I did a little bit of research and although there are many solutions out there, the top two I shortlisted to based on many criteria (community, plugins, eco-system, features) are zabbix and nagios, and I list below the pros and cons from my perspective.
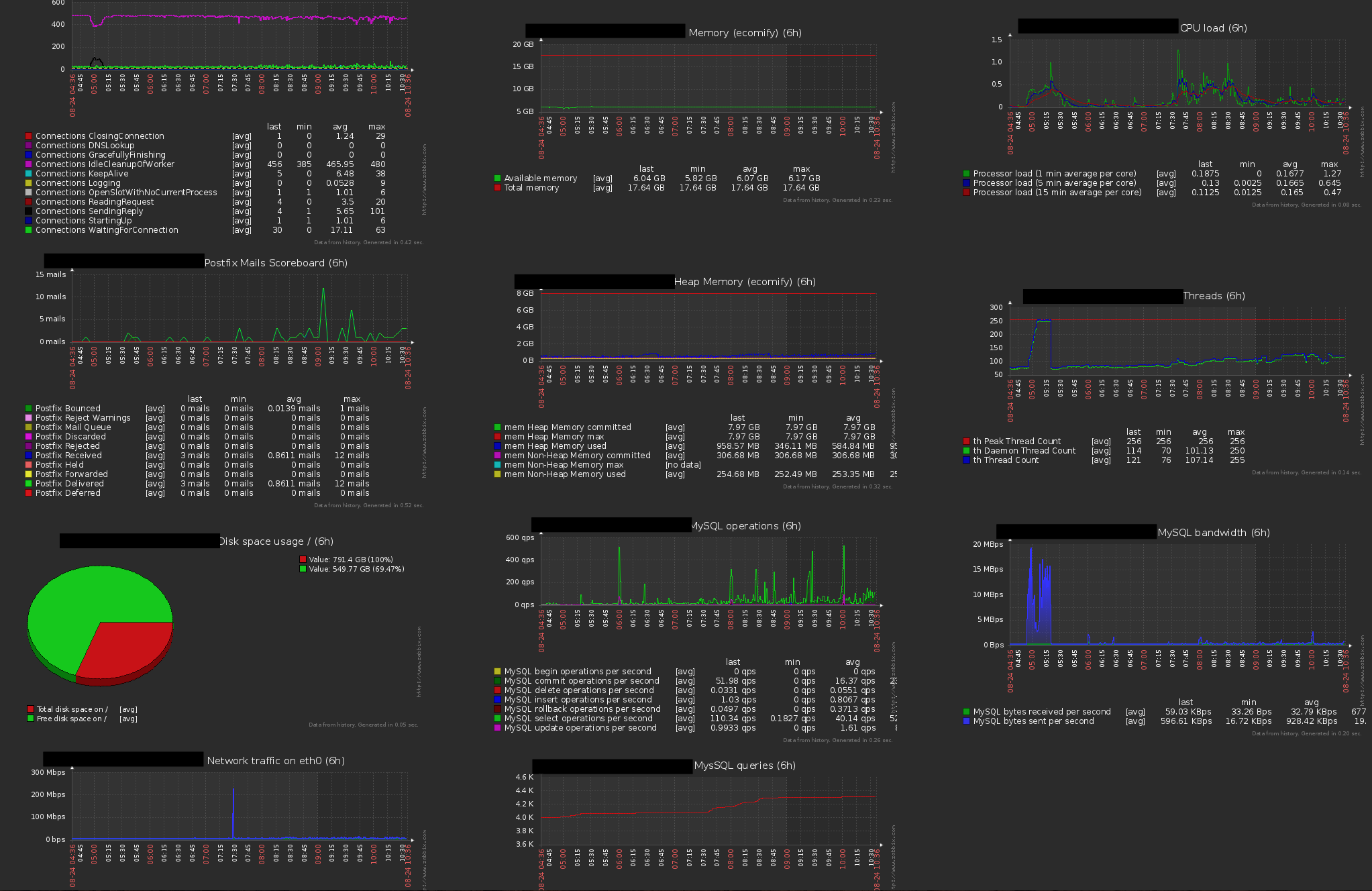
Given that our needs are not too complex, I find my self leaning slightly towards zabbix. # nagios pros - mature and battle tested - massive plugin collection - highly customizable - Configuration can be stored in a revision system (config files) - No database, simpler # nagios cons - steep learning curve (everything is a config file) - The web interface is limited - because of the huge eco-system some plugins are abandoned or not well maintained - community is a bit fragmented with many forks out there (e.g. icinga, etc ...) # zabbix pros - Powerful web interface - Excellent template system that makes complex flows - Easy to deploy and configure - Easy to learn and use - More functionality OOTB # zabbix cons - More complex architecture with a database backend - Less customizable - Smaller community and eco-system, plugins not as numerous On Sat, Aug 25, 2018 at 12:30 PM Jacques Le Roux <[email protected]> wrote: > > Mind you, I already asked when the infra stopped providing it. Then Daniel > (Gruno) told me I could use the free tool his company provided. I used that > for months, but it's now discontinued. So I had to find the one which suited > me best and I explained that at the start of this thread. > > The problem for me is how to share the burden and especially have more brains > around it. It's years I handle the demos alone... > > Jacques > > Le 25/08/2018 à 11:07, Pierre Smits a écrit : > > Since we're talking about our demo instances on the infrastructure of the > > ASF I suggest getting in touch with INFRA and work out a solution with them > > that favours both parties. They surely will have monitoring solutions in > > place and can advice on what is achievable. > > > > > > > > Best regards, > > > > Pierre Smits > > > > Apache Trafodion <https://trafodion.apache.org>, Vice President > > Apache Directory <https://directory.apache.org>, PMC Member > > Apache Incubator <https://incubator.apache.org>, committer > > *Apache OFBiz <https://ofbiz.apache.org>, contributor (without privileges) > > since 2008* > > Apache Steve <https://steve.apache.org>, committer > > > > > > On Fri, Aug 24, 2018 at 4:36 PM Jacques Le Roux < > > [email protected]> wrote: > > > >> Agreed, I have used VisualVMin the past, it's a simple and efficient tool > >> > >> I have planned to make a VOTE about options if needed. Let's see if it > >> will be necessary (consensus being preferred) > >> > >> Jacques > >> > >> > >> Le 24/08/2018 à 16:06, Girish Vasmatkar a écrit : > >>> Speaking of monitoring tools and if we don't want to go for third party > >>> tools, we can also use VisualVM that comes bundled with Oracle JDK. It > >> can > >>> connect to the remote VM (OFBiz process) and start displaying various > >>> information. > >>> > >>> Very minimal configuration is needed in the form of VM argument to allow > >>> for remote monitoring. Also, to enable further analysis of what went > >> wrong, > >>> why JVM crashed etc, we should also dump heap as the JVM shuts down. > >>> > >>> Too many ways and too many options. Probably need to reach a unanimous > >>> decision, IMO. > >>> > >>> Thanks and Best regards, > >>> Girish Vasmatkar > >>> > >>> On Fri, Aug 24, 2018 at 4:56 PM Jacques Le Roux < > >>> [email protected]> wrote: > >>> > >>>> Thanks Michael, > >>>> > >>>> Best idea so far! > >>>> > >>>> Jacques > >>>> > >>>> > >>>> Le 24/08/2018 à 11:08, Michael Brohl a écrit : > >>>>> We are monitoring our OFBiz instances with JMX and self hosted Zabbix > >>>> [1]. > >>>>> Zabbix gives you a nice overview about the system health and metrics > >>>> like memory consumption etc. It also sends out warnings (Email, SMS or > >>>> else) > >>>>> if metrics are exceeded (like CPU load or memory consumption) as well > >> as > >>>> the system is not accessible. > >>>>> Looks like this: [2] > >>>>> > >>>>> There is no programming needed, just some configuration for JMX and > >>>> Zabbix. > >>>>> [1] https://www.zabbix.com/ > >>>>> [2] > >>>> https://www.ecomify.de/wp-content/uploads/2018/08/Zabbix_Monitoring.png > >>>>> If we want to see why the demos crash, it might be useful. If we only > >>>> want to monitor if the system is up, a simple cron job which sends a > >> mail > >>>>> might be enough... > >>>>> > >>>>> Regards, > >>>>> > >>>>> Michael Brohl > >>>>> ecomify GmbH > >>>>> www.ecomify.de > >>>>> > >>>>> > >>>>> Am 24.08.18 um 10:07 schrieb Taher Alkhateeb: > >>>>>> Okay all neat ideas, I'm not sure if the energy you will put into > >>>> something > >>>>>> like this is equal to the value produced but if you want to make this > >>>>>> happen I would be happy to assist. > >>>>>> > >>>>>> How much time will it take to make something like this happen? I ask > >>>>>> because it seems Jacques ia getting annoyed with these crashes and > >> we'd > >>>>>> like to help him out. > >>>>>> > >>>>>> On Fri, Aug 24, 2018, 10:59 AM Girish Vasmatkar < > >>>>>> [email protected]> wrote: > >>>>>> > >>>>>>> Hi Taher > >>>>>>> > >>>>>>> Please see my reply below in-line. > >>>>>>> > >>>>>>> On Fri, Aug 24, 2018 at 12:22 PM Taher Alkhateeb < > >>>>>>> [email protected]> > >>>>>>> wrote: > >>>>>>> > >>>>>>>> Hi Girish, inline... > >>>>>>>> > >>>>>>>> On Thu, Aug 23, 2018, 7:25 PM Girish Vasmatkar < > >>>>>>>> [email protected]> wrote: > >>>>>>>> > >>>>>>>>> I had earlier replied to this thread but looks like the email did > >> not > >>>>>>> go > >>>>>>>>> through. I had leaned towards using the tool (only just) instead of > >>>> may > >>>>>>>> be > >>>>>>>>> having a CRON job or an alternative. > >>>>>>>>> > >>>>>>>>> What I feel now is that may be we can use JMX here and try to use > >>>>>>> various > >>>>>>>>> in build MBeans that provide CPU usage for the system and also for > >>>> the > >>>>>>>> JVM > >>>>>>>>> process we are concerned about that is OFBiz instance. We should > >> also > >>>>>>> be > >>>>>>>>> able to get the memory usage of the JVM and if reaches a particular > >>>>>>>>> threshold we can be notified. > >>>>>>>>> > >>>>>>>> Do you have a PoC for all of this? > >>>>>>>> > >>>>>>> GV : I can have one ready; and there is going to be much doing > >>>> involved. > >>>>>>>>> In addition, I think we already add a shutdown hook to the JVM > >>>>>>>> process... I > >>>>>>>>> am not sure and have not used it much but may be we can use it to > >>>> send > >>>>>>>> some > >>>>>>>>> notifications? Of course, it is applicable for graceful exits of > >> JVM > >>>>>>> only > >>>>>>>>> and if you just happen to kill the process it won't be of much > >> help. > >>>>>>>> The shutdown hook is used for shutting down. I'm not sure what is > >> the > >>>>>>>> purpose of mentioning it here? > >>>>>>>> > >>>>>>> GV : The reason I mentioned shutdown hook was it can be used to > >>>> send > >>>>>>> notification (may be email) or anything per our needs indicating that > >>>> the > >>>>>>> demo process was shut down. Per my understanding, shutdown hook > >>>> gets > >>>>>>> called whenever JVM shuts down gracefully. Graceful word is very > >>>> important > >>>>>>> here because we won't be able to do much if someone just kills the > >>>> process. > >>>>>>> The only thing a shutdown hook will add to this is that we will be > >>>> notified > >>>>>>> then and there. > >>>>>>> > >>>>>>>>> Hope it makes sense and correct me if I am wrong. > >>>>>>>> Well I'm struggling a bit. I didn't understand exactly what needs to > >>>> be > >>>>>>>> done? I see mixed topics about JMX, Mbeans, Memory monitors and > >>>> shutdown > >>>>>>>> hooks. First this seems to be more like coding than a tool, and > >>>> second I > >>>>>>>> have no idea how you want to implement this? > >>>>>>>> > >>>>>>> GV: Yes, it would mostly be coding rather than being a > >> substitute > >>>> for > >>>>>>> the tool. My idea was that to have a timer service run within the JVM > >>>> and > >>>>>>> it access various MBeans for the CPU usage and Memory usages just for > >>>> our > >>>>>>> monitoring purpose and raise an alert if it reaches a threshold. It > >> was > >>>>>>> just to have a glance over how JVM is performing. The disadvantage? > >> The > >>>>>>> service will run in OFBiz JVM and there will be considerable amount > >> of > >>>>>>> coding involved. > >>>>>>> > >>>>>>>> My idea for example is simple: create a cronjob that checks the > >> system > >>>>>>>> periodically and if the demo process stopped, restart it (or maybe > >>>>>>> rebuild > >>>>>>>> and restart). To go with your suggestion we need to perhaps first > >>>>>>>> understand it. > >>>>>>>> > >>>>>>> GV: There is nothing wrong with creating a CRON job, per se. The > >>>> only > >>>>>>> reason why I introduced MBeans in the mix was to be able to sort of > >>>> having > >>>>>>> OFBiz monitor itself within it's realm, hence use of MBeans. I > >> believe > >>>> a > >>>>>>> CRON will be able to do it as well. I probably did not get that we > >>>> probably > >>>>>>> want something that take some action after the JVM has crashed and > >> not > >>>>>>> having something that monitors the process and alerts concerned > >> parties > >>>>>>> that the process is occupying more than say 2 GB or it's CPU usage > >> has > >>>>>>> spiked above 80%. > >>>>>>> > >>>>>>> All in all, I feel we should choose the solution based on what we > >> want > >>>> to > >>>>>>> do and whether we want to take it further as well. I do not know what > >>>> the > >>>>>>> tool does now or whether it can build the system again and restart it > >>>>>>> automatically. I also do not know what measures we take in such an > >>>> event. I > >>>>>>> agree CRON will be simplest of them all, but if the tool provides all > >>>> of > >>>>>>> these (be able to take corrective measures) and not just send > >>>>>>> notifications, then it can also be worth it's salt. Yes, CRON will be > >>>> more > >>>>>>> technical way of achieving :) > >>>>>>> > >>>>>>> Thanks and Best regards, > >>>>>>> Girish Vasmatkar > >>>>>>> HotWax Systems > >>>>>>> > >>>>>>>>> Best regards, > >>>>>>>>> Girish Vasmatkar > >>>>>>>>> HotWax Systems > >>>>>>>>> > >>>>>>>>> > >>>>>>>>> On Thu, Aug 23, 2018 at 8:48 PM Jacques Le Roux < > >>>>>>>>> [email protected]> wrote: > >>>>>>>>> > >>>>>>>>>> Le 23/08/2018 à 14:04, Taher Alkhateeb a écrit : > >>>>>>>>>>> I'm not sure why you're hanging this on me, > >>>>>>>>>> Because you answered to the bait ;) > >>>>>>>>>> > >>>>>>>>>>> but sure I'm willing to > >>>>>>>>>>> help. > >>>>>>>>>> Thanks, much appreciated! > >>>>>>>>>> > >>>>>>>>>>> Can I get some information on how the crashes are happening and > >>>>>>>>>>> how you're getting notified, and I will take it from there. > >>>>>>>>>> I think after a crash it's mostly to use dumps there (we have > >>>> several > >>>>>>>>> from > >>>>>>>>>> the recent pas) but I'm not sure they will help, and it takes time > >>>> to > >>>>>>>>>> analyse. > >>>>>>>>>> > >>>>>>>>>> In the past I took the time to analyse some of them and it was > >>>>>>>>>> interesting. For instance in 2010 I found a bug in a Java version > >> we > >>>>>>>> were > >>>>>>>>>> using and it > >>>>>>>>>> helped me in a custom project I was also doing then: > >>>>>>>>>> https://markmail.org/message/byu2ivjn7wckayzz > >>>>>>>>>> > >>>>>>>>>> Lastly it was mostly lack of memory, despite having 8GB now. I > >>>>>>> created > >>>>>>>>>> https://issues.apache.org/jira/browse/INFRA-16780 for that, but > >> not > >>>>>>>> sure > >>>>>>>>>> it was > >>>>>>>>>> the reason. At least we have less issues since. > >>>>>>>>>> > >>>>>>>>>> Before (months ago) the Infra was monitoring our demos and > >> alerting > >>>>>>> us > >>>>>>>> by > >>>>>>>>>> mail (you just had to subscribe). Unfortunately we are on our own > >>>> for > >>>>>>>>> that > >>>>>>>>>> now, too much projects in the ASF... > >>>>>>>>>> As as I said initially in this thread I'm currently using > >>>>>>>> montastic.com > >>>>>>>>>> for the email alerts. > >>>>>>>>>> My idea when I started this thread was that it all depends on me, > >>>> and > >>>>>>>>>> that's bad. So I wanted people to be aware, you are much welcome. > >>>>>>>>>> > >>>>>>>>>> Jacques > >>>>>>>>>>> On Thu, Aug 23, 2018 at 2:29 PM Jacques Le Roux > >>>>>>>>>>> <[email protected]> wrote: > >>>>>>>>>>>> Yes we can, will you? > >>>>>>>>>>>> > >>>>>>>>>>>> Jacques > >>>>>>>>>>>> > >>>>>>>>>>>> > >>>>>>>>>>>> Le 22/08/2018 à 19:29, Taher Alkhateeb a écrit : > >>>>>>>>>>>>> Well, we can ask Infra for help, we can check available > >>>>>>> solutions, > >>>>>>>> we > >>>>>>>>>>>>> can create a CRON script that checks things periodically, there > >>>>>>> are > >>>>>>>>>>>>> multiple ways to go about this. > >>>>>>>>>>>>> > >>>>>>>>>>>>> My personal preference is for a simple CRON script that takes > >>>>>>> care > >>>>>>>> of > >>>>>>>>>> this. > >>>>>>>>>>>>> On Wed, Aug 22, 2018 at 8:25 PM Jacques Le Roux > >>>>>>>>>>>>> <[email protected]> wrote: > >>>>>>>>>>>>>> So you prefer that I'm the only one to take care of the demos > >>>>>>> and > >>>>>>>>> act > >>>>>>>>>> on alerts? > >>>>>>>>>>>>>> Jacques > >>>>>>>>>>>>>> > >>>>>>>>>>>>>> > >>>>>>>>>>>>>> Le 22/08/2018 à 18:53, Taher Alkhateeb a écrit : > >>>>>>>>>>>>>>> I prefer not to include any tools without proper analysis and > >>>>>>>>>>>>>>> discussion first. Less is more. > >>>>>>>>>>>>>>> On Wed, Aug 22, 2018 at 5:31 PM Jacques Le Roux > >>>>>>>>>>>>>>> <[email protected]> wrote: > >>>>>>>>>>>>>>>> Hi, > >>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>> Should I consider no answers as a lazy consensus and should > >> I > >>>>>>>> send > >>>>>>>>>> (rare) alerts to this ML? > >>>>>>>>>>>>>>>> Without any answers I'll consider it a lazy consensus in 2 > >>>>>>> days. > >>>>>>>>>>>>>>>> Jacques > >>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>> Le 17/08/2018 à 12:22, Jacques Le Roux a écrit : > >>>>>>>>>>>>>>>>> Le 13/08/2018 à 18:21, Jacques Le Roux a écrit : > >>>>>>>>>>>>>>>>>> Le 12/08/2018 à 11:26, Jacques Le Roux a écrit : > >>>>>>>>>>>>>>>>>>> Hi, > >>>>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>>> This morning I noticed the old demo was down and > >> restarted > >>>>>>> it > >>>>>>>>>> after cleaning things. > >>>>>>>>>>>>>>>>>>> Previously (still some weeks ago) Daniel Gruno's (from > >>>>>>> Infra > >>>>>>>>>> team) company was kindly providing us a mean to monitor our demos > >>>> but > >>>>>>>> it > >>>>>>>>>> seems that > >>>>>>>>>>>>>>>>>>> this mean is no longer available > >>>>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>>> I have asked about it and will let you know about it... > >>>>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>>> Have a good weekend > >>>>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>>> Jadques > >>>>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>> Daniel confirmed it's terminated. I turned to UpTimeRobot > >>>>>>>> which > >>>>>>>>>> is free and seems as well good :) > >>>>>>>>>>>>>>>>>> Jacques > >>>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>> This thread started on user ML but I don't want to bother > >>>>>>>>> everyone > >>>>>>>>>> with technical details. > >>>>>>>>>>>>>>>>> I used my own @a.o email to create the monitoring. > >>>>>>> UpTimeRobot > >>>>>>>> is > >>>>>>>>>> certainly the best free monitoring tool, with some possibilities > >>>>>>> others > >>>>>>>>>> don't give. > >>>>>>>>>>>>>>>>> But the free version has an inconvenient. You can only > >> check > >>>>>>>>> every > >>>>>>>>>> 5 mins and when the instances restart it takes more than 5 mins > >>>> each. > >>>>>>>>>>>>>>>>> So everyday I get a down an up alerts for each. I have > >>>>>>> switched > >>>>>>>>> to > >>>>>>>>>> montastic.com. > >>>>>>>>>>>>>>>>> I was wondering if we don't want to share that here. > >>>>>>>>>>>>>>>>> We could then have these alerts here and any committer, > >> using > >>>>>>>> the > >>>>>>>>>> info inhttps://svn.apache.org/repos/asf/ofbiz/tools/demo-backup > >>>>>>> could > >>>>>>>>>> handle issues. > >>>>>>>>>>>>>>>>> It seems better, isn'it? > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>> Jacques > >>>>>>>>>>>>>>>>> > >>>>>>>>>>>>>>>>> > >> >
{kind=link}