umehrot2 opened a new issue #2633:
URL: https://github.com/apache/hudi/issues/2633
**Describe the problem you faced**
IHAC who is using Hudi's `Spark structured streaming sink` with
`asynchronous compaction` and `Hbase Index` on EMR. The Hudi version being used
is 0.6.0. After a while their job fails with the following error:
```
java.util.NoSuchElementException: No value present
at java.util.Optional.get(Optional.java:135)
at
org.apache.hudi.table.action.deltacommit.UpsertDeltaCommitPartitioner.getSmallFiles(UpsertDeltaCommitPartitioner.java:103)
at
org.apache.hudi.table.action.commit.UpsertPartitioner.lambda$getSmallFilesForPartitions$d2bd4b49$1(UpsertPartitioner.java:216)
at
org.apache.spark.api.java.JavaPairRDD$$anonfun$pairFunToScalaFun$1.apply(JavaPairRDD.scala:1043)
at
org.apache.spark.api.java.JavaPairRDD$$anonfun$pairFunToScalaFun$1.apply(JavaPairRDD.scala:1043)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:410)
at scala.collection.Iterator$class.foreach(Iterator.scala:891)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1334)
at
scala.collection.generic.Growable$class.$plus$plus$eq(Growable.scala:59)
at
scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:104)
at
scala.collection.mutable.ArrayBuffer.$plus$plus$eq(ArrayBuffer.scala:48)
at scala.collection.TraversableOnce$class.to(TraversableOnce.scala:310)
at scala.collection.AbstractIterator.to(Iterator.scala:1334)
at
scala.collection.TraversableOnce$class.toBuffer(TraversableOnce.scala:302)
at scala.collection.AbstractIterator.toBuffer(Iterator.scala:1334)
at
scala.collection.TraversableOnce$class.toArray(TraversableOnce.scala:289)
at scala.collection.AbstractIterator.toArray(Iterator.scala:1334)
at
org.apache.spark.rdd.RDD$$anonfun$collect$1$$anonfun$15.apply(RDD.scala:990)
at
org.apache.spark.rdd.RDD$$anonfun$collect$1$$anonfun$15.apply(RDD.scala:990)
at
org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at
org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2101)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at
org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
Here is a timeline of events as well leading up to the failure of the final
delta commit `20210228152758`:
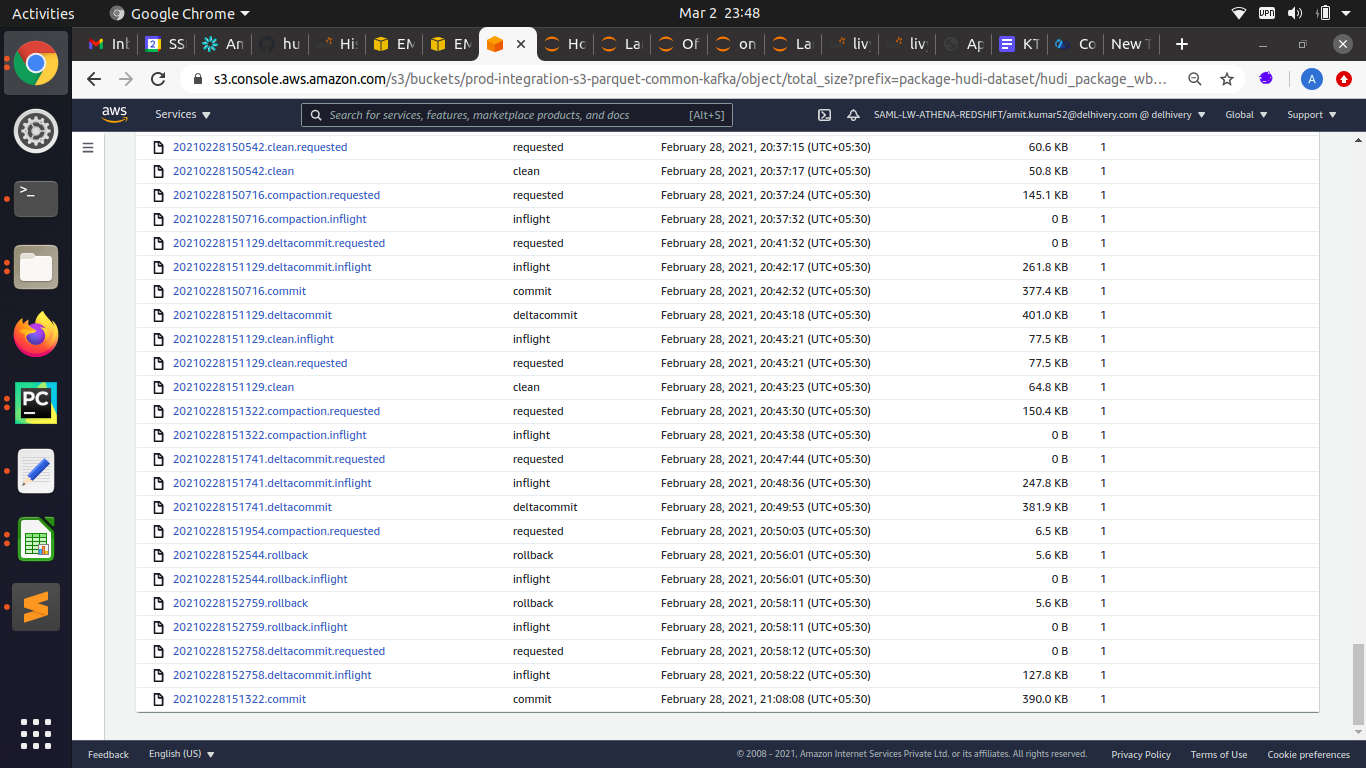
As an observation you can see that there are two asynchronous compactions
running at the same before the delta commit failure. After discussions with
Vinoth, I also verified that there are no common file groups between the two
concurrent compactions, so nothing suspicious was found there.
I followed the code path, and as we can see the error stems from here where
its assuming that some log files will be present in the file slice:
https://github.com/apache/hudi/blob/release-0.6.0/hudi-client/src/main/java/org/apache/hudi/table/action/deltacommit/UpsertDeltaCommitPartitioner.java#L103
Upon following this piece of code, I found this suspicious code:
https://github.com/apache/hudi/blob/release-0.6.0/hudi-common/src/main/java/org/apache/hudi/common/table/view/AbstractTableFileSystemView.java#L190
It is generating an empty file slice if there is a pending compaction,
without any base file or log file. This is bound to cause failure in the small
files logic.
Can you please confirm if my findings make sense to you ?
Also from the comment:
```
// If there is no delta-commit after compaction request, this step would
ensure a new file-slice appears
// so that any new ingestion uses the correct base-instant
```
I only see us checking for pending compaction, but not for presence of delta
commit after compaction request. So is that code actually doing whats its
intended to ?
As for our customer, I am suggestion for now to turn off the small files
optimizations feature by setting `HoodieStorageConfig.PARQUET_FILE_MAX_BYTES`
to `0`.
Another action item from this, is that small files optimizations code needs
a check to ignore the file slice if its completely empty instead of causing a
failure, since empty file slice can be expected.
**Environment Description**
* Hudi version : 0.6.0
* Spark version : 2.4.6
* Hive version :
* Hadoop version : 2.8.5
* Storage (HDFS/S3/GCS..) : S3
* Running on Docker? (yes/no) : no
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
{kind=link}