wzx140 commented on code in PR #6745:
URL: https://github.com/apache/hudi/pull/6745#discussion_r981159766
##########
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/HoodieSparkSqlWriter.scala:
##########
@@ -867,18 +867,20 @@ object HoodieSparkSqlWriter {
hoodieRecord
}).toJavaRDD()
case HoodieRecord.HoodieRecordType.SPARK =>
+ log.info("Use spark record")
// ut will use AvroKeyGenerator, so we need to cast it in spark record
val sparkKeyGenerator =
keyGenerator.asInstanceOf[SparkKeyGeneratorInterface]
+ val schemaWithMetaField = HoodieAvroUtils.addMetadataFields(schema,
config.allowOperationMetadataField)
val structType = HoodieInternalRowUtils.getCachedSchema(schema)
- val structTypeBC = SparkContext.getOrCreate().broadcast(structType)
- HoodieInternalRowUtils.addCompressedSchema(structType)
+ val structTypeWithMetaField =
HoodieInternalRowUtils.getCachedSchema(schemaWithMetaField)
+ val structTypeBC = sparkContext.broadcast(structType)
+ HoodieInternalRowUtils.broadcastCompressedSchema(List(structType,
structTypeWithMetaField), sparkContext)
Review Comment:
The broadcast ensures that every executor has the same fingerprint->schema
cache. We can't make every executor initialize fingerprint->schema locally.
For example, if we initialize fingerprint->schema in sparksqlwriter df, it
is possible that **the number of dataframe partitions is less than the number
of executors**.
```scala
HoodieInternalRowUtils.addCompressedSchema(structType)
df.queryExecution.toRdd.map(row => {
val internalRow = row.copy()
val (processedRow, writeSchema) =
getSparkProcessedRecord(partitionCols, internalRow, dropPartitionColumns,
structTypeBC.value)
val recordKey = sparkKeyGenerator.getRecordKey(internalRow,
structTypeBC.value)
val partitionPath =
sparkKeyGenerator.getPartitionPath(internalRow, structTypeBC.value)
val key = new HoodieKey(recordKey.toString, partitionPath.toString)
// See this We can't guarantee that this is executed in all
executors
HoodieInternalRowUtils.addCompressedSchema(structType)
new HoodieSparkRecord(key, processedRow, writeSchema)
}).toJavaRDD().asInstanceOf[JavaRDD[HoodieRecord[_]]]
```
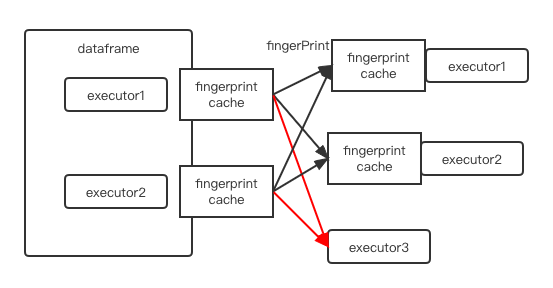
As shown in the figure below, executor3 do not has the fingerPrint cache and
can not deserialize the fingerPrint to schema.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
{kind=link}