ahmed-elfar commented on issue #1498: Migrating parquet table to hudi issue [SUPPORT] URL: https://github.com/apache/incubator-hudi/issues/1498#issuecomment-612650421 @vinothchandar Thank you very much for your answer and help, and everyone participated to resolve the issue. We already have done further attempts with Hudi for bulk-insert, but I didn't want to mention that in the current thread, until we make sure that it is **either we are missing something or there is an initial high cost to migrate the base tables from parquet to Hudi**, because we need to know the pros, cons and limitation before adding Hudi to our product, we are talking about migrating hundreds of GB and/or TB of data from parquet to Hudi table. So I will share more details which might help, and answer to your suggestions and questions. First I will share information about the data: - For initial bench-marking we generate standard **tpch** data 1GB, 10GB, 30GB, 100GB, 265GB and 1TB. The tables mentioned on previous discussion is **lineitem** generated by tpch 30GB and 100GB, which has original parquet size of 6.7GB and 21GB respectively. - Schema for lineitem 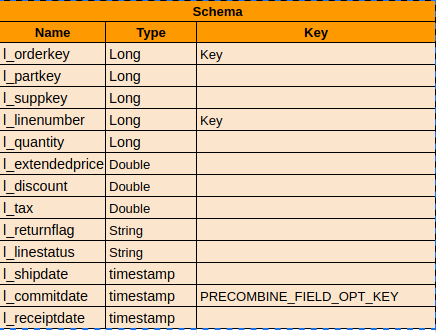 - We have another version of lineitem with additional column last_updated with generated timestamp to define as PRECOMBINE_FIELD_OPT_KEY - Increments are 3% to 5% of the original base table count, 30% updates and 70% inserts. - We have 2 versions of generated updates, one which touches only the last quarter of the year and another one generated randomly to touch most of the parquet parts during updates. - Currently we generate no duplicates for the base table and increments. Based on the same test data we have done further attempts by modifying HoodieSparkSqlWriter itself, UserDefinedBulkInsertPartitioner, HoodieRecord, change the payload. I will share the test result for defining UserDefinedBulkInsertPartitioner because it looks similar as the approach you mentioned to avoid the sorting for bulk-insert: Applying bulk-insert for **lineitem** generated from tpch 1GB **Table** : 213MB parquet, 6M records, 16 columns and key is composite of 2 columns. **Spark Conf** : 1 executor, 12 cores, 16GB, 32 shuffle, 32 bulk-insert-parallelism. **Hudi Version**: % "hudi-spark-bundle" % "0.5.2-incubating" **Spark** : 2.4.5 with hadoop 2.7 **Table Type** : COW - Using vanilla % "hudi-spark-bundle" % "0.5.2-incubating", spark stages  As you can see the data has been shuffled to disk twice, applying the sorting twice as well. - Eagerly persist the input RDD before the bulk-insert, which uses the same sorting provided before the bulk-insert. `@Override public JavaRDD<HoodieRecord> repartitionRecords(JavaRDD records, int outputSparkPartitions) { JavaRDD<HoodieRecord> data = ((JavaRDD<HoodieRecord>)records).sortBy(record -> { return String.format("%s+%s", record.getPartitionPath(), record.getRecordKey()); }, true, outputSparkPartitions) .persist(StorageLevel.MEMORY_ONLY()); data.foreach(record -> {}); return data; } ` 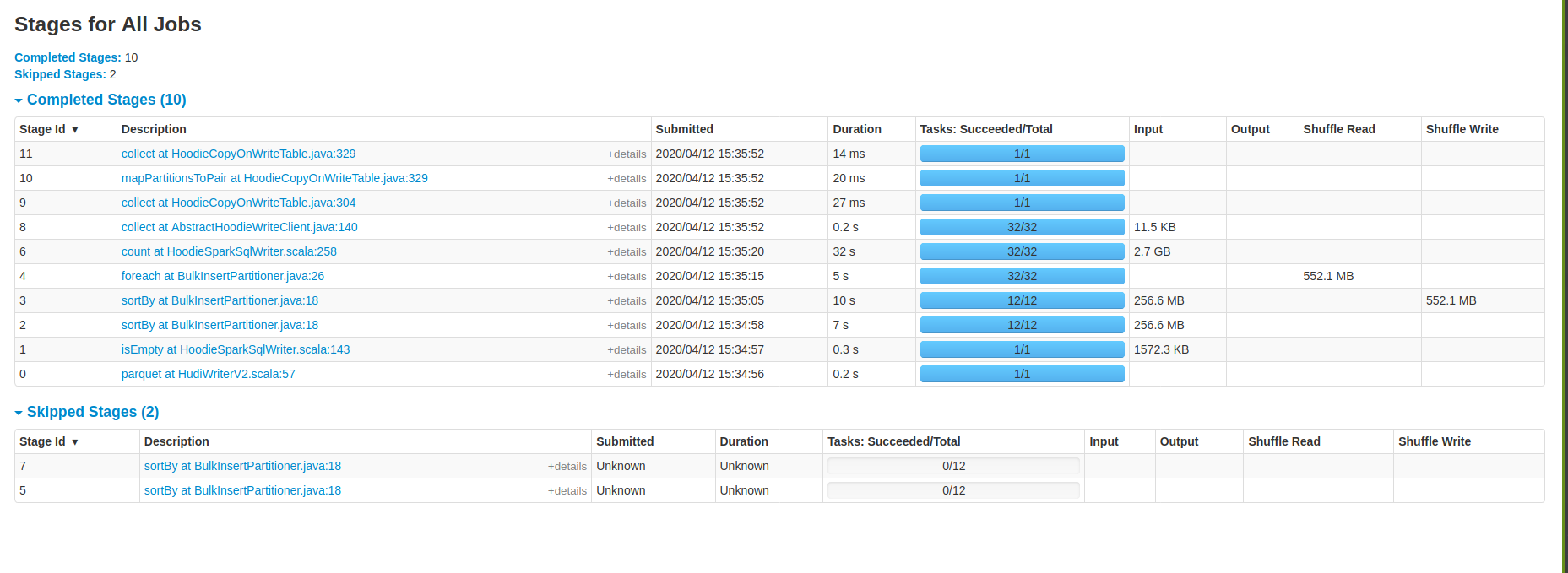 So we avoided additional shuffle to disk, yet the performance still the same as well as we can't persist in memory for very large inputs. - Just return the RDD as it is, or (sort, partition the data based on the key columns) on the dataframe level before passing the dataframe to HudiSparkSqlWriter, then just return the data. `@Override public JavaRDD<HoodieRecord> repartitionRecords(JavaRDD records, int outputSparkPartitions) { return records; }` 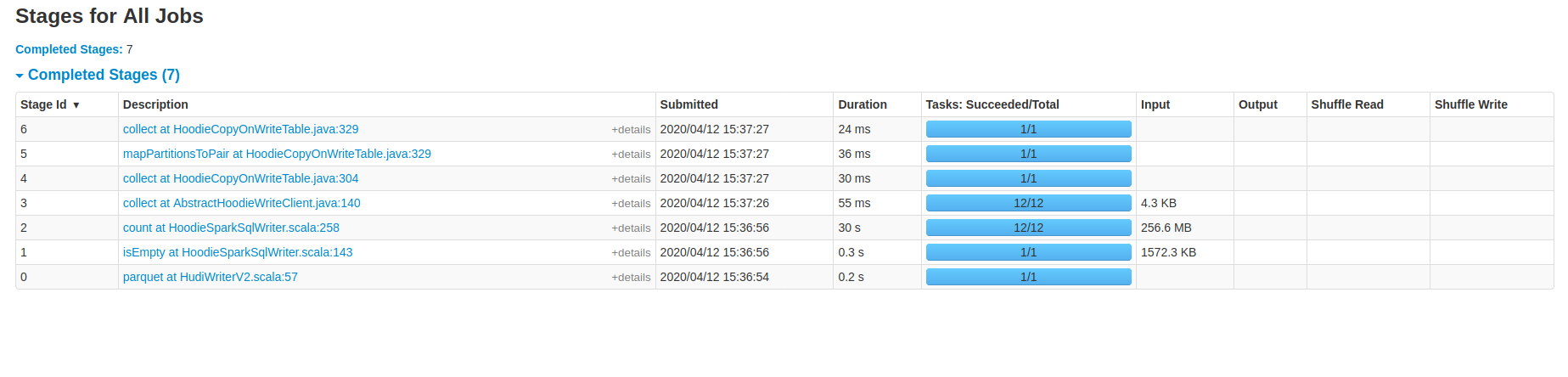 **Note:** this approach impact the Upsert time significantly specially if you didn't apply any sorting to the data, it might be because the upsert operation touched most of the parquet parts. So please correct me if I am wrong, all the attached spark stages to the thread shows most of time spent (bottle neck) in the count action which filter the records with invalid write status, it is actually a narrow transformation after the sorting operation. We haven't checked the logic behind this action in details yet, I thought this might be the indexing operation and creating the metadata columns for Hudi table. Replaying to the questions and suggestion you mentioned: > If you are trying to ultimately migrate a table (using bulk_insert once) and then do updates/deletes. I suggest, testing upserts/deletes rather than bulk_insert.. If you primarily want to do bulk_insert alone to get other benefits of Hudi. Happy to work with you more and resolve this. Perf is a major push for the next release. So we can def collaborate here Yes we need to fully migrate the table to Hudi and apply excessive upserts / insert operations over it later. If I get your suggestion right, would you suggest to initially load the table using upsert or insert operation for the whole table instead of bulk-insert? We have tried that and it was extremely slower, consuming more memory and disk than bulk-insert. We followed the documentation as well in the code which suggest to use the bulk-insert for initial table loading. > Optimizing the spark executor memory to avoid GC hits and using snappy compression We actually have tried many optimizations related to spark yet the performance improvements is limited or no gain.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services