https://bugzilla.wikimedia.org/show_bug.cgi?id=39501
MZMcBride <b...@mzmcbride.com> changed:
What |Removed |Added
----------------------------------------------------------------------------
CC| |b...@mzmcbride.com,
| |legoktm.wikipe...@gmail.com
| |, matma....@gmail.com
--- Comment #9 from MZMcBride <b...@mzmcbride.com> ---
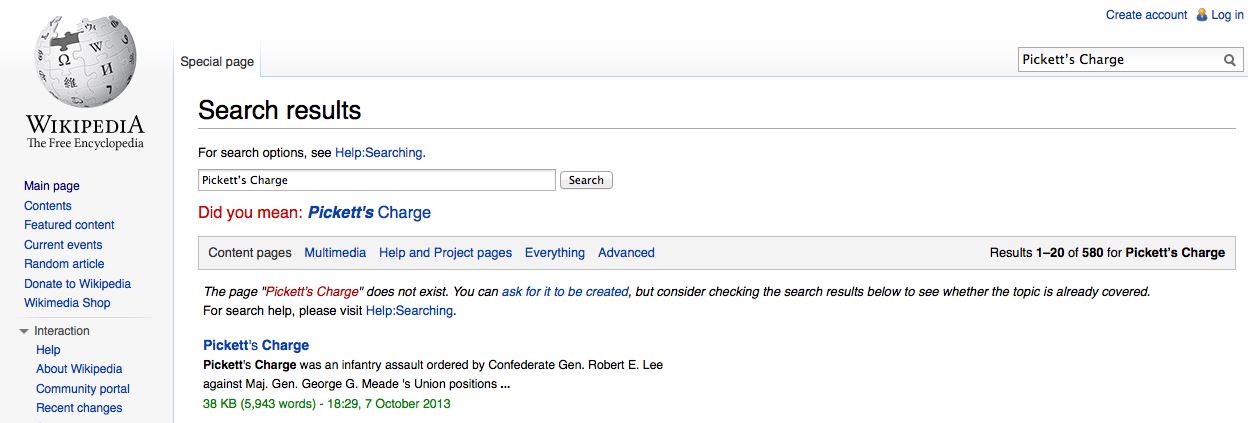
Looks like apostrophes came up on The Daily WTF:
<http://thedailywtf.com/Articles/Lightspeed-is-Too-Slow-for-MY-Luggage.aspx>
(specifically <http://img.thedailywtf.com/images/14/q1/e95/Pic-5.jpg>).
(In reply to comment #6)
> Were you thinking this should be done in Cirrus for all languages by pushing
> analysis configuration to Elasticsearch? Something along those lines would
> be pretty flexible, allowing, for example, us to boost perfect matches of the
> typed unicode characters above the squashed ones.
We already do some input normalization at some level of the stack (for example,
multiple underscores get squashed and input such as "AbrAhAm LincoLn" works if
there's a redirect at "Abraham lincoln").
It's difficult to look at the provided screenshot and not think that the
software has failed our readers. Unless you think these should be MediaWiki
page redirects (#REDIRECT)? I think we should do better normalization for
search inputs.
Any rough idea how big of a project this would be to implement?
--
You are receiving this mail because:
You are on the CC list for the bug.
You are the assignee for the bug.
_______________________________________________
Wikibugs-l mailing list
Wikibugs-l@lists.wikimedia.org
https://lists.wikimedia.org/mailman/listinfo/wikibugs-l
{kind=link}