[
https://issues.apache.org/jira/browse/DRILL-5975?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16303987#comment-16303987
]
Paul Rogers commented on DRILL-5975:
------------------------------------
[~weijie], thanks for the additional information.
An update from our tests. We ran a TPC-H workload at various concurrencies and
scale factors. We found that we could seldom push Drill above 50% average CPU
load, though there were spikes up to 100% and down to 0%. Work is ongoing to
better understand the dynamics. It has been proposed that the workload itself
is questionable. However, the key result is that, even when Drill should be
working flat out, there may be issues that cause Drill to use less than full
CPU.
In these cases, it is not clear that better scheduling of fragments is the
answer. Instead, we want to look at what might cause waiting or
synchronization. Drill is designed to be shared-nothing, except at the network
(exchange, shuffle) layer. So, you may be right to suspect that layer. Might
there be some unintended synchronization effects when moving data across
fragments? Additional research may reveal the answer.
Thank you for the reference to the Dremel paper. The BigQuery shuffle has a
family resemblance to the [Apache
Apex|https://apex.apache.org/docs/apex/application_development/] buffer server.
(I can't find detailed notes on that component, my comment is based on a
presentation that described its operation.)
Drill does try to perform all processing in memory. Unlike most tools, Drill
does not work with records. Since Drill is columnar, it works with collections
of records called "batches." Drill receivers are obligated to buffer up to
three batches. Drill senders tend to accumulate up to 64K records before
sending. Sending in batches may improve network efficiency, but does add
latency as a sender (especially a hash sender) must accumulate enough rows to
form a send batch.
Drill held a "Developer's Day" some time back. IMHO, the outcome of that was a
sense that Drill is reaching maturity and that the time for major changes is
mostly past. Instead, there is a desire to build out the feature set and
provide incremental performance improvements. Here, that means that the
fragment, batch and exchange models are mature, and we now turn our attention
to finding and fixing specific bottlenecks. The testing I mentioned above is
driving that effort.
Your experience with a much different workload can provide valuable insight
into additional specific improvements that might be possible.
> Resource utilization
> --------------------
>
> Key: DRILL-5975
> URL: https://issues.apache.org/jira/browse/DRILL-5975
> Project: Apache Drill
> Issue Type: New Feature
> Affects Versions: 2.0.0
> Reporter: weijie.tong
> Assignee: weijie.tong
>
> h1. Motivation
> Now the resource utilization radio of Drill's cluster is not too good. Most
> of the cluster resource is wasted. We can not afford too much concurrent
> queries. Once the system accepted more queries with a not high cpu load, the
> query which originally is very quick will become slower and slower.
> The reason is Drill does not supply a scheduler . It just assume all the
> nodes have enough calculation resource. Once a query comes, it will schedule
> the related fragments to random nodes not caring about the node's load. Some
> nodes will suffer more cpu context switch to satisfy the coming query. The
> profound causes to this is that the runtime minor fragments construct a
> runtime tree whose nodes spread different drillbits. The runtime tree is a
> memory pipeline that is all the nodes will stay alone the whole lifecycle of
> a query by sending out data to upper nodes successively, even though some
> node could run quickly and quit immediately.What's more the runtime tree is
> constructed before actual running. The schedule target to Drill will become
> the whole runtime tree nodes.
> h1. Design
> It will be hard to schedule the runtime tree nodes as a whole. So I try to
> solve this by breaking the runtime cascade nodes. The graph below describes
> the initial design.
> !https://raw.githubusercontent.com/wiki/weijietong/drill/images/design.png!
> [graph
> link|https://raw.githubusercontent.com/wiki/weijietong/drill/images/design.png]
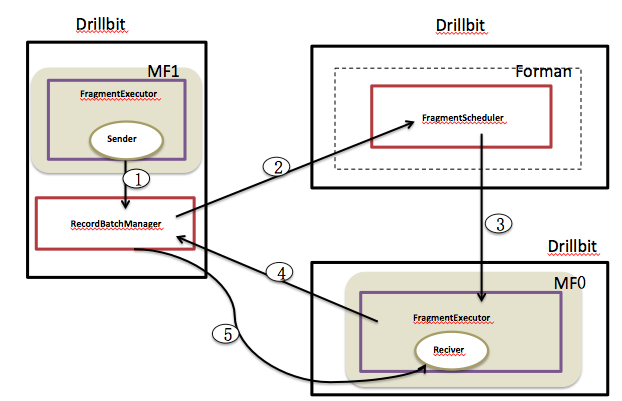
> Every Drillbit instance will have a RecordBatchManager which will accept all
> the RecordBatchs written by the senders of local different MinorFragments.
> The RecordBatchManager will hold the RecordBatchs in memory firstly then disk
> storage . Once the first RecordBatch of a MinorFragment sender of one query
> occurs , it will notice the FragmentScheduler. The FragmentScheduler is
> instanced by the Foreman.It holds the whole PlanFragment execution graph.It
> will allocate a new corresponding FragmentExecutor to run the generated
> RecordBatch. The allocated FragmentExecutor will then notify the
> corresponding FragmentManager to indicate that I am ready to receive the
> data. Then the FragmentManger will send out the RecordBatch one by one to the
> corresponding FragmentExecutor's receiver like what the current Sender does
> by throttling the data stream.
> What we can gain from this design is :
> a. The computation leaf node does not to wait for the consumer's speed to end
> its life to release the resource.
> b. The sending data logic will be isolated from the computation nodes and
> shared by different FragmentManagers.
> c. We can schedule the MajorFragments according to Drillbit's actual resource
> capacity at runtime.
> d. Drill's pipeline data processing characteristic is also retained.
> h1. Plan
> This will be a large PR ,so I plan to divide it into some small ones.
> a. to implement the RecordManager.
> b. to implement a simple random FragmentScheduler and the whole event flow.
> c. to implement a primitive FragmentScheduler which may reference the Sparrow
> project.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
{kind=link}