afeldman1 opened a new issue #2639: URL: https://github.com/apache/hudi/issues/2639
Using Hudi 0.6.0, updated from Spark 2.4.7 on EMR 5.32.0 to Spark 3.0.1 on EMR 6.2.0, there is a significant slowdown on writing into Hudi tables. With Spark 2.4.7 the process writing into the Hudi table takes about 6 minutes, while with Spark 3.0.1, the same code takes about 3.4 hours. The table has 60073874 records. The source Spark is reading the data from is a single un-partitioned parquet file. Using AWS Glue as the metastore and S3 as the table file store location. Originally it was writing into a Hudi table with a single partition, but I also attempted to break it up partitioned into groups as see below, with no significant change in performance: 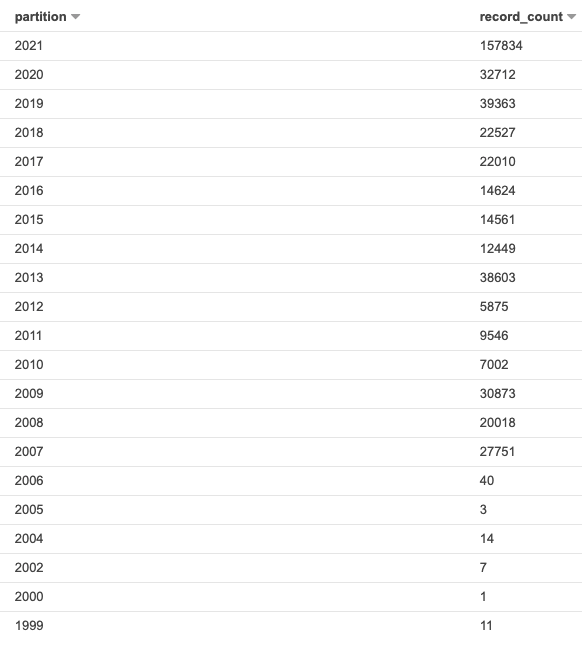 The Hudi write config is the same with both Spark 2.4.7 and Spark 3.0.1: `DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY -> datalakeDbName, HoodieWriteConfig.TABLE_NAME -> table.tableName, DataSourceWriteOptions.TABLE_TYPE_OPT_KEY -> DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL, DataSourceWriteOptions.OPERATION_OPT_KEY -> DataSourceWriteOptions.BULK_INSERT_OPERATION_OPT_VAL, DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY -> classOf[ComplexKeyGenerator].getName, DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY -> table.keyCols.reduce(_ + "," + _), DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY -> table.partitionCols, DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY -> "ts", DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY -> "true", DataSourceWriteOptions.HIVE_TABLE_OPT_KEY -> table.tableName, DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY -> classOf[MultiPartKeysValueExtractor].getCanonicalName, DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY -> partitionCols DataSourceWriteOptions.HIVE_URL_OPT_KEY -> getHiveMetastoreJdbcUrl` (also attempted to switch to `DataSourceWriteOptions.INSERT_OPERATION_OPT_VAL` for `DataSourceWriteOptions.OPERATION_OPT_KEY`, but this does not help) It’s spending most time time on the piece “UpsertPartitioner”, “Getting small files from partitions” with spark job “sortBy at GlobalSortPartitioner.java” and “count at HoodieSparkSqlWriter.scala" Is there something wrong with the config, that's causing this extreme increase in hudi processing time? With Spark 3.0.1 Using single partition: 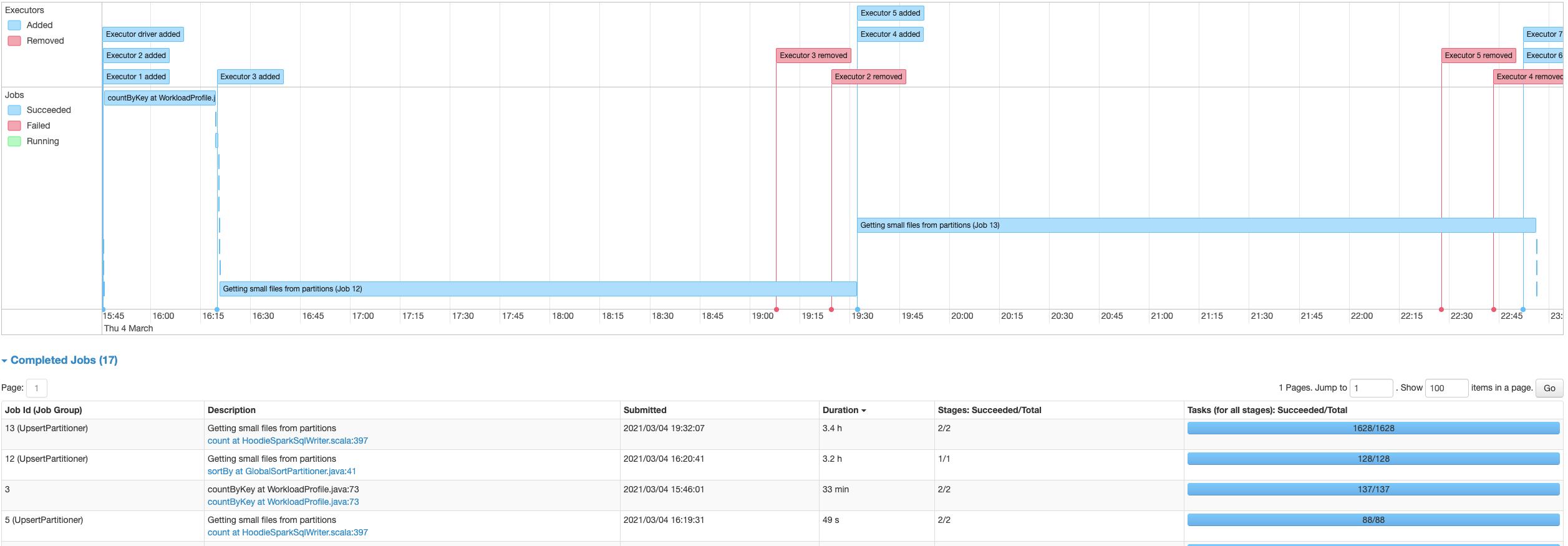 With Spark 3.0.1 Using multiple partitions: 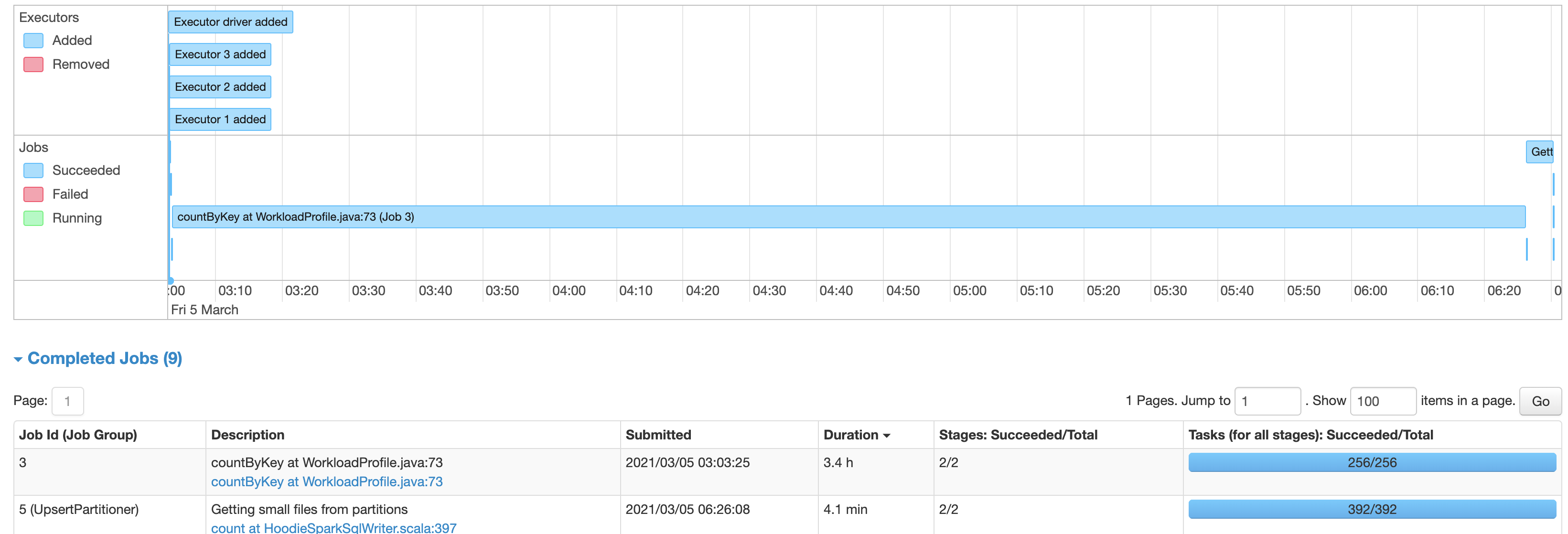 With Spark 2.4.7: 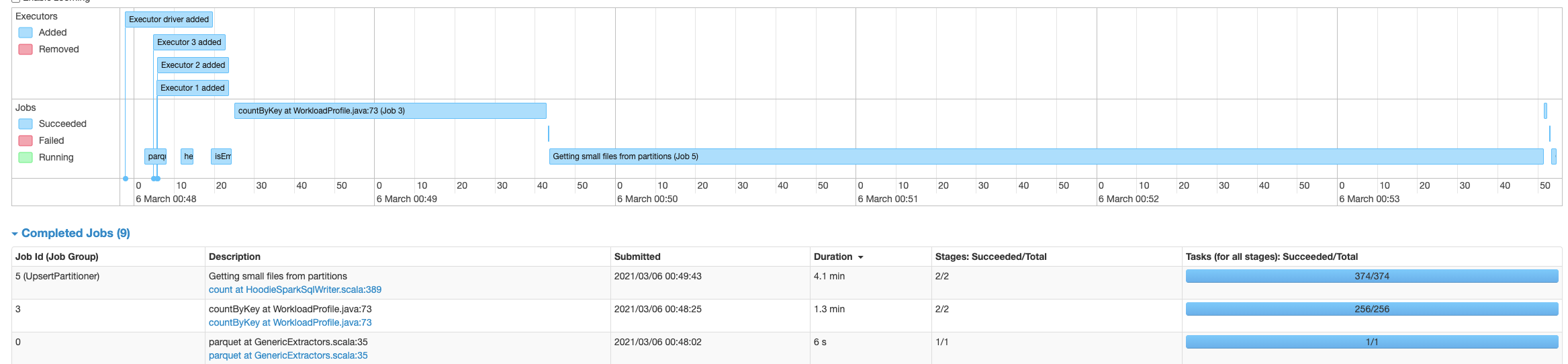 **Problematic Environment Description** Hudi version : 0.6.0 Spark version : 3.0.1 Storage: AWS S3 Running on EMR ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}