lidavidm edited a comment on pull request #9656: URL: https://github.com/apache/arrow/pull/9656#issuecomment-811974394
I've tested on EC2/S3 now. In terms of Datasets, this doesn't affect scans when files <= cores, but improves performance when files > cores. It also fixes a regression compared to just using ARROW-7001 by itself. (The ARROW-11772 case in the charts is with ARROW-7001 combined with ARROW-11772.) 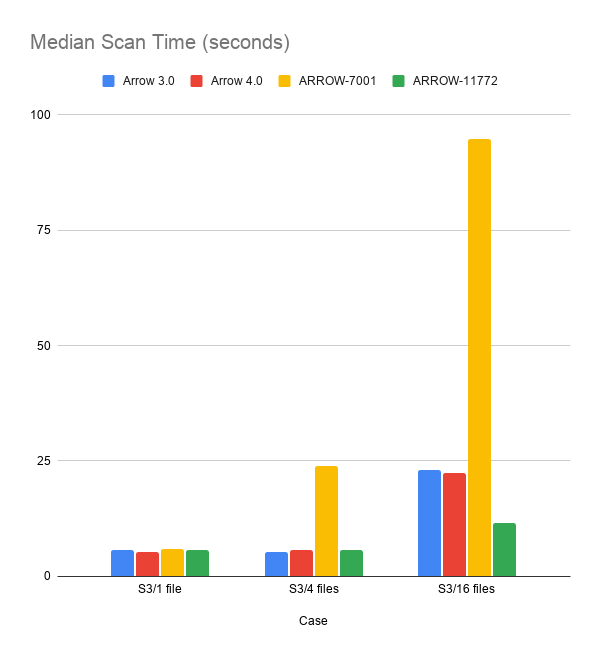 The dataset tested was a 16-file feather dataset, scanning either 1, 4, or all 16 files. Each file had 32 columns of mixed primitive types with 128 batches of 4096 rows per batch. Files had LZ4 compression. The EC2 instance tested was a t3.xlarge (4 cores). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}