Public bug reported: Hi community,
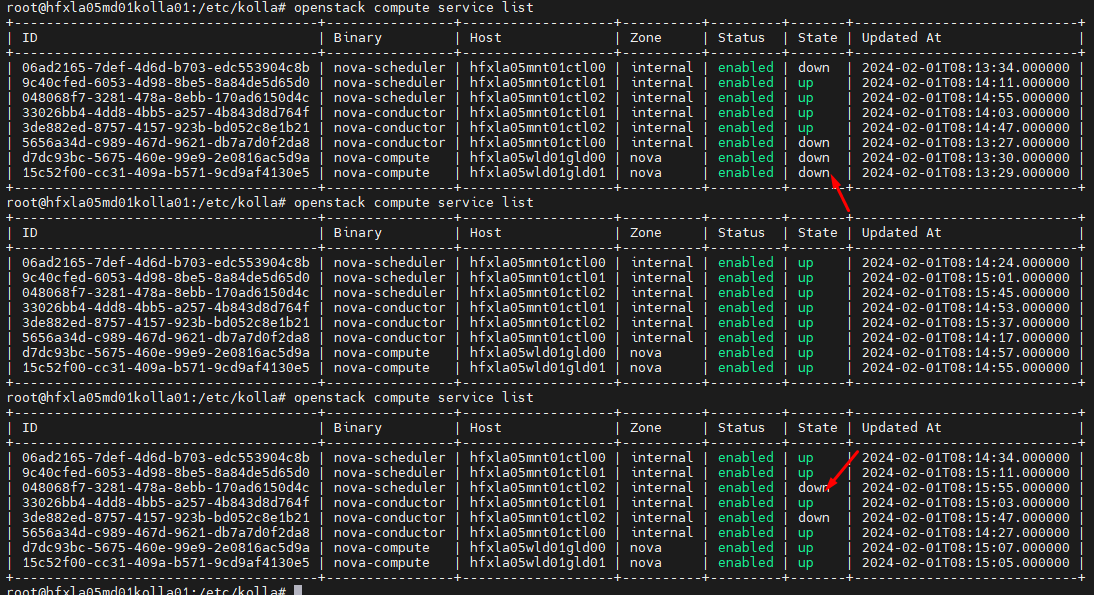
When you type: $ watch openstack nova compute service list You will see the status of components such as "nova-conductor", "nova- scheduler" and "nova-compute" continuously jump between "up" and "down", this is not normal and it has absolutely no end. This happens and a chain of functions are affected such as live-migrate, creating virtual machines,... while checking, the compute server still works. After some debugging I discovered that the current time "now" retrieved from the system is smaller than the past time "last_heartbeat"!!! And the mistake of not pointing this out in the source code cost me a lot of time to understand. In fact, as soon as the current time is received, there should be a comparison calculation with the last heartbeat. If it is small, we need to log the warning to easily configure time synchronization for the cluster. Around the abs(elapsed) line of code -> https://github.com/openstack/nova/blob/stable/2023.2/nova/servicegroup/drivers/db.py ... ... def is_up(self, service_ref): ... ... # Timestamps in DB are UTC. elapsed = timeutils.delta_seconds(last_heartbeat, timeutils.utcnow()) is_up = abs(elapsed) <= self.service_down_time if not is_up: LOG.debug('Seems service %(binary)s on host %(host)s is down. ' 'Last heartbeat was %(lhb)s. Elapsed time is %(el)s', {'binary': service_ref.get('binary'), 'host': service_ref.get('host'), 'lhb': str(last_heartbeat), 'el': str(elapsed)}) return is_up ... ... ** Affects: nova Importance: Undecided Status: New ** Attachment added: "Up/down continuously" https://bugs.launchpad.net/bugs/2052718/+attachment/5745271/+files/MicrosoftTeams-image.png -- You received this bug notification because you are a member of Yahoo! Engineering Team, which is subscribed to OpenStack Compute (nova). https://bugs.launchpad.net/bugs/2052718 Title: Nova Compute Service status goes up and down abnormally Status in OpenStack Compute (nova): New Bug description: Hi community, When you type: $ watch openstack nova compute service list You will see the status of components such as "nova-conductor", "nova- scheduler" and "nova-compute" continuously jump between "up" and "down", this is not normal and it has absolutely no end. This happens and a chain of functions are affected such as live-migrate, creating virtual machines,... while checking, the compute server still works. After some debugging I discovered that the current time "now" retrieved from the system is smaller than the past time "last_heartbeat"!!! And the mistake of not pointing this out in the source code cost me a lot of time to understand. In fact, as soon as the current time is received, there should be a comparison calculation with the last heartbeat. If it is small, we need to log the warning to easily configure time synchronization for the cluster. Around the abs(elapsed) line of code -> https://github.com/openstack/nova/blob/stable/2023.2/nova/servicegroup/drivers/db.py ... ... def is_up(self, service_ref): ... ... # Timestamps in DB are UTC. elapsed = timeutils.delta_seconds(last_heartbeat, timeutils.utcnow()) is_up = abs(elapsed) <= self.service_down_time if not is_up: LOG.debug('Seems service %(binary)s on host %(host)s is down. ' 'Last heartbeat was %(lhb)s. Elapsed time is %(el)s', {'binary': service_ref.get('binary'), 'host': service_ref.get('host'), 'lhb': str(last_heartbeat), 'el': str(elapsed)}) return is_up ... ... To manage notifications about this bug go to: https://bugs.launchpad.net/nova/+bug/2052718/+subscriptions -- Mailing list: https://launchpad.net/~yahoo-eng-team Post to : yahoo-eng-team@lists.launchpad.net Unsubscribe : https://launchpad.net/~yahoo-eng-team More help : https://help.launchpad.net/ListHelp
{kind=link}