[
https://issues.apache.org/jira/browse/PARQUET-2159?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17692616#comment-17692616
]
ASF GitHub Bot commented on PARQUET-2159:
-----------------------------------------
jiangjiguang commented on code in PR #1011:
URL: https://github.com/apache/parquet-mr/pull/1011#discussion_r1115471862
##########
parquet-column/src/main/java/org/apache/parquet/column/values/bitpacking/ParquetReadRouter.java:
##########
@@ -0,0 +1,133 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+package org.apache.parquet.column.values.bitpacking;
+
+import org.apache.parquet.bytes.ByteBufferInputStream;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.EOFException;
+import java.io.IOException;
+import java.nio.ByteBuffer;
+import java.nio.charset.StandardCharsets;
+import java.nio.file.Files;
+import java.nio.file.Paths;
+import java.util.Arrays;
+import java.util.List;
+import java.util.Set;
+import java.util.stream.Collectors;
+
+/**
+ * Utility class for big data applications (such as Apache Spark and Apache
Flink).
+ * For Intel CPU, Flags containing avx512vbmi and avx512_vbmi2 can have better
performance gains.
+ */
+public class ParquetReadRouter {
+ private static final Logger LOG =
LoggerFactory.getLogger(ParquetReadRouter.class);
+
+ private static final int BITS_PER_BYTE = 8;
+
+ // register of avx512 are 512 bits, and can load up to 64 bytes
+ private static final int BYTES_PER_VECTOR_512 = 64;
+
+ // values are bit packed 8 at a time, so reading bitWidth will always work
+ private static final int NUM_VALUES_TO_PACK = 8;
+
+ private static final VectorSupport vectorSupport;
+
+ static {
+ vectorSupport = getSupportVectorFromCPUFlags();
+ }
+
+ // Dispatches to use vector when available. Directly call
readBatchUsing512Vector() if you are sure about it.
+ public static void read(int bitWidth, ByteBufferInputStream in, int
currentCount, int[] currentBuffer) throws IOException {
+ switch (vectorSupport) {
+ case VECTOR_512:
+ readBatchUsing512Vector(bitWidth, in, currentCount, currentBuffer);
+ break;
+ default:
+ readBatch(bitWidth, in, currentCount, currentBuffer);
+ }
+ }
+
+ // Call the method directly if your computer system contains avx512vbmi and
avx512_vbmi2 CPU Flags
+ public static void readBatchUsing512Vector(int bitWidth,
ByteBufferInputStream in, int currentCount, int[] currentBuffer) throws
IOException {
+ BytePacker packer = Packer.LITTLE_ENDIAN.newBytePacker(bitWidth);
+ BytePacker packerVector =
Packer.LITTLE_ENDIAN.newBytePackerVector(bitWidth);
+ int valueIndex = 0;
+ int byteIndex = 0;
+ int unpackCount = packerVector.getUnpackCount();
+ int inputByteCountPerVector = packerVector.getUnpackCount() /
BITS_PER_BYTE * bitWidth;
+ int totalByteCount = currentCount * bitWidth / BITS_PER_BYTE;
+ int totalByteCountVector = totalByteCount - BYTES_PER_VECTOR_512;
+ ByteBuffer buffer = in.slice(totalByteCount);
+ if (buffer.hasArray()) {
+ for (; byteIndex < totalByteCountVector; byteIndex +=
inputByteCountPerVector, valueIndex += unpackCount) {
+ packerVector.unpackValuesUsingVector(buffer.array(),
buffer.arrayOffset() + buffer.position() + byteIndex, currentBuffer,
valueIndex);
+ }
+ // If the remaining bytes size <= {BYTES_PER_512VECTOR}, the remaining
bytes are unpacked by packer
+ for (; byteIndex < totalByteCount; byteIndex += bitWidth, valueIndex +=
NUM_VALUES_TO_PACK) {
+ packer.unpack8Values(buffer.array(), buffer.arrayOffset() +
buffer.position() + byteIndex, currentBuffer, valueIndex);
+ }
+ } else {
+ for (; byteIndex < totalByteCountVector; byteIndex +=
inputByteCountPerVector, valueIndex += unpackCount) {
+ packerVector.unpackValuesUsingVector(buffer, buffer.position() +
byteIndex, currentBuffer, valueIndex);
+ }
+ for (; byteIndex < totalByteCount; byteIndex += bitWidth, valueIndex +=
NUM_VALUES_TO_PACK) {
+ packer.unpack8Values(buffer, buffer.position() + byteIndex,
currentBuffer, valueIndex);
+ }
+ }
+ }
+
+ // Call the method directly if your computer system doesn't contain
avx512vbmi and avx512_vbmi2 CPU Flags
+ public static void readBatch(int bitWidth, ByteBufferInputStream in, int
currentCount, int[] currentBuffer) throws EOFException {
+ BytePacker packer = Packer.LITTLE_ENDIAN.newBytePacker(bitWidth);
+ int valueIndex = 0;
+ while (valueIndex < currentCount) {
+ ByteBuffer buffer = in.slice(bitWidth);
+ packer.unpack8Values(buffer, buffer.position(), currentBuffer,
valueIndex);
+ valueIndex += NUM_VALUES_TO_PACK;
+ }
+ }
+
+ private static VectorSupport getSupportVectorFromCPUFlags() {
+ try {
+ String os = System.getProperty("os.name");
+ if (os == null || !os.toLowerCase().startsWith("linux")) {
+ return VectorSupport.NONE;
+ }
+ List<String> allLines = Files.readAllLines(Paths.get("/proc/cpuinfo"),
StandardCharsets.UTF_8);
+ for (String line : allLines) {
+ if (line != null && line.startsWith("flags")) {
+ int index = line.indexOf(":");
+ if (index < 0) {
+ continue;
+ }
+ line = line.substring(index + 1);
+ Set<String> flagsSet = Arrays.stream(line.split("
")).collect(Collectors.toSet());
+ if (flagsSet.contains("avx512vbmi") &&
flagsSet.contains("avx512_vbmi2")) {
+ return VectorSupport.VECTOR_512;
+ }
+ }
+ }
Review Comment:
@gszadovszky Even though the java vector API can check the CPU Flags(low
level check), but if users use java vector api on computer which dose not
contain avx512vbmi && avx512_vbmi2, the java vector API how to do ? throw
exception? fall back ?
Besides, the CPU Flags are becoming more and more, and Java vector api is
also increasing. maybe Java vector api dose not know which CPU Flags the users
need.
I think users should have already known their computer(including CPU
Flags). They can decide whether to enable parquet java17 vector optimization.
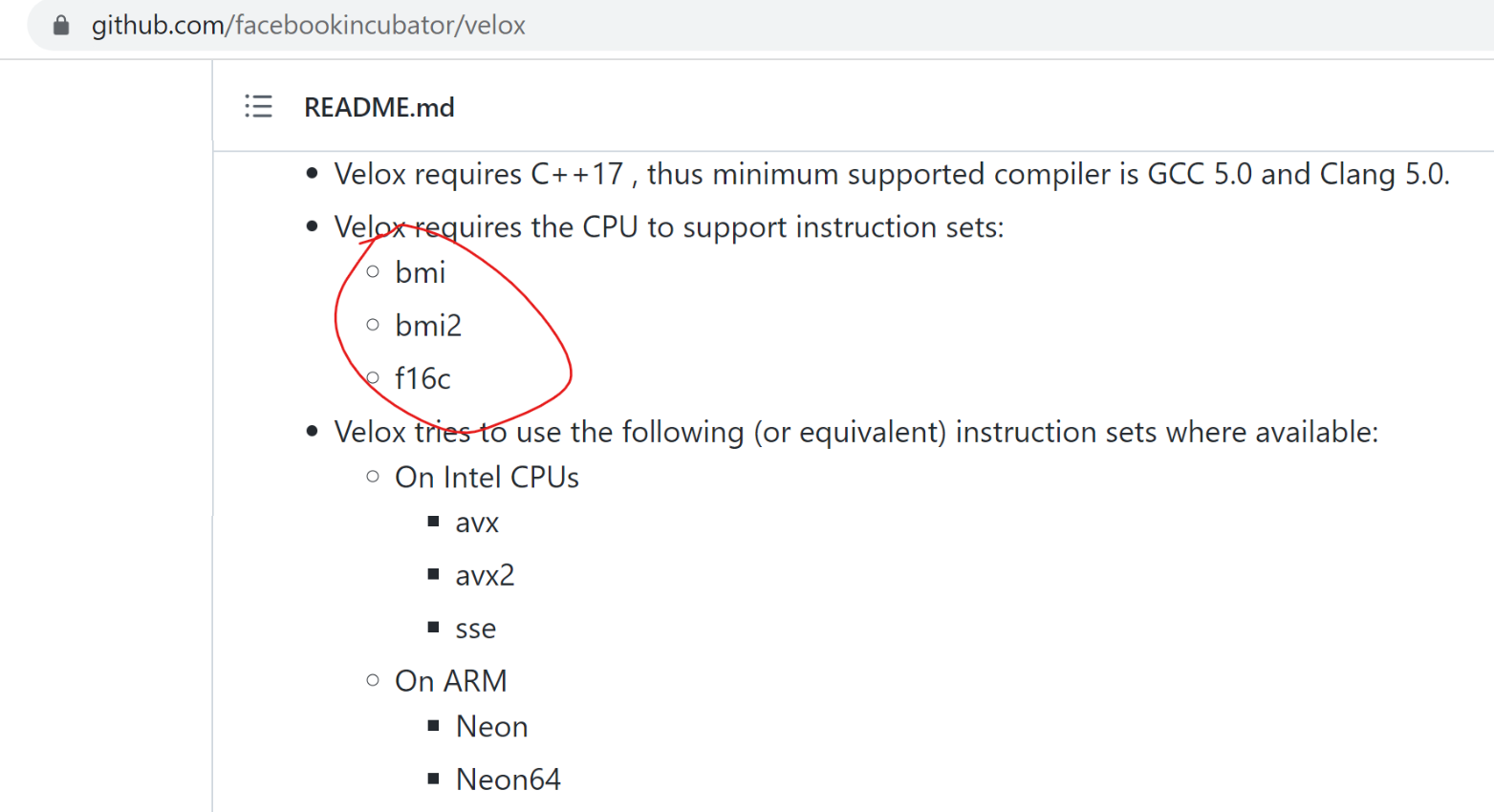
We only need show what CPU Flags needed in README.md
For example, velox(https://github.com/facebookincubator/velox) shows only
what CPU Flags needed.
> Parquet bit-packing de/encode optimization
> ------------------------------------------
>
> Key: PARQUET-2159
> URL: https://issues.apache.org/jira/browse/PARQUET-2159
> Project: Parquet
> Issue Type: Improvement
> Components: parquet-mr
> Affects Versions: 1.13.0
> Reporter: Fang-Xie
> Assignee: Fang-Xie
> Priority: Major
> Fix For: 1.13.0
>
> Attachments: image-2022-06-15-22-56-08-396.png,
> image-2022-06-15-22-57-15-964.png, image-2022-06-15-22-58-01-442.png,
> image-2022-06-15-22-58-40-704.png
>
>
> Current Spark use Parquet-mr as parquet reader/writer library, but the
> built-in bit-packing en/decode is not efficient enough.
> Our optimization for Parquet bit-packing en/decode with jdk.incubator.vector
> in Open JDK18 brings prominent performance improvement.
> Due to Vector API is added to OpenJDK since 16, So this optimization request
> JDK16 or higher.
> *Below are our test results*
> Functional test is based on open-source parquet-mr Bit-pack decoding
> function: *_public final void unpack8Values(final byte[] in, final int inPos,
> final int[] out, final int outPos)_* __
> compared with our implementation with vector API *_public final void
> unpack8Values_vec(final byte[] in, final int inPos, final int[] out, final
> int outPos)_*
> We tested 10 pairs (open source parquet bit unpacking vs ours optimized
> vectorized SIMD implementation) decode function with bit
> width=\{1,2,3,4,5,6,7,8,9,10}, below are test results:
> !image-2022-06-15-22-56-08-396.png|width=437,height=223!
> We integrated our bit-packing decode implementation into parquet-mr, tested
> the parquet batch reader ability from Spark VectorizedParquetRecordReader
> which get parquet column data by the batch way. We construct parquet file
> with different row count and column count, the column data type is Int32, the
> maximum int value is 127 which satisfies bit pack encode with bit width=7,
> the count of the row is from 10k to 100 million and the count of the column
> is from 1 to 4.
> !image-2022-06-15-22-57-15-964.png|width=453,height=229!
> !image-2022-06-15-22-58-01-442.png|width=439,height=217!
> !image-2022-06-15-22-58-40-704.png|width=415,height=208!
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
{kind=link}