hj2016 commented on PR #4015: URL: https://github.com/apache/hudi/pull/4015#issuecomment-1099815631
@nsivabalan 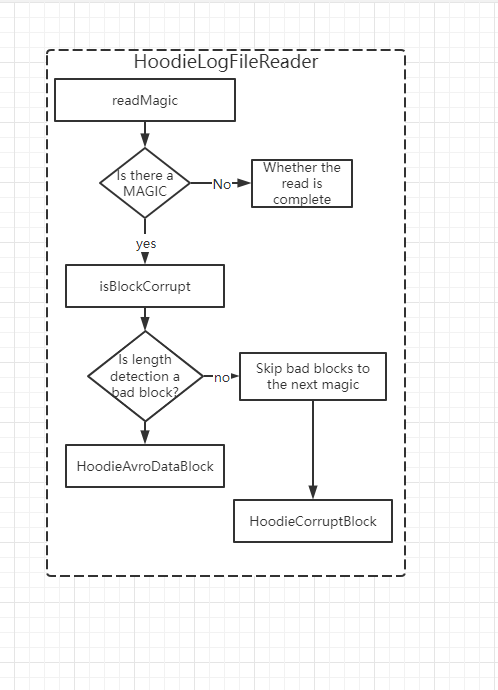 The hudi log file consists of blocks. A log may contain several blocks information written by deltacommits. Each block is divided by MAGIC. The content of each block is shown in the figure above. The Block Header will record the deltacommit instantTime of each block. It will scan and read the blocks that need to be merged during the compact process. HoodieLogFileReader is used to read log files and convert the log files into blocks. First, it will try to read the MAGIC separation. If find the separation, it will read the size of next position and check if it exceed the total size of the file to recognize bad blocks. If a bad block is recognized, it will skip the bad block content and create a bad block object HoodieCorruptBlock. Skipping he bad block means to retrieve the MAGIC (#HUDI#) after the current block total size position, read 1 megabyte each time until the next MAGIC separation. After finding the MAGIC, jump to the current MAGIC position, and then you can continue to rea d complete block information. The position of the bad block mentioned above is retrieved after the block total size position. If the file only contains MAGIC content without task content, it will lead to error. At this time, the HoodieLogFileReader will write MAGIC continuously, and consider MAGIC the Block Total size, and the next normal block will be skipped during the retrieval process and returned as a bad block. This part of the block data is lost during the merging process. In this situation, the skipped bad block is retrieved after the MAGIC instead of after the block total size, and the normal block will not be skipped when continuous MAGIC occurs during reading. This problem was discovered when we do random online kill flink task. The data will not be lost by repairing and merging data in this way. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
{kind=link}