[GitHub] [hudi] so-lazy commented on issue #2338: [SUPPORT] MOR table found duplicate and process so slowly
so-lazy commented on issue #2338: URL: https://github.com/apache/hudi/issues/2338#issuecomment-760708042 @bvaradar sir, now i used global simple index, but for some satages **Getting small files from partitions** **Compacting file slices** they cost so long mintues, and i attach my option, am i wrong with some config? By the way i searched a lot about global_bloom and global_simple, i am still not so clear, what's the difference between them? 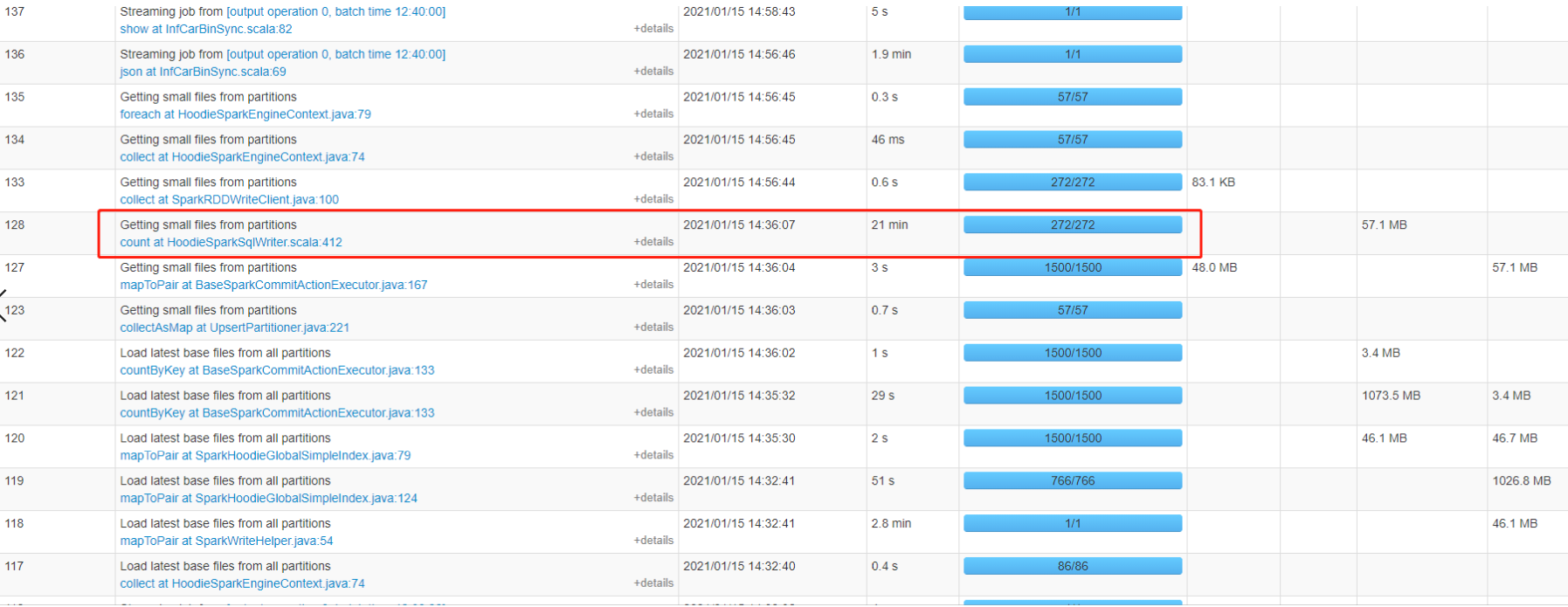 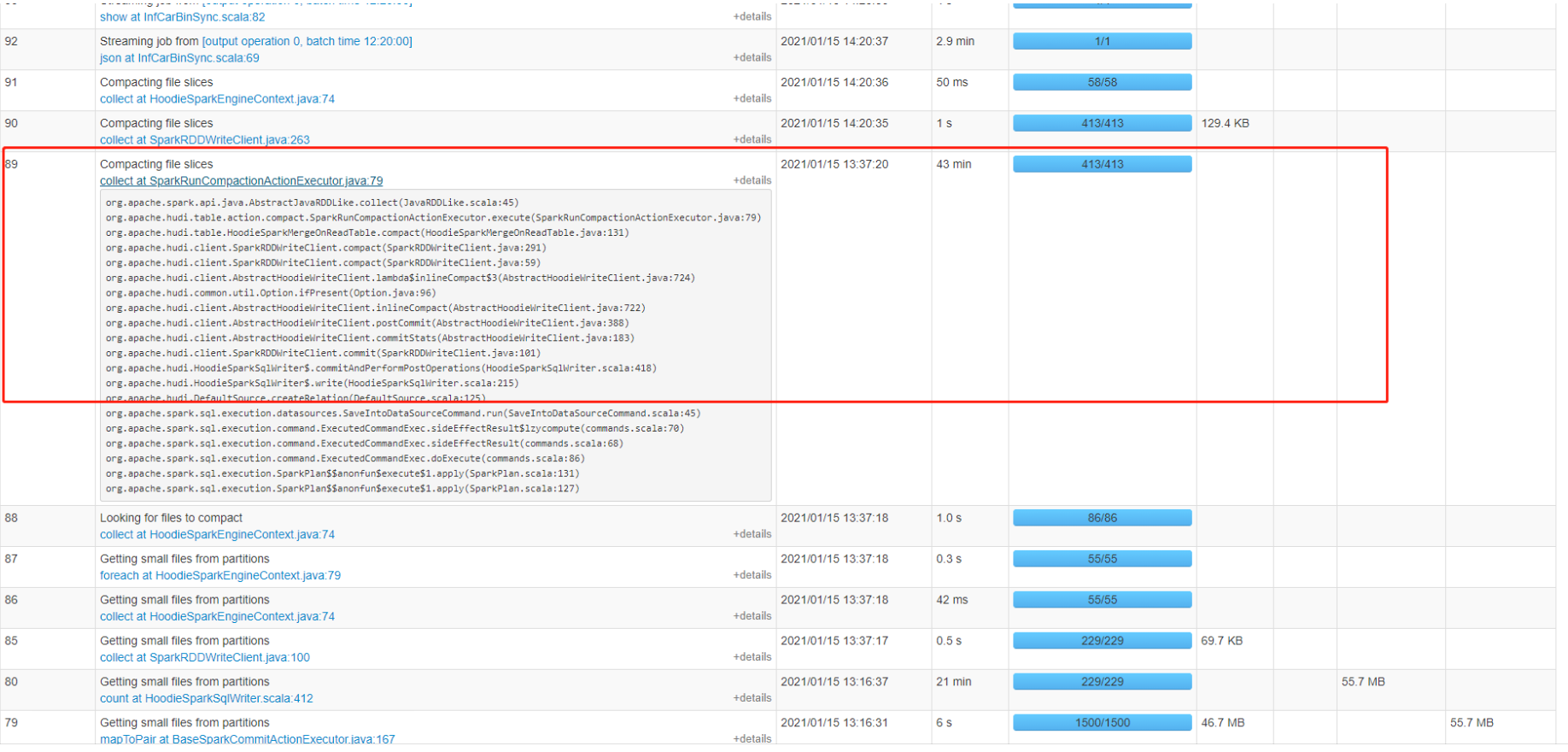 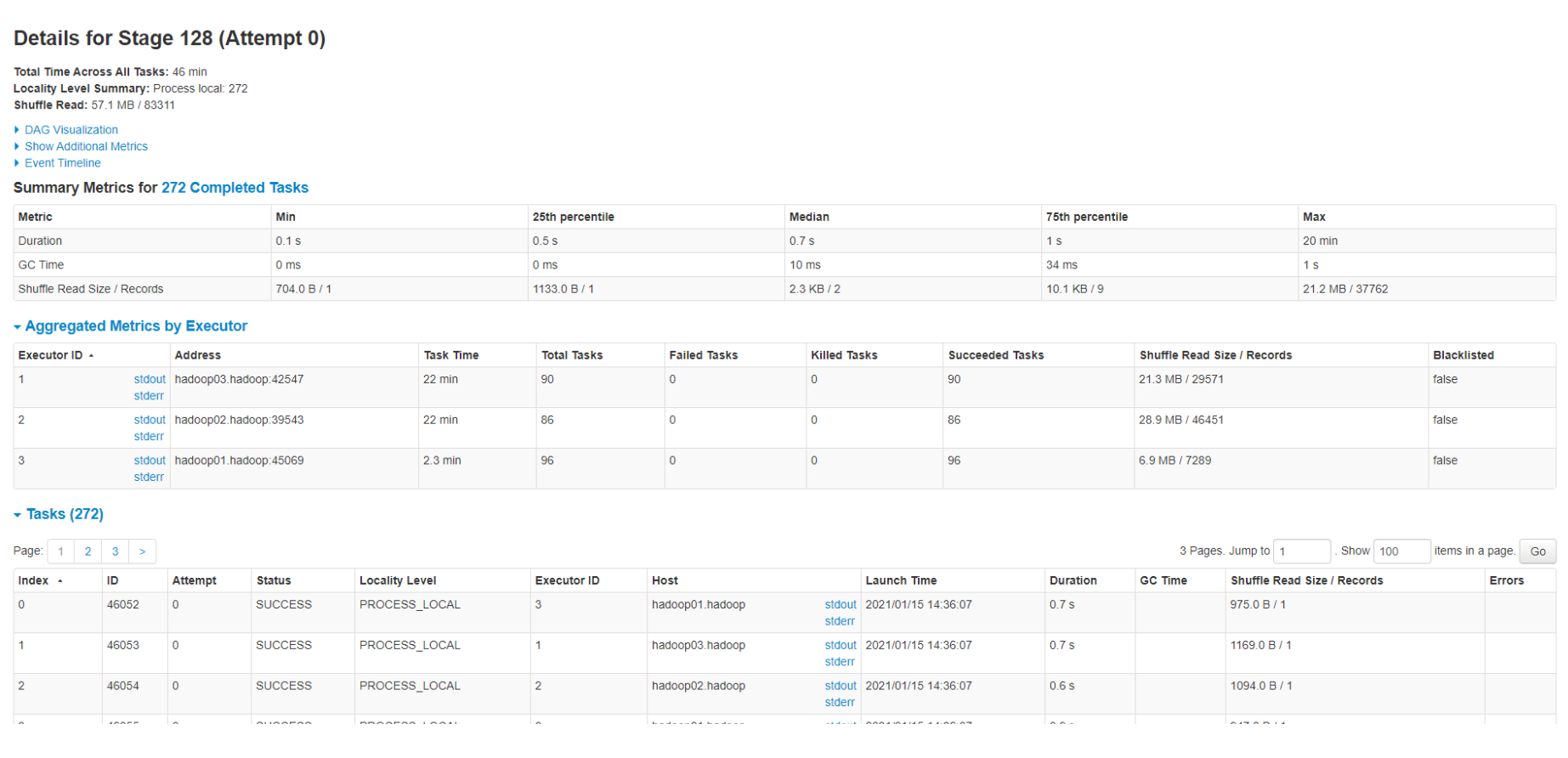 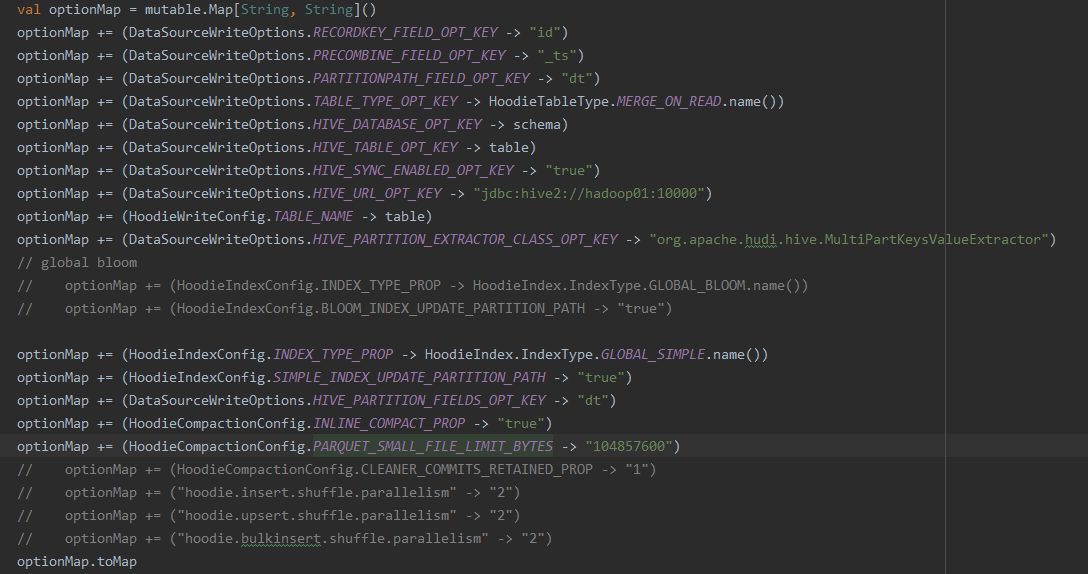 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] so-lazy commented on issue #2338: [SUPPORT] MOR table found duplicate and process so slowly
so-lazy commented on issue #2338:
URL: https://github.com/apache/hudi/issues/2338#issuecomment-758656180
> @so-lazy :
> Also, I see you have space around "=" sign (set
spark.sql.hive.convertMetastoreParquet = false;) Try removing it. Please also
enable INFO logging and run the select group by query and attach them if the
problem persists.
@bvaradar Sorry,bvaradar, these days i was so busy didn't reply on time.
Today i followed your suggest and attach screen shot.
> val df =
spark.read.format("hudi").load("hdfs://hadoop01:9000/hudi/cars/carsdata/inf_car_bin/*")
run this i got unique record
> run sql on hive ro table
> Also, Are you passing the config
(spark.sql.hive.convertMetastoreParquet=false) when you are launching spark ?
https://hudi.apache.org/docs/querying_data.html#spark-sql.
Yeah after passing this config, i can see unique record. thanks so much ,
and now i am gonna try other index type, for global_bloom , it's so slowly may
be there are some problems in my program. Hudi is a good software , thanks for
your time and effort.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] so-lazy commented on issue #2338: [SUPPORT] MOR table found duplicate and process so slowly
so-lazy commented on issue #2338: URL: https://github.com/apache/hudi/issues/2338#issuecomment-756485939 > @so-lazy : I think the hive table may not be a hudi table. can you show the output of the following hive command ? > > desc formatted table > > Also, can you please attach the listing of .hoodie folder ? > > Thanks, > Balaji.V @bvaradar Here are my table desc and .hoodie folder, thanks so much. [desc table.txt](https://github.com/apache/hudi/files/5784674/desc.table.txt) [hoodie.tar.gz](https://github.com/apache/hudi/files/5784676/hoodie.tar.gz) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] so-lazy commented on issue #2338: [SUPPORT] MOR table found duplicate and process so slowly
so-lazy commented on issue #2338: URL: https://github.com/apache/hudi/issues/2338#issuecomment-753710467 @nsivabalan Sir,can u help me out of this? I am so curious, thanks too much This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] so-lazy commented on issue #2338: [SUPPORT] MOR table found duplicate and process so slowly
so-lazy commented on issue #2338:
URL: https://github.com/apache/hudi/issues/2338#issuecomment-751638099
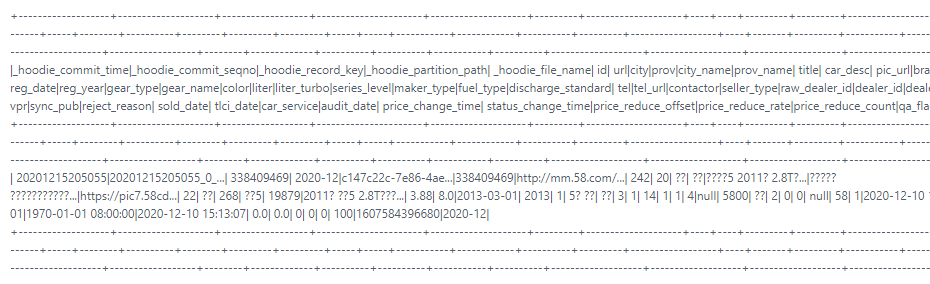
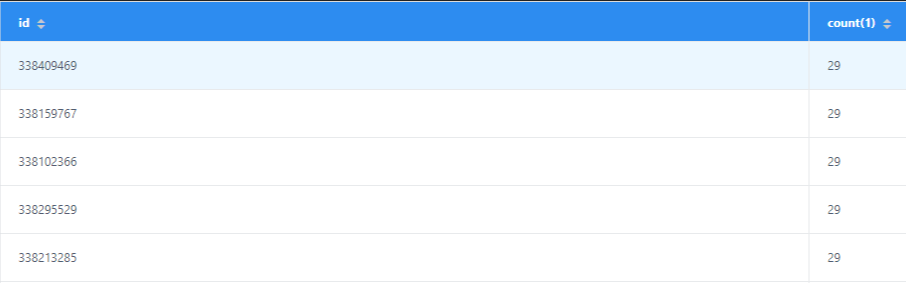
I run `select id,count(1) from table_ro group by id having count(1) > 1` got
this
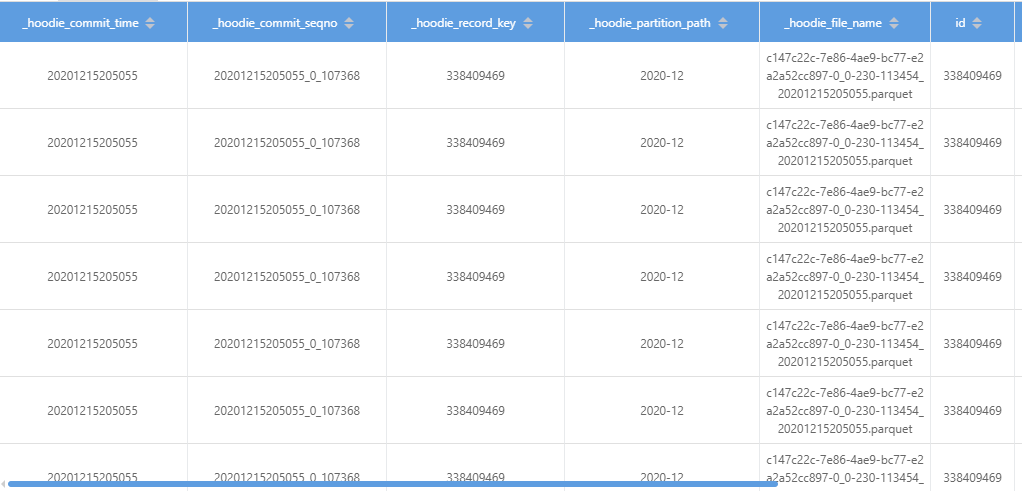
then i query data by id got this
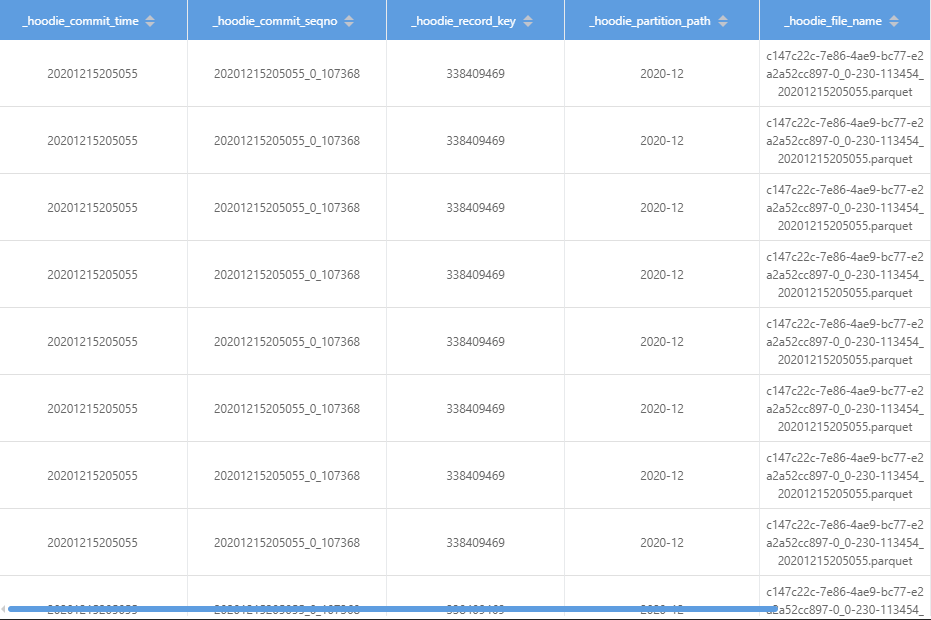
then i go to check the parquet file
`val df =
spark.read.parquet("/hudi/2020-12/c147c22c-7e86-4ae9-bc77-e2a2a52cc897-0_0-230-113454_20201215205055.parquet")
df.createOrReplaceTempView("table")
spark.sql("select
_hoodie_commit_time,_hoodie_commit_seqno,_hoodie_record_key,_hoodie_partition_path,_hoodie_file_name,id
from table WHERE id = 338409469").show`
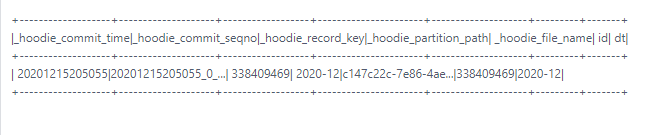
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [hudi] so-lazy commented on issue #2338: [SUPPORT] MOR table found duplicate and process so slowly
so-lazy commented on issue #2338: URL: https://github.com/apache/hudi/issues/2338#issuecomment-751363149 > @so-lazy :would u mind elaborating more on your use-case. did you choose Global_bloom intentionally? > And by this statement of yours "i found much duplicate records,..", did you mean to insinuate that compaction hasn't happened and hence you found duplicates or did you refer in general your dataset has duplicates? > Do you want to do dedup for your use-case in general? This is my mysql table **id** | name | add_time 1 | "so-lazy" | 2020-12-26 yeah, for my use case, i consume binlog delta data from kafka and those data they have primary key "id", i set dt based on the column add_time, and format is -MM-dd. What i want is if one row id is 1 and at the first time hudi upserts this row into table partitiion 2020-12-26, then next time this id 1 come again,it will be updated. But now what i found is , when i use spark-sql search "select * from table where id = 1" on hive table synced by hudi, i saw many the same records they are totally the same, all the column values they are the same, also in the same parquet file, but when i read this parquet file by spark, i can only find one row which id = 1 in that parquet file. Sir do u understand what i mean, thanks sooo much. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [hudi] so-lazy commented on issue #2338: [SUPPORT] MOR table found duplicate and process so slowly
so-lazy commented on issue #2338: URL: https://github.com/apache/hudi/issues/2338#issuecomment-745774960 > @nsivabalan : Can you take a look at this. > > Thanks, > Balaji.V Thanks for your quick reply This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org