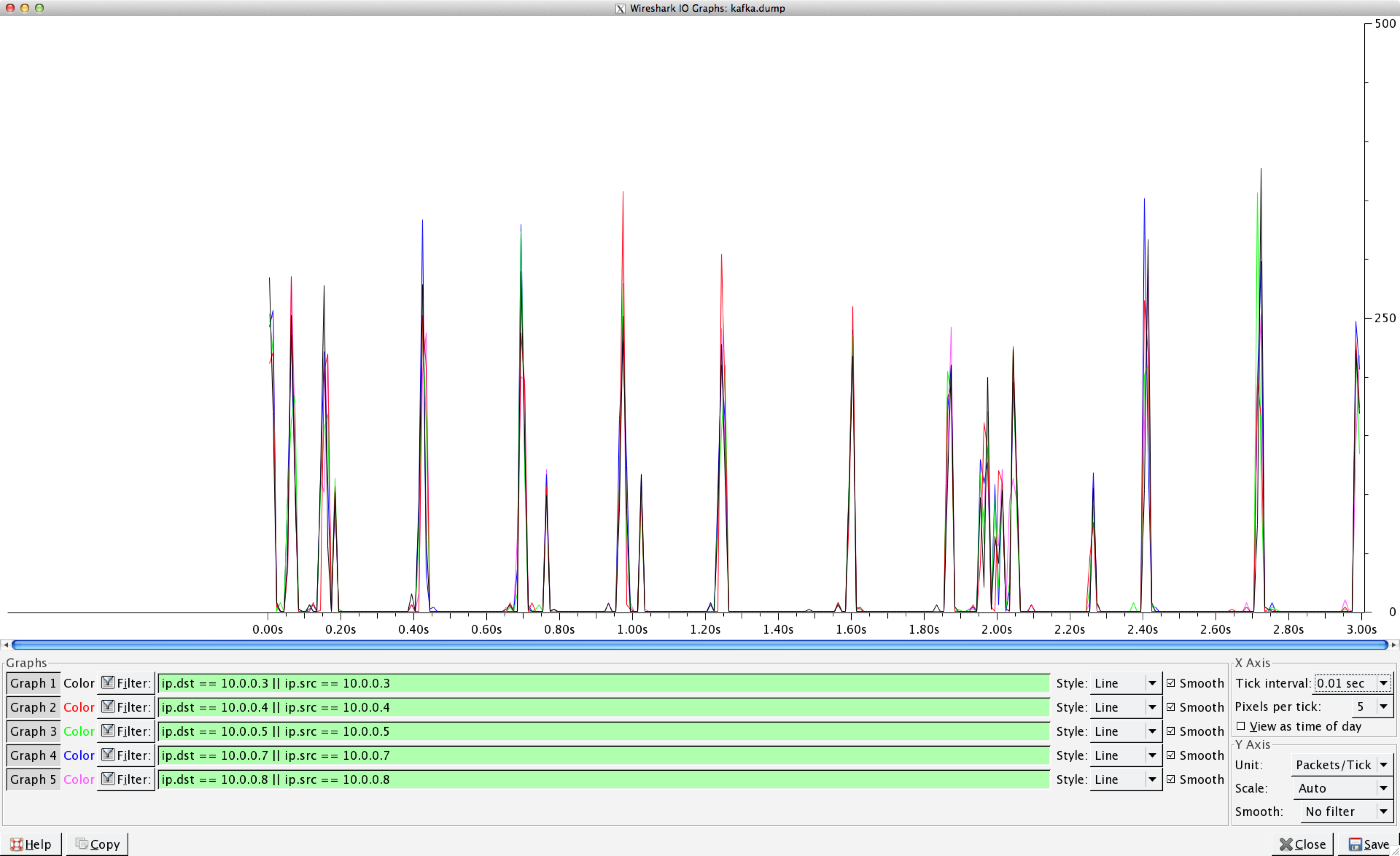
- 5 kafka nodes with one zookeeper instance on each machine - FreeBSD 9.2 - Nagle off (sysctl net.inet.tcp.delayed_ack=0) - all kafka machines write a ZFS ZIL to a dedicated SSD - 8 producers on 2 machines, writing to 30 topics, partitioning 5, replication factor 2, Ack -1 (both replicas) - batch size 2000, snappy compression, each message 550 bytes uncompressed - Gigabit Ethernet, all machines on one switch, ping 0.05 ms worst case. We send 10 million messages and get ~80k messages/s on average. Interestingly, the response time is usually between 8 and 15ms but some times goes up to >200ms on all nodes at the same time. We looked at CPU, network I/O, disk I/O, network latency and disk latency on all machines but all these parameter seem ok. So we don't seem to exhaust any resources here. Load average on producers and brokers is well below it's limits. It seems as if replication has problems keeping up since with Ack 1 (leader) we see double the rate (168k messages/s, constant request times). Any ideas on how to improve this situation or on what hinders better performance? Best regards, Florian Odronitz http://smyck.org/kafka_traffic.png shows a network traffic graph from a producer, showing traffic to and from brokers in different colors. Attached: kafka server.properties # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # see kafka.server.KafkaConfig for additional details and defaults ############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker. broker.id=4 ############################# Socket Server Settings ############################# # The port the socket server listens on port=9092 # Hostname the broker will bind to and advertise to producers and consumers. # If not set, the server will bind to all interfaces and advertise the value returned from # from java.net.InetAddress.getCanonicalHostName(). host.name=test-kafka-four.local # The number of threads handling network requests num.network.threads=8 # The number of threads doing disk I/O num.io.threads=8 # The send buffer (SO_SNDBUF) used by the socket server socket.send.buffer.bytes=1048576 # The receive buffer (SO_RCVBUF) used by the socket server socket.receive.buffer.bytes=1048576 # The maximum size of a request that the socket server will accept (protection against OOM) socket.request.max.bytes=104857600 ############################# Log Basics ############################# # The directory under which to store log files log.dir=/kafka/data/kafka #log.dir=/mnt # The number of logical partitions per topic per server. More partitions allow greater parallelism # for consumption, but also mean more files. num.partitions=1 ############################# Log Flush Policy ############################# # The following configurations control the flush of data to disk. This is the most # important performance knob in kafka. # There are a few important trade-offs here: # 1. Durability: Unflushed data is at greater risk of loss in the event of a crash. # 2. Latency: Data is not made available to consumers until it is flushed (which adds latency). # 3. Throughput: The flush is generally the most expensive operation. # The settings below allow one to configure the flush policy to flush data after a period of time or # every N messages (or both). This can be done globally and overridden on a per-topic basis. # The number of messages to accept before forcing a flush of data to disk log.flush.interval.messages=10000 # The maximum amount of time a message can sit in a log before we force a flush log.flush.interval.ms=1000 # Per-topic overrides for log.flush.interval.ms #log.flush.intervals.ms.per.topic=topic1:1000, topic2:3000 ############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can # be set to delete segments after a period of time, or after a given size has accumulated. # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log. # The minimum age of a log file to be eligible for deletion log.retention.hours=168 # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining # segments don't drop below log.retention.bytes. #log.retention.bytes=1073741824 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=536870912 # The interval at which log segments are checked to see if they can be deleted according # to the retention policies log.cleanup.interval.mins=1 ############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=test-kafka-one.local:2181,test-kafka-two.local:2181,test-kafka-three.local:2181,test-kafka-four.local:2181,test-kafka-five.local:2181 # Timeout in ms for connecting to zookeeper zookeeper.connection.timeout.ms=1000000 # metrics reporter properties kafka.metrics.polling.interval.secs=5 kafka.metrics.reporters=kafka.metrics.KafkaCSVMetricsReporter kafka.csv.metrics.dir=/kafka/metrics/kafka # Disable csv reporting by default. kafka.csv.metrics.reporter.enabled=false # taken from http://kafka.apache.org/documentation.html#config # Replication configurations num.replica.fetchers=8 replica.fetch.max.bytes=1048576 replica.fetch.wait.max.ms=500 replica.high.watermark.checkpoint.interval.ms=5000 replica.socket.timeout.ms=30000 replica.socket.receive.buffer.bytes=65536 replica.lag.time.max.ms=10000 replica.lag.max.messages=4000 controller.socket.timeout.ms=30000 controller.message.queue.size=10 # Log configuration message.max.bytes=1000000 auto.create.topics.enable=true num.partitions=20 default.replication.factor=2 log.index.interval.bytes=4096 log.index.size.max.bytes=10485760 log.retention.hours=168 log.flush.interval.ms=10000 log.flush.interval.messages=20000 log.flush.scheduler.interval.ms=2000 log.roll.hours=168 log.cleanup.interval.mins=30 log.segment.bytes=1073741824 # ZK configuration zk.connection.timeout.ms=6000 zk.sync.time.ms=2000 # Socket server configuration num.io.threads=8 num.network.threads=8 socket.request.max.bytes=104857600 socket.receive.buffer.bytes=1048576 socket.send.buffer.bytes=1048576 queued.max.requests=16 fetch.purgatory.purge.interval.requests=100 producer.purgatory.purge.interval.requests=100
{kind=link}