WTa-hash opened a new issue #2229: URL: https://github.com/apache/hudi/issues/2229
I am running a Spark structured stream running on AWS EMR that is setup to query from AWS Kinesis. Batches are sent to Hudi for processing. Each batch may contain 10k-30k records. Currently the AWS Kinesis stream is setup with 1 shard. If I resize my EMR cluster and add additional core/task nodes, the processing time remains roughly the same. I see that UpsertPartitioner (Getting small files from partitions) is taking the most time (see screenshot below). 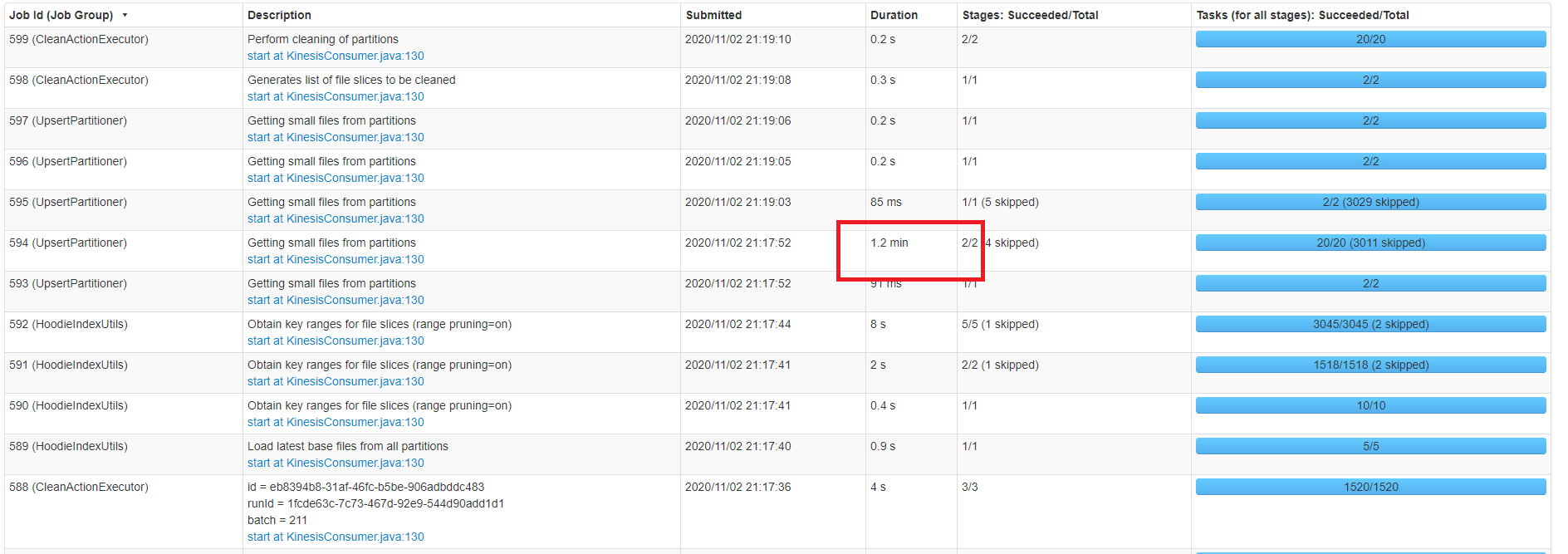 Below is a closer look at the Task: 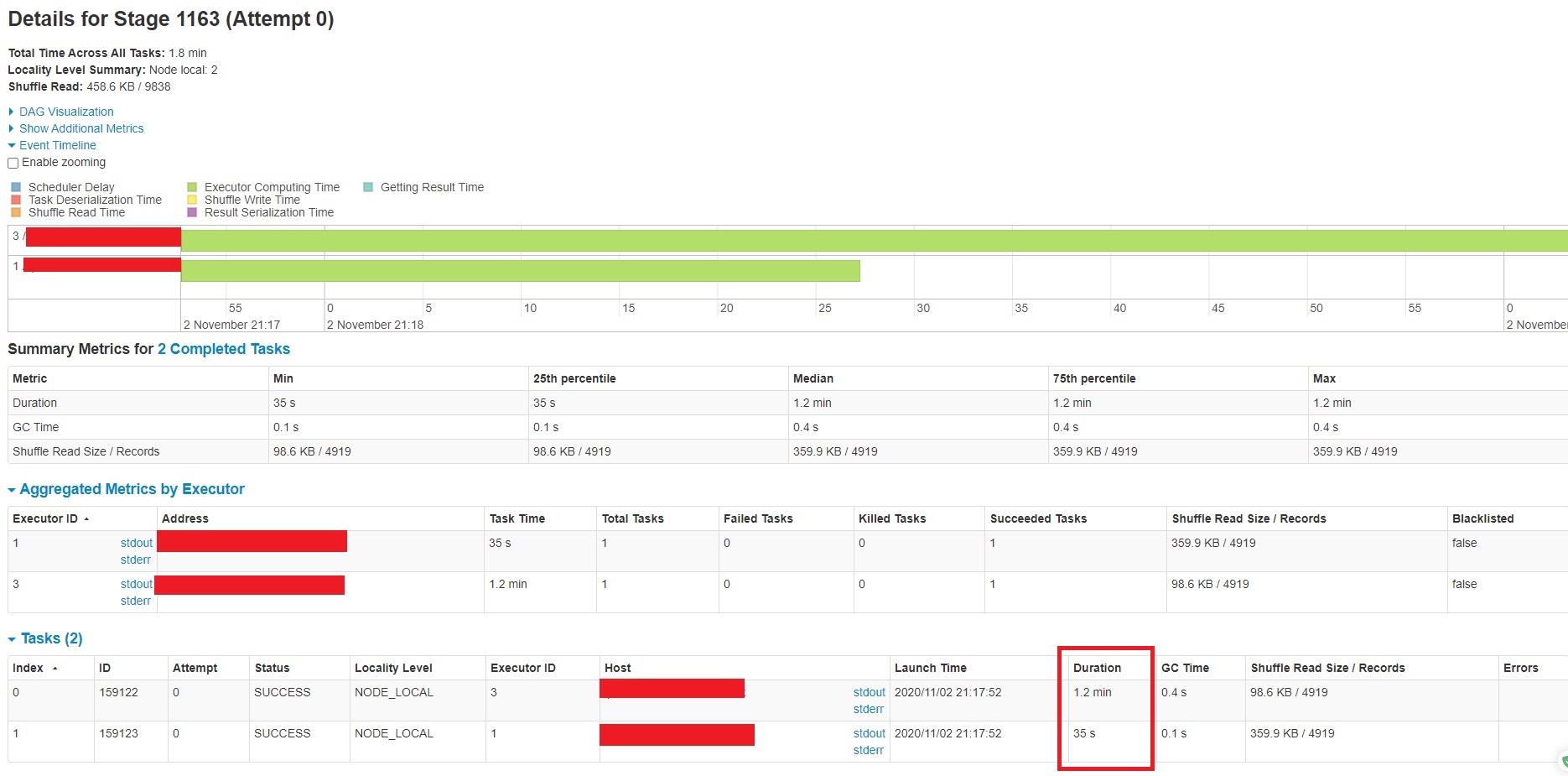 What is UpsertPartitioner (Getting small files from partitions)? How might I improve its performance? **HUDI PROPERTIES** KEY={hoodie.datasource.hive_sync.table} VALUE={...} KEY={hoodie.datasource.hive_sync.partition_fields} VALUE={__date} KEY={hoodie.datasource.hive_sync.partition_extractor_class} VALUE={org.apache.hudi.hive.MultiPartKeysValueExtractor} KEY={hoodie.datasource.write.partitionpath.field} VALUE={__date} KEY={hoodie.bloom.index.update.partition.path} VALUE={true} KEY={hoodie.parquet.max.file.size} VALUE={125829120} KEY={hoodie.table.name} VALUE={....} KEY={hoodie.datasource.write.recordkey.field} VALUE={....} KEY={hoodie.consistency.check.enabled} VALUE={true} KEY={hoodie.datasource.write.keygenerator.class} VALUE={org.apache.hudi.keygen.ComplexKeyGenerator} KEY={hoodie.datasource.write.table.type} VALUE={COPY_ON_WRITE} KEY={hoodie.datasource.hive_sync.jdbcurl} VALUE={jdbc:hive2://.....:10000} KEY={hoodie.index.class} VALUE={org.apache.hudi.index.bloom.HoodieGlobalBloomIndex} KEY={hoodie.datasource.write.payload.class} VALUE={...custom payload class} KEY={hoodie.datasource.write.precombine.field} VALUE={__ts_ms} KEY={hoodie.datasource.hive_sync.enable} VALUE={true} KEY={hoodie.datasource.hive_sync.database} VALUE={...} **SPARK CONFIG** --conf spark.driver.userClassPathFirst=true --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.driver.cores=3 --conf spark.driver.memory=9216m --conf spark.driver.memoryOverhead=2048m --conf spark.executor.cores=3 --conf spark.executor.memory=9216m --conf spark.executor.memoryOverhead=2048m --conf spark.default.parallelism=18 --conf spark.locality.wait=10s --conf spark.task.maxFailures=8 --conf spark.ui.killEnabled=false --conf spark.logConf=true --conf spark.yarn.maxAppAttempts=4 --conf spark.yarn.am.attemptFailuresValidityInterval=1h --conf spark.yarn.max.executor.failures=12 --conf spark.yarn.executor.failuresValidityInterval=1h --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.initialExecutors=3 --conf spark.dynamicAllocation.minExecutors=0 --conf spark.dynamicAllocation.maxExecutors=30 --conf spark.dynamicAllocation.executorAllocationRatio=1 --conf spark.dynamicAllocation.executorIdleTimeout=120s --conf spark.dynamicAllocation.cachedExecutorIdleTimeout=300s --conf spark.dynamicAllocation.schedulerBacklogTimeout=3s --conf spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=10s **ENVIRONMENT SETUP** AWS EMR: 5.31.0 Hudi version : 0.6.0 Spark version : 2.4.6 Hive version : 2.3.7 Hadoop version : 2.10.0 Storage (HDFS/S3/GCS..) : S3 Running on Docker? (yes/no) : no ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}