[
https://issues.apache.org/jira/browse/DRILL-5975?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16258585#comment-16258585
]
Paul Rogers commented on DRILL-5975:
------------------------------------
The design proposed may work for simple queries, but it is not sufficiently
general for large queries. Let's start with some background. Here is Drill's
current design. As you point out, there are many opportunities for improvement.
But, this is what we have today.
This is an important topic, so I've taken the liberty of explaining our current
understanding in some detail.
h4. Current Model
Drill's current resource model is based on symmetry: it assumes queries arrive
randomly at each Drillbit. That is, that each user connects to a random
Foreman, that each user has similar load, and that the number of users is
larger than the number of Drillbits, so that each Foreman sees roughly equal
load.
Next, Drill assumes that users want maximum performance of each query.
Therefore, it strives for maximum parallelization across both the CPUs in each
node and all nodes in the cluster.
To do this, Drill assumes nodes are symmetrical: that all have the same number
of available CPUs and memory. Drill also assumes that Drill is the cluster is
dedicated to Drill and so Drill attempts to saturate all CPUs on all hosts.
Next, Drill assumes that all queries are fast, and so that query 1 will
complete roughly before query 2 starts. This means that resource sharing is
sequential: query 1 uses all memory and CPUs, then query 2 does so.
The above model may not be ideal, but it is the "simplest thing that could
work." It has gotten Drill this far, but it does clearly have limits.
h4. Limitations of the Current Model
Problems occur, obviously, when the real world does not agree with Drill's
assumptions. Typical problems:
* Drill does not "own" its cluster, and instead shared resources (such as CPU)
with other workloads.
* Queries are not short, and instead of running sequentially, they end up
running in parallel.
* Queries need more resources (CPU or memory) than the user has provided.
h4. CPU Overload
While our recent work focused on memory (with spilling and queue-based memory
allocation), you correctly point out that we need to turn our attention to CPU.
Let's look just a bit deep at the cause of CPU usage. Drill makes two
assumptions:
* Create as many "major fragments" (work units) as possible for each query.
(Shown as different colors in the query plan visualization UI.)
* Create as many "minor fragments" (slices) as possible for each major
fragment. (Shown as numbered items in the query plan UI tables.)
* By default, create a number of minor fragments equal to 70% of the number of
CPUs. (If your machine has 20 cores, Drill will create 14 slices per major
fragment.)
* Every minor fragment is implemented as a Java thread.
A bit of math shows why this is a problem. Assume a typical query with, say, 5
major fragments. Assume 24 CPUs. We will create a number of threads equal to:
24 CPUs * 70% * 5 major fragments = 87 threads
If all these threads were busy at the same time, we'd overload our CPUs by a
factor of 3, causing intense context switching (which pretty much defeats any
attempts to optimize for internal CPU caches.) Larger queries can easily
oversubscribe CPUs by 10 or more times.
Note that each of these threads wants to make use of unlimited memory. It does
not take too many such queries before Drill thrashes the CPU and runs out of
memory.
The lesson is that the workload exceeds the available resources, then the
"assume infinite resources" model no longer works. Some form of throttling is
needed. Let's discuss that.
Suppose that Drill can make a query faster by using all CPUs. Then, there is,
by design, no room in the cluster for another query. If we are already using
300% of CPU, then adding another query simply causes more thrashing, puts more
pressure on memory, and causes both queries to slow down. In an ideal case,
both queries will take twice as long as if they ran separately. In extreme
cases, the slow-down is sub-linear once the OS starts wasting time thrashing
threads (as shown by the percent system time in, say, the "top" command.)
In this (simplified) model, we are better off running one query to completion,
then starting the second. Both make full use of the cluster. Total run time is
the same. Plus, memory pressure is halved.
In general, some queries need all resources, but many do not. In our own
testing, we see that, with TPC-H queries, there is some advantage to running
parallel queries up to maybe three or four concurrent queries. After that, we
just see a linear slow-down. (We've pushed the system to 20, 30 or more queries
-- it is like your local freeway at rush hour; everything becomes vey slow.)
h4. Throttling
The first challenge is to accept that every cluster has limits. Once Drill
saturates CPUs, there is nothing more to give; things will just get slower. No
one likes this truth, but the physics are pretty clear.
This leads to the idea of throttling queries as a whole. To maximize query
performance, allow a limited number of queries into the system. Hold additional
queries until resources are available. The goal would be to keep CPU
utilization at some target (say 90%). Too few concurrent queries and CPU is
wasted. Too many and the CPUs are overused, leading to excessive context
switching and memory pressure.
In the end, a throttling model maximizes query throughput for a given cluster
size. (Of course, we should work to improve Drill efficiency so that each query
requires less CPU. Even so, in any given release, there is some CPU cost per
query that we must manage.)
Once one starts rationing resources (which is what throttling is), users want
some say. The Boss is more important than a worker-bee and so should move to
the head of the line. ("Per-user prioritization.") Dashboard queries should run
before batch reports. ("Application prioritization.") Marketing paid for only
1/3 of the cluster and so should only be able to use that much. ("Resource
pools.") And so on. Impala, as noted, does a pretty good job here.
h4. Minor Fragment Scheduling
The proposal in this query is to schedule at the fragment level. This seems
like a good idea, but the devil is in the details.
* Deadlock can occur if fragment A depends on B and C, but fragment C is
blocked waiting for A to complete. Good DAG dependency analysis will help here.
* Drill gets its speed from in-memory processing. Spilling data to disk between
stages simply reinvents Hive. So, while Drill should do spilling when
absolutely necessary, we wish to minimize extra disk writes.
* Drill is a big data engine: it is designed to deal with large data volumes.
Typically, insufficient memory is available to buffer the entire data set.
(Hence the need for spilling in operations such as sort.) Instead, Drill
attempts to "stream" data from data source, through the DAG, and out to the
client.
* Increased memory pressure as fragment A holds onto buffers while paused.
Ideally, fragments with large memory would have a higher priority to finish so
that they can release memory. But, they may feed into another memory-hungry
operator.
Where fragment-level throttling would be helpful is if a single query were so
large that, by itself, it would create far too many threads. In this case, it
might be a good idea to break the query into "stages" which run sequentially,
with intermediate results materialized to disk. (That is, be Hive-like for
large queries.)
h4. Open vs. Closed Loop Scheduling
Let me introduce one other concept. Impala has tried many ways to control load.
One attempt was to use a "closed-loop" controller: the Impala state store
attempted to monitor actual cluster load. Impala daemons (equivalent to a
Foreman) released queries based on this perceived load. The problems were
exactly what control theory predicts: extreme oscillation. Queries use
resources over time. Monitor load early and it looks like the cluster is idle,
so admit more queries. Eventually, all these queries need peak resources
queries are blocked. But, by now, excessive resources are in use and
out-of-memory errors occur. Queries die, load drops, and the whole cycle starts
again.
Impala moved to the classic YARN-like "open loop" design: queries are assigned
resources and must (presumably) live within that "resource budget." We wish to
learn from Impala and start with the classic open-loop, resource allocation
scheduling model.
h4. Summary
All of this is a way of suggesting that the best next step in throttling is to
implement a better query-level scheduler. Some goals:
* Better estimate query resource usage to do better resource planning. (Better
than the crude large/small model that exists today.)
* Revise each operator so that it lives within a defined memory budget. (That
is, add spilling or other techniques where needed.)
* Find a solution to schedule threads; perhaps limiting slices per major
fragment.
* Find a solution to the major-fragment count problem.
Once query-level throttling works, then we can look at opportunities to
optimize at the slice (minor-fragment) level.
> Resource utilization
> --------------------
>
> Key: DRILL-5975
> URL: https://issues.apache.org/jira/browse/DRILL-5975
> Project: Apache Drill
> Issue Type: New Feature
> Affects Versions: 2.0.0
> Reporter: weijie.tong
> Assignee: weijie.tong
>
> h1. Motivation
> Now the resource utilization radio of Drill's cluster is not too good. Most
> of the cluster resource is wasted. We can not afford too much concurrent
> queries. Once the system accepted more queries with a not high cpu load, the
> query which originally is very quick will become slower and slower.
> The reason is Drill does not supply a scheduler . It just assume all the
> nodes have enough calculation resource. Once a query comes, it will schedule
> the related fragments to random nodes not caring about the node's load. Some
> nodes will suffer more cpu context switch to satisfy the coming query. The
> profound causes to this is that the runtime minor fragments construct a
> runtime tree whose nodes spread different drillbits. The runtime tree is a
> memory pipeline that is all the nodes will stay alone the whole lifecycle of
> a query by sending out data to upper nodes successively, even though some
> node could run quickly and quit immediately.What's more the runtime tree is
> constructed before actual running. The schedule target to Drill will become
> the whole runtime tree nodes.
> h1. Design
> It will be hard to schedule the runtime tree nodes as a whole. So I try to
> solve this by breaking the runtime cascade nodes. The graph below describes
> the initial design.
> !https://raw.githubusercontent.com/wiki/weijietong/drill/images/design.png!
> [graph
> link|https://raw.githubusercontent.com/wiki/weijietong/drill/images/design.png]
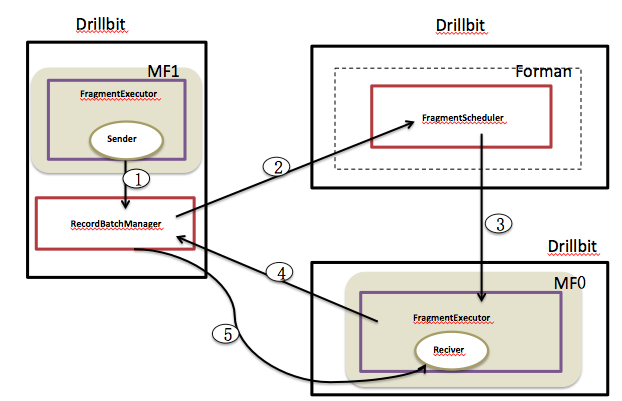
> Every Drillbit instance will have a RecordBatchManager which will accept all
> the RecordBatchs written by the senders of local different MinorFragments.
> The RecordBatchManager will hold the RecordBatchs in memory firstly then disk
> storage . Once the first RecordBatch of a MinorFragment sender of one query
> occurs , it will notice the FragmentScheduler. The FragmentScheduler is
> instanced by the Foreman.It holds the whole PlanFragment execution graph.It
> will allocate a new corresponding FragmentExecutor to run the generated
> RecordBatch. The allocated FragmentExecutor will then notify the
> corresponding FragmentManager to indicate that I am ready to receive the
> data. Then the FragmentManger will send out the RecordBatch one by one to the
> corresponding FragmentExecutor's receiver like what the current Sender does
> by throttling the data stream.
> What we can gain from this design is :
> a. The computation leaf node does not to wait for the consumer's speed to end
> its life to release the resource.
> b. The sending data logic will be isolated from the computation nodes and
> shared by different FragmentManagers.
> c. We can schedule the MajorFragments according to Drillbit's actual resource
> capacity at runtime.
> d. Drill's pipeline data processing characteristic is also retained.
> h1. Plan
> This will be a large PR ,so I plan to divide it into some small ones.
> a. to implement the RecordManager.
> b. to implement a simple random FragmentScheduler and the whole event flow.
> c. to implement a primitive FragmentScheduler which may reference the Sparrow
> project.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
{kind=link}