Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/22533#discussion_r220122281
--- Diff: python/pyspark/sql/window.py ---
@@ -76,12 +79,37 @@ def partitionBy(*cols):
@staticmethod
@since(1.4)
- def orderBy(*cols):
+ def orderBy(*cols, **kwargs):
"""
Creates a :class:`WindowSpec` with the ordering defined.
+
+ :param cols: names of columns or expressions.
+ :param ascending: boolean or list of boolean (default True).
+ Sort ascending vs. descending. Specify list for multiple sort
orders.
+ If a list is specified, length of the list must equal length
of the `cols`.
+
+ >>> from pyspark.sql import functions as F, SparkSession, Window
+ >>> spark = SparkSession.builder.getOrCreate()
+ >>> df = spark.createDataFrame(
+ ... [(1, "a"), (1, "a"), (2, "a"), (1, "b"), (2, "b"), (3,
"b")], ["id", "category"])
+ >>> window = Window.orderBy("id",
ascending=False).partitionBy("category").rowsBetween(
+ ... Window.unboundedPreceding, Window.currentRow)
+ >>> df.withColumn("sum", F.sum("id").over(window)).show()
+ +---+--------+---+
+ | id|category|sum|
+ +---+--------+---+
+ | 3| b| 3|
+ | 2| b| 5|
+ | 1| b| 6|
+ | 2| a| 2|
+ | 1| a| 3|
+ | 1| a| 4|
+ +---+--------+---+
"""
sc = SparkContext._active_spark_context
- jspec =
sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(_to_java_cols(cols))
+ ascending = kwargs.get('ascending', True)
+ jspec = sc._jvm.org.apache.spark.sql.expressions.Window.orderBy(
+ _to_seq(sc, _to_sorted_java_columns(cols, ascending)))
--- End diff --
`orderBy` looks not taking `ascending` in the API documentation.
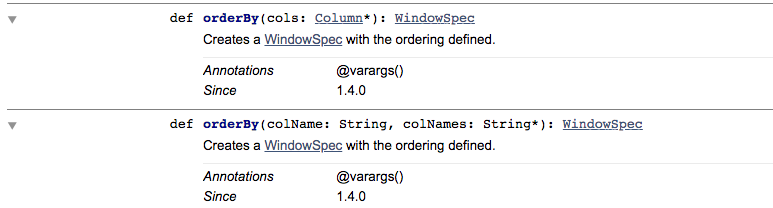
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}