[GitHub] spark issue #22721: [SPARK-25403][SQL] Refreshes the table after inserting t...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22721 **[Test build #97371 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97371/testReport)** for PR 22721 at commit [`8a7f4af`](https://github.com/apache/spark/commit/8a7f4af6b0e02c772f950c9a61e17eec5b988ef2). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22721: [SPARK-25403][SQL] Refreshes the table after inse...
GitHub user wangyum opened a pull request: https://github.com/apache/spark/pull/22721 [SPARK-25403][SQL] Refreshes the table after inserting the table ## What changes were proposed in this pull request? Refreshes the table after inserting the table, Otherwise, we will encounter inconsistency, such as mentioned in `SPARK-25403`. In fact, the `InsertIntoHiveTable` refreshes the table after inserting the table: https://github.com/apache/spark/blob/f8b4d5aafd1923d9524415601469f8749b3d0811/sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/InsertIntoHiveTable.scala#L107-L108 ## How was this patch tested? unit tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/wangyum/spark SPARK-25403 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22721.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22721 commit 8a7f4af6b0e02c772f950c9a61e17eec5b988ef2 Author: Yuming Wang Date: 2018-10-15T05:09:58Z Refresh table after insert into table --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][SQL] Pluggable JDBC connection factory
Github user maropu commented on the issue: https://github.com/apache/spark/pull/22560 Just a question about the design: what's the relationship between `JdbcDialect` and tihs provider? In the master, we now abstract JDBC connections by `JdbcDialect`. BTW, you can't reuse `PostgresDialect` by connecting an AWS Aurora postgres? We need to add a new interface to do so? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][SQL] Pluggable JDBC connection factory
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22560 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][SQL] Pluggable JDBC connection factory
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22560 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97370/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][SQL] Pluggable JDBC connection factory
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22560 **[Test build #97370 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97370/testReport)** for PR 22560 at commit [`f5671a3`](https://github.com/apache/spark/commit/f5671a3552322f96bf26ec78392f4383bb6d6cd3). * This patch passes all tests. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `trait ConnectionFactoryProvider extends Serializable ` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20303: [SPARK-23128][SQL] A new approach to do adaptive executi...
Github user aaron-aa commented on the issue: https://github.com/apache/spark/pull/20303 @carsonwang Thanks --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20303: [SPARK-23128][SQL] A new approach to do adaptive executi...
Github user aaron-aa commented on the issue: https://github.com/apache/spark/pull/20303 > @aaron-aa , the committers agreed to start reviewing the code after 2.4 release. Thanks a lot! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user cloud-fan commented on the issue: https://github.com/apache/spark/pull/22379 BTW how would the `schema_of_csv` function help with `from_csv`? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user cloud-fan commented on the issue: https://github.com/apache/spark/pull/22379 Looks pretty good! just one minor commet --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22379#discussion_r225033899
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/csv/CSVDataSource.scala
---
@@ -254,7 +256,7 @@ object TextInputCSVDataSource extends CSVDataSource {
val header = makeSafeHeader(firstRow, caseSensitive, parsedOptions)
val sampled: Dataset[String] = CSVUtils.sample(csv, parsedOptions)
val tokenRDD = sampled.rdd.mapPartitions { iter =>
- val filteredLines = CSVUtils.filterCommentAndEmpty(iter,
parsedOptions)
+ val filteredLines = filterCommentAndEmpty(iter, parsedOptions)
--- End diff --
+1
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22379#discussion_r225033808
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/csvExpressions.scala
---
@@ -0,0 +1,117 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.expressions
+
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.csv._
+import org.apache.spark.sql.catalyst.expressions.codegen.CodegenFallback
+import org.apache.spark.sql.catalyst.util._
+import org.apache.spark.sql.types._
+import org.apache.spark.unsafe.types.UTF8String
+
+/**
+ * Converts a CSV input string to a [[StructType]] with the specified
schema.
+ */
+// scalastyle:off line.size.limit
+@ExpressionDescription(
+ usage = "_FUNC_(csvStr, schema[, options]) - Returns a struct value with
the given `csvStr` and `schema`.",
+ examples = """
+Examples:
+ > SELECT _FUNC_('1, 0.8', 'a INT, b DOUBLE');
+ {"a":1, "b":0.8}
+ > SELECT _FUNC_('26/08/2015', 'time Timestamp',
map('timestampFormat', 'dd/MM/'))
+ {"time":2015-08-26 00:00:00.0}
+ """,
+ since = "3.0.0")
+// scalastyle:on line.size.limit
+case class CsvToStructs(
+schema: StructType,
+options: Map[String, String],
+child: Expression,
+timeZoneId: Option[String] = None)
+ extends UnaryExpression
+with TimeZoneAwareExpression
+with CodegenFallback
+with ExpectsInputTypes
+with NullIntolerant {
+
+ override def nullable: Boolean = child.nullable
+
+ // The CSV input data might be missing certain fields. We force the
nullability
+ // of the user-provided schema to avoid data corruptions.
+ val nullableSchema: StructType = schema.asNullable
+
+ // Used in `FunctionRegistry`
+ def this(child: Expression, schema: Expression, options: Map[String,
String]) =
+this(
+ schema = ExprUtils.evalSchemaExpr(schema),
+ options = options,
+ child = child,
+ timeZoneId = None)
+
+ def this(child: Expression, schema: Expression) = this(child, schema,
Map.empty[String, String])
+
+ def this(child: Expression, schema: Expression, options: Expression) =
+this(
+ schema = ExprUtils.evalSchemaExpr(schema),
+ options = ExprUtils.convertToMapData(options),
+ child = child,
+ timeZoneId = None)
+
+ // This converts parsed rows to the desired output by the given schema.
+ @transient
+ lazy val converter = (rows: Iterator[InternalRow]) => {
+if (rows.hasNext) {
+ rows.next()
--- End diff --
what if `rows` have more than one row? shall we fail or shall we return
null?
Up to my understanding it should fail. The parser should only return one
row for struct type. If it doesn't, there must be a bug.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22029: [SPARK-24395][SQL] IN operator should return NULL when c...
Github user cloud-fan commented on the issue: https://github.com/apache/spark/pull/22029 It looks to me that this is another instance of special handling `(a, b, ..)`, like https://github.com/apache/spark/pull/21403 `(a, b) in (struct_col1, struct_col2, ...)` is different from `input_struct_col in (struct_col1, struct_col2, ...)`, right? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22708: [SPARK-21402] Fix java array/map of structs deserializat...
Github user cloud-fan commented on the issue: https://github.com/apache/spark/pull/22708 Can you explain how this happens? Why thhe fields of structs get mixed up? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22561: [SPARK-25548][SQL]In the PruneFileSourcePartition...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22561#discussion_r225030929
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/PruneFileSourcePartitions.scala
---
@@ -39,21 +40,31 @@ private[sql] object PruneFileSourcePartitions extends
Rule[LogicalPlan] {
_,
_))
if filters.nonEmpty && fsRelation.partitionSchemaOption.isDefined
=>
+
+ val sparkSession = fsRelation.sparkSession
+ val partitionColumns =
+logicalRelation.resolve(
+ partitionSchema, sparkSession.sessionState.analyzer.resolver)
+ val partitionSet = AttributeSet(partitionColumns)
// The attribute name of predicate could be different than the one
in schema in case of
// case insensitive, we should change them to match the one in
schema, so we donot need to
// worry about case sensitivity anymore.
val normalizedFilters = filters.map { e =>
-e transform {
+e transformUp {
case a: AttributeReference =>
a.withName(logicalRelation.output.find(_.semanticEquals(a)).get.name)
+ // Replace the nonPartitionOps field with true in the
And(partitionOps, nonPartitionOps)
+ // to make the partition can be pruned
+ case and @And(left, right) =>
+val leftPartition =
left.references.filter(partitionSet.contains(_))
+val rightPartition =
right.references.filter(partitionSet.contains(_))
+if (leftPartition.size == left.references.size &&
rightPartition.size == 0) {
+ and.withNewChildren(Seq(left, Literal(true, BooleanType)))
+} else if (leftPartition.size == 0 && rightPartition.size ==
right.references.size) {
+ and.withNewChildren(Seq(Literal(true, BooleanType), right))
+} else and
}
}
-
- val sparkSession = fsRelation.sparkSession
- val partitionColumns =
-logicalRelation.resolve(
- partitionSchema, sparkSession.sessionState.analyzer.resolver)
- val partitionSet = AttributeSet(partitionColumns)
val partitionKeyFilters =
--- End diff --
I think a simpler change is
```
val partitionKeyFilters =
ExpressionSet(normalizedFilters.map(splitConjunctivePredicates).filter...)
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22309: [SPARK-20384][SQL] Support value class in schema ...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22309#discussion_r225030497
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/ScalaReflection.scala
---
@@ -125,6 +125,17 @@ object ScalaReflection extends ScalaReflection {
case _ => false
}
+ def isValueClass(tpe: `Type`): Boolean = {
+val notNull = !(tpe <:< localTypeOf[Null])
+notNull && definedByConstructorParams(tpe) && tpe <:<
localTypeOf[AnyVal]
--- End diff --
why a value class must be a `Product`? Is it because there is no way to get
the value class field name and type?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22309: [SPARK-20384][SQL] Support value class in schema ...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22309#discussion_r225030384
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/ScalaReflection.scala
---
@@ -376,6 +387,23 @@ object ScalaReflection extends ScalaReflection {
dataType = ObjectType(udt.getClass))
Invoke(obj, "deserialize", ObjectType(udt.userClass), getPath ::
Nil)
+ case t if isValueClass(t) =>
+// nested value class is treated as its underlying type
+// top level value class must be treated as a product
+val underlyingType = getUnderlyingTypeOf(t)
+val underlyingClsName = getClassNameFromType(underlyingType)
+val clsName = t.typeSymbol.asClass.fullName
--- End diff --
how about `getClassNameFromType(t)`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22309: [SPARK-20384][SQL] Support value class in schema ...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22309#discussion_r225030352
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/ScalaReflection.scala
---
@@ -376,6 +387,23 @@ object ScalaReflection extends ScalaReflection {
dataType = ObjectType(udt.getClass))
Invoke(obj, "deserialize", ObjectType(udt.userClass), getPath ::
Nil)
+ case t if isValueClass(t) =>
+// nested value class is treated as its underlying type
+// top level value class must be treated as a product
+val underlyingType = getUnderlyingTypeOf(t)
+val underlyingClsName = getClassNameFromType(underlyingType)
+val clsName = t.typeSymbol.asClass.fullName
+val newTypePath = s"""- Scala value class:
$clsName($underlyingClsName)""" +:
+ walkedTypePath
+
+val arg = deserializerFor(underlyingType, path, newTypePath)
+if (path.isDefined) {
+ arg
--- End diff --
why can we skip the `NewInstance`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22379: [SPARK-25393][SQL] Adding new function from_csv()
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22379#discussion_r225030219
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/functions.scala ---
@@ -3854,6 +3854,38 @@ object functions {
@scala.annotation.varargs
def map_concat(cols: Column*): Column = withExpr {
MapConcat(cols.map(_.expr)) }
+ /**
+ * Parses a column containing a CSV string into a `StructType` with the
specified schema.
+ * Returns `null`, in the case of an unparseable string.
+ *
+ * @param e a string column containing CSV data.
+ * @param schema the schema to use when parsing the CSV string
+ * @param options options to control how the CSV is parsed. accepts the
same options and the
+ *CSV data source.
+ *
+ * @group collection_funcs
+ * @since 3.0.0
+ */
+ def from_csv(e: Column, schema: StructType, options: Map[String,
String]): Column = withExpr {
+CsvToStructs(schema, options, e.expr)
+ }
+
+ /**
+ * (Java-specific) Parses a column containing a CSV string into a
`StructType`
+ * with the specified schema. Returns `null`, in the case of an
unparseable string.
+ *
+ * @param e a string column containing CSV data.
+ * @param schema the schema to use when parsing the CSV string
+ * @param options options to control how the CSV is parsed. accepts the
same options and the
+ *CSV data source.
+ *
+ * @group collection_funcs
+ * @since 3.0.0
+ */
+ def from_csv(e: Column, schema: String, options: java.util.Map[String,
String]): Column = {
--- End diff --
Let me address this one tonight.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22677: [SPARK-25683][Core] Make AsyncEventQueue.lastReportTimes...
Github user jiangxb1987 commented on the issue: https://github.com/apache/spark/pull/22677 Sounds good! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22561: [SPARK-25548][SQL]In the PruneFileSourcePartition...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22561#discussion_r225029074
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/PruneFileSourcePartitions.scala
---
@@ -39,21 +40,31 @@ private[sql] object PruneFileSourcePartitions extends
Rule[LogicalPlan] {
_,
_))
if filters.nonEmpty && fsRelation.partitionSchemaOption.isDefined
=>
+
+ val sparkSession = fsRelation.sparkSession
+ val partitionColumns =
+logicalRelation.resolve(
+ partitionSchema, sparkSession.sessionState.analyzer.resolver)
+ val partitionSet = AttributeSet(partitionColumns)
// The attribute name of predicate could be different than the one
in schema in case of
// case insensitive, we should change them to match the one in
schema, so we donot need to
// worry about case sensitivity anymore.
val normalizedFilters = filters.map { e =>
-e transform {
+e transformUp {
case a: AttributeReference =>
a.withName(logicalRelation.output.find(_.semanticEquals(a)).get.name)
+ // Replace the nonPartitionOps field with true in the
And(partitionOps, nonPartitionOps)
+ // to make the partition can be pruned
+ case and @And(left, right) =>
--- End diff --
nit: and @ And
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22561: [SPARK-25548][SQL]In the PruneFileSourcePartition...
Github user xuanyuanking commented on a diff in the pull request:
https://github.com/apache/spark/pull/22561#discussion_r225029122
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/PruneFileSourcePartitions.scala
---
@@ -39,21 +40,31 @@ private[sql] object PruneFileSourcePartitions extends
Rule[LogicalPlan] {
_,
_))
if filters.nonEmpty && fsRelation.partitionSchemaOption.isDefined
=>
+
+ val sparkSession = fsRelation.sparkSession
+ val partitionColumns =
+logicalRelation.resolve(
+ partitionSchema, sparkSession.sessionState.analyzer.resolver)
+ val partitionSet = AttributeSet(partitionColumns)
// The attribute name of predicate could be different than the one
in schema in case of
// case insensitive, we should change them to match the one in
schema, so we donot need to
// worry about case sensitivity anymore.
val normalizedFilters = filters.map { e =>
-e transform {
+e transformUp {
case a: AttributeReference =>
a.withName(logicalRelation.output.find(_.semanticEquals(a)).get.name)
+ // Replace the nonPartitionOps field with true in the
And(partitionOps, nonPartitionOps)
+ // to make the partition can be pruned
+ case and @And(left, right) =>
+val leftPartition =
left.references.filter(partitionSet.contains(_))
+val rightPartition =
right.references.filter(partitionSet.contains(_))
+if (leftPartition.size == left.references.size &&
rightPartition.size == 0) {
--- End diff --
`rightPartition.size == 0` => `rightPartition.isEmpty`
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22697: [SPARK-25700][SQL][BRANCH-2.4] Partially revert a...
Github user HyukjinKwon closed the pull request at: https://github.com/apache/spark/pull/22697 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22697: [SPARK-25700][SQL][BRANCH-2.4] Partially revert append m...
Github user cloud-fan commented on the issue: https://github.com/apache/spark/pull/22697 thanks, merging to 2.4! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22713: [SPARK-25691][SQL] Use semantic equality in Optim...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22713#discussion_r225025827
--- Diff:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/RemoveRedundantAliasAndProjectSuite.scala
---
@@ -124,4 +124,11 @@ class RemoveRedundantAliasAndProjectSuite extends
PlanTest with PredicateHelper
val expected = Subquery(relation.select('a as "a", 'b).where('b <
10).select('a).analyze)
comparePlans(optimized, expected)
}
+
+ test("SPARK-25691: RemoveRedundantProject works also with different
cases") {
+val relation = LocalRelation('a.int, 'b.int)
+val query = relation.select('A, 'b).analyzeCaseInsensitive
+val optimized = Optimize.execute(query)
+comparePlans(optimized, relation)
--- End diff --
I agree that using `==` on attributes is error-prone, but we should update
then one-by-one, to narrow down the scope and make sure the change is
reasonable.
For instance, I don't think this is a valid case. If we optimize it, the
final schema field names will change, which is a breaking change if this plan
an input of a parquet writing plan. (the result parquet files will have a
different schema)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22597: [SPARK-25579][SQL] Use quoted attribute names if ...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22597#discussion_r225025622
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilterSuite.scala
---
@@ -383,4 +385,17 @@ class OrcFilterSuite extends OrcTest with
SharedSQLContext {
)).get.toString
}
}
+
+ test("SPARK-25579 ORC PPD should support column names with dot") {
+import testImplicits._
+
+withSQLConf(SQLConf.ORC_FILTER_PUSHDOWN_ENABLED.key -> "true") {
+ withTempDir { dir =>
+val path = new File(dir, "orc").getCanonicalPath
+Seq((1, 2), (3, 4)).toDF("col.dot.1", "col.dot.2").write.orc(path)
+val df = spark.read.orc(path).where("`col.dot.1` = 1 and
`col.dot.2` = 2")
+checkAnswer(stripSparkFilter(df), Row(1, 2))
--- End diff --
Yup.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22597: [SPARK-25579][SQL] Use quoted attribute names if ...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22597#discussion_r225024900
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilterSuite.scala
---
@@ -383,4 +385,17 @@ class OrcFilterSuite extends OrcTest with
SharedSQLContext {
)).get.toString
}
}
+
+ test("SPARK-25579 ORC PPD should support column names with dot") {
+import testImplicits._
+
+withSQLConf(SQLConf.ORC_FILTER_PUSHDOWN_ENABLED.key -> "true") {
+ withTempDir { dir =>
+val path = new File(dir, "orc").getCanonicalPath
+Seq((1, 2), (3, 4)).toDF("col.dot.1", "col.dot.2").write.orc(path)
--- End diff --
How about explicitly repartition to make separate output files?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22597: [SPARK-25579][SQL] Use quoted attribute names if ...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22597#discussion_r225024728
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilterSuite.scala
---
@@ -383,4 +385,17 @@ class OrcFilterSuite extends OrcTest with
SharedSQLContext {
)).get.toString
}
}
+
+ test("SPARK-25579 ORC PPD should support column names with dot") {
+import testImplicits._
+
+withSQLConf(SQLConf.ORC_FILTER_PUSHDOWN_ENABLED.key -> "true") {
+ withTempDir { dir =>
+val path = new File(dir, "orc").getCanonicalPath
+Seq((1, 2), (3, 4)).toDF("col.dot.1", "col.dot.2").write.orc(path)
+val df = spark.read.orc(path).where("`col.dot.1` = 1 and
`col.dot.2` = 2")
+checkAnswer(stripSparkFilter(df), Row(1, 2))
--- End diff --
to confirm, this only works when `(1, 2)` and `(3, 4)` are in the same row
group? (not sure what's the terminology in ORC)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22707: [SPARK-25717][SQL] Insert overwrite a recreated external...
Github user fjh100456 commented on the issue: https://github.com/apache/spark/pull/22707 @wangyum I have added the test. Thank you. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22715: [SPARK-25727][SQL] Add outputOrdering to otherCop...
Github user cloud-fan commented on a diff in the pull request: https://github.com/apache/spark/pull/22715#discussion_r225024084 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/execution/columnar/InMemoryRelation.scala --- @@ -206,7 +206,7 @@ case class InMemoryRelation( outputOrdering).asInstanceOf[this.type] } - override protected def otherCopyArgs: Seq[AnyRef] = Seq(statsOfPlanToCache) + override protected def otherCopyArgs: Seq[AnyRef] = Seq(statsOfPlanToCache, outputOrdering) --- End diff -- The thing I don't understand is why we put the `outputOrdering` in the curry constructor at the first place... --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22646: [SPARK-25654][SQL] Support for nested JavaBean ar...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22646#discussion_r225021394
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala ---
@@ -1115,9 +1126,38 @@ object SQLContext {
})
}
}
-def createConverter(cls: Class[_], dataType: DataType): Any => Any =
dataType match {
- case struct: StructType => createStructConverter(cls,
struct.map(_.dataType))
- case _ => CatalystTypeConverters.createToCatalystConverter(dataType)
+def createConverter(t: Type, dataType: DataType): Any => Any = (t,
dataType) match {
+ case (cls: Class[_], struct: StructType) =>
--- End diff --
wait .. can we reuse `JavaTypeInference.serializerFor` and make a
projection, rather then reimplementing whole logics here?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][SQL] Pluggable JDBC connection factory
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22560 **[Test build #97370 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97370/testReport)** for PR 22560 at commit [`f5671a3`](https://github.com/apache/spark/commit/f5671a3552322f96bf26ec78392f4383bb6d6cd3). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22646: [SPARK-25654][SQL] Support for nested JavaBean ar...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22646#discussion_r225021732
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala ---
@@ -1115,9 +1126,38 @@ object SQLContext {
})
}
}
-def createConverter(cls: Class[_], dataType: DataType): Any => Any =
dataType match {
- case struct: StructType => createStructConverter(cls,
struct.map(_.dataType))
- case _ => CatalystTypeConverters.createToCatalystConverter(dataType)
+def createConverter(t: Type, dataType: DataType): Any => Any = (t,
dataType) match {
+ case (cls: Class[_], struct: StructType) =>
--- End diff --
https://github.com/apache/spark/blob/5264164a67df498b73facae207eda12ee133be7d/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/JavaTypeInference.scala#L131-L132
We should drop the support for getter or setter only. adding @cloud-fan
here as well.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][SQL] Pluggable JDBC connection factory
Github user fsauer65 commented on the issue: https://github.com/apache/spark/pull/22560 tests are failing with ``` Caused by: sbt.ForkMain$ForkError: java.io.NotSerializableException: org.apache.spark.sql.execution.datasources.jdbc.DefaultConnectionFactoryProvider$ Serialization stack: - object not serializable (class: org.apache.spark.sql.execution.datasources.jdbc.DefaultConnectionFactoryProvider$, value: org.apache.spark.sql.execution.datasources.jdbc.DefaultConnectionFactoryProvider$@7d4b4fa8) ``` Not sure what the right way is to fix this but could it be as simple as extending Serializable? I don't understand why I'm not seeing this in our environment. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22720: [K8S] Delete executor pods from kubernetes after figurin...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22720 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22720: [K8S] Delete executor pods from kubernetes after figurin...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22720 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22455: [SPARK-24572][SPARKR] "eager execution" for R shell, IDE
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22455 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22455: [SPARK-24572][SPARKR] "eager execution" for R shell, IDE
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22455 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97368/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22720: [K8S] Delete executor pods from kubernetes after figurin...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22720 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22455: [SPARK-24572][SPARKR] "eager execution" for R shell, IDE
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22455 **[Test build #97368 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97368/testReport)** for PR 22455 at commit [`44df922`](https://github.com/apache/spark/commit/44df922fb347211c9a962bf1771e2e0005634305). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22720: [K8S] Delete executor pods from kubernetes after ...
GitHub user mikekap opened a pull request: https://github.com/apache/spark/pull/22720 [K8S] Delete executor pods from kubernetes after figuring out why they died ## What changes were proposed in this pull request? `removeExecutorFromSpark` tries to fetch the reason the executor exited from Kubernetes, which may be useful if the pod was OOMKilled. However, the code previously deleted the pod from Kubernetes first which made retrieving this status impossible. This fixes the ordering. On a separate but related note, it would be nice to wait some time before removing the pod - to let the operator examine logs and such. ## How was this patch tested? Running on my local cluster. You can merge this pull request into a Git repository by running: $ git pull https://github.com/mikekap/spark patch-1 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22720.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22720 commit 71727a83aed15c76a653bf08df456b6e2372fe3f Author: Mike Kaplinskiy Date: 2018-10-15T01:14:08Z [K8S] Delete executor pods from kubernetes after figuring out why they died --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][SQL] Pluggable JDBC connection factory
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22560 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][SQL] Pluggable JDBC connection factory
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22560 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97369/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][SQL] Pluggable JDBC connection factory
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22560 **[Test build #97369 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97369/testReport)** for PR 22560 at commit [`526a1d0`](https://github.com/apache/spark/commit/526a1d0ac7922bc104864f3137aa993f9c4e7c67). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22597: [SPARK-25579][SQL] Use quoted attribute names if needed ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22597 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22597: [SPARK-25579][SQL] Use quoted attribute names if needed ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22597 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97366/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22597: [SPARK-25579][SQL] Use quoted attribute names if needed ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22597 **[Test build #97366 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97366/testReport)** for PR 22597 at commit [`849c7fa`](https://github.com/apache/spark/commit/849c7fa67007aea784e95b81c65b52f23ea24425). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22646: [SPARK-25654][SQL] Support for nested JavaBean ar...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22646#discussion_r225016843
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala ---
@@ -1115,9 +1126,38 @@ object SQLContext {
})
}
}
-def createConverter(cls: Class[_], dataType: DataType): Any => Any =
dataType match {
- case struct: StructType => createStructConverter(cls,
struct.map(_.dataType))
- case _ => CatalystTypeConverters.createToCatalystConverter(dataType)
+def createConverter(t: Type, dataType: DataType): Any => Any = (t,
dataType) match {
--- End diff --
BTW, how about we put this method in `CatalystTypeConverters`? Looks it is
a Catalyst converter for beans. Few Java types like `java.lang.Iterable`,
`java.math.BigDecimal` and `java.math.BigInteger` are being handled there.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22527: [SPARK-17952][SQL] Nested Java beans support in createDa...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22527 Looks good to me too! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22527: [SPARK-17952][SQL] Nested Java beans support in createDa...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/22527 Hey @ueshin, sorry I was late. I'm a bit busy for these couple of weeks so please don't block by me and ignore me. Thank you for asking it to me. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22597: [SPARK-25579][SQL] Use quoted attribute names if ...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22597#discussion_r225014099
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilterSuite.scala
---
@@ -383,4 +384,15 @@ class OrcFilterSuite extends OrcTest with
SharedSQLContext {
)).get.toString
}
}
+
+ test("SPARK-25579 ORC PPD should support column names with dot") {
+import testImplicits._
--- End diff --
Okay. One end to end test should be enough
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22718: [SPARK-25714] [BACKPORT-2.3] Fix Null Handling in the Op...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22718 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22718: [SPARK-25714] [BACKPORT-2.3] Fix Null Handling in the Op...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22718 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97365/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22718: [SPARK-25714] [BACKPORT-2.3] Fix Null Handling in the Op...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22718 **[Test build #97365 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97365/testReport)** for PR 22718 at commit [`8303483`](https://github.com/apache/spark/commit/8303483832ff3f28bfc907c7522254c1ab5f9808). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22719: [SPARK-25714] [BACKPORT-2.2] Fix Null Handling in the Op...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22719 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22719: [SPARK-25714] [BACKPORT-2.2] Fix Null Handling in the Op...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22719 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97364/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][SQL] Pluggable JDBC connection factory
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22560 **[Test build #97369 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97369/testReport)** for PR 22560 at commit [`526a1d0`](https://github.com/apache/spark/commit/526a1d0ac7922bc104864f3137aa993f9c4e7c67). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22719: [SPARK-25714] [BACKPORT-2.2] Fix Null Handling in the Op...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22719 **[Test build #97364 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97364/testReport)** for PR 22719 at commit [`be7a236`](https://github.com/apache/spark/commit/be7a23645a3a48f3a8afd9ea00ee118e764e8e8b). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][Spark Core] Pluggable JDBC connection fact...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22560 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97367/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][Spark Core] Pluggable JDBC connection fact...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22560 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22455: [SPARK-24572][SPARKR] "eager execution" for R shell, IDE
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22455 **[Test build #97368 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97368/testReport)** for PR 22455 at commit [`44df922`](https://github.com/apache/spark/commit/44df922fb347211c9a962bf1771e2e0005634305). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][Spark Core] Pluggable JDBC connection fact...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22560 **[Test build #97367 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97367/testReport)** for PR 22560 at commit [`bc4f671`](https://github.com/apache/spark/commit/bc4f671d084b0d679eb8890083161016e6408a4d). * This patch **fails to build**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22455: [SPARK-24572][SPARKR] "eager execution" for R shell, IDE
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22455 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3966/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22455: [SPARK-24572][SPARKR] "eager execution" for R shell, IDE
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22455 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22455: [SPARK-24572][SPARKR] "eager execution" for R shell, IDE
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22455 Retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][Spark Core] Pluggable JDBC connection fact...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22560 **[Test build #97367 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97367/testReport)** for PR 22560 at commit [`bc4f671`](https://github.com/apache/spark/commit/bc4f671d084b0d679eb8890083161016e6408a4d). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][Spark Core] Pluggable JDBC connection fact...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22560 ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22560: [SPARK-25547][Spark Core] Pluggable JDBC connection fact...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22560 Hi, @fsauer65 . - We are in the middle of Spark 2.4.0 RC voting. So, we are careful and not active for new features. Sorry for the delays. - Could you change `[Spark Core]` to `[SQL]`? That improves your PR visibility in https://spark-prs.appspot.com/open-prs . --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22597: [SPARK-25579][SQL] Use quoted attribute names if needed ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22597 **[Test build #97366 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97366/testReport)** for PR 22597 at commit [`849c7fa`](https://github.com/apache/spark/commit/849c7fa67007aea784e95b81c65b52f23ea24425). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22597: [SPARK-25579][SQL] Use quoted attribute names if needed ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22597 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3965/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22597: [SPARK-25579][SQL] Use quoted attribute names if needed ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22597 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22719: [SPARK-25714] [BACKPORT-2.2] Fix Null Handling in the Op...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22719 **[Test build #97364 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97364/testReport)** for PR 22719 at commit [`be7a236`](https://github.com/apache/spark/commit/be7a23645a3a48f3a8afd9ea00ee118e764e8e8b). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22719: [SPARK-25714] [BACKPORT-2.2] Fix Null Handling in the Op...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22719 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3963/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22718: [SPARK-25714] [BACKPORT-2.3] Fix Null Handling in the Op...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22718 **[Test build #97365 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97365/testReport)** for PR 22718 at commit [`8303483`](https://github.com/apache/spark/commit/8303483832ff3f28bfc907c7522254c1ab5f9808). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22718: [SPARK-25714] [BACKPORT-2.3] Fix Null Handling in the Op...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22718 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/3964/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22719: [SPARK-25714] [BACKPORT-2.2] Fix Null Handling in the Op...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22719 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22718: [SPARK-25714] [BACKPORT-2.3] Fix Null Handling in the Op...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22718 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22719: [SPARK-25714] [BACKPORT-2.2] Fix Null Handling in the Op...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22719 Retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22718: [SPARK-25714] [BACKPORT-2.3] Fix Null Handling in the Op...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22718 Retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22263: [SPARK-25269][SQL] SQL interface support specify ...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/22263#discussion_r225005803
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/CachedTableSuite.scala ---
@@ -288,6 +297,69 @@ class CachedTableSuite extends QueryTest with
SQLTestUtils with SharedSQLContext
}
}
+ test("SQL interface support storageLevel(DISK_ONLY)") {
+sql("CACHE TABLE testData OPTIONS('storageLevel' 'DISK_ONLY')")
+assertCached(spark.table("testData"))
+val rddId = rddIdOf("testData")
+assert(isExpectStorageLevel(rddId, Disk))
+assert(!isExpectStorageLevel(rddId, Memory))
--- End diff --
Do we need line 305 when we have line 304?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22662: [SPARK-25627][TEST] Reduce test time for ContinuousStres...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/22662 Hi, @tdas and @zsxwing . Could you review this PR which aims to reduce the test time greatly? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22597: [SPARK-25579][SQL] Use quoted attribute names if ...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/22597#discussion_r225004937
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilterSuite.scala
---
@@ -383,4 +384,15 @@ class OrcFilterSuite extends OrcTest with
SharedSQLContext {
)).get.toString
}
}
+
+ test("SPARK-25579 ORC PPD should support column names with dot") {
+import testImplicits._
+
+withTempDir { dir =>
+ val path = new File(dir, "orc").getCanonicalPath
+ Seq((1, 2), (3, 4)).toDF("col.dot.1", "col.dot.2").write.orc(path)
+ val df = spark.read.orc(path).where("`col.dot.1` = 1 and `col.dot.2`
= 2")
+ checkAnswer(stripSparkFilter(df), Row(1, 2))
--- End diff --
Like that test, this test also generates two ORC files with one row and
test if PPD works.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22714: [SPARK-25720][WEBUI] Support auto refresh page for the W...
Github user shahidki31 commented on the issue: https://github.com/apache/spark/pull/22714 @gengliangwang Sorry, I didn't see the PR. Yes, that PR also for refreshing functionality for the webui. I have taken the patch and checked the functionality, and it seems fine. Below is the screen shot of the ui. **Except the alignment of the tabs,** functionality seems good. **After the patch** 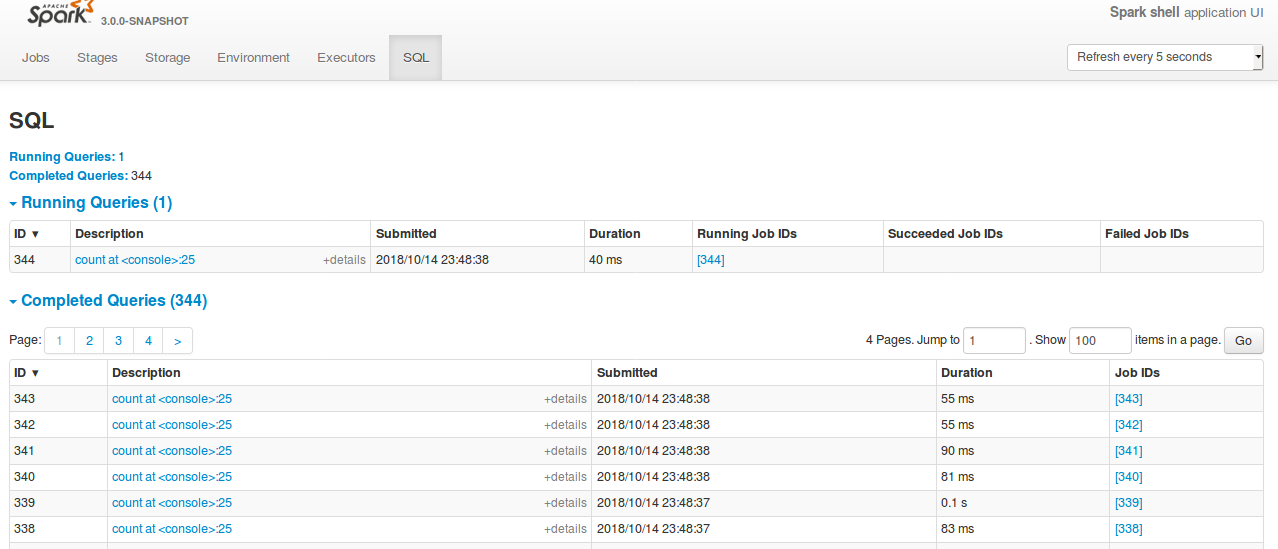 **Before the patch**  --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22597: [SPARK-25579][SQL] Use quoted attribute names if ...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/22597#discussion_r225001748
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilterSuite.scala
---
@@ -383,4 +384,15 @@ class OrcFilterSuite extends OrcTest with
SharedSQLContext {
)).get.toString
}
}
+
+ test("SPARK-25579 ORC PPD should support column names with dot") {
+import testImplicits._
--- End diff --
Ur, this is `OrcFilterSuite`.
> Can we add a test at OrcFilterSuite too?
For `HiveOrcFilterSuite`, `hive` ORC implementation doesn't support `dot`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22662: [SPARK-25627][TEST] Reduce test time for Continuo...
Github user kiszk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22662#discussion_r225000849
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/streaming/continuous/ContinuousSuite.scala
---
@@ -259,10 +259,10 @@ class ContinuousStressSuite extends
ContinuousSuiteBase {
testStream(df, useV2Sink = true)(
StartStream(Trigger.Continuous(2012)),
--- End diff --
Got it, thanks
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22714: [SPARK-25720][WEBUI] Support auto refresh page for the W...
Github user gengliangwang commented on the issue: https://github.com/apache/spark/pull/22714 BTW there is another approach: https://github.com/apache/spark/pull/21512 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22575: [SPARK-24630][SS] Support SQLStreaming in Spark
Github user stczwd commented on the issue: https://github.com/apache/spark/pull/22575 cc @xuanyuanking --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21537: [SPARK-24505][SQL] Convert strings in codegen to blocks:...
Github user kiszk commented on the issue: https://github.com/apache/spark/pull/21537 @HyukjinKwon sorry for being late. I was swampped with several things. I have just submitted it. Looking forward to seeing feedback. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22662: [SPARK-25627][TEST] Reduce test time for Continuo...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/22662#discussion_r224994803
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/streaming/continuous/ContinuousSuite.scala
---
@@ -259,10 +259,10 @@ class ContinuousStressSuite extends
ContinuousSuiteBase {
testStream(df, useV2Sink = true)(
StartStream(Trigger.Continuous(2012)),
--- End diff --
I think 2012 is safer here as it only increases to epoch 1. Smaller value
might make this test flaky.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22219: [SPARK-25224][SQL] Improvement of Spark SQL ThriftServer...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22219 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22219: [SPARK-25224][SQL] Improvement of Spark SQL ThriftServer...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22219 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97363/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22219: [SPARK-25224][SQL] Improvement of Spark SQL ThriftServer...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22219 **[Test build #97363 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97363/testReport)** for PR 22219 at commit [`ffafd62`](https://github.com/apache/spark/commit/ffafd62b6d5b916e286ee6870e0db168d36a09eb). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22713: [SPARK-25691][SQL] Use semantic equality in Optimizer in...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22713 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97361/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22713: [SPARK-25691][SQL] Use semantic equality in Optimizer in...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22713 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22713: [SPARK-25691][SQL] Use semantic equality in Optimizer in...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22713 **[Test build #97361 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97361/testReport)** for PR 22713 at commit [`64aafc5`](https://github.com/apache/spark/commit/64aafc5fa08d995f508065d3d33e9b29bb4da6c5). * This patch passes all tests. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `sealed class BaseSimpleAnalyzer(caseSensitive: Boolean) extends Analyzer(` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22636: [SPARK-25629][TEST] Reduce ParquetFilterSuite: filter pu...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22636 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22636: [SPARK-25629][TEST] Reduce ParquetFilterSuite: filter pu...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22636 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97362/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22309: [SPARK-20384][SQL] Support value class in schema of Data...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22309 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/97360/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22636: [SPARK-25629][TEST] Reduce ParquetFilterSuite: filter pu...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/22636 **[Test build #97362 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/97362/testReport)** for PR 22636 at commit [`e40d79c`](https://github.com/apache/spark/commit/e40d79ce33941800408a0697e433ea4d0b20b3b5). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22309: [SPARK-20384][SQL] Support value class in schema of Data...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/22309 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org