[GitHub] [hudi] SteNicholas commented on a diff in pull request #8024: [MINOR] Improve RollbackToInstantTimeProcedure
SteNicholas commented on code in PR #8024:
URL: https://github.com/apache/hudi/pull/8024#discussion_r1116609526
##
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/RollbackToInstantTimeProcedure.scala:
##
@@ -38,7 +37,8 @@ class RollbackToInstantTimeProcedure extends BaseProcedure
with ProcedureBuilder
ProcedureParameter.required(1, "instant_time", DataTypes.StringType, None))
private val OUTPUT_TYPE = new StructType(Array[StructField](
-StructField("rollback_result", DataTypes.BooleanType, nullable = true,
Metadata.empty))
+StructField("rollback_result", DataTypes.BooleanType, nullable = true,
Metadata.empty),
+StructField("instant_time", DataTypes.StringType, nullable = true,
Metadata.empty))
Review Comment:
Like `rollback_to_savepoint`, the request argument of `rollback_to_instant`
has the `instant_time`, therefore the return result doesn't need the
`instant_time`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] SteNicholas commented on a diff in pull request #8024: [MINOR] Improve RollbackToInstantTimeProcedure
SteNicholas commented on code in PR #8024: URL: https://github.com/apache/hudi/pull/8024#discussion_r1116542929 ## hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/RollbackToInstantTimeProcedure.scala: ## @@ -73,10 +73,14 @@ class RollbackToInstantTimeProcedure extends BaseProcedure with ProcedureBuilder throw new HoodieException(s"Commit $instantTime not found in Commits $completedTimeline") } - val result = if (client.rollback(instantTime)) true else false - val outputRow = Row(result) + val outputRow = new util.ArrayList[Row] + val allInstants: List[HoodieInstant] = completedTimeline +.findInstantsAfterOrEquals(instantTime, Integer.MAX_VALUE).getReverseOrderedInstants.toArray() +.map(r => r.asInstanceOf[HoodieInstant]).toList - Seq(outputRow) + allInstants.foreach(p => outputRow.add(Row(client.rollback(p.getTimestamp), p.getTimestamp))) Review Comment: Like `rollback_to_savepoint`, the request argument of `rollback_to_instant` has the `instant_time`, therefore the return result doesn't need the `instant_time`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7987: [HUDI-5514] Record Keys Auto-gen Prototype
hudi-bot commented on PR #7987: URL: https://github.com/apache/hudi/pull/7987#issuecomment-1442932367 ## CI report: * 70aa11e1869b46f7d97fc45de15abbad712868a5 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15355) * 5cfa69e4c1c487e5cedb4f8d7d3a4c7334cfe266 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15380) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7847: [HUDI-5697] Revisiting refreshing of Hudi relations after write operations on the tables
hudi-bot commented on PR #7847: URL: https://github.com/apache/hudi/pull/7847#issuecomment-1442930988 ## CI report: * 0241dc20d80d9f8d5fee38637ba1c3b5277ed55f Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15369) * 24f50e8f624dd2b928cf1c6c4ca7db8b84c760fd Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15379) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7987: [HUDI-5514] Record Keys Auto-gen Prototype
hudi-bot commented on PR #7987: URL: https://github.com/apache/hudi/pull/7987#issuecomment-1442908809 ## CI report: * 70aa11e1869b46f7d97fc45de15abbad712868a5 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15355) * 5cfa69e4c1c487e5cedb4f8d7d3a4c7334cfe266 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7847: [HUDI-5697] Revisiting refreshing of Hudi relations after write operations on the tables
hudi-bot commented on PR #7847: URL: https://github.com/apache/hudi/pull/7847#issuecomment-1442908327 ## CI report: * 0241dc20d80d9f8d5fee38637ba1c3b5277ed55f Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15369) * 24f50e8f624dd2b928cf1c6c4ca7db8b84c760fd UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7951: [HUDI-5796] Adding auto inferring partition from incoming df
hudi-bot commented on PR #7951: URL: https://github.com/apache/hudi/pull/7951#issuecomment-1442900932 ## CI report: * cbb0a8c7b89b90b134b7ad41442cfaf59b3654a5 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15371) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao commented on issue #8020: [SUPPORT] org.apache.avro.AvroTypeException: Cannot encode decimal with precision 4 as max precision 2
xiarixiaoyao commented on issue #8020: URL: https://github.com/apache/hudi/issues/8020#issuecomment-1442900569 @simonjobs Which version of hudi do you use, i run the test on the master branch -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] koochiswathiTR commented on issue #8025: Found commits after time :20230220161017756, please rollback greater commits first
koochiswathiTR commented on issue #8025: URL: https://github.com/apache/hudi/issues/8025#issuecomment-1442893835 @danny0405 We are not using multi writer, Its only single writer. What is lazy cleaning can you brief on this? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] alexeykudinkin commented on a diff in pull request #7847: [HUDI-5697] Revisiting refreshing of Hudi relations after write operations on the tables
alexeykudinkin commented on code in PR #7847:
URL: https://github.com/apache/hudi/pull/7847#discussion_r1116571566
##
hudi-client/hudi-spark-client/src/main/scala/org/apache/spark/sql/HoodieCatalogUtils.scala:
##
@@ -17,8 +17,76 @@
package org.apache.spark.sql
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.catalyst.{QualifiedTableName, TableIdentifier}
+
/**
* NOTE: Since support for [[TableCatalog]] was only added in Spark 3, this
trait
* is going to be an empty one simply serving as a placeholder (for
compatibility w/ Spark 2)
*/
trait HoodieCatalogUtils {}
+
+object HoodieCatalogUtils {
+
+ /**
+ * Please check scala-doc for other overloaded [[refreshTable()]] operation
+ */
+ def refreshTable(spark: SparkSession, qualifiedTableName: String): Unit = {
+val tableId =
spark.sessionState.sqlParser.parseTableIdentifier(qualifiedTableName)
+refreshTable(spark, tableId)
+ }
+
+ /**
+ * Refreshes metadata and flushes cached data (resolved [[LogicalPlan]]
representation,
+ * already loaded [[InMemoryRelation]]) for the table identified by
[[tableId]].
+ *
+ * This method is usually invoked at the ond of the write operation to make
sure cached
+ * data/metadata are synchronized with the state on storage.
+ *
+ * NOTE: PLEASE READ CAREFULLY BEFORE CHANGING
+ * This is borrowed from Spark 3.1.3 and modified to satisfy Hudi
needs:
Review Comment:
Great question!
This seems to be the PR that changed it:
https://github.com/apache/spark/pull/31206
I don't see any particular rationale for changing the part that triggers
`relation.refresh()`. I guess the reason why Spark's core doesn't really care
too much about it is simply b/c after listing of the (parquet) table, for ex,
they simply create `InMemoryFileIndex` that is passed into `HadoopFsRelation`
in that case you'd not notice the refresh as it actually just happens in memory.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] codope commented on a diff in pull request #7847: [HUDI-5697] Revisiting refreshing of Hudi relations after write operations on the tables
codope commented on code in PR #7847:
URL: https://github.com/apache/hudi/pull/7847#discussion_r1116550390
##
hudi-client/hudi-spark-client/src/main/scala/org/apache/spark/sql/HoodieCatalogUtils.scala:
##
@@ -17,8 +17,76 @@
package org.apache.spark.sql
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.catalyst.{QualifiedTableName, TableIdentifier}
+
/**
* NOTE: Since support for [[TableCatalog]] was only added in Spark 3, this
trait
* is going to be an empty one simply serving as a placeholder (for
compatibility w/ Spark 2)
*/
trait HoodieCatalogUtils {}
+
+object HoodieCatalogUtils {
+
+ /**
+ * Please check scala-doc for other overloaded [[refreshTable()]] operation
+ */
+ def refreshTable(spark: SparkSession, qualifiedTableName: String): Unit = {
+val tableId =
spark.sessionState.sqlParser.parseTableIdentifier(qualifiedTableName)
+refreshTable(spark, tableId)
+ }
+
+ /**
+ * Refreshes metadata and flushes cached data (resolved [[LogicalPlan]]
representation,
+ * already loaded [[InMemoryRelation]]) for the table identified by
[[tableId]].
+ *
+ * This method is usually invoked at the ond of the write operation to make
sure cached
Review Comment:
```suggestion
* This method is usually invoked at the end of the write operation to
make sure cached
```
##
hudi-client/hudi-spark-client/src/main/scala/org/apache/spark/sql/HoodieCatalogUtils.scala:
##
@@ -17,8 +17,76 @@
package org.apache.spark.sql
+import org.apache.spark.sql.catalyst.catalog.CatalogTableType
+import org.apache.spark.sql.catalyst.{QualifiedTableName, TableIdentifier}
+
/**
* NOTE: Since support for [[TableCatalog]] was only added in Spark 3, this
trait
* is going to be an empty one simply serving as a placeholder (for
compatibility w/ Spark 2)
*/
trait HoodieCatalogUtils {}
+
+object HoodieCatalogUtils {
+
+ /**
+ * Please check scala-doc for other overloaded [[refreshTable()]] operation
+ */
+ def refreshTable(spark: SparkSession, qualifiedTableName: String): Unit = {
+val tableId =
spark.sessionState.sqlParser.parseTableIdentifier(qualifiedTableName)
+refreshTable(spark, tableId)
+ }
+
+ /**
+ * Refreshes metadata and flushes cached data (resolved [[LogicalPlan]]
representation,
+ * already loaded [[InMemoryRelation]]) for the table identified by
[[tableId]].
+ *
+ * This method is usually invoked at the ond of the write operation to make
sure cached
+ * data/metadata are synchronized with the state on storage.
+ *
+ * NOTE: PLEASE READ CAREFULLY BEFORE CHANGING
+ * This is borrowed from Spark 3.1.3 and modified to satisfy Hudi
needs:
Review Comment:
I am wondering what prompted Spark to change the behavior in version 3.2?
IMO, whatever Spark 3.1.3 was doing is more reasonable. What do we lose by not
sticking to 3.2 behavior?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8027: [HUDI-5838] Mask sensitive info while printing hudi properties in DeltaStreamer
hudi-bot commented on PR #8027: URL: https://github.com/apache/hudi/pull/8027#issuecomment-1442864516 ## CI report: * cbaa69ce341917be6f6549a27328a9019b5cfae2 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15362) * 10e71ac0feb93693f00ea82dabe07d0807cd1e8a Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15378) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope commented on a diff in pull request #8027: [HUDI-5838] Mask sensitive info while printing hudi properties in DeltaStreamer
codope commented on code in PR #8027:
URL: https://github.com/apache/hudi/pull/8027#discussion_r1116542520
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java:
##
@@ -620,6 +620,12 @@ public class HoodieWriteConfig extends HoodieConfig {
.withDocumentation("Whether to enable commit conflict checking or not
during early "
+ "conflict detection.");
+ public static final ConfigProperty SENSITIVE_CONFIG_KEYS_FILTER =
ConfigProperty
+ .key("hoodie.sensitive.config.keys")
+ .defaultValue("ssl,tls,sasl,auth,credentials")
+ .withDocumentation("Comma separated list of filters for sensitive config
keys. Delta Streamer "
+ + "avoids printing any configurations which contains the configured
filter.");
Review Comment:
Instead of saying `avoids`, be more explicit and say `... will not print any
configuration...`.
Also, you could add an example.
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/deltastreamer/HoodieDeltaStreamer.java:
##
@@ -528,7 +533,10 @@ public String toString() {
}
}
- private static String toSortedTruncatedString(TypedProperties props) {
+ static String toSortedTruncatedString(TypedProperties props) {
+List sensitiveConfigList =
props.getStringList(HoodieWriteConfig.SENSITIVE_CONFIG_KEYS_FILTER.key(),
Review Comment:
Why can't it be a Set? Not that it matters for few handful of elements, but
Set feels more intuitive.
##
hudi-utilities/src/test/java/org/apache/hudi/utilities/deltastreamer/TestHoodieDeltaStreamer.java:
##
@@ -2319,6 +2319,22 @@ public void testDeletePartitions() throws Exception {
TestHelpers.assertNoPartitionMatch(tableBasePath, sqlContext,
HoodieTestDataGenerator.DEFAULT_FIRST_PARTITION_PATH);
}
+ @Test
+ public void testToSortedTruncatedStringSecretsMasked() {
+TypedProperties props =
+new DFSPropertiesConfiguration(fs.getConf(), new Path(basePath + "/" +
PROPS_FILENAME_TEST_SOURCE)).getProps();
+props.put("ssl.trustore.location", "SSL SECRET KEY");
+props.put("sasl.jaas.config", "SASL SECRET KEY");
+props.put("auth.credentials", "AUTH CREDENTIALS");
+props.put("auth.user.info", "AUTH USER INFO");
+
+String truncatedKeys = HoodieDeltaStreamer.toSortedTruncatedString(props);
+assertFalse(truncatedKeys.contains("SSL SECRET KEY"));
Review Comment:
Shouldn't the assertion be that truncatedKeys contains
`SENSITIVE_INFO_MASKED`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8027: [HUDI-5838] Mask sensitive info while printing hudi properties in DeltaStreamer
hudi-bot commented on PR #8027: URL: https://github.com/apache/hudi/pull/8027#issuecomment-1442860303 ## CI report: * cbaa69ce341917be6f6549a27328a9019b5cfae2 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15362) * 10e71ac0feb93693f00ea82dabe07d0807cd1e8a UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] SteNicholas commented on a diff in pull request #8024: [MINOR] Improve RollbackToInstantTimeProcedure
SteNicholas commented on code in PR #8024: URL: https://github.com/apache/hudi/pull/8024#discussion_r1116542929 ## hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/RollbackToInstantTimeProcedure.scala: ## @@ -73,10 +73,14 @@ class RollbackToInstantTimeProcedure extends BaseProcedure with ProcedureBuilder throw new HoodieException(s"Commit $instantTime not found in Commits $completedTimeline") } - val result = if (client.rollback(instantTime)) true else false - val outputRow = Row(result) + val outputRow = new util.ArrayList[Row] + val allInstants: List[HoodieInstant] = completedTimeline +.findInstantsAfterOrEquals(instantTime, Integer.MAX_VALUE).getReverseOrderedInstants.toArray() +.map(r => r.asInstanceOf[HoodieInstant]).toList - Seq(outputRow) + allInstants.foreach(p => outputRow.add(Row(client.rollback(p.getTimestamp), p.getTimestamp))) Review Comment: The request argument of `rollback_to_instant` has the `instant_time`, therefore the return result doesn't need the `instant_time`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7962: [HUDI-5801] Speed metaTable initializeFileGroups
hudi-bot commented on PR #7962: URL: https://github.com/apache/hudi/pull/7962#issuecomment-1442825587 ## CI report: * a3c0dc7bddb55332966676136a55d9cd59dd6bb6 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15374) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] huangxiaopingRD opened a new issue, #8036: [SUPPORT] Migration of hudi tables encountered issue related to metadata column
huangxiaopingRD opened a new issue, #8036: URL: https://github.com/apache/hudi/issues/8036 **Describe the problem you faced** We have a workflow that is `hive table (upstream) -> hive table (downstream)`, and we want to modify it to `hudi table-upstream) -> hive table (downstream)`. However, there is a problem. For example, the downstream may use a SQL similar to "`insert into hive_table select * from hudi_table`". At this time, the number of read data columns and the number of columns to be inserted into the table will be inconsistent. The reason is that the metadata column of Hudi is added after the expansion of star(*). Our initial solution now is to add a rule to spark. When processing the execution plan, if it is the hudi metadata column added after star expansion, delete it and return the execution plan without the metadata column. I wonder if the hudi community has a better solution for such a case. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar merged pull request #8005: [HUDI-5825] disable Spark UI in tests if SPARK_EVLOG_DIR not set
bvaradar merged PR #8005: URL: https://github.com/apache/hudi/pull/8005 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated: [HUDI-5825] disable Spark UI in tests if SPARK_EVLOG_DIR not set (#8005)
This is an automated email from the ASF dual-hosted git repository.
vbalaji pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new 265aac89584 [HUDI-5825] disable Spark UI in tests if SPARK_EVLOG_DIR
not set (#8005)
265aac89584 is described below
commit 265aac895840ffc97d7a73d65024c0c68e4aa6d0
Author: kazdy
AuthorDate: Fri Feb 24 05:51:07 2023 +0100
[HUDI-5825] disable Spark UI in tests if SPARK_EVLOG_DIR not set (#8005)
---
.../src/test/java/org/apache/hudi/testutils/HoodieClientTestUtils.java | 3 +++
1 file changed, 3 insertions(+)
diff --git
a/hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/testutils/HoodieClientTestUtils.java
b/hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/testutils/HoodieClientTestUtils.java
index 09447965b2c..842c37449d5 100644
---
a/hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/testutils/HoodieClientTestUtils.java
+++
b/hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/testutils/HoodieClientTestUtils.java
@@ -116,6 +116,9 @@ public class HoodieClientTestUtils {
if (evlogDir != null) {
sparkConf.set("spark.eventLog.enabled", "true");
sparkConf.set("spark.eventLog.dir", evlogDir);
+ sparkConf.set("spark.ui.enabled", "true");
+} else {
+ sparkConf.set("spark.ui.enabled", "false");
}
return SparkRDDReadClient.addHoodieSupport(sparkConf);
[GitHub] [hudi] bvaradar closed pull request #6456: [HUDI-4674]Change the default value of inputFormat for the MOR table
bvaradar closed pull request #6456: [HUDI-4674]Change the default value of inputFormat for the MOR table URL: https://github.com/apache/hudi/pull/6456 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] stayrascal commented on pull request #8029: [HUDI-5832] add relocated prefix for hbase classes in hbase-site.xml
stayrascal commented on PR #8029: URL: https://github.com/apache/hudi/pull/8029#issuecomment-1442801528 @danny0405 Thanks for review this. I give more context here. I meet a problem about ClassNotFound exception `org.apache.hadoop.hbase.master.ClusterStatusPublisher$MulticastPublisher` during loading flink-hbase-connector and hudi-flink-bundle. Because we package `hbase-site.xml` in the bundle jar, and the value of `hbase.status.publisher.class` is `org.apache.hadoop.hbase.master.ClusterStatusPublisher$MulticastPublisher`, but it `hudi-flink-bundle`, the class location is `org/apache/hudi/org/apache/hadoop/hbase/master/ClusterStatusPublisher$MulticastPublisher`. During open Hbase connection and write data to Hbase, the application will load the `hbase-site.xml` of `hudi-flink-bundle` jar, and latter try to initialise the class of `hbase.status.publisher.class` property, and then meet ClassNotFound problem. So I'm thinking all configured classes properties should start with relocated prefix `org.apapche.hudi`. @yihua could you please help to double check if it's reasonable? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7901: [HUDI-5665] Adding support to re-use table configs
hudi-bot commented on PR #7901: URL: https://github.com/apache/hudi/pull/7901#issuecomment-1442790708 ## CI report: * 0ee4a7ebbf09c02b2bd81c425f4656e783f815c7 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15373) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7804: [HUDI-915][HUDI-5656] Rebased `HoodieBootstrapRelation` onto `HoodieBaseRelation`
hudi-bot commented on PR #7804: URL: https://github.com/apache/hudi/pull/7804#issuecomment-1442786346 ## CI report: * f18bb659d5887dff772f261ed1d01e11992a551f Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15216) * 96daf49ab19a803bfe8ce25f1fc9945f685db473 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15376) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8032: [HUDI-5845] Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields.
hudi-bot commented on PR #8032: URL: https://github.com/apache/hudi/pull/8032#issuecomment-1442782485 ## CI report: * c303fc268b71faf519eaabe8d686d1c167b99d17 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15372) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7804: [HUDI-915][HUDI-5656] Rebased `HoodieBootstrapRelation` onto `HoodieBaseRelation`
hudi-bot commented on PR #7804: URL: https://github.com/apache/hudi/pull/7804#issuecomment-1442781983 ## CI report: * f18bb659d5887dff772f261ed1d01e11992a551f Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15216) * 96daf49ab19a803bfe8ce25f1fc9945f685db473 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #7978: [HUDI-5812] Optimize the data size check in HoodieBaseParquetWriter
danny0405 commented on code in PR #7978:
URL: https://github.com/apache/hudi/pull/7978#discussion_r1116479337
##
hudi-common/src/main/java/org/apache/hudi/io/storage/HoodieParquetConfig.java:
##
@@ -78,4 +83,12 @@ public T getWriteSupport() {
public boolean dictionaryEnabled() {
return dictionaryEnabled;
}
+
+ public long getMinRowCountForSizeCheck() {
+return minRowCountForSizeCheck;
Review Comment:
How the user config these options, seems we only use the default value, if
that is the case, I would suggest we hard code the options in
`HoodieBaseParquetWriter`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao commented on a diff in pull request #8024: [MINOR] Improve RollbackToInstantTimeProcedure
xiarixiaoyao commented on code in PR #8024: URL: https://github.com/apache/hudi/pull/8024#discussion_r1116474823 ## hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/RollbackToInstantTimeProcedure.scala: ## @@ -73,10 +73,14 @@ class RollbackToInstantTimeProcedure extends BaseProcedure with ProcedureBuilder throw new HoodieException(s"Commit $instantTime not found in Commits $completedTimeline") } - val result = if (client.rollback(instantTime)) true else false - val outputRow = Row(result) + val outputRow = new util.ArrayList[Row] + val allInstants: List[HoodieInstant] = completedTimeline +.findInstantsAfterOrEquals(instantTime, Integer.MAX_VALUE).getReverseOrderedInstants.toArray() +.map(r => r.asInstanceOf[HoodieInstant]).toList - Seq(outputRow) + allInstants.foreach(p => outputRow.add(Row(client.rollback(p.getTimestamp), p.getTimestamp))) Review Comment: why we need outputRow, how about return allInstants.map(p => Row(client.rollback(p.getTimestamp), p.getTimestamp)) directly -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-5842) Json to Dataset conversion might be broken for some cases
[
https://issues.apache.org/jira/browse/HUDI-5842?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jonathan Vexler updated HUDI-5842:
--
Summary: Json to Dataset conversion might be broken for some cases
(was: Json to Dataset conversion might be broken)
> Json to Dataset conversion might be broken for some cases
> --
>
> Key: HUDI-5842
> URL: https://issues.apache.org/jira/browse/HUDI-5842
> Project: Apache Hudi
> Issue Type: Bug
> Components: deltastreamer
>Reporter: Jonathan Vexler
>Priority: Major
>
> In TestJsonKafkaSource If you try to do more than just count the number of
> records you get a null pointer exception.
> [https://github.com/apache/hudi/blob/812950bc9ead4c28763b907dc5a1840162f35337/hudi-utilities/src/test/java/org/apache/hudi/utilities/sources/TestJsonKafkaSource.java]
> is a permalink to show what schema it fails on because I am updating the
> tests to use a different schema for now. You can trigger the exception by
> adding
> {code:java}
>for (Row r : fetch2.getBatch().get().collectAsList()) {
> for (StructField f : r.schema().fields()) {
> System.out.println(f.name() + ":" + r.get(r.fieldIndex(f.name(;
> }
> } {code}
> to the end of TestJsonKafkaSource.testJsonKafkaSourceWithDefaultUpperCap
> (using the schema from the permalink)
> The exception is
> {code:java}
> java.lang.NullPointerException
> at
> org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificSafeProjection.createExternalRow_0_0$(Unknown
> Source)
> at
> org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificSafeProjection.apply(Unknown
> Source)
> at
> org.apache.spark.sql.Dataset$$anonfun$org$apache$spark$sql$Dataset$$collectFromPlan$1.apply(Dataset.scala:3391)
> at
> org.apache.spark.sql.Dataset$$anonfun$org$apache$spark$sql$Dataset$$collectFromPlan$1.apply(Dataset.scala:3388)
> at
> scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
> at
> scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
> at
> scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
> at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
> at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
> at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:186)
> at
> org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collectFromPlan(Dataset.scala:3388)
> at
> org.apache.spark.sql.Dataset$$anonfun$collectAsList$1.apply(Dataset.scala:2800)
> at
> org.apache.spark.sql.Dataset$$anonfun$collectAsList$1.apply(Dataset.scala:2799)
> at org.apache.spark.sql.Dataset$$anonfun$53.apply(Dataset.scala:3369)
> at
> org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:80)
> at
> org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:127)
> at
> org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:75)
> at
> org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$withAction(Dataset.scala:3368)
> at org.apache.spark.sql.Dataset.collectAsList(Dataset.scala:2799)
> at
> org.apache.hudi.utilities.sources.TestJsonKafkaSource.testJsonKafkaSourceWithDefaultUpperCap(TestJsonKafkaSource.java:128)
> at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
> at
> sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
> at
> sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
> at java.lang.reflect.Method.invoke(Method.java:498)
> at
> org.junit.platform.commons.util.ReflectionUtils.invokeMethod(ReflectionUtils.java:688)
> at
> org.junit.jupiter.engine.execution.MethodInvocation.proceed(MethodInvocation.java:60)
> at
> org.junit.jupiter.engine.execution.InvocationInterceptorChain$ValidatingInvocation.proceed(InvocationInterceptorChain.java:131)
> at
> org.junit.jupiter.engine.extension.TimeoutExtension.intercept(TimeoutExtension.java:149)
> at
> org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestableMethod(TimeoutExtension.java:140)
> at
> org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestMethod(TimeoutExtension.java:84)
> at
> org.junit.jupiter.engine.execution.ExecutableInvoker$ReflectiveInterceptorCall.lambda$ofVoidMethod$0(ExecutableInvoker.java:115)
> at
> org.junit.jupiter.engine.execution.ExecutableInvoker.lambda$invoke$0(ExecutableInvoker.java:105)
> at
> org.junit.jupiter.engine.execution.InvocationInterceptorChain$InterceptedInvocation.proceed(InvocationInterceptorChain.java:106)
> at
> org.junit.jupiter.engine.ex
[GitHub] [hudi] nsivabalan commented on pull request #7948: [HUDI-5794] Failing new commits on any pending restore commits
nsivabalan commented on PR #7948: URL: https://github.com/apache/hudi/pull/7948#issuecomment-1442719726 CI is green https://user-images.githubusercontent.com/513218/221079206-ec0c571f-2ce9-4338-ba36-7354902e3cb3.png";> -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bithw1 commented on issue #7994: [SUPPORT]How to get back the historic commit time information in my scenario
bithw1 commented on issue #7994: URL: https://github.com/apache/hudi/issues/7994#issuecomment-1442718112 如问题描述,我用四个dataset做了四次更新,一个四个record key,A~D,最后一次,我把ABCD全部更新了一遍,完了之后通过select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime,只能查到一个commit time,就是最后一个commit time。 我要做历史commit的as of instance查询,首先我需要知道我有哪些commit time,但是我现在只能获取一个,所以我想请问下,除了使用select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime获取表的commitTime,还有其他方式吗? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao commented on issue #8020: [SUPPORT] org.apache.avro.AvroTypeException: Cannot encode decimal with precision 4 as max precision 2
xiarixiaoyao commented on issue #8020: URL: https://github.com/apache/hudi/issues/8020#issuecomment-1442717948 @kazdy Thank you for your participation, let me check the code of iceberg -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao commented on a diff in pull request #8026: [HUDI-5835] After performing the update operation, the hoodie table cannot be read normally by spark
xiarixiaoyao commented on code in PR #8026:
URL: https://github.com/apache/hudi/pull/8026#discussion_r1116443597
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/HoodieBaseRelation.scala:
##
@@ -155,12 +158,13 @@ abstract class HoodieBaseRelation(val sqlContext:
SQLContext,
}
}
+val avroNameAndSpace =
AvroConversionUtils.getAvroRecordNameAndNamespace(tableName)
val avroSchema = internalSchemaOpt.map { is =>
- AvroInternalSchemaConverter.convert(is, "schema")
+ AvroInternalSchemaConverter.convert(is, avroNameAndSpace._2 + "." +
avroNameAndSpace._1)
Review Comment:
@danny0405
I checked the code of Flink, and there was no problem with Flink, since
schema evolution will call HoodieAvroUtils.rewriteRecordWithNewSchema to uinfy
namespace.
by the way, This pr problem has nothing to do with this modification ,i
change this line just want to ensure that the namespace of reading schema and
writing schema are consistent from spark side.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] bithw1 commented on issue #7994: [SUPPORT]How to get back the historic commit time information in my scenario
bithw1 commented on issue #7994:
URL: https://github.com/apache/hudi/issues/7994#issuecomment-1442713934
> Specify the end query time point is how we get the history records, as
long as the instant is still alive in the timeline.
In my scenario as described in the question area, I updated **all** the
records in the last commit, then I can't get back the historic commits time, so
that I can't do point in time query like the following because I don't know how
to get back the historical commit times (`select distinct _hoodie_commit_time
from mytable` won't work in my scenario, this is my question here)
```
Seq("", "").foreach(point_in_time => {
val df = spark.read.
format("hudi").
option("as.of.instant", point_in_time).
load(base_path)
df.show()
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on pull request #8029: [HUDI-5832] add relocated prefix for hbase classes in hbase-site.xml
danny0405 commented on PR #8029: URL: https://github.com/apache/hudi/pull/8029#issuecomment-1442713257 Thanks for contribution, can we elaborate a little the details? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #8018: [SUPPORT] why is the schema evolution done while not setting hoodie.schema.on.read.enable
danny0405 commented on issue #8018: URL: https://github.com/apache/hudi/issues/8018#issuecomment-1442711148 There is another option for the writer.  Maybe that is what you need. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua opened a new pull request, #8035: [WIP] Add a MOR table validation tool
yihua opened a new pull request, #8035: URL: https://github.com/apache/hudi/pull/8035 ### Change Logs _Describe context and summary for this change. Highlight if any code was copied._ ### Impact _Describe any public API or user-facing feature change or any performance impact._ ### Risk level (write none, low medium or high below) _If medium or high, explain what verification was done to mitigate the risks._ ### Documentation Update _Describe any necessary documentation update if there is any new feature, config, or user-facing change_ - _The config description must be updated if new configs are added or the default value of the configs are changed_ - _Any new feature or user-facing change requires updating the Hudi website. Please create a Jira ticket, attach the ticket number here and follow the [instruction](https://hudi.apache.org/contribute/developer-setup#website) to make changes to the website._ ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xiarixiaoyao commented on a diff in pull request #8026: [HUDI-5835] After performing the update operation, the hoodie table cannot be read normally by spark
xiarixiaoyao commented on code in PR #8026:
URL: https://github.com/apache/hudi/pull/8026#discussion_r1116437743
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/HoodieBaseRelation.scala:
##
@@ -155,12 +158,13 @@ abstract class HoodieBaseRelation(val sqlContext:
SQLContext,
}
}
+val avroNameAndSpace =
AvroConversionUtils.getAvroRecordNameAndNamespace(tableName)
val avroSchema = internalSchemaOpt.map { is =>
- AvroInternalSchemaConverter.convert(is, "schema")
+ AvroInternalSchemaConverter.convert(is, avroNameAndSpace._2 + "." +
avroNameAndSpace._1)
Review Comment:
@alexeykudinkin thanks for your review.
1) schema evolution has nothing to do with this scene,since schema
evolution will call HoodieAvroUtils.rewriteRecordWithNewSchema to uinfy
namespace.i change this line just want to ensure that the namespace of
reading schema and writing schema are consistent.
2) The namespace of the schema used by hudi when writing the log is from
tableName, but the namespace of read schema is “schema"
3) When the schema evolution is not enabled,For decimal types, different
namespaces produce different names, avro is name sensitive. we should keep
the read schema and write schema has the same namespace just as previous
versions of hudi
eg:
ff decimal(38, 10)
hudi log write schema will be :
{"name":"ff","type":[{"type":"fixed","name":"fixed","namespace":"hoodie.h0.h0_record.ff","size":16,"logicalType":"decimal","precision":38,"scale":10}
spark read schema will be
ff type is :
"name":"ff","type":[{"type":"fixed","name":"fixed","namespace":"Record.ff","size":16,"logicalType":"decimal","precision":38,"scale":10},"null"]}
the read schema and write schema is incompatible, we cannot use read
schema to read log。previous versions of hudi does not have this problem
Caused by: org.apache.avro.AvroTypeException: Found
hoodie.h0.h0_record.ff.fixed, expecting union
at
org.apache.avro.io.ResolvingDecoder.doAction(ResolvingDecoder.java:308)
at org.apache.avro.io.parsing.Parser.advance(Parser.java:86)
at
org.apache.avro.io.ResolvingDecoder.readIndex(ResolvingDecoder.java:275)
at
org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:188)
at
org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:161)
at
org.apache.avro.generic.GenericDatumReader.readField(GenericDatumReader.java:260)
at
org.apache.avro.generic.GenericDatumReader.readRecord(GenericDatumReader.java:248)
at
org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:180)
at
org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:161)
at
org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:154)
at
org.apache.hudi.common.table.log.block.HoodieAvroDataBlock$RecordIterator.next(HoodieAvroDataBlock.java:201)
at
org.apache.hudi.common.table.log.block.HoodieAvroDataBlock$RecordIterator.next(HoodieAvroDataBlock.java:149)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] XuQianJin-Stars commented on pull request #8024: [MINOR] Improve RollbackToInstantTimeProcedure
XuQianJin-Stars commented on PR #8024: URL: https://github.com/apache/hudi/pull/8024#issuecomment-1442708173 > Can we elaborate a little what are we try to improve here? updated -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (HUDI-5173) Skip if there is only one file in clusteringGroup
[ https://issues.apache.org/jira/browse/HUDI-5173?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Danny Chen closed HUDI-5173. Fix Version/s: 0.13.1 0.14.0 (was: 0.12.1) Assignee: Danny Chen Resolution: Fixed Fixed via master branch: d705dcc4188223fbd824f36a5d211abeda7b1f23 > Skip if there is only one file in clusteringGroup > - > > Key: HUDI-5173 > URL: https://issues.apache.org/jira/browse/HUDI-5173 > Project: Apache Hudi > Issue Type: Improvement >Reporter: zhuanshenbsj1 >Assignee: Danny Chen >Priority: Minor > Labels: pull-request-available > Fix For: 0.13.1, 0.14.0 > > > When generate Clustering plan using > FlinkSizeBasedClusteringPlanStrategy,there is no need to continue if > fileSliceGroup has only one file. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[hudi] branch master updated: [HUDI-5173] Skip if there is only one file in clusteringGroup (#7159)
This is an automated email from the ASF dual-hosted git repository.
danny0405 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new d705dcc4188 [HUDI-5173] Skip if there is only one file in
clusteringGroup (#7159)
d705dcc4188 is described below
commit d705dcc4188223fbd824f36a5d211abeda7b1f23
Author: zhuanshenbsj1 <34104400+zhuanshenb...@users.noreply.github.com>
AuthorDate: Fri Feb 24 10:23:25 2023 +0800
[HUDI-5173] Skip if there is only one file in clusteringGroup (#7159)
Introduce a new option
'hoodie.clustering.plan.strategy.single.group.clustering.enabled' to allow
disabling single file group clustering, when the clustering sort is also
disabled, clustering single file group is unnecessary and can cause unnecessary
read/write costs.
---
.../apache/hudi/config/HoodieClusteringConfig.java | 11 +++
.../org/apache/hudi/config/HoodieWriteConfig.java | 12 +++
.../FlinkSizeBasedClusteringPlanStrategy.java | 32 ++--
.../TestFlinkSizeBasedClusteringPlanStrategy.java | 96 ++
.../SparkSizeBasedClusteringPlanStrategy.java | 10 ++-
...TestSparkBuildClusteringGroupsForPartition.java | 93 +
.../realtime/TestHoodieRealtimeRecordReader.java | 1 +
7 files changed, 243 insertions(+), 12 deletions(-)
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieClusteringConfig.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieClusteringConfig.java
index bfcd4315d29..b76a66d91c5 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieClusteringConfig.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieClusteringConfig.java
@@ -182,6 +182,12 @@ public class HoodieClusteringConfig extends HoodieConfig {
.sinceVersion("0.7.0")
.withDocumentation("Each group can produce 'N'
(CLUSTERING_MAX_GROUP_SIZE/CLUSTERING_TARGET_FILE_SIZE) output file groups");
+ public static final ConfigProperty
PLAN_STRATEGY_SINGLE_GROUP_CLUSTERING_ENABLED = ConfigProperty
+ .key(CLUSTERING_STRATEGY_PARAM_PREFIX +
".single.group.clustering.enabled")
+ .defaultValue(true)
+ .sinceVersion("0.14.0")
+ .withDocumentation("Whether to generate clustering plan when there is
only one file group involved, by default true");
+
public static final ConfigProperty PLAN_STRATEGY_SORT_COLUMNS =
ConfigProperty
.key(CLUSTERING_STRATEGY_PARAM_PREFIX + "sort.columns")
.noDefaultValue()
@@ -469,6 +475,11 @@ public class HoodieClusteringConfig extends HoodieConfig {
return this;
}
+public Builder withSingleGroupClusteringEnabled(Boolean enabled) {
+ clusteringConfig.setValue(PLAN_STRATEGY_SINGLE_GROUP_CLUSTERING_ENABLED,
String.valueOf(enabled));
+ return this;
+}
+
public Builder
withClusteringPlanPartitionFilterMode(ClusteringPlanPartitionFilterMode mode) {
clusteringConfig.setValue(PLAN_PARTITION_FILTER_MODE_NAME.key(),
mode.toString());
return this;
diff --git
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
index f82ac90c424..2ccd0435d3a 100644
---
a/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
+++
b/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/config/HoodieWriteConfig.java
@@ -1601,10 +1601,22 @@ public class HoodieWriteConfig extends HoodieConfig {
return
getInt(HoodieClusteringConfig.PLAN_STRATEGY_SKIP_PARTITIONS_FROM_LATEST);
}
+ public boolean isSingleGroupClusteringEnabled() {
+return
getBoolean(HoodieClusteringConfig.PLAN_STRATEGY_SINGLE_GROUP_CLUSTERING_ENABLED);
+ }
+
+ public boolean shouldClusteringSingleGroup() {
+return isClusteringSortEnabled() || isSingleGroupClusteringEnabled();
+ }
+
public String getClusteringSortColumns() {
return getString(HoodieClusteringConfig.PLAN_STRATEGY_SORT_COLUMNS);
}
+ public boolean isClusteringSortEnabled() {
+return
!StringUtils.isNullOrEmpty(getString(HoodieClusteringConfig.PLAN_STRATEGY_SORT_COLUMNS));
+ }
+
public HoodieClusteringConfig.LayoutOptimizationStrategy
getLayoutOptimizationStrategy() {
return HoodieClusteringConfig.LayoutOptimizationStrategy.fromValue(
getStringOrDefault(HoodieClusteringConfig.LAYOUT_OPTIMIZE_STRATEGY)
diff --git
a/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/client/clustering/plan/strategy/FlinkSizeBasedClusteringPlanStrategy.java
b/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/client/clustering/plan/strategy/FlinkSizeBasedClusteringPlanStrategy.java
index 3abffe38d8b..ac320ceefe6 100644
---
a/hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/c
[GitHub] [hudi] danny0405 merged pull request #7159: [HUDI-5173] Skip if there is only one file in clusteringGroup
danny0405 merged PR #7159: URL: https://github.com/apache/hudi/pull/7159 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7962: [HUDI-5801] Speed metaTable initializeFileGroups
hudi-bot commented on PR #7962: URL: https://github.com/apache/hudi/pull/7962#issuecomment-1442703937 ## CI report: * bd715641ef0532c50771d1ae02fdeb5f39e6a52c Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15202) * a3c0dc7bddb55332966676136a55d9cd59dd6bb6 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15374) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7901: [HUDI-5665] Adding support to re-use table configs
hudi-bot commented on PR #7901: URL: https://github.com/apache/hudi/pull/7901#issuecomment-1442703792 ## CI report: * c55e96ff2e67739855776b50b3a88dd43bfc2f9d Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15347) * 0ee4a7ebbf09c02b2bd81c425f4656e783f815c7 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15373) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #7994: [SUPPORT]How to get back the historic commit time information in my scenario
danny0405 commented on issue #7994: URL: https://github.com/apache/hudi/issues/7994#issuecomment-1442699289 Specify the end query time point is how we get the history records, as long as the instant is still alive in the timeline. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7962: [HUDI-5801] Speed metaTable initializeFileGroups
hudi-bot commented on PR #7962: URL: https://github.com/apache/hudi/pull/7962#issuecomment-1442698881 ## CI report: * bd715641ef0532c50771d1ae02fdeb5f39e6a52c Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15202) * a3c0dc7bddb55332966676136a55d9cd59dd6bb6 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7901: [HUDI-5665] Adding support to re-use table configs
hudi-bot commented on PR #7901: URL: https://github.com/apache/hudi/pull/7901#issuecomment-1442698689 ## CI report: * c55e96ff2e67739855776b50b3a88dd43bfc2f9d Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15347) * 0ee4a7ebbf09c02b2bd81c425f4656e783f815c7 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] peanut-chenzhong opened a new issue, #8034: [SUPPORT]merge into didn`t reinsert the delete record
peanut-chenzhong opened a new issue, #8034: URL: https://github.com/apache/hudi/issues/8034 **_Tips before filing an issue_** - Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)? - Join the mailing list to engage in conversations and get faster support at dev-subscr...@hudi.apache.org. - If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly. **Describe the problem you faced** A clear and concise description of the problem. **To Reproduce** Steps to reproduce the behavior: 1.create table if not exists hudi_table1 (id int,name string,price double) using hudi options (type = 'mor',primaryKey = 'id',preCombineField = 'price'); 2.create table if not exists hudi_table2 (id int,name string,price double) using hudi options (type = 'mor',primaryKey = 'id',preCombineField = 'price'); 3.set hoodie.parquet.small.file.limit=0; 4.insert into hudi_table1 select 1,1,1; 5.insert into hudi_table1 select 2,1,1; 6.merge into hudi_table2 using (select * from hudi_table1) as b on (hudi_table2.id = b.id and hudi_table2.name=b.name) when not matched then insert *; 7.select * from hudi_table2; 8.delete from hudi_table2 where id=1; 9.merge into hudi_table2 using (select * from hudi_table1) as b on (hudi_table2.id = b.id and hudi_table2.name=b.name) when not matched then insert *; 10select * from hudi_table2; **Expected behavior** after step 10, where should be two records in hudi_table2, but now we can only get one which id=2; **Environment Description** * Hudi version :0.14.0 * Spark version :3.3.1 * Hive version :3.1.1 * Hadoop version : * Storage (HDFS/S3/GCS..) : * Running on Docker? (yes/no) : **Additional context** Add any other context about the problem here. **Stacktrace** ```Add the stacktrace of the error.``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] the-other-tim-brown commented on a diff in pull request #8010: [HUDI-4442] [HUDI-5001] Sanitize JsonConversion and RowSource
the-other-tim-brown commented on code in PR #8010:
URL: https://github.com/apache/hudi/pull/8010#discussion_r1116422754
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/sources/helpers/SanitizationUtils.java:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.utilities.sources.helpers;
+
+import org.apache.hudi.avro.HoodieAvroUtils;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.common.util.collection.Pair;
+import org.apache.hudi.utilities.sources.InputBatch;
+
+import com.fasterxml.jackson.core.JsonParser;
+import com.fasterxml.jackson.databind.ObjectMapper;
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaParseException;
+import org.apache.spark.sql.Dataset;
+import org.apache.spark.sql.Row;
+import org.apache.spark.sql.types.ArrayType;
+import org.apache.spark.sql.types.DataType;
+import org.apache.spark.sql.types.MapType;
+import org.apache.spark.sql.types.StructField;
+import org.apache.spark.sql.types.StructType;
+
+import java.util.List;
+import java.util.Map;
+import java.util.stream.Collectors;
+
+public class SanitizationUtils {
+
+ public static class Config {
+// sanitizes names of invalid schema fields both in the data read from
source and also in the schema.
+// invalid definition here goes by avro naming convention
(https://avro.apache.org/docs/current/spec.html#names).
+public static final String SANITIZE_SCHEMA_FIELD_NAMES =
"hoodie.deltastreamer.source.sanitize.invalid.schema.field.names";
+
+public static final String SCHEMA_FIELD_NAME_INVALID_CHAR_MASK =
"hoodie.deltastreamer.source.sanitize.invalid.char.mask";
+ }
+
+ private static final String AVRO_FIELD_NAME_KEY = "name";
+
+ private static DataType sanitizeDataTypeForAvro(DataType dataType, String
invalidCharMask) {
+if (dataType instanceof ArrayType) {
+ ArrayType arrayType = (ArrayType) dataType;
+ DataType sanitizedDataType =
sanitizeDataTypeForAvro(arrayType.elementType(), invalidCharMask);
+ return new ArrayType(sanitizedDataType, arrayType.containsNull());
+} else if (dataType instanceof MapType) {
+ MapType mapType = (MapType) dataType;
+ DataType sanitizedKeyDataType =
sanitizeDataTypeForAvro(mapType.keyType(), invalidCharMask);
+ DataType sanitizedValueDataType =
sanitizeDataTypeForAvro(mapType.valueType(), invalidCharMask);
+ return new MapType(sanitizedKeyDataType, sanitizedValueDataType,
mapType.valueContainsNull());
+} else if (dataType instanceof StructType) {
+ return sanitizeStructTypeForAvro((StructType) dataType, invalidCharMask);
+}
+return dataType;
+ }
+
+ // TODO(HUDI-5256): Refactor this to use InternalSchema when it is ready.
+ private static StructType sanitizeStructTypeForAvro(StructType structType,
String invalidCharMask) {
+StructType sanitizedStructType = new StructType();
+StructField[] structFields = structType.fields();
+for (StructField s : structFields) {
+ DataType currFieldDataTypeSanitized =
sanitizeDataTypeForAvro(s.dataType(), invalidCharMask);
+ StructField structFieldCopy = new
StructField(HoodieAvroUtils.sanitizeName(s.name(), invalidCharMask),
+ currFieldDataTypeSanitized, s.nullable(), s.metadata());
+ sanitizedStructType = sanitizedStructType.add(structFieldCopy);
+}
+return sanitizedStructType;
+ }
+
+ private static Dataset sanitizeColumnNamesForAvro(Dataset
inputDataset, String invalidCharMask) {
+StructField[] inputFields = inputDataset.schema().fields();
+Dataset targetDataset = inputDataset;
+for (StructField sf : inputFields) {
+ DataType sanitizedFieldDataType = sanitizeDataTypeForAvro(sf.dataType(),
invalidCharMask);
+ if (!sanitizedFieldDataType.equals(sf.dataType())) {
+// Sanitizing column names for nested types can be thought of as going
from one schema to another
+// which are structurally similar except for actual column names
itself. So casting is safe and sufficient.
+targetDataset = targetDataset.withColumn(sf.name(),
targetDataset.col(sf.name()).cast(sanitizedFieldDataType));
+ }
+ String possibleRename
[GitHub] [hudi] nsivabalan commented on a diff in pull request #8010: [HUDI-4442] [HUDI-5001] Sanitize JsonConversion and RowSource
nsivabalan commented on code in PR #8010: URL: https://github.com/apache/hudi/pull/8010#discussion_r1116416387 ## hudi-utilities/src/main/java/org/apache/hudi/utilities/deltastreamer/SourceFormatAdapter.java: ## @@ -97,6 +101,7 @@ public InputBatch> fetchNewDataInAvroFormat(Option> r = ((Source>) source).fetchNext(lastCkptStr, sourceLimit); + MercifulJsonConverter.clearCache(r.getSchemaProvider().getSourceSchema().getFullName()); Review Comment: don't we need to clear cache for the other method? fetchNewDataInRowFormat -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8032: [HUDI-5845] Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields.
hudi-bot commented on PR #8032: URL: https://github.com/apache/hudi/pull/8032#issuecomment-1442662597 ## CI report: * c303fc268b71faf519eaabe8d686d1c167b99d17 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15372) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8032: [HUDI-5845] Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields.
hudi-bot commented on PR #8032: URL: https://github.com/apache/hudi/pull/8032#issuecomment-1442656664 ## CI report: * c303fc268b71faf519eaabe8d686d1c167b99d17 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7914: [HUDI-5080] Unpersist only relevant RDDs instead of all
hudi-bot commented on PR #7914: URL: https://github.com/apache/hudi/pull/7914#issuecomment-1442656338 ## CI report: * 94ad2976cd88f284df074090b4da639d0a2eeeab Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15370) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7914: [HUDI-5080] Unpersist only relevant RDDs instead of all
hudi-bot commented on PR #7914: URL: https://github.com/apache/hudi/pull/7914#issuecomment-1442650574 ## CI report: * 94ad2976cd88f284df074090b4da639d0a2eeeab UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] soumilshah1995 opened a new issue, #8033: [SUPPORT] Hudi to support Change-Data-Capture RFC 51 |
soumilshah1995 opened a new issue, #8033:
URL: https://github.com/apache/hudi/issues/8033
i am trying to learn new feature hudi has released in RFC
https://github.com/apache/hudi/blob/master/rfc/rfc-51/rfc-51.md
### Sample Code
```
try:
import os
import sys
import uuid
import pyspark
from pyspark.sql import SparkSession
from pyspark import SparkConf, SparkContext
from pyspark.sql.functions import col, asc, desc
from pyspark.sql.functions import col, to_timestamp,
monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from pyspark.sql.types import *
from datetime import datetime
from functools import reduce
from faker import Faker
except Exception as e:
pass
SUBMIT_ARGS = "--packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.13
pyspark-shell"
os.environ["PYSPARK_SUBMIT_ARGS"] = SUBMIT_ARGS
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executable
spark = SparkSession.builder \
.config('spark.serializer',
'org.apache.spark.serializer.KryoSerializer') \
.config('className', 'org.apache.hudi') \
.config('spark.sql.hive.convertMetastoreParquet', 'false') \
.getOrCreate()
db_name = "hudidb"
table_name = "hudi_cdc_table"
recordkey = 'uuid'
precombine = 'date'
path = f"file:///C:/tmp/{db_name}/{table_name}"
method = 'upsert'
table_type = "COPY_ON_WRITE" # COPY_ON_WRITE | MERGE_ON_READ
hudi_options = {
'hoodie.table.name': table_name,
'hoodie.datasource.write.recordkey.field': recordkey,
'hoodie.datasource.write.table.name': table_name,
'hoodie.datasource.write.operation': method,
'hoodie.datasource.write.precombine.field': precombine,
'hoodie.table.cdc.enabled':'true',
'hoodie.table.cdc.supplemental.logging.mode': 'DATA_AFTER',
}
data_items = [
(1, "insert 1", 111, "2020-01-06 12:12:12"),
(2, "insert 2", 22, "2020-01-06 12:12:12"),
]
columns = ["uuid", "message", "precomb", "date"]
spark_df = spark.createDataFrame(data=data_items, schema=columns)
spark_df.write.format("hudi"). \
options(**hudi_options). \
mode("append"). \
save(path)
data_items = [
(3, "insert 1", 111, "2020-01-06 12:12:12"),
(4, "insert 2", 22, "2020-01-06 12:12:12"),
]
columns = ["uuid", "message", "precomb", "date"]
spark_df = spark.createDataFrame(data=data_items, schema=columns)
spark_df.write.format("hudi"). \
options(**hudi_options). \
mode("append"). \
save(path)
# CDC==
spark. \
read. \
format("hudi"). \
load(path). \
createOrReplaceTempView("hudi_snapshot")
commits = list(map(lambda row: row[0], spark.sql("select
distinct(_hoodie_commit_time) as commitTime from hudi_snapshot order by
commitTime").limit(50).collect()))
beginTime = commits[len(commits) - 2] # commit time we are interested in
print(f"commits : {commits} beginTime : {beginTime} ")
print("beginTime", beginTime)
incremental_read_options = {
'hoodie.datasource.query.type': 'incremental',
'hoodie.datasource.read.begin.instanttime': beginTime,
'hoodie.datasource.query.incremental.forma':'cdc',
'hoodie.datasource.read.begin.instanttime': beginTime,
'hoodie.datasource.read.end.instanttime':"20230223194341503"
}
IncrementalDF = spark.read.format("hudi"). \
options(**incremental_read_options). \
load(path)
IncrementalDF.createOrReplaceTempView("hudi_incremental")
spark.sql("select * from hudi_incremental").show()
```
* This features is just announced and i am trying to learn how exactly it
works so i can teach community and pass it on to other via YouTube channel
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (HUDI-5845) Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields
[ https://issues.apache.org/jira/browse/HUDI-5845?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-5845: - Labels: pull-request-available (was: ) > Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields > -- > > Key: HUDI-5845 > URL: https://issues.apache.org/jira/browse/HUDI-5845 > Project: Apache Hudi > Issue Type: Improvement >Reporter: Shilun Fan >Priority: Major > Labels: pull-request-available > > Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] slfan1989 opened a new pull request, #8032: [HUDI-5845]. Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields.
slfan1989 opened a new pull request, #8032: URL: https://github.com/apache/hudi/pull/8032 ### Change Logs JIRA: HUDI-5845. Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields. ### Impact none. ### Risk level (write none, low medium or high below) none. ### Documentation Update none. ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-5845) Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields
[ https://issues.apache.org/jira/browse/HUDI-5845?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Shilun Fan updated HUDI-5845: - Status: In Progress (was: Open) > Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields > -- > > Key: HUDI-5845 > URL: https://issues.apache.org/jira/browse/HUDI-5845 > Project: Apache Hudi > Issue Type: Improvement >Reporter: Shilun Fan >Priority: Major > > Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Created] (HUDI-5845) Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields
Shilun Fan created HUDI-5845: Summary: Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields Key: HUDI-5845 URL: https://issues.apache.org/jira/browse/HUDI-5845 Project: Apache Hudi Issue Type: Improvement Reporter: Shilun Fan Remove usage of deprecated getTableAvroSchemaWithoutMetadataFields -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] hudi-bot commented on pull request #7951: [HUDI-5796] Adding auto inferring partition from incoming df
hudi-bot commented on PR #7951: URL: https://github.com/apache/hudi/pull/7951#issuecomment-1442610576 ## CI report: * ffc4e3d7fb447cb72feaeaa4a1aec866c519e561 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15344) * cbb0a8c7b89b90b134b7ad41442cfaf59b3654a5 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15371) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] soumilshah1995 opened a new issue, #8031: [SUPPORT] Hudi Timestamp Based Key Generator Need Assistance
soumilshah1995 opened a new issue, #8031:
URL: https://github.com/apache/hudi/issues/8031
Hello Good Evening
i am trying to experiment with Timestamp based key generator following docx
on hudi websites
### Code
```
try:
import os
import sys
import uuid
import pyspark
from pyspark.sql import SparkSession
from pyspark import SparkConf, SparkContext
from pyspark.sql.functions import col, asc, desc
from pyspark.sql.functions import col, to_timestamp,
monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from pyspark.sql.types import *
from datetime import datetime
from functools import reduce
from faker import Faker
except Exception as e:
pass
SUBMIT_ARGS = "--packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.1
pyspark-shell"
os.environ["PYSPARK_SUBMIT_ARGS"] = SUBMIT_ARGS
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executable
spark = SparkSession.builder \
.config('spark.serializer',
'org.apache.spark.serializer.KryoSerializer') \
.config('className', 'org.apache.hudi') \
.config('spark.sql.hive.convertMetastoreParquet', 'false') \
.getOrCreate()
db_name = "hudidb"
table_name = "hudi_table"
recordkey = 'uuid'
precombine = 'date'
path = f"file:///C:/tmp/{db_name}/{table_name}"
method = 'upsert'
table_type = "COPY_ON_WRITE" # COPY_ON_WRITE | MERGE_ON_READ
hudi_options = {
'hoodie.table.name': table_name,
'hoodie.datasource.write.recordkey.field': recordkey,
'hoodie.datasource.write.table.name': table_name,
'hoodie.datasource.write.operation': method,
'hoodie.datasource.write.precombine.field': precombine,
'hoodie.datasource.write.partitionpath.field':
'year:SIMPLE,month:SIMPLE,day:SIMPLE',
"hoodie-conf hoodie.datasource.write.partitionpath.field":"date",
'hoodie.datasource.write.keygenerator.class':
'org.apache.hudi.keygen.TimestampBasedKeyGenerator',
'hoodie.deltastreamer.keygen.timebased.timestamp.type': 'DATE_STRING',
'hoodie.deltastreamer.keygen.timebased.timezone':"GMT+8:00",
'hoodie.deltastreamer.keygen.timebased.input.dateformat': '-MM-dd
hh:mm:ss',
'hoodie.deltastreamer.keygen.timebased.output.dateformat': '/MM/dd'
}
#Input field value: “2020-01-06 12:12:12”
# Partition path generated from key generator: “2020-01-06 12”
data_items = [
(1, "mess 1", 111, "2020-01-06 12:12:12"),
(2, "mes 2", 22, "2020-01-06 12:12:12"),
]
columns = ["uuid", "message", "precomb", "date"]
spark_df = spark.createDataFrame(data=data_items, schema=columns)
spark_df.show()
spark_df.printSchema()
spark_df.write.format("hudi"). \
options(**hudi_options). \
mode("append"). \
save(path)
```
## Expectation was to see partition 2020/01/06/ hudi files inside that
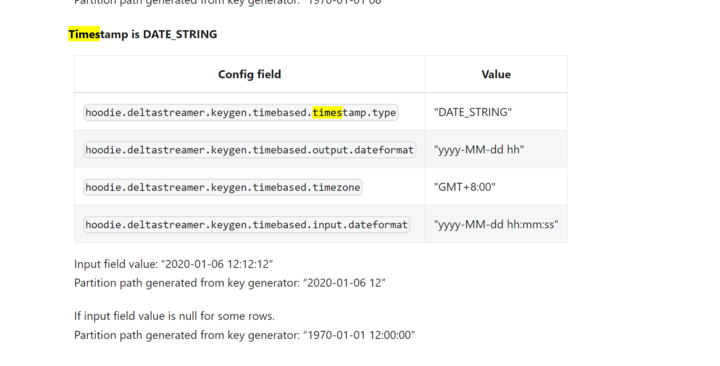
* Maybe i am missing something help from community to point out missing conf
would be great :D
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7951: [HUDI-5796] Adding auto inferring partition from incoming df
hudi-bot commented on PR #7951: URL: https://github.com/apache/hudi/pull/7951#issuecomment-1442604881 ## CI report: * ffc4e3d7fb447cb72feaeaa4a1aec866c519e561 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15344) * cbb0a8c7b89b90b134b7ad41442cfaf59b3654a5 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7847: [HUDI-5697] Revisiting refreshing of Hudi relations after write operations on the tables
hudi-bot commented on PR #7847: URL: https://github.com/apache/hudi/pull/7847#issuecomment-1442597841 ## CI report: * 0241dc20d80d9f8d5fee38637ba1c3b5277ed55f Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15369) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-5844) Resolve going from single writer deltastreamer to multiwriter checkpoint
Jonathan Vexler created HUDI-5844: - Summary: Resolve going from single writer deltastreamer to multiwriter checkpoint Key: HUDI-5844 URL: https://issues.apache.org/jira/browse/HUDI-5844 Project: Apache Hudi Issue Type: Improvement Components: deltastreamer Reporter: Jonathan Vexler If you go from single writer to multiwriter, the single writer checkpoints might be in a different format. Possible solutions: * Require all deltastreamer to have an identifier * cli tool to convert older checkpoints -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Created] (HUDI-5843) Multiwriter Checkpoints for deltastreamer
Jonathan Vexler created HUDI-5843: - Summary: Multiwriter Checkpoints for deltastreamer Key: HUDI-5843 URL: https://issues.apache.org/jira/browse/HUDI-5843 Project: Apache Hudi Issue Type: Improvement Components: deltastreamer Reporter: Jonathan Vexler Assignee: Jonathan Vexler Give each deltastreamer an identifier. Map identifiers to checkpoints so that we can run multiple delta streamers at the same time. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] kazdy commented on issue #8020: [SUPPORT] org.apache.avro.AvroTypeException: Cannot encode decimal with precision 4 as max precision 2
kazdy commented on issue #8020: URL: https://github.com/apache/hudi/issues/8020#issuecomment-1442581108 Hi @xiarixiaoyao wanted to chime in and mention that for Iceberg below is supported with Spark: `decimal(P,S) to decimal(P2,S) when P2 > P (scale cannot change)` https://iceberg.apache.org/docs/latest/spark-ddl/#alter-table--alter-column which is exactly what Simon described, decimal(2,0) to decimal(4,0) then 4 > 2. On the other hand, it seems like in Delta one can't change precision nor scale: https://github.com/delta-io/delta/blob/8b3fd4855deda50b20f27984d187961e7fd4a5a3/core/src/main/scala/org/apache/spark/sql/delta/schema/SchemaMergingUtils.scala#L237-L257 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] alexeykudinkin commented on a diff in pull request #7914: [HUDI-5080] Unpersist only relevant RDDs instead of all
alexeykudinkin commented on code in PR #7914:
URL: https://github.com/apache/hudi/pull/7914#discussion_r111651
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/compact/HoodieCompactor.java:
##
@@ -83,7 +83,7 @@ public abstract void preCompact(
*
* @param writeStatus {@link HoodieData} of {@link WriteStatus}.
*/
- public abstract void maybePersist(HoodieData writeStatus,
HoodieWriteConfig config);
+ public abstract void maybePersist(HoodieData writeStatus,
HoodieEngineContext context, HoodieWriteConfig config, String instantTime);
Review Comment:
nit: Shall we place context as first arg (it's a convention)
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/data/HoodieJavaRDD.java:
##
@@ -81,11 +84,22 @@ public static JavaPairRDD
getJavaRDD(HoodiePairData hoodieDat
return ((HoodieJavaPairRDD) hoodieData).get();
}
+ @Override
+ public int getId() {
+return rddData.id();
+ }
+
@Override
public void persist(String level) {
rddData.persist(StorageLevel.fromString(level));
}
+ @Override
+ public void persist(String level, HoodieEngineContext engineContext,
HoodieDataCacheKey cacheKey) {
Review Comment:
Why do we have 2 overrides now (one accepting context and one that doesn't)?
##
hudi-common/src/main/java/org/apache/hudi/common/data/HoodieData.java:
##
@@ -196,4 +212,42 @@ default HoodieData
distinctWithKey(SerializableFunction keyGetter,
.reduceByKey((value1, value2) -> value1, parallelism)
.values();
}
+
+ /**
+ * The key used in a caching map to identify a {@link HoodieData}.
+ *
+ * At the end of a write operation, we manually unpersist the {@link
HoodieData} associated with that writer.
+ * Therefore, in multi-writer scenario, we need to use both {@code basePath}
and {@code instantTime} to identify {@link HoodieData}s.
+ */
+ class HoodieDataCacheKey implements Serializable {
Review Comment:
We should avoid exposing this outside of the `HoodieData` class (no other
components should be exposed to how we're caching it, so it would be easier for
us to change if we need to)
##
hudi-client/hudi-flink-client/src/main/java/org/apache/hudi/table/action/compact/HoodieFlinkMergeOnReadTableCompactor.java:
##
@@ -55,7 +56,7 @@ public void preCompact(
}
@Override
- public void maybePersist(HoodieData writeStatus,
HoodieWriteConfig config) {
+ public void maybePersist(HoodieData writeStatus,
HoodieEngineContext context, HoodieWriteConfig config, String instantTime) {
Review Comment:
Same comment as above
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/common/HoodieSparkEngineContext.java:
##
@@ -180,4 +187,29 @@ public Option getProperty(EngineProperty key) {
public void setJobStatus(String activeModule, String activityDescription) {
javaSparkContext.setJobGroup(activeModule, activityDescription);
}
+
+ @Override
+ public void putCachedDataIds(HoodieDataCacheKey cacheKey, int... ids) {
+synchronized (cacheLock) {
Review Comment:
No need for separate lock, we can synchronize on the cache itself
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/client/common/HoodieSparkEngineContext.java:
##
@@ -180,4 +187,29 @@ public Option getProperty(EngineProperty key) {
public void setJobStatus(String activeModule, String activityDescription) {
javaSparkContext.setJobGroup(activeModule, activityDescription);
}
+
+ @Override
+ public void putCachedDataIds(HoodieDataCacheKey cacheKey, int... ids) {
+synchronized (cacheLock) {
Review Comment:
Let's also annotates this class as `@ThreadSafe`
##
hudi-client/hudi-spark-client/src/test/java/org/apache/hudi/client/TestSparkRDDWriteClient.java:
##
@@ -0,0 +1,124 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.hudi.client;
+
+import org.apache.hudi.common.config.HoodieMetadataConfig;
+import org.apache.hudi.common.data.HoodieData.HoodieDataCacheKey;
+import org.apache.hudi.common.model.HoodieRecord;
+import org.apache.hudi.common.model.
[GitHub] [hudi] hudi-bot commented on pull request #7914: [HUDI-5080] Unpersist only relevant RDDs instead of all
hudi-bot commented on PR #7914: URL: https://github.com/apache/hudi/pull/7914#issuecomment-1442513046 ## CI report: * ebff5c5a2399351d21de4eb80e3437749c6d1209 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15289) * 94ad2976cd88f284df074090b4da639d0a2eeeab Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15370) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8011: [HUDI-5808] Add Support for kaffka ofsets in jsonkafkasource and avrokafkasource
hudi-bot commented on PR #8011: URL: https://github.com/apache/hudi/pull/8011#issuecomment-1442503418 ## CI report: * 13fc080a47d3abb9793ca160eb0034f5b8368492 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15368) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7914: [HUDI-5080] Unpersist only relevant RDDs instead of all
hudi-bot commented on PR #7914: URL: https://github.com/apache/hudi/pull/7914#issuecomment-1442503094 ## CI report: * ebff5c5a2399351d21de4eb80e3437749c6d1209 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15289) * 94ad2976cd88f284df074090b4da639d0a2eeeab UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8010: [HUDI-4442] [HUDI-5001] Sanitize JsonConversion and RowSource
hudi-bot commented on PR #8010: URL: https://github.com/apache/hudi/pull/8010#issuecomment-1442495928 ## CI report: * 87cbf70ffa73ceab81349245097c830ae28ddeb5 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15367) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7847: [HUDI-5697] Revisiting refreshing of Hudi relations after write operations on the tables
hudi-bot commented on PR #7847: URL: https://github.com/apache/hudi/pull/7847#issuecomment-1442495331 ## CI report: * 2e431b454879172e6042db57391c5345c24479f9 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15252) * 0241dc20d80d9f8d5fee38637ba1c3b5277ed55f Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15369) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7847: [HUDI-5697] Revisiting refreshing of Hudi relations after write operations on the tables
hudi-bot commented on PR #7847: URL: https://github.com/apache/hudi/pull/7847#issuecomment-1442457327 ## CI report: * 2e431b454879172e6042db57391c5345c24479f9 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15252) * 0241dc20d80d9f8d5fee38637ba1c3b5277ed55f UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] soumilshah1995 commented on issue #8021: [DOC] Adding new stored procedures and brief documentation to the Hudi website
soumilshah1995 commented on issue #8021: URL: https://github.com/apache/hudi/issues/8021#issuecomment-1442421112 Thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-5842) Json to Dataset conversion might be broken
[
https://issues.apache.org/jira/browse/HUDI-5842?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Jonathan Vexler updated HUDI-5842:
--
Description:
In TestJsonKafkaSource If you try to do more than just count the number of
records you get a null pointer exception.
[https://github.com/apache/hudi/blob/812950bc9ead4c28763b907dc5a1840162f35337/hudi-utilities/src/test/java/org/apache/hudi/utilities/sources/TestJsonKafkaSource.java]
is a permalink to show what schema it fails on because I am updating the tests
to use a different schema for now. You can trigger the exception by adding
{code:java}
for (Row r : fetch2.getBatch().get().collectAsList()) {
for (StructField f : r.schema().fields()) {
System.out.println(f.name() + ":" + r.get(r.fieldIndex(f.name(;
}
} {code}
to the end of TestJsonKafkaSource.testJsonKafkaSourceWithDefaultUpperCap (using
the schema from the permalink)
The exception is
{code:java}
java.lang.NullPointerException
at
org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificSafeProjection.createExternalRow_0_0$(Unknown
Source)
at
org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificSafeProjection.apply(Unknown
Source)
at
org.apache.spark.sql.Dataset$$anonfun$org$apache$spark$sql$Dataset$$collectFromPlan$1.apply(Dataset.scala:3391)
at
org.apache.spark.sql.Dataset$$anonfun$org$apache$spark$sql$Dataset$$collectFromPlan$1.apply(Dataset.scala:3388)
at
scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at
scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at
scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:186)
at
org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collectFromPlan(Dataset.scala:3388)
at
org.apache.spark.sql.Dataset$$anonfun$collectAsList$1.apply(Dataset.scala:2800)
at
org.apache.spark.sql.Dataset$$anonfun$collectAsList$1.apply(Dataset.scala:2799)
at org.apache.spark.sql.Dataset$$anonfun$53.apply(Dataset.scala:3369)
at
org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:80)
at
org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:127)
at
org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:75)
at
org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$withAction(Dataset.scala:3368)
at org.apache.spark.sql.Dataset.collectAsList(Dataset.scala:2799)
at
org.apache.hudi.utilities.sources.TestJsonKafkaSource.testJsonKafkaSourceWithDefaultUpperCap(TestJsonKafkaSource.java:128)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.junit.platform.commons.util.ReflectionUtils.invokeMethod(ReflectionUtils.java:688)
at
org.junit.jupiter.engine.execution.MethodInvocation.proceed(MethodInvocation.java:60)
at
org.junit.jupiter.engine.execution.InvocationInterceptorChain$ValidatingInvocation.proceed(InvocationInterceptorChain.java:131)
at
org.junit.jupiter.engine.extension.TimeoutExtension.intercept(TimeoutExtension.java:149)
at
org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestableMethod(TimeoutExtension.java:140)
at
org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestMethod(TimeoutExtension.java:84)
at
org.junit.jupiter.engine.execution.ExecutableInvoker$ReflectiveInterceptorCall.lambda$ofVoidMethod$0(ExecutableInvoker.java:115)
at
org.junit.jupiter.engine.execution.ExecutableInvoker.lambda$invoke$0(ExecutableInvoker.java:105)
at
org.junit.jupiter.engine.execution.InvocationInterceptorChain$InterceptedInvocation.proceed(InvocationInterceptorChain.java:106)
at
org.junit.jupiter.engine.execution.InvocationInterceptorChain.proceed(InvocationInterceptorChain.java:64)
at
org.junit.jupiter.engine.execution.InvocationInterceptorChain.chainAndInvoke(InvocationInterceptorChain.java:45)
at
org.junit.jupiter.engine.execution.InvocationInterceptorChain.invoke(InvocationInterceptorChain.java:37)
at
org.junit.jupiter.engine.execution.ExecutableInvoker.invoke(ExecutableInvoker.java:104)
at
org.junit.jupiter.engine.execution.ExecutableInvoker.invoke(ExecutableInvoker.java:98)
at
org.junit.jupiter.engine.descriptor.TestMethodTestDescriptor.lambda$invokeTestMethod$6(TestMethodTestDescriptor.java:210)
at
org.junit.platform.engin
[jira] [Created] (HUDI-5842) Json to Dataset conversion might be broken
Jonathan Vexler created HUDI-5842:
-
Summary: Json to Dataset conversion might be broken
Key: HUDI-5842
URL: https://issues.apache.org/jira/browse/HUDI-5842
Project: Apache Hudi
Issue Type: Bug
Components: deltastreamer
Reporter: Jonathan Vexler
In TestJsonKafkaSource If you try to do more than just count the number of
records you get a null pointer exception.
[https://github.com/apache/hudi/blob/812950bc9ead4c28763b907dc5a1840162f35337/hudi-utilities/src/test/java/org/apache/hudi/utilities/sources/TestJsonKafkaSource.java]
is a permalink to show what schema it fails on because I am updating the tests
to use a different schema for now. You can trigger the exception by adding
{code:java}
for (Row r : fetch2.getBatch().get().collectAsList()) {
for (StructField f : r.schema().fields()) {
System.out.println(f.name() + ":" + r.get(r.fieldIndex(f.name(;
}
} {code}
to the end of TestJsonKafkaSource.testJsonKafkaSourceWithDefaultUpperCap (using
the schema from the permalink)
The exception is
{code:java}
java.lang.NullPointerException
at
org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificSafeProjection.createExternalRow_0_0$(Unknown
Source)
at
org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificSafeProjection.apply(Unknown
Source)
at
org.apache.spark.sql.Dataset$$anonfun$org$apache$spark$sql$Dataset$$collectFromPlan$1.apply(Dataset.scala:3391)
at
org.apache.spark.sql.Dataset$$anonfun$org$apache$spark$sql$Dataset$$collectFromPlan$1.apply(Dataset.scala:3388)
at
scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at
scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234)
at
scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:234)
at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:186)
at
org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$collectFromPlan(Dataset.scala:3388)
at
org.apache.spark.sql.Dataset$$anonfun$collectAsList$1.apply(Dataset.scala:2800)
at
org.apache.spark.sql.Dataset$$anonfun$collectAsList$1.apply(Dataset.scala:2799)
at org.apache.spark.sql.Dataset$$anonfun$53.apply(Dataset.scala:3369)
at
org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:80)
at
org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:127)
at
org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:75)
at
org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$withAction(Dataset.scala:3368)
at org.apache.spark.sql.Dataset.collectAsList(Dataset.scala:2799)
at
org.apache.hudi.utilities.sources.TestJsonKafkaSource.testJsonKafkaSourceWithDefaultUpperCap(TestJsonKafkaSource.java:128)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at
sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at
org.junit.platform.commons.util.ReflectionUtils.invokeMethod(ReflectionUtils.java:688)
at
org.junit.jupiter.engine.execution.MethodInvocation.proceed(MethodInvocation.java:60)
at
org.junit.jupiter.engine.execution.InvocationInterceptorChain$ValidatingInvocation.proceed(InvocationInterceptorChain.java:131)
at
org.junit.jupiter.engine.extension.TimeoutExtension.intercept(TimeoutExtension.java:149)
at
org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestableMethod(TimeoutExtension.java:140)
at
org.junit.jupiter.engine.extension.TimeoutExtension.interceptTestMethod(TimeoutExtension.java:84)
at
org.junit.jupiter.engine.execution.ExecutableInvoker$ReflectiveInterceptorCall.lambda$ofVoidMethod$0(ExecutableInvoker.java:115)
at
org.junit.jupiter.engine.execution.ExecutableInvoker.lambda$invoke$0(ExecutableInvoker.java:105)
at
org.junit.jupiter.engine.execution.InvocationInterceptorChain$InterceptedInvocation.proceed(InvocationInterceptorChain.java:106)
at
org.junit.jupiter.engine.execution.InvocationInterceptorChain.proceed(InvocationInterceptorChain.java:64)
at
org.junit.jupiter.engine.execution.InvocationInterceptorChain.chainAndInvoke(InvocationInterceptorChain.java:45)
at
org.junit.jupiter.engine.execution.InvocationInterceptorChain.invoke(InvocationInterceptorChain.java:37)
at
org.junit.jupiter.engine.execution.ExecutableInvoker.invoke(ExecutableInvoker.java:104)
at
org.junit.jupiter.engine.execution.ExecutableInvoker.invoke(ExecutableInvoker.java
[GitHub] [hudi] hudi-bot commented on pull request #8011: [HUDI-5808] Add Support for kaffka ofsets in jsonkafkasource and avrokafkasource
hudi-bot commented on PR #8011: URL: https://github.com/apache/hudi/pull/8011#issuecomment-1442387076 ## CI report: * a813e246a66bdfe0411fdc96909c7ae560406bfd Azure: [CANCELED](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15366) * 13fc080a47d3abb9793ca160eb0034f5b8368492 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15368) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8011: [HUDI-5808] Add Support for kaffka ofsets in jsonkafkasource and avrokafkasource
hudi-bot commented on PR #8011: URL: https://github.com/apache/hudi/pull/8011#issuecomment-1442378678 ## CI report: * 608b303b0b6fb858d575f6942857a6eade742f90 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15341) * a813e246a66bdfe0411fdc96909c7ae560406bfd Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15366) * 13fc080a47d3abb9793ca160eb0034f5b8368492 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8010: [HUDI-4442] [HUDI-5001] Sanitize JsonConversion and RowSource
hudi-bot commented on PR #8010: URL: https://github.com/apache/hudi/pull/8010#issuecomment-1442316263 ## CI report: * 7dd3bae6a568456284d48df18c0ab558d675169b Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15340) * 87cbf70ffa73ceab81349245097c830ae28ddeb5 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15367) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (HUDI-5841) [Presto-Hudi] Generate splits for base files based on rowgroups
[ https://issues.apache.org/jira/browse/HUDI-5841?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Sagar Sumit reassigned HUDI-5841: - Assignee: Sagar Sumit > [Presto-Hudi] Generate splits for base files based on rowgroups > --- > > Key: HUDI-5841 > URL: https://issues.apache.org/jira/browse/HUDI-5841 > Project: Apache Hudi > Issue Type: Improvement >Reporter: Sagar Sumit >Assignee: Sagar Sumit >Priority: Major > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] hudi-bot commented on pull request #8011: [HUDI-5808] Add Support for kaffka ofsets in jsonkafkasource and avrokafkasource
hudi-bot commented on PR #8011: URL: https://github.com/apache/hudi/pull/8011#issuecomment-1442308579 ## CI report: * 608b303b0b6fb858d575f6942857a6eade742f90 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15341) * a813e246a66bdfe0411fdc96909c7ae560406bfd Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15366) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8010: [HUDI-4442] [HUDI-5001] Sanitize JsonConversion and RowSource
hudi-bot commented on PR #8010: URL: https://github.com/apache/hudi/pull/8010#issuecomment-1442308517 ## CI report: * 7dd3bae6a568456284d48df18c0ab558d675169b Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15340) * 87cbf70ffa73ceab81349245097c830ae28ddeb5 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] kazdy commented on pull request #7548: [DOCS] fix when I click on Update or MergeInto link in spark quickstart it d…
kazdy commented on PR #7548: URL: https://github.com/apache/hudi/pull/7548#issuecomment-1442301162 @nfarah86, gentle reminder :) could we get this reviewed and merged soon? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8011: [HUDI-5808] Add Support for kaffka ofsets in jsonkafkasource and avrokafkasource
hudi-bot commented on PR #8011: URL: https://github.com/apache/hudi/pull/8011#issuecomment-1442300723 ## CI report: * 608b303b0b6fb858d575f6942857a6eade742f90 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15341) * a813e246a66bdfe0411fdc96909c7ae560406bfd UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] kazdy commented on pull request #7547: [DOCS] add DROP TABLE, TRUNCATE TABLE docs to spark quick start guide, minor syntax fixes to ALTER TABLE docs
kazdy commented on PR #7547: URL: https://github.com/apache/hudi/pull/7547#issuecomment-1442299803 @bhasudha gentle reminder, could we merge this one? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] kazdy commented on pull request #7998: [HUDI-5824] Fix: do not combine if write operation is Upsert and COMBINE_BEFORE_UPSERT is false
kazdy commented on PR #7998: URL: https://github.com/apache/hudi/pull/7998#issuecomment-1442298082 Hi Hudi devs, I would appreciate a review, thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7998: [HUDI-5824] Fix: do not combine if write operation is Upsert and COMBINE_BEFORE_UPSERT is false
hudi-bot commented on PR #7998: URL: https://github.com/apache/hudi/pull/7998#issuecomment-1442291366 ## CI report: * 27d61f01fb6709e3aaa08de9ace7738dbedffb24 UNKNOWN * e8e3240aff997075065eb01d9277b227ab2bdf73 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15365) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] jonvex commented on a diff in pull request #8010: [HUDI-4442] [HUDI-5001] Sanitize JsonConversion and RowSource
jonvex commented on code in PR #8010:
URL: https://github.com/apache/hudi/pull/8010#discussion_r1116130380
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/deltastreamer/SourceFormatAdapter.java:
##
@@ -124,6 +261,7 @@ public InputBatch>
fetchNewDataInRowFormat(Option lastCkptS
r.getCheckpointForNextBatch(), r.getSchemaProvider());
}
case PROTO: {
+//sanitizing is not done, but could be implemented if needed
Review Comment:
I put the check in SourceFormatAdapter constructor
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Created] (HUDI-5841) [Presto-Hudi] Generate splits for base files based on rowgroups
Sagar Sumit created HUDI-5841: - Summary: [Presto-Hudi] Generate splits for base files based on rowgroups Key: HUDI-5841 URL: https://issues.apache.org/jira/browse/HUDI-5841 Project: Apache Hudi Issue Type: Improvement Reporter: Sagar Sumit -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] hudi-bot commented on pull request #8029: [HUDI-5832] add relocated prefix for hbase classes in hbase-site.xml
hudi-bot commented on PR #8029: URL: https://github.com/apache/hudi/pull/8029#issuecomment-1442156297 ## CI report: * 8216a936bdc1522e4b9621e2cc45a37f3e5cb436 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15364) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] alexeykudinkin commented on a diff in pull request #8026: [HUDI-5835] After performing the update operation, the hoodie table cannot be read normally by spark
alexeykudinkin commented on code in PR #8026:
URL: https://github.com/apache/hudi/pull/8026#discussion_r1116010686
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/HoodieBaseRelation.scala:
##
@@ -155,12 +158,13 @@ abstract class HoodieBaseRelation(val sqlContext:
SQLContext,
}
}
+val avroNameAndSpace =
AvroConversionUtils.getAvroRecordNameAndNamespace(tableName)
val avroSchema = internalSchemaOpt.map { is =>
- AvroInternalSchemaConverter.convert(is, "schema")
+ AvroInternalSchemaConverter.convert(is, avroNameAndSpace._2 + "." +
avroNameAndSpace._1)
Review Comment:
For the context: this name/namespace are actually generated from the table
name so that qualified name is no better than the previous one (using just
"schema").
We need to understand the real root-cause of the issue
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7998: [HUDI-5824] Fix: do not combine if write operation is Upsert and COMBINE_BEFORE_UPSERT is false
hudi-bot commented on PR #7998: URL: https://github.com/apache/hudi/pull/7998#issuecomment-1442139735 ## CI report: * 27d61f01fb6709e3aaa08de9ace7738dbedffb24 UNKNOWN * c164a3991b8bd900b802fa8de8e85ccb54f6cb98 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15349) * e8e3240aff997075065eb01d9277b227ab2bdf73 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15365) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] kazdy commented on issue #8021: [DOC] Adding new stored procedures and brief documentation to the Hudi website
kazdy commented on issue #8021: URL: https://github.com/apache/hudi/issues/8021#issuecomment-1442130424 Created jira for this and assigned myself, https://issues.apache.org/jira/browse/HUDI-5840 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-5840) [DOCS] Add spark procedures do docs
kazdy created HUDI-5840: --- Summary: [DOCS] Add spark procedures do docs Key: HUDI-5840 URL: https://issues.apache.org/jira/browse/HUDI-5840 Project: Apache Hudi Issue Type: Improvement Reporter: kazdy Assignee: kazdy Add spark procedures do docs, most are missing -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] alexeykudinkin commented on a diff in pull request #8026: [HUDI-5835] After performing the update operation, the hoodie table cannot be read normally by spark
alexeykudinkin commented on code in PR #8026:
URL: https://github.com/apache/hudi/pull/8026#discussion_r1115993642
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/HoodieBaseRelation.scala:
##
@@ -155,12 +158,13 @@ abstract class HoodieBaseRelation(val sqlContext:
SQLContext,
}
}
+val avroNameAndSpace =
AvroConversionUtils.getAvroRecordNameAndNamespace(tableName)
val avroSchema = internalSchemaOpt.map { is =>
- AvroInternalSchemaConverter.convert(is, "schema")
+ AvroInternalSchemaConverter.convert(is, avroNameAndSpace._2 + "." +
avroNameAndSpace._1)
Review Comment:
@xiarixiaoyao can you please share the stacktrace you've observed? Avro
name/namespaces shouldn't matter in that case.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Updated] (HUDI-5835) spark cannot read mor table after execute update statement
[
https://issues.apache.org/jira/browse/HUDI-5835?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Alexey Kudinkin updated HUDI-5835:
--
Fix Version/s: 0.13.1
> spark cannot read mor table after execute update statement
> --
>
> Key: HUDI-5835
> URL: https://issues.apache.org/jira/browse/HUDI-5835
> Project: Apache Hudi
> Issue Type: Bug
> Components: spark
>Affects Versions: 0.13.0
>Reporter: Tao Meng
>Assignee: Tao Meng
>Priority: Blocker
> Labels: pull-request-available
> Fix For: 0.13.1
>
>
> avro schema create by sparksql miss avro name and namespace,
> This will lead the read schema and write schema of the log file to be
> incompatible
>
> {code:java}
> // code placeholder
> spark.sql(
>s"""
> |create table $tableName (
> | id int,
> | name string,
> | price double,
> | ts long,
> | ff decimal(38, 10)
> |) using hudi
> | location '${tablePath.toString}'
> | tblproperties (
> | type = 'mor',
> | primaryKey = 'id',
> | preCombineField = 'ts'
> | )
> """.stripMargin)
> spark.sql(s"insert into $tableName select 1, 'a1', 10, 1000, 10.0")
> checkAnswer(s"select id, name, price, ts from $tableName")(
> Seq(1, "a1", 10.0, 1000)
> )
> spark.sql(s"update $tableName set price = 22 where id = 1")
> checkAnswer(s"select id, name, price, ts from $tableName")( failed
> Seq(1, "a1", 22.0, 1000)
> )
> {code}
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Updated] (HUDI-5839) Insert in non-strict mode deduplices dataset in "append" mode - spark
[
https://issues.apache.org/jira/browse/HUDI-5839?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
kazdy updated HUDI-5839:
Description:
There seem to be a bug with non-strict insert mode when precombine is not
defined (but I have not checked for when it is).
When using spark datasource it can insert duplicates only in overwrite mode or
append mode when data is inserted to the table for the first time, but if I
want to insert in append mode for the second time it deduplicates the dataset
as if it was working in upsert mode. Found in master (0.13.0).
I happens to be a regression, because I'm using this functionality in Hudi
0.12.1.
{code:java}
from pyspark.sql.functions import expr
path = "/tmp/huditbl"
opt_insert = {
'hoodie.table.name': 'huditbl',
'hoodie.datasource.write.recordkey.field': 'keyid',
'hoodie.datasource.write.table.name': 'huditbl',
'hoodie.datasource.write.operation': 'insert',
'hoodie.sql.insert.mode': 'non-strict',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.insert.shuffle.parallelism': 2,
'hoodie.combine.before.upsert': 'false',
'hoodie.combine.before.insert': 'false',
'hoodie.datasource.write.insert.drop.duplicates': 'false'
}
df = spark.range(0, 10).toDF("keyid") \
.withColumn("age", expr("keyid + 1000"))
df.write.format("hudi"). \
options(**opt_insert). \
mode("overwrite"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 10
df = df.union(df) # creates duplicates
df.write.format("hudi"). \
options(**opt_insert). \
mode("append"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 10 but should return 20
# note
# this works:
df = df.union(df) # creates duplicates
df.write.format("hudi"). \
options(**opt_insert). \
mode("overwrite"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 20 as it should{code}
was:
There seem to be a bug with non-strict insert mode when precombine is not
defined (but I have not checked for when it is).
When using spark datasource it can insert duplicates only in overwrite mode or
append mode when data is inserted to the table for the first time, but if I
want to insert in append mode for the second time it deduplicates the dataset
as if it was working in upsert mode. Found in master (0.13.0).
I happens to be a regression, because I'm using this functionality in Hudi
0.12.1.
{code:java}
from pyspark.sql.functions import expr
path = "/tmp/huditbl"
opt_insert = {
'hoodie.table.name': 'huditbl',
'hoodie.datasource.write.recordkey.field': 'keyid',
'hoodie.datasource.write.table.name': 'huditbl',
'hoodie.datasource.write.operation': 'insert',
'hoodie.sql.insert.mode': 'non-strict',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.insert.shuffle.parallelism': 2,
'hoodie.combine.before.upsert': 'false',
'hoodie.combine.before.insert': 'false',
'hoodie.datasource.write.insert.drop.duplicates': 'false'
}
df = spark.range(0, 10).toDF("keyid") \
.withColumn("age", expr("keyid + 1000"))
df.write.format("hudi"). \
options(**opt_insert). \
mode("overwrite"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 10
df = df.union(df) # creates duplicates
df.write.format("hudi"). \
options(**opt_insert). \
mode("append"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 10 but should return 20
{code}
> Insert in non-strict mode deduplices dataset in "append" mode - spark
> -
>
> Key: HUDI-5839
> URL: https://issues.apache.org/jira/browse/HUDI-5839
> Project: Apache Hudi
> Issue Type: Bug
> Components: spark, writer-core
>Affects Versions: 0.13.0
>Reporter: kazdy
>Priority: Major
>
> There seem to be a bug with non-strict insert mode when precombine is not
> defined (but I have not checked for when it is).
> When using spark datasource it can insert duplicates only in overwrite mode
> or append mode when data is inserted to the table for the first time, but if
> I want to insert in append mode for the second time it deduplicates the
> dataset as if it was working in upsert mode. Found in master (0.13.0).
> I happens to be a regression, because I'm using this functionality in Hudi
> 0.12.1.
> {code:java}
> from pyspark.sql.functions import expr
> path = "/tmp/huditbl"
> opt_insert = {
> 'hoodie.table.name': 'huditbl',
> 'hoodie.datasource.write.recordkey.field': 'keyid',
> 'hoodie.datasource.write.table.name': 'huditbl',
> 'hoodie.datasource.write.operation': 'insert',
> 'hoodie.sql.insert.mode': 'non-strict',
> 'hoodie.upsert.shuffle.parallelism': 2,
> 'hoodie.insert.shuffle.parallelism': 2,
> 'hoodie.combine.before.upsert': 'false',
> 'hoodie.combine.before.insert': 'false',
> 'hoodie.datasource.write.insert.
[GitHub] [hudi] hudi-bot commented on pull request #7998: [HUDI-5824] Fix: do not combine if write operation is Upsert and COMBINE_BEFORE_UPSERT is false
hudi-bot commented on PR #7998: URL: https://github.com/apache/hudi/pull/7998#issuecomment-1442053212 ## CI report: * 27d61f01fb6709e3aaa08de9ace7738dbedffb24 UNKNOWN * c164a3991b8bd900b802fa8de8e85ccb54f6cb98 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=15349) * e8e3240aff997075065eb01d9277b227ab2bdf73 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] stayrascal commented on issue #2813: [SUPPORT] HoodieRealtimeRecordReader can only work on RealtimeSplit and not with hdfs://111.parquet:0+4
stayrascal commented on issue #2813: URL: https://github.com/apache/hudi/issues/2813#issuecomment-1442028158 thanks @danny0405, it works. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-5839) Insert in non-strict mode deduplices dataset in "append" mode - spark
[
https://issues.apache.org/jira/browse/HUDI-5839?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
kazdy updated HUDI-5839:
Description:
There seem to be a bug with non-strict insert mode when precombine is not
defined (but I have not checked for when it is).
When using spark datasource it can insert duplicates only in overwrite mode or
append mode when data is inserted to the table for the first time, but if I
want to insert in append mode for the second time it deduplicates the dataset
as if it was working in upsert mode. Found in master (0.13.0).
I happens to be a regression, because I'm using this functionality in Hudi
0.12.1.
{code:java}
from pyspark.sql.functions import expr
path = "/tmp/huditbl"
opt_insert = {
'hoodie.table.name': 'huditbl',
'hoodie.datasource.write.recordkey.field': 'keyid',
'hoodie.datasource.write.table.name': 'huditbl',
'hoodie.datasource.write.operation': 'insert',
'hoodie.sql.insert.mode': 'non-strict',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.insert.shuffle.parallelism': 2,
'hoodie.combine.before.upsert': 'false',
'hoodie.combine.before.insert': 'false',
'hoodie.datasource.write.insert.drop.duplicates': 'false'
}
df = spark.range(0, 10).toDF("keyid") \
.withColumn("age", expr("keyid + 1000"))
df.write.format("hudi"). \
options(**opt_insert). \
mode("overwrite"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 10
df = df.union(df) # creates duplicates
df.write.format("hudi"). \
options(**opt_insert). \
mode("append"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 10 but should return 20
{code}
was:
There seem to be a bug with non-strict insert mode when precombine is not
defined (but I have not checked for when it is).
When using spark datasource it can insert duplicates only in overwrite mode or
append mode when data is inserted to the table for the first time, but if I
want to insert in append mode for the second time it deduplicates the dataset
as if it was working in upsert mode. Found in master (0.13.0).
I happens to be a regression, because I'm using this functionality in Hudi
0.12.1.
{code:java}
from pyspark.sql.functions import expr
opt_insert = {
'hoodie.table.name': 'huditbl',
'hoodie.datasource.write.recordkey.field': 'keyid',
'hoodie.datasource.write.table.name': 'huditbl',
'hoodie.datasource.write.operation': 'insert',
'hoodie.sql.insert.mode': 'non-strict',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.insert.shuffle.parallelism': 2,
'hoodie.combine.before.upsert': 'false',
'hoodie.combine.before.insert': 'false',
'hoodie.datasource.write.insert.drop.duplicates': 'false'
}
df = spark.range(0, 10).toDF("keyid") \
.withColumn("age", expr("keyid + 1000"))
df.write.format("hudi"). \
options(**opt_insert). \
mode("overwrite"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 10
df = df.union(df) # creates duplicates
df.write.format("hudi"). \
options(**opt_insert). \
mode("append"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 10 but should return 20
{code}
> Insert in non-strict mode deduplices dataset in "append" mode - spark
> -
>
> Key: HUDI-5839
> URL: https://issues.apache.org/jira/browse/HUDI-5839
> Project: Apache Hudi
> Issue Type: Bug
> Components: spark, writer-core
>Affects Versions: 0.13.0
>Reporter: kazdy
>Priority: Major
>
> There seem to be a bug with non-strict insert mode when precombine is not
> defined (but I have not checked for when it is).
> When using spark datasource it can insert duplicates only in overwrite mode
> or append mode when data is inserted to the table for the first time, but if
> I want to insert in append mode for the second time it deduplicates the
> dataset as if it was working in upsert mode. Found in master (0.13.0).
> I happens to be a regression, because I'm using this functionality in Hudi
> 0.12.1.
> {code:java}
> from pyspark.sql.functions import expr
> path = "/tmp/huditbl"
> opt_insert = {
> 'hoodie.table.name': 'huditbl',
> 'hoodie.datasource.write.recordkey.field': 'keyid',
> 'hoodie.datasource.write.table.name': 'huditbl',
> 'hoodie.datasource.write.operation': 'insert',
> 'hoodie.sql.insert.mode': 'non-strict',
> 'hoodie.upsert.shuffle.parallelism': 2,
> 'hoodie.insert.shuffle.parallelism': 2,
> 'hoodie.combine.before.upsert': 'false',
> 'hoodie.combine.before.insert': 'false',
> 'hoodie.datasource.write.insert.drop.duplicates': 'false'
> }
> df = spark.range(0, 10).toDF("keyid") \
> .withColumn("age", expr("keyid + 1000"))
> df.write.format("hudi"). \
> options(**opt_insert). \
> mode("overwrite"). \
> save(path)
> spark.read.format("hudi").load(pat
[jira] [Updated] (HUDI-5839) Insert in non-strict mode deduplices dataset in "append" mode - spark
[
https://issues.apache.org/jira/browse/HUDI-5839?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
kazdy updated HUDI-5839:
Description:
There seem to be a bug with non-strict insert mode when precombine is not
defined (but I have not checked for when it is).
When using spark datasource it can insert duplicates only in overwrite mode or
append mode when data is inserted to the table for the first time, but if I
want to insert in append mode for the second time it deduplicates the dataset
as if it was working in upsert mode. Found in master (0.13.0).
I happens to be a regression, because I'm using this functionality in Hudi
0.12.1.
{code:java}
from pyspark.sql.functions import expr
opt_insert = {
'hoodie.table.name': 'huditbl',
'hoodie.datasource.write.recordkey.field': 'keyid',
'hoodie.datasource.write.table.name': 'huditbl',
'hoodie.datasource.write.operation': 'insert',
'hoodie.sql.insert.mode': 'non-strict',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.insert.shuffle.parallelism': 2,
'hoodie.combine.before.upsert': 'false',
'hoodie.combine.before.insert': 'false',
'hoodie.datasource.write.insert.drop.duplicates': 'false'
}
df = spark.range(0, 10).toDF("keyid") \
.withColumn("age", expr("keyid + 1000"))
df.write.format("hudi"). \
options(**opt_insert). \
mode("overwrite"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 10
df = df.union(df) # creates duplicates
df.write.format("hudi"). \
options(**opt_insert). \
mode("append"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 10 but should return 20
{code}
was:
There seem to be a bug with non-strict insert mode when precombine is not
defined (but I have not checked for when it is).
When using spark datasource it can insert duplicates only in overwrite mode or
append mode when data is inserted to the table for the first time, but if I
want to insert in append mode for the second time it deduplicates the dataset
as if it was working in upsert mode.
I happens to be a regression, because I'm using this functionality in Hudi
0.12.1.
{code:java}
from pyspark.sql.functions import expr
opt_insert = {
'hoodie.table.name': 'huditbl',
'hoodie.datasource.write.recordkey.field': 'keyid',
'hoodie.datasource.write.table.name': 'huditbl',
'hoodie.datasource.write.operation': 'insert',
'hoodie.sql.insert.mode': 'non-strict',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.insert.shuffle.parallelism': 2,
'hoodie.combine.before.upsert': 'false',
'hoodie.combine.before.insert': 'false',
'hoodie.datasource.write.insert.drop.duplicates': 'false'
}
df = spark.range(0, 10).toDF("keyid") \
.withColumn("age", expr("keyid + 1000"))
df.write.format("hudi"). \
options(**opt_insert). \
mode("overwrite"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 10
df = df.union(df) # creates duplicates
df.write.format("hudi"). \
options(**opt_insert). \
mode("append"). \
save(path)
spark.read.format("hudi").load(path).count() # returns 10 but should return 20
{code}
> Insert in non-strict mode deduplices dataset in "append" mode - spark
> -
>
> Key: HUDI-5839
> URL: https://issues.apache.org/jira/browse/HUDI-5839
> Project: Apache Hudi
> Issue Type: Bug
> Components: spark, writer-core
>Affects Versions: 0.13.0
>Reporter: kazdy
>Priority: Major
>
> There seem to be a bug with non-strict insert mode when precombine is not
> defined (but I have not checked for when it is).
> When using spark datasource it can insert duplicates only in overwrite mode
> or append mode when data is inserted to the table for the first time, but if
> I want to insert in append mode for the second time it deduplicates the
> dataset as if it was working in upsert mode. Found in master (0.13.0).
> I happens to be a regression, because I'm using this functionality in Hudi
> 0.12.1.
> {code:java}
> from pyspark.sql.functions import expr
> opt_insert = {
> 'hoodie.table.name': 'huditbl',
> 'hoodie.datasource.write.recordkey.field': 'keyid',
> 'hoodie.datasource.write.table.name': 'huditbl',
> 'hoodie.datasource.write.operation': 'insert',
> 'hoodie.sql.insert.mode': 'non-strict',
> 'hoodie.upsert.shuffle.parallelism': 2,
> 'hoodie.insert.shuffle.parallelism': 2,
> 'hoodie.combine.before.upsert': 'false',
> 'hoodie.combine.before.insert': 'false',
> 'hoodie.datasource.write.insert.drop.duplicates': 'false'
> }
> df = spark.range(0, 10).toDF("keyid") \
> .withColumn("age", expr("keyid + 1000"))
> df.write.format("hudi"). \
> options(**opt_insert). \
> mode("overwrite"). \
> save(path)
> spark.read.format("hudi").load(path).count() # returns 10
> df = df.union(df) # creates duplicates
> df.wri