[spark] branch master updated: [SPARK-43334][UI] Fix error while serializing ExecutorPeakMetricsDistributions into API response
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 5ec13854620 [SPARK-43334][UI] Fix error while serializing
ExecutorPeakMetricsDistributions into API response
5ec13854620 is described below
commit 5ec138546205ba4248cc9ec72c3b7baf60f2fede
Author: Thejdeep Gudivada
AuthorDate: Wed May 24 18:25:36 2023 -0500
[SPARK-43334][UI] Fix error while serializing
ExecutorPeakMetricsDistributions into API response
When we calculate the quantile information from the peak executor metrics
values for the distribution, there is a possibility of running into an
`ArrayIndexOutOfBounds` exception when the metric values are empty. This PR
addresses that and fixes it by returning an empty array if the values are empty.
### Why are the changes needed?
Without these changes, when the withDetails query parameter is used to
query the stages REST API, we encounter a partial JSON response since the peak
executor metrics distribution cannot be serialized due to the above index error.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added a unit test to test this behavior
Closes #41017 from thejdeep/SPARK-43334.
Authored-by: Thejdeep Gudivada
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/status/AppStatusStore.scala | 9 +
.../main/scala/org/apache/spark/status/AppStatusUtils.scala | 12
core/src/main/scala/org/apache/spark/status/api/v1/api.scala | 7 +++
.../scala/org/apache/spark/status/AppStatusUtilsSuite.scala | 11 +++
4 files changed, 27 insertions(+), 12 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/status/AppStatusStore.scala
b/core/src/main/scala/org/apache/spark/status/AppStatusStore.scala
index d02d4b2507a..eaa7b7b9873 100644
--- a/core/src/main/scala/org/apache/spark/status/AppStatusStore.scala
+++ b/core/src/main/scala/org/apache/spark/status/AppStatusStore.scala
@@ -27,6 +27,7 @@ import scala.collection.mutable.HashMap
import org.apache.spark.{JobExecutionStatus, SparkConf, SparkContext}
import org.apache.spark.internal.Logging
import org.apache.spark.internal.config.Status.LIVE_UI_LOCAL_STORE_DIR
+import org.apache.spark.status.AppStatusUtils.getQuantilesValue
import org.apache.spark.status.api.v1
import org.apache.spark.storage.FallbackStorage.FALLBACK_BLOCK_MANAGER_ID
import org.apache.spark.ui.scope._
@@ -770,14 +771,6 @@ private[spark] class AppStatusStore(
}
}
- def getQuantilesValue(
-values: IndexedSeq[Double],
-quantiles: Array[Double]): IndexedSeq[Double] = {
-val count = values.size
-val indices = quantiles.map { q => math.min((q * count).toLong, count - 1)
}
-indices.map(i => values(i.toInt)).toIndexedSeq
- }
-
def rdd(rddId: Int): v1.RDDStorageInfo = {
store.read(classOf[RDDStorageInfoWrapper], rddId).info
}
diff --git a/core/src/main/scala/org/apache/spark/status/AppStatusUtils.scala
b/core/src/main/scala/org/apache/spark/status/AppStatusUtils.scala
index 87f434daf48..04918ccbd57 100644
--- a/core/src/main/scala/org/apache/spark/status/AppStatusUtils.scala
+++ b/core/src/main/scala/org/apache/spark/status/AppStatusUtils.scala
@@ -72,4 +72,16 @@ private[spark] object AppStatusUtils {
-1
}
}
+
+ def getQuantilesValue(
+values: IndexedSeq[Double],
+quantiles: Array[Double]): IndexedSeq[Double] = {
+val count = values.size
+if (count > 0) {
+ val indices = quantiles.map { q => math.min((q * count).toLong, count -
1) }
+ indices.map(i => values(i.toInt)).toIndexedSeq
+} else {
+ IndexedSeq.fill(quantiles.length)(0.0)
+}
+ }
}
diff --git a/core/src/main/scala/org/apache/spark/status/api/v1/api.scala
b/core/src/main/scala/org/apache/spark/status/api/v1/api.scala
index e272cf04dc7..f436d16ca47 100644
--- a/core/src/main/scala/org/apache/spark/status/api/v1/api.scala
+++ b/core/src/main/scala/org/apache/spark/status/api/v1/api.scala
@@ -31,6 +31,7 @@ import org.apache.spark.JobExecutionStatus
import org.apache.spark.executor.ExecutorMetrics
import org.apache.spark.metrics.ExecutorMetricType
import org.apache.spark.resource.{ExecutorResourceRequest,
ResourceInformation, TaskResourceRequest}
+import org.apache.spark.status.AppStatusUtils.getQuantilesValue
case class ApplicationInfo private[spark](
id: String,
@@ -454,13 +455,11 @@ class ExecutorMetricsDistributions private[spark](
class ExecutorPeakMetricsDistributions private[spark](
val quantiles: IndexedSeq[Double],
val executorMetrics: IndexedSeq[ExecutorMetrics]) {
- private lazy val count = executorMetrics.length
- private lazy val indices = quantiles.map { q => math.min((q * count).toLong,
count - 1) }
/** Returns
[spark] branch master updated (1c6b5382051 -> f2b4ff2769b)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 1c6b5382051 [SPARK-43771][BUILD][CONNECT] Upgrade mima-core from 1.1.0 to 1.1.2 add f2b4ff2769b [SPARK-43573][BUILD] Make SparkBuilder could config the heap size of test JVM No new revisions were added by this update. Summary of changes: project/SparkBuild.scala | 6 -- 1 file changed, 4 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (afc508722e0 -> 5d03950b358)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from afc508722e0 [SPARK-43595][BUILD] Update some maven plugins to newest version add 5d03950b358 [SPARK-43534][BUILD] Add log4j-1.2-api and log4j-slf4j2-impl to classpath if active hadoop-provided No new revisions were added by this update. Summary of changes: pom.xml | 2 -- 1 file changed, 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-43595][BUILD] Update some maven plugins to newest version
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new afc508722e0 [SPARK-43595][BUILD] Update some maven plugins to newest
version
afc508722e0 is described below
commit afc508722e07cf8fceb24204f538e51c6192c3e4
Author: panbingkun
AuthorDate: Sat May 20 08:50:16 2023 -0500
[SPARK-43595][BUILD] Update some maven plugins to newest version
### What changes were proposed in this pull request?
The pr aims to update some maven plugins to newest version. include:
- exec-maven-plugin from 1.6.0 to 3.1.0
- scala-maven-plugin from 4.8.0 to 4.8.1
- maven-antrun-plugin from 1.8 to 3.1.0
- maven-enforcer-plugin from 3.2.1 to 3.3.0
- build-helper-maven-plugin from 3.3.0 to 3.4.0
- maven-surefire-plugin from 3.0.0 to 3.1.0
- maven-assembly-plugin from 3.1.0 to 3.6.0
- maven-install-plugin from 3.1.0 to 3.1.1
- maven-deploy-plugin from 3.1.0 to 3.1.1
- maven-checkstyle-plugin from 3.2.1 to 3.2.2
### Why are the changes needed?
Routine upgrade.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA.
Closes #41228 from panbingkun/maven_plugin_upgrade.
Authored-by: panbingkun
Signed-off-by: Sean Owen
---
pom.xml | 20 ++--
1 file changed, 10 insertions(+), 10 deletions(-)
diff --git a/pom.xml b/pom.xml
index dfc54b25705..1c4c4eb0fa6 100644
--- a/pom.xml
+++ b/pom.xml
@@ -115,7 +115,7 @@
${java.version}
${java.version}
3.8.8
-1.6.0
+3.1.0
spark
9.5
2.0.7
@@ -175,7 +175,7 @@
errors building different Hadoop versions.
See: SPARK-36547, SPARK-38394.
-->
-4.8.0
+4.8.1
false
2.15.0
@@ -210,7 +210,7 @@
4.7.2
4.7.2
2.67.0
-1.8
+3.1.0
1.1.0
1.5.0
1.60
@@ -2744,7 +2744,7 @@
org.apache.maven.plugins
maven-enforcer-plugin
- 3.2.1
+ 3.3.0
enforce-versions
@@ -2787,7 +2787,7 @@
org.codehaus.mojo
build-helper-maven-plugin
- 3.3.0
+ 3.4.0
module-timestamp-property
@@ -2907,7 +2907,7 @@
org.apache.maven.plugins
maven-surefire-plugin
- 3.0.0
+ 3.1.0
@@ -3118,7 +3118,7 @@
org.apache.maven.plugins
maven-assembly-plugin
- 3.1.0
+ 3.6.0
posix
@@ -3143,12 +3143,12 @@
org.apache.maven.plugins
maven-install-plugin
- 3.1.0
+ 3.1.1
org.apache.maven.plugins
maven-deploy-plugin
- 3.1.0
+ 3.1.1
org.apache.maven.plugins
@@ -3293,7 +3293,7 @@
org.apache.maven.plugins
maven-checkstyle-plugin
-3.2.1
+3.2.2
false
true
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (37b9c532d69 -> f55fdca10b1)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 37b9c532d69 [SPARK-43542][SS] Define a new error class and apply for the case where streaming query fails due to concurrent run of streaming query with same checkpoint add f55fdca10b1 [MINOR][INFRA] Deduplicate `scikit-learn` in Dockerfile No new revisions were added by this update. Summary of changes: dev/infra/Dockerfile | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-43537][INFA][BUILD] Upgrading the ASM dependencies used in the `tools` module to 9.4
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 9785353684b [SPARK-43537][INFA][BUILD] Upgrading the ASM dependencies used in the `tools` module to 9.4 9785353684b is described below commit 9785353684bdc2a2c7445b7e6b9ab85154f6933f Author: yangjie01 AuthorDate: Wed May 17 11:18:14 2023 -0500 [SPARK-43537][INFA][BUILD] Upgrading the ASM dependencies used in the `tools` module to 9.4 ### What changes were proposed in this pull request? This pr aims upgrade ASM related dependencies in the `tools` module from version 7.1 to version 9.4 to make `GenerateMIMAIgnore` can process Java 17+ compiled code. Additionally, this pr defines `asm.version` to manage versions of ASM. ### Why are the changes needed? The classpath processed by `GenerateMIMAIgnore` cannot contain Java 17+ compiled code now due to the ASM version use by `tools` module is too low, but https://github.com/bmc/classutil has not been updated for a long time, we can't solve the problem by upgrading `classutil`, so this pr make the `tools` module explicitly rely on ASM 9.4 for workaround. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GitHub Action - Manual checked `dev/mima` due to this pr upgrade the dependency of tools module ``` dev/mima ``` and ``` dev/change-scala-version.sh 2.13 dev/mima -Pscala-2.13 ``` - A case that can reproduce the problem: run following script with master branch: ``` set -o pipefail set -e FWDIR="$(cd "`dirname "$0"`"/..; pwd)" cd "$FWDIR" export SPARK_HOME=$FWDIR echo $SPARK_HOME if [[ -x "$JAVA_HOME/bin/java" ]]; then JAVA_CMD="$JAVA_HOME/bin/java" else JAVA_CMD=java fi TOOLS_CLASSPATH="$(build/sbt -DcopyDependencies=false "export tools/fullClasspath" | grep jar | tail -n1)" ASSEMBLY_CLASSPATH="$(build/sbt -DcopyDependencies=false "export assembly/fullClasspath" | grep jar | tail -n1)" rm -f .generated-mima* $JAVA_CMD \ -Xmx2g \ -XX:+IgnoreUnrecognizedVMOptions --add-opens=java.base/java.util.jar=ALL-UNNAMED \ -cp "$TOOLS_CLASSPATH:$ASSEMBLY_CLASSPATH" \ org.apache.spark.tools.GenerateMIMAIgnore rm -f .generated-mima* ``` **Before** ``` Exception in thread "main" java.lang.IllegalArgumentException: Unsupported class file major version 61 at org.objectweb.asm.ClassReader.(ClassReader.java:195) at org.objectweb.asm.ClassReader.(ClassReader.java:176) at org.objectweb.asm.ClassReader.(ClassReader.java:162) at org.objectweb.asm.ClassReader.(ClassReader.java:283) at org.clapper.classutil.asm.ClassFile$.load(ClassFinderImpl.scala:222) at org.clapper.classutil.ClassFinder.classData(ClassFinder.scala:404) at org.clapper.classutil.ClassFinder.$anonfun$processOpenZip$2(ClassFinder.scala:359) at scala.collection.Iterator$$anon$10.next(Iterator.scala:461) at scala.collection.Iterator$$anon$11.nextCur(Iterator.scala:486) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:492) at scala.collection.Iterator.toStream(Iterator.scala:1417) at scala.collection.Iterator.toStream$(Iterator.scala:1416) at scala.collection.AbstractIterator.toStream(Iterator.scala:1431) at scala.collection.Iterator.$anonfun$toStream$1(Iterator.scala:1417) at scala.collection.immutable.Stream$Cons.tail(Stream.scala:1173) at scala.collection.immutable.Stream$Cons.tail(Stream.scala:1163) at scala.collection.immutable.Stream.$anonfun$$plus$plus$1(Stream.scala:372) at scala.collection.immutable.Stream$Cons.tail(Stream.scala:1173) at scala.collection.immutable.Stream$Cons.tail(Stream.scala:1163) at scala.collection.immutable.Stream.$anonfun$$plus$plus$1(Stream.scala:372) at scala.collection.immutable.Stream$Cons.tail(Stream.scala:1173) at scala.collection.immutable.Stream$Cons.tail(Stream.scala:1163) at scala.collection.immutable.Stream.$anonfun$map$1(Stream.scala:418) at scala.collection.immutable.Stream$Cons.tail(Stream.scala:1173) at scala.collection.immutable.Stream$Cons.tail(Stream.scala:1163) at scala.collection.immutable.Stream.filterImpl(Stream.scala:506) at scala.collection.immutable.Stream$.$anonfun$filteredTail$1(Stream.scala:1260) at scala.collection.immutable.Stream$Cons.tail(Stream.scala:1173) at scala.collection.immutable.Stream$Cons.tail(Stream.scala:1163) at scala.collection.immutable.S
[spark] branch master updated: [MINOR] Remove redundant character escape "\\" and add UT
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b8f22f33308 [MINOR] Remove redundant character escape "\\" and add UT
b8f22f33308 is described below
commit b8f22f33308ab51b93052457dba17b04c2daeb4a
Author: panbingkun
AuthorDate: Mon May 15 18:04:31 2023 -0500
[MINOR] Remove redundant character escape "\\" and add UT
### What changes were proposed in this pull request?
The pr aims to remove redundant character escape "\\" and add UT for
SparkHadoopUtil.substituteHadoopVariables.
### Why are the changes needed?
Make code clean & remove warning.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA & Add new UT.
Closes #41170 from panbingkun/SparkHadoopUtil_fix.
Authored-by: panbingkun
Signed-off-by: Sean Owen
---
.../org/apache/spark/deploy/SparkHadoopUtil.scala | 4 +-
.../apache/spark/deploy/SparkHadoopUtilSuite.scala | 52 ++
2 files changed, 54 insertions(+), 2 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/deploy/SparkHadoopUtil.scala
b/core/src/main/scala/org/apache/spark/deploy/SparkHadoopUtil.scala
index 4908a081367..9ff2621b791 100644
--- a/core/src/main/scala/org/apache/spark/deploy/SparkHadoopUtil.scala
+++ b/core/src/main/scala/org/apache/spark/deploy/SparkHadoopUtil.scala
@@ -174,7 +174,7 @@ private[spark] class SparkHadoopUtil extends Logging {
* So we need a map to track the bytes read from the child threads and
parent thread,
* summing them together to get the bytes read of this task.
*/
-new Function0[Long] {
+new (() => Long) {
private val bytesReadMap = new mutable.HashMap[Long, Long]()
override def apply(): Long = {
@@ -248,7 +248,7 @@ private[spark] class SparkHadoopUtil extends Logging {
if (isGlobPath(pattern)) globPath(fs, pattern) else Seq(pattern)
}
- private val HADOOP_CONF_PATTERN =
"(\\$\\{hadoopconf-[^\\}\\$\\s]+\\})".r.unanchored
+ private val HADOOP_CONF_PATTERN =
"(\\$\\{hadoopconf-[^}$\\s]+})".r.unanchored
/**
* Substitute variables by looking them up in Hadoop configs. Only variables
that match the
diff --git
a/core/src/test/scala/org/apache/spark/deploy/SparkHadoopUtilSuite.scala
b/core/src/test/scala/org/apache/spark/deploy/SparkHadoopUtilSuite.scala
index 17f1476cd8d..6250b7d0ed2 100644
--- a/core/src/test/scala/org/apache/spark/deploy/SparkHadoopUtilSuite.scala
+++ b/core/src/test/scala/org/apache/spark/deploy/SparkHadoopUtilSuite.scala
@@ -123,6 +123,58 @@ class SparkHadoopUtilSuite extends SparkFunSuite {
assertConfigValue(hadoopConf, "fs.s3a.session.token", null)
}
+ test("substituteHadoopVariables") {
+val hadoopConf = new Configuration(false)
+hadoopConf.set("xxx", "yyy")
+
+val text1 = "${hadoopconf-xxx}"
+val result1 = new SparkHadoopUtil().substituteHadoopVariables(text1,
hadoopConf)
+assert(result1 == "yyy")
+
+val text2 = "${hadoopconf-xxx"
+val result2 = new SparkHadoopUtil().substituteHadoopVariables(text2,
hadoopConf)
+assert(result2 == "${hadoopconf-xxx")
+
+val text3 = "${hadoopconf-xxx}zzz"
+val result3 = new SparkHadoopUtil().substituteHadoopVariables(text3,
hadoopConf)
+assert(result3 == "yyyzzz")
+
+val text4 = "www${hadoopconf-xxx}zzz"
+val result4 = new SparkHadoopUtil().substituteHadoopVariables(text4,
hadoopConf)
+assert(result4 == "wwwyyyzzz")
+
+val text5 = "www${hadoopconf-xxx}"
+val result5 = new SparkHadoopUtil().substituteHadoopVariables(text5,
hadoopConf)
+assert(result5 == "wwwyyy")
+
+val text6 = "www${hadoopconf-xxx"
+val result6 = new SparkHadoopUtil().substituteHadoopVariables(text6,
hadoopConf)
+assert(result6 == "www${hadoopconf-xxx")
+
+val text7 = "www$hadoopconf-xxx}"
+val result7 = new SparkHadoopUtil().substituteHadoopVariables(text7,
hadoopConf)
+assert(result7 == "www$hadoopconf-xxx}")
+
+val text8 = "www{hadoopconf-xxx}"
+val result8 = new SparkHadoopUtil().substituteHadoopVariables(text8,
hadoopConf)
+assert(result8 == "www{hadoopconf-xxx}")
+ }
+
+ test("Redundant character escape '\\}' in RegExp ") {
+val HADOOP_CONF_PATTERN_1 = "(\\$\\{hadoopconf-[^}$\\s]+})".r.unanchored
+val HADOOP_CONF_PATTERN_2 = "(\\$\\{hadoopconf-[^}$\\s]+\\})".r.unanchored
+
+val text = "www${hadoopconf-xxx}zzz"
+val target1 = text match {
+ case HADOOP_CONF_PATTERN_1(matched) =&
[spark] branch master updated: [SPARK-43508][DOC] Replace the link related to hadoop version 2 with hadoop version 3
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new cadfef6f807 [SPARK-43508][DOC] Replace the link related to hadoop
version 2 with hadoop version 3
cadfef6f807 is described below
commit cadfef6f807a75ff403f6dd9234a3996ec7c691c
Author: panbingkun
AuthorDate: Mon May 15 09:44:03 2023 -0500
[SPARK-43508][DOC] Replace the link related to hadoop version 2 with hadoop
version 3
### What changes were proposed in this pull request?
The pr aims to replace the link related to hadoop version 2 with hadoop
version 3
### Why are the changes needed?
Because [SPARK-40651](https://issues.apache.org/jira/browse/SPARK-40651)
Drop Hadoop2 binary distribtuion from release process and
[SPARK-42447](https://issues.apache.org/jira/browse/SPARK-42447) Remove Hadoop
2 GitHub Action job.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test.
Closes #41171 from panbingkun/SPARK-43508.
Authored-by: panbingkun
Signed-off-by: Sean Owen
---
docs/streaming-programming-guide.md | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/docs/streaming-programming-guide.md
b/docs/streaming-programming-guide.md
index 5ed66eab348..f8f98ca5442 100644
--- a/docs/streaming-programming-guide.md
+++ b/docs/streaming-programming-guide.md
@@ -748,7 +748,7 @@ of the store is consistent with that expected by Spark
Streaming. It may be
that writing directly into a destination directory is the appropriate strategy
for
streaming data via the chosen object store.
-For more details on this topic, consult the [Hadoop Filesystem
Specification](https://hadoop.apache.org/docs/stable2/hadoop-project-dist/hadoop-common/filesystem/introduction.html).
+For more details on this topic, consult the [Hadoop Filesystem
Specification](https://hadoop.apache.org/docs/stable3/hadoop-project-dist/hadoop-common/filesystem/introduction.html).
Streams based on Custom Receivers
{:.no_toc}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-43495][BUILD] Upgrade RoaringBitmap to 0.9.44
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new bee8187d731 [SPARK-43495][BUILD] Upgrade RoaringBitmap to 0.9.44 bee8187d731 is described below commit bee8187d7319ededf82701b4fd2a2928cd56c7f8 Author: yangjie01 AuthorDate: Mon May 15 08:46:20 2023 -0500 [SPARK-43495][BUILD] Upgrade RoaringBitmap to 0.9.44 ### What changes were proposed in this pull request? This pr aims upgrade `RoaringBitmap` from 0.9.39 to 0.9.44. ### Why are the changes needed? The new version brings 2 bug fix: - https://github.com/RoaringBitmap/RoaringBitmap/issues/619 | https://github.com/RoaringBitmap/RoaringBitmap/pull/620 - https://github.com/RoaringBitmap/RoaringBitmap/issues/623 | https://github.com/RoaringBitmap/RoaringBitmap/pull/624 The full release notes as follows: - https://github.com/RoaringBitmap/RoaringBitmap/releases/tag/0.9.40 - https://github.com/RoaringBitmap/RoaringBitmap/releases/tag/0.9.41 - https://github.com/RoaringBitmap/RoaringBitmap/releases/tag/0.9.44 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GitHub Actions Closes #41165 from LuciferYang/SPARK-43495. Authored-by: yangjie01 Signed-off-by: Sean Owen --- core/benchmarks/MapStatusesConvertBenchmark-jdk11-results.txt | 10 +- core/benchmarks/MapStatusesConvertBenchmark-jdk17-results.txt | 10 +- core/benchmarks/MapStatusesConvertBenchmark-results.txt | 10 +- dev/deps/spark-deps-hadoop-3-hive-2.3 | 4 ++-- pom.xml | 2 +- 5 files changed, 18 insertions(+), 18 deletions(-) diff --git a/core/benchmarks/MapStatusesConvertBenchmark-jdk11-results.txt b/core/benchmarks/MapStatusesConvertBenchmark-jdk11-results.txt index ef9dd139ff2..f42b95e8d4c 100644 --- a/core/benchmarks/MapStatusesConvertBenchmark-jdk11-results.txt +++ b/core/benchmarks/MapStatusesConvertBenchmark-jdk11-results.txt @@ -2,12 +2,12 @@ MapStatuses Convert Benchmark -OpenJDK 64-Bit Server VM 11.0.18+10 on Linux 5.15.0-1031-azure -Intel(R) Xeon(R) Platinum 8370C CPU @ 2.80GHz +OpenJDK 64-Bit Server VM 11.0.19+7 on Linux 5.15.0-1037-azure +Intel(R) Xeon(R) CPU E5-2673 v4 @ 2.30GHz MapStatuses Convert: Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative -Num Maps: 5 Fetch partitions:500 1288 1317 38 0.0 1288194389.0 1.0X -Num Maps: 5 Fetch partitions:1000 2608 2671 65 0.0 2607771122.0 0.5X -Num Maps: 5 Fetch partitions:1500 3985 4026 64 0.0 3984885770.0 0.3X +Num Maps: 5 Fetch partitions:500 1346 1367 28 0.0 1345826909.0 1.0X +Num Maps: 5 Fetch partitions:1000 2807 2818 11 0.0 2806866333.0 0.5X +Num Maps: 5 Fetch partitions:1500 4287 4308 19 0.0 4286688536.0 0.3X diff --git a/core/benchmarks/MapStatusesConvertBenchmark-jdk17-results.txt b/core/benchmarks/MapStatusesConvertBenchmark-jdk17-results.txt index 12af87d9689..b0b61cc11ef 100644 --- a/core/benchmarks/MapStatusesConvertBenchmark-jdk17-results.txt +++ b/core/benchmarks/MapStatusesConvertBenchmark-jdk17-results.txt @@ -2,12 +2,12 @@ MapStatuses Convert Benchmark -OpenJDK 64-Bit Server VM 17.0.6+10 on Linux 5.15.0-1031-azure -Intel(R) Xeon(R) Platinum 8370C CPU @ 2.80GHz +OpenJDK 64-Bit Server VM 17.0.7+7 on Linux 5.15.0-1037-azure +Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz MapStatuses Convert: Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative -Num Maps: 5 Fetch partitions:500 1052 1061 12 0.0 1051946292.0 1.0X -Num Maps: 5 Fetch partitions:1000 1888 2007 109 0.0 1888235523.0 0.6X -Num Maps: 5 Fetch partitions:1500 3070 3149 81 0.0 3070386448.0 0.3X +Num Maps: 5 Fetch partitions:500 1041 1050 16 0.0
[spark] branch master updated: [SPARK-43489][BUILD] Remove protobuf 2.5.0
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b23185080cc [SPARK-43489][BUILD] Remove protobuf 2.5.0
b23185080cc is described below
commit b23185080cc3e5a00b88496cec70c2b3cd7019f5
Author: Cheng Pan
AuthorDate: Sun May 14 08:09:37 2023 -0500
[SPARK-43489][BUILD] Remove protobuf 2.5.0
### What changes were proposed in this pull request?
Spark does not use protobuf 2.5.0 directly, instead, it comes from other
dependencies, with the following changes, now, Spark does not require protobuf
2.5.0 (please let me know if I miss something),
- SPARK-40323 upgraded ORC 1.8.0, which moved from protobuf 2.5.0 to a
shaded protobuf 3
- SPARK-33212 switched from Hadoop vanilla client to Hadoop shaded client,
also removed the protobuf 2 dependency. SPARK-42452 removed the support for
Hadoop 2.
- SPARK-14421 shaded and relocated protobuf 2.6.1, which is required by the
kinesis client, into the kinesis assembly jar
- Spark itself's core/connect/protobuf modules use protobuf 3, also shaded
and relocated all protobuf 3 deps.
### Why are the changes needed?
Remove the obsolete dependency, which is EOL long ago, and has CVEs
[CVE-2022-3510](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-3510)
[CVE-2022-3509](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-3509)
[CVE-2022-3171](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-3171)
[CVE-2021-22569](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-22569)
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA.
Closes #41153 from pan3793/remove-protobuf-2.
Authored-by: Cheng Pan
Signed-off-by: Sean Owen
---
connector/connect/client/jvm/pom.xml | 1 -
connector/connect/common/pom.xml | 1 -
connector/connect/server/pom.xml | 2 --
connector/protobuf/pom.xml| 2 --
core/pom.xml | 3 +--
dev/deps/spark-deps-hadoop-3-hive-2.3 | 1 -
pom.xml | 18 --
sql/core/pom.xml | 1 -
sql/hive/pom.xml | 11 ---
9 files changed, 9 insertions(+), 31 deletions(-)
diff --git a/connector/connect/client/jvm/pom.xml
b/connector/connect/client/jvm/pom.xml
index 8543057d0c0..413764d0ea2 100644
--- a/connector/connect/client/jvm/pom.xml
+++ b/connector/connect/client/jvm/pom.xml
@@ -65,7 +65,6 @@
com.google.protobuf
protobuf-java
- ${protobuf.version}
compile
diff --git a/connector/connect/common/pom.xml b/connector/connect/common/pom.xml
index e457620e593..06076646df7 100644
--- a/connector/connect/common/pom.xml
+++ b/connector/connect/common/pom.xml
@@ -57,7 +57,6 @@
com.google.protobuf
protobuf-java
-${protobuf.version}
compile
diff --git a/connector/connect/server/pom.xml b/connector/connect/server/pom.xml
index a62c420bcc0..8313f21f4ba 100644
--- a/connector/connect/server/pom.xml
+++ b/connector/connect/server/pom.xml
@@ -170,13 +170,11 @@
com.google.protobuf
protobuf-java
- ${protobuf.version}
compile
com.google.protobuf
protobuf-java-util
- ${protobuf.version}
compile
diff --git a/connector/protobuf/pom.xml b/connector/protobuf/pom.xml
index 6feef54ce71..e85f07841df 100644
--- a/connector/protobuf/pom.xml
+++ b/connector/protobuf/pom.xml
@@ -79,13 +79,11 @@
com.google.protobuf
protobuf-java
- ${protobuf.version}
compile
com.google.protobuf
protobuf-java-util
- ${protobuf.version}
compile
diff --git a/core/pom.xml b/core/pom.xml
index 66e41837d52..09b0a2af96f 100644
--- a/core/pom.xml
+++ b/core/pom.xml
@@ -536,7 +536,6 @@
com.google.protobuf
protobuf-java
- ${protobuf.version}
compile
@@ -627,7 +626,7 @@
true
true
-
guava,jetty-io,jetty-servlet,jetty-servlets,jetty-continuation,jetty-http,jetty-plus,jetty-util,jetty-server,jetty-security,jetty-proxy,jetty-client
+
guava,protobuf-java,jetty-io,jetty-servlet,jetty-servlets,jetty-continuation,jetty-http,jetty-plus,jetty-util,jetty-server,jetty-security,jetty-proxy,jetty-client
true
diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3
b/dev/deps/spark-deps-hadoop-3-hive-2.3
index c23bb89c983..7e702e44c40 100644
--- a/dev/deps/spark-deps-hadoop-3-hive-2.3
+++ b/dev/deps/spark-deps-hadoop-3-hive-2.3
@@ -221,7 +221,6 @@
parquet-format-structures/1.13.0
[spark] branch master updated: [SPARK-43138][CORE] Fix ClassNotFoundException during migration
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 37a0ae3511c [SPARK-43138][CORE] Fix ClassNotFoundException during migration 37a0ae3511c is described below commit 37a0ae3511c9f153537d5928e9938f72763f5464 Author: Emil Ejbyfeldt AuthorDate: Thu May 11 08:25:45 2023 -0500 [SPARK-43138][CORE] Fix ClassNotFoundException during migration ### What changes were proposed in this pull request? This PR fixes an unhandled ClassNotFoundException during RDD block decommissions migrations. ``` 2023-04-08 04:15:11,791 ERROR server.TransportRequestHandler: Error while invoking RpcHandler#receive() on RPC id 6425687122551756860 java.lang.ClassNotFoundException: com.class.from.user.jar.ClassName at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:581) at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:178) at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:522) at java.base/java.lang.Class.forName0(Native Method) at java.base/java.lang.Class.forName(Class.java:398) at org.apache.spark.serializer.JavaDeserializationStream$$anon$1.resolveClass(JavaSerializer.scala:71) at java.base/java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:2003) at java.base/java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1870) at java.base/java.io.ObjectInputStream.readClass(ObjectInputStream.java:1833) at java.base/java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1658) at java.base/java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2496) at java.base/java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2390) at java.base/java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2228) at java.base/java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1687) at java.base/java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2496) at java.base/java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2390) at java.base/java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2228) at java.base/java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1687) at java.base/java.io.ObjectInputStream.readObject(ObjectInputStream.java:489) at java.base/java.io.ObjectInputStream.readObject(ObjectInputStream.java:447) at org.apache.spark.serializer.JavaDeserializationStream.readObject(JavaSerializer.scala:87) at org.apache.spark.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:123) at org.apache.spark.network.netty.NettyBlockRpcServer.deserializeMetadata(NettyBlockRpcServer.scala:180) at org.apache.spark.network.netty.NettyBlockRpcServer.receive(NettyBlockRpcServer.scala:119) at org.apache.spark.network.server.TransportRequestHandler.processRpcRequest(TransportRequestHandler.java:163) at org.apache.spark.network.server.TransportRequestHandler.handle(TransportRequestHandler.java:109) at org.apache.spark.network.server.TransportChannelHandler.channelRead0(TransportChannelHandler.java:140) at org.apache.spark.network.server.TransportChannelHandler.channelRead0(TransportChannelHandler.java:53) at io.netty.channel.SimpleChannelInboundHandler.channelRead(SimpleChannelInboundHandler.java:99) at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:379) at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:365) at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:357) at io.netty.handler.timeout.IdleStateHandler.channelRead(IdleStateHandler.java:286) at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:379) at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:365) at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:357) at io.netty.handler.codec.MessageToMessageDecoder.channelRead(MessageToMessageDecoder.java:103) at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:379) at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:365) at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:357
[spark] branch master updated: [SPARK-40912][CORE] Overhead of Exceptions in KryoDeserializationStream
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 4def99d54fc [SPARK-40912][CORE] Overhead of Exceptions in KryoDeserializationStream 4def99d54fc is described below commit 4def99d54fcb55e80fb4f5f9558af1739b385e6c Author: Emil Ejbyfeldt AuthorDate: Wed May 10 08:23:07 2023 -0500 [SPARK-40912][CORE] Overhead of Exceptions in KryoDeserializationStream ### What changes were proposed in this pull request? This PR avoid exceptions in the implementation of KryoDeserializationStream. ### Why are the changes needed? Using an exceptions for end of stream is slow, especially for small streams. It also problematic as it the exception caught in the KryoDeserializationStream could also be caused by corrupt data which would just be ignored in the current implementation. ### Does this PR introduce _any_ user-facing change? Yes, it changes so some method on KryoDeserializationStream no longer raises EOFException. ### How was this patch tested? Existing tests. This PR only changes KryoDeserializationStream as a proof of concept. If this is the direction we want to go we should probably change DerserializationStream isntead so that the interface is consistent. Closes #38428 from eejbyfeldt/SPARK-40912. Authored-by: Emil Ejbyfeldt Signed-off-by: Sean Owen --- core/benchmarks/KryoBenchmark-jdk11-results.txt| 40 +++ core/benchmarks/KryoBenchmark-jdk17-results.txt| 36 +++ core/benchmarks/KryoBenchmark-results.txt | 40 +++ .../KryoIteratorBenchmark-jdk11-results.txt| 28 + .../KryoIteratorBenchmark-jdk17-results.txt| 28 + core/benchmarks/KryoIteratorBenchmark-results.txt | 28 + .../KryoSerializerBenchmark-jdk11-results.txt | 8 +- .../KryoSerializerBenchmark-jdk17-results.txt | 6 +- .../benchmarks/KryoSerializerBenchmark-results.txt | 8 +- .../apache/spark/serializer/KryoSerializer.scala | 48 - .../util/collection/ExternalAppendOnlyMap.scala| 46 +++- .../spark/serializer/KryoIteratorBenchmark.scala | 120 + .../spark/serializer/KryoSerializerSuite.scala | 24 - 13 files changed, 360 insertions(+), 100 deletions(-) diff --git a/core/benchmarks/KryoBenchmark-jdk11-results.txt b/core/benchmarks/KryoBenchmark-jdk11-results.txt index 73e7f15ba22..01269b496e0 100644 --- a/core/benchmarks/KryoBenchmark-jdk11-results.txt +++ b/core/benchmarks/KryoBenchmark-jdk11-results.txt @@ -2,27 +2,27 @@ Benchmark Kryo Unsafe vs safe Serialization -OpenJDK 64-Bit Server VM 11.0.18+10 on Linux 5.15.0-1031-azure -Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz +OpenJDK 64-Bit Server VM 11.0.18+10 on Linux 5.15.0-1036-azure +Intel(R) Xeon(R) Platinum 8370C CPU @ 2.80GHz Benchmark Kryo Unsafe vs safe Serialization: Best Time(ms) Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative --- -basicTypes: Int with unsafe:true 301319 11 3.3 301.5 1.0X -basicTypes: Long with unsafe:true 337351 9 3.0 337.2 0.9X -basicTypes: Float with unsafe:true 327335 6 3.1 327.5 0.9X -basicTypes: Double with unsafe:true321336 10 3.1 321.0 0.9X -Array: Int with unsafe:true 4 5 1245.2 4.1 73.9X -Array: Long with unsafe:true 7 8 1147.6 6.8 44.5X -Array: Float with unsafe:true4 5 1250.4 4.0 75.5X -Array: Double with unsafe:true 7 8 1144.1 6.9 43.4X -Map of string->Double with unsafe:true 42 46 4 23.8 42.0 7.2X -basicTypes: Int with unsafe:false 347357 10 2.9 347.4 0.9X -basicTypes: Long with unsafe:false 378394 10 2.6 378.1 0.8X -basicTypes: Float with unsafe:false346359 9 2.9 345.6 0.9X -basicTypes: Double with unsafe:false 350372 20 2.9 350.3 0
[spark] branch master updated: [SPARK-43394][BUILD] Upgrade maven to 3.8.8
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 04ef3d5d0f2 [SPARK-43394][BUILD] Upgrade maven to 3.8.8
04ef3d5d0f2 is described below
commit 04ef3d5d0f2bfebce8dd3b48b9861a2aa5ba1c3a
Author: Cheng Pan
AuthorDate: Sun May 7 08:24:12 2023 -0500
[SPARK-43394][BUILD] Upgrade maven to 3.8.8
### What changes were proposed in this pull request?
Upgrade Maven from 3.8.7 to 3.8.8.
### Why are the changes needed?
Maven 3.8.8 is the latest patched version of 3.8.x
https://maven.apache.org/docs/3.8.8/release-notes.html
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GA.
Closes #41073 from pan3793/SPARK-43394.
Authored-by: Cheng Pan
Signed-off-by: Sean Owen
---
dev/appveyor-install-dependencies.ps1 | 2 +-
docs/building-spark.md| 2 +-
pom.xml | 2 +-
3 files changed, 3 insertions(+), 3 deletions(-)
diff --git a/dev/appveyor-install-dependencies.ps1
b/dev/appveyor-install-dependencies.ps1
index 7f4f027c820..88090149f5c 100644
--- a/dev/appveyor-install-dependencies.ps1
+++ b/dev/appveyor-install-dependencies.ps1
@@ -81,7 +81,7 @@ if (!(Test-Path $tools)) {
# == Maven
# Push-Location $tools
#
-# $mavenVer = "3.8.7"
+# $mavenVer = "3.8.8"
# Start-FileDownload
"https://archive.apache.org/dist/maven/maven-3/$mavenVer/binaries/apache-maven-$mavenVer-bin.zip;
"maven.zip"
#
# # extract
diff --git a/docs/building-spark.md b/docs/building-spark.md
index ba8dddbf6b1..4b8e70655d5 100644
--- a/docs/building-spark.md
+++ b/docs/building-spark.md
@@ -27,7 +27,7 @@ license: |
## Apache Maven
The Maven-based build is the build of reference for Apache Spark.
-Building Spark using Maven requires Maven 3.8.7 and Java 8.
+Building Spark using Maven requires Maven 3.8.8 and Java 8/11/17.
Spark requires Scala 2.12/2.13; support for Scala 2.11 was removed in Spark
3.0.0.
### Setting up Maven's Memory Usage
diff --git a/pom.xml b/pom.xml
index c760eaf0cbb..96ee3fb5ed9 100644
--- a/pom.xml
+++ b/pom.xml
@@ -114,7 +114,7 @@
1.8
${java.version}
${java.version}
-3.8.7
+3.8.8
1.6.0
spark
2.0.7
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-43395][BUILD] Exclude macOS tar extended metadata in make-distribution.sh
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new 37c27451a2d [SPARK-43395][BUILD] Exclude macOS tar extended metadata in make-distribution.sh 37c27451a2d is described below commit 37c27451a2dbb4668c2793c1fcae4759c845d3ad Author: Cheng Pan AuthorDate: Sat May 6 09:37:44 2023 -0500 [SPARK-43395][BUILD] Exclude macOS tar extended metadata in make-distribution.sh ### What changes were proposed in this pull request? Add args `--no-mac-metadata --no-xattrs --no-fflags` to `tar` on macOS in `dev/make-distribution.sh` to exclude macOS-specific extended metadata. ### Why are the changes needed? The binary tarball created on macOS includes extended macOS-specific metadata and xattrs, which causes warnings when unarchiving it on Linux. Step to reproduce 1. create tarball on macOS (13.3.1) ``` ➜ apache-spark git:(master) tar --version bsdtar 3.5.3 - libarchive 3.5.3 zlib/1.2.11 liblzma/5.0.5 bz2lib/1.0.8 ``` ``` ➜ apache-spark git:(master) dev/make-distribution.sh --tgz ``` 2. unarchive the binary tarball on Linux (CentOS-7) ``` ➜ ~ tar --version tar (GNU tar) 1.26 Copyright (C) 2011 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>. This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Written by John Gilmore and Jay Fenlason. ``` ``` ➜ ~ tar -xzf spark-3.5.0-SNAPSHOT-bin-3.3.5.tgz tar: Ignoring unknown extended header keyword `SCHILY.fflags' tar: Ignoring unknown extended header keyword `LIBARCHIVE.xattr.com.apple.FinderInfo' ``` ### Does this PR introduce _any_ user-facing change? No, dev only. ### How was this patch tested? Create binary tarball on macOS then unarchive on Linux, warnings disappear after this change. Closes #41074 from pan3793/SPARK-43395. Authored-by: Cheng Pan Signed-off-by: Sean Owen (cherry picked from commit 2d0240df3c474902e263f67b93fb497ca13da00f) Signed-off-by: Sean Owen --- dev/make-distribution.sh | 6 +- 1 file changed, 5 insertions(+), 1 deletion(-) diff --git a/dev/make-distribution.sh b/dev/make-distribution.sh index 571059be6fd..e92f445f046 100755 --- a/dev/make-distribution.sh +++ b/dev/make-distribution.sh @@ -287,6 +287,10 @@ if [ "$MAKE_TGZ" == "true" ]; then TARDIR="$SPARK_HOME/$TARDIR_NAME" rm -rf "$TARDIR" cp -r "$DISTDIR" "$TARDIR" - tar czf "spark-$VERSION-bin-$NAME.tgz" -C "$SPARK_HOME" "$TARDIR_NAME" + TAR="tar" + if [ "$(uname -s)" = "Darwin" ]; then +TAR="tar --no-mac-metadata --no-xattrs --no-fflags" + fi + $TAR -czf "spark-$VERSION-bin-$NAME.tgz" -C "$SPARK_HOME" "$TARDIR_NAME" rm -rf "$TARDIR" fi - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-43395][BUILD] Exclude macOS tar extended metadata in make-distribution.sh
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.3 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.3 by this push: new 85ff71f9459 [SPARK-43395][BUILD] Exclude macOS tar extended metadata in make-distribution.sh 85ff71f9459 is described below commit 85ff71f94593dd8ede9a0ea3278f5026da10c46f Author: Cheng Pan AuthorDate: Sat May 6 09:37:44 2023 -0500 [SPARK-43395][BUILD] Exclude macOS tar extended metadata in make-distribution.sh ### What changes were proposed in this pull request? Add args `--no-mac-metadata --no-xattrs --no-fflags` to `tar` on macOS in `dev/make-distribution.sh` to exclude macOS-specific extended metadata. ### Why are the changes needed? The binary tarball created on macOS includes extended macOS-specific metadata and xattrs, which causes warnings when unarchiving it on Linux. Step to reproduce 1. create tarball on macOS (13.3.1) ``` ➜ apache-spark git:(master) tar --version bsdtar 3.5.3 - libarchive 3.5.3 zlib/1.2.11 liblzma/5.0.5 bz2lib/1.0.8 ``` ``` ➜ apache-spark git:(master) dev/make-distribution.sh --tgz ``` 2. unarchive the binary tarball on Linux (CentOS-7) ``` ➜ ~ tar --version tar (GNU tar) 1.26 Copyright (C) 2011 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>. This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Written by John Gilmore and Jay Fenlason. ``` ``` ➜ ~ tar -xzf spark-3.5.0-SNAPSHOT-bin-3.3.5.tgz tar: Ignoring unknown extended header keyword `SCHILY.fflags' tar: Ignoring unknown extended header keyword `LIBARCHIVE.xattr.com.apple.FinderInfo' ``` ### Does this PR introduce _any_ user-facing change? No, dev only. ### How was this patch tested? Create binary tarball on macOS then unarchive on Linux, warnings disappear after this change. Closes #41074 from pan3793/SPARK-43395. Authored-by: Cheng Pan Signed-off-by: Sean Owen (cherry picked from commit 2d0240df3c474902e263f67b93fb497ca13da00f) Signed-off-by: Sean Owen --- dev/make-distribution.sh | 6 +- 1 file changed, 5 insertions(+), 1 deletion(-) diff --git a/dev/make-distribution.sh b/dev/make-distribution.sh index 571059be6fd..e92f445f046 100755 --- a/dev/make-distribution.sh +++ b/dev/make-distribution.sh @@ -287,6 +287,10 @@ if [ "$MAKE_TGZ" == "true" ]; then TARDIR="$SPARK_HOME/$TARDIR_NAME" rm -rf "$TARDIR" cp -r "$DISTDIR" "$TARDIR" - tar czf "spark-$VERSION-bin-$NAME.tgz" -C "$SPARK_HOME" "$TARDIR_NAME" + TAR="tar" + if [ "$(uname -s)" = "Darwin" ]; then +TAR="tar --no-mac-metadata --no-xattrs --no-fflags" + fi + $TAR -czf "spark-$VERSION-bin-$NAME.tgz" -C "$SPARK_HOME" "$TARDIR_NAME" rm -rf "$TARDIR" fi - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-43395][BUILD] Exclude macOS tar extended metadata in make-distribution.sh
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.4 by this push: new cd2a6f38e0c [SPARK-43395][BUILD] Exclude macOS tar extended metadata in make-distribution.sh cd2a6f38e0c is described below commit cd2a6f38e0cceff68493918fe7cd6498a7f4119d Author: Cheng Pan AuthorDate: Sat May 6 09:37:44 2023 -0500 [SPARK-43395][BUILD] Exclude macOS tar extended metadata in make-distribution.sh ### What changes were proposed in this pull request? Add args `--no-mac-metadata --no-xattrs --no-fflags` to `tar` on macOS in `dev/make-distribution.sh` to exclude macOS-specific extended metadata. ### Why are the changes needed? The binary tarball created on macOS includes extended macOS-specific metadata and xattrs, which causes warnings when unarchiving it on Linux. Step to reproduce 1. create tarball on macOS (13.3.1) ``` ➜ apache-spark git:(master) tar --version bsdtar 3.5.3 - libarchive 3.5.3 zlib/1.2.11 liblzma/5.0.5 bz2lib/1.0.8 ``` ``` ➜ apache-spark git:(master) dev/make-distribution.sh --tgz ``` 2. unarchive the binary tarball on Linux (CentOS-7) ``` ➜ ~ tar --version tar (GNU tar) 1.26 Copyright (C) 2011 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>. This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Written by John Gilmore and Jay Fenlason. ``` ``` ➜ ~ tar -xzf spark-3.5.0-SNAPSHOT-bin-3.3.5.tgz tar: Ignoring unknown extended header keyword `SCHILY.fflags' tar: Ignoring unknown extended header keyword `LIBARCHIVE.xattr.com.apple.FinderInfo' ``` ### Does this PR introduce _any_ user-facing change? No, dev only. ### How was this patch tested? Create binary tarball on macOS then unarchive on Linux, warnings disappear after this change. Closes #41074 from pan3793/SPARK-43395. Authored-by: Cheng Pan Signed-off-by: Sean Owen (cherry picked from commit 2d0240df3c474902e263f67b93fb497ca13da00f) Signed-off-by: Sean Owen --- dev/make-distribution.sh | 6 +- 1 file changed, 5 insertions(+), 1 deletion(-) diff --git a/dev/make-distribution.sh b/dev/make-distribution.sh index d4c8559fd4a..948ee19fbac 100755 --- a/dev/make-distribution.sh +++ b/dev/make-distribution.sh @@ -287,6 +287,10 @@ if [ "$MAKE_TGZ" == "true" ]; then TARDIR="$SPARK_HOME/$TARDIR_NAME" rm -rf "$TARDIR" cp -r "$DISTDIR" "$TARDIR" - tar czf "spark-$VERSION-bin-$NAME.tgz" -C "$SPARK_HOME" "$TARDIR_NAME" + TAR="tar" + if [ "$(uname -s)" = "Darwin" ]; then +TAR="tar --no-mac-metadata --no-xattrs --no-fflags" + fi + $TAR -czf "spark-$VERSION-bin-$NAME.tgz" -C "$SPARK_HOME" "$TARDIR_NAME" rm -rf "$TARDIR" fi - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (566980fba1c -> 2d0240df3c4)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 566980fba1c [SPARK-38462][CORE] Add error class INTERNAL_ERROR_EXECUTOR add 2d0240df3c4 [SPARK-43395][BUILD] Exclude macOS tar extended metadata in make-distribution.sh No new revisions were added by this update. Summary of changes: dev/make-distribution.sh | 6 +- 1 file changed, 5 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated (e9aab411ca8 -> bc2c9553805)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch branch-3.3 in repository https://gitbox.apache.org/repos/asf/spark.git from e9aab411ca8 [SPARK-43293][SQL] `__qualified_access_only` should be ignored in normal columns add bc2c9553805 [SPARK-43337][UI][3.3] Asc/desc arrow icons for sorting column does not get displayed in the table column No new revisions were added by this update. Summary of changes: .../org/apache/spark/ui/static/jquery.dataTables.1.10.25.min.css| 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (d65a0ce996b -> 1b54b014543)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from d65a0ce996b [SPARK-43379][DOCS] Deprecate old Java 8 versions prior to 8u371 add 1b54b014543 [SPARK-43185][BUILD] Inline `hadoop-client` related properties in `pom.xml` No new revisions were added by this update. Summary of changes: common/network-yarn/pom.xml | 4 ++-- connector/kafka-0-10-assembly/pom.xml | 4 ++-- connector/kafka-0-10-token-provider/pom.xml | 2 +- connector/kinesis-asl-assembly/pom.xml | 4 ++-- core/pom.xml| 4 ++-- hadoop-cloud/pom.xml| 4 ++-- launcher/pom.xml| 4 ++-- pom.xml | 27 +++ resource-managers/yarn/pom.xml | 6 +++--- sql/hive/pom.xml| 2 +- 10 files changed, 20 insertions(+), 41 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-43379][DOCS] Deprecate old Java 8 versions prior to 8u371
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new d65a0ce996b [SPARK-43379][DOCS] Deprecate old Java 8 versions prior to 8u371 d65a0ce996b is described below commit d65a0ce996b776392e6be8fef37ee2754ebc4dfd Author: Dongjoon Hyun AuthorDate: Fri May 5 10:37:46 2023 -0500 [SPARK-43379][DOCS] Deprecate old Java 8 versions prior to 8u371 ### What changes were proposed in this pull request? This PR aims to deprecate old Java 8 versions prior to 8u371. Specifically, it's fixed at Java SE 8u371, 11.0.19, 17.0.7, 20.0.1. ### Why are the changes needed? To avoid TLS issue - [OpenJDK: improper connection handling during TLS handshake](https://bugzilla.redhat.com/show_bug.cgi?id=2187435) - https://www.oracle.com/security-alerts/cpuapr2023.html#AppendixJAVA Release notes: - https://www.oracle.com/java/technologies/javase/8u371-relnotes.html - https://www.oracle.com/java/technologies/javase/11-0-19-relnotes.html - https://www.oracle.com/java/technologies/javase/17-0-7-relnotes.html - https://www.oracle.com/java/technologies/javase/20-0-1-relnotes.html ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual review. Closes #41051 from dongjoon-hyun/SPARK-43379. Authored-by: Dongjoon Hyun Signed-off-by: Sean Owen --- docs/index.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/docs/index.md b/docs/index.md index 81311b3442d..c673537d214 100644 --- a/docs/index.md +++ b/docs/index.md @@ -35,7 +35,7 @@ source, visit [Building Spark](building-spark.html). Spark runs on both Windows and UNIX-like systems (e.g. Linux, Mac OS), and it should run on any platform that runs a supported version of Java. This should include JVMs on x86_64 and ARM64. It's easy to run locally on one machine --- all you need is to have `java` installed on your system `PATH`, or the `JAVA_HOME` environment variable pointing to a Java installation. Spark runs on Java 8/11/17, Scala 2.12/2.13, Python 3.8+, and R 3.5+. -Java 8 prior to version 8u362 support is deprecated as of Spark 3.4.0. +Java 8 prior to version 8u371 support is deprecated as of Spark 3.5.0. When using the Scala API, it is necessary for applications to use the same version of Scala that Spark was compiled for. For example, when using Scala 2.13, use Spark compiled for 2.13, and compile code/applications for Scala 2.13 as well. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (79d5d908e5d -> 44e68599228)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 79d5d908e5d [SPARK-43284][SQL][FOLLOWUP] Return URI encoded path, and add a test add 44e68599228 [SPARK-43279][CORE] Cleanup unused members from `SparkHadoopUtil` No new revisions were added by this update. Summary of changes: .../org/apache/spark/deploy/SparkHadoopUtil.scala | 59 +- 1 file changed, 1 insertion(+), 58 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-43337][UI][3.4] Asc/desc arrow icons for sorting column does not get displayed in the table column
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new e04025e359f [SPARK-43337][UI][3.4] Asc/desc arrow icons for sorting
column does not get displayed in the table column
e04025e359f is described below
commit e04025e359fe3d8bbaa7b695b491319f050adeb1
Author: Maytas Monsereenusorn
AuthorDate: Fri May 5 10:25:46 2023 -0500
[SPARK-43337][UI][3.4] Asc/desc arrow icons for sorting column does not get
displayed in the table column
### What changes were proposed in this pull request? Remove css
`!important` tag for asc/desc arrow icons in jquery.dataTables.1.10.25.min.css
### Why are the changes needed?
Upgrading to DataTables 1.10.25 broke asc/desc arrow icons for sorting
column. The sorting icon is not displayed when the column is clicked to sort by
asc/desc. This is because the new DataTables 1.10.25's
jquery.dataTables.1.10.25.min.css file added `!important` rule preventing the
override set in webui-dataTables.css
### Does this PR introduce _any_ user-facing change? No.
### How was this patch tested?
Manual test.
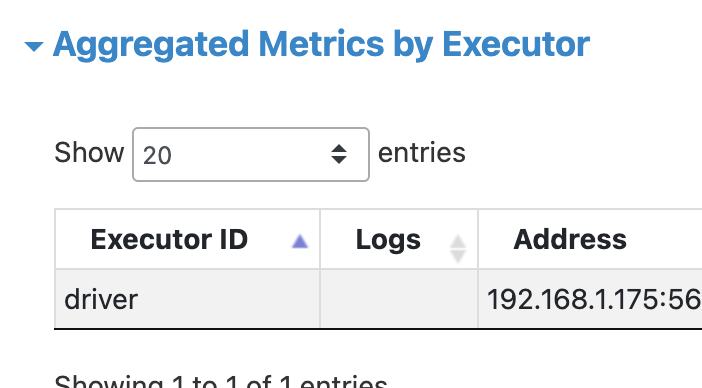
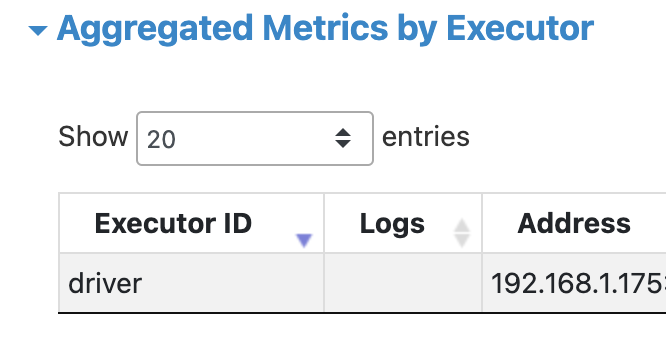
Closes #41061 from maytasm/fix-arrow-4.
Authored-by: Maytas Monsereenusorn
Signed-off-by: Sean Owen
---
.../org/apache/spark/ui/static/jquery.dataTables.1.10.25.min.css| 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git
a/core/src/main/resources/org/apache/spark/ui/static/jquery.dataTables.1.10.25.min.css
b/core/src/main/resources/org/apache/spark/ui/static/jquery.dataTables.1.10.25.min.css
index 6e60559741c..4df81e13a75 100644
---
a/core/src/main/resources/org/apache/spark/ui/static/jquery.dataTables.1.10.25.min.css
+++
b/core/src/main/resources/org/apache/spark/ui/static/jquery.dataTables.1.10.25.min.css
@@ -1 +1 @@
-table.dataTable{width:100%;margin:0
auto;clear:both;border-collapse:separate;border-spacing:0}table.dataTable thead
th,table.dataTable tfoot th{font-weight:bold}table.dataTable thead
th,table.dataTable thead td{padding:10px 18px;border-bottom:1px solid
#111}table.dataTable thead th:active,table.dataTable thead
td:active{outline:none}table.dataTable tfoot th,table.dataTable tfoot
td{padding:10px 18px 6px 18px;border-top:1px solid #111}table.dataTable thead
.sorting,table.dataTable thead . [...]
\ No newline at end of file
+table.dataTable{width:100%;margin:0
auto;clear:both;border-collapse:separate;border-spacing:0}table.dataTable thead
th,table.dataTable tfoot th{font-weight:bold}table.dataTable thead
th,table.dataTable thead td{padding:10px 18px;border-bottom:1px solid
#111}table.dataTable thead th:active,table.dataTable thead
td:active{outline:none}table.dataTable tfoot th,table.dataTable tfoot
td{padding:10px 18px 6px 18px;border-top:1px solid #111}table.dataTable thead
.sorting,table.dataTable thead . [...]
\ No newline at end of file
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-43378][CORE] Properly close stream objects in deserializeFromChunkedBuffer
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new b51e860cbfd [SPARK-43378][CORE] Properly close stream objects in
deserializeFromChunkedBuffer
b51e860cbfd is described below
commit b51e860cbfdc03c0b085dc6e7dcb11fd1579113b
Author: Emil Ejbyfeldt
AuthorDate: Thu May 4 19:34:14 2023 -0500
[SPARK-43378][CORE] Properly close stream objects in
deserializeFromChunkedBuffer
### What changes were proposed in this pull request?
Fixes a that SerializerHelper.deserializeFromChunkedBuffer does not call
close on the deserialization stream. For some serializers like Kryo this
creates a performance regressions as the kryo instances are not returned to the
pool.
### Why are the changes needed?
This causes a performance regression in Spark 3.4.0 for some workloads.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing tests.
Closes #41049 from eejbyfeldt/SPARK-43378.
Authored-by: Emil Ejbyfeldt
Signed-off-by: Sean Owen
(cherry picked from commit cb26ad88c522070c66e979ab1ab0f040cd1bdbe7)
Signed-off-by: Sean Owen
---
.../src/main/scala/org/apache/spark/serializer/SerializerHelper.scala | 4 +++-
1 file changed, 3 insertions(+), 1 deletion(-)
diff --git
a/core/src/main/scala/org/apache/spark/serializer/SerializerHelper.scala
b/core/src/main/scala/org/apache/spark/serializer/SerializerHelper.scala
index 2cff87990a4..54a0b2e339e 100644
--- a/core/src/main/scala/org/apache/spark/serializer/SerializerHelper.scala
+++ b/core/src/main/scala/org/apache/spark/serializer/SerializerHelper.scala
@@ -49,6 +49,8 @@ private[spark] object SerializerHelper extends Logging {
serializerInstance: SerializerInstance,
bytes: ChunkedByteBuffer): T = {
val in = serializerInstance.deserializeStream(bytes.toInputStream())
-in.readObject()
+val res = in.readObject()
+in.close()
+res
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (05df8c472b4 -> cb26ad88c52)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 05df8c472b4 [SPARK-43312][PROTOBUF] Option to convert Any fields into JSON add cb26ad88c52 [SPARK-43378][CORE] Properly close stream objects in deserializeFromChunkedBuffer No new revisions were added by this update. Summary of changes: .../src/main/scala/org/apache/spark/serializer/SerializerHelper.scala | 4 +++- 1 file changed, 3 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Update for CVE-2023-32007
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 54ff7efc3b Update for CVE-2023-32007 54ff7efc3b is described below commit 54ff7efc3bc512a57abc99325896bcaeb674d9b4 Author: Sean Owen AuthorDate: Tue May 2 08:57:30 2023 -0500 Update for CVE-2023-32007 --- security.md| 7 ++- site/security.html | 7 ++- 2 files changed, 12 insertions(+), 2 deletions(-) diff --git a/security.md b/security.md index 805e400fa4..182b1e8ef7 100644 --- a/security.md +++ b/security.md @@ -18,6 +18,11 @@ non-public list that will reach the Apache Security team, as well as the Spark P Known security issues +CVE-2023-32007: Apache Spark shell command injection vulnerability via Spark UI + +This CVE is only an update to [CVE-2022-33891](#CVE-2022-33891) to clarify that version 3.1.3 is also +affected. It is otherwise not a new vulnerability. Note that Apache Spark 3.1.x is EOL now. + CVE-2023-22946: Apache Spark proxy-user privilege escalation from malicious configuration class Severity: Medium @@ -81,7 +86,7 @@ Vendor: The Apache Software Foundation Versions Affected: -- 3.1.3 and earlier +- 3.1.3 and earlier (previously, this was marked as fixed in 3.1.3; this change is tracked as [CVE-2023-32007](#CVE-2023-32007)) - 3.2.0 to 3.2.1 Description: diff --git a/site/security.html b/site/security.html index 57b3def5b5..959e474d80 100644 --- a/site/security.html +++ b/site/security.html @@ -133,6 +133,11 @@ non-public list that will reach the Apache Security team, as well as the Spark P Known security issues +CVE-2023-32007: Apache Spark shell command injection vulnerability via Spark UI + +This CVE is only an update to CVE-2022-33891 to clarify that version 3.1.3 is also +affected. It is otherwise not a new vulnerability. Note that Apache Spark 3.1.x is EOL now. + CVE-2023-22946: Apache Spark proxy-user privilege escalation from malicious configuration class Severity: Medium @@ -207,7 +212,7 @@ the logs which would be returned in logs rendered in the UI. Versions Affected: - 3.1.3 and earlier + 3.1.3 and earlier (previously, this was marked as fixed in 3.1.3; this change is tracked as CVE-2023-32007) 3.2.0 to 3.2.1 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-43320][SQL][HIVE] Directly call Hive 2.3.9 API
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new aed6a47580e [SPARK-43320][SQL][HIVE] Directly call Hive 2.3.9 API
aed6a47580e is described below
commit aed6a47580e66f92b0641d5bc08ad833be4724f4
Author: Cheng Pan
AuthorDate: Sat Apr 29 09:38:14 2023 -0500
[SPARK-43320][SQL][HIVE] Directly call Hive 2.3.9 API
### What changes were proposed in this pull request?
Call Hive 2.3.9 API directly instead of reflection, basically reverts
SPARK-37446.
### Why are the changes needed?
Switch to direct calling to achieve compile time check.
Spark does not officially support building against Hive other than 2.3.9,
for cases listed in SPARK-37446, it's the vendor's responsibility to port
HIVE-21563 into their maintained Hive 2.3.8-[vender-custom-version].
See full discussion in https://github.com/apache/spark/pull/40893.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA.
Closes #40995 from pan3793/SPARK-43320.
Authored-by: Cheng Pan
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala | 5 ++---
1 file changed, 2 insertions(+), 3 deletions(-)
diff --git
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
index becca8eae5e..5b0309813fc 100644
---
a/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
+++
b/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
@@ -1347,12 +1347,11 @@ private[hive] object HiveClientImpl extends Logging {
new HiveConf(conf, classOf[HiveConf])
}
try {
- classOf[Hive].getMethod("getWithoutRegisterFns", classOf[HiveConf])
-.invoke(null, hiveConf).asInstanceOf[Hive]
+ Hive.getWithoutRegisterFns(hiveConf)
} catch {
// SPARK-37069: not all Hive versions have the above method (e.g., Hive
2.3.9 has it but
// 2.3.8 don't), therefore here we fallback when encountering the
exception.
- case _: NoSuchMethodException =>
+ case _: NoSuchMethodError =>
Hive.get(hiveConf)
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-43263][BUILD] Upgrade `FasterXML jackson` to 2.15.0
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new a4a274c4e4f [SPARK-43263][BUILD] Upgrade `FasterXML jackson` to 2.15.0
a4a274c4e4f is described below
commit a4a274c4e4f709765e7a8c687347816d8951a681
Author: bjornjorgensen
AuthorDate: Fri Apr 28 08:29:59 2023 -0500
[SPARK-43263][BUILD] Upgrade `FasterXML jackson` to 2.15.0
### What changes were proposed in this pull request?
Upgrade FasterXML jackson from 2.14.2 to 2.15.0
### Why are the changes needed?
Upgrade Snakeyaml to 2.0 (resolves CVE-2022-1471 [CVE-2022-1471 at
nist](https://nvd.nist.gov/vuln/detail/CVE-2022-1471)
### Does this PR introduce _any_ user-facing change?
This PR introduces user-facing changes by implementing streaming read
constraints in the JSONOptions class. The constraints limit the size of input
constructs, improving security and efficiency when processing input data.
Users working with JSON data larger than the following default settings may
need to adjust the constraints accordingly:
Maximum Number value length: 1000 characters (`DEFAULT_MAX_NUM_LEN`)
Maximum String value length: 5,000,000 characters (`DEFAULT_MAX_STRING_LEN`)
Maximum Nesting depth: 1000 levels (`DEFAULT_MAX_DEPTH`)
Additionally, the maximum magnitude of scale for BigDecimal to BigInteger
conversion is set to 100,000 digits (`MAX_BIGINT_SCALE_MAGNITUDE`) and cannot
be changed.
Users can customize the constraints as needed by providing the
corresponding options in the parameters object. If not explicitly specified,
default settings will be applied.
### How was this patch tested?
Pass GA
Closes #40933 from bjornjorgensen/test_jacon.
Authored-by: bjornjorgensen
Signed-off-by: Sean Owen
---
dev/deps/spark-deps-hadoop-3-hive-2.3 | 16 +++---
pom.xml| 4 ++--
.../spark/sql/catalyst/json/JSONOptions.scala | 25 +-
3 files changed, 34 insertions(+), 11 deletions(-)
diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3
b/dev/deps/spark-deps-hadoop-3-hive-2.3
index a6c41cdd726..bd689f9e913 100644
--- a/dev/deps/spark-deps-hadoop-3-hive-2.3
+++ b/dev/deps/spark-deps-hadoop-3-hive-2.3
@@ -97,13 +97,13 @@ httpcore/4.4.16//httpcore-4.4.16.jar
ini4j/0.5.4//ini4j-0.5.4.jar
istack-commons-runtime/3.0.8//istack-commons-runtime-3.0.8.jar
ivy/2.5.1//ivy-2.5.1.jar
-jackson-annotations/2.14.2//jackson-annotations-2.14.2.jar
-jackson-core/2.14.2//jackson-core-2.14.2.jar
-jackson-databind/2.14.2//jackson-databind-2.14.2.jar
-jackson-dataformat-cbor/2.14.2//jackson-dataformat-cbor-2.14.2.jar
-jackson-dataformat-yaml/2.14.2//jackson-dataformat-yaml-2.14.2.jar
-jackson-datatype-jsr310/2.14.2//jackson-datatype-jsr310-2.14.2.jar
-jackson-module-scala_2.12/2.14.2//jackson-module-scala_2.12-2.14.2.jar
+jackson-annotations/2.15.0//jackson-annotations-2.15.0.jar
+jackson-core/2.15.0//jackson-core-2.15.0.jar
+jackson-databind/2.15.0//jackson-databind-2.15.0.jar
+jackson-dataformat-cbor/2.15.0//jackson-dataformat-cbor-2.15.0.jar
+jackson-dataformat-yaml/2.15.0//jackson-dataformat-yaml-2.15.0.jar
+jackson-datatype-jsr310/2.15.0//jackson-datatype-jsr310-2.15.0.jar
+jackson-module-scala_2.12/2.15.0//jackson-module-scala_2.12-2.15.0.jar
jakarta.annotation-api/1.3.5//jakarta.annotation-api-1.3.5.jar
jakarta.inject/2.6.1//jakarta.inject-2.6.1.jar
jakarta.servlet-api/4.0.3//jakarta.servlet-api-4.0.3.jar
@@ -233,7 +233,7 @@ scala-xml_2.12/2.1.0//scala-xml_2.12-2.1.0.jar
shims/0.9.39//shims-0.9.39.jar
slf4j-api/2.0.7//slf4j-api-2.0.7.jar
snakeyaml-engine/2.6//snakeyaml-engine-2.6.jar
-snakeyaml/1.33//snakeyaml-1.33.jar
+snakeyaml/2.0//snakeyaml-2.0.jar
snappy-java/1.1.9.1//snappy-java-1.1.9.1.jar
spire-macros_2.12/0.17.0//spire-macros_2.12-0.17.0.jar
spire-platform_2.12/0.17.0//spire-platform_2.12-0.17.0.jar
diff --git a/pom.xml b/pom.xml
index c74da8e3ace..df7fef1cf79 100644
--- a/pom.xml
+++ b/pom.xml
@@ -184,8 +184,8 @@
true
true
1.9.13
-2.14.2
-
2.14.2
+2.15.0
+
2.15.0
1.1.9.1
3.0.3
1.15
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JSONOptions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JSONOptions.scala
index bf5b83e9df0..c06f411c505 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JSONOptions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/json/JSONOptions.scala
@@ -21,7 +21,7 @@ import java.nio.charset.{Charset, StandardCharsets}
import java.time.ZoneId
import java.util.Locale
-import com.fasterxml.jackson.core.{JsonFactory, JsonFactoryBuilder}
+import com.fasterxml.jackson.core.{JsonFactory, JsonFactoryBuilder
[spark] branch master updated: [SPARK-43277][YARN] Clean up deprecation hadoop api usage in `yarn` module
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 014685c41e4 [SPARK-43277][YARN] Clean up deprecation hadoop api usage
in `yarn` module
014685c41e4 is described below
commit 014685c41e4741f83570d8a2a6a253e48967919a
Author: yangjie01
AuthorDate: Tue Apr 25 22:12:35 2023 -0500
[SPARK-43277][YARN] Clean up deprecation hadoop api usage in `yarn` module
### What changes were proposed in this pull request?
`yarn` module has the following compilation warnings related to the Hadoop
API:
```
[WARNING] [Warn]
/${spark-source-dir}/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala:157:
[deprecation
org.apache.spark.deploy.yarn.ApplicationMaster.prepareLocalResources.setupDistributedCache
| origin=org.apache.hadoop.yarn.util.ConverterUtils.getYarnUrlFromURI |
version=] method getYarnUrlFromURI in class ConverterUtils is deprecated
[WARNING] [Warn]
/${spark-source-dir}/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala:292:
[deprecation
org.apache.spark.deploy.yarn.Client.createApplicationSubmissionContext |
origin=org.apache.hadoop.yarn.api.records.Resource.setMemory | version=] method
setMemory in class Resource is deprecated
[WARNING] [Warn]
/${spark-source-dir}/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala:307:
[deprecation
org.apache.spark.deploy.yarn.Client.createApplicationSubmissionContext |
origin=org.apache.hadoop.yarn.api.records.ApplicationSubmissionContext.setAMContainerResourceRequest
| version=] method setAMContainerResourceRequest in class
ApplicationSubmissionContext is deprecated
[WARNING] [Warn]
/${spark-source-dir}/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala:392:
[deprecation
org.apache.spark.deploy.yarn.Client.verifyClusterResources.maxMem |
origin=org.apache.hadoop.yarn.api.records.Resource.getMemory | version=] method
getMemory in class Resource is deprecated
[WARNING] [Warn]
/${spark-source-dir}/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ClientDistributedCacheManager.scala:76:
[deprecation
org.apache.spark.deploy.yarn.ClientDistributedCacheManager.addResource |
origin=org.apache.hadoop.yarn.util.ConverterUtils.getYarnUrlFromPath |
version=] method getYarnUrlFromPath in class ConverterUtils is deprecated
[WARNING] [Warn]
/${spark-source-dir}/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnAllocator.scala:510:
[deprecation
org.apache.spark.deploy.yarn.YarnAllocator.updateResourceRequests.$anonfun.requestContainerMessage
| origin=org.apache.hadoop.yarn.api.records.Resource.getMemory | version=]
method getMemory in class Resource is deprecated
[WARNING] [Warn]
/${spark-source-dir}/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnAllocator.scala:737:
[deprecation
org.apache.spark.deploy.yarn.YarnAllocator.runAllocatedContainers.$anonfun |
origin=org.apache.hadoop.yarn.api.records.Resource.getMemory | version=] method
getMemory in class Resource is deprecated
[WARNING] [Warn]
/${spark-source-dir}/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnAllocator.scala:737:
[deprecation
org.apache.spark.deploy.yarn.YarnAllocator.runAllocatedContainers.$anonfun |
origin=org.apache.hadoop.yarn.api.records.Resource.getMemory | version=] method
getMemory in class Resource is deprecated
[WARNING] [Warn]
/${spark-source-dir}/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala:202:
[deprecation org.apache.spark.deploy.yarn.YarnSparkHadoopUtil.getContainerId
| origin=org.apache.hadoop.yarn.util.ConverterUtils.toContainerId | version=]
method toContainerId in class ConverterUtils is deprecated
[WARNING] [Warn]
/${spark-source-dir}/resource-managers/yarn/src/main/scala/org/apache/spark/util/YarnContainerInfoHelper.scala:75:
[deprecation org.apache.spark.util.YarnContainerInfoHelper.getAttributes |
origin=org.apache.hadoop.yarn.util.ConverterUtils.toString | version=] method
toString in class ConverterUtils is deprecated
[WARNING] [Warn]
/${spark-source-dir}/resource-managers/yarn/src/test/scala/org/apache/spark/deploy/yarn/ClientDistributedCacheManagerSuite.scala:83:
[deprecation
org.apache.spark.deploy.yarn.ClientDistributedCacheManagerSuite..$org_scalatest_assert_macro_expr.$org_scalatest_assert_macro_left
| origin=org.apache.hadoop.yarn.util.ConverterUtils.getPathFromYarnURL |
version=] method getPathFromYarnURL in class ConverterUtils is deprecated
[WARNING] [Warn]
/${spark-source-dir}/resource-managers/yarn/src/test/scala/org/apache/spark/deploy/yarn/ClientDistributedCacheManagerSuite.scala:105:
[deprecation
[spark] branch master updated (516d7b3d483 -> 9c237d7bc7b)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 516d7b3d483 [SPARK-42798][BUILD] Upgrade protobuf-java to 3.22.3 add 9c237d7bc7b [SPARK-43225][BUILD][SQL] Remove jackson-core-asl and jackson-mapper-asl from pre-built distribution No new revisions were added by this update. Summary of changes: core/pom.xml | 8 dev/deps/spark-deps-hadoop-3-hive-2.3 | 2 -- pom.xml| 23 ++ .../org/apache/hive/service/cli/CLIService.java| 2 +- .../hive/service/cli/session/HiveSessionImpl.java | 4 ++-- .../cli/session/HiveSessionImplwithUGI.java| 4 ++-- 6 files changed, 7 insertions(+), 36 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42798][BUILD] Upgrade protobuf-java to 3.22.3
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 516d7b3d483 [SPARK-42798][BUILD] Upgrade protobuf-java to 3.22.3
516d7b3d483 is described below
commit 516d7b3d483687018fc457ab2fec82c05b169057
Author: YangJie
AuthorDate: Tue Apr 25 08:52:54 2023 -0500
[SPARK-42798][BUILD] Upgrade protobuf-java to 3.22.3
### What changes were proposed in this pull request?
This pr aims upgrade protobuf-java from 3.22.0 to 3.22.3.
### Why are the changes needed?
The new version fixed the issue of `NoSuchMethodError` thrown when using
Java 8 to run proto compiled with Java 9+ (even if --target 1.8):
- https://github.com/protocolbuffers/protobuf/issues/11393 /
https://github.com/protocolbuffers/protobuf/pull/12035
The full release notes as follows:
- https://github.com/protocolbuffers/protobuf/releases/tag/v22.1
- https://github.com/protocolbuffers/protobuf/releases/tag/v22.2
- https://github.com/protocolbuffers/protobuf/releases/tag/v22.3
- https://github.com/protocolbuffers/protobuf/compare/v3.22.0...v3.22.3
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GitHub Actions
Closes #40430 from LuciferYang/SPARK-42798.
Lead-authored-by: YangJie
Co-authored-by: yangjie01
Signed-off-by: Sean Owen
---
pom.xml | 2 +-
project/SparkBuild.scala | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/pom.xml b/pom.xml
index a3b7f57ace9..2cb6ff86bb5 100644
--- a/pom.xml
+++ b/pom.xml
@@ -124,7 +124,7 @@
2.5.0
-3.22.0
+3.22.3
3.11.4
${hadoop.version}
3.6.3
diff --git a/project/SparkBuild.scala b/project/SparkBuild.scala
index d8a6972bae1..25f5ea4fa85 100644
--- a/project/SparkBuild.scala
+++ b/project/SparkBuild.scala
@@ -88,7 +88,7 @@ object BuildCommons {
// Google Protobuf version used for generating the protobuf.
// SPARK-41247: needs to be consistent with `protobuf.version` in `pom.xml`.
- val protoVersion = "3.22.0"
+ val protoVersion = "3.22.3"
// GRPC version used for Spark Connect.
val gprcVersion = "1.47.0"
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-43008][BUILD] Upgrade joda-time from 2.12.2 to 2.12.5
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 00c2c19e0bf [SPARK-43008][BUILD] Upgrade joda-time from 2.12.2 to 2.12.5 00c2c19e0bf is described below commit 00c2c19e0bfba30c9e2a2080f0960a5bfc4b49e3 Author: yangjie01 AuthorDate: Sun Apr 23 09:34:57 2023 -0500 [SPARK-43008][BUILD] Upgrade joda-time from 2.12.2 to 2.12.5 ### What changes were proposed in this pull request? This pr aims upgrade joda-time from 2.12.2 to 2.12.5. ### Why are the changes needed? New version bring a bug fix https://github.com/JodaOrg/joda-time/pull/681 and Update time zone data to version 2023cgtz. - https://www.joda.org/joda-time/changes-report.html#a2.12.5 - https://github.com/JodaOrg/joda-time/compare/v2.12.2...v2.12.5 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass Github Actions Closes #40640 from LuciferYang/SPARK-43008. Lead-authored-by: yangjie01 Co-authored-by: YangJie Signed-off-by: Sean Owen --- dev/deps/spark-deps-hadoop-3-hive-2.3 | 2 +- pom.xml | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3 b/dev/deps/spark-deps-hadoop-3-hive-2.3 index a7625a66e65..c387d5c1793 100644 --- a/dev/deps/spark-deps-hadoop-3-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-3-hive-2.3 @@ -130,7 +130,7 @@ jettison/1.5.3//jettison-1.5.3.jar jetty-util-ajax/9.4.51.v20230217//jetty-util-ajax-9.4.51.v20230217.jar jetty-util/9.4.51.v20230217//jetty-util-9.4.51.v20230217.jar jline/2.14.6//jline-2.14.6.jar -joda-time/2.12.2//joda-time-2.12.2.jar +joda-time/2.12.5//joda-time-2.12.5.jar jodd-core/3.5.2//jodd-core-3.5.2.jar jpam/1.1//jpam-1.1.jar json/1.8//json-1.8.jar diff --git a/pom.xml b/pom.xml index 1d69e295285..a3b7f57ace9 100644 --- a/pom.xml +++ b/pom.xml @@ -200,7 +200,7 @@ 14.0.1 3.1.9 2.36 -2.12.2 +2.12.5 3.5.2 3.0.0 0.12.0 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Remove hadoop2 pre-built for 3.4.0
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch asf-site
in repository https://gitbox.apache.org/repos/asf/spark-website.git
The following commit(s) were added to refs/heads/asf-site by this push:
new 03544c47af Remove hadoop2 pre-built for 3.4.0
03544c47af is described below
commit 03544c47af6464d27d69e9a70de085c42df5f848
Author: Kent Yao
AuthorDate: Thu Apr 20 08:45:20 2023 -0500
Remove hadoop2 pre-built for 3.4.0
Referring to https://archive.apache.org/dist/spark/spark-3.4.0/, the binary
release for hadoop2 is not pre-built and published
Author: Kent Yao
Closes #460 from yaooqinn/hadoop2.
---
js/downloads.js | 4 +++-
site/js/downloads.js | 4 +++-
2 files changed, 6 insertions(+), 2 deletions(-)
diff --git a/js/downloads.js b/js/downloads.js
index 9781273310..974b4ac676 100644
--- a/js/downloads.js
+++ b/js/downloads.js
@@ -24,8 +24,10 @@ var hadoop3pscala213 = {pretty: "Pre-built for Apache Hadoop
3.3 and later (Scal
var packagesV12 = [hadoop3p3, hadoop3p3scala213, hadoop2p7, hadoopFree,
sources];
// 3.3.0+
var packagesV13 = [hadoop3p, hadoop3pscala213, hadoop2p, hadoopFree, sources];
+// 3.4.0+
+var packagesV14 = [hadoop3p, hadoop3pscala213, hadoopFree, sources];
-addRelease("3.4.0", new Date("04/13/2023"), packagesV13, true);
+addRelease("3.4.0", new Date("04/13/2023"), packagesV14, true);
addRelease("3.3.2", new Date("02/17/2023"), packagesV13, true);
addRelease("3.2.4", new Date("04/13/2023"), packagesV12, true);
diff --git a/site/js/downloads.js b/site/js/downloads.js
index 9781273310..974b4ac676 100644
--- a/site/js/downloads.js
+++ b/site/js/downloads.js
@@ -24,8 +24,10 @@ var hadoop3pscala213 = {pretty: "Pre-built for Apache Hadoop
3.3 and later (Scal
var packagesV12 = [hadoop3p3, hadoop3p3scala213, hadoop2p7, hadoopFree,
sources];
// 3.3.0+
var packagesV13 = [hadoop3p, hadoop3pscala213, hadoop2p, hadoopFree, sources];
+// 3.4.0+
+var packagesV14 = [hadoop3p, hadoop3pscala213, hadoopFree, sources];
-addRelease("3.4.0", new Date("04/13/2023"), packagesV13, true);
+addRelease("3.4.0", new Date("04/13/2023"), packagesV14, true);
addRelease("3.3.2", new Date("02/17/2023"), packagesV13, true);
addRelease("3.2.4", new Date("04/13/2023"), packagesV12, true);
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Including ApacheSparkMéxicoCity Meetup on community page
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new b2a33a5de6 Including ApacheSparkMéxicoCity Meetup on community page b2a33a5de6 is described below commit b2a33a5de6a1043ee93cd60722835131af81b0c5 Author: Juan Diaz AuthorDate: Wed Apr 19 14:31:02 2023 -0500 Including ApacheSparkMéxicoCity Meetup on community page Including ApacheSparkMéxicoCity Meetup on community page `While browsing the site, I find out that the site is missing Apache Spark México City. [https://www.meetup.com/es/apache-spark-mexicocity/](https://www.meetup.com/es/apache-spark-mexicocity/) I And would like to include the community on the following web page [https://spark.apache.org/community.html](https://spark.apache.org/community.html) I change the .md and the .html community files. I hope this helps. Author: Juan Diaz juanchodishotmail.com` Author: Juan Diaz Closes #459 from JuanPabloDiaz/asf-site. --- community.md| 5 - site/community.html | 5 - 2 files changed, 8 insertions(+), 2 deletions(-) diff --git a/community.md b/community.md index 6c04ee5f83..e7fdec7c74 100644 --- a/community.md +++ b/community.md @@ -166,11 +166,14 @@ Spark Meetups are grass-roots events organized and hosted by individuals in the https://www.meetup.com/Apache-Spark-Maryland/;>Maryland Spark Meetup -https://www.meetup.com/Mumbai-Spark-Meetup/;>Mumbai Spark Meetup +https://www.meetup.com/es/apache-spark-mexicocity/;>México City Spark Meetup https://www.meetup.com/Apache-Spark-in-Moscow/;>Moscow Spark Meetup + +https://www.meetup.com/Mumbai-Spark-Meetup/;>Mumbai Spark Meetup + https://www.meetup.com/Spark-NYC/;>NYC Spark Meetup diff --git a/site/community.html b/site/community.html index e712a48435..127822931d 100644 --- a/site/community.html +++ b/site/community.html @@ -294,11 +294,14 @@ vulnerabilities, and for information on known security issues. https://www.meetup.com/Apache-Spark-Maryland/;>Maryland Spark Meetup -https://www.meetup.com/Mumbai-Spark-Meetup/;>Mumbai Spark Meetup +https://www.meetup.com/es/apache-spark-mexicocity/;>México City Spark Meetup https://www.meetup.com/Apache-Spark-in-Moscow/;>Moscow Spark Meetup + +https://www.meetup.com/Mumbai-Spark-Meetup/;>Mumbai Spark Meetup + https://www.meetup.com/Spark-NYC/;>NYC Spark Meetup - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Improve instructions for the release process
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new d0a3ad9fe5 Improve instructions for the release process d0a3ad9fe5 is described below commit d0a3ad9fe57a07640160ad88b98c0c5e44eec303 Author: Xinrong Meng AuthorDate: Sat Apr 15 14:22:51 2023 -0500 Improve instructions for the release process Improve instructions for the release process, specifically, the `Finalize the release` step. That includes - point out which steps have been automated - details to pay attention to - typo fixing - more clear steps by naming Author: Xinrong Meng Closes #454 from xinrong-meng/release-process. --- release-process.md| 26 ++ site/release-process.html | 28 2 files changed, 46 insertions(+), 8 deletions(-) diff --git a/release-process.md b/release-process.md index 2133010840..4030352f8b 100644 --- a/release-process.md +++ b/release-process.md @@ -186,6 +186,18 @@ that looks something like `[VOTE][RESULT] ...`. Finalize the release +Note that `dev/create-release/do-release-docker.sh` script (`finalize` step ) automates most of the following steps **except** for: +- Publish to CRAN +- Update the configuration of Algolia Crawler +- Remove old releases from Mirror Network +- Update the rest of the Spark website +- Create and upload Spark Docker Images +- Create an announcement + +Please manually verify the result after each step. + +Upload to Apache release directory + **Be Careful!** **THIS STEP IS IRREVERSIBLE so make sure you selected the correct staging repository. Once you @@ -237,7 +249,7 @@ Publishing to CRAN is done using https://cran.r-project.org/submit.html Since it requires further manual steps, please also contact the mailto:priv...@spark.apache.org;>PMC. - Remove RC artifacts from repositories +Remove RC artifacts from repositories After the vote passes and you moved the approved RC to the release repository, you should delete the RC directories from the staging repository. For example: @@ -279,6 +291,8 @@ The search box on the https://spark.apache.org/docs/latest/;>Spark docu Update the Spark website +Upload generated docs + The website repository is located at https://github.com/apache/spark-website;>https://github.com/apache/spark-website. @@ -297,17 +311,19 @@ $ git clone https://github.com/apache/spark-website $ cp -R _site spark-website/site/docs/1.1.1 # Update the "latest" link -$ cd spark/site/docs +$ cd spark-website/site/docs $ rm latest $ ln -s 1.1.1 latest ``` +Update the rest of the Spark website + Next, update the rest of the Spark website. See how the previous releases are documented (all the HTML file changes are generated by `jekyll`). In particular: * update `_layouts/global.html` if the new release is the latest one * update `documentation.md` to add link to the docs for the new release -* add the new release to `js/downloads.js` +* add the new release to `js/downloads.js` (attention to the order of releases) * check `security.md` for anything to update ``` @@ -324,6 +340,8 @@ be the date you create it. Then run `bundle exec jekyll build` to update the `site` directory. +Considering the Pull Request will be large, please separate the commits of code changes and generated `site` directory for an easier review. + After merging the change into the `asf-site` branch, you may need to create a follow-up empty commit to force synchronization between ASF's git and the web site, and also the GitHub mirror. For some reason synchronization seems to not be reliable for this repository. @@ -393,7 +411,7 @@ Once you have your cross-platform docker build environment setup, extract the bu Create an announcement Once everything is working (website docs, website changes) create an announcement on the website -and then send an e-mail to the mailing list. To create an announcement, create a post under +and then send an e-mail to the mailing list with a subject that looks something like `[ANNOUNCE] ...`. To create an announcement, create a post under `news/_posts` and then run `bundle exec jekyll build`. Enjoy an adult beverage of your choice, and congratulations on making a Spark release. diff --git a/site/release-process.html b/site/release-process.html index 263ba6431e..72d6bd7982 100644 --- a/site/release-process.html +++ b/site/release-process.html @@ -310,6 +310,20 @@ that looks something like [VO Finalize the release +Note that dev/create-release/do-release-docker.sh script (finalize step ) automates most of the following steps except for: + + Publish to CRAN + Update the configuration of Algolia Crawler + Remove old releases from Mirror Network + Update the rest of the Spar
[spark-website] branch asf-site updated: Add CVE-2023-22946
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 28acafb092 Add CVE-2023-22946 28acafb092 is described below commit 28acafb0929be2f9aef1fa09c0683566b057bba8 Author: Sean Owen AuthorDate: Sat Apr 15 08:29:48 2023 -0500 Add CVE-2023-22946 --- security.md| 29 + site/security.html | 34 ++ 2 files changed, 63 insertions(+) diff --git a/security.md b/security.md index 5147a7e915..805e400fa4 100644 --- a/security.md +++ b/security.md @@ -18,6 +18,35 @@ non-public list that will reach the Apache Security team, as well as the Spark P Known security issues +CVE-2023-22946: Apache Spark proxy-user privilege escalation from malicious configuration class + +Severity: Medium + +Vendor: The Apache Software Foundation + +Versions Affected: + +- Versions prior to 3.4.0 + +Description: + +In Apache Spark versions prior to 3.4.0, applications using spark-submit can specify a 'proxy-user' to run as, +limiting privileges. The application can execute code with the privileges of the submitting user, however, by +providing malicious configuration-related classes on the classpath. This affects architectures relying on +proxy-user, for example those using Apache Livy to manage submitted applications. + +This issue is being tracked as SPARK-41958 + +Mitigation: + +- Update to Apache Spark 3.4.0 or later, and ensure that `spark.submit.proxyUser.allowCustomClasspathInClusterMode` is set to its default of "false", and is not overridden by submitted applications. + +Credit: + +- Hideyuki Furue (finder) +- Yi Wu (Databricks) (remediation developer) + + CVE-2022-31777: Apache Spark XSS vulnerability in log viewer UI Javascript Severity: Medium diff --git a/site/security.html b/site/security.html index 1c3128a493..57b3def5b5 100644 --- a/site/security.html +++ b/site/security.html @@ -133,6 +133,40 @@ non-public list that will reach the Apache Security team, as well as the Spark P Known security issues +CVE-2023-22946: Apache Spark proxy-user privilege escalation from malicious configuration class + +Severity: Medium + +Vendor: The Apache Software Foundation + +Versions Affected: + + + Versions prior to 3.4.0 + + +Description: + +In Apache Spark versions prior to 3.4.0, applications using spark-submit can specify a proxy-user to run as, +limiting privileges. The application can execute code with the privileges of the submitting user, however, by +providing malicious configuration-related classes on the classpath. This affects architectures relying on +proxy-user, for example those using Apache Livy to manage submitted applications. + +This issue is being tracked as SPARK-41958 + +Mitigation: + + + Update to Apache Spark 3.4.0 or later, and ensure that spark.submit.proxyUser.allowCustomClasspathInClusterMode is set to its default of false, and is not overridden by submitted applications. + + +Credit: + + + Hideyuki Furue (finder) + Yi Wu (Databricks) (remediation developer) + + CVE-2022-31777: Apache Spark XSS vulnerability in log viewer UI Javascript Severity: Medium - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42974][CORE] Restore `Utils.createTempDir` to use the `ShutdownHookManager` and clean up `JavaUtils.createTempDir` method
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 707408d98dc [SPARK-42974][CORE] Restore `Utils.createTempDir` to use
the `ShutdownHookManager` and clean up `JavaUtils.createTempDir` method
707408d98dc is described below
commit 707408d98dce8a0f56c29bef0ecd0010f7d9f3c2
Author: yangjie01
AuthorDate: Mon Apr 3 08:28:25 2023 -0500
[SPARK-42974][CORE] Restore `Utils.createTempDir` to use the
`ShutdownHookManager` and clean up `JavaUtils.createTempDir` method
### What changes were proposed in this pull request?
The main change of this pr as follows:
1. Make `Utils.createTempDir` and `JavaUtils.createTempDir` back to two
independent implementations to restore `Utils.createTempDir` to use the
`spark.util.ShutdownHookManager` mechanism.
2. Use `Utils.createTempDir` or `JavaUtils.createDirectory` instead for
testing where `JavaUtils.createTempDir` is used.
3. Clean up `JavaUtils.createTempDir` method
### Why are the changes needed?
Restore `Utils.createTempDir` to use the `spark.util.ShutdownHookManager`
mechanism and clean up `JavaUtils.createTempDir` method.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GitHub Actions
Closes #40613 from LuciferYang/revert-SPARK-39204.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../org/apache/spark/network/util/JavaUtils.java | 20
.../org/apache/spark/network/StreamTestHelper.java | 2 +-
.../network/shuffle/ExternalBlockHandlerSuite.java | 2 +-
.../network/shuffle/TestShuffleDataContext.java | 3 ++-
.../spark/network/yarn/YarnShuffleService.java | 4 +++-
.../src/main/scala/org/apache/spark/util/Utils.scala | 11 ++-
.../java/test/org/apache/spark/Java8RDDAPISuite.java | 3 +--
.../java/test/org/apache/spark/JavaAPISuite.java | 4 ++--
.../org/apache/spark/streaming/JavaAPISuite.java | 5 ++---
9 files changed, 22 insertions(+), 32 deletions(-)
diff --git
a/common/network-common/src/main/java/org/apache/spark/network/util/JavaUtils.java
b/common/network-common/src/main/java/org/apache/spark/network/util/JavaUtils.java
index 544fe16a569..7e410e9eab2 100644
---
a/common/network-common/src/main/java/org/apache/spark/network/util/JavaUtils.java
+++
b/common/network-common/src/main/java/org/apache/spark/network/util/JavaUtils.java
@@ -368,26 +368,6 @@ public class JavaUtils {
}
}
- /**
- * Create a temporary directory inside `java.io.tmpdir` with default
namePrefix "spark".
- * The directory will be automatically deleted when the VM shuts down.
- */
- public static File createTempDir() throws IOException {
-return createTempDir(System.getProperty("java.io.tmpdir"), "spark");
- }
-
- /**
- * Create a temporary directory inside the given parent directory. The
directory will be
- * automatically deleted when the VM shuts down.
- */
- public static File createTempDir(String root, String namePrefix) throws
IOException {
-if (root == null) root = System.getProperty("java.io.tmpdir");
-if (namePrefix == null) namePrefix = "spark";
-File dir = createDirectory(root, namePrefix);
-dir.deleteOnExit();
-return dir;
- }
-
/**
* Create a directory inside the given parent directory with default
namePrefix "spark".
* The directory is guaranteed to be newly created, and is not marked for
automatic deletion.
diff --git
a/common/network-common/src/test/java/org/apache/spark/network/StreamTestHelper.java
b/common/network-common/src/test/java/org/apache/spark/network/StreamTestHelper.java
index 3ba6a585653..da83e549d1c 100644
---
a/common/network-common/src/test/java/org/apache/spark/network/StreamTestHelper.java
+++
b/common/network-common/src/test/java/org/apache/spark/network/StreamTestHelper.java
@@ -49,7 +49,7 @@ class StreamTestHelper {
}
StreamTestHelper() throws Exception {
-tempDir = JavaUtils.createTempDir();
+tempDir = JavaUtils.createDirectory(System.getProperty("java.io.tmpdir"),
"spark");
emptyBuffer = createBuffer(0);
smallBuffer = createBuffer(100);
largeBuffer = createBuffer(10);
diff --git
a/common/network-shuffle/src/test/java/org/apache/spark/network/shuffle/ExternalBlockHandlerSuite.java
b/common/network-shuffle/src/test/java/org/apache/spark/network/shuffle/ExternalBlockHandlerSuite.java
index 54f29fedf83..44dcb71f753 100644
---
a/common/network-shuffle/src/test/java/org/apache/spark/network/shuffle/ExternalBlockHandlerSuite.java
+++
b/common/network-shuffle/src/test/java/org/apache/spark/network/shuffle/ExternalBlockHandlerSuite.java
@@ -125,7 +125,7 @@ p
[spark] branch branch-3.4 updated: [SPARK-43006][PYSPARK] Fix typo in StorageLevel __eq__()
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.4 by this push: new 54d1b625716 [SPARK-43006][PYSPARK] Fix typo in StorageLevel __eq__() 54d1b625716 is described below commit 54d1b6257165385edfe7b0bff69d775218369b11 Author: thyecust AuthorDate: Mon Apr 3 08:26:00 2023 -0500 [SPARK-43006][PYSPARK] Fix typo in StorageLevel __eq__() ### What changes were proposed in this pull request? fix `self.deserialized == self.deserialized` with `self.deserialized == other.deserialized` ### Why are the changes needed? The original expression is always True, which is likely to be a typo. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? No test added. Use GitHub Actions. Closes #40619 from thyecust/patch-1. Authored-by: thyecust Signed-off-by: Sean Owen (cherry picked from commit f57c3686a4fc5cf6c15442c116155b75d338a35d) Signed-off-by: Sean Owen --- python/pyspark/storagelevel.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/python/pyspark/storagelevel.py b/python/pyspark/storagelevel.py index c9a70fabdf7..dabc0d2717c 100644 --- a/python/pyspark/storagelevel.py +++ b/python/pyspark/storagelevel.py @@ -80,7 +80,7 @@ class StorageLevel: and self.useMemory == other.useMemory and self.useDisk == other.useDisk and self.useOffHeap == other.useOffHeap -and self.deserialized == self.deserialized +and self.deserialized == other.deserialized and self.replication == other.replication ) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (5ac2b0fc024 -> f57c3686a4f)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 5ac2b0fc024 [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py add f57c3686a4f [SPARK-43006][PYSPARK] Fix typo in StorageLevel __eq__() No new revisions were added by this update. Summary of changes: python/pyspark/storagelevel.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.2 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.2 by this push: new 7773740e414 [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py 7773740e414 is described below commit 7773740e4141444bf78ba75dcee9f3fade7f6e11 Author: thyecust AuthorDate: Mon Apr 3 08:24:17 2023 -0500 [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py By comparing compute.isin_limit and plotting.max_rows, `v is v` is likely to be a typo. ### What changes were proposed in this pull request? fix `v is v >= 0` with `v >= 0`. ### Why are the changes needed? By comparing compute.isin_limit and plotting.max_rows, `v is v` is likely to be a typo. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By GitHub Actions. Closes #40620 from thyecust/patch-2. Authored-by: thyecust Signed-off-by: Sean Owen (cherry picked from commit 5ac2b0fc024ae499119dfd5ab2ee4d038418c5fd) Signed-off-by: Sean Owen --- python/pyspark/pandas/config.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/python/pyspark/pandas/config.py b/python/pyspark/pandas/config.py index b03f2e13790..a89c8dda3dd 100644 --- a/python/pyspark/pandas/config.py +++ b/python/pyspark/pandas/config.py @@ -204,7 +204,7 @@ _options = [ default=1000, types=int, check_func=( -lambda v: v is v >= 0, +lambda v: v >= 0, "'plotting.max_rows' should be greater than or equal to 0.", ), ), - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.3 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.3 by this push: new b40e408ea13 [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py b40e408ea13 is described below commit b40e408ea13d9d2d55d407f0758940cbba5ade3e Author: thyecust AuthorDate: Mon Apr 3 08:24:17 2023 -0500 [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py By comparing compute.isin_limit and plotting.max_rows, `v is v` is likely to be a typo. ### What changes were proposed in this pull request? fix `v is v >= 0` with `v >= 0`. ### Why are the changes needed? By comparing compute.isin_limit and plotting.max_rows, `v is v` is likely to be a typo. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By GitHub Actions. Closes #40620 from thyecust/patch-2. Authored-by: thyecust Signed-off-by: Sean Owen (cherry picked from commit 5ac2b0fc024ae499119dfd5ab2ee4d038418c5fd) Signed-off-by: Sean Owen --- python/pyspark/pandas/config.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/python/pyspark/pandas/config.py b/python/pyspark/pandas/config.py index a0b8db67758..b96828333ef 100644 --- a/python/pyspark/pandas/config.py +++ b/python/pyspark/pandas/config.py @@ -233,7 +233,7 @@ _options: List[Option] = [ default=1000, types=int, check_func=( -lambda v: v is v >= 0, +lambda v: v >= 0, "'plotting.max_rows' should be greater than or equal to 0.", ), ), - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.4 by this push: new 9244afb5624 [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py 9244afb5624 is described below commit 9244afb5624dd9ca526f28eb233fbaac32a062c7 Author: thyecust AuthorDate: Mon Apr 3 08:24:17 2023 -0500 [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py By comparing compute.isin_limit and plotting.max_rows, `v is v` is likely to be a typo. ### What changes were proposed in this pull request? fix `v is v >= 0` with `v >= 0`. ### Why are the changes needed? By comparing compute.isin_limit and plotting.max_rows, `v is v` is likely to be a typo. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By GitHub Actions. Closes #40620 from thyecust/patch-2. Authored-by: thyecust Signed-off-by: Sean Owen (cherry picked from commit 5ac2b0fc024ae499119dfd5ab2ee4d038418c5fd) Signed-off-by: Sean Owen --- python/pyspark/pandas/config.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/python/pyspark/pandas/config.py b/python/pyspark/pandas/config.py index 7c084bd9e22..ffc5154e49c 100644 --- a/python/pyspark/pandas/config.py +++ b/python/pyspark/pandas/config.py @@ -270,7 +270,7 @@ _options: List[Option] = [ default=1000, types=int, check_func=( -lambda v: v is v >= 0, +lambda v: v >= 0, "'plotting.max_rows' should be greater than or equal to 0.", ), ), - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 5ac2b0fc024 [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py 5ac2b0fc024 is described below commit 5ac2b0fc024ae499119dfd5ab2ee4d038418c5fd Author: thyecust AuthorDate: Mon Apr 3 08:24:17 2023 -0500 [SPARK-43005][PYSPARK] Fix typo in pyspark/pandas/config.py By comparing compute.isin_limit and plotting.max_rows, `v is v` is likely to be a typo. ### What changes were proposed in this pull request? fix `v is v >= 0` with `v >= 0`. ### Why are the changes needed? By comparing compute.isin_limit and plotting.max_rows, `v is v` is likely to be a typo. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? By GitHub Actions. Closes #40620 from thyecust/patch-2. Authored-by: thyecust Signed-off-by: Sean Owen --- python/pyspark/pandas/config.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/python/pyspark/pandas/config.py b/python/pyspark/pandas/config.py index 7c084bd9e22..ffc5154e49c 100644 --- a/python/pyspark/pandas/config.py +++ b/python/pyspark/pandas/config.py @@ -270,7 +270,7 @@ _options: List[Option] = [ default=1000, types=int, check_func=( -lambda v: v is v >= 0, +lambda v: v >= 0, "'plotting.max_rows' should be greater than or equal to 0.", ), ), - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-43004][CORE] Fix typo in ResourceRequest.equals()
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new 807abf9c53e [SPARK-43004][CORE] Fix typo in ResourceRequest.equals()
807abf9c53e is described below
commit 807abf9c53ee8c1c7ef69646ebd8a266f60d5580
Author: thyecust
AuthorDate: Sun Apr 2 22:36:04 2023 -0500
[SPARK-43004][CORE] Fix typo in ResourceRequest.equals()
vendor == vendor is always true, this is likely to be a typo.
### What changes were proposed in this pull request?
fix `vendor == vendor` with `that.vendor == vendor`, and `discoveryScript
== discoveryScript` with `that.discoveryScript == discoveryScript`
### Why are the changes needed?
vendor == vendor is always true, this is likely to be a typo.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
By GitHub Actions.
Closes #40622 from thyecust/patch-4.
Authored-by: thyecust
Signed-off-by: Sean Owen
(cherry picked from commit 52c000ece27c9ef34969a7fb252714588f395926)
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala
b/core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala
index 0e18ecf0e51..6e294397a3c 100644
--- a/core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala
+++ b/core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala
@@ -87,8 +87,8 @@ class ResourceRequest(
obj match {
case that: ResourceRequest =>
that.getClass == this.getClass &&
- that.id == id && that.amount == amount && discoveryScript ==
discoveryScript &&
- vendor == vendor
+ that.id == id && that.amount == amount && that.discoveryScript ==
discoveryScript &&
+ that.vendor == vendor
case _ =>
false
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-43004][CORE] Fix typo in ResourceRequest.equals()
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 568fbcfd8b2 [SPARK-43004][CORE] Fix typo in ResourceRequest.equals()
568fbcfd8b2 is described below
commit 568fbcfd8b2125064cdd40a6977b15e4dbb18b23
Author: thyecust
AuthorDate: Sun Apr 2 22:36:04 2023 -0500
[SPARK-43004][CORE] Fix typo in ResourceRequest.equals()
vendor == vendor is always true, this is likely to be a typo.
### What changes were proposed in this pull request?
fix `vendor == vendor` with `that.vendor == vendor`, and `discoveryScript
== discoveryScript` with `that.discoveryScript == discoveryScript`
### Why are the changes needed?
vendor == vendor is always true, this is likely to be a typo.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
By GitHub Actions.
Closes #40622 from thyecust/patch-4.
Authored-by: thyecust
Signed-off-by: Sean Owen
(cherry picked from commit 52c000ece27c9ef34969a7fb252714588f395926)
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala
b/core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala
index 837b2d80aac..cf6dd9c147a 100644
--- a/core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala
+++ b/core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala
@@ -87,8 +87,8 @@ class ResourceRequest(
obj match {
case that: ResourceRequest =>
that.getClass == this.getClass &&
- that.id == id && that.amount == amount && discoveryScript ==
discoveryScript &&
- vendor == vendor
+ that.id == id && that.amount == amount && that.discoveryScript ==
discoveryScript &&
+ that.vendor == vendor
case _ =>
false
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (6bac24e39f8 -> 52c000ece27)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 6bac24e39f8 [SPARK-42806][SPARK-42811][CONNECT] Add `Catalog` support add 52c000ece27 [SPARK-43004][CORE] Fix typo in ResourceRequest.equals() No new revisions were added by this update. Summary of changes: core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-43004][CORE] Fix typo in ResourceRequest.equals()
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 92e8d26fee9 [SPARK-43004][CORE] Fix typo in ResourceRequest.equals()
92e8d26fee9 is described below
commit 92e8d26fee9ed85234d110a53bfac69bcf16f527
Author: thyecust
AuthorDate: Sun Apr 2 22:36:04 2023 -0500
[SPARK-43004][CORE] Fix typo in ResourceRequest.equals()
vendor == vendor is always true, this is likely to be a typo.
### What changes were proposed in this pull request?
fix `vendor == vendor` with `that.vendor == vendor`, and `discoveryScript
== discoveryScript` with `that.discoveryScript == discoveryScript`
### Why are the changes needed?
vendor == vendor is always true, this is likely to be a typo.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
By GitHub Actions.
Closes #40622 from thyecust/patch-4.
Authored-by: thyecust
Signed-off-by: Sean Owen
(cherry picked from commit 52c000ece27c9ef34969a7fb252714588f395926)
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala
b/core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala
index 3f0a0d36dff..0762ee9c73e 100644
--- a/core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala
+++ b/core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala
@@ -87,8 +87,8 @@ class ResourceRequest(
obj match {
case that: ResourceRequest =>
that.getClass == this.getClass &&
- that.id == id && that.amount == amount && discoveryScript ==
discoveryScript &&
- vendor == vendor
+ that.id == id && that.amount == amount && that.discoveryScript ==
discoveryScript &&
+ that.vendor == vendor
case _ =>
false
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: typo: StogeLevel -> StorageLevel
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 03531a20ec2 typo: StogeLevel -> StorageLevel 03531a20ec2 is described below commit 03531a20ec26871b5da586f10a19d7dd7549ba7d Author: Siarhei Fedartsou AuthorDate: Sat Apr 1 14:23:51 2023 -0500 typo: StogeLevel -> StorageLevel ### What changes were proposed in this pull request? Just a typo fix. ### Why are the changes needed? Just to make things cleaner. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? It seems no testing required. Closes #39880 from SiarheiFedartsou/fix/type-stogelevel-storagelevel. Authored-by: Siarhei Fedartsou Signed-off-by: Sean Owen --- python/pyspark/pandas/spark/accessors.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/python/pyspark/pandas/spark/accessors.py b/python/pyspark/pandas/spark/accessors.py index 2e64469747b..4dd4da4f846 100644 --- a/python/pyspark/pandas/spark/accessors.py +++ b/python/pyspark/pandas/spark/accessors.py @@ -564,7 +564,7 @@ class SparkFrameMethods: ) -> "CachedDataFrame": """ Yields and caches the current DataFrame with a specific StorageLevel. -If a StogeLevel is not given, the `MEMORY_AND_DISK` level is used by default like PySpark. +If a StorageLevel is not given, the `MEMORY_AND_DISK` level is used by default like PySpark. The pandas-on-Spark DataFrame is yielded as a protected resource and its corresponding data is cached which gets uncached after execution goes off the context. - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-42927][CORE] Change the access scope of `o.a.spark.util.Iterators#size` to `private[util]`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new 312447055b3 [SPARK-42927][CORE] Change the access scope of
`o.a.spark.util.Iterators#size` to `private[util]`
312447055b3 is described below
commit 312447055b34a943f329c35e588dbd460fa4f7a1
Author: yangjie01
AuthorDate: Tue Mar 28 09:06:50 2023 -0500
[SPARK-42927][CORE] Change the access scope of
`o.a.spark.util.Iterators#size` to `private[util]`
### What changes were proposed in this pull request?
https://github.com/apache/spark/pull/37353 introduce
`o.a.spark.util.Iterators#size` to speed up get `Iterator` size when using
Scala 2.13. It will only be used by `o.a.spark.util.Utils#getIteratorSize`, and
will disappear when Spark only supports Scala 2.13. It should not be public, so
this pr change it access scope to `private[util]`.
### Why are the changes needed?
`o.a.spark.util.Iterators#size` should not public.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Pass GitHub Actions
Closes #40556 from LuciferYang/SPARK-42927.
Authored-by: yangjie01
Signed-off-by: Sean Owen
(cherry picked from commit 6e4c352d5f91f8343cec748fea4723178d5ae9af)
Signed-off-by: Sean Owen
---
core/src/main/scala-2.12/org/apache/spark/util/Iterators.scala | 2 +-
core/src/main/scala-2.13/org/apache/spark/util/Iterators.scala | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/core/src/main/scala-2.12/org/apache/spark/util/Iterators.scala
b/core/src/main/scala-2.12/org/apache/spark/util/Iterators.scala
index 59530b4ba27..af5f369de53 100644
--- a/core/src/main/scala-2.12/org/apache/spark/util/Iterators.scala
+++ b/core/src/main/scala-2.12/org/apache/spark/util/Iterators.scala
@@ -17,7 +17,7 @@
package org.apache.spark.util
-object Iterators {
+private[util] object Iterators {
/**
* Counts the number of elements of an iterator using a while loop rather
than calling
diff --git a/core/src/main/scala-2.13/org/apache/spark/util/Iterators.scala
b/core/src/main/scala-2.13/org/apache/spark/util/Iterators.scala
index 0ffba8d13a3..9756cf49b95 100644
--- a/core/src/main/scala-2.13/org/apache/spark/util/Iterators.scala
+++ b/core/src/main/scala-2.13/org/apache/spark/util/Iterators.scala
@@ -17,7 +17,7 @@
package org.apache.spark.util
-object Iterators {
+private[util] object Iterators {
/**
* Counts the number of elements of an iterator.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42927][CORE] Change the access scope of `o.a.spark.util.Iterators#size` to `private[util]`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 6e4c352d5f9 [SPARK-42927][CORE] Change the access scope of
`o.a.spark.util.Iterators#size` to `private[util]`
6e4c352d5f9 is described below
commit 6e4c352d5f91f8343cec748fea4723178d5ae9af
Author: yangjie01
AuthorDate: Tue Mar 28 09:06:50 2023 -0500
[SPARK-42927][CORE] Change the access scope of
`o.a.spark.util.Iterators#size` to `private[util]`
### What changes were proposed in this pull request?
https://github.com/apache/spark/pull/37353 introduce
`o.a.spark.util.Iterators#size` to speed up get `Iterator` size when using
Scala 2.13. It will only be used by `o.a.spark.util.Utils#getIteratorSize`, and
will disappear when Spark only supports Scala 2.13. It should not be public, so
this pr change it access scope to `private[util]`.
### Why are the changes needed?
`o.a.spark.util.Iterators#size` should not public.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Pass GitHub Actions
Closes #40556 from LuciferYang/SPARK-42927.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
core/src/main/scala-2.12/org/apache/spark/util/Iterators.scala | 2 +-
core/src/main/scala-2.13/org/apache/spark/util/Iterators.scala | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/core/src/main/scala-2.12/org/apache/spark/util/Iterators.scala
b/core/src/main/scala-2.12/org/apache/spark/util/Iterators.scala
index 59530b4ba27..af5f369de53 100644
--- a/core/src/main/scala-2.12/org/apache/spark/util/Iterators.scala
+++ b/core/src/main/scala-2.12/org/apache/spark/util/Iterators.scala
@@ -17,7 +17,7 @@
package org.apache.spark.util
-object Iterators {
+private[util] object Iterators {
/**
* Counts the number of elements of an iterator using a while loop rather
than calling
diff --git a/core/src/main/scala-2.13/org/apache/spark/util/Iterators.scala
b/core/src/main/scala-2.13/org/apache/spark/util/Iterators.scala
index 0ffba8d13a3..9756cf49b95 100644
--- a/core/src/main/scala-2.13/org/apache/spark/util/Iterators.scala
+++ b/core/src/main/scala-2.13/org/apache/spark/util/Iterators.scala
@@ -17,7 +17,7 @@
package org.apache.spark.util
-object Iterators {
+private[util] object Iterators {
/**
* Counts the number of elements of an iterator.
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-42922][SQL] Move from Random to SecureRandom
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 4aa88606295 [SPARK-42922][SQL] Move from Random to SecureRandom
4aa88606295 is described below
commit 4aa886062952d715118c92bcb581e8a4f60ccc0a
Author: Mridul Muralidharan
AuthorDate: Mon Mar 27 22:48:05 2023 -0500
[SPARK-42922][SQL] Move from Random to SecureRandom
### What changes were proposed in this pull request?
Most uses of `Random` in spark are either in testcases or where we need a
pseudo random number which is repeatable.
Use `SecureRandom`, instead of `Random` for the cases where it impacts
security.
### Why are the changes needed?
Use of `SecureRandom` in more security sensitive contexts.
This was flagged in our internal scans as well.
### Does this PR introduce _any_ user-facing change?
Directly no.
Would improve security posture of Apache Spark.
### How was this patch tested?
Existing unit tests
Closes #40568 from mridulm/SPARK-42922.
Authored-by: Mridul Muralidharan
Signed-off-by: Sean Owen
(cherry picked from commit 744434358cb0c687b37d37dd62f2e7d837e52b2d)
Signed-off-by: Sean Owen
---
.../src/main/java/org/apache/hive/service/auth/HttpAuthUtils.java| 5 +++--
.../java/org/apache/hive/service/cli/thrift/ThriftHttpServlet.java | 4 ++--
2 files changed, 5 insertions(+), 4 deletions(-)
diff --git
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/auth/HttpAuthUtils.java
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/auth/HttpAuthUtils.java
index 4183cba0c68..08a8258db06 100644
---
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/auth/HttpAuthUtils.java
+++
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/auth/HttpAuthUtils.java
@@ -20,11 +20,11 @@ package org.apache.hive.service.auth;
import java.security.AccessControlContext;
import java.security.AccessController;
import java.security.PrivilegedExceptionAction;
+import java.security.SecureRandom;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
-import java.util.Random;
import java.util.Set;
import java.util.StringTokenizer;
@@ -57,6 +57,7 @@ public final class HttpAuthUtils {
private static final String COOKIE_KEY_VALUE_SEPARATOR = "=";
private static final Set COOKIE_ATTRIBUTES =
new HashSet(Arrays.asList(COOKIE_CLIENT_USER_NAME,
COOKIE_CLIENT_RAND_NUMBER));
+ private static final SecureRandom random = new SecureRandom();
/**
* @return Stringified Base64 encoded kerberosAuthHeader on success
@@ -95,7 +96,7 @@ public final class HttpAuthUtils {
sb.append(COOKIE_CLIENT_USER_NAME).append(COOKIE_KEY_VALUE_SEPARATOR).append(clientUserName)
.append(COOKIE_ATTR_SEPARATOR);
sb.append(COOKIE_CLIENT_RAND_NUMBER).append(COOKIE_KEY_VALUE_SEPARATOR)
- .append((new Random(System.currentTimeMillis())).nextLong());
+ .append(random.nextLong());
return sb.toString();
}
diff --git
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/thrift/ThriftHttpServlet.java
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/thrift/ThriftHttpServlet.java
index f0f5cdcd38f..712b1d49eac 100644
---
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/thrift/ThriftHttpServlet.java
+++
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/thrift/ThriftHttpServlet.java
@@ -20,8 +20,8 @@ package org.apache.hive.service.cli.thrift;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.security.PrivilegedExceptionAction;
+import java.security.SecureRandom;
import java.util.Map;
-import java.util.Random;
import java.util.Set;
import java.util.concurrent.TimeUnit;
@@ -76,7 +76,7 @@ public class ThriftHttpServlet extends TServlet {
// Class members for cookie based authentication.
private CookieSigner signer;
public static final String AUTH_COOKIE = "hive.server2.auth";
- private static final Random RAN = new Random();
+ private static final SecureRandom RAN = new SecureRandom();
private boolean isCookieAuthEnabled;
private String cookieDomain;
private String cookiePath;
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-42922][SQL] Move from Random to SecureRandom
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new 2cd341f7e36 [SPARK-42922][SQL] Move from Random to SecureRandom
2cd341f7e36 is described below
commit 2cd341f7e36525f0de1fe5447809a5cda92a6769
Author: Mridul Muralidharan
AuthorDate: Mon Mar 27 22:48:05 2023 -0500
[SPARK-42922][SQL] Move from Random to SecureRandom
### What changes were proposed in this pull request?
Most uses of `Random` in spark are either in testcases or where we need a
pseudo random number which is repeatable.
Use `SecureRandom`, instead of `Random` for the cases where it impacts
security.
### Why are the changes needed?
Use of `SecureRandom` in more security sensitive contexts.
This was flagged in our internal scans as well.
### Does this PR introduce _any_ user-facing change?
Directly no.
Would improve security posture of Apache Spark.
### How was this patch tested?
Existing unit tests
Closes #40568 from mridulm/SPARK-42922.
Authored-by: Mridul Muralidharan
Signed-off-by: Sean Owen
(cherry picked from commit 744434358cb0c687b37d37dd62f2e7d837e52b2d)
Signed-off-by: Sean Owen
---
.../src/main/java/org/apache/hive/service/auth/HttpAuthUtils.java| 5 +++--
.../java/org/apache/hive/service/cli/thrift/ThriftHttpServlet.java | 4 ++--
2 files changed, 5 insertions(+), 4 deletions(-)
diff --git
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/auth/HttpAuthUtils.java
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/auth/HttpAuthUtils.java
index 4183cba0c68..08a8258db06 100644
---
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/auth/HttpAuthUtils.java
+++
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/auth/HttpAuthUtils.java
@@ -20,11 +20,11 @@ package org.apache.hive.service.auth;
import java.security.AccessControlContext;
import java.security.AccessController;
import java.security.PrivilegedExceptionAction;
+import java.security.SecureRandom;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
-import java.util.Random;
import java.util.Set;
import java.util.StringTokenizer;
@@ -57,6 +57,7 @@ public final class HttpAuthUtils {
private static final String COOKIE_KEY_VALUE_SEPARATOR = "=";
private static final Set COOKIE_ATTRIBUTES =
new HashSet(Arrays.asList(COOKIE_CLIENT_USER_NAME,
COOKIE_CLIENT_RAND_NUMBER));
+ private static final SecureRandom random = new SecureRandom();
/**
* @return Stringified Base64 encoded kerberosAuthHeader on success
@@ -95,7 +96,7 @@ public final class HttpAuthUtils {
sb.append(COOKIE_CLIENT_USER_NAME).append(COOKIE_KEY_VALUE_SEPARATOR).append(clientUserName)
.append(COOKIE_ATTR_SEPARATOR);
sb.append(COOKIE_CLIENT_RAND_NUMBER).append(COOKIE_KEY_VALUE_SEPARATOR)
- .append((new Random(System.currentTimeMillis())).nextLong());
+ .append(random.nextLong());
return sb.toString();
}
diff --git
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/thrift/ThriftHttpServlet.java
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/thrift/ThriftHttpServlet.java
index f0f5cdcd38f..712b1d49eac 100644
---
a/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/thrift/ThriftHttpServlet.java
+++
b/sql/hive-thriftserver/src/main/java/org/apache/hive/service/cli/thrift/ThriftHttpServlet.java
@@ -20,8 +20,8 @@ package org.apache.hive.service.cli.thrift;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.security.PrivilegedExceptionAction;
+import java.security.SecureRandom;
import java.util.Map;
-import java.util.Random;
import java.util.Set;
import java.util.concurrent.TimeUnit;
@@ -76,7 +76,7 @@ public class ThriftHttpServlet extends TServlet {
// Class members for cookie based authentication.
private CookieSigner signer;
public static final String AUTH_COOKIE = "hive.server2.auth";
- private static final Random RAN = new Random();
+ private static final SecureRandom RAN = new SecureRandom();
private boolean isCookieAuthEnabled;
private String cookieDomain;
private String cookiePath;
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (31965a06c9f -> 744434358cb)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 31965a06c9f [SPARK-41876][CONNECT][PYTHON] Implement DataFrame.toLocalIterator add 744434358cb [SPARK-42922][SQL] Move from Random to SecureRandom No new revisions were added by this update. Summary of changes: .../src/main/java/org/apache/hive/service/auth/HttpAuthUtils.java| 5 +++-- .../java/org/apache/hive/service/cli/thrift/ThriftHttpServlet.java | 4 ++-- 2 files changed, 5 insertions(+), 4 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (5825db81e00 -> 7ad1c80f281)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 5825db81e00 [SPARK-42052][SQL] Codegen Support for HiveSimpleUDF add 7ad1c80f281 [SPARK-42880][DOCS] Update running-on-yarn.md to log4j2 syntax No new revisions were added by this update. Summary of changes: docs/running-on-yarn.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42808][CORE] Avoid getting availableProcessors every time in `MapOutputTrackerMaster#getStatistics`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c04e0de0733 [SPARK-42808][CORE] Avoid getting availableProcessors
every time in `MapOutputTrackerMaster#getStatistics`
c04e0de0733 is described below
commit c04e0de073354458f89d30733134a004fe2a25bd
Author: sychen
AuthorDate: Tue Mar 21 09:57:06 2023 -0500
[SPARK-42808][CORE] Avoid getting availableProcessors every time in
`MapOutputTrackerMaster#getStatistics`
### What changes were proposed in this pull request?
The return value of `Runtime.getRuntime.availableProcessors` is generally a
fixed value. It is not necessary to obtain it every time `getStatistics` is
called to avoid a native method call.
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
exist UT
Closes #40440 from cxzl25/SPARK-42808.
Authored-by: sychen
Signed-off-by: Sean Owen
---
core/src/main/scala/org/apache/spark/MapOutputTracker.scala | 4 +++-
1 file changed, 3 insertions(+), 1 deletion(-)
diff --git a/core/src/main/scala/org/apache/spark/MapOutputTracker.scala
b/core/src/main/scala/org/apache/spark/MapOutputTracker.scala
index 5772285a63d..5ad62159d24 100644
--- a/core/src/main/scala/org/apache/spark/MapOutputTracker.scala
+++ b/core/src/main/scala/org/apache/spark/MapOutputTracker.scala
@@ -697,6 +697,8 @@ private[spark] class MapOutputTrackerMaster(
pool
}
+ private val availableProcessors = Runtime.getRuntime.availableProcessors()
+
// Make sure that we aren't going to exceed the max RPC message size by
making sure
// we use broadcast to send large map output statuses.
if (minSizeForBroadcast > maxRpcMessageSize) {
@@ -966,7 +968,7 @@ private[spark] class MapOutputTrackerMaster(
val parallelAggThreshold = conf.get(
SHUFFLE_MAP_OUTPUT_PARALLEL_AGGREGATION_THRESHOLD)
val parallelism = math.min(
-Runtime.getRuntime.availableProcessors(),
+availableProcessors,
statuses.length.toLong * totalSizes.length / parallelAggThreshold +
1).toInt
if (parallelism <= 1) {
statuses.filter(_ != null).foreach { s =>
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42536][BUILD] Upgrade log4j2 to 2.20.0
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new df2e2516188 [SPARK-42536][BUILD] Upgrade log4j2 to 2.20.0 df2e2516188 is described below commit df2e2516188b46537349aa7a5f279de6141c6450 Author: yangjie01 AuthorDate: Tue Mar 21 09:45:32 2023 -0500 [SPARK-42536][BUILD] Upgrade log4j2 to 2.20.0 ### What changes were proposed in this pull request? This version aims upgrade log4j2 from 2.19.0 to 2.20.0 ### Why are the changes needed? This version brings some bug fix like [Fix java.sql.Time object formatting in MapMessage ](https://issues.apache.org/jira/browse/LOG4J2-2297) and [Fix level propagation in Log4jBridgeHandler](https://issues.apache.org/jira/browse/LOG4J2-3634), and some new support like [Add support for timezones in RollingFileAppender](https://issues.apache.org/jira/browse/LOG4J2-1631), the release notes as follows: - https://logging.apache.org/log4j/2.x/release-notes/2.20.0.html ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass GitHub Actions Closes #40490 from LuciferYang/SPARK-42536. Lead-authored-by: yangjie01 Co-authored-by: YangJie Signed-off-by: Sean Owen --- dev/deps/spark-deps-hadoop-2-hive-2.3 | 8 dev/deps/spark-deps-hadoop-3-hive-2.3 | 8 pom.xml | 2 +- 3 files changed, 9 insertions(+), 9 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-2-hive-2.3 b/dev/deps/spark-deps-hadoop-2-hive-2.3 index e3d588d36cd..df04d79969d 100644 --- a/dev/deps/spark-deps-hadoop-2-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-2-hive-2.3 @@ -188,10 +188,10 @@ lapack/3.0.3//lapack-3.0.3.jar leveldbjni-all/1.8//leveldbjni-all-1.8.jar libfb303/0.9.3//libfb303-0.9.3.jar libthrift/0.12.0//libthrift-0.12.0.jar -log4j-1.2-api/2.19.0//log4j-1.2-api-2.19.0.jar -log4j-api/2.19.0//log4j-api-2.19.0.jar -log4j-core/2.19.0//log4j-core-2.19.0.jar -log4j-slf4j2-impl/2.19.0//log4j-slf4j2-impl-2.19.0.jar +log4j-1.2-api/2.20.0//log4j-1.2-api-2.20.0.jar +log4j-api/2.20.0//log4j-api-2.20.0.jar +log4j-core/2.20.0//log4j-core-2.20.0.jar +log4j-slf4j2-impl/2.20.0//log4j-slf4j2-impl-2.20.0.jar logging-interceptor/3.12.12//logging-interceptor-3.12.12.jar lz4-java/1.8.0//lz4-java-1.8.0.jar mesos/1.4.3/shaded-protobuf/mesos-1.4.3-shaded-protobuf.jar diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3 b/dev/deps/spark-deps-hadoop-3-hive-2.3 index fd32245ec28..c8d83233bcc 100644 --- a/dev/deps/spark-deps-hadoop-3-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-3-hive-2.3 @@ -172,10 +172,10 @@ lapack/3.0.3//lapack-3.0.3.jar leveldbjni-all/1.8//leveldbjni-all-1.8.jar libfb303/0.9.3//libfb303-0.9.3.jar libthrift/0.12.0//libthrift-0.12.0.jar -log4j-1.2-api/2.19.0//log4j-1.2-api-2.19.0.jar -log4j-api/2.19.0//log4j-api-2.19.0.jar -log4j-core/2.19.0//log4j-core-2.19.0.jar -log4j-slf4j2-impl/2.19.0//log4j-slf4j2-impl-2.19.0.jar +log4j-1.2-api/2.20.0//log4j-1.2-api-2.20.0.jar +log4j-api/2.20.0//log4j-api-2.20.0.jar +log4j-core/2.20.0//log4j-core-2.20.0.jar +log4j-slf4j2-impl/2.20.0//log4j-slf4j2-impl-2.20.0.jar logging-interceptor/3.12.12//logging-interceptor-3.12.12.jar lz4-java/1.8.0//lz4-java-1.8.0.jar mesos/1.4.3/shaded-protobuf/mesos-1.4.3-shaded-protobuf.jar diff --git a/pom.xml b/pom.xml index 86f6435ee86..61fe9d23b2a 100644 --- a/pom.xml +++ b/pom.xml @@ -118,7 +118,7 @@ 1.6.0 spark 2.0.6 -2.19.0 +2.20.0 3.3.4 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (30337c5fa8d -> 67a254c7ed8)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 30337c5fa8d [MINOR][BUILD] Remove unused properties in pom file add 67a254c7ed8 [SPARK-42790][SQL] Abstract the excluded method for better test for JDBC docker tests No new revisions were added by this update. Summary of changes: .../spark/sql/jdbc/v2/DB2IntegrationSuite.scala| 30 ++-- .../spark/sql/jdbc/v2/DB2NamespaceSuite.scala | 3 - .../sql/jdbc/v2/MsSqlServerIntegrationSuite.scala | 30 ++-- .../sql/jdbc/v2/MsSqlServerNamespaceSuite.scala| 3 - .../spark/sql/jdbc/v2/MySQLIntegrationSuite.scala | 30 ++-- .../spark/sql/jdbc/v2/MySQLNamespaceSuite.scala| 3 - .../spark/sql/jdbc/v2/OracleIntegrationSuite.scala | 30 ++-- .../spark/sql/jdbc/v2/OracleNamespaceSuite.scala | 3 + .../sql/jdbc/v2/PostgresIntegrationSuite.scala | 27 .../spark/sql/jdbc/v2/PostgresNamespaceSuite.scala | 3 - .../spark/sql/jdbc/v2/V2JDBCNamespaceTest.scala| 132 - .../org/apache/spark/sql/jdbc/v2/V2JDBCTest.scala | 162 - .../scala/org/apache/spark/SparkFunSuite.scala | 16 +- 13 files changed, 212 insertions(+), 260 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [MINOR][BUILD] Remove unused properties in pom file
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 30337c5fa8d [MINOR][BUILD] Remove unused properties in pom file
30337c5fa8d is described below
commit 30337c5fa8ddd3fdf4f58101685a5ff5072849e3
Author: panbingkun
AuthorDate: Mon Mar 20 08:41:24 2023 -0500
[MINOR][BUILD] Remove unused properties in pom file
### What changes were proposed in this pull request?
The pr aims to remove unused properties in pom file.
### Why are the changes needed?
Make the code more concise.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA.
Closes #40476 from panbingkun/remove_pom_unused_properties.
Authored-by: panbingkun
Signed-off-by: Sean Owen
---
resource-managers/kubernetes/integration-tests/pom.xml | 4 +---
1 file changed, 1 insertion(+), 3 deletions(-)
diff --git a/resource-managers/kubernetes/integration-tests/pom.xml
b/resource-managers/kubernetes/integration-tests/pom.xml
index 297ad8532ae..1ffd5adba84 100644
--- a/resource-managers/kubernetes/integration-tests/pom.xml
+++ b/resource-managers/kubernetes/integration-tests/pom.xml
@@ -26,8 +26,6 @@
spark-kubernetes-integration-tests_2.12
-1.3.0
-
kubernetes-integration-tests
@@ -163,7 +161,7 @@
${project.build.directory}/surefire-reports
.
SparkTestSuite.txt
- -ea -Xmx4g -XX:ReservedCodeCacheSize=1g
${extraScalaTestArgs}
+ -ea -Xmx4g -XX:ReservedCodeCacheSize=1g
file:src/test/resources/log4j2.properties
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42803][CORE][SQL][ML] Use getParameterCount function instead of getParameterTypes.length
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 11c9838283e [SPARK-42803][CORE][SQL][ML] Use getParameterCount
function instead of getParameterTypes.length
11c9838283e is described below
commit 11c9838283e98d5ebe6ce13b85e26217494feef2
Author: narek_karapetian
AuthorDate: Fri Mar 17 21:46:25 2023 -0500
[SPARK-42803][CORE][SQL][ML] Use getParameterCount function instead of
getParameterTypes.length
### What changes were proposed in this pull request?
Since jdk1.8 there is an additional function in reflection API
`getParameterCount`, it is better to use that function instead of
`getParameterTypes.length` because `getParameterTypes` function makes a copy of
the parameter types array every invocation:
```java
public Class[] getParameterTypes() {
return parameterTypes.clone();
}
```
`getParameterCount` returns amount of parameters directly:
```java
public int getParameterCount() { return parameterTypes.length; }
```
### Why are the changes needed?
To avoid redundant arrays creation.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By existing unit tests
Closes #40422 from NarekDW/reflection-get-parameter-count.
Authored-by: narek_karapetian
Signed-off-by: Sean Owen
---
.../src/main/java/org/apache/spark/util/kvstore/KVTypeInfo.java | 2 +-
mllib/common/src/main/scala/org/apache/spark/ml/param/params.scala | 2 +-
.../main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala | 6 +++---
3 files changed, 5 insertions(+), 5 deletions(-)
diff --git
a/common/kvstore/src/main/java/org/apache/spark/util/kvstore/KVTypeInfo.java
b/common/kvstore/src/main/java/org/apache/spark/util/kvstore/KVTypeInfo.java
index a15d07cf599..bf7c256fc94 100644
--- a/common/kvstore/src/main/java/org/apache/spark/util/kvstore/KVTypeInfo.java
+++ b/common/kvstore/src/main/java/org/apache/spark/util/kvstore/KVTypeInfo.java
@@ -56,7 +56,7 @@ public class KVTypeInfo {
KVIndex idx = m.getAnnotation(KVIndex.class);
if (idx != null) {
checkIndex(idx, indices);
-Preconditions.checkArgument(m.getParameterTypes().length == 0,
+Preconditions.checkArgument(m.getParameterCount() == 0,
"Annotated method %s::%s should not have any parameters.",
type.getName(), m.getName());
m.setAccessible(true);
indices.put(idx.value(), idx);
diff --git a/mllib/common/src/main/scala/org/apache/spark/ml/param/params.scala
b/mllib/common/src/main/scala/org/apache/spark/ml/param/params.scala
index 52840e04eae..b818be30583 100644
--- a/mllib/common/src/main/scala/org/apache/spark/ml/param/params.scala
+++ b/mllib/common/src/main/scala/org/apache/spark/ml/param/params.scala
@@ -652,7 +652,7 @@ trait Params extends Identifiable with Serializable {
methods.filter { m =>
Modifier.isPublic(m.getModifiers) &&
classOf[Param[_]].isAssignableFrom(m.getReturnType) &&
- m.getParameterTypes.isEmpty
+ m.getParameterCount == 0
}.sortBy(_.getName)
.map(m => m.invoke(this).asInstanceOf[Param[_]])
}
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
index b90fc585a09..7468d895cff 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
@@ -786,7 +786,7 @@ abstract class TreeNode[BaseType <: TreeNode[BaseType]]
extends Product with Tre
}
// Skip no-arg constructors that are just there for kryo.
-val ctors = allCtors.filter(allowEmptyArgs || _.getParameterTypes.size !=
0)
+val ctors = allCtors.filter(allowEmptyArgs || _.getParameterCount != 0)
if (ctors.isEmpty) {
throw QueryExecutionErrors.constructorNotFoundError(nodeName)
}
@@ -796,7 +796,7 @@ abstract class TreeNode[BaseType <: TreeNode[BaseType]]
extends Product with Tre
newArgs ++ otherCopyArgs
}
val defaultCtor = ctors.find { ctor =>
- if (ctor.getParameterTypes.length != allArgs.length) {
+ if (ctor.getParameterCount != allArgs.length) {
false
} else if (allArgs.contains(null)) {
// if there is a `null`, we can't figure out the class, therefore we
should just fallback
@@ -806,7 +806,7 @@ abstract class TreeNode[BaseType <: TreeNode[BaseType]]
extends Product with Tre
val argsArray: Array[Class[_]] = allArgs.map(_.getClass)
ClassUtils.isAssignable(argsArray, ctor.getParameterTypes, true /*
autoboxi
[spark] branch master updated: [SPARK-42752][PYSPARK][SQL] Make PySpark exceptions printable during initialization
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new b2a7f14cbd8 [SPARK-42752][PYSPARK][SQL] Make PySpark exceptions printable during initialization b2a7f14cbd8 is described below commit b2a7f14cbd8fd3b1a51d7b53fc7c23fb71e9f370 Author: Gera Shegalov AuthorDate: Tue Mar 14 08:30:15 2023 -0500 [SPARK-42752][PYSPARK][SQL] Make PySpark exceptions printable during initialization Ignore SQLConf initialization exceptions during Python exception creation. Otherwise there is no diagnostics for the issue in the following scenario: 1. download a standard "Hadoop Free" build 2. Start PySpark REPL with Hive support ```bash SPARK_DIST_CLASSPATH=$(~/dist/hadoop-3.4.0-SNAPSHOT/bin/hadoop classpath) \ ~/dist/spark-3.2.3-bin-without-hadoop/bin/pyspark --conf spark.sql.catalogImplementation=hive ``` 3. Execute any simple dataframe operation ```Python >>> spark.range(100).show() Traceback (most recent call last): File "", line 1, in File "/home/user/dist/spark-3.2.3-bin-without-hadoop/python/pyspark/sql/session.py", line 416, in range jdf = self._jsparkSession.range(0, int(start), int(step), int(numPartitions)) File "/home/user/dist/spark-3.2.3-bin-without-hadoop/python/lib/py4j-0.10.9.5-src.zip/py4j/java_gateway.py", line 1321, in __call__ File "/home/user/dist/spark-3.2.3-bin-without-hadoop/python/pyspark/sql/utils.py", line 117, in deco raise converted from None pyspark.sql.utils.IllegalArgumentException: ``` 4. In fact just spark.conf already exhibits the issue ```Python >>> spark.conf Traceback (most recent call last): File "", line 1, in File "/home/user/dist/spark-3.2.3-bin-without-hadoop/python/pyspark/sql/session.py", line 347, in conf self._conf = RuntimeConfig(self._jsparkSession.conf()) File "/home/user/dist/spark-3.2.3-bin-without-hadoop/python/lib/py4j-0.10.9.5-src.zip/py4j/java_gateway.py", line 1321, in __call__ File "/home/user/dist/spark-3.2.3-bin-without-hadoop/python/pyspark/sql/utils.py", line 117, in deco raise converted from None pyspark.sql.utils.IllegalArgumentException: ``` There are probably two issues here: 1) that Hive support should be gracefully disabled if it the dependency not on the classpath as claimed by https://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html 2) but at the very least the user should be able to see the exception to understand the issue, and take an action ### What changes were proposed in this pull request? Ignore exceptions during `CapturedException` creation ### Why are the changes needed? To make the cause visible to the user ```Python Traceback (most recent call last): File "", line 1, in File "/home/user/gits/apache/spark/python/pyspark/sql/session.py", line 679, in conf self._conf = RuntimeConfig(self._jsparkSession.conf()) File "/home/user/gits/apache/spark/python/lib/py4j-0.10.9.7-src.zip/py4j/java_gateway.py", line 1322, in __call__ File "/home/user/gits/apache/spark/python/pyspark/errors/exceptions/captured.py", line 166, in deco raise converted from None pyspark.errors.exceptions.captured.IllegalArgumentException: Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder': JVM stacktrace: java.lang.IllegalArgumentException: Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder': at org.apache.spark.sql.SparkSession$.org$apache$spark$sql$SparkSession$$instantiateSessionState(SparkSession.scala:1237) at org.apache.spark.sql.SparkSession.$anonfun$sessionState$2(SparkSession.scala:162) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.sql.SparkSession.sessionState$lzycompute(SparkSession.scala:160) at org.apache.spark.sql.SparkSession.sessionState(SparkSession.scala:157) at org.apache.spark.sql.SparkSession.conf$lzycompute(SparkSession.scala:185) at org.apache.spark.sql.SparkSession.conf(SparkSession.scala:185) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvo
[spark-website] branch asf-site updated: Fix CVE-2022-33891 resolved version
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 8a3ce1f42d Fix CVE-2022-33891 resolved version 8a3ce1f42d is described below commit 8a3ce1f42dfb6072541a84857eb2bf2b0a11a70e Author: Sean Owen AuthorDate: Mon Mar 13 09:36:20 2023 -0500 Fix CVE-2022-33891 resolved version --- security.md| 5 ++--- site/security.html | 5 ++--- 2 files changed, 4 insertions(+), 6 deletions(-) diff --git a/security.md b/security.md index c648bbbe78..5147a7e915 100644 --- a/security.md +++ b/security.md @@ -52,8 +52,7 @@ Vendor: The Apache Software Foundation Versions Affected: -- 3.0.3 and earlier -- 3.1.1 to 3.1.2 +- 3.1.3 and earlier - 3.2.0 to 3.2.1 Description: @@ -67,7 +66,7 @@ execution as the user Spark is currently running as. Mitigation -- Update to Spark 3.1.3, 3.2.2, or 3.3.0 or later +- Update to Spark 3.2.2, or 3.3.0 or later Credit: diff --git a/site/security.html b/site/security.html index 28fce6830b..f802a20172 100644 --- a/site/security.html +++ b/site/security.html @@ -173,8 +173,7 @@ the logs which would be returned in logs rendered in the UI. Versions Affected: - 3.0.3 and earlier - 3.1.1 to 3.1.2 + 3.1.3 and earlier 3.2.0 to 3.2.1 @@ -190,7 +189,7 @@ execution as the user Spark is currently running as. Mitigation - Update to Spark 3.1.3, 3.2.2, or 3.3.0 or later + Update to Spark 3.2.2, or 3.3.0 or later Credit: - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42758][BUILD][MLLIB] Remove dependency on breeze
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new e0d0657d5e5 [SPARK-42758][BUILD][MLLIB] Remove dependency on breeze
e0d0657d5e5 is described below
commit e0d0657d5e543988b778898d012e2cecab0722f1
Author: panbingkun
AuthorDate: Sat Mar 11 18:35:20 2023 -0600
[SPARK-42758][BUILD][MLLIB] Remove dependency on breeze
### What changes were proposed in this pull request?
The pr aims to remove dependency `shapeless` on breeze.
### Why are the changes needed?
After pr https://github.com/apache/spark/pull/37002, `shapeless` has been
deleted in
[spark-deps-hadoop-2-hive-2.3](https://github.com/apache/spark/pull/37002/files#diff-670b971a2758f55d602f0d1ef63f7af5f8d9ca095b5a55664bc3275e274ca395).
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA.
Closes #40378 from panbingkun/remove_dep_on_breeze.
Authored-by: panbingkun
Signed-off-by: Sean Owen
---
pom.xml | 5 -
1 file changed, 5 deletions(-)
diff --git a/pom.xml b/pom.xml
index b465a735343..9fb07c7010c 100644
--- a/pom.xml
+++ b/pom.xml
@@ -1074,11 +1074,6 @@
-
-com.chuusai
-shapeless_${scala.binary.version}
-2.3.9
-
org.json4s
json4s-jackson_${scala.binary.version}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.3 updated: [SPARK-42747][ML] Fix incorrect internal status of LoR and AFT
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new aa8609342dd [SPARK-42747][ML] Fix incorrect internal status of LoR and
AFT
aa8609342dd is described below
commit aa8609342dd4febf0dd2d773e878e5fe14ec8be7
Author: Ruifeng Zheng
AuthorDate: Sat Mar 11 08:45:54 2023 -0600
[SPARK-42747][ML] Fix incorrect internal status of LoR and AFT
### What changes were proposed in this pull request?
Add a hook `onParamChange` in `Params.{set, setDefault, clear}`, so that
subclass can update the internal status within it.
### Why are the changes needed?
In 3.1, we added internal auxiliary variables in LoR and AFT to optimize
prediction/transformation.
In LoR, when users call `model.{setThreshold, setThresholds}`, the internal
status will be correctly updated.
But users still can call `model.set(model.threshold, value)`, then the
status will not be updated.
And when users call `model.clear(model.threshold)`, the status should be
updated with default threshold value 0.5.
for example:
```
import org.apache.spark.ml.linalg._
import org.apache.spark.ml.classification._
val df = Seq((1.0, 1.0, Vectors.dense(0.0, 5.0)), (0.0, 2.0,
Vectors.dense(1.0, 2.0)), (1.0, 3.0, Vectors.dense(2.0, 1.0)), (0.0, 4.0,
Vectors.dense(3.0, 3.0))).toDF("label", "weight", "features")
val lor = new LogisticRegression().setWeightCol("weight")
val model = lor.fit(df)
val vec = Vectors.dense(0.0, 5.0)
val p0 = model.predict(vec)
// return 0.0
model.setThreshold(0.05) //
change status
val p1 = model.set(model.threshold, 0.5).predict(vec) // return 1.0; but
should be 0.0
val p2 = model.clear(model.threshold).predict(vec) // return 1.0; but
should be 0.0
```
what makes it even worse it that `pyspark.ml` always set params via
`model.set(model.threshold, value)`, so the internal status is easily out of
sync, see the example in
[SPARK-42747](https://issues.apache.org/jira/browse/SPARK-42747)
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
added ut
Closes #40367 from zhengruifeng/ml_param_hook.
Authored-by: Ruifeng Zheng
Signed-off-by: Sean Owen
(cherry picked from commit 5a702f22f49ca6a1b6220ac645e3fce70ec5189d)
Signed-off-by: Sean Owen
---
.../ml/classification/LogisticRegression.scala | 54 +-
.../scala/org/apache/spark/ml/param/params.scala | 16 +++
.../ml/regression/AFTSurvivalRegression.scala | 26 ++-
.../scala/org/apache/spark/ml/util/ReadWrite.scala | 2 +-
.../classification/LogisticRegressionSuite.scala | 21 +
.../ml/regression/AFTSurvivalRegressionSuite.scala | 13 ++
python/pyspark/ml/tests/test_algorithms.py | 35 ++
7 files changed, 113 insertions(+), 54 deletions(-)
diff --git
a/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
b/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
index f18b8af1a7f..9dda76190d7 100644
---
a/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
+++
b/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
@@ -1107,46 +1107,36 @@ class LogisticRegressionModel private[spark] (
_intercept
}
- private lazy val _intercept = interceptVector(0)
- private lazy val _interceptVector = interceptVector.toDense
- private lazy val _binaryThresholdArray = {
-val array = Array(Double.NaN, Double.NaN)
-updateBinaryThresholds(array)
-array
- }
- private def _threshold: Double = _binaryThresholdArray(0)
- private def _rawThreshold: Double = _binaryThresholdArray(1)
-
- private def updateBinaryThresholds(array: Array[Double]): Unit = {
-if (!isMultinomial) {
- val _threshold = getThreshold
- array(0) = _threshold
- if (_threshold == 0.0) {
-array(1) = Double.NegativeInfinity
- } else if (_threshold == 1.0) {
-array(1) = Double.PositiveInfinity
+ private val _interceptVector = if (isMultinomial) interceptVector.toDense
else null
+ private val _intercept = if (!isMultinomial) interceptVector(0) else
Double.NaN
+ // Array(0.5, 0.0) is the value for default threshold (0.5) and thresholds
(unset)
+ private var _binaryThresholds: Array[Double] = if (!isMultinomial)
Array(0.5, 0.0) else null
+
+ private[ml] override def onParamChange(param: Param[_]): Unit = {
+if (!isMultinomial && (param.name == "threshold" || param.name ==
"threshol
[spark] branch branch-3.2 updated: [SPARK-42747][ML] Fix incorrect internal status of LoR and AFT
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 5e14e0a70fe [SPARK-42747][ML] Fix incorrect internal status of LoR and
AFT
5e14e0a70fe is described below
commit 5e14e0a70fe6957d8b468f7b5c5e87395062c6d9
Author: Ruifeng Zheng
AuthorDate: Sat Mar 11 08:45:54 2023 -0600
[SPARK-42747][ML] Fix incorrect internal status of LoR and AFT
### What changes were proposed in this pull request?
Add a hook `onParamChange` in `Params.{set, setDefault, clear}`, so that
subclass can update the internal status within it.
### Why are the changes needed?
In 3.1, we added internal auxiliary variables in LoR and AFT to optimize
prediction/transformation.
In LoR, when users call `model.{setThreshold, setThresholds}`, the internal
status will be correctly updated.
But users still can call `model.set(model.threshold, value)`, then the
status will not be updated.
And when users call `model.clear(model.threshold)`, the status should be
updated with default threshold value 0.5.
for example:
```
import org.apache.spark.ml.linalg._
import org.apache.spark.ml.classification._
val df = Seq((1.0, 1.0, Vectors.dense(0.0, 5.0)), (0.0, 2.0,
Vectors.dense(1.0, 2.0)), (1.0, 3.0, Vectors.dense(2.0, 1.0)), (0.0, 4.0,
Vectors.dense(3.0, 3.0))).toDF("label", "weight", "features")
val lor = new LogisticRegression().setWeightCol("weight")
val model = lor.fit(df)
val vec = Vectors.dense(0.0, 5.0)
val p0 = model.predict(vec)
// return 0.0
model.setThreshold(0.05) //
change status
val p1 = model.set(model.threshold, 0.5).predict(vec) // return 1.0; but
should be 0.0
val p2 = model.clear(model.threshold).predict(vec) // return 1.0; but
should be 0.0
```
what makes it even worse it that `pyspark.ml` always set params via
`model.set(model.threshold, value)`, so the internal status is easily out of
sync, see the example in
[SPARK-42747](https://issues.apache.org/jira/browse/SPARK-42747)
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
added ut
Closes #40367 from zhengruifeng/ml_param_hook.
Authored-by: Ruifeng Zheng
Signed-off-by: Sean Owen
(cherry picked from commit 5a702f22f49ca6a1b6220ac645e3fce70ec5189d)
Signed-off-by: Sean Owen
---
.../ml/classification/LogisticRegression.scala | 54 +-
.../scala/org/apache/spark/ml/param/params.scala | 16 +++
.../ml/regression/AFTSurvivalRegression.scala | 26 ++-
.../scala/org/apache/spark/ml/util/ReadWrite.scala | 2 +-
.../classification/LogisticRegressionSuite.scala | 21 +
.../ml/regression/AFTSurvivalRegressionSuite.scala | 13 ++
python/pyspark/ml/tests/test_algorithms.py | 35 ++
7 files changed, 113 insertions(+), 54 deletions(-)
diff --git
a/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
b/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
index f5166ba50e6..525107e0da3 100644
---
a/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
+++
b/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
@@ -1106,46 +1106,36 @@ class LogisticRegressionModel private[spark] (
_intercept
}
- private lazy val _intercept = interceptVector(0)
- private lazy val _interceptVector = interceptVector.toDense
- private lazy val _binaryThresholdArray = {
-val array = Array(Double.NaN, Double.NaN)
-updateBinaryThresholds(array)
-array
- }
- private def _threshold: Double = _binaryThresholdArray(0)
- private def _rawThreshold: Double = _binaryThresholdArray(1)
-
- private def updateBinaryThresholds(array: Array[Double]): Unit = {
-if (!isMultinomial) {
- val _threshold = getThreshold
- array(0) = _threshold
- if (_threshold == 0.0) {
-array(1) = Double.NegativeInfinity
- } else if (_threshold == 1.0) {
-array(1) = Double.PositiveInfinity
+ private val _interceptVector = if (isMultinomial) interceptVector.toDense
else null
+ private val _intercept = if (!isMultinomial) interceptVector(0) else
Double.NaN
+ // Array(0.5, 0.0) is the value for default threshold (0.5) and thresholds
(unset)
+ private var _binaryThresholds: Array[Double] = if (!isMultinomial)
Array(0.5, 0.0) else null
+
+ private[ml] override def onParamChange(param: Param[_]): Unit = {
+if (!isMultinomial && (param.name == "threshold" || param.name ==
"threshol
[spark] branch branch-3.4 updated: [SPARK-42747][ML] Fix incorrect internal status of LoR and AFT
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new cb7ae0407d4 [SPARK-42747][ML] Fix incorrect internal status of LoR and
AFT
cb7ae0407d4 is described below
commit cb7ae0407d440feb6c228b1265af50c0006e21e9
Author: Ruifeng Zheng
AuthorDate: Sat Mar 11 08:45:54 2023 -0600
[SPARK-42747][ML] Fix incorrect internal status of LoR and AFT
### What changes were proposed in this pull request?
Add a hook `onParamChange` in `Params.{set, setDefault, clear}`, so that
subclass can update the internal status within it.
### Why are the changes needed?
In 3.1, we added internal auxiliary variables in LoR and AFT to optimize
prediction/transformation.
In LoR, when users call `model.{setThreshold, setThresholds}`, the internal
status will be correctly updated.
But users still can call `model.set(model.threshold, value)`, then the
status will not be updated.
And when users call `model.clear(model.threshold)`, the status should be
updated with default threshold value 0.5.
for example:
```
import org.apache.spark.ml.linalg._
import org.apache.spark.ml.classification._
val df = Seq((1.0, 1.0, Vectors.dense(0.0, 5.0)), (0.0, 2.0,
Vectors.dense(1.0, 2.0)), (1.0, 3.0, Vectors.dense(2.0, 1.0)), (0.0, 4.0,
Vectors.dense(3.0, 3.0))).toDF("label", "weight", "features")
val lor = new LogisticRegression().setWeightCol("weight")
val model = lor.fit(df)
val vec = Vectors.dense(0.0, 5.0)
val p0 = model.predict(vec)
// return 0.0
model.setThreshold(0.05) //
change status
val p1 = model.set(model.threshold, 0.5).predict(vec) // return 1.0; but
should be 0.0
val p2 = model.clear(model.threshold).predict(vec) // return 1.0; but
should be 0.0
```
what makes it even worse it that `pyspark.ml` always set params via
`model.set(model.threshold, value)`, so the internal status is easily out of
sync, see the example in
[SPARK-42747](https://issues.apache.org/jira/browse/SPARK-42747)
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
added ut
Closes #40367 from zhengruifeng/ml_param_hook.
Authored-by: Ruifeng Zheng
Signed-off-by: Sean Owen
(cherry picked from commit 5a702f22f49ca6a1b6220ac645e3fce70ec5189d)
Signed-off-by: Sean Owen
---
.../ml/classification/LogisticRegression.scala | 54 +-
.../scala/org/apache/spark/ml/param/params.scala | 16 +++
.../ml/regression/AFTSurvivalRegression.scala | 26 ++-
.../scala/org/apache/spark/ml/util/ReadWrite.scala | 2 +-
.../classification/LogisticRegressionSuite.scala | 21 +
.../ml/regression/AFTSurvivalRegressionSuite.scala | 13 ++
python/pyspark/ml/tests/test_algorithms.py | 35 ++
7 files changed, 113 insertions(+), 54 deletions(-)
diff --git
a/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
b/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
index 3ad1e2c17db..adf77eb6113 100644
---
a/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
+++
b/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
@@ -1112,46 +1112,36 @@ class LogisticRegressionModel private[spark] (
_intercept
}
- private lazy val _intercept = interceptVector(0)
- private lazy val _interceptVector = interceptVector.toDense
- private lazy val _binaryThresholdArray = {
-val array = Array(Double.NaN, Double.NaN)
-updateBinaryThresholds(array)
-array
- }
- private def _threshold: Double = _binaryThresholdArray(0)
- private def _rawThreshold: Double = _binaryThresholdArray(1)
-
- private def updateBinaryThresholds(array: Array[Double]): Unit = {
-if (!isMultinomial) {
- val _threshold = getThreshold
- array(0) = _threshold
- if (_threshold == 0.0) {
-array(1) = Double.NegativeInfinity
- } else if (_threshold == 1.0) {
-array(1) = Double.PositiveInfinity
+ private val _interceptVector = if (isMultinomial) interceptVector.toDense
else null
+ private val _intercept = if (!isMultinomial) interceptVector(0) else
Double.NaN
+ // Array(0.5, 0.0) is the value for default threshold (0.5) and thresholds
(unset)
+ private var _binaryThresholds: Array[Double] = if (!isMultinomial)
Array(0.5, 0.0) else null
+
+ private[ml] override def onParamChange(param: Param[_]): Unit = {
+if (!isMultinomial && (param.name == "threshold" || param.name ==
"threshol
[spark] branch master updated: [SPARK-42747][ML] Fix incorrect internal status of LoR and AFT
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 5a702f22f49 [SPARK-42747][ML] Fix incorrect internal status of LoR and
AFT
5a702f22f49 is described below
commit 5a702f22f49ca6a1b6220ac645e3fce70ec5189d
Author: Ruifeng Zheng
AuthorDate: Sat Mar 11 08:45:54 2023 -0600
[SPARK-42747][ML] Fix incorrect internal status of LoR and AFT
### What changes were proposed in this pull request?
Add a hook `onParamChange` in `Params.{set, setDefault, clear}`, so that
subclass can update the internal status within it.
### Why are the changes needed?
In 3.1, we added internal auxiliary variables in LoR and AFT to optimize
prediction/transformation.
In LoR, when users call `model.{setThreshold, setThresholds}`, the internal
status will be correctly updated.
But users still can call `model.set(model.threshold, value)`, then the
status will not be updated.
And when users call `model.clear(model.threshold)`, the status should be
updated with default threshold value 0.5.
for example:
```
import org.apache.spark.ml.linalg._
import org.apache.spark.ml.classification._
val df = Seq((1.0, 1.0, Vectors.dense(0.0, 5.0)), (0.0, 2.0,
Vectors.dense(1.0, 2.0)), (1.0, 3.0, Vectors.dense(2.0, 1.0)), (0.0, 4.0,
Vectors.dense(3.0, 3.0))).toDF("label", "weight", "features")
val lor = new LogisticRegression().setWeightCol("weight")
val model = lor.fit(df)
val vec = Vectors.dense(0.0, 5.0)
val p0 = model.predict(vec)
// return 0.0
model.setThreshold(0.05) //
change status
val p1 = model.set(model.threshold, 0.5).predict(vec) // return 1.0; but
should be 0.0
val p2 = model.clear(model.threshold).predict(vec) // return 1.0; but
should be 0.0
```
what makes it even worse it that `pyspark.ml` always set params via
`model.set(model.threshold, value)`, so the internal status is easily out of
sync, see the example in
[SPARK-42747](https://issues.apache.org/jira/browse/SPARK-42747)
### Does this PR introduce _any_ user-facing change?
no
### How was this patch tested?
added ut
Closes #40367 from zhengruifeng/ml_param_hook.
Authored-by: Ruifeng Zheng
Signed-off-by: Sean Owen
---
.../ml/classification/LogisticRegression.scala | 54 +-
.../scala/org/apache/spark/ml/param/params.scala | 16 +++
.../ml/regression/AFTSurvivalRegression.scala | 26 ++-
.../scala/org/apache/spark/ml/util/ReadWrite.scala | 2 +-
.../classification/LogisticRegressionSuite.scala | 21 +
.../ml/regression/AFTSurvivalRegressionSuite.scala | 13 ++
python/pyspark/ml/tests/test_algorithms.py | 35 ++
7 files changed, 113 insertions(+), 54 deletions(-)
diff --git
a/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
b/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
index 3ad1e2c17db..adf77eb6113 100644
---
a/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
+++
b/mllib/src/main/scala/org/apache/spark/ml/classification/LogisticRegression.scala
@@ -1112,46 +1112,36 @@ class LogisticRegressionModel private[spark] (
_intercept
}
- private lazy val _intercept = interceptVector(0)
- private lazy val _interceptVector = interceptVector.toDense
- private lazy val _binaryThresholdArray = {
-val array = Array(Double.NaN, Double.NaN)
-updateBinaryThresholds(array)
-array
- }
- private def _threshold: Double = _binaryThresholdArray(0)
- private def _rawThreshold: Double = _binaryThresholdArray(1)
-
- private def updateBinaryThresholds(array: Array[Double]): Unit = {
-if (!isMultinomial) {
- val _threshold = getThreshold
- array(0) = _threshold
- if (_threshold == 0.0) {
-array(1) = Double.NegativeInfinity
- } else if (_threshold == 1.0) {
-array(1) = Double.PositiveInfinity
+ private val _interceptVector = if (isMultinomial) interceptVector.toDense
else null
+ private val _intercept = if (!isMultinomial) interceptVector(0) else
Double.NaN
+ // Array(0.5, 0.0) is the value for default threshold (0.5) and thresholds
(unset)
+ private var _binaryThresholds: Array[Double] = if (!isMultinomial)
Array(0.5, 0.0) else null
+
+ private[ml] override def onParamChange(param: Param[_]): Unit = {
+if (!isMultinomial && (param.name == "threshold" || param.name ==
"thresholds")) {
+ if (isDefined(threshold) || isDefined(thresholds)) {
+val _threshold = getThreshold
+if (
[spark] branch master updated (79b5abed8bd -> bdcf68a69c4)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 79b5abed8bd [SPARK-42691][CONNECT][PYTHON] Implement Dataset.semanticHash add bdcf68a69c4 [SPARK-42670][BUILD] Upgrade maven-surefire-plugin to 3.0.0-M9 & eliminate build warnings No new revisions were added by this update. Summary of changes: pom.xml | 6 +++--- 1 file changed, 3 insertions(+), 3 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42685][CORE] Optimize Utils.bytesToString routines
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 645d33ea3e8 [SPARK-42685][CORE] Optimize Utils.bytesToString routines
645d33ea3e8 is described below
commit 645d33ea3e8e9ba41409f15b63544ea6b078fba4
Author: Alkis Evlogimenos
AuthorDate: Fri Mar 10 11:27:41 2023 -0600
[SPARK-42685][CORE] Optimize Utils.bytesToString routines
### What changes were proposed in this pull request?
Optimize `Utils.bytesToString`. Arithmetic ops on `BigInt` and `BigDecimal`
are order(s) of magnitude slower than the ops on primitive types. Division is
an especially slow operation and it is used en masse here.
To avoid heating up the Earth while formatting byte counts for human
consumption we observe that most formatting operations are not in the 10s of
EiBs but on counts that fit in 64-bits and use (fastpath) 64-bit operations to
format them.
### Why are the changes needed?
Use of `Utils.bytesToString` is prevalent through the codebase and they are
mainly used in logs. If the logs are emitted then this becomes a heavyweight
operation.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes #40301 from alkis/faster-byte-to-string.
Authored-by: Alkis Evlogimenos
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/util/Utils.scala | 43 --
1 file changed, 16 insertions(+), 27 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/util/Utils.scala
b/core/src/main/scala/org/apache/spark/util/Utils.scala
index 510486bc56b..d81e85ffe08 100644
--- a/core/src/main/scala/org/apache/spark/util/Utils.scala
+++ b/core/src/main/scala/org/apache/spark/util/Utils.scala
@@ -1305,41 +1305,30 @@ private[spark] object Utils extends Logging {
(JavaUtils.byteStringAsBytes(str) / 1024 / 1024).toInt
}
+ private[this] val siByteSizes =
+Array(1L << 60, 1L << 50, 1L << 40, 1L << 30, 1L << 20, 1L << 10, 1)
+ private[this] val siByteSuffixes =
+Array("EiB", "PiB", "TiB", "GiB", "MiB", "KiB", "B")
/**
* Convert a quantity in bytes to a human-readable string such as "4.0 MiB".
*/
- def bytesToString(size: Long): String = bytesToString(BigInt(size))
+ def bytesToString(size: Long): String = {
+var i = 0
+while (i < siByteSizes.length - 1 && size < 2 * siByteSizes(i)) i += 1
+"%.1f %s".formatLocal(Locale.US, size.toDouble / siByteSizes(i),
siByteSuffixes(i))
+ }
def bytesToString(size: BigInt): String = {
val EiB = 1L << 60
-val PiB = 1L << 50
-val TiB = 1L << 40
-val GiB = 1L << 30
-val MiB = 1L << 20
-val KiB = 1L << 10
-
-if (size >= BigInt(1L << 11) * EiB) {
+if (size.isValidLong) {
+ // Common case, most sizes fit in 64 bits and all ops on BigInt are
order(s) of magnitude
+ // slower than Long/Double.
+ bytesToString(size.toLong)
+} else if (size < BigInt(2L << 10) * EiB) {
+ "%.1f EiB".formatLocal(Locale.US, BigDecimal(size) / EiB)
+} else {
// The number is too large, show it in scientific notation.
BigDecimal(size, new MathContext(3, RoundingMode.HALF_UP)).toString() +
" B"
-} else {
- val (value, unit) = {
-if (size >= 2 * EiB) {
- (BigDecimal(size) / EiB, "EiB")
-} else if (size >= 2 * PiB) {
- (BigDecimal(size) / PiB, "PiB")
-} else if (size >= 2 * TiB) {
- (BigDecimal(size) / TiB, "TiB")
-} else if (size >= 2 * GiB) {
- (BigDecimal(size) / GiB, "GiB")
-} else if (size >= 2 * MiB) {
- (BigDecimal(size) / MiB, "MiB")
-} else if (size >= 2 * KiB) {
- (BigDecimal(size) / KiB, "KiB")
-} else {
- (BigDecimal(size), "B")
-}
- }
- "%.1f %s".formatLocal(Locale.US, value, unit)
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42654][BUILD] Upgrade dropwizard metrics 4.2.17
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 4b8b36834e2 [SPARK-42654][BUILD] Upgrade dropwizard metrics 4.2.17 4b8b36834e2 is described below commit 4b8b36834e2902184088d171ee919cf5c5e3b9a3 Author: yangjie01 AuthorDate: Sun Mar 5 20:32:45 2023 -0600 [SPARK-42654][BUILD] Upgrade dropwizard metrics 4.2.17 ### What changes were proposed in this pull request? This pr aims upgrade dropwizard metrics to 4.2.15. ### Why are the changes needed? The new version bring some bug fix: - https://github.com/dropwizard/metrics/pull/3125 - https://github.com/dropwizard/metrics/pull/3179 And the release notes as follows: - https://github.com/dropwizard/metrics/releases/tag/v4.2.16 - https://github.com/dropwizard/metrics/releases/tag/v4.2.17 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass Github Actions Closes #40254 from LuciferYang/SPARK-42654. Lead-authored-by: yangjie01 Co-authored-by: YangJie Signed-off-by: Sean Owen --- dev/deps/spark-deps-hadoop-2-hive-2.3 | 10 +- dev/deps/spark-deps-hadoop-3-hive-2.3 | 10 +- pom.xml | 2 +- 3 files changed, 11 insertions(+), 11 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-2-hive-2.3 b/dev/deps/spark-deps-hadoop-2-hive-2.3 index 3d338059d83..bc4baad4d0b 100644 --- a/dev/deps/spark-deps-hadoop-2-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-2-hive-2.3 @@ -194,11 +194,11 @@ log4j-slf4j2-impl/2.19.0//log4j-slf4j2-impl-2.19.0.jar logging-interceptor/3.12.12//logging-interceptor-3.12.12.jar lz4-java/1.8.0//lz4-java-1.8.0.jar mesos/1.4.3/shaded-protobuf/mesos-1.4.3-shaded-protobuf.jar -metrics-core/4.2.15//metrics-core-4.2.15.jar -metrics-graphite/4.2.15//metrics-graphite-4.2.15.jar -metrics-jmx/4.2.15//metrics-jmx-4.2.15.jar -metrics-json/4.2.15//metrics-json-4.2.15.jar -metrics-jvm/4.2.15//metrics-jvm-4.2.15.jar +metrics-core/4.2.17//metrics-core-4.2.17.jar +metrics-graphite/4.2.17//metrics-graphite-4.2.17.jar +metrics-jmx/4.2.17//metrics-jmx-4.2.17.jar +metrics-json/4.2.17//metrics-json-4.2.17.jar +metrics-jvm/4.2.17//metrics-jvm-4.2.17.jar minlog/1.3.0//minlog-1.3.0.jar netty-all/4.1.89.Final//netty-all-4.1.89.Final.jar netty-buffer/4.1.89.Final//netty-buffer-4.1.89.Final.jar diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3 b/dev/deps/spark-deps-hadoop-3-hive-2.3 index b25f1680854..fee97a4e659 100644 --- a/dev/deps/spark-deps-hadoop-3-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-3-hive-2.3 @@ -178,11 +178,11 @@ log4j-slf4j2-impl/2.19.0//log4j-slf4j2-impl-2.19.0.jar logging-interceptor/3.12.12//logging-interceptor-3.12.12.jar lz4-java/1.8.0//lz4-java-1.8.0.jar mesos/1.4.3/shaded-protobuf/mesos-1.4.3-shaded-protobuf.jar -metrics-core/4.2.15//metrics-core-4.2.15.jar -metrics-graphite/4.2.15//metrics-graphite-4.2.15.jar -metrics-jmx/4.2.15//metrics-jmx-4.2.15.jar -metrics-json/4.2.15//metrics-json-4.2.15.jar -metrics-jvm/4.2.15//metrics-jvm-4.2.15.jar +metrics-core/4.2.17//metrics-core-4.2.17.jar +metrics-graphite/4.2.17//metrics-graphite-4.2.17.jar +metrics-jmx/4.2.17//metrics-jmx-4.2.17.jar +metrics-json/4.2.17//metrics-json-4.2.17.jar +metrics-jvm/4.2.17//metrics-jvm-4.2.17.jar minlog/1.3.0//minlog-1.3.0.jar netty-all/4.1.89.Final//netty-all-4.1.89.Final.jar netty-buffer/4.1.89.Final//netty-buffer-4.1.89.Final.jar diff --git a/pom.xml b/pom.xml index f233fe4654a..6e31e60db29 100644 --- a/pom.xml +++ b/pom.xml @@ -152,7 +152,7 @@ If you changes codahale.metrics.version, you also need to change the link to metrics.dropwizard.io in docs/monitoring.md. --> -4.2.15 +4.2.17 1.11.1 1.12.0 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42648][BUILD] Upgrade `versions-maven-plugin` to 2.15.0
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 037e6cf7674 [SPARK-42648][BUILD] Upgrade `versions-maven-plugin` to 2.15.0 037e6cf7674 is described below commit 037e6cf7674069f9ed4fd45f0c8e2ec46234ed6b Author: yangjie01 AuthorDate: Fri Mar 3 08:10:14 2023 -0600 [SPARK-42648][BUILD] Upgrade `versions-maven-plugin` to 2.15.0 ### What changes were proposed in this pull request? This pr aims upgrade `versions-maven-plugin` to 2.15.0 ### Why are the changes needed? New version bring some improvements like: - https://github.com/mojohaus/versions/pull/898 - https://github.com/mojohaus/versions/pull/883 - https://github.com/mojohaus/versions/pull/878 - https://github.com/mojohaus/versions/pull/893 and some bug fix: - https://github.com/mojohaus/versions/pull/901 - https://github.com/mojohaus/versions/pull/897 - https://github.com/mojohaus/versions/pull/891 The full release notes as follows: - https://github.com/mojohaus/versions/releases/tag/2.15.0 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - GA `Dependencies test` should work normally - Manually check `./dev/test-dependencies.sh --replace-manifest`, run successful Closes #40248 from LuciferYang/SPARK-42648. Authored-by: yangjie01 Signed-off-by: Sean Owen --- pom.xml | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/pom.xml b/pom.xml index 1db6d565bad..f233fe4654a 100644 --- a/pom.xml +++ b/pom.xml @@ -177,7 +177,7 @@ See: SPARK-36547, SPARK-38394. --> 4.8.0 -2.14.2 +2.15.0 true true - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-42647][PYTHON] Change alias for numpy deprecated and removed types
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new 7151667cf4d [SPARK-42647][PYTHON] Change alias for numpy deprecated
and removed types
7151667cf4d is described below
commit 7151667cf4d6f5c2b86812132cfab27ec5e151e0
Author: Aimilios Tsouvelekakis
AuthorDate: Thu Mar 2 18:50:20 2023 -0600
[SPARK-42647][PYTHON] Change alias for numpy deprecated and removed types
### Problem description
Numpy has started changing the alias to some of its data-types. This means
that users with the latest version of numpy they will face either warnings or
errors according to the type that they are using. This affects all the users
using numoy > 1.20.0
One of the types was fixed back in September with this
[pull](https://github.com/apache/spark/pull/37817) request
[numpy 1.24.0](https://github.com/numpy/numpy/pull/22607): The scalar type
aliases ending in a 0 bit size: np.object0, np.str0, np.bytes0, np.void0,
np.int0, np.uint0 as well as np.bool8 are now deprecated and will eventually be
removed.
[numpy 1.20.0](https://github.com/numpy/numpy/pull/14882): Using the
aliases of builtin types like np.int is deprecated
### What changes were proposed in this pull request?
From numpy 1.20.0 we receive a deprecattion warning on
np.object(https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations) and
from numpy 1.24.0 we received an attribute error:
```
attr = 'object'
def __getattr__(attr):
# Warn for expired attributes, and return a dummy function
# that always raises an exception.
import warnings
try:
msg = __expired_functions__[attr]
except KeyError:
pass
else:
warnings.warn(msg, DeprecationWarning, stacklevel=2)
def _expired(*args, **kwds):
raise RuntimeError(msg)
return _expired
# Emit warnings for deprecated attributes
try:
val, msg = __deprecated_attrs__[attr]
except KeyError:
pass
else:
warnings.warn(msg, DeprecationWarning, stacklevel=2)
return val
if attr in __future_scalars__:
# And future warnings for those that will change, but also give
# the AttributeError
warnings.warn(
f"In the future `np.{attr}` will be defined as the "
"corresponding NumPy scalar.", FutureWarning, stacklevel=2)
if attr in __former_attrs__:
> raise AttributeError(__former_attrs__[attr])
E AttributeError: module 'numpy' has no attribute 'object'.
E `np.object` was a deprecated alias for the builtin `object`. To
avoid this error in existing code, use `object` by itself. Doing this will not
modify any behavior and is safe.
E The aliases was originally deprecated in NumPy 1.20; for more
details and guidance see the original release note at:
E
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
```
From numpy version 1.24.0 we receive a deprecation warning on np.object0
and every np.datatype0 and np.bool8
>>> np.object0(123)
:1: DeprecationWarning: `np.object0` is a deprecated alias for
``np.object0` is a deprecated alias for `np.object_`. `object` can be used
instead. (Deprecated NumPy 1.24)`. (Deprecated NumPy 1.24)
### Why are the changes needed?
The changes are needed so pyspark can be compatible with the latest numpy
and avoid
- attribute errors on data types being deprecated from version 1.20.0:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
- warnings on deprecated data types from version 1.24.0:
https://numpy.org/devdocs/release/1.24.0-notes.html#deprecations
### Does this PR introduce _any_ user-facing change?
The change will suppress the warning coming from numpy 1.24.0 and the error
coming from numpy 1.22.0
### How was this patch tested?
I assume that the existing tests should catch this. (see all section Extra
questions)
I found this to be a problem in my work's project where we use for our unit
tests the toPandas() function to convert to np.object. Attaching the run result
of our test:
```
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
_ _ _ _ _ _ _ _ _ _ _ _ _
/usr/local/lib/python3.9/dist-packages//unit/spark_test.py:64: in
run_testcase
self.handler.
[spark] branch branch-3.3 updated: [SPARK-42647][PYTHON] Change alias for numpy deprecated and removed types
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 20870c3d157 [SPARK-42647][PYTHON] Change alias for numpy deprecated
and removed types
20870c3d157 is described below
commit 20870c3d157ef2c154301046caa6b71cb186a4ad
Author: Aimilios Tsouvelekakis
AuthorDate: Thu Mar 2 18:50:20 2023 -0600
[SPARK-42647][PYTHON] Change alias for numpy deprecated and removed types
### Problem description
Numpy has started changing the alias to some of its data-types. This means
that users with the latest version of numpy they will face either warnings or
errors according to the type that they are using. This affects all the users
using numoy > 1.20.0
One of the types was fixed back in September with this
[pull](https://github.com/apache/spark/pull/37817) request
[numpy 1.24.0](https://github.com/numpy/numpy/pull/22607): The scalar type
aliases ending in a 0 bit size: np.object0, np.str0, np.bytes0, np.void0,
np.int0, np.uint0 as well as np.bool8 are now deprecated and will eventually be
removed.
[numpy 1.20.0](https://github.com/numpy/numpy/pull/14882): Using the
aliases of builtin types like np.int is deprecated
### What changes were proposed in this pull request?
From numpy 1.20.0 we receive a deprecattion warning on
np.object(https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations) and
from numpy 1.24.0 we received an attribute error:
```
attr = 'object'
def __getattr__(attr):
# Warn for expired attributes, and return a dummy function
# that always raises an exception.
import warnings
try:
msg = __expired_functions__[attr]
except KeyError:
pass
else:
warnings.warn(msg, DeprecationWarning, stacklevel=2)
def _expired(*args, **kwds):
raise RuntimeError(msg)
return _expired
# Emit warnings for deprecated attributes
try:
val, msg = __deprecated_attrs__[attr]
except KeyError:
pass
else:
warnings.warn(msg, DeprecationWarning, stacklevel=2)
return val
if attr in __future_scalars__:
# And future warnings for those that will change, but also give
# the AttributeError
warnings.warn(
f"In the future `np.{attr}` will be defined as the "
"corresponding NumPy scalar.", FutureWarning, stacklevel=2)
if attr in __former_attrs__:
> raise AttributeError(__former_attrs__[attr])
E AttributeError: module 'numpy' has no attribute 'object'.
E `np.object` was a deprecated alias for the builtin `object`. To
avoid this error in existing code, use `object` by itself. Doing this will not
modify any behavior and is safe.
E The aliases was originally deprecated in NumPy 1.20; for more
details and guidance see the original release note at:
E
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
```
From numpy version 1.24.0 we receive a deprecation warning on np.object0
and every np.datatype0 and np.bool8
>>> np.object0(123)
:1: DeprecationWarning: `np.object0` is a deprecated alias for
``np.object0` is a deprecated alias for `np.object_`. `object` can be used
instead. (Deprecated NumPy 1.24)`. (Deprecated NumPy 1.24)
### Why are the changes needed?
The changes are needed so pyspark can be compatible with the latest numpy
and avoid
- attribute errors on data types being deprecated from version 1.20.0:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
- warnings on deprecated data types from version 1.24.0:
https://numpy.org/devdocs/release/1.24.0-notes.html#deprecations
### Does this PR introduce _any_ user-facing change?
The change will suppress the warning coming from numpy 1.24.0 and the error
coming from numpy 1.22.0
### How was this patch tested?
I assume that the existing tests should catch this. (see all section Extra
questions)
I found this to be a problem in my work's project where we use for our unit
tests the toPandas() function to convert to np.object. Attaching the run result
of our test:
```
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
_ _ _ _ _ _ _ _ _ _ _ _ _
/usr/local/lib/python3.9/dist-packages//unit/spark_test.py:64: in
run_testcase
self.handler.
[spark] branch master updated: [SPARK-42647][PYTHON] Change alias for numpy deprecated and removed types
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new b3c26b8b3aa [SPARK-42647][PYTHON] Change alias for numpy deprecated
and removed types
b3c26b8b3aa is described below
commit b3c26b8b3aa90c829aec50ba170d14873ca5bde9
Author: Aimilios Tsouvelekakis
AuthorDate: Thu Mar 2 18:50:20 2023 -0600
[SPARK-42647][PYTHON] Change alias for numpy deprecated and removed types
### Problem description
Numpy has started changing the alias to some of its data-types. This means
that users with the latest version of numpy they will face either warnings or
errors according to the type that they are using. This affects all the users
using numoy > 1.20.0
One of the types was fixed back in September with this
[pull](https://github.com/apache/spark/pull/37817) request
[numpy 1.24.0](https://github.com/numpy/numpy/pull/22607): The scalar type
aliases ending in a 0 bit size: np.object0, np.str0, np.bytes0, np.void0,
np.int0, np.uint0 as well as np.bool8 are now deprecated and will eventually be
removed.
[numpy 1.20.0](https://github.com/numpy/numpy/pull/14882): Using the
aliases of builtin types like np.int is deprecated
### What changes were proposed in this pull request?
From numpy 1.20.0 we receive a deprecattion warning on
np.object(https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations) and
from numpy 1.24.0 we received an attribute error:
```
attr = 'object'
def __getattr__(attr):
# Warn for expired attributes, and return a dummy function
# that always raises an exception.
import warnings
try:
msg = __expired_functions__[attr]
except KeyError:
pass
else:
warnings.warn(msg, DeprecationWarning, stacklevel=2)
def _expired(*args, **kwds):
raise RuntimeError(msg)
return _expired
# Emit warnings for deprecated attributes
try:
val, msg = __deprecated_attrs__[attr]
except KeyError:
pass
else:
warnings.warn(msg, DeprecationWarning, stacklevel=2)
return val
if attr in __future_scalars__:
# And future warnings for those that will change, but also give
# the AttributeError
warnings.warn(
f"In the future `np.{attr}` will be defined as the "
"corresponding NumPy scalar.", FutureWarning, stacklevel=2)
if attr in __former_attrs__:
> raise AttributeError(__former_attrs__[attr])
E AttributeError: module 'numpy' has no attribute 'object'.
E `np.object` was a deprecated alias for the builtin `object`. To
avoid this error in existing code, use `object` by itself. Doing this will not
modify any behavior and is safe.
E The aliases was originally deprecated in NumPy 1.20; for more
details and guidance see the original release note at:
E
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
```
From numpy version 1.24.0 we receive a deprecation warning on np.object0
and every np.datatype0 and np.bool8
>>> np.object0(123)
:1: DeprecationWarning: `np.object0` is a deprecated alias for
``np.object0` is a deprecated alias for `np.object_`. `object` can be used
instead. (Deprecated NumPy 1.24)`. (Deprecated NumPy 1.24)
### Why are the changes needed?
The changes are needed so pyspark can be compatible with the latest numpy
and avoid
- attribute errors on data types being deprecated from version 1.20.0:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
- warnings on deprecated data types from version 1.24.0:
https://numpy.org/devdocs/release/1.24.0-notes.html#deprecations
### Does this PR introduce _any_ user-facing change?
The change will suppress the warning coming from numpy 1.24.0 and the error
coming from numpy 1.22.0
### How was this patch tested?
I assume that the existing tests should catch this. (see all section Extra
questions)
I found this to be a problem in my work's project where we use for our unit
tests the toPandas() function to convert to np.object. Attaching the run result
of our test:
```
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
_ _ _ _ _ _ _ _ _ _ _ _ _
/usr/local/lib/python3.9/dist-packages//unit/spark_test.py:64: in
run_testcase
self.handler.
[spark] branch branch-3.4 updated: [SPARK-42622][CORE] Disable substitution in values
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.4
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.4 by this push:
new 06c5feddc0a [SPARK-42622][CORE] Disable substitution in values
06c5feddc0a is described below
commit 06c5feddc0aaf7b8528d4711f900548513deb30f
Author: Jelmer Kuperus
AuthorDate: Thu Mar 2 08:43:32 2023 -0600
[SPARK-42622][CORE] Disable substitution in values
https://issues.apache.org/jira/browse/SPARK-42622
### What changes were proposed in this pull request?
Disable substitution in values for the `StringSubstitutor` used to resolve
error messages
### Why are the changes needed?
when constructing an error message `ErrorClasssesJSONReader`
1. reads the error message from
core/src/main/resources/error/error-classes.json
2. replaces `` with `${fieldValue}` in the error message it read
3. uses `StringSubstitutor` to replace `${fieldValue}` with the actual value
If `fieldValue` is defined as `"${foo}"` then it will also try and resolve
foo.
When foo is undefined it will throw an IllegalArgumentException
This is very problematic instance in this scenario. Where parsing json will
fail if it does not adhere to the correct schema

Here the error message produced will be something like
`Cannot parse the field name properties and the value ${foo} of the JSON
token type string to target Spark data type struct.`
And because foo is undefined another error will be triggered, and another,
and another.. until you have a stackoverflow.
It could be employed as a denial of service attack on data pipelines
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Locally
Before
After
Closes #40219 from jelmerk/jelmer/no_string_substitutor.
Authored-by: Jelmer Kuperus
Signed-off-by: Sean Owen
(cherry picked from commit 258746f7f89352266e4ac367e29aac9fe542dd15)
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/ErrorClassesJSONReader.scala | 1 +
.../src/test/scala/org/apache/spark/SparkThrowableSuite.scala | 11 +++
2 files changed, 12 insertions(+)
diff --git a/core/src/main/scala/org/apache/spark/ErrorClassesJSONReader.scala
b/core/src/main/scala/org/apache/spark/ErrorClassesJSONReader.scala
index 34dd13addff..ca7b9cc1bd6 100644
--- a/core/src/main/scala/org/apache/spark/ErrorClassesJSONReader.scala
+++ b/core/src/main/scala/org/apache/spark/ErrorClassesJSONReader.scala
@@ -47,6 +47,7 @@ class ErrorClassesJsonReader(jsonFileURLs: Seq[URL]) {
val messageTemplate = getMessageTemplate(errorClass)
val sub = new StringSubstitutor(messageParameters.asJava)
sub.setEnableUndefinedVariableException(true)
+sub.setDisableSubstitutionInValues(true)
try {
sub.replace(messageTemplate.replaceAll("<([a-zA-Z0-9_-]+)>",
"\\$\\{$1\\}"))
} catch {
diff --git a/core/src/test/scala/org/apache/spark/SparkThrowableSuite.scala
b/core/src/test/scala/org/apache/spark/SparkThrowableSuite.scala
index c20c287c564..a8c56cf1460 100644
--- a/core/src/test/scala/org/apache/spark/SparkThrowableSuite.scala
+++ b/core/src/test/scala/org/apache/spark/SparkThrowableSuite.scala
@@ -210,6 +210,17 @@ class SparkThrowableSuite extends SparkFunSuite {
)
}
+ test("Error message does not do substitution on values") {
+assert(
+ getMessage(
+"UNRESOLVED_COLUMN.WITH_SUGGESTION",
+Map("objectName" -> "`foo`", "proposal" -> "`${bar}`, `baz`")
+ ) ==
+"[UNRESOLVED_COLUMN.WITH_SUGGESTION] A column or function parameter
with " +
+ "name `foo` cannot be resolved. Did you mean one of the following?
[`${bar}`, `baz`]."
+)
+ }
+
test("Try catching legacy SparkError") {
try {
throw new SparkException("Arbitrary legacy message")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42622][CORE] Disable substitution in values
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 258746f7f89 [SPARK-42622][CORE] Disable substitution in values
258746f7f89 is described below
commit 258746f7f89352266e4ac367e29aac9fe542dd15
Author: Jelmer Kuperus
AuthorDate: Thu Mar 2 08:43:32 2023 -0600
[SPARK-42622][CORE] Disable substitution in values
https://issues.apache.org/jira/browse/SPARK-42622
### What changes were proposed in this pull request?
Disable substitution in values for the `StringSubstitutor` used to resolve
error messages
### Why are the changes needed?
when constructing an error message `ErrorClasssesJSONReader`
1. reads the error message from
core/src/main/resources/error/error-classes.json
2. replaces `` with `${fieldValue}` in the error message it read
3. uses `StringSubstitutor` to replace `${fieldValue}` with the actual value
If `fieldValue` is defined as `"${foo}"` then it will also try and resolve
foo.
When foo is undefined it will throw an IllegalArgumentException
This is very problematic instance in this scenario. Where parsing json will
fail if it does not adhere to the correct schema

Here the error message produced will be something like
`Cannot parse the field name properties and the value ${foo} of the JSON
token type string to target Spark data type struct.`
And because foo is undefined another error will be triggered, and another,
and another.. until you have a stackoverflow.
It could be employed as a denial of service attack on data pipelines
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Locally
Before

After

Closes #40219 from jelmerk/jelmer/no_string_substitutor.
Authored-by: Jelmer Kuperus
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/ErrorClassesJSONReader.scala | 1 +
.../src/test/scala/org/apache/spark/SparkThrowableSuite.scala | 11 +++
2 files changed, 12 insertions(+)
diff --git a/core/src/main/scala/org/apache/spark/ErrorClassesJSONReader.scala
b/core/src/main/scala/org/apache/spark/ErrorClassesJSONReader.scala
index 34dd13addff..ca7b9cc1bd6 100644
--- a/core/src/main/scala/org/apache/spark/ErrorClassesJSONReader.scala
+++ b/core/src/main/scala/org/apache/spark/ErrorClassesJSONReader.scala
@@ -47,6 +47,7 @@ class ErrorClassesJsonReader(jsonFileURLs: Seq[URL]) {
val messageTemplate = getMessageTemplate(errorClass)
val sub = new StringSubstitutor(messageParameters.asJava)
sub.setEnableUndefinedVariableException(true)
+sub.setDisableSubstitutionInValues(true)
try {
sub.replace(messageTemplate.replaceAll("<([a-zA-Z0-9_-]+)>",
"\\$\\{$1\\}"))
} catch {
diff --git a/core/src/test/scala/org/apache/spark/SparkThrowableSuite.scala
b/core/src/test/scala/org/apache/spark/SparkThrowableSuite.scala
index c20c287c564..a8c56cf1460 100644
--- a/core/src/test/scala/org/apache/spark/SparkThrowableSuite.scala
+++ b/core/src/test/scala/org/apache/spark/SparkThrowableSuite.scala
@@ -210,6 +210,17 @@ class SparkThrowableSuite extends SparkFunSuite {
)
}
+ test("Error message does not do substitution on values") {
+assert(
+ getMessage(
+"UNRESOLVED_COLUMN.WITH_SUGGESTION",
+Map("objectName" -> "`foo`", "proposal" -> "`${bar}`, `baz`")
+ ) ==
+"[UNRESOLVED_COLUMN.WITH_SUGGESTION] A column or function parameter
with " +
+ "name `foo` cannot be resolved. Did you mean one of the following?
[`${bar}`, `baz`]."
+)
+ }
+
test("Try catching legacy SparkError") {
try {
throw new SparkException("Arbitrary legacy message")
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (9d2fe90c9c8 -> 3b258ef949b)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 9d2fe90c9c8 [SPARK-42593][PS] Deprecate & remove the APIs that will be removed in pandas 2.0 add 3b258ef949b [MINOR][BUILD] Delete a invalid TODO from `dev/test-dependencies.sh` No new revisions were added by this update. Summary of changes: dev/test-dependencies.sh | 1 - 1 file changed, 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42491][BUILD] Upgrade jetty to 9.4.51.v20230217
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new e11b331c637 [SPARK-42491][BUILD] Upgrade jetty to 9.4.51.v20230217 e11b331c637 is described below commit e11b331c637043bb48b885ee13e06bd7ce708ba8 Author: yangjie01 AuthorDate: Tue Feb 28 20:44:28 2023 -0600 [SPARK-42491][BUILD] Upgrade jetty to 9.4.51.v20230217 ### What changes were proposed in this pull request? This pr aims upgrade jetty from 9.4.50.v20221201 to 9.4.51.v20230217. ### Why are the changes needed? The main change of this version includes: - https://github.com/eclipse/jetty.project/pull/9352 - https://github.com/eclipse/jetty.project/pull/9345 The release notes as follows: - https://github.com/eclipse/jetty.project/releases/tag/jetty-9.4.51.v20230217 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass Github Actions Closes #40214 from LuciferYang/jetty-9451. Authored-by: yangjie01 Signed-off-by: Sean Owen --- dev/deps/spark-deps-hadoop-2-hive-2.3 | 2 +- dev/deps/spark-deps-hadoop-3-hive-2.3 | 4 ++-- pom.xml | 2 +- 3 files changed, 4 insertions(+), 4 deletions(-) diff --git a/dev/deps/spark-deps-hadoop-2-hive-2.3 b/dev/deps/spark-deps-hadoop-2-hive-2.3 index 6abe6cb768e..3d338059d83 100644 --- a/dev/deps/spark-deps-hadoop-2-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-2-hive-2.3 @@ -143,7 +143,7 @@ jersey-hk2/2.36//jersey-hk2-2.36.jar jersey-server/2.36//jersey-server-2.36.jar jetty-sslengine/6.1.26//jetty-sslengine-6.1.26.jar jetty-util/6.1.26//jetty-util-6.1.26.jar -jetty-util/9.4.50.v20221201//jetty-util-9.4.50.v20221201.jar +jetty-util/9.4.51.v20230217//jetty-util-9.4.51.v20230217.jar jetty/6.1.26//jetty-6.1.26.jar jline/2.14.6//jline-2.14.6.jar joda-time/2.12.2//joda-time-2.12.2.jar diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3 b/dev/deps/spark-deps-hadoop-3-hive-2.3 index 17acf370720..b25f1680854 100644 --- a/dev/deps/spark-deps-hadoop-3-hive-2.3 +++ b/dev/deps/spark-deps-hadoop-3-hive-2.3 @@ -128,8 +128,8 @@ jersey-container-servlet/2.36//jersey-container-servlet-2.36.jar jersey-hk2/2.36//jersey-hk2-2.36.jar jersey-server/2.36//jersey-server-2.36.jar jettison/1.1//jettison-1.1.jar -jetty-util-ajax/9.4.50.v20221201//jetty-util-ajax-9.4.50.v20221201.jar -jetty-util/9.4.50.v20221201//jetty-util-9.4.50.v20221201.jar +jetty-util-ajax/9.4.51.v20230217//jetty-util-ajax-9.4.51.v20230217.jar +jetty-util/9.4.51.v20230217//jetty-util-9.4.51.v20230217.jar jline/2.14.6//jline-2.14.6.jar joda-time/2.12.2//joda-time-2.12.2.jar jodd-core/3.5.2//jodd-core-3.5.2.jar diff --git a/pom.xml b/pom.xml index 4bd2639e9a7..1db6d565bad 100644 --- a/pom.xml +++ b/pom.xml @@ -143,7 +143,7 @@ 1.12.3 1.8.2 shaded-protobuf -9.4.50.v20221201 +9.4.51.v20230217 4.0.3 0.10.0 2.5.1 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Remove Jenkins from pages
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch asf-site
in repository https://gitbox.apache.org/repos/asf/spark-website.git
The following commit(s) were added to refs/heads/asf-site by this push:
new 48d982a6f1 Remove Jenkins from pages
48d982a6f1 is described below
commit 48d982a6f19bebf60584b8aa8c287ecf2adc81c9
Author: Bjørn
AuthorDate: Sat Feb 25 14:10:36 2023 -0600
Remove Jenkins from pages
`bundle exec jekyll build --watch`
Removed info about Jerkins from the developer-tools.md fil
Regenerating: 1 file(s) changed at 2023-02-25 15:14:42
developer-tools.md
...done in 2.778396909 seconds.
We don't use Jenkins anymore so we can remove this info.
Author: Bjørn
Closes #442 from bjornjorgensen/remove-Jenkins-form-dev.tools.
---
contributing.md | 15 ---
developer-tools.md| 23 ---
release-process.md| 10 --
site/contributing.html| 21 -
site/developer-tools.html | 24
site/release-process.html | 9 -
6 files changed, 102 deletions(-)
diff --git a/contributing.md b/contributing.md
index b127afe919..8f0ec49869 100644
--- a/contributing.md
+++ b/contributing.md
@@ -387,21 +387,6 @@ will trigger workflows "On pull request*" (on Spark repo)
that will look/watch f
1. The related JIRA, if any, will be marked as "In Progress" and your pull
request will
automatically be linked to it. There is no need to be the Assignee of the JIRA
to work on it,
though you are welcome to comment that you have begun work.
-1. The Jenkins automatic pull request builder will test your changes
- 1. If it is your first contribution, Jenkins will wait for confirmation
before building
- your code and post "Can one of the admins verify this patch?"
- 1. A committer can authorize testing with a comment like "ok to test"
- 1. A committer can automatically allow future pull requests from a
contributor to be
- tested with a comment like "Jenkins, add to whitelist"
-1. After about 2 hours, Jenkins will post the results of the test to the pull
request, along
-with a link to the full results on Jenkins.
-1. Watch for the results, and investigate and fix failures promptly
- 1. Fixes can simply be pushed to the same branch from which you opened
your pull request
- 1. Jenkins will automatically re-test when new commits are pushed
- 1. If the tests failed for reasons unrelated to the change (e.g. Jenkins
outage), then a
- committer can request a re-test with "Jenkins, retest this please".
- Ask if you need a test restarted. If you were added by "Jenkins, add to
whitelist" from a
- committer before, you can also request the re-test.
1. If there is a change related to SparkR in your pull request, AppVeyor will
be triggered
automatically to test SparkR on Windows, which takes roughly an hour.
Similarly to the steps
above, fix failures and push new commits which will request the re-test in
AppVeyor.
diff --git a/developer-tools.md b/developer-tools.md
index c8b8892b89..fdbf88796e 100644
--- a/developer-tools.md
+++ b/developer-tools.md
@@ -240,18 +240,6 @@ sufficient to run a test from the command line:
build/sbt "testOnly org.apache.spark.rdd.SortingSuite"
```
-Running different test permutations on Jenkins
-
-When running tests for a pull request on Jenkins, you can add special phrases
to the title of
-your pull request to change testing behavior. This includes:
-
-- `[test-maven]` - signals to test the pull request using maven
-- `[test-hadoop2.7]` - signals to test using Spark's Hadoop 2.7 profile
-- `[test-hadoop3.2]` - signals to test using Spark's Hadoop 3.2 profile
-- `[test-hadoop3.2][test-java11]` - signals to test using Spark's Hadoop 3.2
profile with JDK 11
-- `[test-hive1.2]` - signals to test using Spark's Hive 1.2 profile
-- `[test-hive2.3]` - signals to test using Spark's Hive 2.3 profile
-
Binary compatibility
To ensure binary compatibility, Spark uses
[MiMa](https://github.com/typesafehub/migration-manager).
@@ -274,17 +262,6 @@ A binary incompatibility reported by MiMa might look like
the following:
[error] filter with:
ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.SomeClass.this")
```
-If you open a pull request containing binary incompatibilities anyway, Jenkins
-will remind you by failing the test build with the following message:
-
-```
-Test build #xx has finished for PR yy at commit ff.
-
- This patch fails MiMa tests.
- This patch merges cleanly.
- This patch adds no public classes.
-```
-
Solving a binary incompatibility
If you believe that your binary incompatibilies are justified or that MiMa
diff --git a
[spark] branch branch-3.3 updated: [SPARK-40376][PYTHON] Avoid Numpy deprecation warning
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.3 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.3 by this push: new 52d52a158c9 [SPARK-40376][PYTHON] Avoid Numpy deprecation warning 52d52a158c9 is described below commit 52d52a158c9a169d97122523142b7c3026ee92bb Author: ELHoussineT AuthorDate: Mon Sep 12 20:46:15 2022 -0500 [SPARK-40376][PYTHON] Avoid Numpy deprecation warning ### What changes were proposed in this pull request? Use `bool` instead of `np.bool` as `np.bool` will be deprecated (see: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations) Using `np.bool` generates this warning: ``` UserWarning: toPandas attempted Arrow optimization because 'spark.sql.execution.arrow.pyspark.enabled' is set to true, but has reached the error below and can not continue. Note that 'spark.sql.execution.arrow.pyspark.fallback.enabled' does not have an effect on failures in the middle of computation. 3070E `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here. 3071E Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations ``` ### Why are the changes needed? Deprecation soon: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations. ### Does this PR introduce _any_ user-facing change? The warning will be suppressed ### How was this patch tested? Existing tests should suffice. Closes #37817 from ELHoussineT/patch-1. Authored-by: ELHoussineT Signed-off-by: Sean Owen --- python/pyspark/sql/pandas/conversion.py | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) diff --git a/python/pyspark/sql/pandas/conversion.py b/python/pyspark/sql/pandas/conversion.py index fff0bac5480..22717241fde 100644 --- a/python/pyspark/sql/pandas/conversion.py +++ b/python/pyspark/sql/pandas/conversion.py @@ -295,7 +295,7 @@ class PandasConversionMixin: elif type(dt) == DoubleType: return np.float64 elif type(dt) == BooleanType: -return np.bool # type: ignore[attr-defined] +return bool elif type(dt) == TimestampType: return np.datetime64 elif type(dt) == TimestampNTZType: - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42490][BUILD] Upgrade protobuf-java from 3.21.12 to 3.22.0
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 66ab715a6be [SPARK-42490][BUILD] Upgrade protobuf-java from 3.21.12 to
3.22.0
66ab715a6be is described below
commit 66ab715a6bef2d88edc33f146a6c7a504cc7c388
Author: yangjie01
AuthorDate: Mon Feb 20 08:17:13 2023 -0600
[SPARK-42490][BUILD] Upgrade protobuf-java from 3.21.12 to 3.22.0
### What changes were proposed in this pull request?
This pr aims upgrade `protobuf-java` from 3.21.12 to 3.22.0
### Why are the changes needed?
The new version bring some improvements like:
- Use bit-field int values in buildPartial to skip work on unset groups of
fields.
(https://github.com/protocolbuffers/protobuf/commit/2326aef1a454a4eea363cc6ed8b8def8b88365f5)
- Fix serialization warnings in generated code when compiling with Java 18
and above (https://github.com/protocolbuffers/protobuf/pull/10561)
- Enable Text format parser to skip unknown short-formed repeated fields.
(https://github.com/protocolbuffers/protobuf/commit/6dbd4131fa6b2ad29b2b1b827f21fc61b160aeeb)
- Add serialVersionUID to ByteString and subclasses
(https://github.com/protocolbuffers/protobuf/pull/10718)
and some bug fix like:
- Mark default instance as immutable first to avoid race during static
initialization of default instances.
(https://github.com/protocolbuffers/protobuf/pull/10770)
- Fix Timestamps fromDate for negative 'exact second' java.sql.Timestamps
(https://github.com/protocolbuffers/protobuf/pull/10321)
- Fix Timestamps.fromDate to correctly handle java.sql.Timestamps before
unix epoch (https://github.com/protocolbuffers/protobuf/pull/10126)
- Fix bug in nested builder caching logic where cleared sub-field builders
would remain dirty after a clear and build in a parent layer.
https://github.com/protocolbuffers/protobuf/issues/10624
The release notes as follows:
- https://github.com/protocolbuffers/protobuf/releases/tag/v22.0
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GitHub Actions
Closes #40084 from LuciferYang/SPARK-42490.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
pom.xml | 2 +-
project/SparkBuild.scala | 2 +-
2 files changed, 2 insertions(+), 2 deletions(-)
diff --git a/pom.xml b/pom.xml
index 7a81101d2d4..ae65be7d3e3 100644
--- a/pom.xml
+++ b/pom.xml
@@ -124,7 +124,7 @@
2.5.0
-3.21.12
+3.22.0
3.11.4
${hadoop.version}
3.6.3
diff --git a/project/SparkBuild.scala b/project/SparkBuild.scala
index 4b077f593fe..2c3907bc734 100644
--- a/project/SparkBuild.scala
+++ b/project/SparkBuild.scala
@@ -88,7 +88,7 @@ object BuildCommons {
// Google Protobuf version used for generating the protobuf.
// SPARK-41247: needs to be consistent with `protobuf.version` in `pom.xml`.
- val protoVersion = "3.21.12"
+ val protoVersion = "3.22.0"
// GRPC version used for Spark Connect.
val gprcVersion = "1.47.0"
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42489][BUILD] Upgrdae scala-parser-combinators from 2.1.1 to 2.2.0
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 09d1e947264 [SPARK-42489][BUILD] Upgrdae scala-parser-combinators from
2.1.1 to 2.2.0
09d1e947264 is described below
commit 09d1e9472642a4ca76cd320f86e1c4373842b113
Author: yangjie01
AuthorDate: Mon Feb 20 08:16:04 2023 -0600
[SPARK-42489][BUILD] Upgrdae scala-parser-combinators from 2.1.1 to 2.2.0
### What changes were proposed in this pull request?
This pr aims upgrade `scala-parser-combinators from` from 2.1.1 to 2.2.0.
### Why are the changes needed?
https://github.com/scala/scala-parser-combinators/pull/496 add
`NoSuccess.I` to helps users avoid exhaustiveness warnings in their pattern
matches, especially on Scala 2.13 and 3. The full release note as follows:
- https://github.com/scala/scala-parser-combinators/releases/tag/v2.2.0
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GitHub Actions
Closes #40083 from LuciferYang/SPARK-42489.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
dev/deps/spark-deps-hadoop-2-hive-2.3 | 2 +-
dev/deps/spark-deps-hadoop-3-hive-2.3 | 2 +-
pom.xml | 2 +-
3 files changed, 3 insertions(+), 3 deletions(-)
diff --git a/dev/deps/spark-deps-hadoop-2-hive-2.3
b/dev/deps/spark-deps-hadoop-2-hive-2.3
index 57739a7c0ff..f858c9782cc 100644
--- a/dev/deps/spark-deps-hadoop-2-hive-2.3
+++ b/dev/deps/spark-deps-hadoop-2-hive-2.3
@@ -242,7 +242,7 @@ rocksdbjni/7.9.2//rocksdbjni-7.9.2.jar
scala-collection-compat_2.12/2.7.0//scala-collection-compat_2.12-2.7.0.jar
scala-compiler/2.12.17//scala-compiler-2.12.17.jar
scala-library/2.12.17//scala-library-2.12.17.jar
-scala-parser-combinators_2.12/2.1.1//scala-parser-combinators_2.12-2.1.1.jar
+scala-parser-combinators_2.12/2.2.0//scala-parser-combinators_2.12-2.2.0.jar
scala-reflect/2.12.17//scala-reflect-2.12.17.jar
scala-xml_2.12/2.1.0//scala-xml_2.12-2.1.0.jar
shims/0.9.39//shims-0.9.39.jar
diff --git a/dev/deps/spark-deps-hadoop-3-hive-2.3
b/dev/deps/spark-deps-hadoop-3-hive-2.3
index 3b54e0365e0..01345fd13ff 100644
--- a/dev/deps/spark-deps-hadoop-3-hive-2.3
+++ b/dev/deps/spark-deps-hadoop-3-hive-2.3
@@ -229,7 +229,7 @@ rocksdbjni/7.9.2//rocksdbjni-7.9.2.jar
scala-collection-compat_2.12/2.7.0//scala-collection-compat_2.12-2.7.0.jar
scala-compiler/2.12.17//scala-compiler-2.12.17.jar
scala-library/2.12.17//scala-library-2.12.17.jar
-scala-parser-combinators_2.12/2.1.1//scala-parser-combinators_2.12-2.1.1.jar
+scala-parser-combinators_2.12/2.2.0//scala-parser-combinators_2.12-2.2.0.jar
scala-reflect/2.12.17//scala-reflect-2.12.17.jar
scala-xml_2.12/2.1.0//scala-xml_2.12-2.1.0.jar
shims/0.9.39//shims-0.9.39.jar
diff --git a/pom.xml b/pom.xml
index e2fee86682d..7a81101d2d4 100644
--- a/pom.xml
+++ b/pom.xml
@@ -1119,7 +1119,7 @@
org.scala-lang.modules
scala-parser-combinators_${scala.binary.version}
-2.1.1
+2.2.0
jline
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Update branch-cut dates in the release cadence
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch asf-site
in repository https://gitbox.apache.org/repos/asf/spark-website.git
The following commit(s) were added to refs/heads/asf-site by this push:
new 020caa52dc Update branch-cut dates in the release cadence
020caa52dc is described below
commit 020caa52dc372dd9aa087b01c3d10b62fc5c83ab
Author: Hyukjin Kwon
AuthorDate: Fri Feb 17 10:41:19 2023 -0600
Update branch-cut dates in the release cadence
This PR updates branch-cut dates as every January and July in the release
cadence.
See also https://lists.apache.org/thread/l6tprb580lrq1118c83kt9fst30jp8n3
Author: Hyukjin Kwon
Closes #438 from HyukjinKwon/release-cadence.
---
site/versioning-policy.html | 4 ++--
versioning-policy.md| 4 ++--
2 files changed, 4 insertions(+), 4 deletions(-)
diff --git a/site/versioning-policy.html b/site/versioning-policy.html
index e9e860615e..80e5121e36 100644
--- a/site/versioning-policy.html
+++ b/site/versioning-policy.html
@@ -246,8 +246,8 @@ available APIs.
Release cadence
-In general, feature (minor) releases occur about every 6
months. Hence, Spark 2.3.0 would
-generally be released about 6 months after 2.2.0. Maintenance releases happen
as needed
+The branch is cut every January and July, so feature (minor)
releases occur about every 6 months in general.
+Hence, Spark 2.3.0 would generally be released about 6 months after 2.2.0.
Maintenance releases happen as needed
in between feature releases. Major releases do not happen according to a fixed
schedule.
Spark 3.4 release window
diff --git a/versioning-policy.md b/versioning-policy.md
index c5fbe1196b..153085259f 100644
--- a/versioning-policy.md
+++ b/versioning-policy.md
@@ -99,8 +99,8 @@ In cases where there is a "Bad API", but where the cost of
removal is also high,
Release cadence
-In general, feature ("minor") releases occur about every 6 months. Hence,
Spark 2.3.0 would
-generally be released about 6 months after 2.2.0. Maintenance releases happen
as needed
+The branch is cut every January and July, so feature ("minor") releases occur
about every 6 months in general.
+Hence, Spark 2.3.0 would generally be released about 6 months after 2.2.0.
Maintenance releases happen as needed
in between feature releases. Major releases do not happen according to a fixed
schedule.
Spark 3.4 release window
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42463][SPARK-27180][YARN][TESTS] Clean up the third-party Java files copy introduced by
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 64e5928e863 [SPARK-42463][SPARK-27180][YARN][TESTS] Clean up the
third-party Java files copy introduced by
64e5928e863 is described below
commit 64e5928e86377a216e48bb7be12150ad130322f3
Author: yangjie01
AuthorDate: Thu Feb 16 09:26:33 2023 -0600
[SPARK-42463][SPARK-27180][YARN][TESTS] Clean up the third-party Java files
copy introduced by
### What changes were proposed in this pull request?
SPARK-27180 introduced some third-party Java source code to solve Yarn
module test failure, but maven and sbt can also test pass without them, so
this pr remove these files.
### Why are the changes needed?
Clean up the third-party Java source code copy in Spark.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
- Pass GitHub Actions
- manual check:
**Maven**
```
build/mvn clean
build/mvn clean install -DskipTestes -pl resource-managers/yarn -am -Pyarn
build/mvn -Dtest=none
-DwildcardSuites=org.apache.spark.deploy.yarn.YarnClusterSuite -pl
resource-managers/yarn test -Pyarn
build/mvn test -pl resource-managers/yarn -Pyarn
-Dtest.exclude.tags=org.apache.spark.tags.ExtendedLevelDBTest
```
Both `YarnClusterSuite` and full module test passed.
**SBT**
```
build/sbt clean yarn/test -Pyarn
-Dtest.exclude.tags=org.apache.spark.tags.ExtendedLevelDBTest
```
All tests passed.
Closes #40052 from LuciferYang/SPARK-42463.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
dev/.rat-excludes | 2 -
.../org/apache/hadoop/net/ServerSocketUtil.java| 132 --
.../org/eclipse/jetty/server/SessionManager.java | 290 -
.../jetty/server/session/SessionHandler.java | 90 ---
4 files changed, 514 deletions(-)
diff --git a/dev/.rat-excludes b/dev/.rat-excludes
index 458fe7594b2..9ac820fc216 100644
--- a/dev/.rat-excludes
+++ b/dev/.rat-excludes
@@ -118,8 +118,6 @@ kafka-source-initial-offset-version-2.1.0.bin
kafka-source-initial-offset-future-version.bin
announce.tmpl
vote.tmpl
-SessionManager.java
-SessionHandler.java
GangliaReporter.java
application_1578436911597_0052
config.properties
diff --git
a/resource-managers/yarn/src/test/java/org/apache/hadoop/net/ServerSocketUtil.java
b/resource-managers/yarn/src/test/java/org/apache/hadoop/net/ServerSocketUtil.java
deleted file mode 100644
index 89e012ecd42..000
---
a/resource-managers/yarn/src/test/java/org/apache/hadoop/net/ServerSocketUtil.java
+++ /dev/null
@@ -1,132 +0,0 @@
-/*
- * Licensed to the Apache Software Foundation (ASF) under one or more
- * contributor license agreements. See the NOTICE file distributed with
- * this work for additional information regarding copyright ownership.
- * The ASF licenses this file to You under the Apache License, Version 2.0
- * (the "License"); you may not use this file except in compliance with
- * the License. You may obtain a copy of the License at
- *
- *http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-package org.apache.hadoop.net;
-
-import org.slf4j.Logger;
-import org.slf4j.LoggerFactory;
-
-import java.io.IOException;
-import java.net.ServerSocket;
-import java.util.Random;
-
-/**
- * Copied from
- *
hadoop-common-project/hadoop-common/src/test/java/org/apache/hadoop/net/ServerSocketUtil.java
- * for Hadoop-3.x testing
- */
-public class ServerSocketUtil {
-
- private static final Logger LOG =
LoggerFactory.getLogger(ServerSocketUtil.class);
- private static Random rand = new Random();
-
- /**
- * Port scan & allocate is how most other apps find ports
- *
- * @param port given port
- * @param retries number of retries
- * @return
- * @throws IOException
- */
- public static int getPort(int port, int retries) throws IOException {
-int tryPort = port;
-int tries = 0;
-while (true) {
- if (tries > 0 || tryPort == 0) {
-tryPort = port + rand.nextInt(65535 - port);
- }
- if (tryPort == 0) {
-continue;
- }
- try (ServerSocket s = new ServerSocket(tryPort)) {
-LOG.info("Using port " + tryPort);
-return tryPort;
- } catch (IOException e) {
-tries++;
-if (tries >= retries) {
- LOG.info("Port is already in use; giv
[spark] branch master updated: [SPARK-42424][YARN] Remove unused declarations from Yarn module
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new f5deb7c9af6 [SPARK-42424][YARN] Remove unused declarations from Yarn
module
f5deb7c9af6 is described below
commit f5deb7c9af618494adecfeb103f94219e27fcf70
Author: yangjie01
AuthorDate: Thu Feb 16 09:25:47 2023 -0600
[SPARK-42424][YARN] Remove unused declarations from Yarn module
### What changes were proposed in this pull request?
This pr cleans up unused declarations in the Yarn module:
- `YarnSparkHadoopUtil#setEnvFromInputString`: this method Introduced by
SPARK-3477 and becomes a unused and no test coverage method after SPARK-17979
- `YarnSparkHadoopUtil#environmentVariableRegex`: this `val` is only used
by `YarnSparkHadoopUtil#setEnvFromInputString`
- `ApplicationMasterArguments.DEFAULT_NUMBER_EXECUTORS`: this `val`
Introduced by SPARK-1946 and replaced by
`YarnSparkHadoopUtil.DEFAULT_NUMBER_EXECUTORS` in SPARK-4138, and It was
eventually replaced by `config#EXECUTOR_INSTANCES`
- `ApplicationMaster.EXIT_SECURITY`: this `val` introduced by SPARK-3627
and it is used to represent the exit code of errors related to
`System.setSecurityManager`, SPARK-4584 deleted the use of `SecurityManager`
and this val is useless.
### Why are the changes needed?
Code clean up.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GitHub Actions
Closes #39997 from LuciferYang/SPARK-42424.
Authored-by: yangjie01
Signed-off-by: Sean Owen
---
.../spark/deploy/yarn/ApplicationMaster.scala | 1 -
.../deploy/yarn/ApplicationMasterArguments.scala | 4 --
.../spark/deploy/yarn/YarnSparkHadoopUtil.scala| 50 --
3 files changed, 55 deletions(-)
diff --git
a/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala
b/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala
index 9815fa6df8a..252c84a1cd4 100644
---
a/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala
+++
b/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMaster.scala
@@ -891,7 +891,6 @@ object ApplicationMaster extends Logging {
private val EXIT_MAX_EXECUTOR_FAILURES = 11
private val EXIT_REPORTER_FAILURE = 12
private val EXIT_SC_NOT_INITED = 13
- private val EXIT_SECURITY = 14
private val EXIT_EXCEPTION_USER_CLASS = 15
private val EXIT_EARLY = 16
private val EXIT_DISCONNECTED = 17
diff --git
a/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMasterArguments.scala
b/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMasterArguments.scala
index d2275980814..821a31502af 100644
---
a/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMasterArguments.scala
+++
b/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/ApplicationMasterArguments.scala
@@ -102,7 +102,3 @@ class ApplicationMasterArguments(val args: Array[String]) {
System.exit(exitCode)
}
}
-
-object ApplicationMasterArguments {
- val DEFAULT_NUMBER_EXECUTORS = 2
-}
diff --git
a/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala
b/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala
index 1869c739e48..4d050b91a85 100644
---
a/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala
+++
b/resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala
@@ -17,8 +17,6 @@
package org.apache.spark.deploy.yarn
-import java.util.regex.{Matcher, Pattern}
-
import scala.collection.immutable.{Map => IMap}
import scala.collection.mutable.{HashMap, ListBuffer}
import scala.util.matching.Regex
@@ -59,41 +57,6 @@ object YarnSparkHadoopUtil {
env.put(key, newValue)
}
- /**
- * Set zero or more environment variables specified by the given input
string.
- * The input string is expected to take the form
"KEY1=VAL1,KEY2=VAL2,KEY3=VAL3".
- */
- def setEnvFromInputString(env: HashMap[String, String], inputString:
String): Unit = {
-if (inputString != null && inputString.length() > 0) {
- val childEnvs = inputString.split(",")
- val p = Pattern.compile(environmentVariableRegex)
- for (cEnv <- childEnvs) {
-val parts = cEnv.split("=") // split on '='
-val m = p.matcher(parts(1))
-val sb = new StringBuffer
-while (m.find()) {
- val variable = m.group(1)
- var replace = ""
- if (env.contains(variable))
[spark] branch master updated (39dbcd7edd3 -> 9b625fdc7dd)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 39dbcd7edd3 [SPARK-42313][SQL] Assign name to `_LEGACY_ERROR_TEMP_1152` add 9b625fdc7dd [SPARK-42422][BUILD] Upgrade `maven-shade-plugin` to 3.4.1 No new revisions were added by this update. Summary of changes: pom.xml | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.4 updated: [SPARK-42422][BUILD] Upgrade `maven-shade-plugin` to 3.4.1
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch branch-3.4 in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/branch-3.4 by this push: new 4a73f25c7a8 [SPARK-42422][BUILD] Upgrade `maven-shade-plugin` to 3.4.1 4a73f25c7a8 is described below commit 4a73f25c7a8b8553d4da84a08c56da5a5e9fb46d Author: yangjie01 AuthorDate: Mon Feb 13 08:27:29 2023 -0600 [SPARK-42422][BUILD] Upgrade `maven-shade-plugin` to 3.4.1 ### What changes were proposed in this pull request? This pr aims upgrade `maven-shade-plugin` from 3.2.4 to 3.4.1 ### Why are the changes needed? The `maven-shade-plugin` was [built by Java 8](https://github.com/apache/maven-shade-plugin/commit/33273411d3033bc866bba46ec5f2fc39e60b) from 3.4.1, all other changes as follows: - https://github.com/apache/maven-shade-plugin/releases/tag/maven-shade-plugin-3.3.0 - https://github.com/apache/maven-shade-plugin/compare/maven-shade-plugin-3.3.0...maven-shade-plugin-3.4.1 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GitHub Actions - Manual check: There are 6 modules actually use shade function, checked the maven compilation logs manually: 1. spark-core Before ``` [INFO] --- maven-shade-plugin:3.2.4:shade (default) spark-core_2.12 --- [INFO] Including org.eclipse.jetty:jetty-plus:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-security:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-util:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-server:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-io:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-http:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-continuation:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-servlet:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-proxy:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-client:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-servlets:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including com.google.protobuf:protobuf-java:jar:3.21.12 in the shaded jar. [INFO] Including org.spark-project.spark:unused:jar:1.0.0 in the shaded jar. ``` After ``` [INFO] --- maven-shade-plugin:3.4.1:shade (default) spark-core_2.12 --- [INFO] Including org.eclipse.jetty:jetty-plus:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-security:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-util:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-server:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-io:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-http:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-continuation:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-servlet:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-proxy:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-client:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including org.eclipse.jetty:jetty-servlets:jar:9.4.50.v20221201 in the shaded jar. [INFO] Including com.google.protobuf:protobuf-java:jar:3.21.12 in the shaded jar. [INFO] Including org.spark-project.spark:unused:jar:1.0.0 in the shaded jar. ``` 2. spark-network-yarn Before ``` [INFO] --- maven-shade-plugin:3.2.4:shade (default) spark-network-yarn_2.12 --- [INFO] Including org.apache.spark:spark-network-shuffle_2.12:jar:3.5.0-SNAPSHOT in the shaded jar. [INFO] Including org.apache.spark:spark-network-common_2.12:jar:3.5.0-SNAPSHOT in the shaded jar. [INFO] Including io.netty:netty-all:jar:4.1.87.Final in the shaded jar. [INFO] Including io.netty:netty-buffer:jar:4.1.87.Final in the shaded jar. [INFO] Including io.netty:netty-codec:jar:4.1.87.Final in the shaded jar. [INFO] Including io.netty:netty-codec-http:jar:4.1.87.Final in the shaded jar. [INFO] Including io.netty:netty-codec-http2:jar:4.1.87.Final in the shaded jar. [INFO] Including io.netty:netty-codec-socks:jar:4.1.87.Final in the shaded jar. [INFO] Including io.netty:netty-common:jar:4.1.87.Final in the shaded jar. [INFO] Including io.netty:netty-handler:jar:4.1.87.Final in the shaded jar
svn commit: r60067 - /release/spark/spark-3.1.3/
Author: srowen Date: Mon Feb 13 04:32:53 2023 New Revision: 60067 Log: Remove EOL Spark 3.1.x Removed: release/spark/spark-3.1.3/ - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (4a27c604eef -> c49b23fd81e)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 4a27c604eef [SPARK-42312][SQL] Assign name to _LEGACY_ERROR_TEMP_0042 add c49b23fd81e [SPARK-42400] Code clean up in org.apache.spark.storage No new revisions were added by this update. Summary of changes: .../main/scala/org/apache/spark/storage/BlockManager.scala | 12 +--- .../main/scala/org/apache/spark/storage/BlockManagerId.scala | 2 +- .../scala/org/apache/spark/storage/BlockManagerMaster.scala | 3 +-- .../apache/spark/storage/BlockManagerMasterEndpoint.scala| 8 .../scala/org/apache/spark/storage/DiskBlockManager.scala| 8 core/src/main/scala/org/apache/spark/storage/RDDInfo.scala | 6 ++ .../apache/spark/storage/ShuffleBlockFetcherIterator.scala | 8 .../scala/org/apache/spark/storage/memory/MemoryStore.scala | 2 +- .../spark/storage/ShuffleBlockFetcherIteratorSuite.scala | 2 -- 9 files changed, 22 insertions(+), 29 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark-website] branch asf-site updated: Upgrade dev. tools to Ubuntu 22.04
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 551848fe0 Upgrade dev. tools to Ubuntu 22.04 551848fe0 is described below commit 551848fe08b20722123836e1878e5c350899fc38 Author: bjornjorgensen AuthorDate: Fri Feb 10 16:57:23 2023 -0800 Upgrade dev. tools to Ubuntu 22.04 Github actions are running on Ubuntu 22.04. Author: bjornjorgensen Closes #434 from bjornjorgensen/ubuntu-22.04. --- developer-tools.md| 2 +- site/developer-tools.html | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) diff --git a/developer-tools.md b/developer-tools.md index 8db0fb8c7..c8b8892b8 100644 --- a/developer-tools.md +++ b/developer-tools.md @@ -13,7 +13,7 @@ Apache Spark community uses various resources to maintain the community test cov GitHub Action -[GitHub Action](https://github.com/apache/spark/actions) provides the following on Ubuntu 20.04. +[GitHub Action](https://github.com/apache/spark/actions) provides the following on Ubuntu 22.04. - Scala 2.12/2.13 SBT build with Java 8 - Scala 2.12 Maven build with Java 11/17 - Java/Scala/Python/R unit tests with Java 8/Scala 2.12/SBT diff --git a/site/developer-tools.html b/site/developer-tools.html index 37ae2c246..1467affb4 100644 --- a/site/developer-tools.html +++ b/site/developer-tools.html @@ -128,7 +128,7 @@ GitHub Action -https://github.com/apache/spark/actions;>GitHub Action provides the following on Ubuntu 20.04. +https://github.com/apache/spark/actions;>GitHub Action provides the following on Ubuntu 22.04. Scala 2.12/2.13 SBT build with Java 8 Scala 2.12 Maven build with Java 11/17 - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42355][BUILD] Upgrade some maven-plugins
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/spark.git The following commit(s) were added to refs/heads/master by this push: new 89b16f23f8b [SPARK-42355][BUILD] Upgrade some maven-plugins 89b16f23f8b is described below commit 89b16f23f8b3fa92d1a4cab504b088cab6f41577 Author: yangjie01 AuthorDate: Wed Feb 8 18:46:26 2023 -0800 [SPARK-42355][BUILD] Upgrade some maven-plugins ### What changes were proposed in this pull request? This pr aims upgrade maven plugins including: - maven-checkstyle-plugin: from 3.2.0 to 3.2.1 - maven-clean-plugin: from 3.1.0 to 3.2.0 - maven-dependency-plugin: from 3.3.0 to 3.5.0 - maven-source-plugin: from 3.1.0 to 3.2.1 - maven-surefire-plugin: from 3.0.0-M7 to 3.0.0-M8 - maven-jar-plugin: from 3.2.2 to 3.3.0 ### Why are the changes needed? - maven-checkstyle-plugin https://github.com/apache/maven-checkstyle-plugin/compare/maven-checkstyle-plugin-3.2.0...maven-checkstyle-plugin-3.2.1 - maven-clean-plugin 3.2.0 include a new feature: https://github.com/apache/maven-clean-plugin/pull/6 https://github.com/apache/maven-clean-plugin/releases/tag/maven-clean-plugin-3.2.0 - maven-dependency-plugin https://github.com/apache/maven-dependency-plugin/compare/maven-dependency-plugin-3.3.0...maven-dependency-plugin-3.5.0 - maven-source-plugin https://github.com/apache/maven-source-plugin/compare/maven-source-plugin-3.1.0...maven-source-plugin-3.2.1 - maven-surefire-plugin https://github.com/apache/maven-surefire/compare/surefire-3.0.0-M7...surefire-3.0.0-M8 - maven-jar-plugin https://github.com/apache/maven-jar-plugin/releases/tag/maven-jar-plugin-3.3.0 ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? - Pass GitHub Actions - Manually check these plugins work normally Closes #39899 from LuciferYang/SPARK-42355. Authored-by: yangjie01 Signed-off-by: Sean Owen --- pom.xml | 12 ++-- 1 file changed, 6 insertions(+), 6 deletions(-) diff --git a/pom.xml b/pom.xml index 2cd24d441e5..08c6958b4e9 100644 --- a/pom.xml +++ b/pom.xml @@ -2934,7 +2934,7 @@ org.apache.maven.plugins maven-surefire-plugin - 3.0.0-M7 + 3.0.0-M8 @@ -3041,7 +3041,7 @@ org.apache.maven.plugins maven-jar-plugin - 3.2.2 + 3.3.0 org.apache.maven.plugins @@ -3051,7 +3051,7 @@ org.apache.maven.plugins maven-source-plugin - 3.1.0 + 3.2.1 true @@ -3068,7 +3068,7 @@ org.apache.maven.plugins maven-clean-plugin - 3.1.0 + 3.2.0 @@ -3178,7 +3178,7 @@ org.apache.maven.plugins maven-dependency-plugin - 3.3.0 + 3.5.0 default-cli @@ -3318,7 +3318,7 @@ org.apache.maven.plugins maven-checkstyle-plugin -3.2.0 +3.2.1 false true - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (bdf56c48357 -> 72f8a0ca3e7)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from bdf56c48357 [SPARK-40770][PYTHON] Improved error messages for applyInPandas for schema mismatch add 72f8a0ca3e7 [SPARK-42350][SQL][K8S][SS] Replcace `get().getOrElse` with `getOrElse` No new revisions were added by this update. Summary of changes: .../apache/spark/sql/kafka010/KafkaOffsetReaderConsumer.scala | 5 ++--- .../org/apache/spark/deploy/k8s/KubernetesVolumeUtils.scala| 2 +- .../org/apache/spark/sql/catalyst/expressions/Expression.scala | 2 +- .../spark/sql/execution/datasources/orc/OrcFileFormat.scala| 10 -- .../sql/execution/datasources/parquet/ParquetFileFormat.scala | 10 -- .../streaming/AsyncProgressTrackingMicroBatchExecution.scala | 6 ++ 6 files changed, 14 insertions(+), 21 deletions(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42335][SQL] Pass the comment option through to univocity if users set it explicitly in CSV dataSource
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 67b6f0ef85d [SPARK-42335][SQL] Pass the comment option through to
univocity if users set it explicitly in CSV dataSource
67b6f0ef85d is described below
commit 67b6f0ef85d75d33bd460ab76d5137d254684bb7
Author: wayneguow
AuthorDate: Wed Feb 8 13:12:47 2023 -0800
[SPARK-42335][SQL] Pass the comment option through to univocity if users
set it explicitly in CSV dataSource
### What changes were proposed in this pull request?
Pass the comment option through to univocity if users set it explicitly in
CSV dataSource.
### Why are the changes needed?
In #29516 , in order to fix some bugs, univocity-parsers was upgrade from
2.8.3 to 2.9.0, it also involved a new feature of univocity-parsers that
quoting values of the first column that start with the comment character. It
made a breaking for users downstream that handing a whole row as input.
Before this change:
#abc,1
After this change:
"#abc",1
We change the related `isCommentSet` check logic to enable users to keep
behavior as before.
### Does this PR introduce _any_ user-facing change?
Yes, a little. If users set comment option as '\u' explicitly, now they
should remove it to keep comment option unset.
### How was this patch tested?
Add a full new test.
Closes #39878 from wayneguow/comment.
Authored-by: wayneguow
Signed-off-by: Sean Owen
---
.../apache/spark/sql/catalyst/csv/CSVOptions.scala | 5 ++-
.../sql/execution/datasources/csv/CSVSuite.scala | 47 ++
2 files changed, 51 insertions(+), 1 deletion(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala
index a66070aa853..81fcffec586 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/CSVOptions.scala
@@ -222,7 +222,10 @@ class CSVOptions(
*/
val maxErrorContentLength = 1000
- val isCommentSet = this.comment != '\u'
+ val isCommentSet = parameters.get(COMMENT) match {
+case Some(value) if value.length == 1 => true
+case _ => false
+ }
val samplingRatio =
parameters.get(SAMPLING_RATIO).map(_.toDouble).getOrElse(1.0)
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
index 3fe91b12e15..44f1b2faceb 100644
---
a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
+++
b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
@@ -3101,6 +3101,53 @@ abstract class CSVSuite
}
}
+ test("SPARK-42335: Pass the comment option through to univocity " +
+"if users set it explicitly in CSV dataSource") {
+withTempPath { path =>
+ Seq("#abc", "\udef", "xyz").toDF()
+.write.option("comment", "\u").csv(path.getCanonicalPath)
+ checkAnswer(
+spark.read.text(path.getCanonicalPath),
+Seq(Row("#abc"), Row("\"def\""), Row("xyz"))
+ )
+}
+withTempPath { path =>
+ Seq("#abc", "\udef", "xyz").toDF()
+.write.option("comment", "#").csv(path.getCanonicalPath)
+ checkAnswer(
+spark.read.text(path.getCanonicalPath),
+Seq(Row("\"#abc\""), Row("def"), Row("xyz"))
+ )
+}
+withTempPath { path =>
+ Seq("#abc", "\udef", "xyz").toDF()
+.write.csv(path.getCanonicalPath)
+ checkAnswer(
+spark.read.text(path.getCanonicalPath),
+Seq(Row("\"#abc\""), Row("def"), Row("xyz"))
+ )
+}
+withTempPath { path =>
+ Seq("#abc", "\udef", "xyz").toDF().write.text(path.getCanonicalPath)
+ checkAnswer(
+spark.read.option("comment", "\u").csv(path.getCanonicalPath),
+Seq(Row("#abc"), Row("xyz")))
+}
+withTempPath { path =>
+ Seq("#abc", "\udef", "xyz").toDF().write.text(path.getCanonicalPath)
+ checkAnswer(
+spark.read.option("comment", "#").csv(path.getCanonicalPath),
+Seq(Row("\udef"
[spark] branch master updated: [SPARK-42336][CORE] Use `getOrElse()` instead of `contains()` in ResourceAllocator
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new fdcf85ee263 [SPARK-42336][CORE] Use `getOrElse()` instead of
`contains()` in ResourceAllocator
fdcf85ee263 is described below
commit fdcf85ee263f406597aa99a2f9a187bb9cd1ef76
Author: smallzhongfeng
AuthorDate: Sun Feb 5 20:54:56 2023 -0600
[SPARK-42336][CORE] Use `getOrElse()` instead of `contains()` in
ResourceAllocator
### What changes were proposed in this pull request?
Use `.getOrElse(address, throw new SparkException(...))` instead of one
`contains` in `addressAvailabilityMap`‘s `require` and `release`.
### Why are the changes needed?
Improving performance.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Origin uts.
Closes #39879 from smallzhongfeng/SPARK-42336.
Authored-by: smallzhongfeng
Signed-off-by: Sean Owen
---
.../org/apache/spark/resource/ResourceAllocator.scala | 14 --
1 file changed, 4 insertions(+), 10 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/resource/ResourceAllocator.scala
b/core/src/main/scala/org/apache/spark/resource/ResourceAllocator.scala
index 10cf0402d5f..7b97d970428 100644
--- a/core/src/main/scala/org/apache/spark/resource/ResourceAllocator.scala
+++ b/core/src/main/scala/org/apache/spark/resource/ResourceAllocator.scala
@@ -38,8 +38,6 @@ private[spark] trait ResourceAllocator {
* For task resources ([[org.apache.spark.scheduler.ExecutorResourceInfo]]),
this value
* can be a multiple, such that each address can be allocated up to
[[slotsPerAddress]]
* times.
- *
- * TODO Use [[org.apache.spark.util.collection.OpenHashMap]] instead to gain
better performance.
*/
private lazy val addressAvailabilityMap = {
mutable.HashMap(resourceAddresses.map(_ -> slotsPerAddress): _*)
@@ -76,11 +74,9 @@ private[spark] trait ResourceAllocator {
*/
def acquire(addrs: Seq[String]): Unit = {
addrs.foreach { address =>
- if (!addressAvailabilityMap.contains(address)) {
+ val isAvailable = addressAvailabilityMap.getOrElse(address,
throw new SparkException(s"Try to acquire an address that doesn't
exist. $resourceName " +
- s"address $address doesn't exist.")
- }
- val isAvailable = addressAvailabilityMap(address)
+s"address $address doesn't exist."))
if (isAvailable > 0) {
addressAvailabilityMap(address) -= 1
} else {
@@ -97,11 +93,9 @@ private[spark] trait ResourceAllocator {
*/
def release(addrs: Seq[String]): Unit = {
addrs.foreach { address =>
- if (!addressAvailabilityMap.contains(address)) {
+ val isAvailable = addressAvailabilityMap.getOrElse(address,
throw new SparkException(s"Try to release an address that doesn't
exist. $resourceName " +
- s"address $address doesn't exist.")
- }
- val isAvailable = addressAvailabilityMap(address)
+ s"address $address doesn't exist."))
if (isAvailable < slotsPerAddress) {
addressAvailabilityMap(address) += 1
} else {
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch branch-3.2 updated: [SPARK-41554] fix changing of Decimal scale when scale decreased by m…
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new d304a652823 [SPARK-41554] fix changing of Decimal scale when scale
decreased by m…
d304a652823 is described below
commit d304a6528233798dc93d31da58be220cf6d0485e
Author: oleksii.diagiliev
AuthorDate: Fri Feb 3 10:49:42 2023 -0600
[SPARK-41554] fix changing of Decimal scale when scale decreased by m…
…ore than 18
This is a backport PR for https://github.com/apache/spark/pull/39099
Closes #39381 from fe2s/branch-3.2-fix-decimal-scaling.
Authored-by: oleksii.diagiliev
Signed-off-by: Sean Owen
---
.../scala/org/apache/spark/sql/types/Decimal.scala | 60 +-
.../org/apache/spark/sql/types/DecimalSuite.scala | 53 ++-
2 files changed, 88 insertions(+), 25 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/types/Decimal.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/types/Decimal.scala
index bc5fba8d0d8..503a887d690 100644
--- a/sql/catalyst/src/main/scala/org/apache/spark/sql/types/Decimal.scala
+++ b/sql/catalyst/src/main/scala/org/apache/spark/sql/types/Decimal.scala
@@ -388,30 +388,42 @@ final class Decimal extends Ordered[Decimal] with
Serializable {
if (scale < _scale) {
// Easier case: we just need to divide our scale down
val diff = _scale - scale
-val pow10diff = POW_10(diff)
-// % and / always round to 0
-val droppedDigits = longVal % pow10diff
-longVal /= pow10diff
-roundMode match {
- case ROUND_FLOOR =>
-if (droppedDigits < 0) {
- longVal += -1L
-}
- case ROUND_CEILING =>
-if (droppedDigits > 0) {
- longVal += 1L
-}
- case ROUND_HALF_UP =>
-if (math.abs(droppedDigits) * 2 >= pow10diff) {
- longVal += (if (droppedDigits < 0) -1L else 1L)
-}
- case ROUND_HALF_EVEN =>
-val doubled = math.abs(droppedDigits) * 2
-if (doubled > pow10diff || doubled == pow10diff && longVal % 2 !=
0) {
- longVal += (if (droppedDigits < 0) -1L else 1L)
-}
- case _ =>
-throw QueryExecutionErrors.unsupportedRoundingMode(roundMode)
+// If diff is greater than max number of digits we store in Long, then
+// value becomes 0. Otherwise we calculate new value dividing by power
of 10.
+// In both cases we apply rounding after that.
+if (diff > MAX_LONG_DIGITS) {
+ longVal = roundMode match {
+case ROUND_FLOOR => if (longVal < 0) -1L else 0L
+case ROUND_CEILING => if (longVal > 0) 1L else 0L
+case ROUND_HALF_UP | ROUND_HALF_EVEN => 0L
+case _ => sys.error(s"Not supported rounding mode: $roundMode")
+ }
+} else {
+ val pow10diff = POW_10(diff)
+ // % and / always round to 0
+ val droppedDigits = longVal % pow10diff
+ longVal /= pow10diff
+ roundMode match {
+case ROUND_FLOOR =>
+ if (droppedDigits < 0) {
+longVal += -1L
+ }
+case ROUND_CEILING =>
+ if (droppedDigits > 0) {
+longVal += 1L
+ }
+case ROUND_HALF_UP =>
+ if (math.abs(droppedDigits) * 2 >= pow10diff) {
+longVal += (if (droppedDigits < 0) -1L else 1L)
+ }
+case ROUND_HALF_EVEN =>
+ val doubled = math.abs(droppedDigits) * 2
+ if (doubled > pow10diff || doubled == pow10diff && longVal % 2
!= 0) {
+longVal += (if (droppedDigits < 0) -1L else 1L)
+ }
+case _ =>
+ throw QueryExecutionErrors.unsupportedRoundingMode(roundMode)
+ }
}
} else if (scale > _scale) {
// We might be able to multiply longVal by a power of 10 and not
overflow, but if not,
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/types/DecimalSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/types/DecimalSuite.scala
index 5433c561a03..1f4862fcbdc 100644
--- a/sql/catalyst/src/test/scala/org/apache/spark/sql/types/DecimalSuite.scala
+++ b/sql/catalyst/src/test/scala/org/apache/spark/sql/types/DecimalSuite.scala
@@ -27,6 +27,9 @@ import org.apache.spark.sql.types.Decimal._
import org.apache.spark.unsafe.types.UTF8String
class DecimalSuite extends SparkFunSuite with PrivateMethodTester with
SQLHelper {
+
+ val allSupportedRoundModes = Seq(ROUND_HALF_UP, ROUND_HALF_EVEN,
ROUND_CEIL
[spark] branch branch-3.3 updated: [SPARK-41554] fix changing of Decimal scale when scale decreased by m…
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch branch-3.3
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.3 by this push:
new 2d539c5c702 [SPARK-41554] fix changing of Decimal scale when scale
decreased by m…
2d539c5c702 is described below
commit 2d539c5c7022d44d8a2d53e752287c42c2601444
Author: oleksii.diagiliev
AuthorDate: Fri Feb 3 10:48:56 2023 -0600
[SPARK-41554] fix changing of Decimal scale when scale decreased by m…
…ore than 18
This is a backport PR for https://github.com/apache/spark/pull/39099
Closes #39813 from fe2s/branch-3.3-fix-decimal-scaling.
Authored-by: oleksii.diagiliev
Signed-off-by: Sean Owen
---
.../scala/org/apache/spark/sql/types/Decimal.scala | 60 +-
.../org/apache/spark/sql/types/DecimalSuite.scala | 53 ++-
2 files changed, 88 insertions(+), 25 deletions(-)
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/types/Decimal.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/types/Decimal.scala
index 7a43d01eb2f..07a2c47cff0 100644
--- a/sql/catalyst/src/main/scala/org/apache/spark/sql/types/Decimal.scala
+++ b/sql/catalyst/src/main/scala/org/apache/spark/sql/types/Decimal.scala
@@ -397,30 +397,42 @@ final class Decimal extends Ordered[Decimal] with
Serializable {
if (scale < _scale) {
// Easier case: we just need to divide our scale down
val diff = _scale - scale
-val pow10diff = POW_10(diff)
-// % and / always round to 0
-val droppedDigits = longVal % pow10diff
-longVal /= pow10diff
-roundMode match {
- case ROUND_FLOOR =>
-if (droppedDigits < 0) {
- longVal += -1L
-}
- case ROUND_CEILING =>
-if (droppedDigits > 0) {
- longVal += 1L
-}
- case ROUND_HALF_UP =>
-if (math.abs(droppedDigits) * 2 >= pow10diff) {
- longVal += (if (droppedDigits < 0) -1L else 1L)
-}
- case ROUND_HALF_EVEN =>
-val doubled = math.abs(droppedDigits) * 2
-if (doubled > pow10diff || doubled == pow10diff && longVal % 2 !=
0) {
- longVal += (if (droppedDigits < 0) -1L else 1L)
-}
- case _ =>
-throw QueryExecutionErrors.unsupportedRoundingMode(roundMode)
+// If diff is greater than max number of digits we store in Long, then
+// value becomes 0. Otherwise we calculate new value dividing by power
of 10.
+// In both cases we apply rounding after that.
+if (diff > MAX_LONG_DIGITS) {
+ longVal = roundMode match {
+case ROUND_FLOOR => if (longVal < 0) -1L else 0L
+case ROUND_CEILING => if (longVal > 0) 1L else 0L
+case ROUND_HALF_UP | ROUND_HALF_EVEN => 0L
+case _ => sys.error(s"Not supported rounding mode: $roundMode")
+ }
+} else {
+ val pow10diff = POW_10(diff)
+ // % and / always round to 0
+ val droppedDigits = longVal % pow10diff
+ longVal /= pow10diff
+ roundMode match {
+case ROUND_FLOOR =>
+ if (droppedDigits < 0) {
+longVal += -1L
+ }
+case ROUND_CEILING =>
+ if (droppedDigits > 0) {
+longVal += 1L
+ }
+case ROUND_HALF_UP =>
+ if (math.abs(droppedDigits) * 2 >= pow10diff) {
+longVal += (if (droppedDigits < 0) -1L else 1L)
+ }
+case ROUND_HALF_EVEN =>
+ val doubled = math.abs(droppedDigits) * 2
+ if (doubled > pow10diff || doubled == pow10diff && longVal % 2
!= 0) {
+longVal += (if (droppedDigits < 0) -1L else 1L)
+ }
+case _ =>
+ throw QueryExecutionErrors.unsupportedRoundingMode(roundMode)
+ }
}
} else if (scale > _scale) {
// We might be able to multiply longVal by a power of 10 and not
overflow, but if not,
diff --git
a/sql/catalyst/src/test/scala/org/apache/spark/sql/types/DecimalSuite.scala
b/sql/catalyst/src/test/scala/org/apache/spark/sql/types/DecimalSuite.scala
index 6f70dc51b95..6ccd2b9bd32 100644
--- a/sql/catalyst/src/test/scala/org/apache/spark/sql/types/DecimalSuite.scala
+++ b/sql/catalyst/src/test/scala/org/apache/spark/sql/types/DecimalSuite.scala
@@ -27,6 +27,9 @@ import org.apache.spark.sql.types.Decimal._
import org.apache.spark.unsafe.types.UTF8String
class DecimalSuite extends SparkFunSuite with PrivateMethodTester with
SQLHelper {
+
+ val allSupportedRoundModes = Seq(ROUND_HALF_UP, ROUND_HALF_EVEN,
ROUND_CEIL
[spark] branch master updated: [SPARK-42257][CORE] Remove unused variable external sorter
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new c6cb21da05c [SPARK-42257][CORE] Remove unused variable external sorter
c6cb21da05c is described below
commit c6cb21da05c67de0f8d664f8456f41d0d3f9c72d
Author: khalidmammadov
AuthorDate: Tue Jan 31 15:55:24 2023 -0600
[SPARK-42257][CORE] Remove unused variable external sorter
### What changes were proposed in this pull request?
Remove unused variable
### Why are the changes needed?
To simplify and clean up
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing unit tests
Closes #39823 from
khalidmammadov/feature/remove_unused_variable_external_sorter.
Lead-authored-by: khalidmammadov
Co-authored-by: Khalid Mammadov
Signed-off-by: Sean Owen
---
.../main/scala/org/apache/spark/util/collection/ExternalSorter.scala | 3 ---
1 file changed, 3 deletions(-)
diff --git
a/core/src/main/scala/org/apache/spark/util/collection/ExternalSorter.scala
b/core/src/main/scala/org/apache/spark/util/collection/ExternalSorter.scala
index 4ca838b7655..7153bb72476 100644
--- a/core/src/main/scala/org/apache/spark/util/collection/ExternalSorter.scala
+++ b/core/src/main/scala/org/apache/spark/util/collection/ExternalSorter.scala
@@ -697,7 +697,6 @@ private[spark] class ExternalSorter[K, V, C](
shuffleId: Int,
mapId: Long,
mapOutputWriter: ShuffleMapOutputWriter): Unit = {
-var nextPartitionId = 0
if (spills.isEmpty) {
// Case where we only have in-memory data
val collection = if (aggregator.isDefined) map else buffer
@@ -724,7 +723,6 @@ private[spark] class ExternalSorter[K, V, C](
partitionPairsWriter.close()
}
}
-nextPartitionId = partitionId + 1
}
} else {
// We must perform merge-sort; get an iterator by partition and write
everything directly.
@@ -751,7 +749,6 @@ private[spark] class ExternalSorter[K, V, C](
partitionPairsWriter.close()
}
}
-nextPartitionId = id + 1
}
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [SPARK-42245][BUILD] Upgrade scalafmt from 3.6.1 to 3.7.1
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 93d169db319 [SPARK-42245][BUILD] Upgrade scalafmt from 3.6.1 to 3.7.1
93d169db319 is described below
commit 93d169db31991c354cb46c3bacc0de4f0517d819
Author: panbingkun
AuthorDate: Tue Jan 31 09:32:11 2023 -0600
[SPARK-42245][BUILD] Upgrade scalafmt from 3.6.1 to 3.7.1
### What changes were proposed in this pull request?
The pr aims to upgrade scalafmt from 3.6.1 to 3.7.1
### Why are the changes needed?
A. Release note:
> https://github.com/scalameta/scalafmt/releases
B. V3.6.1 VS V3.7.1
> https://github.com/scalameta/scalafmt/compare/v3.6.1...v3.7.1
C. Bring bug fix & some improvement:
https://user-images.githubusercontent.com/15246973/215639186-47ad2abc-5827-4b0b-a401-10737bd05743.png;>
https://user-images.githubusercontent.com/15246973/215639316-0df69d85-cb6b-40f8-acbf-d792193d1ba1.png;>
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually run: sh ./dev/scalafmt
Pass GA.
Closes #39816 from panbingkun/upgrade_scalafmt_3_7_1.
Authored-by: panbingkun
Signed-off-by: Sean Owen
---
dev/.scalafmt.conf | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/dev/.scalafmt.conf b/dev/.scalafmt.conf
index e06ea5bbfd2..786259ea4db 100644
--- a/dev/.scalafmt.conf
+++ b/dev/.scalafmt.conf
@@ -32,4 +32,4 @@ fileOverride {
runner.dialect = scala213
}
}
-version = 3.6.1
+version = 3.7.1
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [MINOR] Fix typo `Exlude` to `Exclude` in `HealthTracker`
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 720fe2f7e60 [MINOR] Fix typo `Exlude` to `Exclude` in `HealthTracker`
720fe2f7e60 is described below
commit 720fe2f7e6054ba25bd06fcc154127c74d057c5d
Author: sychen
AuthorDate: Tue Jan 31 08:13:44 2023 -0600
[MINOR] Fix typo `Exlude` to `Exclude` in `HealthTracker`
### What changes were proposed in this pull request?
Fix typo
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
exist UT
Closes #39798 from cxzl25/typo_HealthTracker.
Authored-by: sychen
Signed-off-by: Sean Owen
---
.../scala/org/apache/spark/scheduler/HealthTracker.scala | 12 ++--
.../org/apache/spark/scheduler/HealthTrackerSuite.scala | 6 +++---
.../spark/deploy/yarn/YarnAllocatorNodeHealthTracker.scala | 2 +-
3 files changed, 10 insertions(+), 10 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/scheduler/HealthTracker.scala
b/core/src/main/scala/org/apache/spark/scheduler/HealthTracker.scala
index 6bd5668651a..d7ddeade2fd 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/HealthTracker.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/HealthTracker.scala
@@ -62,7 +62,7 @@ private[scheduler] class HealthTracker (
HealthTracker.validateExcludeOnFailureConfs(conf)
private val MAX_FAILURES_PER_EXEC = conf.get(config.MAX_FAILURES_PER_EXEC)
private val MAX_FAILED_EXEC_PER_NODE =
conf.get(config.MAX_FAILED_EXEC_PER_NODE)
- val EXCLUDE_ON_FAILURE_TIMEOUT_MILLIS =
HealthTracker.getExludeOnFailureTimeout(conf)
+ val EXCLUDE_ON_FAILURE_TIMEOUT_MILLIS =
HealthTracker.getExcludeOnFailureTimeout(conf)
private val EXCLUDE_FETCH_FAILURE_ENABLED =
conf.get(config.EXCLUDE_ON_FAILURE_FETCH_FAILURE_ENABLED)
private val EXCLUDE_ON_FAILURE_DECOMMISSION_ENABLED =
@@ -93,7 +93,7 @@ private[scheduler] class HealthTracker (
* remove from this when executors are removed from spark, so we can track
when we get multiple
* successive excluded executors on one node. Nonetheless, it will not grow
too large because
* there cannot be many excluded executors on one node, before we stop
requesting more
- * executors on that node, and we clean up the list of exluded executors
once an executor has
+ * executors on that node, and we clean up the list of excluded executors
once an executor has
* been excluded for EXCLUDE_ON_FAILURE_TIMEOUT_MILLIS.
*/
val nodeToExcludedExecs = new HashMap[String, HashSet[String]]()
@@ -110,7 +110,7 @@ private[scheduler] class HealthTracker (
// Apply the timeout to excluded nodes and executors
val execsToInclude = executorIdToExcludedStatus.filter(_._2.expiryTime <
now).keys
if (execsToInclude.nonEmpty) {
-// Include any executors that have been exluded longer than the
excludeOnFailure timeout.
+// Include any executors that have been excluded longer than the
excludeOnFailure timeout.
logInfo(s"Removing executors $execsToInclude from exclude list because
the " +
s"the executors have reached the timed out")
execsToInclude.foreach { exec =>
@@ -382,7 +382,7 @@ private[scheduler] class HealthTracker (
/**
* Apply the timeout to individual tasks. This is to prevent one-off
failures that are very
* spread out in time (and likely have nothing to do with problems on the
executor) from
- * triggering exlusion. However, note that we do *not* remove executors
and nodes from
+ * triggering exclusion. However, note that we do *not* remove executors
and nodes from
* being excluded as we expire individual task failures -- each have their
own timeout. E.g.,
* suppose:
* * timeout = 10, maxFailuresPerExec = 2
@@ -447,7 +447,7 @@ private[spark] object HealthTracker extends Logging {
}
}
- def getExludeOnFailureTimeout(conf: SparkConf): Long = {
+ def getExcludeOnFailureTimeout(conf: SparkConf): Long = {
conf.get(config.EXCLUDE_ON_FAILURE_TIMEOUT_CONF).getOrElse {
conf.get(config.EXCLUDE_ON_FAILURE_LEGACY_TIMEOUT_CONF).getOrElse {
Utils.timeStringAsMs(DEFAULT_TIMEOUT)
@@ -484,7 +484,7 @@ private[spark] object HealthTracker extends Logging {
}
}
-val timeout = getExludeOnFailureTimeout(conf)
+val timeout = getExcludeOnFailureTimeout(conf)
if (timeout <= 0) {
// first, figure out where the timeout came from, to include the right
conf in the message.
conf.get(config.EXCLUDE_ON_FAILURE_TIMEOUT_CONF) match {
diff --git
a/core/src/test/scala/org/apache/spark/scheduler/HealthTrackerSuite.scala
b/core/src/test/scala/org/apache/spark/scheduler/H
[spark-website] branch asf-site updated: Change Gabor Somogyi company
This is an automated email from the ASF dual-hosted git repository. srowen pushed a commit to branch asf-site in repository https://gitbox.apache.org/repos/asf/spark-website.git The following commit(s) were added to refs/heads/asf-site by this push: new 2f766afbc Change Gabor Somogyi company 2f766afbc is described below commit 2f766afbcb77e495f0e5e7e6a81458075e6ade96 Author: Gabor Somogyi AuthorDate: Mon Jan 23 07:12:20 2023 -0600 Change Gabor Somogyi company Author: Gabor Somogyi Closes #432 from gaborgsomogyi/company. --- committers.md| 2 +- site/committers.html | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) diff --git a/committers.md b/committers.md index a16b33d31..827073a0d 100644 --- a/committers.md +++ b/committers.md @@ -74,7 +74,7 @@ navigation: |Kousuke Saruta|NTT Data| |Saisai Shao|Tencent| |Prashant Sharma|IBM| -|Gabor Somogyi|Cloudera| +|Gabor Somogyi|Apple| |Ram Sriharsha|Databricks| |Chao Sun|Apple| |Maciej Szymkiewicz|| diff --git a/site/committers.html b/site/committers.html index 5ac86d8db..c0543233b 100644 --- a/site/committers.html +++ b/site/committers.html @@ -390,7 +390,7 @@ Gabor Somogyi - Cloudera + Apple Ram Sriharsha - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated: [MINOR][SHUFFLE] Include IOException in warning log of finalizeShuffleMerge
This is an automated email from the ASF dual-hosted git repository.
srowen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 074894ce70e [MINOR][SHUFFLE] Include IOException in warning log of
finalizeShuffleMerge
074894ce70e is described below
commit 074894ce70e90717cbc81f7e6abc53d10872cda3
Author: Ted Yu
AuthorDate: Sat Jan 21 15:56:40 2023 -0600
[MINOR][SHUFFLE] Include IOException in warning log of finalizeShuffleMerge
### What changes were proposed in this pull request?
This PR adds `ioe` to the warning log of `finalizeShuffleMerge`.
### Why are the changes needed?
With `ioe` logged, user would have more clue as to the root cause.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing test suite.
Closes #39654 from tedyu/shuffle-ioe.
Authored-by: Ted Yu
Signed-off-by: Sean Owen
---
.../org/apache/spark/network/shuffle/RemoteBlockPushResolver.java| 5 +++--
1 file changed, 3 insertions(+), 2 deletions(-)
diff --git
a/common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/RemoteBlockPushResolver.java
b/common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/RemoteBlockPushResolver.java
index fb3f8109a1a..a2e8219228a 100644
---
a/common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/RemoteBlockPushResolver.java
+++
b/common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/RemoteBlockPushResolver.java
@@ -814,8 +814,9 @@ public class RemoteBlockPushResolver implements
MergedShuffleFileManager {
}
} catch (IOException ioe) {
logger.warn("{} attempt {} shuffle {} shuffleMerge {}: exception
while " +
-"finalizing shuffle partition {}", msg.appId,
msg.appAttemptId, msg.shuffleId,
-msg.shuffleMergeId, partition.reduceId);
+"finalizing shuffle partition {}. Exception message: {}",
msg.appId,
+msg.appAttemptId, msg.shuffleId, msg.shuffleMergeId,
partition.reduceId,
+ioe.getMessage());
} finally {
partition.closeAllFilesAndDeleteIfNeeded(false);
}
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org
[spark] branch master updated (68af2fd106e -> e969bb2b7bc)
This is an automated email from the ASF dual-hosted git repository. srowen pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/spark.git from 68af2fd106e [SPARK-42082][SPARK-41598][PYTHON][CONNECT] Introduce `PySparkValueError` and `PySparkTypeError` add e969bb2b7bc [SPARK-41683][CORE] Fix issue of getting incorrect property numActiveStages in jobs API No new revisions were added by this update. Summary of changes: .../org/apache/spark/status/AppStatusListener.scala | 1 - .../apache/spark/status/AppStatusListenerSuite.scala | 19 +++ 2 files changed, 19 insertions(+), 1 deletion(-) - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org