Hey Raul, sorry for the delay in responding.
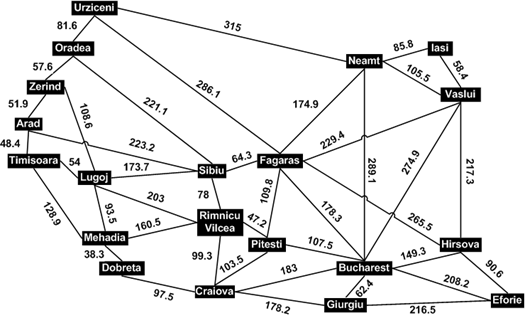
> > I'd like my A* > > program to work on arbitrary graphs, where a step from one space to > another > > can have any non-negative real length. Thus it doesn't work to simply > count > > the length of the path for the general case. > > Can you show me some examples of what this kind of data would look like? > I already provided one in the P.S. of my last message gridExtendPathWithSwampsInsteadOfHoles takes a bit matrix just like gridExtendPath, and it provides steps that don't have uniform cost. (Specifically, walking on a "0" square costs 6, while walking on a "1" costs 1.) Another, more useful application, is pathfinding in spaces where the graph being traversed has nodes placed arbitrarily (rather than regularly) in said space, and the cost is some arbitrary number greater than the euclidean distance. Pathfinding between cities on earth via the highway system is a classic example: http://lh5.ggpht.com/_W1dLiLjFqdw/Sj1dxuN9IgI/AAAAAAAAAj8/qHz2vTDgW_E/RomaniaMap_thumb%5B26%5D.png?imgmax=800 Here's that data in a more J-friendly form: cities =: 'UOZATLMDRSFPCGBHEIVN' dists =: 20 20 $ _ 81.6 _ _ _ _ _ _ _ _ 286.1 _ _ _ _ _ _ _ _ 315 81.6 _ 57.6 _ _ _ _ _ _ 221.1 _ _ _ _ _ _ _ _ _ _ _ 57.6 _ 51.9 _ 108.6 _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ 51.9 _ 48.4 _ _ _ _ 223.2 _ _ _ _ _ _ _ _ _ _ _ _ _ 48.4 _ 54 128.9 _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ 108.6 _ 54 _ 93.5 _ 203 173.7 _ _ _ _ _ _ _ _ _ _ _ _ _ _ 128.9 93.5 _ 38.3 160.5 _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ 38.3 _ _ _ _ _ 97.5 _ _ _ _ _ _ _ _ _ _ _ _ 203 160.5 _ _ 78 _ 47.2 99.3 _ _ _ _ _ _ _ _ 221.1 _ 223.2 _ 173.7 _ _ 78 _ 64.3 _ _ _ _ _ _ _ _ _ 286.1 _ _ _ _ _ _ _ _ 64.3 _ 109.8 _ _ 178.3 265.5 _ _ 229.4 174.9 _ _ _ _ _ _ _ _ 47.2 _ 109.8 _ 103.5 _ 107.5 _ _ _ _ _ _ _ _ _ _ _ _ 97.5 99.3 _ _ 103.5 _ 178.2 183 _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ 178.2 _ 62.4 _ 216.5 _ _ _ _ _ _ _ _ _ _ _ _ _ 178.3 107.5 183 62.4 _ 149.3 208.2 _ _ 289.1 _ _ _ _ _ _ _ _ _ _ 265.5 _ _ _ 149.3 _ 90.6 _ 217.3 _ _ _ _ _ _ _ _ _ _ _ _ _ _ 216.5 208.2 90.6 _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ 58.4 85.8 _ _ _ _ _ _ _ _ _ _ 229.4 _ _ _ _ 217.3 _ 58.4 _ 105.5 315 _ _ _ _ _ _ _ _ _ 174.9 _ _ _ 289.1 _ _ 85.8 105.5 _ table =: (<"0 ' ',cities) , (<"0 cities) ,"0 1 (<"0 dists) Or do you mean "cost is an expensive to calculate"? If so, I think > the right approach there would be to persist calculated scores. (If > you can't calculate the cost of your path, given the path, and the > system in which the path exists, that should mean that the cost does > not depend on the path?) > > Note also that this particular datum was a term in computing the > score, rather than being the complete score. So, thinking about it as > distance... how hard can it be to calculate distance? > > Which brings me back to thinking about caching scores. Something like > this: > > frontier=. frontier, newfrontier > scores=. scores, newscore > priority=. /: scores > frontier=. priority { frontier > scores=. priority { scores > You're suggesting that the lengths of each path be handled in a different data structure than the paths themselves, yes? That could work, but I'm not convinced it's actually cleaner than my implementation. While it's true that it makes things more homogeneous, it also introduces a new verb to calculate (real, not approximate) distances, and the need to ensure the path list and the distance list are aligned correctly. I think this may be a case of different good solutions to the same problem. If you want to restructure it like that, be my guest. It's hard to say which is better without an implementation, but I'm pretty satisfied with the one I have. ^_^ - Max ---------------------------------------------------------------------- For information about J forums see http://www.jsoftware.com/forums.htm
{kind=link}