YP AB Intermittent failures meeting
===================================
https://windriver.zoom.us/j/3696693975
Attendees: Richard, Trevor, Randy, Saul, AlexB
Summary:
========
--------------------------------------------------------------
People have been busy with other work so this is mostly a duplicate
of the previous minutes with some cyptic? IRC chat logs added below.
--------------------------------------------------------------
Ptest results continue to improve yet again but there's still room
for even more improvement.
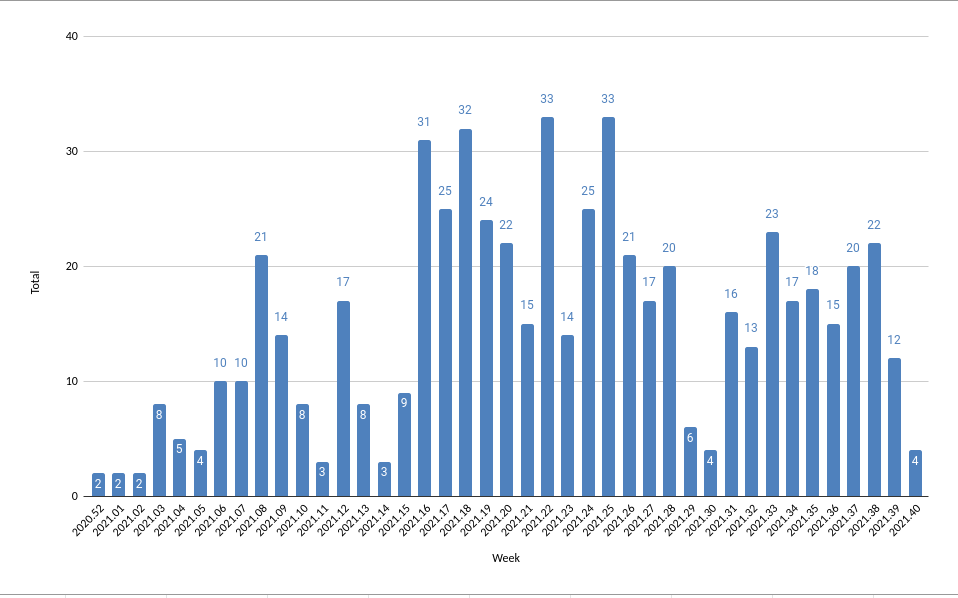
Alex made a graph of the number of AB INT issues per week:
https://bootlin.com/~alexandre/SWAT_stats.png
We assume that week 15, 16 was when the RCU bug in he kernel
started being a problem and week 29 was when it go fixed but
more careful analysis is required.
The make/ninja load average limit is in but it's not clear
if it's effective yet and it breaks dunfell.
Trevor has a build of dunfell that with some patches appears to work.
If anyone wants to help, we could use more eyes on the logs,
particularly the summary logs and understanding iostat #
when the dd test times out.
Plans for the week:
===================
Richard: M1
Alex: look into Rest API for BZ as part of Triage.
Sakib: hook more responsive load average in to latency test. (v3)
: Add PSI (/proc/pressure/*) when available
Trevor: No AB work
Saul: No AB work
Randy: PSI, simple experiments to learn what's 'normal',
make some PSI graphs!
Idea: bitbake/make/ninja use /proc/pressure to throttle builds?
../Randy
Meeting Notes:
==============
Cryptic notes this week since I don't have time for a proper summary!
[09:01] <vmeson> Agenda Items?
[09:01] <vmeson> 1. PSI /proc/pressure
see: https://www.kernel.org/doc/html/latest/accounting/psi.html
[09:01] <vmeson> 2. Status of AB
[09:02] <vmeson> 3. Randy promises valgrind patches (again!).
Discussion:
Randy explained what the PSI proc data was and
how overloaded ubuntu2004-ty-2.yocto.io was for most of a 25 hour
logging window. Typical high load data is:
pressure.cpu
some avg10=0.00 avg60=0.00 avg300=1.12 total=8891584119
some avg10=0.00 avg60=0.00 avg300=1.00 total=8891596517
some avg10=0.00 avg60=0.00 avg300=0.90 total=8891613258
some avg10=0.00 avg60=0.00 avg300=0.81 total=8891631326
pressure.memory
some avg10=0.00 avg60=0.00 avg300=0.00 total=237120503
full avg10=0.00 avg60=0.00 avg300=0.00 total=194500170
some avg10=0.00 avg60=0.00 avg300=0.00 total=237121370
full avg10=0.00 avg60=0.00 avg300=0.00 total=194500170
pressure.io
some avg10=65.22 avg60=56.24 avg300=40.82 total=142092410628
full avg10=65.22 avg60=56.23 avg300=40.28 total=134090291475
some avg10=48.50 avg60=52.56 avg300=41.42 total=142106526703
full avg10=48.50 avg60=52.56 avg300=40.93 total=134104406782
This is just:
for i in pressure.cpu pressure.memory pressure.io; do \
echo $i; tail -4 $i; \
done
There are two lines per call for some of the /proc/pressure files:
$ wc -l pressure*
3000 pressure.cpu
6000 pressure.io
6000 pressure.memory
Looking at the max io load for the times when the 'full' system
is overloaded:
$ grep full pressure.io | cat -n > pressure.io-full.numbered
$ sed -e 's/=/ /g' pressure.io-full.numbered | sort -k 4 -n | tail -2
1710 full avg10 97.52 avg60 93.85 avg300 92.29 total 124322928244
1699 full avg10 97.57 avg60 93.16 avg300 91.36 total 124015261496
# make a link so we have *full.numbered files for each subsystem:
$ ln -s pressure.cpu.numbered pressure.cpu-ful.numbered
$ for i in pressure.cpu pressure.memory pressure.io; do \
echo $i; egrep ' 1710| 1699' $i-full.numbered; \
done
pressure.cpu
1699 some avg10=0.00 avg60=0.00 avg300=0.00 total=7340981927
1710 some avg10=0.00 avg60=0.00 avg300=0.00 total=7341522636
pressure.memory
1699 full avg10=0.00 avg60=0.00 avg300=0.00 total=131800420
1710 full avg10=0.00 avg60=0.00 avg300=0.00 total=131800502
pressure.io
1699 full avg10=97.57 avg60=93.16 avg300=91.36 total=124015261496
1710 full avg10=97.52 avg60=93.85 avg300=92.29 total=124322928244
Conclusion, no cpu, memory contention, lots of IO -- clean-up or ???
[09:22] <vmeson> read-only YP BZ database query to find "AB-INT" build
failures, find build and highlight in "non-release" AB build summary.
[09:23] <vmeson> add /proc/pressure info to test results logs.
Sakib and I may do this, else Alex in January
[09:24] <vmeson> network access: weird AB bugs: DNS or connextion
failure, at times even qemu net connection fails!
[09:26] <vmeson> systemd-networkd at times monitors and maybe even
changes (if up/down?) tap interfaces
This seems to be hard-coded, mandatory behaviour in systemd managed
distros.
[09:26] <vmeson> Test system, start / stop qemu instances in a loop.
[09:29] <vmeson> say: 16 qemus booting core-image-minimal and doing a
simple test such as a network connection (download curl), along with
stress --mumble-args to load the host sytem to simulate a build.
[09:30] <abelloni> vmeson:
https://bugzilla.yoctoproject.org/show_bug.cgi?id=14467
[09:32] <vmeson> use rest API to query the bugzilla -- where's the API?
[09:33] <abelloni> https://wiki.mozilla.org/Bugzilla:REST_API
[09:33] <abelloni> I'll have a look at that
[09:37] <RP> "BzAPI is an alternate, deprecated REST API" - that will
be ours as we're not on bz5 yet
Notes from previous meeting which are largely still relevant.
1. job server
- ninja could be patched with make's more responsive algorithm
next or is this good enough?
Aug 26:
Randy made some graphs that show that the -l NUM results
in the number of compile jobs oscillates *wildly* between 0 and 200
on a 192 core builder compiling chromium. What I did was:
$ bitbake -c cleansstate chromium-x11
$ bitbake -c configure chromium-x11
$ bitbake -c compile chromium-x11
and while that compile was running:
$ while [ ! -f /tmp/compiling-chromium-is-done ]; do \
cat /proc/loadavg >> procs-load.log ; sleep 0.5 ;
done
Results so far:
https://postimg.cc/gallery/3hjfYfG/f8f46c97
Next step is either:
a. collect data as above for an image build and see if the sub-optimal
ninja behaviour makes a difference
and/or
b. patch ninja with make's more responsive load avg
algorithm:
https://git.savannah.gnu.org/cgit/make.git/commit/?id=d8728efc8
- Richard suggested that we extract make's code for measuring the load
average to a separate binary and run it in the periodic io latency
test. Also can we translate it to python?
- Trevor is working on this and had some problems so next week.
(Aug 19 - Trevor is back from vaction so maybe next week.)
- Trevor to see if the load average change really did reduce load
on WR build systems. (Aug 19)
2. AB status
Trevor is learning about buildbot and working on a scheduling bug
(CentOS worker?)
bitbake layer setup tool should allow multiple backends:
eg: kas, a y-a-helper.
ptest cases are improving, we may be close to done!
Let's wait a week to see how things go.
(July29, Aug 5, Aug 19, we're not done...)
- lttng-tools ptest is failing. RP is working on it with upstream.
The timeout (done on Aug 5) increase hasn't helped.
3. Sakib's improvements to the logging are merged.
Sakib generated a summary of all high latency 'top' logs from
~July 23->July 29 by just running his summary script on the
merged raw top logs.
More analysis required....
Still relevant parts of
Previous Meeting Notes:
=======================
4. bitbake server timeout ( no change july 29, Aug 19, Oct 7)
"Timeout while waiting for a reply from the bitbake server (60s)"
5. io stalls (no update: July 29, Oct 7)
Richard said that it would make sense to write an ftrace utility
/ script to monitor io latency and we could install it with sudo
Ch^W mentioned ftrace on IRC.
Sakib and Randy will work on that but not for a week or two
or longer! (Aug 19).
Randy collected iostat data on 3 build server:
https://postimg.cc/gallery/8cN6LYB
We agreed that having -ty-2 be ~ 100 utilization for many hours
in a row is not acceptable and that a threshold of ~ 10 minutes
at 100% utilization may be a reasonable limt. I need to figure out
if I can get data on the fraction of IO done per IO clas since
we do use ionice to do clean-up and other activities.
../Randy
-=-=-=-=-=-=-=-=-=-=-=-
Links: You receive all messages sent to this group.
View/Reply Online (#55540): https://lists.yoctoproject.org/g/yocto/message/55540
Mute This Topic: https://lists.yoctoproject.org/mt/87620057/21656
Group Owner: yocto+ow...@lists.yoctoproject.org
Unsubscribe: https://lists.yoctoproject.org/g/yocto/unsub
[arch...@mail-archive.com]
-=-=-=-=-=-=-=-=-=-=-=-
{kind=link}