so-lazy commented on issue #2338:
URL: https://github.com/apache/hudi/issues/2338#issuecomment-758656180
> @so-lazy :
> Also, I see you have space around "=" sign (set
spark.sql.hive.convertMetastoreParquet = false;) Try removing it. Please also
enable INFO logging and run the select group by query and attach them if the
problem persists.
@bvaradar Sorry,bvaradar, these days i was so busy didn't reply on time.
Today i followed your suggest and attach screen shot.
> val df =
spark.read.format("hudi").load("hdfs://hadoop01:9000/hudi/cars/carsdata/inf_car_bin/*")
run this i got unique record
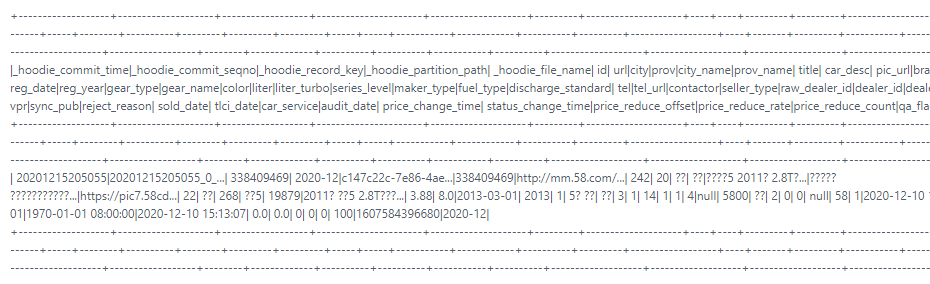
> run sql on hive ro table
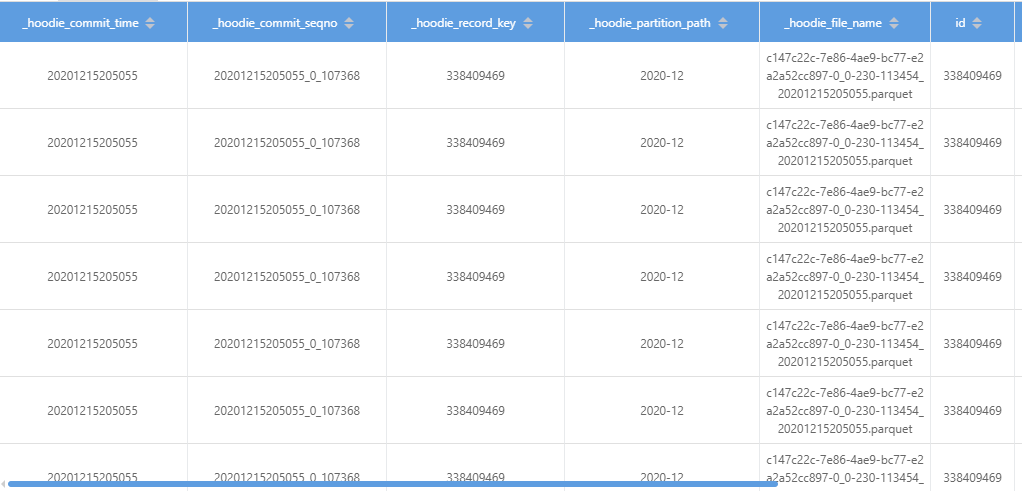
> Also, Are you passing the config
(spark.sql.hive.convertMetastoreParquet=false) when you are launching spark ?
https://hudi.apache.org/docs/querying_data.html#spark-sql.
Yeah after passing this config, i can see unique record. thanks so much ,
and now i am gonna try other index type, for global_bloom , it's so slowly may
be there are some problems in my program. Hudi is a good software , thanks for
your time and effort.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
{kind=link}
{kind=link}