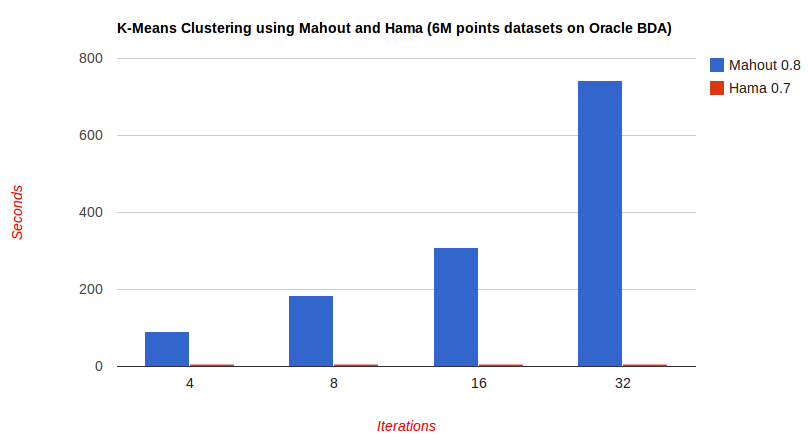
Hi all, I just noticed that the graph on our homepage [0] looks very similar to the one on Spark homepage [1] so I wonder if we could at least make it a bit clearer either by writing the benchmarks results in a table near it (it seems Hama always takes ~0) or something else I cannot think to right now.
The reference to the benchmarks wiki page is ok but I cannot find the entry for the comparison with Mahout, maybe I'm missing something ... Regards and happy new year everyone. Tommaso [0] : http://hama.apache.org/images/mahout_vs_hama.png [1] : http://spark.incubator.apache.org/images/spark-lr.png 2013/12/20 Edward J. Yoon <[email protected]> > Hi all, > > I published new website for our community. If you have other ideas, please > feel free to share your comments or file a JIRA ticket. > > > On Fri, Dec 20, 2013 at 11:29 AM, Edward J. Yoon <[email protected] > >wrote: > > > Thanks, I'll. > > > > Sent from my iPhone > > > > > On 2013. 12. 19., at 오후 10:41, Yexi Jiang <[email protected]> wrote: > > > > > > Hi, > > > > > > It looks nice. Is it possible to add more description to the figure? > When > > > people first saw this, they may not know what the x axis is (the number > > of > > > cores or the number of the number of groom servers?). Moreover, it is > > > better to tell the reader some specs of the dataset used. > > > > > > Regards, > > > Yexi > > > > > > > > > 2013/12/19 Edward J. Yoon <[email protected]> > > > > > >> Thank you so much! > > >> > > >> Sent from my iPhone > > >> > > >>>> On 2013. 12. 19., at 오후 4:45, Tommaso Teofili < > > [email protected]> > > >>> wrote: > > >>> > > >>> Hi Edward, > > >>> > > >>> I think it generally looks better than the current one, I would just > > >> change > > >>> this: > > >>> > > >>> Many data analysis techniques such as machine learning and graph > > >> algorithms > > >>> require iterative computations but MapReduce model doesn't fit for > > these > > >>> iterative data analysis applications. To run these iterative data > > >> analysis > > >>> applications more efficiently, Hama offers pure Bulk Synchronous > > Parallel > > >>> computing engine. > > >>> > > >>> > > >>> to something like this: > > >>> > > >>> Many data analysis techniques such as machine learning and graph > > >> algorithms > > >>> require iterative computations, this is where Bulk Synchronous > Parallel > > >>> model can be more effective than "plain" MapReduce. Therefore to run > > such > > >>> iterative data analysis applications more efficiently, Hama offers > pure > > >>> Bulk Synchronous Parallel computing engine. > > >>> > > >>> > > >>> As I wouldn't say MR is inherently not good for iterative > computations, > > >>> just BSP can be a better / more perfomant alternative. > > >>> My 2 cents, > > >>> Tommaso > > >>> > > >>> > > >>> 2013/12/19 Edward J. Yoon <[email protected]> > > >>> > > >>>> Hi, > > >>>> > > >>>> I've made some changes to our website - > > >>>> http://people.apache.org/~edwardyoon/site/ - Please review and > > feedback > > >>>> here. > > >>>> > > >>>> -- > > >>>> Best Regards, Edward J. Yoon > > >>>> @eddieyoon > > > > > > > > > > > > -- > > > ------ > > > Yexi Jiang, > > > ECS 251, [email protected] > > > School of Computer and Information Science, > > > Florida International University > > > Homepage: http://users.cis.fiu.edu/~yjian004/ > > > > > > -- > Best Regards, Edward J. Yoon > @eddieyoon >
{kind=link}
{kind=link}