[GitHub] [hudi] bvaradar commented on pull request #7680: [HUDI-5548] spark sql show | update hudi's table properties
bvaradar commented on PR #7680: URL: https://github.com/apache/hudi/pull/7680#issuecomment-1539440046 @XuQianJin-Stars : Checking to see if you can take this to finish line ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #8159: [SUPPORT] - Debezium PostgreSQL
ad1happy2go commented on issue #8159: URL: https://github.com/apache/hudi/issues/8159#issuecomment-1539434631 @lenhardtx Did you got a chance to test out with the patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on a diff in pull request #8452: [HUDI-6077] Add more partition push down filters
bvaradar commented on code in PR #8452:
URL: https://github.com/apache/hudi/pull/8452#discussion_r1188099833
##
hudi-common/src/main/java/org/apache/hudi/metadata/FileSystemBackedTableMetadata.java:
##
@@ -58,13 +62,21 @@ public class FileSystemBackedTableMetadata implements
HoodieTableMetadata {
private final SerializableConfiguration hadoopConf;
private final String datasetBasePath;
private final boolean assumeDatePartitioning;
+ private final boolean hiveStylePartitioningEnabled;
+ private final boolean urlEncodePartitioningEnabled;
public FileSystemBackedTableMetadata(HoodieEngineContext engineContext,
SerializableConfiguration conf, String datasetBasePath,
boolean assumeDatePartitioning) {
this.engineContext = engineContext;
this.hadoopConf = conf;
this.datasetBasePath = datasetBasePath;
this.assumeDatePartitioning = assumeDatePartitioning;
+HoodieTableMetaClient metaClient = HoodieTableMetaClient.builder()
Review Comment:
The super class already instantiates metaclient. Please move the members
hiveStylePartitioningEnabled and urlEncodePartitioningEnabled there so that
they can be reused for HoodieBackedTableMetadata
##
hudi-sync/hudi-hive-sync/src/main/java/org/apache/hudi/hive/util/FilterGenVisitor.java:
##
@@ -42,9 +43,10 @@ private String quoteStringLiteral(String value) {
}
}
- private String visitAnd(Expression left, Expression right) {
-String leftResult = left.accept(this);
-String rightResult = right.accept(this);
+ @Override
+ public String visitAnd(Predicates.And and) {
Review Comment:
Is case sensitivity same between hive-sync and spark integration ?
##
hudi-spark-datasource/hudi-spark2/src/main/scala/org/apache/spark/sql/adapter/Spark2Adapter.scala:
##
@@ -186,4 +186,13 @@ class Spark2Adapter extends SparkAdapter {
case OFF_HEAP => "OFF_HEAP"
case _ => throw new IllegalArgumentException(s"Invalid StorageLevel:
$level")
}
+
+ override def translateFilter(predicate: Expression,
+ supportNestedPredicatePushdown: Boolean =
false): Option[Filter] = {
+if (supportNestedPredicatePushdown) {
Review Comment:
Is this expected to fail any spark 2 queries ?
##
hudi-common/src/main/java/org/apache/hudi/metadata/HoodieBackedTableMetadata.java:
##
@@ -153,6 +156,20 @@ protected Option>
getRecordByKey(String key,
return recordsByKeys.size() == 0 ? Option.empty() :
recordsByKeys.get(0).getValue();
}
+ @Override
+ public List getPartitionPathByExpression(List
relativePathPrefixes,
+ Types.RecordType
partitionFields,
+ Expression expression)
throws IOException {
+Expression boundedExpr = expression.accept(new
BindVisitor(partitionFields, false));
+boolean hiveStylePartitioningEnabled =
Boolean.parseBoolean(dataMetaClient.getTableConfig().getHiveStylePartitioningEnable());
Review Comment:
Once we move hiveStylePartitioningEnabled and urlEncodePartitioningEnabled
to base class, reuse them instead of creating this each time.
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/SparkHoodieTableFileIndex.scala:
##
@@ -307,8 +318,20 @@ class SparkHoodieTableFileIndex(spark: SparkSession,
Seq(new PartitionPath(relativePartitionPathPrefix,
staticPartitionColumnNameValuePairs.map(_._2._2.asInstanceOf[AnyRef]).toArray))
} else {
// Otherwise, compile extracted partition values (from query
predicates) into a sub-path which is a prefix
-// of the complete partition path, do listing for this prefix-path only
-
listPartitionPaths(Seq(relativePartitionPathPrefix).toList.asJava).asScala
+// of the complete partition path, do listing for this prefix-path and
filter them with partitionPredicates
+Try {
+
SparkFilterHelper.convertDataType(partitionSchema).asInstanceOf[RecordType]
+} match {
+ case Success(partitionRecordType) if
partitionRecordType.fields().size() == _partitionSchemaFromProperties.size =>
+val convertedFilters = SparkFilterHelper.convertFilters(
+ partitionColumnPredicates.flatMap {
+expr => sparkAdapter.translateFilter(expr)
+ })
+listPartitionPaths(Seq(relativePartitionPathPrefix).toList.asJava,
partitionRecordType, convertedFilters).asScala
Review Comment:
If we encounter exception such as in Conversions.fromPartitionString
default case, we should revert to list by prefix without filtering.
##
hudi-common/src/main/java/org/apache/hudi/metadata/FileSystemBackedTableMetadata.java:
##
@@ -84,6 +96,19 @@ public List getAllPartitionPaths() throws
IOException {
return
[GitHub] [hudi] ad1happy2go commented on issue #8614: [SUPPORT] Exception in thread "main" java.lang.NoSuchMethodError: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDown(Lscala/Par
ad1happy2go commented on issue #8614: URL: https://github.com/apache/hudi/issues/8614#issuecomment-1539432004 @abdkumar Were you able to test out with this patch. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #8532: [SUPPORT]org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 11 partition 1
ad1happy2go commented on issue #8532: URL: https://github.com/apache/hudi/issues/8532#issuecomment-1539432545 @gtwuser Did the tuning guide helped? Were you Able to resolve the issue? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] codope closed issue #8340: [SUPPORT] cannot assign instance of java.lang.invoke.SerializedLambda
codope closed issue #8340: [SUPPORT] cannot assign instance of java.lang.invoke.SerializedLambda URL: https://github.com/apache/hudi/issues/8340 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] ad1happy2go commented on issue #8340: [SUPPORT] cannot assign instance of java.lang.invoke.SerializedLambda
ad1happy2go commented on issue #8340: URL: https://github.com/apache/hudi/issues/8340#issuecomment-1539430091 Thanks @TranHuyTiep. Closing the issue as you are able to fix. Please reopen if you see issue again. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8659: [HUDI-6155] Fix cleaner based on hours for earliest commit to retain
hudi-bot commented on PR #8659: URL: https://github.com/apache/hudi/pull/8659#issuecomment-1539417125 ## CI report: * 4173ee7fd4dda6e1791b5356a4ca0d09df207f27 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16958) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Closed] (HUDI-6031) checkpoint lost after changing COW to MOR, when using deltastreamer
[ https://issues.apache.org/jira/browse/HUDI-6031?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kong Wei closed HUDI-6031. -- Resolution: Fixed > checkpoint lost after changing COW to MOR, when using deltastreamer > --- > > Key: HUDI-6031 > URL: https://issues.apache.org/jira/browse/HUDI-6031 > Project: Apache Hudi > Issue Type: Bug > Components: deltastreamer >Reporter: Kong Wei >Assignee: Kong Wei >Priority: Major > Labels: pull-request-available > > after changing existing COW table to MOR (follow the > [FAQ|#how-to-convert-an-existing-cow-table-to-mor]), then continue the > deltastreamer on the MOR table, the checkpoint from COW (saved in commit > file) will lost, cause the dataloss issue in this case. > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Resolved] (HUDI-6031) checkpoint lost after changing COW to MOR, when using deltastreamer
[ https://issues.apache.org/jira/browse/HUDI-6031?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kong Wei resolved HUDI-6031. > checkpoint lost after changing COW to MOR, when using deltastreamer > --- > > Key: HUDI-6031 > URL: https://issues.apache.org/jira/browse/HUDI-6031 > Project: Apache Hudi > Issue Type: Bug > Components: deltastreamer >Reporter: Kong Wei >Assignee: Kong Wei >Priority: Major > Labels: pull-request-available > > after changing existing COW table to MOR (follow the > [FAQ|#how-to-convert-an-existing-cow-table-to-mor]), then continue the > deltastreamer on the MOR table, the checkpoint from COW (saved in commit > file) will lost, cause the dataloss issue in this case. > > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[jira] [Closed] (HUDI-6019) Kafka source support split by count
[
https://issues.apache.org/jira/browse/HUDI-6019?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kong Wei closed HUDI-6019.
--
Resolution: Fixed
> Kafka source support split by count
> ---
>
> Key: HUDI-6019
> URL: https://issues.apache.org/jira/browse/HUDI-6019
> Project: Apache Hudi
> Issue Type: New Feature
> Components: deltastreamer, hudi-utilities
>Reporter: Kong Wei
>Assignee: Kong Wei
>Priority: Major
> Labels: pull-request-available
>
> For the kafka source, when pulling data from kafka, the default parallelism
> is the number of kafka partitions, and the only way to increase the
> parallelism (to speed up) is to add more kafka partitions.
> There are cases:
> # Pulling large amount of data from kafka (eg. maxEvents=1), but the
> # of kafka partition is not enough, the procedure of the pulling will cost
> too much of time, even worse can cause the executor OOM
> # There is huge data skew between kafka partitions, the procedure of the
> pulling will be blocked by the slowest partition
> to solve those cases, I want to add a parameter
> {{*hoodie.deltastreamer.source.kafka.per.partition.maxEvents*}} to control
> the maxEvents in one kafka partition, default Long.MAX_VALUE means not trun
> this feature on.
>
> For example, given hoodie.deltastreamer.kafka.source.maxEvents=1000, 2
> kafka partitions:
> the best case is pulling 500 events from each kafka partition, which may
> take minutes to finish;
> while worse case may be pulling 900 event from one partition, and pulling
> 100 events from another one, which will take more time to finish due to
> data skew.
>
> In this example, we set
> {{hoodie.deltastreamer.source.kafka.per.partition.maxEvents=100, then we
> will split the kafka source into at least 10 parts, each executor will
> pulling at most 100 events from kafka, which will take the advantage of
> parallelism.}}
> {{}}
> {{}}
> {{**}}
> 3 benefits of this feature:
> # Avoid a single executor pulling a large amount of data and taking too long
> ({*}avoid data skew{*})
> # Avoid a single executor pulling a large amount of data, use too much
> memory or even OOM ({*}avoid OOM{*})
> # A single executor pulls a small amount of data, which can make full use of
> the number of cores to improve concurrency, then reduce the time of the
> pulling procedure ({*}increase parallelism{*})
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[jira] [Resolved] (HUDI-6019) Kafka source support split by count
[
https://issues.apache.org/jira/browse/HUDI-6019?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Kong Wei resolved HUDI-6019.
> Kafka source support split by count
> ---
>
> Key: HUDI-6019
> URL: https://issues.apache.org/jira/browse/HUDI-6019
> Project: Apache Hudi
> Issue Type: New Feature
> Components: deltastreamer, hudi-utilities
>Reporter: Kong Wei
>Assignee: Kong Wei
>Priority: Major
> Labels: pull-request-available
>
> For the kafka source, when pulling data from kafka, the default parallelism
> is the number of kafka partitions, and the only way to increase the
> parallelism (to speed up) is to add more kafka partitions.
> There are cases:
> # Pulling large amount of data from kafka (eg. maxEvents=1), but the
> # of kafka partition is not enough, the procedure of the pulling will cost
> too much of time, even worse can cause the executor OOM
> # There is huge data skew between kafka partitions, the procedure of the
> pulling will be blocked by the slowest partition
> to solve those cases, I want to add a parameter
> {{*hoodie.deltastreamer.source.kafka.per.partition.maxEvents*}} to control
> the maxEvents in one kafka partition, default Long.MAX_VALUE means not trun
> this feature on.
>
> For example, given hoodie.deltastreamer.kafka.source.maxEvents=1000, 2
> kafka partitions:
> the best case is pulling 500 events from each kafka partition, which may
> take minutes to finish;
> while worse case may be pulling 900 event from one partition, and pulling
> 100 events from another one, which will take more time to finish due to
> data skew.
>
> In this example, we set
> {{hoodie.deltastreamer.source.kafka.per.partition.maxEvents=100, then we
> will split the kafka source into at least 10 parts, each executor will
> pulling at most 100 events from kafka, which will take the advantage of
> parallelism.}}
> {{}}
> {{}}
> {{**}}
> 3 benefits of this feature:
> # Avoid a single executor pulling a large amount of data and taking too long
> ({*}avoid data skew{*})
> # Avoid a single executor pulling a large amount of data, use too much
> memory or even OOM ({*}avoid OOM{*})
> # A single executor pulls a small amount of data, which can make full use of
> the number of cores to improve concurrency, then reduce the time of the
> pulling procedure ({*}increase parallelism{*})
>
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
[hudi] branch master updated: [MINOR] Claim RFC-69 for Hudi 1.x (#8671)
This is an automated email from the ASF dual-hosted git repository. vinoth pushed a commit to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git The following commit(s) were added to refs/heads/master by this push: new a71d3e49fe6 [MINOR] Claim RFC-69 for Hudi 1.x (#8671) a71d3e49fe6 is described below commit a71d3e49fe6fb1c7d3dbbed846eb81d97464768b Author: vinoth chandar AuthorDate: Mon May 8 21:39:27 2023 -0700 [MINOR] Claim RFC-69 for Hudi 1.x (#8671) --- rfc/README.md | 1 + 1 file changed, 1 insertion(+) diff --git a/rfc/README.md b/rfc/README.md index d894ccf0d22..9218b0e71b6 100644 --- a/rfc/README.md +++ b/rfc/README.md @@ -104,3 +104,4 @@ The list of all RFCs can be found here. | 66 | [Lockless Multi-Writer Support](./rfc-66/rfc-66.md) | `UNDER REVIEW` | | 67 | [Hudi Bundle Standards](./rfc-67/rfc-67.md) | `UNDER REVIEW` | | 68 | [A More Effective HoodieMergeHandler for COW Table with Parquet](./rfc-68/rfc-68.md) | `UNDER REVIEW` | +| 69 | [Hudi 1.x](./rfc-69/rfc-69.md) | `UNDER REVIEW` |
[GitHub] [hudi] vinothchandar merged pull request #8671: [MINOR] Claim RFC-69 for Hudi 1.x
vinothchandar merged PR #8671: URL: https://github.com/apache/hudi/pull/8671 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8503: [HUDI-6047] Clustering operation on consistent hashing index resulting in duplicate data
danny0405 commented on code in PR #8503:
URL: https://github.com/apache/hudi/pull/8503#discussion_r1188118551
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/index/HoodieIndex.java:
##
@@ -154,6 +154,14 @@ public boolean requiresTagging(WriteOperationType
operationType) {
public void close() {
}
+ /***
+ * Updates index metadata of the given table and instant if needed.
+ * @param table The committed table.
+ * @param hoodieInstant The instant to commit.
+ */
+ public void commitIndexMetadataIfNeeded(HoodieTable table, String
hoodieInstant) {
+ }
+
Review Comment:
Cool, then we can get rid of the in-consistency and also the method
`commitIndexMetadataIfNeeded`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8669: [HUDI-5362] Rebase IncrementalRelation over HoodieBaseRelation
hudi-bot commented on PR #8669: URL: https://github.com/apache/hudi/pull/8669#issuecomment-1539383881 ## CI report: * 9b8fd1cd5d56d58fc52d334a54e326c405fadf53 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16966) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8660: [MINOR] Fix RunBootstrapProcedure doesn't has database default value
hudi-bot commented on PR #8660: URL: https://github.com/apache/hudi/pull/8660#issuecomment-1539383737 ## CI report: * a8c869a89e0382f1d82eab51a73dac7b180b766a Azure: [CANCELED](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16961) * 07fff1ff35fd19d4abb39a184e17cc0683db770e Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16965) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] vinothchandar opened a new pull request, #8671: [MINOR] Claim RFC-69 for Hudi 1.x
vinothchandar opened a new pull request, #8671: URL: https://github.com/apache/hudi/pull/8671 ### Change Logs _Describe context and summary for this change. Highlight if any code was copied._ ### Impact _Describe any public API or user-facing feature change or any performance impact._ ### Risk level (write none, low medium or high below) _If medium or high, explain what verification was done to mitigate the risks._ ### Documentation Update _Describe any necessary documentation update if there is any new feature, config, or user-facing change_ - _The config description must be updated if new configs are added or the default value of the configs are changed_ - _Any new feature or user-facing change requires updating the Hudi website. Please create a Jira ticket, attach the ticket number here and follow the [instruction](https://hudi.apache.org/contribute/developer-setup#website) to make changes to the website._ ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8452: [HUDI-6077] Add more partition push down filters
hudi-bot commented on PR #8452: URL: https://github.com/apache/hudi/pull/8452#issuecomment-1539382645 ## CI report: * 6526a12287cc85865da640d23a9266d887e82eba Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16864) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16877) * 38071fbfee977489b4997fd386e6d183435a6cbe Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16964) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8669: [HUDI-5362] Rebase IncrementalRelation over HoodieBaseRelation
hudi-bot commented on PR #8669: URL: https://github.com/apache/hudi/pull/8669#issuecomment-1539373231 ## CI report: * 9b8fd1cd5d56d58fc52d334a54e326c405fadf53 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8668: [HUDI-3639] Add Proper Incremental Records FIltering support into Hudi's custom RDD
hudi-bot commented on PR #8668: URL: https://github.com/apache/hudi/pull/8668#issuecomment-1539373202 ## CI report: * f13c6675399e5ef6c4a64b276251ef7cbd7a7c84 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16963) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8660: [MINOR] Fix RunBootstrapProcedure doesn't has database default value
hudi-bot commented on PR #8660: URL: https://github.com/apache/hudi/pull/8660#issuecomment-1539373174 ## CI report: * b0f6290c6294d4857e4781dc83de2e626ed68f3a Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16930) * a8c869a89e0382f1d82eab51a73dac7b180b766a Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16961) * 07fff1ff35fd19d4abb39a184e17cc0683db770e UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8452: [HUDI-6077] Add more partition push down filters
hudi-bot commented on PR #8452: URL: https://github.com/apache/hudi/pull/8452#issuecomment-1539372872 ## CI report: * 6526a12287cc85865da640d23a9266d887e82eba Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16864) Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16877) * 38071fbfee977489b4997fd386e6d183435a6cbe UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8668: [HUDI-3639] Add Proper Incremental Records FIltering support into Hudi's custom RDD
hudi-bot commented on PR #8668: URL: https://github.com/apache/hudi/pull/8668#issuecomment-1539369241 ## CI report: * f13c6675399e5ef6c4a64b276251ef7cbd7a7c84 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8666: [HUDI-915] Add missing partititonpath to records COW
hudi-bot commented on PR #8666: URL: https://github.com/apache/hudi/pull/8666#issuecomment-1539369207 ## CI report: * 5d1b90a6e91fbfe1229556377831d0c52d9c7613 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16956) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on a diff in pull request #8452: [HUDI-6077] Add more partition push down filters
bvaradar commented on code in PR #8452:
URL: https://github.com/apache/hudi/pull/8452#discussion_r1186777672
##
hudi-common/src/main/java/org/apache/hudi/expression/Expression.java:
##
@@ -40,14 +51,19 @@ public enum Operator {
}
}
- private final List children;
+ List getChildren();
Review Comment:
Make this and getDataType protected
##
hudi-common/src/main/java/org/apache/hudi/metadata/FileSystemBackedTableMetadata.java:
##
@@ -112,6 +164,17 @@ private List getPartitionPathWithPathPrefix(String
relativePathPrefix) t
}, listingParallelism);
pathsToList.clear();
+ Expression boundedExpr;
Review Comment:
Please add descriptive comment for this block.
##
hudi-common/src/main/java/org/apache/hudi/metadata/FileSystemBackedTableMetadata.java:
##
@@ -95,11 +120,38 @@ public List
getPartitionPathWithPathPrefixes(List relativePathPr
}).collect(Collectors.toList());
}
+ private int getRelativePathPartitionLevel(Types.RecordType partitionFields,
String relativePathPrefix) {
+if (StringUtils.isNullOrEmpty(relativePathPrefix) || partitionFields ==
null || partitionFields.fields().size() == 1) {
+ return 0;
+}
+
+int level = 0;
+for (int i = 1; i < relativePathPrefix.length() - 1; i++) {
Review Comment:
Can we use partitionFields.size to find the level ?
##
hudi-common/src/main/java/org/apache/hudi/expression/BindVisitor.java:
##
@@ -0,0 +1,179 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.hudi.expression;
+
+import org.apache.hudi.internal.schema.Types;
+
+import java.util.List;
+import java.util.stream.Collectors;
+
+public class BindVisitor implements ExpressionVisitor {
+
+ protected final Types.RecordType recordType;
+ protected final boolean caseSensitive;
+
+ public BindVisitor(Types.RecordType recordType, boolean caseSensitive) {
+this.recordType = recordType;
+this.caseSensitive = caseSensitive;
+ }
+
+ @Override
+ public Expression alwaysTrue() {
+return Predicates.True.get();
+ }
+
+ @Override
+ public Expression alwaysFalse() {
+return Predicates.False.get();
+ }
+
+ @Override
+ public Expression visitAnd(Predicates.And and) {
+if (and.getLeft() instanceof Predicates.False
+|| and.getRight() instanceof Predicates.False) {
+ return alwaysFalse();
+}
+
+Expression left = and.getLeft().accept(this);
+Expression right = and.getRight().accept(this);
+if (left instanceof Predicates.False
+|| right instanceof Predicates.False) {
+ return alwaysFalse();
+}
+
+if (left instanceof Predicates.True
+&& right instanceof Predicates.True) {
+ return alwaysTrue();
+}
+
+if (left instanceof Predicates.True) {
+ return right;
+}
+
+if (right instanceof Predicates.True) {
+ return left;
+}
+
+return Predicates.and(left, right);
+ }
+
+ @Override
+ public Expression visitOr(Predicates.Or or) {
+if (or.getLeft() instanceof Predicates.True
+|| or.getRight() instanceof Predicates.True) {
+ return alwaysTrue();
+}
+
+Expression left = or.getLeft().accept(this);
+Expression right = or.getRight().accept(this);
+if (left instanceof Predicates.True
+|| right instanceof Predicates.True) {
+ return alwaysTrue();
+}
+
+if (left instanceof Predicates.False
+&& right instanceof Predicates.False) {
+ return alwaysFalse();
+}
+
+if (left instanceof Predicates.False) {
+ return right;
+}
+
+if (right instanceof Predicates.False) {
+ return left;
+}
+
+return Predicates.or(left, right);
+ }
+
+ @Override
+ public Expression visitLiteral(Literal literal) {
+return literal;
+ }
+
+ @Override
+ public Expression visitNameReference(NameReference attribute) {
+// TODO Should consider caseSensitive?
Review Comment:
Yes, case insensitive by default would make it consistent with spark sql.
For this , I think it would be ok to introduce a config for case sensitivity
and align it with spark.sql.caseSensitive config in the hudi-spark integration.
[GitHub] [hudi] boneanxs commented on pull request #8076: [HUDI-5884] Support bulk_insert for insert_overwrite and insert_overwrite_table
boneanxs commented on PR #8076: URL: https://github.com/apache/hudi/pull/8076#issuecomment-1539365438 Hi @codope @stream2000 Gentle ping... Could you please take a look again? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] boneanxs commented on a diff in pull request #8669: [HUDI-5362] Rebase IncrementalRelation over HoodieBaseRelation
boneanxs commented on code in PR #8669:
URL: https://github.com/apache/hudi/pull/8669#discussion_r1188092438
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/IncrementalRelation.scala:
##
@@ -17,281 +17,82 @@
package org.apache.hudi
-import org.apache.avro.Schema
-import org.apache.hadoop.fs.{GlobPattern, Path}
-import org.apache.hudi.HoodieBaseRelation.isSchemaEvolutionEnabledOnRead
-import org.apache.hudi.client.common.HoodieSparkEngineContext
-import org.apache.hudi.client.utils.SparkInternalSchemaConverter
-import org.apache.hudi.common.fs.FSUtils
-import org.apache.hudi.common.model.{HoodieCommitMetadata, HoodieFileFormat,
HoodieRecord, HoodieReplaceCommitMetadata}
-import org.apache.hudi.common.table.timeline.{HoodieInstant, HoodieTimeline}
-import org.apache.hudi.common.table.{HoodieTableMetaClient,
TableSchemaResolver}
-import org.apache.hudi.common.util.{HoodieTimer, InternalSchemaCache}
-import org.apache.hudi.config.HoodieWriteConfig
-import org.apache.hudi.exception.HoodieException
-import org.apache.hudi.internal.schema.InternalSchema
-import org.apache.hudi.internal.schema.utils.SerDeHelper
-import org.apache.hudi.table.HoodieSparkTable
-import org.apache.spark.api.java.JavaSparkContext
+import org.apache.hudi.common.table.timeline.HoodieTimeline
+import org.apache.hudi.common.table.view.HoodieTableFileSystemView
+import org.apache.hudi.common.table.HoodieTableMetaClient
+import
org.apache.hudi.hadoop.utils.HoodieInputFormatUtils.getWritePartitionPaths
import org.apache.spark.rdd.RDD
-import
org.apache.spark.sql.execution.datasources.parquet.HoodieParquetFileFormat
-import org.apache.spark.sql.sources.{BaseRelation, TableScan}
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.Expression
+import org.apache.spark.sql.sources.Filter
import org.apache.spark.sql.types.StructType
-import org.apache.spark.sql.{DataFrame, Row, SQLContext}
-import org.slf4j.LoggerFactory
+import org.apache.spark.sql.SQLContext
-import scala.collection.JavaConversions._
-import scala.collection.mutable
+import scala.collection.JavaConverters._
/**
* Relation, that implements the Hoodie incremental view.
*
* Implemented for Copy_on_write storage.
- * TODO: rebase w/ HoodieBaseRelation HUDI-5362
*
*/
-class IncrementalRelation(val sqlContext: SQLContext,
- val optParams: Map[String, String],
- val userSchema: Option[StructType],
- val metaClient: HoodieTableMetaClient) extends
BaseRelation with TableScan {
-
- private val log = LoggerFactory.getLogger(classOf[IncrementalRelation])
-
- val skeletonSchema: StructType = HoodieSparkUtils.getMetaSchema
- private val basePath = metaClient.getBasePathV2
- // TODO : Figure out a valid HoodieWriteConfig
- private val hoodieTable =
HoodieSparkTable.create(HoodieWriteConfig.newBuilder().withPath(basePath.toString).build(),
-new HoodieSparkEngineContext(new
JavaSparkContext(sqlContext.sparkContext)),
-metaClient)
- private val commitTimeline =
hoodieTable.getMetaClient.getCommitTimeline.filterCompletedInstants()
-
- private val useStateTransitionTime =
optParams.get(DataSourceReadOptions.READ_BY_STATE_TRANSITION_TIME.key)
-.map(_.toBoolean)
-
.getOrElse(DataSourceReadOptions.READ_BY_STATE_TRANSITION_TIME.defaultValue)
-
- if (commitTimeline.empty()) {
-throw new HoodieException("No instants to incrementally pull")
- }
- if (!optParams.contains(DataSourceReadOptions.BEGIN_INSTANTTIME.key)) {
-throw new HoodieException(s"Specify the begin instant time to pull from
using " +
- s"option ${DataSourceReadOptions.BEGIN_INSTANTTIME.key}")
+case class IncrementalRelation(override val sqlContext: SQLContext,
+ override val optParams: Map[String, String],
+ private val userSchema: Option[StructType],
+ override val metaClient: HoodieTableMetaClient,
+ private val prunedDataSchema:
Option[StructType] = None)
+ extends AbstractBaseFileOnlyRelation(sqlContext, metaClient, optParams,
userSchema, Seq(), prunedDataSchema)
+with HoodieIncrementalRelationTrait {
+
+ override type Relation = IncrementalRelation
+
+ override def imbueConfigs(sqlContext: SQLContext): Unit = {
+super.imbueConfigs(sqlContext)
+// TODO(HUDI-3639) vectorized reader has to be disabled to make sure
IncrementalRelation is working properly
+
sqlContext.sparkSession.sessionState.conf.setConfString("spark.sql.parquet.enableVectorizedReader",
"false")
}
-
- if (!metaClient.getTableConfig.populateMetaFields()) {
-throw new HoodieException("Incremental queries are not supported when meta
fields are disabled")
- }
-
- val useEndInstantSchema =
optParams.getOrElse(DataSourceReadOptions.INCREMENTAL_READ_SCHEMA_USE_END_INSTANTTIME.key,
-
[GitHub] [hudi] boneanxs commented on a diff in pull request #8669: [HUDI-5362] Rebase IncrementalRelation over HoodieBaseRelation
boneanxs commented on code in PR #8669:
URL: https://github.com/apache/hudi/pull/8669#discussion_r1188092438
##
hudi-spark-datasource/hudi-spark-common/src/main/scala/org/apache/hudi/IncrementalRelation.scala:
##
@@ -17,281 +17,82 @@
package org.apache.hudi
-import org.apache.avro.Schema
-import org.apache.hadoop.fs.{GlobPattern, Path}
-import org.apache.hudi.HoodieBaseRelation.isSchemaEvolutionEnabledOnRead
-import org.apache.hudi.client.common.HoodieSparkEngineContext
-import org.apache.hudi.client.utils.SparkInternalSchemaConverter
-import org.apache.hudi.common.fs.FSUtils
-import org.apache.hudi.common.model.{HoodieCommitMetadata, HoodieFileFormat,
HoodieRecord, HoodieReplaceCommitMetadata}
-import org.apache.hudi.common.table.timeline.{HoodieInstant, HoodieTimeline}
-import org.apache.hudi.common.table.{HoodieTableMetaClient,
TableSchemaResolver}
-import org.apache.hudi.common.util.{HoodieTimer, InternalSchemaCache}
-import org.apache.hudi.config.HoodieWriteConfig
-import org.apache.hudi.exception.HoodieException
-import org.apache.hudi.internal.schema.InternalSchema
-import org.apache.hudi.internal.schema.utils.SerDeHelper
-import org.apache.hudi.table.HoodieSparkTable
-import org.apache.spark.api.java.JavaSparkContext
+import org.apache.hudi.common.table.timeline.HoodieTimeline
+import org.apache.hudi.common.table.view.HoodieTableFileSystemView
+import org.apache.hudi.common.table.HoodieTableMetaClient
+import
org.apache.hudi.hadoop.utils.HoodieInputFormatUtils.getWritePartitionPaths
import org.apache.spark.rdd.RDD
-import
org.apache.spark.sql.execution.datasources.parquet.HoodieParquetFileFormat
-import org.apache.spark.sql.sources.{BaseRelation, TableScan}
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.Expression
+import org.apache.spark.sql.sources.Filter
import org.apache.spark.sql.types.StructType
-import org.apache.spark.sql.{DataFrame, Row, SQLContext}
-import org.slf4j.LoggerFactory
+import org.apache.spark.sql.SQLContext
-import scala.collection.JavaConversions._
-import scala.collection.mutable
+import scala.collection.JavaConverters._
/**
* Relation, that implements the Hoodie incremental view.
*
* Implemented for Copy_on_write storage.
- * TODO: rebase w/ HoodieBaseRelation HUDI-5362
*
*/
-class IncrementalRelation(val sqlContext: SQLContext,
- val optParams: Map[String, String],
- val userSchema: Option[StructType],
- val metaClient: HoodieTableMetaClient) extends
BaseRelation with TableScan {
-
- private val log = LoggerFactory.getLogger(classOf[IncrementalRelation])
-
- val skeletonSchema: StructType = HoodieSparkUtils.getMetaSchema
- private val basePath = metaClient.getBasePathV2
- // TODO : Figure out a valid HoodieWriteConfig
- private val hoodieTable =
HoodieSparkTable.create(HoodieWriteConfig.newBuilder().withPath(basePath.toString).build(),
-new HoodieSparkEngineContext(new
JavaSparkContext(sqlContext.sparkContext)),
-metaClient)
- private val commitTimeline =
hoodieTable.getMetaClient.getCommitTimeline.filterCompletedInstants()
-
- private val useStateTransitionTime =
optParams.get(DataSourceReadOptions.READ_BY_STATE_TRANSITION_TIME.key)
-.map(_.toBoolean)
-
.getOrElse(DataSourceReadOptions.READ_BY_STATE_TRANSITION_TIME.defaultValue)
-
- if (commitTimeline.empty()) {
-throw new HoodieException("No instants to incrementally pull")
- }
- if (!optParams.contains(DataSourceReadOptions.BEGIN_INSTANTTIME.key)) {
-throw new HoodieException(s"Specify the begin instant time to pull from
using " +
- s"option ${DataSourceReadOptions.BEGIN_INSTANTTIME.key}")
+case class IncrementalRelation(override val sqlContext: SQLContext,
+ override val optParams: Map[String, String],
+ private val userSchema: Option[StructType],
+ override val metaClient: HoodieTableMetaClient,
+ private val prunedDataSchema:
Option[StructType] = None)
+ extends AbstractBaseFileOnlyRelation(sqlContext, metaClient, optParams,
userSchema, Seq(), prunedDataSchema)
+with HoodieIncrementalRelationTrait {
+
+ override type Relation = IncrementalRelation
+
+ override def imbueConfigs(sqlContext: SQLContext): Unit = {
+super.imbueConfigs(sqlContext)
+// TODO(HUDI-3639) vectorized reader has to be disabled to make sure
IncrementalRelation is working properly
+
sqlContext.sparkSession.sessionState.conf.setConfString("spark.sql.parquet.enableVectorizedReader",
"false")
}
-
- if (!metaClient.getTableConfig.populateMetaFields()) {
-throw new HoodieException("Incremental queries are not supported when meta
fields are disabled")
- }
-
- val useEndInstantSchema =
optParams.getOrElse(DataSourceReadOptions.INCREMENTAL_READ_SCHEMA_USE_END_INSTANTTIME.key,
-
[GitHub] [hudi] tomyanth opened a new issue, #8670: [SUPPORT] Hudi cannot multi-write referring to case #7653
tomyanth opened a new issue, #8670:
URL: https://github.com/apache/hudi/issues/8670
**Describe the problem you faced**
Actually I raise my issues under case #7653 because I have almost the same
issue with that original question which is
java.util.ConcurrentModificationException: Cannot resolve conflicts for
overlapping writes
**To Reproduce**
Steps to reproduce the behavior:
1. Run 2 hudi job to write the same location to simulate the process of
multi write
2. If set to overwrite, both job fails
3. If set to append, at most one job succeed.
4. With or without the multi-write setting suggest below, at most only one
job succeed but the error message is different
hudi_options = {
'hoodie.table.name': table_name,
'hoodie.datasource.write.recordkey.field': 'emp_id',
'hoodie.datasource.write.table.name': table_name,
'hoodie.datasource.write.operation': 'upsert',
'hoodie.datasource.write.precombine.field': 'ts',
'hoodie.upsert.shuffle.parallelism': 2,
'hoodie.insert.shuffle.parallelism': 2,
'hoodie.schema.on.read.enable' : 'true', # for changing column names
'hoodie.write.concurrency.mode':'optimistic_concurrency_control',
#added for zookeeper to deal with multiple source writes
'hoodie.cleaner.policy.failed.writes':'LAZY',
#
'hoodie.write.lock.provider':'org.apache.hudi.client.transaction.lock.FileSystemBasedLockProvider',
'hoodie.write.lock.provider':'org.apache.hudi.client.transaction.lock.ZookeeperBasedLockProvider',
'hoodie.write.lock.zookeeper.url':'localhost',
'hoodie.write.lock.zookeeper.port':'2181',
'hoodie.write.lock.zookeeper.lock_key':'my_lock',
'hoodie.write.lock.zookeeper.base_path':'/hudi_locks',
}
**Expected behavior**
I expect at least FileSystemBasedLockProvider wll be able to perform
multi-write but unfortunately the same error message
java.util.ConcurrentModificationException: Cannot resolve conflicts for
overlapping writes always pops up.
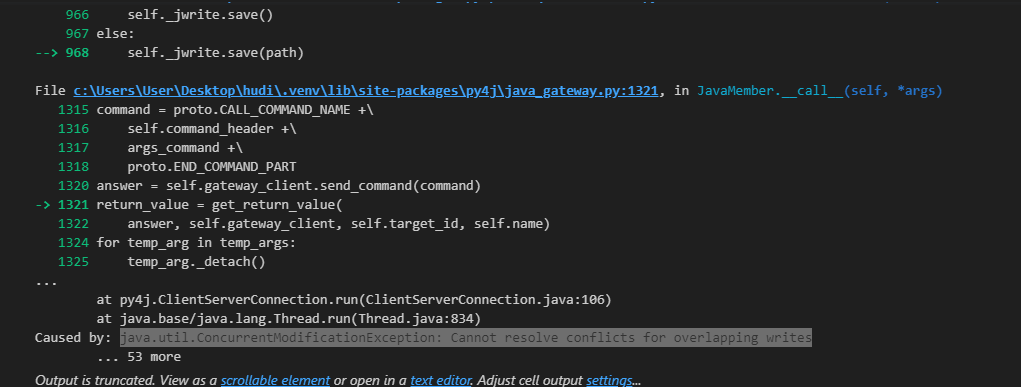
Code run
"""
Install
https://dlcdn.apache.org/spark/spark-3.3.1/spark-3.3.1-bin-hadoop2.tgz
hadoop2.7
https://github.com/soumilshah1995/winutils/blob/master/hadoop-2.7.7/bin/winutils.exe
pyspark --packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.1 --conf
'spark.serializer=org.apache.spark.serializer.KryoSerializer'
VAR
SPARK_HOME
HADOOP_HOME
PATH
`%HAPOOP_HOME%\bin`
`%SPARK_HOME%\bin`
Complete Tutorials on HUDI
https://github.com/soumilshah1995/Insert-Update-Read-Write-SnapShot-Time-Travel-incremental-Query-on-APache-Hudi-transacti/blob/main/hudi%20(1).ipynb
"""
import os
import sys
import uuid
import pyspark
from pyspark.sql import SparkSession
from pyspark import SparkConf, SparkContext
from pyspark.sql.functions import col, asc, desc
from pyspark.sql.functions import col, to_timestamp,
monotonically_increasing_id, to_date, when
from pyspark.sql.functions import *
from pyspark.sql.types import *
from datetime import datetime
from functools import reduce
from faker import Faker
from faker import Faker
import findspark
import datetime
time = datetime.datetime.now()
time = time.strftime("YMD%Y%m%dHHMMSSms%H%M%S%f")
SUBMIT_ARGS = "--packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.1
pyspark-shell"
os.environ["PYSPARK_SUBMIT_ARGS"] = SUBMIT_ARGS
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executable
findspark.init()
spark = SparkSession.builder\
.config('spark.serializer',
'org.apache.spark.serializer.KryoSerializer') \
.config('className', 'org.apache.hudi') \
.config('spark.sql.hive.convertMetastoreParquet', 'false') \
.config('spark.sql.extensions',
'org.apache.spark.sql.hudi.HoodieSparkSessionExtension') \
.config('spark.sql.warehouse.dir', 'file:///C:/tmp/spark_warehouse') \
.getOrCreate()
global faker
faker = Faker()
class DataGenerator(object):
@staticmethod
def get_data():
return [
(
x,
faker.name(),
faker.random_element(elements=('IT', 'HR', 'Sales',
'Marketing')),
faker.random_element(elements=('CA', 'NY', 'TX', 'FL', 'IL',
'RJ')),
faker.random_int(min=1, max=15),
faker.random_int(min=18, max=60),
faker.random_int(min=0, max=10),
faker.unix_time()
) for x in range(5)
]
data = DataGenerator.get_data()
columns = ["emp_id", "employee_name",
[jira] [Updated] (HUDI-5362) Rebase IncrementalRelation over HoodieBaseRelation
[ https://issues.apache.org/jira/browse/HUDI-5362?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-5362: - Labels: pull-request-available (was: ) > Rebase IncrementalRelation over HoodieBaseRelation > -- > > Key: HUDI-5362 > URL: https://issues.apache.org/jira/browse/HUDI-5362 > Project: Apache Hudi > Issue Type: Improvement > Components: reader-core >Reporter: sivabalan narayanan >Priority: Major > Labels: pull-request-available > > We need to rebase IncrementalRelation over HoodieBaseRelation. As of now, its > based of of BaseRelation. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] boneanxs opened a new pull request, #8669: [HUDI-5362] Rebase IncrementalRelation over HoodieBaseRelation
boneanxs opened a new pull request, #8669: URL: https://github.com/apache/hudi/pull/8669 ### Change Logs _Describe context and summary for this change. Highlight if any code was copied._ Rebase IncrementalRelation over HoodieBaseRelation ### Impact _Describe any public API or user-facing feature change or any performance impact._ None. ### Risk level (write none, low medium or high below) _If medium or high, explain what verification was done to mitigate the risks._ none. ### Documentation Update _Describe any necessary documentation update if there is any new feature, config, or user-facing change_ - _The config description must be updated if new configs are added or the default value of the configs are changed_ - _Any new feature or user-facing change requires updating the Hudi website. Please create a Jira ticket, attach the ticket number here and follow the [instruction](https://hudi.apache.org/contribute/developer-setup#website) to make changes to the website._ ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8082: [HUDI-5868] Upgrade Spark to 3.3.2
danny0405 commented on code in PR #8082:
URL: https://github.com/apache/hudi/pull/8082#discussion_r1188080016
##
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/io/storage/HoodieSparkFileReaderFactory.java:
##
@@ -33,6 +33,8 @@ protected HoodieFileReader newParquetFileReader(Configuration
conf, Path path) {
conf.setIfUnset(SQLConf.PARQUET_BINARY_AS_STRING().key(),
SQLConf.PARQUET_BINARY_AS_STRING().defaultValueString());
conf.setIfUnset(SQLConf.PARQUET_INT96_AS_TIMESTAMP().key(),
SQLConf.PARQUET_INT96_AS_TIMESTAMP().defaultValueString());
conf.setIfUnset(SQLConf.CASE_SENSITIVE().key(),
SQLConf.CASE_SENSITIVE().defaultValueString());
+// Using string value of this conf to preserve compatibility across spark
versions.
+conf.setIfUnset("spark.sql.legacy.parquet.nanosAsLong", "false");
Review Comment:
No need to do that.
##
hudi-spark-datasource/hudi-spark3.2plus-common/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/Spark32PlusHoodieParquetFileFormat.scala:
##
@@ -95,7 +95,11 @@ class Spark32PlusHoodieParquetFileFormat(private val
shouldAppendPartitionValues
hadoopConf.setBoolean(
SQLConf.PARQUET_INT96_AS_TIMESTAMP.key,
sparkSession.sessionState.conf.isParquetINT96AsTimestamp)
-
+// Using string value of this conf to preserve compatibility across spark
versions.
+hadoopConf.setBoolean(
+ "spark.sql.legacy.parquet.nanosAsLong",
+
sparkSession.sessionState.conf.getConfString("spark.sql.legacy.parquet.nanosAsLong",
"false").toBoolean
Review Comment:
No need to do that.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8082: [HUDI-5868] Upgrade Spark to 3.3.2
danny0405 commented on code in PR #8082:
URL: https://github.com/apache/hudi/pull/8082#discussion_r1188080242
##
hudi-client/hudi-spark-client/src/main/scala/org/apache/hudi/HoodieSparkUtils.scala:
##
@@ -58,6 +58,7 @@ private[hudi] trait SparkVersionsSupport {
def gteqSpark3_2_1: Boolean = getSparkVersion >= "3.2.1"
def gteqSpark3_2_2: Boolean = getSparkVersion >= "3.2.2"
def gteqSpark3_3: Boolean = getSparkVersion >= "3.3"
+ def gteqSpark3_3_2: Boolean = getSparkVersion >= "3.3.2"
Review Comment:
Should be runtime, I think.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on pull request #8082: [HUDI-5868] Upgrade Spark to 3.3.2
danny0405 commented on PR #8082: URL: https://github.com/apache/hudi/pull/8082#issuecomment-1539339102 There was one failure in the CI: TestAvroSchemaResolutionSupport.testDataTypePromotions -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8659: [HUDI-6155] Fix cleaner based on hours for earliest commit to retain
danny0405 commented on code in PR #8659: URL: https://github.com/apache/hudi/pull/8659#discussion_r1188076995 ## hudi-common/src/main/java/org/apache/hudi/common/table/timeline/HoodieInstantTimeGenerator.java: ## @@ -94,7 +96,9 @@ public static Date parseDateFromInstantTime(String timestamp) throws ParseExcept } LocalDateTime dt = LocalDateTime.parse(timestampInMillis, MILLIS_INSTANT_TIME_FORMATTER); - return Date.from(dt.atZone(ZoneId.systemDefault()).toInstant()); + Instant instant = dt.atZone(getZoneId()).toInstant(); + TimeZone.setDefault(TimeZone.getTimeZone(getZoneId())); + return Date.from(instant); Review Comment: It is risky to set up timezone per JVM process: `TimeZone.setDefault(`, this could impact all the threads in the JVM. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-3639) [Incremental] Add Proper Incremental Records FIltering support into Hudi's custom RDD
[ https://issues.apache.org/jira/browse/HUDI-3639?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-3639: - Labels: pull-request-available (was: ) > [Incremental] Add Proper Incremental Records FIltering support into Hudi's > custom RDD > - > > Key: HUDI-3639 > URL: https://issues.apache.org/jira/browse/HUDI-3639 > Project: Apache Hudi > Issue Type: Bug >Reporter: Alexey Kudinkin >Priority: Critical > Labels: pull-request-available > Fix For: 0.13.1 > > > Currently, Hudi's `MergeOnReadIncrementalRelation` solely relies on > `ParquetFileReader` to do record-level filtering of the records that don't > belong to a timeline span being queried. > As a side-effect, Hudi actually have to disable the use of > [VectorizedParquetReader|https://jaceklaskowski.gitbooks.io/mastering-spark-sql/content/spark-sql-vectorized-parquet-reader.html] > (since using one would prevent records from being filtered by the Reader) > > Instead, we should make sure that proper record-level filtering is performed > w/in the returned RDD, instead of squarely relying on FileReader to do that. -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] cxzl25 opened a new pull request, #8668: [HUDI-3639] [Incremental] Add Proper Incremental Records FIltering support into Hudi's custom RDD
cxzl25 opened a new pull request, #8668: URL: https://github.com/apache/hudi/pull/8668 ### Change Logs Add the filter operator in `HoodieMergeOnReadRDD`, and ensure the accuracy of incremental query results when `spark.sql.parquet.recordLevelFilter.enabled=false` or `spark.sql.parquet.enableVectorizedReader=true` ### Impact Fix the scenario where the incremental query data may be wrong. https://github.com/apache/hudi/pull/5168#discussion_r1186728549 ### Risk level (write none, low medium or high below) ### Documentation Update ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8660: [MINOR] Fix RunBootstrapProcedure doesn't has database default value
hudi-bot commented on PR #8660: URL: https://github.com/apache/hudi/pull/8660#issuecomment-1539325879 ## CI report: * b0f6290c6294d4857e4781dc83de2e626ed68f3a Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16930) * a8c869a89e0382f1d82eab51a73dac7b180b766a Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16961) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on a diff in pull request #6176: [HUDI-4445] S3 Incremental source improvements
xushiyan commented on code in PR #6176:
URL: https://github.com/apache/hudi/pull/6176#discussion_r1188070807
##
hudi-common/src/test/java/org/apache/hudi/common/testutils/S3EventTestPayload.java:
##
@@ -0,0 +1,53 @@
+package org.apache.hudi.common.testutils;
+
+import org.apache.hudi.avro.MercifulJsonConverter;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.util.Option;
+
+import org.apache.avro.Schema;
+import org.apache.avro.generic.IndexedRecord;
+
+import java.io.IOException;
+import java.util.Map;
+
+/**
+ * Test payload for S3 event here
(https://docs.aws.amazon.com/AmazonS3/latest/userguide/notification-content-structure.html).
+ */
+public class S3EventTestPayload extends GenericTestPayload implements
HoodieRecordPayload {
Review Comment:
there is a lot of existing misused with the RawTripTestPayload see
https://issues.apache.org/jira/browse/HUDI-6164
so you may want to decouple the improvement changes from payload changes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8107: [HUDI-5514][HUDI-5574][HUDI-5604][HUDI-5535] Adding auto generation of record keys support to Hudi/Spark
hudi-bot commented on PR #8107: URL: https://github.com/apache/hudi/pull/8107#issuecomment-1539325235 ## CI report: * 780318c5f048c4bf69980ac47d10d5e23994a21b Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16954) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on a diff in pull request #6176: [HUDI-4445] S3 Incremental source improvements
xushiyan commented on code in PR #6176:
URL: https://github.com/apache/hudi/pull/6176#discussion_r1188069077
##
hudi-common/src/test/java/org/apache/hudi/common/testutils/S3EventTestPayload.java:
##
@@ -0,0 +1,53 @@
+package org.apache.hudi.common.testutils;
+
+import org.apache.hudi.avro.MercifulJsonConverter;
+import org.apache.hudi.common.model.HoodieRecordPayload;
+import org.apache.hudi.common.util.Option;
+
+import org.apache.avro.Schema;
+import org.apache.avro.generic.IndexedRecord;
+
+import java.io.IOException;
+import java.util.Map;
+
+/**
+ * Test payload for S3 event here
(https://docs.aws.amazon.com/AmazonS3/latest/userguide/notification-content-structure.html).
+ */
+public class S3EventTestPayload extends GenericTestPayload implements
HoodieRecordPayload {
Review Comment:
I'd suggest just test with DefaultHoodieRecordPayload with a specific S3
event schema, instead of creating a new test payload, as we want to test as
close as the real scenario. Besides, we don't couple payload with schema, as
payload is just responsible for how to merge
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on a diff in pull request #6176: [HUDI-4445] S3 Incremental source improvements
xushiyan commented on code in PR #6176:
URL: https://github.com/apache/hudi/pull/6176#discussion_r1188065909
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/sources/S3EventsHoodieIncrSource.java:
##
@@ -224,6 +232,6 @@ public Pair>, String>
fetchNextBatch(Option lastCkpt
}
LOG.debug("Extracted distinct files " + cloudFiles.size()
+ " and some samples " +
cloudFiles.stream().limit(10).collect(Collectors.toList()));
-return Pair.of(dataset, queryTypeAndInstantEndpts.getRight().getRight());
+return Pair.of(dataset, sourceMetadata.getRight());
}
-}
+}
Review Comment:
we should have the EOL
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on a diff in pull request #6176: [HUDI-4445] S3 Incremental source improvements
xushiyan commented on code in PR #6176:
URL: https://github.com/apache/hudi/pull/6176#discussion_r1188065742
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/sources/S3EventsHoodieIncrSource.java:
##
@@ -189,33 +194,36 @@ public Pair>, String>
fetchNextBatch(Option lastCkpt
.filter(filter)
.select("s3.bucket.name", "s3.object.key")
.distinct()
-.mapPartitions((MapPartitionsFunction) fileListIterator
-> {
+.rdd()
+// JavaRDD simplifies coding with collect and suitable mapPartitions
signature. check if this can be avoided.
+.toJavaRDD()
+.mapPartitions(fileListIterator -> {
Review Comment:
we usually prefer high level dataframe apis. how is it actually beneficial
to convert to rdd here? don't quite get the comment
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on a diff in pull request #6176: [HUDI-4445] S3 Incremental source improvements
xushiyan commented on code in PR #6176:
URL: https://github.com/apache/hudi/pull/6176#discussion_r1188064051
##
hudi-common/src/test/java/org/apache/hudi/common/testutils/GenericTestPayload.java:
##
@@ -0,0 +1,110 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.hudi.common.testutils;
+
+import org.apache.hudi.avro.MercifulJsonConverter;
+import org.apache.hudi.common.util.FileIOUtils;
+import org.apache.hudi.common.util.Option;
+
+import com.fasterxml.jackson.databind.ObjectMapper;
+import org.apache.avro.Schema;
+import org.apache.avro.generic.IndexedRecord;
+
+import java.io.ByteArrayInputStream;
+import java.io.ByteArrayOutputStream;
+import java.io.IOException;
+import java.util.Map;
+import java.util.zip.Deflater;
+import java.util.zip.DeflaterOutputStream;
+import java.util.zip.InflaterInputStream;
+
+/**
+ * Generic class for specific payload implementations to inherit from.
+ */
+public abstract class GenericTestPayload {
Review Comment:
unsure about the necessity of creating a parent payload in tests. we need
just different types of payload to use directly, be it json, avro, spark, etc.
we should make test utils/models more straightforward
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8631: [HUDI-6170] Use correct zone id while calculating earliestTimeToRetain
danny0405 commented on code in PR #8631:
URL: https://github.com/apache/hudi/pull/8631#discussion_r1188063597
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/clean/CleanPlanner.java:
##
@@ -510,7 +510,7 @@ public Option getEarliestCommitToRetain() {
}
} else if (config.getCleanerPolicy() ==
HoodieCleaningPolicy.KEEP_LATEST_BY_HOURS) {
Instant instant = Instant.now();
- ZonedDateTime currentDateTime = ZonedDateTime.ofInstant(instant,
ZoneId.systemDefault());
+ ZonedDateTime currentDateTime = ZonedDateTime.ofInstant(instant,
HoodieInstantTimeGenerator.getTimelineTimeZone().getZoneId());
String earliestTimeToRetain =
HoodieActiveTimeline.formatDate(Date.from(currentDateTime.minusHours(hoursRetained).toInstant()));
Review Comment:
Yeah, that means the code is prone to making misusages, let's fix all those
test falures by initialzing the zoneId manually.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8631: [HUDI-6170] Use correct zone id while calculating earliestTimeToRetain
danny0405 commented on code in PR #8631:
URL: https://github.com/apache/hudi/pull/8631#discussion_r1188063597
##
hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/action/clean/CleanPlanner.java:
##
@@ -510,7 +510,7 @@ public Option getEarliestCommitToRetain() {
}
} else if (config.getCleanerPolicy() ==
HoodieCleaningPolicy.KEEP_LATEST_BY_HOURS) {
Instant instant = Instant.now();
- ZonedDateTime currentDateTime = ZonedDateTime.ofInstant(instant,
ZoneId.systemDefault());
+ ZonedDateTime currentDateTime = ZonedDateTime.ofInstant(instant,
HoodieInstantTimeGenerator.getTimelineTimeZone().getZoneId());
String earliestTimeToRetain =
HoodieActiveTimeline.formatDate(Date.from(currentDateTime.minusHours(hoursRetained).toInstant()));
Review Comment:
Yeah, that means the code is prune to making misusages, let's fix all those
test falures by initialzing the zoneId manually.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] xushiyan commented on a diff in pull request #6176: [HUDI-4445] S3 Incremental source improvements
xushiyan commented on code in PR #6176:
URL: https://github.com/apache/hudi/pull/6176#discussion_r1188063109
##
hudi-common/src/test/java/org/apache/hudi/common/testutils/GenericTestPayload.java:
##
@@ -0,0 +1,110 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.hudi.common.testutils;
+
+import org.apache.hudi.avro.MercifulJsonConverter;
+import org.apache.hudi.common.util.FileIOUtils;
+import org.apache.hudi.common.util.Option;
+
+import com.fasterxml.jackson.databind.ObjectMapper;
+import org.apache.avro.Schema;
+import org.apache.avro.generic.IndexedRecord;
+
+import java.io.ByteArrayInputStream;
+import java.io.ByteArrayOutputStream;
+import java.io.IOException;
+import java.util.Map;
+import java.util.zip.Deflater;
+import java.util.zip.DeflaterOutputStream;
+import java.util.zip.InflaterInputStream;
+
+/**
+ * Generic class for specific payload implementations to inherit from.
+ */
+public abstract class GenericTestPayload {
+
+ protected static final transient ObjectMapper OBJECT_MAPPER = new
ObjectMapper();
+ protected String partitionPath;
+ protected String rowKey;
+ protected byte[] jsonDataCompressed;
+ protected int dataSize;
+ protected boolean isDeleted;
+ protected Comparable orderingVal;
+
+ public GenericTestPayload(Option jsonData, String rowKey, String
partitionPath, String schemaStr,
+Boolean isDeleted, Comparable orderingVal) throws
IOException {
+if (jsonData.isPresent()) {
+ this.jsonDataCompressed = compressData(jsonData.get());
+ this.dataSize = jsonData.get().length();
+}
+this.rowKey = rowKey;
+this.partitionPath = partitionPath;
+this.isDeleted = isDeleted;
+this.orderingVal = orderingVal;
+ }
+
+ public GenericTestPayload(String jsonData, String rowKey, String
partitionPath, String schemaStr) throws IOException {
+this(Option.of(jsonData), rowKey, partitionPath, schemaStr, false, 0L);
+ }
+
+ public GenericTestPayload(String jsonData) throws IOException {
+this.jsonDataCompressed = compressData(jsonData);
+this.dataSize = jsonData.length();
+Map jsonRecordMap = OBJECT_MAPPER.readValue(jsonData,
Map.class);
+this.rowKey = jsonRecordMap.get("_row_key").toString();
+this.partitionPath =
jsonRecordMap.get("time").toString().split("T")[0].replace("-", "/");
Review Comment:
i recall this logic has been refactored in the current `RawTripTestPayload`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8665: [HUDI-6190] Fix the default value of RECORD_KEY_FIELD.
danny0405 commented on code in PR #8665:
URL: https://github.com/apache/hudi/pull/8665#discussion_r1188062501
##
hudi-flink-datasource/hudi-flink/src/main/java/org/apache/hudi/configuration/FlinkOptions.java:
##
@@ -411,7 +411,7 @@ private FlinkOptions() {
public static final ConfigOption RECORD_KEY_FIELD = ConfigOptions
.key(KeyGeneratorOptions.RECORDKEY_FIELD_NAME.key())
.stringType()
- .defaultValue("uuid")
+ .defaultValue("")
Review Comment:
Yeah, but make sure to go through the validations in `HoodieTableFactory` to
keep the validity.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[hudi] branch master updated: [MINOR][DOC][hudi-metaserver] Fix typos in README.md (#8536)
This is an automated email from the ASF dual-hosted git repository.
danny0405 pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/master by this push:
new 76a3e0ea863 [MINOR][DOC][hudi-metaserver] Fix typos in README.md
(#8536)
76a3e0ea863 is described below
commit 76a3e0ea8634342f0048766199baea5fc618221d
Author: Brisk Wong <2367785...@qq.com>
AuthorDate: Tue May 9 10:47:58 2023 +0800
[MINOR][DOC][hudi-metaserver] Fix typos in README.md (#8536)
Fix typos and format text-blocks properly.
---
hudi-platform-service/hudi-metaserver/README.md | 8
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/hudi-platform-service/hudi-metaserver/README.md
b/hudi-platform-service/hudi-metaserver/README.md
index a7802e55891..a1d59597491 100644
--- a/hudi-platform-service/hudi-metaserver/README.md
+++ b/hudi-platform-service/hudi-metaserver/README.md
@@ -39,10 +39,10 @@ Attention: Apple m1 cannot install thrift by docker
successfully. The script wil
### Source code generated by Thrift
-After packaging, the generated source code are placed in
`target/generated-sources/thrift/gen-java`.
+After packaging, the generated source code are placed in
`target/generated-sources/gen-java`.
It looks like,
-```shell
+```text
├── gen-java
│ └── org
│ └── apache
@@ -59,7 +59,7 @@ It looks like,
### Start Hudi Metaserver
1. modify the `hikariPool.properties` and config the mysql address. For
example,
-```text
+```properties
jdbcUrl=jdbc:mysql://localhost:3306
dataSource.user=root
dataSource.password=password
@@ -73,7 +73,7 @@ sh start_hudi_metaserver.sh
### Write client configurations
-```shell
+```properties
hoodie.database.name=default
hoodie.table.name=test
hoodie.base.path=${path}
[GitHub] [hudi] danny0405 merged pull request #8536: [MINOR](hudi-metaserver) fix typos in README.md
danny0405 merged PR #8536: URL: https://github.com/apache/hudi/pull/8536 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on pull request #8657: [HUDI-6150] Support bucketing for each hive client
danny0405 commented on PR #8657: URL: https://github.com/apache/hudi/pull/8657#issuecomment-1539309061 > - hashing - file naming - file numbering - file sorting Can you elaborate a little more about these items? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8660: [MINOR] Fix RunBootstrapProcedure doesn't has database default value
danny0405 commented on code in PR #8660:
URL: https://github.com/apache/hudi/pull/8660#discussion_r1188059660
##
hudi-spark-datasource/hudi-spark/src/main/scala/org/apache/spark/sql/hudi/command/procedures/RunBootstrapProcedure.scala:
##
@@ -110,9 +111,7 @@ class RunBootstrapProcedure extends BaseProcedure with
ProcedureBuilder with Log
val cfg = new BootstrapExecutorUtils.Config()
cfg.setTableName(tableName)
-if (database.isDefined) {
- cfg.setDatabase(database.get)
-}
+cfg.setDatabase(database.getOrElse(HIVE_DATABASE.defaultValue()))
cfg.setTableType(tableType)
Review Comment:
I think so. Using the session database name makes more sense.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] bigdata-spec commented on issue #8662: [SUPPORT]Spark on K8s can not stop pod by setting set hoodie.write.concurrency.mode=optimistic_concurrency_control;
bigdata-spec commented on issue #8662: URL: https://github.com/apache/hudi/issues/8662#issuecomment-1539307536  I try use [ hoodie.write.lock.provider=org.apache.hudi.client.transaction.lock.FileSystemBasedLockProvider](url) pod can stop normal. `hoodie.write.lock.filesystem.path` I not use this conf, what should I set this hoodie.write.lock.filesystem.path? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on a diff in pull request #8664: [HUDI-6189] Reuse the `timeline` supplied in predefined variable or parameter
danny0405 commented on code in PR #8664:
URL: https://github.com/apache/hudi/pull/8664#discussion_r1188058295
##
hudi-common/src/main/java/org/apache/hudi/common/table/view/FileSystemViewManager.java:
##
@@ -162,29 +162,28 @@ private static SpillableMapBasedFileSystemView
createSpillableMapBasedFileSystem
*/
private static HoodieTableFileSystemView
createInMemoryFileSystemView(HoodieMetadataConfig metadataConfig,
FileSystemViewStorageConfig viewConf,
HoodieTableMetaClient metaClient, SerializableSupplier
metadataSupplier) {
-LOG.info("Creating InMemory based view for basePath " +
metaClient.getBasePath());
+LOG.info("Creating InMemory based view for basePath " +
metaClient.getBasePathV2());
HoodieTimeline timeline =
metaClient.getActiveTimeline().filterCompletedAndCompactionInstants();
if (metadataConfig.enabled()) {
ValidationUtils.checkArgument(metadataSupplier != null, "Metadata
supplier is null. Cannot instantiate metadata file system view");
- return new HoodieMetadataFileSystemView(metaClient,
metaClient.getActiveTimeline().filterCompletedAndCompactionInstants(),
- metadataSupplier.get());
+ return new HoodieMetadataFileSystemView(metaClient, timeline,
metadataSupplier.get());
}
if (metaClient.getMetaserverConfig().isMetaserverEnabled()) {
return (HoodieTableFileSystemView)
ReflectionUtils.loadClass(HOODIE_METASERVER_FILE_SYSTEM_VIEW_CLASS,
new Class[] {HoodieTableMetaClient.class, HoodieTimeline.class,
HoodieMetaserverConfig.class},
- metaClient,
metaClient.getActiveTimeline().getCommitsTimeline().filterCompletedInstants(),
metaClient.getMetaserverConfig());
+ metaClient, timeline, metaClient.getMetaserverConfig());
Review Comment:
Yeah, I agree.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] danny0405 commented on pull request #7627: [HUDI-5517] HoodieTimeline support filter instants by state transition time
danny0405 commented on PR #7627: URL: https://github.com/apache/hudi/pull/7627#issuecomment-1539304963 Nice findings, we already format the instant time to milli-seconds, so yeah, when the precision is lost, the sequence may break. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8660: [MINOR] Fix RunBootstrapProcedure doesn't has database default value
hudi-bot commented on PR #8660: URL: https://github.com/apache/hudi/pull/8660#issuecomment-1539299266 ## CI report: * b0f6290c6294d4857e4781dc83de2e626ed68f3a Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16930) * a8c869a89e0382f1d82eab51a73dac7b180b766a UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7355: [HUDI-5308] Hive3 query returns null when the where clause has a partition field
hudi-bot commented on PR #7355: URL: https://github.com/apache/hudi/pull/7355#issuecomment-1539298118 ## CI report: * 3abe97c6786171235255fe5c80433db10049c019 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16937) * 2aed142f0880e462346ad694bb2dcdb435891f95 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16960) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7355: [HUDI-5308] Hive3 query returns null when the where clause has a partition field
hudi-bot commented on PR #7355: URL: https://github.com/apache/hudi/pull/7355#issuecomment-1539293897 ## CI report: * 3abe97c6786171235255fe5c80433db10049c019 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16937) * 2aed142f0880e462346ad694bb2dcdb435891f95 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8082: [HUDI-5868] Upgrade Spark to 3.3.2
hudi-bot commented on PR #8082: URL: https://github.com/apache/hudi/pull/8082#issuecomment-1539289962 ## CI report: * f43a772d2efe7d19657b44d2ce8b92b8fcee390f UNKNOWN * b6a62994325c4b1110a265262a56da1a94e1f6e2 UNKNOWN * b285ca4f163dc720d061cfa9ade88aefed49dff1 Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16953) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] littleeleventhwolf commented on pull request #8536: [MINOR](hudi-metaserver) fix typos in README.md
littleeleventhwolf commented on PR #8536: URL: https://github.com/apache/hudi/pull/8536#issuecomment-1539275133 @danny0405 PTAL -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8645: [HUDI-6193] Add support to standalone utility tool to fetch file size stats for a given table w/ optional partition filters
hudi-bot commented on PR #8645: URL: https://github.com/apache/hudi/pull/8645#issuecomment-1539264222 ## CI report: * adfb9e2726fb19e05c700ba7e67d080548d51a60 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16959) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8645: [HUDI-6193] Add support to standalone utility tool to fetch file size stats for a given table w/ optional partition filters
hudi-bot commented on PR #8645: URL: https://github.com/apache/hudi/pull/8645#issuecomment-1539260143 ## CI report: * adfb9e2726fb19e05c700ba7e67d080548d51a60 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8659: [HUDI-6155] Fix cleaner based on hours for earliest commit to retain
hudi-bot commented on PR #8659: URL: https://github.com/apache/hudi/pull/8659#issuecomment-1539255643 ## CI report: * 4907a9c37742902e207331b2e86cc80288704e5c Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16951) * 4173ee7fd4dda6e1791b5356a4ca0d09df207f27 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16958) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-6193) Add file size stats utility
[ https://issues.apache.org/jira/browse/HUDI-6193?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HUDI-6193: - Labels: pull-request-available (was: ) > Add file size stats utility > --- > > Key: HUDI-6193 > URL: https://issues.apache.org/jira/browse/HUDI-6193 > Project: Apache Hudi > Issue Type: Improvement > Components: dev-experience >Reporter: sivabalan narayanan >Priority: Major > Labels: pull-request-available > > would be good to have a standlone spark utility to fetch file size stats > > at table leve > at per partition level > partition level range filter (for day based partitoning) > -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] nsivabalan commented on a diff in pull request #8645: [HUDI-6193] Add support to standalone utility tool to fetch file size stats for a given table w/ optional partition filters
nsivabalan commented on code in PR #8645:
URL: https://github.com/apache/hudi/pull/8645#discussion_r1188012377
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/TableSizeStats.java:
##
@@ -0,0 +1,411 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.hudi.utilities;
+
+import org.apache.hudi.client.common.HoodieSparkEngineContext;
+import org.apache.hudi.common.config.HoodieMetadataConfig;
+import org.apache.hudi.common.config.SerializableConfiguration;
+import org.apache.hudi.common.config.TypedProperties;
+import org.apache.hudi.common.engine.HoodieLocalEngineContext;
+import org.apache.hudi.common.fs.FSUtils;
+import org.apache.hudi.common.model.HoodieBaseFile;
+import org.apache.hudi.common.table.HoodieTableMetaClient;
+import org.apache.hudi.common.table.view.FileSystemViewManager;
+import org.apache.hudi.common.table.view.FileSystemViewStorageConfig;
+import org.apache.hudi.common.table.view.HoodieTableFileSystemView;
+import org.apache.hudi.common.util.Option;
+import org.apache.hudi.exception.HoodieException;
+import org.apache.hudi.exception.HoodieIOException;
+import org.apache.hudi.exception.TableNotFoundException;
+import org.apache.hudi.metadata.HoodieTableMetadata;
+
+import com.beust.jcommander.JCommander;
+import com.beust.jcommander.Parameter;
+import com.codahale.metrics.Histogram;
+import com.codahale.metrics.Snapshot;
+import com.codahale.metrics.UniformReservoir;
+import org.apache.hadoop.conf.Configuration;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+import org.apache.spark.SparkConf;
+import org.apache.spark.api.java.JavaSparkContext;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.io.BufferedReader;
+import java.io.IOException;
+import java.io.InputStreamReader;
+import java.io.Serializable;
+import java.time.LocalDate;
+import java.time.format.DateTimeFormatter;
+import java.time.format.DateTimeFormatterBuilder;
+import java.time.format.DateTimeParseException;
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.List;
+import java.util.Objects;
+import java.util.stream.Collectors;
+
+/**
+ * Calculate and output file size stats of data files that were modified in
the half-open interval [start date (--start-date parameter),
+ * end date (--end-date parameter)). --num-days parameter can be used to
select data files over last --num-days. If --start-date is
+ * specified, --num-days will be ignored. If none of the date parameters are
set, stats will be computed over all data files of all
+ * partitions in the table. Note that date filtering is carried out only if
the partition name has the format '[column name=]-M-d',
+ * '[column name=]/M/d'. By default, only table level file size stats are
printed. If --partition-status option is used, partition
+ * level file size stats also get printed.
+ *
+ * The following stats are calculated:
+ * Number of files.
+ * Total table size.
+ * Minimum file size
+ * Maximum file size
+ * Average file size
+ * Median file size
+ * p50 file size
+ * p90 file size
+ * p95 file size
+ * p99 file size
+ *
+ * Sample spark-submit command:
+ * ./bin/spark-submit \
+ * --class org.apache.hudi.utilities.TableSizeStats \
+ *
$HUDI_DIR/packaging/hudi-utilities-bundle/target/hudi-utilities-bundle_2.11-0.14.0-SNAPSHOT.jar
\
+ * --base-path \
+ * --num-days
+ */
+public class TableSizeStats implements Serializable {
+
+ private static final Logger LOG =
LoggerFactory.getLogger(TableSizeStats.class);
+
+ // Date formatter for parsing partition dates (example: 2023/5/5/ or
2023-5-5).
+ private static final DateTimeFormatter DATE_FORMATTER =
+ (new
DateTimeFormatterBuilder()).appendOptional(DateTimeFormatter.ofPattern("/M/d")).appendOptional(DateTimeFormatter.ofPattern("-M-d")).toFormatter();
+
+ // File size stats will be displayed in the units specified below.
+ private static final String[] FILE_SIZE_UNITS = {"B", "KB", "MB", "GB",
"TB"};
+
+ // Spark context
+ private transient JavaSparkContext jsc;
+ // config
+ private Config cfg;
+ // Properties with source, hoodie client, key generator etc.
+ private TypedProperties props;
[GitHub] [hudi] yihua commented on pull request #8573: [HUDI-6138] Handled empty option for Hoodie Avro Record
yihua commented on PR #8573: URL: https://github.com/apache/hudi/pull/8573#issuecomment-1539243448 > is it not possible to write tests for this? Working on a test now. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (HUDI-6193) Add file size stats utility
sivabalan narayanan created HUDI-6193: - Summary: Add file size stats utility Key: HUDI-6193 URL: https://issues.apache.org/jira/browse/HUDI-6193 Project: Apache Hudi Issue Type: Improvement Components: dev-experience Reporter: sivabalan narayanan would be good to have a standlone spark utility to fetch file size stats at table leve at per partition level partition level range filter (for day based partitoning) -- This message was sent by Atlassian Jira (v8.20.10#820010)
[GitHub] [hudi] hudi-bot commented on pull request #8659: [HUDI-6155] Fix cleaner based on hours for earliest commit to retain
hudi-bot commented on PR #8659: URL: https://github.com/apache/hudi/pull/8659#issuecomment-1539228615 ## CI report: * 4907a9c37742902e207331b2e86cc80288704e5c Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16951) * 4173ee7fd4dda6e1791b5356a4ca0d09df207f27 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] clownxc commented on a diff in pull request #8659: [HUDI-6155] Fix cleaner based on hours for earliest commit to retain
clownxc commented on code in PR #8659:
URL: https://github.com/apache/hudi/pull/8659#discussion_r1188006365
##
hudi-common/src/main/java/org/apache/hudi/common/table/timeline/HoodieInstantTimeGenerator.java:
##
@@ -129,7 +129,7 @@ public static String getInstantForDateString(String
dateString) {
}
private static TemporalAccessor convertDateToTemporalAccessor(Date d) {
-return d.toInstant().atZone(ZoneId.systemDefault()).toLocalDateTime();
+return d.toInstant().atZone(getZoneId()).toLocalDateTime();
}
Review Comment:
> Can we supplement some UTs for `parseDateFromInstantTime` and
`convertDateToTemporalAccessor` ?
And in the TestHoodieActiveTimeline.java, there are many UTs related to
DateParsing, such as:
- `testInvalidInstantDateParsing`
- `testMillisGranularityInstantDateParsing`
etc.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] clownxc commented on a diff in pull request #8659: [HUDI-6155] Fix cleaner based on hours for earliest commit to retain
clownxc commented on code in PR #8659:
URL: https://github.com/apache/hudi/pull/8659#discussion_r1188004776
##
hudi-common/src/main/java/org/apache/hudi/common/table/timeline/HoodieInstantTimeGenerator.java:
##
@@ -129,7 +129,7 @@ public static String getInstantForDateString(String
dateString) {
}
private static TemporalAccessor convertDateToTemporalAccessor(Date d) {
-return d.toInstant().atZone(ZoneId.systemDefault()).toLocalDateTime();
+return d.toInstant().atZone(getZoneId()).toLocalDateTime();
}
Review Comment:
> convertDateToTemporalAccessor
I added two UTs: `testFormatDateWithCommitTimeZone` and
`testInstantDateParsingWithCommitTimeZone`,
`testInstantDateParsingWithCommitTimeZone` is used to test the correctness of
the HoodieInstantTimeGenerator#convertDateToTemporalAccessor()
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] codope commented on a diff in pull request #6176: [HUDI-4445] S3 Incremental source improvements
codope commented on code in PR #6176:
URL: https://github.com/apache/hudi/pull/6176#discussion_r1188004960
##
hudi-common/src/test/java/org/apache/hudi/common/testutils/HoodieTestDataGenerator.java:
##
@@ -274,6 +277,11 @@ public RawTripTestPayload
generatePayloadForShortTripSchema(HoodieKey key, Strin
return new RawTripTestPayload(rec.toString(), key.getRecordKey(),
key.getPartitionPath(), SHORT_TRIP_SCHEMA);
}
+ public RawTripTestPayload generatePayloadForS3EventsSchema(HoodieKey key,
String commitTime) throws IOException {
Review Comment:
This is an old comment. Please check if it's still valid.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] clownxc commented on a diff in pull request #8659: [HUDI-6155] Fix cleaner based on hours for earliest commit to retain
clownxc commented on code in PR #8659:
URL: https://github.com/apache/hudi/pull/8659#discussion_r1188004776
##
hudi-common/src/main/java/org/apache/hudi/common/table/timeline/HoodieInstantTimeGenerator.java:
##
@@ -129,7 +129,7 @@ public static String getInstantForDateString(String
dateString) {
}
private static TemporalAccessor convertDateToTemporalAccessor(Date d) {
-return d.toInstant().atZone(ZoneId.systemDefault()).toLocalDateTime();
+return d.toInstant().atZone(getZoneId()).toLocalDateTime();
}
Review Comment:
> convertDateToTemporalAccessor
I added two UTs: `testFormatDateWithCommitTimeZone` and
`testInstantDateParsingWithCommitTimeZone`,
`testInstantDateParsingWithCommitTimeZone` is used to test the correctness of
the `HoodieInstantTimeGenerator#convertDateToTemporalAccessor()` via
`formatDate()`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] codope commented on a diff in pull request #6176: [HUDI-4445] S3 Incremental source improvements
codope commented on code in PR #6176:
URL: https://github.com/apache/hudi/pull/6176#discussion_r928818365
##
hudi-common/src/test/java/org/apache/hudi/common/testutils/S3EventsSchemaUtils.java:
##
@@ -0,0 +1,70 @@
+package org.apache.hudi.common.testutils;
+
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaBuilder;
+import org.apache.avro.generic.GenericData;
+import org.apache.avro.generic.GenericRecord;
+
+// Utility for the schema of S3 events listed here
(https://docs.aws.amazon.com/AmazonS3/latest/userguide/notification-content-structure.html)
Review Comment:
should be multi-line comment
##
hudi-common/src/test/java/org/apache/hudi/common/testutils/HoodieTestDataGenerator.java:
##
@@ -274,6 +277,11 @@ public RawTripTestPayload
generatePayloadForShortTripSchema(HoodieKey key, Strin
return new RawTripTestPayload(rec.toString(), key.getRecordKey(),
key.getPartitionPath(), SHORT_TRIP_SCHEMA);
}
+ public RawTripTestPayload generatePayloadForS3EventsSchema(HoodieKey key,
String commitTime) throws IOException {
Review Comment:
`RawTripTestPayload` assumes some form of trips schema. If you look at its
constructor, we don't use the schema. And its APIs assume a few things about
the schema. Should we keep all this out of `HoodieTestDataGenerator`?
##
hudi-common/src/test/java/org/apache/hudi/common/testutils/S3EventsSchemaUtils.java:
##
@@ -0,0 +1,70 @@
+package org.apache.hudi.common.testutils;
+
+import org.apache.avro.Schema;
+import org.apache.avro.SchemaBuilder;
+import org.apache.avro.generic.GenericData;
+import org.apache.avro.generic.GenericRecord;
+
+// Utility for the schema of S3 events listed here
(https://docs.aws.amazon.com/AmazonS3/latest/userguide/notification-content-structure.html)
+public class S3EventsSchemaUtils {
+ public static final String DEFAULT_STRING_VALUE = "default_string";
+
+ public static String generateSchemaString() {
+return generateS3EventSchema().toString();
+ }
+
+ public static Schema generateObjInfoSchema() {
+Schema objInfo = SchemaBuilder.record("objInfo")
+.fields()
+.requiredString("key")
+.requiredLong("size")
+.endRecord();
+return objInfo;
+ }
+
+ public static GenericRecord generateObjInfoRecord(String key, Long size) {
+GenericRecord rec = new GenericData.Record(generateObjInfoSchema());
+rec.put("key", key);
+rec.put("size", size);
+return rec;
+ }
+
+ public static Schema generateS3MetadataSchema() {
+Schema s3Metadata = SchemaBuilder.record("s3Metadata")
+.fields()
+.requiredString("configurationId")
+.name("object")
+.type(generateObjInfoSchema())
+.noDefault()
+.endRecord();
+return s3Metadata;
+ }
+
+ public static GenericRecord generateS3MetadataRecord(GenericRecord
objRecord) {
+GenericRecord rec = new GenericData.Record(generateS3MetadataSchema());
+rec.put("configurationId", DEFAULT_STRING_VALUE);
+rec.put("object", objRecord);
+return rec;
+ }
+
+ public static Schema generateS3EventSchema() {
+Schema s3Event = SchemaBuilder.record("s3Event")
+.fields()
+.requiredString("eventSource")
+.requiredString("eventName")
+.name("s3")
Review Comment:
Let's extract all these strings to constants.
##
hudi-common/src/test/java/org/apache/hudi/common/testutils/GenericTestPayload.java:
##
@@ -0,0 +1,110 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.hudi.common.testutils;
+
+import org.apache.hudi.avro.MercifulJsonConverter;
+import org.apache.hudi.common.util.FileIOUtils;
+import org.apache.hudi.common.util.Option;
+
+import com.fasterxml.jackson.databind.ObjectMapper;
+import org.apache.avro.Schema;
+import org.apache.avro.generic.IndexedRecord;
+
+import java.io.ByteArrayInputStream;
+import java.io.ByteArrayOutputStream;
+import java.io.IOException;
+import java.util.Map;
+import java.util.zip.Deflater;
+import java.util.zip.DeflaterOutputStream;
+import java.util.zip.InflaterInputStream;
+
+/**
+ * Generic class for specific payload implementations to inherit from.
+ */
[GitHub] [hudi] hudi-bot commented on pull request #8659: [HUDI-6155] Fix cleaner based on hours for earliest commit to retain
hudi-bot commented on PR #8659: URL: https://github.com/apache/hudi/pull/8659#issuecomment-1539218920 ## CI report: * 4907a9c37742902e207331b2e86cc80288704e5c Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16951) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on pull request #8604: [HUDI-6151] Rollback previously applied commits to MDT when operations are retried.
nsivabalan commented on PR #8604: URL: https://github.com/apache/hudi/pull/8604#issuecomment-1539200771 once the CI is green, we can land -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[hudi] branch master updated (545a26222da -> 45b79362cc4)
This is an automated email from the ASF dual-hosted git repository. sivabalan pushed a change to branch master in repository https://gitbox.apache.org/repos/asf/hudi.git from 545a26222da [HUDI-6147] Deltastreamer finish failed compaction before ingestion (#8589) add 45b79362cc4 [HUDI-6117] Parallelize the initial creation of file groups for a new MDT partition. (#8527) No new revisions were added by this update. Summary of changes: .../metadata/HoodieBackedTableMetadataWriter.java | 35 +- 1 file changed, 28 insertions(+), 7 deletions(-)
[GitHub] [hudi] nsivabalan merged pull request #8527: [HUDI-6117] Parallelize the initial creation of file groups for a new MDT partition.
nsivabalan merged PR #8527: URL: https://github.com/apache/hudi/pull/8527 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on pull request #8487: [HUDI-6093] Use the correct partitionToReplacedFileIds during commit.
nsivabalan commented on PR #8487: URL: https://github.com/apache/hudi/pull/8487#issuecomment-1539199344 ping me once the feedback is addressed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on pull request #8430: [HUDI-6060] Added a config to backup instants before deletion during rollbacks and restores.
nsivabalan commented on PR #8430: URL: https://github.com/apache/hudi/pull/8430#issuecomment-1539199151 hey @prashantwason : ping me once the feedback is addresssed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on issue #8325: [SUPPORT] spark read hudi error: Unable to instantiate HFileBootstrapIndex
yihua commented on issue #8325: URL: https://github.com/apache/hudi/issues/8325#issuecomment-1539190582 It looks like the issues are due to transient connection issues. Also, recently we have fixed the metadata table read in a few code paths so that the numbers FS calls do not rely on the number of partitions. @jfrylings-twilio Thanks for confirming it works after setting the maximum connections. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8563: [HUDI-6133](hudi-metaserver) Eliminate one deletion operation if state is not COMPLETED
hudi-bot commented on PR #8563: URL: https://github.com/apache/hudi/pull/8563#issuecomment-1539185449 ## CI report: * 702e6c35dbb9ed143d3a76314730139281a15a30 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16950) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] yihua commented on pull request #8658: [HUDI-6186] Fix lock identity in InProcessLockProvider
yihua commented on PR #8658: URL: https://github.com/apache/hudi/pull/8658#issuecomment-1539185102 Synced with @nsivabalan and the test is good enough now, as the count down latch may not solve the problem in the locking in this case. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on pull request #8107: [HUDI-5514][HUDI-5574][HUDI-5604][HUDI-5535] Adding auto generation of record keys support to Hudi/Spark
nsivabalan commented on PR #8107: URL: https://github.com/apache/hudi/pull/8107#issuecomment-1539183331 I did ran some benchmarks. Confirmed that write latency is on par w/ 0.13.0 and with this patch w/o auto record key generation. and auto record key generation numbers are also on par. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8536: [MINOR](hudi-metaserver) fix typos in README.md
hudi-bot commented on PR #8536: URL: https://github.com/apache/hudi/pull/8536#issuecomment-1539180503 ## CI report: * 8b25a7d6444a1ec7a848c1f650247d1151871d34 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16949) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] dineshbganesan opened a new issue, #8667: Table exception after enabling inline clustering
dineshbganesan opened a new issue, #8667: URL: https://github.com/apache/hudi/issues/8667 **_Tips before filing an issue_** **Describe the problem you faced** I am facing an exception while writing updates to an hudi table. I think table is messed up after enabling the clustering. I can query and read the table but cannot write updates to the table. The job was running fine until I added the following configs. The recent changes are: **'hoodie.clustering.inline': 'true', 'hoodie.clustering.inline.max.commits': 2, 'hoodie.clustering.execution.strategy.class': 'org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy', 'hoodie.parquet.max.file.size': 128 * 1024 * 1024, 'hoodie.parquet.small.file.limit': 100 * 1024 * 1024, 'hoodie.clustering.plan.strategy.max.num.groups': 1, 'hoodie.clustering.plan.strategy.target.file.max.bytes': 128 * 1024 * 1024, 'hoodie.clustering.plan.strategy.small.file.limit': 100 * 1024 * 1024** **To Reproduce** Steps to reproduce the behavior: 1. Create a new table using the Hudi Configs 2. Publish inserts/updates to the source table 3. Add configs related to clustering listed above 4. Run the job to process inserts/updates **Expected behavior** We were hoping that Hudi would resize the files for better read performance. Instead it throws an exception posted in the stacktrace. **Environment Description** * Hudi version : 0.12.1 * Spark version : Spark 3.3 * Storage (HDFS/S3/GCS..) : S3 * Running on Docker? (yes/no) : no **Additional context** Complete Hudi Configuration: Hoodie Configuration:'className': 'org.apache.hudi', 'hoodie.datasource.hive_sync.use_jdbc': 'false', 'hoodie.datasource.write.precombine.field': 'update_ts_dms', 'hoodie.datasource.write.recordkey.field': primaryKey, 'hoodie.table.name': tableName, 'hoodie.datasource.hive_sync.database': glueDbName, 'hoodie.datasource.hive_sync.table': tableName, 'hoodie.datasource.hive_sync.enable': 'true', 'hoodie.datasource.hive_sync.support_timestamp': 'true', 'hoodie.datasource.hive_sync.mode': 'hms', 'hoodie.schema.on.read.enable': 'true', 'hoodie.index.type': 'BLOOM', 'hoodie.metadata.enable': 'true', 'hoodie.datasource.meta_sync.condition.sync': 'true' 'hoodie.upsert.shuffle.parallelism': 200, 'hoodie.datasource.write.operation': 'upsert', 'hoodie.combine.before.insert': 'true', 'hoodie.cleaner.policy': 'KEEP_LATEST_COMMITS', 'hoodie.cleaner.commits.retained': 10 'hoodie.datasource.write.partitionpath.field': partitionKey, 'hoodie.datasource.hive_sync.partition_fields': partitionKey, 'hoodie.datasource.write.hive_style_partitioning': 'true', 'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.HiveStylePartitionValueExtractor', 'hoodie.datasource.write.keygenerator.consistent.logical.timestamp.enabled': 'true' Clustering config: (Adding the following configs had caused the job to fail with exception. I tried to remove these configs and run the job but it fails with the same exception) 'hoodie.clustering.inline': 'true', 'hoodie.clustering.inline.max.commits': 2, 'hoodie.clustering.execution.strategy.class': 'org.apache.hudi.client.clustering.run.strategy.SparkSortAndSizeExecutionStrategy', 'hoodie.parquet.max.file.size': 128 * 1024 * 1024, 'hoodie.parquet.small.file.limit': 100 * 1024 * 1024, 'hoodie.clustering.plan.strategy.max.num.groups': 1, 'hoodie.clustering.plan.strategy.target.file.max.bytes': 128 * 1024 * 1024, 'hoodie.clustering.plan.strategy.small.file.limit': 100 * 1024 * 1024 **Stacktrace** An error occurred while calling o1021.save. : org.apache.spark.SparkException: Job aborted due to stage failure: Task 109 in stage 382.0 failed 4 times, most recent failure: Lost task 109.3 in stage 382.0 (TID 12069) (172.36.215.53 executor 13): org.apache.hudi.exception.HoodieUpsertException: Error upserting bucketType UPDATE for partition :109 at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.handleUpsertPartition(BaseSparkCommitActionExecutor.java:329) at org.apache.hudi.table.action.commit.BaseSparkCommitActionExecutor.lambda$mapPartitionsAsRDD$a3ab3c4$1(BaseSparkCommitActionExecutor.java:244) at org.apache.spark.api.java.JavaRDDLike.$anonfun$mapPartitionsWithIndex$1(JavaRDDLike.scala:102) at org.apache.spark.api.java.JavaRDDLike.$anonfun$mapPartitionsWithIndex$1$adapted(JavaRDDLike.scala:102) at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndex$2(RDD.scala:907) at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsWithIndex$2$adapted(RDD.scala:907) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365) at
[GitHub] [hudi] hudi-bot commented on pull request #8666: [HUDI-915] Add missing partititonpath to records COW
hudi-bot commented on PR #8666: URL: https://github.com/apache/hudi/pull/8666#issuecomment-1539080730 ## CI report: * 7510bceed906d98b31bf44b4cd78a24a364c1288 Azure: [CANCELED](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16955) * 5d1b90a6e91fbfe1229556377831d0c52d9c7613 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16956) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8666: [HUDI-915] Add missing partititonpath to records COW
hudi-bot commented on PR #8666: URL: https://github.com/apache/hudi/pull/8666#issuecomment-1539069610 ## CI report: * 7510bceed906d98b31bf44b4cd78a24a364c1288 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16955) * 5d1b90a6e91fbfe1229556377831d0c52d9c7613 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8107: [HUDI-5514][HUDI-5574][HUDI-5604][HUDI-5535] Adding auto generation of record keys support to Hudi/Spark
hudi-bot commented on PR #8107: URL: https://github.com/apache/hudi/pull/8107#issuecomment-1539067675 ## CI report: * 780318c5f048c4bf69980ac47d10d5e23994a21b Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16954) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8107: [HUDI-5514][HUDI-5574][HUDI-5604][HUDI-5535] Adding auto generation of record keys support to Hudi/Spark
hudi-bot commented on PR #8107: URL: https://github.com/apache/hudi/pull/8107#issuecomment-1539058174 ## CI report: * 780318c5f048c4bf69980ac47d10d5e23994a21b UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #7632: [HUDI-3775] Allow for offline compaction of MOR tables via spark streaming
hudi-bot commented on PR #7632: URL: https://github.com/apache/hudi/pull/7632#issuecomment-1539057263 ## CI report: * 872829bb0a31b07bec8b18f9d1fb4549fc3d4802 Azure: [SUCCESS](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16946) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] bvaradar commented on a diff in pull request #8378: [HUDI-6031] fix bug: checkpoint lost after changing cow to mor
bvaradar commented on code in PR #8378:
URL: https://github.com/apache/hudi/pull/8378#discussion_r1187895704
##
hudi-utilities/src/main/java/org/apache/hudi/utilities/deltastreamer/DeltaSync.java:
##
@@ -320,11 +320,9 @@ public void refreshTimeline() throws IOException {
.build();
switch (meta.getTableType()) {
case COPY_ON_WRITE:
-this.commitTimelineOpt =
Option.of(meta.getActiveTimeline().getCommitTimeline().filterCompletedInstants());
-this.allCommitsTimelineOpt =
Option.of(meta.getActiveTimeline().getAllCommitsTimeline());
-break;
case MERGE_ON_READ:
-this.commitTimelineOpt =
Option.of(meta.getActiveTimeline().getDeltaCommitTimeline().filterCompletedInstants());
+// we can use getCommitsTimeline for both COW and MOR here,
because for COW there is no deltacommit
+this.commitsTimelineOpt =
Option.of(meta.getActiveTimeline().getCommitsTimeline().filterCompletedInstants());
Review Comment:
As part of this change, we will always use deltacommit only timeline when
one is found in the destination timeline (non-empty).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] sydneyhoran commented on issue #8521: [SUPPORT] Deltastreamer not recognizing config `hoodie.deltastreamer.source.kafka.value.deserializer.class` with PostgresDebeziumSource
sydneyhoran commented on issue #8521: URL: https://github.com/apache/hudi/issues/8521#issuecomment-1539033823 @ad1happy2go I can try the patch, but can you expand on the comment linked above by @samserpoosh that @rmahindra123 mentioned we should not set `--schemaprovider-class` with Debezium source? I see that `SchemaProvider has to be set to use KafkaAvroSchemaDeserializer` so wondering if it's safe to use. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8666: [HUDI-915] Add missing partititonpath to records COW
hudi-bot commented on PR #8666: URL: https://github.com/apache/hudi/pull/8666#issuecomment-1539008630 ## CI report: * 7510bceed906d98b31bf44b4cd78a24a364c1288 Azure: [PENDING](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16955) Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8666: [HUDI-915] Add missing partititonpath to records COW
hudi-bot commented on PR #8666: URL: https://github.com/apache/hudi/pull/8666#issuecomment-1538998123 ## CI report: * 7510bceed906d98b31bf44b4cd78a24a364c1288 UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] hudi-bot commented on pull request #8107: [HUDI-5514][HUDI-5574][HUDI-5604][HUDI-5535] Adding auto generation of record keys support to Hudi/Spark
hudi-bot commented on PR #8107: URL: https://github.com/apache/hudi/pull/8107#issuecomment-1538996828 ## CI report: * fcd81e9fda3e3b6fa7e813d6c56b880042b90bed Azure: [FAILURE](https://dev.azure.com/apache-hudi-ci-org/785b6ef4-2f42-4a89-8f0e-5f0d7039a0cc/_build/results?buildId=16934) * 780318c5f048c4bf69980ac47d10d5e23994a21b UNKNOWN Bot commands @hudi-bot supports the following commands: - `@hudi-bot run azure` re-run the last Azure build -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #8572: [SUPPORT] Getting java.io.FileNotFoundException when reading MOR table.
nsivabalan commented on issue #8572: URL: https://github.com/apache/hudi/issues/8572#issuecomment-1538995505 you are using some internal apis. so getCommitsTimeline will give you cleaned up and noncleaned commits. right one to use is ``` timeline=metaClient.getActiveTimeline().getCleanerTimeline().filterCompletedInstants() ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #8209: [SUPPORT] auto_clean stopped running during ingest
nsivabalan commented on issue #8209: URL: https://github.com/apache/hudi/issues/8209#issuecomment-1538989347 cool, we identified some perf hit w/ timeline server when dealing w/ too many files. https://github.com/apache/hudi/pull/8480 we fixed it in latest master and could go into 0.13.1. So, I suggested to disable timeline server to get past few cleaner where replaced file groups are cleaned up. once the clean up is done, may be number of file groups to deal with are less and hence the timeline server should be able to cope up w/ it (w/o the above fix) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] jonvex opened a new pull request, #8666: [HUDI-915] Add missing partititonpath to records COW
jonvex opened a new pull request, #8666: URL: https://github.com/apache/hudi/pull/8666 ### Change Logs In a bootstrapped table, If there was an upsert in a file group, the records in the file group that were not upserted would have null values for their partition column ### Impact Now works correctly ### Risk level (write none, low medium or high below) Medium Lots of tests written ### Documentation Update N/A ### Contributor's checklist - [ ] Read through [contributor's guide](https://hudi.apache.org/contribute/how-to-contribute) - [ ] Change Logs and Impact were stated clearly - [ ] Adequate tests were added if applicable - [ ] CI passed -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: commits-unsubscr...@hudi.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (HUDI-6138) HoodieAvroRecord - Fix Option get for empty values
[ https://issues.apache.org/jira/browse/HUDI-6138?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Ethan Guo updated HUDI-6138: Fix Version/s: 0.13.1 (was: 0.14.0) > HoodieAvroRecord - Fix Option get for empty values > > > Key: HUDI-6138 > URL: https://issues.apache.org/jira/browse/HUDI-6138 > Project: Apache Hudi > Issue Type: Bug > Components: writer-core >Reporter: Aditya Goenka >Priority: Blocker > Labels: pull-request-available > Fix For: 0.13.1 > > > Details at - [https://github.com/apache/hudi/issues/8278] > Check the option if empty before calling get. > -- This message was sent by Atlassian Jira (v8.20.10#820010)