zhuanshenbsj1 commented on code in PR #8505:
URL: https://github.com/apache/hudi/pull/8505#discussion_r1176051746
##########
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/SparkRDDTableServiceClient.java:
##########
@@ -245,6 +246,7 @@ private void completeClustering(HoodieReplaceCommitMetadata
metadata,
metrics.updateCommitMetrics(parsedInstant.getTime(), durationInMs,
metadata, HoodieActiveTimeline.REPLACE_COMMIT_ACTION)
);
}
+ waitForAsyncServiceCompletion();
LOG.info("Clustering successfully on commit " + clusteringCommitTime);
Review Comment:
Without this change,if config ASYNC_CLEAN = true,AsyncCleanerService will be
used to do clean in offline job .
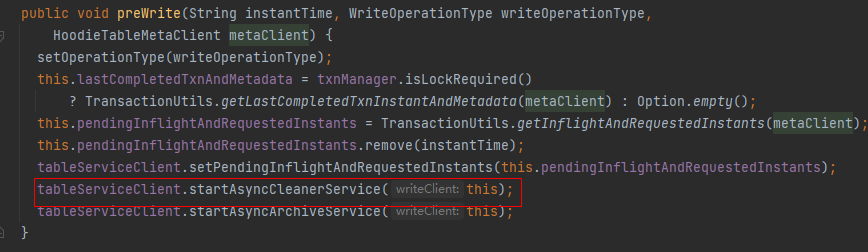
In my unit testing for offline job,if the completion time of the
compact/cluster job is earlier than the completion time of the sync-cleaning
job, function BaseHoodieTableServiceClient.close() will force the
asunc-cleaning job to be closed.
<img width="372" alt="d0570721dc3b1983191e5451751c1815"
src="https://user-images.githubusercontent.com/34104400/234192499-dabdbd5f-8df8-476f-9812-72151e5d6873.png";>
So I added this wait and made the entire task wait for clean to complete
before smoothly exiting.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
{kind=link}
{kind=link}