Sure! A couple things pushed us in to the upgrade. Our machines were very small in terms of storage, we really wanted replication and we weren't really monitoring our current machines well since JMX was turned off (and without replication/leadership a restart was hard).
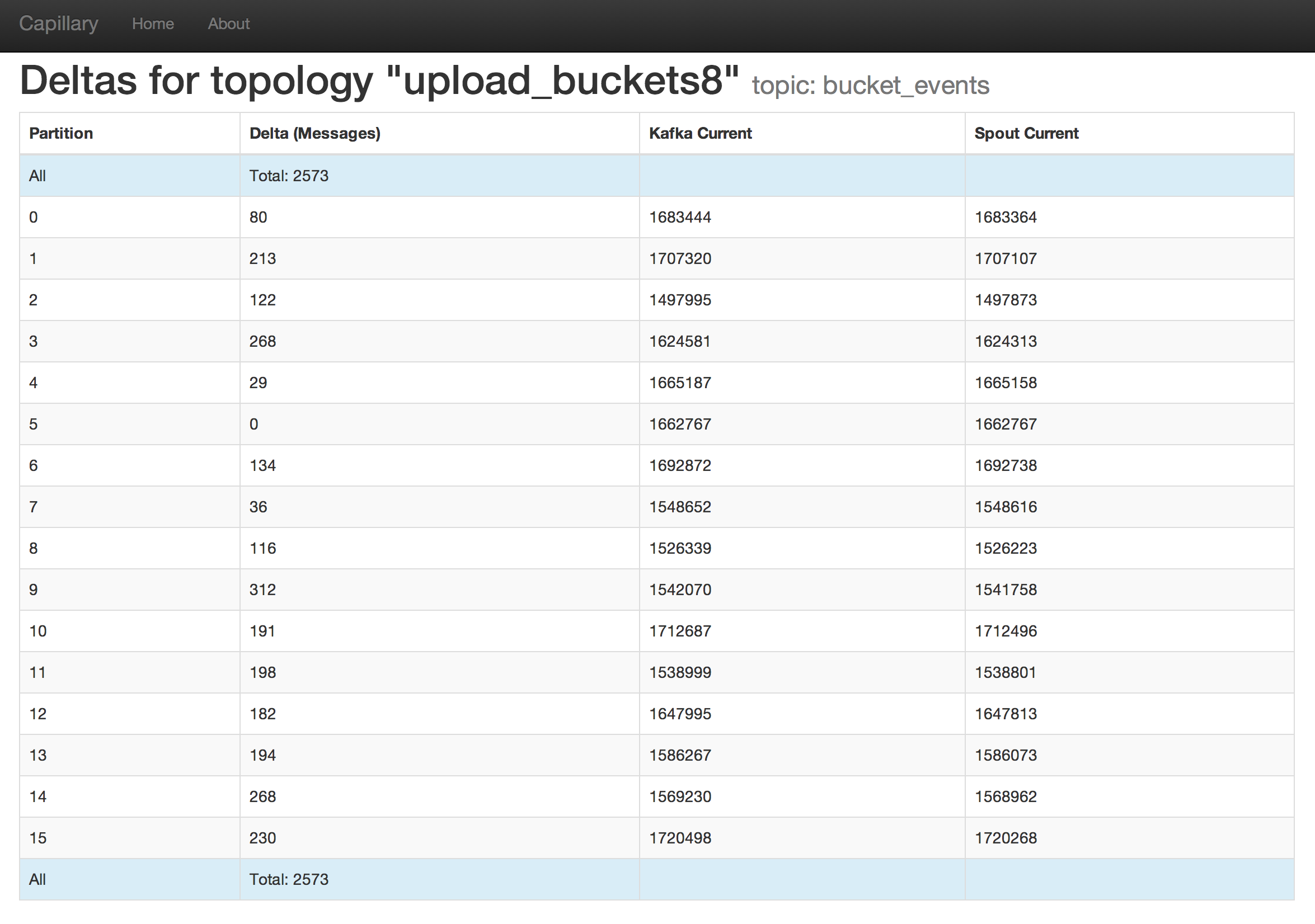
The first wrinkle was that Kafka 0.8 is basically a whole new system. Since the only real way to upgrade is to set up a new cluster things were obviously harder than install & reboot. :) - We had to read a lot of the Storm Spout code to understand how things work with leadership and replication. We've not yet updated Storm and had to use storm-kafka-0.8-plus <https://github.com/wurstmeister/storm-kafka-0.8-plus> since it's not in our dist. - It's really important that you test your producers and consumers with the failure of a leader. The spout seems to throw an uncaught exception and crash, but restarts. We at least know this is the behavior now and can watch for it and test newer versions of storm. - Replication was slower, but well worth it for us. We also had to switch from Python's samsa <https://pypi.python.org/pypi/samsa> to kafka-python <https://github.com/mumrah/kafka-python>. - It's important you grok the sync/async and cluster/local commit modes and make deliberate decisions and load test them in your environment. - Our use of samsa was async but I'm not sure anyone knew that. Our write times went from ~ 0.5ms to 35ms on average. - It's important to verify that your producers are making proper use of partitioning so that you don't end up with hot spots in partitions!! - We deployed with a few producers with a KeyedProducer but set no key. This causes it to pick two partitions only. :) - The information in this post <http://blog.liveramp.com/2013/04/08/kafka-0-8-producer-performance-2/> was very helpful. - The quoted bean names in JMX are really weird and the structure of the metrics is really a pain to fetch with JMX tools. Ugh. The actual process for us was to set up new Kafka 0.8 machines where we made good decisions about replication factors and partitioning. We wrote up a runbook of tasks to perform and it ended up being something like "tear everything down in this order and stand it back up in Kafka 0.8 after the old stuff drains." It went off without a hitch until the latency of writes cross-DC combined with an accidental code change in the producer. I accidentally started posting "batch" writes to our API individually instead of sending them in one write to Kafka. Once we fixed that things were effectively perfect. On Wed, Aug 20, 2014 at 10:17 AM, Philip O'Toole <philip.oto...@yahoo.com> wrote: > Any thoughts on upgrading from 0.7 to 0.8 you'd like to share with the > community? How did it go? How has it been? > > Philip > > ----------------------------------------- > http://www.philipotoole.com > > > On Wednesday, August 20, 2014 10:13 AM, Cory Watson <gp...@keen.io> > wrote: > > > :P Thanks Philip! > > > On Wed, Aug 20, 2014 at 10:04 AM, Philip O'Toole < > philip.oto...@yahoo.com.invalid> wrote: > > Nice work. That tool I put together was getting a bit old. :-) > > > I updated the Kafka "ecosystem" page with details of both tools. > > https://cwiki.apache.org/confluence/display/KAFKA/Ecosystem > > Philip > > > > ----------------------------------------- > http://www.philipotoole.com > > > On Wednesday, August 20, 2014 9:32 AM, Cory Watson <gp...@keen.io> wrote: > > > > Hello all! > > If you use Storm and Kafka 0.8 together I may have an interesting project > for you. Recently at Keen IO <https://keen.io/> we upgraded from Kafka > 0.7 > to 0.8 and needed to replace the features of stormkafkamon > <https://github.com/otoolep/stormkafkamon> for monitoring spout offsets > since it only worked with Kafka 0.7. So we created Capillary > <https://github.com/keenlabs/capillary>! > > Given a bit of information > <https://github.com/keenlabs/capillary#configuration> about your Zookeeper > setup for Storm and Kafka, Capillary is a web application that > automatically discovers topologies running Kafka 0.8 spouts and lets you > click on them to see per-partition offsets > <https://raw.githubusercontent.com/keenlabs/capillary/master/shot.png>. > It's JVM based and shouldn't require anything but Java where you run it. We > decided this was a useful difference over the > install-on-each-host-with-virtualenv model used by stormkafkamon. > > In addition to the helpful UI there is an API that you might use for > collecting this information and sending it to your stats/observability > systems for historical or alerting purposes. There's even an example python > script > <https://github.com/keenlabs/capillary/blob/master/stats-to-datadog.py> we > use for reporting to Datadog <http://www.datadoghq.com/>. It's very > likely > we'll move this to a scheduled thread inside Capillary using metrics > <http://metrics.codahale.com/> and allow you to hook up your own reporter. > > I hope other uses of Kafka + Storm find this useful. Feel free to open an > issue if you have issues setting it up or configuring it, or drop PRs if > you have additional functionality. Thanks! > > (I'll be cross-posting this to the Storm list also!) > > -- > Cory Watson > Principal Infrastructure Engineer // Keen IO > > > > > -- > Cory Watson > Principal Infrastructure Engineer // Keen IO > > > -- Cory Watson Principal Infrastructure Engineer // Keen IO
{kind=link}