Rap70r opened a new issue #3697:
URL: https://github.com/apache/hudi/issues/3697
Hello,
We are using Spark and Hudi to upsert records into parquet in S3, extracted
from Kafka, using EMR. The events could be either inserts or updates.
Currently, it takes 41 minutes for the process to extract and upsert
1,430,000 records (1714 Megabytes).
We are trying to increase the speed of this process. Below are the details
of our environment
**Environment Description**
* Hudi version : 0.9.0
* EMR version : 6.4.0
> Master Instance: 1 r5.xlarge
> Core Instance: 1 c5.xlarge
> Task Instance: 25 c5.xlarge
* Spark version : 3.1.2
* Hive version : n/a
* Hadoop version : 3.2.1
* Source : Kafka
* Storage : S3 (as parquet)
* Partitions: 1100
* Partition Size: ~1MB to 30MB each
* Parallelism: 3000
* Operation: Upsert
* Partition : Concatenation of year, month and week of a date field
* Storage Type: COPY_ON_WRITE
* Running on Docker? : no
**Spark-Submit Configs**
`spark-submit --deploy-mode cluster --conf
spark.dynamicAllocation.enabled=true --conf
spark.dynamicAllocation.cachedExecutorIdleTimeout=300s --conf
spark.dynamicAllocation.executorIdleTimeout=300s --conf
spark.scheduler.mode=FAIR --conf spark.memory.fraction=0.4 --conf
spark.memory.storageFraction=0.1 --conf spark.shuffle.service.enabled=true
--conf spark.sql.hive.convertMetastoreParquet=false --conf
spark.sql.parquet.mergeSchema=true --conf spark.driver.maxResultSize=4g --conf
spark.driver.memory=4g --conf spark.executor.cores=4 --conf
spark.driver.memoryOverhead=1g --conf spark.executor.instances=100 --conf
spark.executor.memoryOverhead=1g --conf spark.driver.cores=4 --conf
spark.executor.memory=4g --conf spark.rdd.compress=true --conf
spark.kryoserializer.buffer.max=512m --conf
spark.serializer=org.apache.spark.serializer.KryoSerializer --conf
spark.yarn.nodemanager.vmem-check-enabled=false --conf
yarn.nodemanager.pmem-check-enabled=false --conf spark.sql.shuffle.partitions=10
0 --conf spark.default.parallelism=100 --conf spark.task.cpus=2`
**Spark Job**
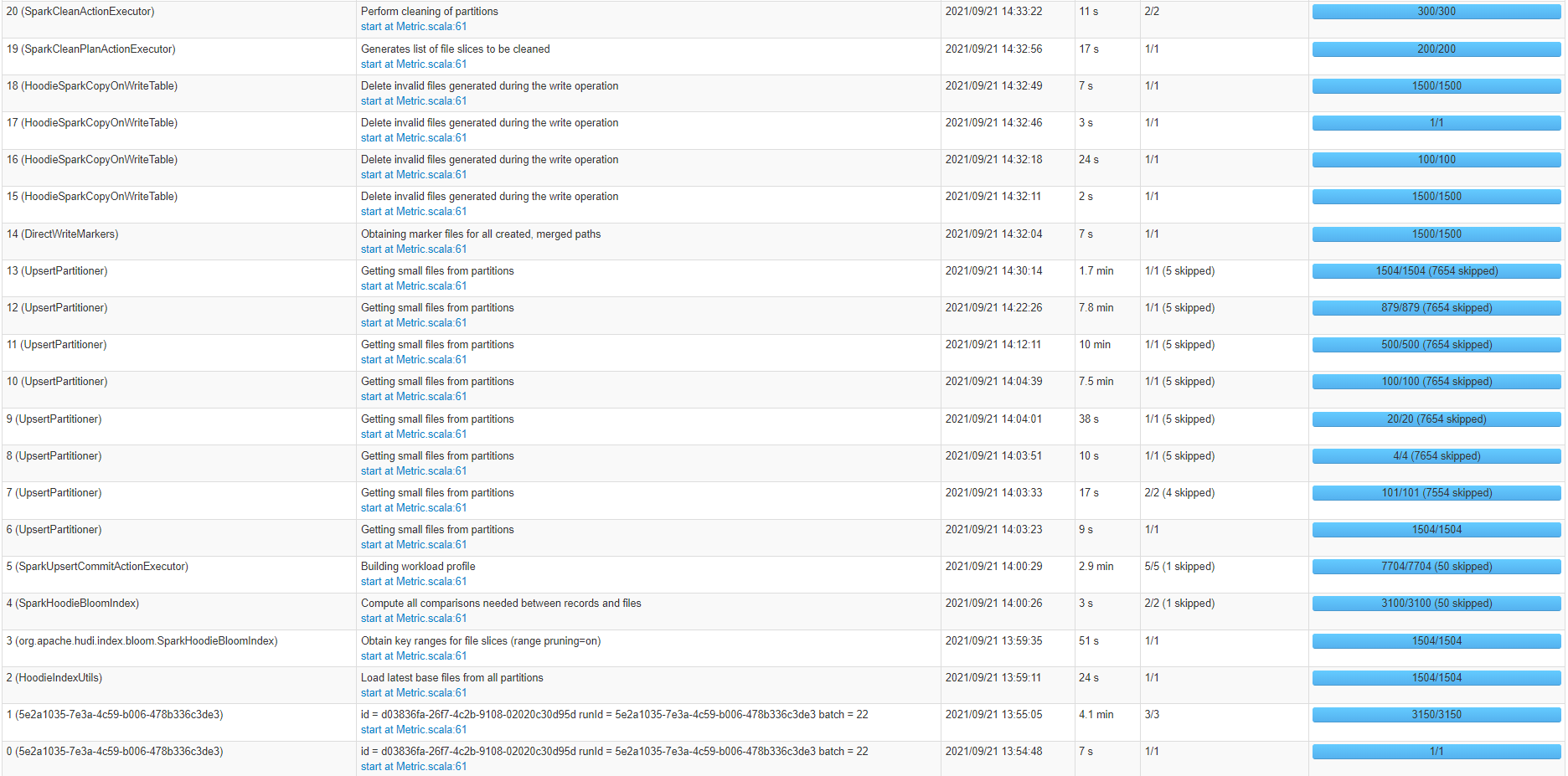
From the job above, it seems that most of the time is consumed by
UpsertPartitioner and SparkUpsertCommitActionExecutor events.
Do you have any suggestions on how to reduce the time above job takes to
complete?
Thank you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
{kind=link}