Github user LosD commented on the issue:
https://github.com/apache/metamodel/pull/194
Made a (bit stupid) test:
```Java
import org.apache.metamodel.data.DataSet;
import org.apache.metamodel.excel.ExcelDataContext;
import org.apache.metamodel.schema.Column;
import org.apache.metamodel.schema.Schema;
import org.apache.metamodel.schema.Table;
import java.io.File;
public class Main {
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
ExcelDataContext excelDataContext = new ExcelDataContext(new
File("C:\\Users\\Dennis\\Documents\\testlarge.xlsx"));
Schema schema = excelDataContext.getDefaultSchema();
Table table = schema.getTable(0);
Column column = table.getColumn(0);
Column column2 = table.getColumn(1);
DataSet ds =
excelDataContext.query().from(table).select(column).where(column2).gt(2).execute();
long rows = 0;
while (ds.next()) {
rows++;
if("NOWAY".equals(ds.getRow().getValue(0))) {
throw new RuntimeException("NO WAY!");
}
}
long endTime = System.currentTimeMillis();
System.out.println("Total execution time: " + (endTime-startTime) +
"ms, for " + rows + " rows");
}
}
```
(Applied the `where` to give MM a little bit of calculating work, and did
the NOWAY test just to ensure that Java doesn't optimize the loop out. It's
been too long for me to remember a better way)
The source sheet is 2 columns of numbers, one of text, and 610560 rows of
it on XLSX, 65536 on XLS (maximum). I newer really did anything with the third
column, but I guess we're mostly testing data loading anyway.
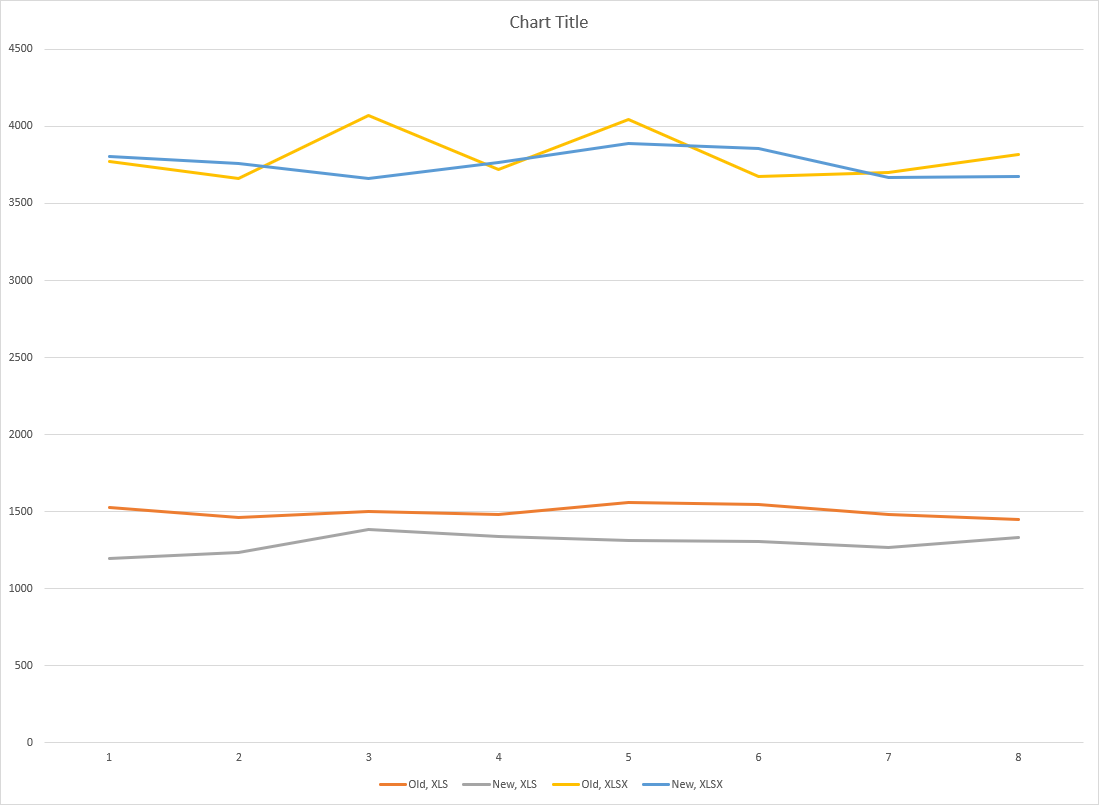
It looks like improvements for XLS, and a toss-up for XLSX to me (scale is
milliseconds). I could average to get a winner there, but I'm pretty sure
there's not enough numbers anyway. Though it looks like the old one is maybe a
bit more peaky (also noticed that when I, errrrr, tested my test):
---
{kind=link}