Github user KyleLi1985 commented on a diff in the pull request:
https://github.com/apache/spark/pull/23126#discussion_r237505113
--- Diff:
mllib/src/main/scala/org/apache/spark/mllib/linalg/distributed/RowMatrix.scala
---
@@ -128,6 +128,69 @@ class RowMatrix @Since("1.0.0") (
RowMatrix.triuToFull(n, GU.data)
}
+ private def computeDenseVectorCovariance(mean: Vector, n: Int, m: Long):
Matrix = {
+
+ val bc = rows.context.broadcast(mean)
+
+ // Computes n*(n+1)/2, avoiding overflow in the multiplication.
+ // This succeeds when n <= 65535, which is checked above
+ val nt = if (n % 2 == 0) ((n / 2) * (n + 1)) else (n * ((n + 1) / 2))
+
+ val MU = rows.treeAggregate(new BDV[Double](nt))(
+ seqOp = (U, v) => {
+ val dv = new DenseVector(v.toArray.zip(bc.value.toArray)
--- End diff --
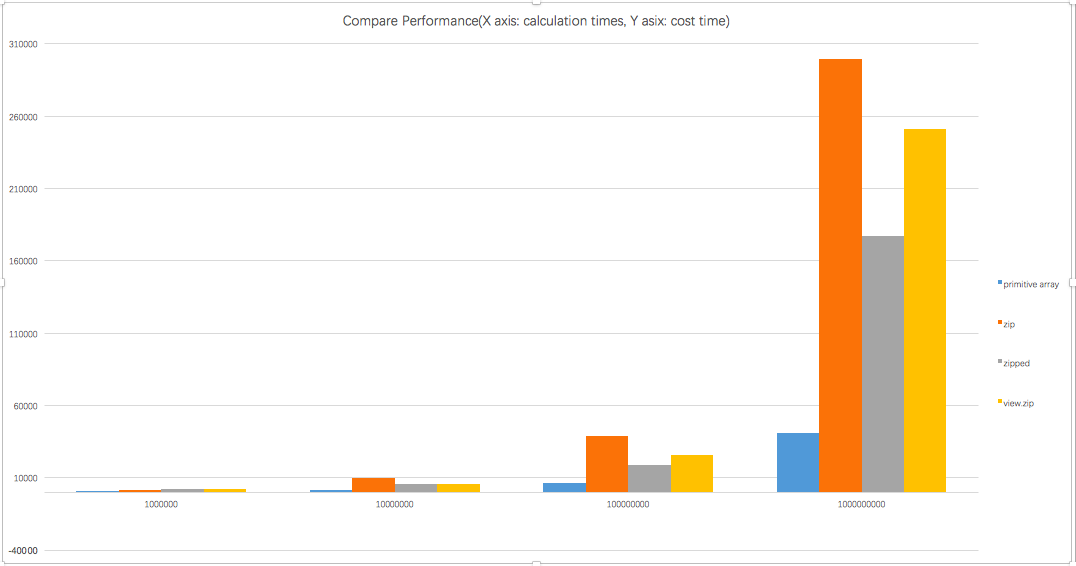
I do some more research about your mention, the primitive array is more
faster than zip, or zipped and view.zip. Because there is no more temporary
collection and extra memory copies.
I do a comparison test, below is the result
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}