[jira] [Work logged] (HDFS-15382) Split FsDatasetImpl from blockpool lock to blockpool volume lock
[ https://issues.apache.org/jira/browse/HDFS-15382?focusedWorklogId=731392&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731392 ] ASF GitHub Bot logged work on HDFS-15382: - Author: ASF GitHub Bot Created on: 23/Feb/22 07:04 Start Date: 23/Feb/22 07:04 Worklog Time Spent: 10m Work Description: jojochuang commented on a change in pull request #3941: URL: https://github.com/apache/hadoop/pull/3941#discussion_r812604507 ## File path: hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/fsdataset/impl/ReplicaMap.java ## @@ -6,58 +6,62 @@ * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at - * - * http://www.apache.org/licenses/LICENSE-2.0 - * + * Review comment: Please, don't touch the license boiler plate text. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 731392) Time Spent: 3h (was: 2h 50m) > Split FsDatasetImpl from blockpool lock to blockpool volume lock > - > > Key: HDFS-15382 > URL: https://issues.apache.org/jira/browse/HDFS-15382 > Project: Hadoop HDFS > Issue Type: Improvement >Reporter: Mingxiang Li >Assignee: Mingxiang Li >Priority: Major > Labels: pull-request-available > Attachments: HDFS-15382-sample.patch, image-2020-06-02-1.png, > image-2020-06-03-1.png > > Time Spent: 3h > Remaining Estimate: 0h > > In HDFS-15180 we split lock to blockpool grain size.But when one volume is in > heavy load and will block other request which in same blockpool but different > volume.So we split lock to two leval to avoid this happend.And to improve > datanode performance. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-15382) Split FsDatasetImpl from blockpool lock to blockpool volume lock
[ https://issues.apache.org/jira/browse/HDFS-15382?focusedWorklogId=731393&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731393 ] ASF GitHub Bot logged work on HDFS-15382: - Author: ASF GitHub Bot Created on: 23/Feb/22 07:04 Start Date: 23/Feb/22 07:04 Worklog Time Spent: 10m Work Description: jojochuang commented on a change in pull request #3941: URL: https://github.com/apache/hadoop/pull/3941#discussion_r812604507 ## File path: hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/fsdataset/impl/ReplicaMap.java ## @@ -6,58 +6,62 @@ * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at - * - * http://www.apache.org/licenses/LICENSE-2.0 - * + * Review comment: Please leave the license boiler plate text unchanged. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 731393) Time Spent: 3h 10m (was: 3h) > Split FsDatasetImpl from blockpool lock to blockpool volume lock > - > > Key: HDFS-15382 > URL: https://issues.apache.org/jira/browse/HDFS-15382 > Project: Hadoop HDFS > Issue Type: Improvement >Reporter: Mingxiang Li >Assignee: Mingxiang Li >Priority: Major > Labels: pull-request-available > Attachments: HDFS-15382-sample.patch, image-2020-06-02-1.png, > image-2020-06-03-1.png > > Time Spent: 3h 10m > Remaining Estimate: 0h > > In HDFS-15180 we split lock to blockpool grain size.But when one volume is in > heavy load and will block other request which in same blockpool but different > volume.So we split lock to two leval to avoid this happend.And to improve > datanode performance. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-11107) TestStartup#testStorageBlockContentsStaleAfterNNRestart fails intermittently
[
https://issues.apache.org/jira/browse/HDFS-11107?focusedWorklogId=731378&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731378
]
ASF GitHub Bot logged work on HDFS-11107:
-
Author: ASF GitHub Bot
Created on: 23/Feb/22 06:33
Start Date: 23/Feb/22 06:33
Worklog Time Spent: 10m
Work Description: ayushtkn commented on pull request #3862:
URL: https://github.com/apache/hadoop/pull/3862#issuecomment-1048485017
The error message in the description is an Assertion Error. Not a timeout
error.
```
Error Message
expected:<0> but was:<2>
Stacktrace
java.lang.AssertionError: expected:<0> but was:<2>
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 731378)
Time Spent: 50m (was: 40m)
> TestStartup#testStorageBlockContentsStaleAfterNNRestart fails intermittently
>
>
> Key: HDFS-11107
> URL: https://issues.apache.org/jira/browse/HDFS-11107
> Project: Hadoop HDFS
> Issue Type: Sub-task
> Components: hdfs
>Reporter: Xiaobing Zhou
>Assignee: Ajith S
>Priority: Minor
> Labels: flaky-test, pull-request-available, unit-test
> Time Spent: 50m
> Remaining Estimate: 0h
>
> It's noticed that this failed in the last Jenkins run of HDFS-11085, but it's
> not reproducible and passed with and without the patch.
> {noformat}
> Error Message
> expected:<0> but was:<2>
> Stacktrace
> java.lang.AssertionError: expected:<0> but was:<2>
> at org.junit.Assert.fail(Assert.java:88)
> at org.junit.Assert.failNotEquals(Assert.java:743)
> at org.junit.Assert.assertEquals(Assert.java:118)
> at org.junit.Assert.assertEquals(Assert.java:555)
> at org.junit.Assert.assertEquals(Assert.java:542)
> at
> org.apache.hadoop.hdfs.server.namenode.TestStartup.testStorageBlockContentsStaleAfterNNRestart(TestStartup.java:726)
> {noformat}
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16479) EC: When reconstruting ec block index, liveBusyBlockIndicies is not enclude, then reconstructing will fail
[
https://issues.apache.org/jira/browse/HDFS-16479?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Yuanbo Liu updated HDFS-16479:
--
Description:
We got this exception from DataNodes
{color:#707070}java.lang.IllegalArgumentException: No enough live striped
blocks.{color}
{color:#707070} at
com.google.common.base.Preconditions.checkArgument(Preconditions.java:141){color}
{color:#707070} at
org.apache.hadoop.hdfs.server.datanode.erasurecode.StripedReader.(StripedReader.java:128){color}
{color:#707070} at
org.apache.hadoop.hdfs.server.datanode.erasurecode.StripedReconstructor.(StripedReconstructor.java:135){color}
{color:#707070} at
org.apache.hadoop.hdfs.server.datanode.erasurecode.StripedBlockReconstructor.(StripedBlockReconstructor.java:41){color}
{color:#707070} at
org.apache.hadoop.hdfs.server.datanode.erasurecode.ErasureCodingWorker.processErasureCodingTasks(ErasureCodingWorker.java:133){color}
{color:#707070} at
org.apache.hadoop.hdfs.server.datanode.BPOfferService.processCommandFromActive(BPOfferService.java:796){color}
{color:#707070} at
org.apache.hadoop.hdfs.server.datanode.BPOfferService.processCommandFromActor(BPOfferService.java:680){color}
{color:#707070} at
org.apache.hadoop.hdfs.server.datanode.BPServiceActor$CommandProcessingThread.processCommand(BPServiceActor.java:1314){color}
{color:#707070} at
org.apache.hadoop.hdfs.server.datanode.BPServiceActor$CommandProcessingThread.lambda$enqueue$2(BPServiceActor.java:1360){color}
{color:#707070} at
org.apache.hadoop.hdfs.server.datanode.BPServiceActor$CommandProcessingThread.processQueue(BPServiceActor.java:1287){color}
After going through the code of ErasureCodingWork.java, we found
{code:java}
targets[0].getDatanodeDescriptor().addBlockToBeErasureCoded( new
ExtendedBlock(blockPoolId, stripedBlk), getSrcNodes(), targets,
getLiveBlockIndicies(), stripedBlk.getErasureCodingPolicy());
{code}
the liveBusyBlockIndicies is not considered as liveBlockIndicies, hence erasure
coding reconstruction sometimes will fail as 'No enough live striped blocks'.
was:
We got this exception from DataNodes
`
java.lang.IllegalArgumentException: No enough live striped blocks.
at
com.google.common.base.Preconditions.checkArgument(Preconditions.java:141)
at
org.apache.hadoop.hdfs.server.datanode.erasurecode.StripedReader.(StripedReader.java:128)
at
org.apache.hadoop.hdfs.server.datanode.erasurecode.StripedReconstructor.(StripedReconstructor.java:135)
at
org.apache.hadoop.hdfs.server.datanode.erasurecode.StripedBlockReconstructor.(StripedBlockReconstructor.java:41)
at
org.apache.hadoop.hdfs.server.datanode.erasurecode.ErasureCodingWorker.processErasureCodingTasks(ErasureCodingWorker.java:133)
at
org.apache.hadoop.hdfs.server.datanode.BPOfferService.processCommandFromActive(BPOfferService.java:796)
at
org.apache.hadoop.hdfs.server.datanode.BPOfferService.processCommandFromActor(BPOfferService.java:680)
at
org.apache.hadoop.hdfs.server.datanode.BPServiceActor$CommandProcessingThread.processCommand(BPServiceActor.java:1314)
at
org.apache.hadoop.hdfs.server.datanode.BPServiceActor$CommandProcessingThread.lambda$enqueue$2(BPServiceActor.java:1360)
at
org.apache.hadoop.hdfs.server.datanode.BPServiceActor$CommandProcessingThread.processQueue(BPServiceActor.java:1287)
`
After going through the code of ErasureCodingWork.java, we found
`java
else {
targets[0].getDatanodeDescriptor().addBlockToBeErasureCoded(
new ExtendedBlock(blockPoolId, stripedBlk), getSrcNodes(), targets,
getLiveBlockIndicies(), stripedBlk.getErasureCodingPolicy());
}
`
the liveBusyBlockIndicies is not considered as liveBlockIndicies, hence erasure
coding reconstruction sometimes will fail as 'No enough live striped blocks'.
> EC: When reconstruting ec block index, liveBusyBlockIndicies is not enclude,
> then reconstructing will fail
> --
>
> Key: HDFS-16479
> URL: https://issues.apache.org/jira/browse/HDFS-16479
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: ec, erasure-coding
>Reporter: Yuanbo Liu
>Priority: Critical
>
> We got this exception from DataNodes
> {color:#707070}java.lang.IllegalArgumentException: No enough live striped
> blocks.{color}
> {color:#707070} at
> com.google.common.base.Preconditions.checkArgument(Preconditions.java:141){color}
> {color:#707070} at
> org.apache.hadoop.hdfs.server.datanode.erasurecode.StripedReader.(StripedReader.java:128){color}
> {color:#707070} at
> org.apache.hadoop.hdfs.server.datanode.erasurecode.StripedReconstructor.(StripedReconstructor.java:135){color}
> {color:#707070} at
> org.apache
[jira] [Created] (HDFS-16479) EC: When reconstruting ec block index, liveBusyBlockIndicies is not enclude, then reconstructing will fail
Yuanbo Liu created HDFS-16479:
-
Summary: EC: When reconstruting ec block index,
liveBusyBlockIndicies is not enclude, then reconstructing will fail
Key: HDFS-16479
URL: https://issues.apache.org/jira/browse/HDFS-16479
Project: Hadoop HDFS
Issue Type: Bug
Components: ec, erasure-coding
Reporter: Yuanbo Liu
We got this exception from DataNodes
`
java.lang.IllegalArgumentException: No enough live striped blocks.
at
com.google.common.base.Preconditions.checkArgument(Preconditions.java:141)
at
org.apache.hadoop.hdfs.server.datanode.erasurecode.StripedReader.(StripedReader.java:128)
at
org.apache.hadoop.hdfs.server.datanode.erasurecode.StripedReconstructor.(StripedReconstructor.java:135)
at
org.apache.hadoop.hdfs.server.datanode.erasurecode.StripedBlockReconstructor.(StripedBlockReconstructor.java:41)
at
org.apache.hadoop.hdfs.server.datanode.erasurecode.ErasureCodingWorker.processErasureCodingTasks(ErasureCodingWorker.java:133)
at
org.apache.hadoop.hdfs.server.datanode.BPOfferService.processCommandFromActive(BPOfferService.java:796)
at
org.apache.hadoop.hdfs.server.datanode.BPOfferService.processCommandFromActor(BPOfferService.java:680)
at
org.apache.hadoop.hdfs.server.datanode.BPServiceActor$CommandProcessingThread.processCommand(BPServiceActor.java:1314)
at
org.apache.hadoop.hdfs.server.datanode.BPServiceActor$CommandProcessingThread.lambda$enqueue$2(BPServiceActor.java:1360)
at
org.apache.hadoop.hdfs.server.datanode.BPServiceActor$CommandProcessingThread.processQueue(BPServiceActor.java:1287)
`
After going through the code of ErasureCodingWork.java, we found
`java
else {
targets[0].getDatanodeDescriptor().addBlockToBeErasureCoded(
new ExtendedBlock(blockPoolId, stripedBlk), getSrcNodes(), targets,
getLiveBlockIndicies(), stripedBlk.getErasureCodingPolicy());
}
`
the liveBusyBlockIndicies is not considered as liveBlockIndicies, hence erasure
coding reconstruction sometimes will fail as 'No enough live striped blocks'.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16476) Increase the number of metrics used to record PendingRecoveryBlocks
[ https://issues.apache.org/jira/browse/HDFS-16476?focusedWorklogId=731363&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731363 ] ASF GitHub Bot logged work on HDFS-16476: - Author: ASF GitHub Bot Created on: 23/Feb/22 05:37 Start Date: 23/Feb/22 05:37 Worklog Time Spent: 10m Work Description: jianghuazhu commented on pull request #4010: URL: https://github.com/apache/hadoop/pull/4010#issuecomment-1048463738 OK, I'll try to perfect it as much as possible. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 731363) Time Spent: 1h (was: 50m) > Increase the number of metrics used to record PendingRecoveryBlocks > --- > > Key: HDFS-16476 > URL: https://issues.apache.org/jira/browse/HDFS-16476 > Project: Hadoop HDFS > Issue Type: Improvement > Components: metrics, namenode >Affects Versions: 2.9.2, 3.4.0 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Labels: pull-request-available > Time Spent: 1h > Remaining Estimate: 0h > > The complete process of block recovery is as follows: > 1. NameNode collects which blocks need to be recovered. > 2. The NameNode issues instructions to some DataNodes for execution. > 3. DataNode tells NameNode after execution is complete. > Now there is no way to know how many blocks are being recovered. The number > of metrics used to record PendingRecoveryBlocks should be increased, which is > good for increasing the robustness of the cluster. > Here are some logs of DataNode execution: > 2022-02-10 23:51:04,386 [12208592621] - INFO [IPC Server handler 38 on > 8025:FsDatasetImpl@2687] - initReplicaRecovery: changing replica state for > blk_ from RBW to RUR > 2022-02-10 23:51:04,395 [12208592630] - INFO [IPC Server handler 47 on > 8025:FsDatasetImpl@2708] - updateReplica: BP-:blk_, > recoveryId=18386356475, length=129869866, replica=ReplicaUnderRecovery, > blk_, RUR > Here are some logs that NameNdoe receives after completion: > 2022-02-22 10:43:58,780 [8193058814] - INFO [IPC Server handler 15 on > 8021:FSNamesystem@3647] - commitBlockSynchronization(oldBlock=BP-, > newgenerationstamp=18551926574, newlength=16929, newtargets=[1:1004, > 2:1004, 3:1004]) successful -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16476) Increase the number of metrics used to record PendingRecoveryBlocks
[ https://issues.apache.org/jira/browse/HDFS-16476?focusedWorklogId=731357&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731357 ] ASF GitHub Bot logged work on HDFS-16476: - Author: ASF GitHub Bot Created on: 23/Feb/22 05:12 Start Date: 23/Feb/22 05:12 Worklog Time Spent: 10m Work Description: ayushtkn commented on pull request #4010: URL: https://github.com/apache/hadoop/pull/4010#issuecomment-1048454886 > I think the block recovery work is something between NameNode and DataNode, so in the RBF module For all such cases we have got the values from all namenodes at Router and then summed up for the metrics, So, as at the Router we can have a global look. We should do the same here as well -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 731357) Time Spent: 40m (was: 0.5h) > Increase the number of metrics used to record PendingRecoveryBlocks > --- > > Key: HDFS-16476 > URL: https://issues.apache.org/jira/browse/HDFS-16476 > Project: Hadoop HDFS > Issue Type: Improvement > Components: metrics, namenode >Affects Versions: 2.9.2, 3.4.0 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Labels: pull-request-available > Time Spent: 40m > Remaining Estimate: 0h > > The complete process of block recovery is as follows: > 1. NameNode collects which blocks need to be recovered. > 2. The NameNode issues instructions to some DataNodes for execution. > 3. DataNode tells NameNode after execution is complete. > Now there is no way to know how many blocks are being recovered. The number > of metrics used to record PendingRecoveryBlocks should be increased, which is > good for increasing the robustness of the cluster. > Here are some logs of DataNode execution: > 2022-02-10 23:51:04,386 [12208592621] - INFO [IPC Server handler 38 on > 8025:FsDatasetImpl@2687] - initReplicaRecovery: changing replica state for > blk_ from RBW to RUR > 2022-02-10 23:51:04,395 [12208592630] - INFO [IPC Server handler 47 on > 8025:FsDatasetImpl@2708] - updateReplica: BP-:blk_, > recoveryId=18386356475, length=129869866, replica=ReplicaUnderRecovery, > blk_, RUR > Here are some logs that NameNdoe receives after completion: > 2022-02-22 10:43:58,780 [8193058814] - INFO [IPC Server handler 15 on > 8021:FSNamesystem@3647] - commitBlockSynchronization(oldBlock=BP-, > newgenerationstamp=18551926574, newlength=16929, newtargets=[1:1004, > 2:1004, 3:1004]) successful -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16476) Increase the number of metrics used to record PendingRecoveryBlocks
[ https://issues.apache.org/jira/browse/HDFS-16476?focusedWorklogId=731358&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731358 ] ASF GitHub Bot logged work on HDFS-16476: - Author: ASF GitHub Bot Created on: 23/Feb/22 05:12 Start Date: 23/Feb/22 05:12 Worklog Time Spent: 10m Work Description: ayushtkn edited a comment on pull request #4010: URL: https://github.com/apache/hadoop/pull/4010#issuecomment-1048454886 > I think the block recovery work is something between NameNode and DataNode, so in the RBF module For all such cases we have got the values from all namenodes at Router and then summed up for the metrics, So, as at the Router we can have a global look. We should do the same here as well -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 731358) Time Spent: 50m (was: 40m) > Increase the number of metrics used to record PendingRecoveryBlocks > --- > > Key: HDFS-16476 > URL: https://issues.apache.org/jira/browse/HDFS-16476 > Project: Hadoop HDFS > Issue Type: Improvement > Components: metrics, namenode >Affects Versions: 2.9.2, 3.4.0 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Labels: pull-request-available > Time Spent: 50m > Remaining Estimate: 0h > > The complete process of block recovery is as follows: > 1. NameNode collects which blocks need to be recovered. > 2. The NameNode issues instructions to some DataNodes for execution. > 3. DataNode tells NameNode after execution is complete. > Now there is no way to know how many blocks are being recovered. The number > of metrics used to record PendingRecoveryBlocks should be increased, which is > good for increasing the robustness of the cluster. > Here are some logs of DataNode execution: > 2022-02-10 23:51:04,386 [12208592621] - INFO [IPC Server handler 38 on > 8025:FsDatasetImpl@2687] - initReplicaRecovery: changing replica state for > blk_ from RBW to RUR > 2022-02-10 23:51:04,395 [12208592630] - INFO [IPC Server handler 47 on > 8025:FsDatasetImpl@2708] - updateReplica: BP-:blk_, > recoveryId=18386356475, length=129869866, replica=ReplicaUnderRecovery, > blk_, RUR > Here are some logs that NameNdoe receives after completion: > 2022-02-22 10:43:58,780 [8193058814] - INFO [IPC Server handler 15 on > 8021:FSNamesystem@3647] - commitBlockSynchronization(oldBlock=BP-, > newgenerationstamp=18551926574, newlength=16929, newtargets=[1:1004, > 2:1004, 3:1004]) successful -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16478) Multiple command processor threads have same name
[
https://issues.apache.org/jira/browse/HDFS-16478?focusedWorklogId=731354&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731354
]
ASF GitHub Bot logged work on HDFS-16478:
-
Author: ASF GitHub Bot
Created on: 23/Feb/22 05:05
Start Date: 23/Feb/22 05:05
Worklog Time Spent: 10m
Work Description: ayushtkn commented on a change in pull request #4016:
URL: https://github.com/apache/hadoop/pull/4016#discussion_r812562187
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/BPServiceActor.java
##
@@ -1378,7 +1378,7 @@ public long monotonicNow() {
private final BlockingQueue queue;
CommandProcessingThread(BPServiceActor actor) {
- super("Command processor");
+ setName("Command processor-" + getId());
Review comment:
I think the issue here is in case of MiniDfsCluster all datanodes log at
one place.Means if we spin a MiniDfsCluster with 9 datanodes, all Command
processor threads will log at same place, and we can't distinguish, which
thread belongs to which datanode.
DN1 will also have same name & DN2 till DN9. If we add namenode address,
then also the names of the thread will stay same right? All datanodes in a
single MiniDfs will be connected to same set of namenodes, right?
May be adding DN address should be a good idea?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 731354)
Time Spent: 1h 20m (was: 1h 10m)
> Multiple command processor threads have same name
> -
>
> Key: HDFS-16478
> URL: https://issues.apache.org/jira/browse/HDFS-16478
> Project: Hadoop HDFS
> Issue Type: Task
> Components: datanode
>Reporter: Mike Drob
>Priority: Minor
> Labels: pull-request-available
> Time Spent: 1h 20m
> Remaining Estimate: 0h
>
> When running an in-process MiniDFSCluster with multiple data nodes, the
> command processor threads all share the same name, making them more difficult
> to get debug and logging information from.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16478) Multiple command processor threads have same name
[
https://issues.apache.org/jira/browse/HDFS-16478?focusedWorklogId=731352&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731352
]
ASF GitHub Bot logged work on HDFS-16478:
-
Author: ASF GitHub Bot
Created on: 23/Feb/22 04:54
Start Date: 23/Feb/22 04:54
Worklog Time Spent: 10m
Work Description: Hexiaoqiao commented on a change in pull request #4016:
URL: https://github.com/apache/hadoop/pull/4016#discussion_r812559159
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/BPServiceActor.java
##
@@ -1378,7 +1378,7 @@ public long monotonicNow() {
private final BlockingQueue queue;
CommandProcessingThread(BPServiceActor actor) {
- super("Command processor");
+ setName("Command processor-" + getId());
Review comment:
> Putting the NN address in would not disambiguate the logs because they
would all be for the same NN still. It would give more information, sure, but
not actually helpful information.
Sorry I don't this information. IIUC, now each command processor match to
block pool one by one. and actually `nnAddr` includes hostname/port together. I
mean that it could different each other even for MiniDFSCluster framework.
Right? for another way, with nnAddr, it could be helpful to dig when this
thread meet issues.
Anyway, I don't disagree to add getId() also here. We could add both them to
the thread name.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 731352)
Time Spent: 1h 10m (was: 1h)
> Multiple command processor threads have same name
> -
>
> Key: HDFS-16478
> URL: https://issues.apache.org/jira/browse/HDFS-16478
> Project: Hadoop HDFS
> Issue Type: Task
> Components: datanode
>Reporter: Mike Drob
>Priority: Minor
> Labels: pull-request-available
> Time Spent: 1h 10m
> Remaining Estimate: 0h
>
> When running an in-process MiniDFSCluster with multiple data nodes, the
> command processor threads all share the same name, making them more difficult
> to get debug and logging information from.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-15382) Split FsDatasetImpl from blockpool lock to blockpool volume lock
[ https://issues.apache.org/jira/browse/HDFS-15382?focusedWorklogId=731346&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731346 ] ASF GitHub Bot logged work on HDFS-15382: - Author: ASF GitHub Bot Created on: 23/Feb/22 04:35 Start Date: 23/Feb/22 04:35 Worklog Time Spent: 10m Work Description: Hexiaoqiao commented on pull request #3941: URL: https://github.com/apache/hadoop/pull/3941#issuecomment-1048442517 @jojochuang @tomscut The previous PR has merge refer to https://github.com/apache/hadoop/pull/3900. At this PR it improve LightWeightResizableGSet to thread-safe and create LockManager mode. Please reference. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 731346) Time Spent: 2h 50m (was: 2h 40m) > Split FsDatasetImpl from blockpool lock to blockpool volume lock > - > > Key: HDFS-15382 > URL: https://issues.apache.org/jira/browse/HDFS-15382 > Project: Hadoop HDFS > Issue Type: Improvement >Reporter: Mingxiang Li >Assignee: Mingxiang Li >Priority: Major > Labels: pull-request-available > Attachments: HDFS-15382-sample.patch, image-2020-06-02-1.png, > image-2020-06-03-1.png > > Time Spent: 2h 50m > Remaining Estimate: 0h > > In HDFS-15180 we split lock to blockpool grain size.But when one volume is in > heavy load and will block other request which in same blockpool but different > volume.So we split lock to two leval to avoid this happend.And to improve > datanode performance. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16478) Multiple command processor threads have same name
[
https://issues.apache.org/jira/browse/HDFS-16478?focusedWorklogId=731345&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731345
]
ASF GitHub Bot logged work on HDFS-16478:
-
Author: ASF GitHub Bot
Created on: 23/Feb/22 04:31
Start Date: 23/Feb/22 04:31
Worklog Time Spent: 10m
Work Description: madrob commented on a change in pull request #4016:
URL: https://github.com/apache/hadoop/pull/4016#discussion_r812552531
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/BPServiceActor.java
##
@@ -1378,7 +1378,7 @@ public long monotonicNow() {
private final BlockingQueue queue;
CommandProcessingThread(BPServiceActor actor) {
- super("Command processor");
+ setName("Command processor-" + getId());
Review comment:
Thanks for the suggestion, but I don't think that would be an
improvement. Let me explain the motivation in more detail?
The id is just the numeric Java thread id, and it's enough to differentiate
the command processors between each other when there are multiple DN running in
the same process like in MiniDFSCluster during unit tests.
Putting the NN address in would not disambiguate the logs because they would
all be for the same NN still. It would give more information, sure, but not
actually helpful information.
With my change, the log messages would have (Command processor-56) or -68 or
whatever the thread was. Again, just enough to differentiate them from one
another, which is what I needed for tracing their lifecycle and operation.
If there's a DN address we can use in the thread name instead, then that's
good too but I don't know enough about Hadoop internals to find that.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 731345)
Time Spent: 1h (was: 50m)
> Multiple command processor threads have same name
> -
>
> Key: HDFS-16478
> URL: https://issues.apache.org/jira/browse/HDFS-16478
> Project: Hadoop HDFS
> Issue Type: Task
> Components: datanode
>Reporter: Mike Drob
>Priority: Minor
> Labels: pull-request-available
> Time Spent: 1h
> Remaining Estimate: 0h
>
> When running an in-process MiniDFSCluster with multiple data nodes, the
> command processor threads all share the same name, making them more difficult
> to get debug and logging information from.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16431) Truncate CallerContext in client side
[ https://issues.apache.org/jira/browse/HDFS-16431?focusedWorklogId=731344&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731344 ] ASF GitHub Bot logged work on HDFS-16431: - Author: ASF GitHub Bot Created on: 23/Feb/22 04:29 Start Date: 23/Feb/22 04:29 Worklog Time Spent: 10m Work Description: Hexiaoqiao commented on pull request #3909: URL: https://github.com/apache/hadoop/pull/3909#issuecomment-1048440490 Thanks @smarthanwang involve me here. I am not very familiar with CallerContext. I think @jojochuang should be the good candidate to review it. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 731344) Time Spent: 2h 10m (was: 2h) > Truncate CallerContext in client side > - > > Key: HDFS-16431 > URL: https://issues.apache.org/jira/browse/HDFS-16431 > Project: Hadoop HDFS > Issue Type: Improvement > Components: nn >Reporter: Chengwei Wang >Assignee: Chengwei Wang >Priority: Major > Labels: pull-request-available > Time Spent: 2h 10m > Remaining Estimate: 0h > > The context of CallerContext would be truncated when it exceeds the maximum > allowed length in server side. I think it's better to do check and truncate > in client side to reduce the unnecessary overhead of network and memory for > NN. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16155) Allow configurable exponential backoff in DFSInputStream refetchLocations
[ https://issues.apache.org/jira/browse/HDFS-16155?focusedWorklogId=731341&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731341 ] ASF GitHub Bot logged work on HDFS-16155: - Author: ASF GitHub Bot Created on: 23/Feb/22 04:25 Start Date: 23/Feb/22 04:25 Worklog Time Spent: 10m Work Description: Hexiaoqiao commented on pull request #3271: URL: https://github.com/apache/hadoop/pull/3271#issuecomment-1048438966 Thanks @bbeaudreault for your great works here and sorry for the late response. It looks good to me in general. +2 from my side. I would like to wait if any other guys are interested for this improvement. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 731341) Time Spent: 3h (was: 2h 50m) > Allow configurable exponential backoff in DFSInputStream refetchLocations > - > > Key: HDFS-16155 > URL: https://issues.apache.org/jira/browse/HDFS-16155 > Project: Hadoop HDFS > Issue Type: Improvement > Components: dfsclient >Reporter: Bryan Beaudreault >Assignee: Bryan Beaudreault >Priority: Minor > Labels: pull-request-available > Time Spent: 3h > Remaining Estimate: 0h > > The retry policy in > [DFSInputStream#refetchLocations|https://github.com/apache/hadoop/blob/trunk/hadoop-hdfs-project/hadoop-hdfs-client/src/main/java/org/apache/hadoop/hdfs/DFSInputStream.java#L1018-L1040] > was first written many years ago. It allows configuration of the base time > window, but subsequent retries double in an un-configurable way. This retry > strategy makes sense in some clusters as it's very conservative and will > avoid DDOSing the namenode in certain systemic failure modes – for example, > if a file is being read by a large hadoop job and the underlying blocks are > moved by the balancer. In this case, enough datanodes would be added to the > deadNodes list and all hadoop tasks would simultaneously try to refetch the > blocks. The 3s doubling with random factor helps break up that stampeding > herd. > However, not all cluster use-cases are created equal, so there are other > cases where a more aggressive initial backoff is preferred. For example in a > low-latency single reader scenario. In this case, if the balancer moves > enough blocks, the reader hits this 3s backoff which is way too long for a > low latency use-case. > One could configure the the window very low (10ms), but then you can hit > other systemic failure modes which would result in readers DDOSing the > namenode again. For example, if blocks went missing due to truly dead > datanodes. In this case, many readers might be refetching locations for > different files with retry backoffs like 10ms, 20ms, 40ms, etc. It takes a > while to backoff enough to avoid impacting the namenode with that strategy. > I suggest adding a configurable multiplier to the backoff strategy so that > operators can tune this as they see fit for their use-case. In the above low > latency case, one could set the base very low (say 2ms) and the multiplier > very high (say 50). This gives an aggressive first retry that very quickly > backs off. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16155) Allow configurable exponential backoff in DFSInputStream refetchLocations
[ https://issues.apache.org/jira/browse/HDFS-16155?focusedWorklogId=731342&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731342 ] ASF GitHub Bot logged work on HDFS-16155: - Author: ASF GitHub Bot Created on: 23/Feb/22 04:25 Start Date: 23/Feb/22 04:25 Worklog Time Spent: 10m Work Description: Hexiaoqiao edited a comment on pull request #3271: URL: https://github.com/apache/hadoop/pull/3271#issuecomment-1048438966 Thanks @bbeaudreault for your great works here and sorry for the late response. It looks good to me in general. +1 from my side. I would like to wait if any other guys are interested for this improvement. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 731342) Time Spent: 3h 10m (was: 3h) > Allow configurable exponential backoff in DFSInputStream refetchLocations > - > > Key: HDFS-16155 > URL: https://issues.apache.org/jira/browse/HDFS-16155 > Project: Hadoop HDFS > Issue Type: Improvement > Components: dfsclient >Reporter: Bryan Beaudreault >Assignee: Bryan Beaudreault >Priority: Minor > Labels: pull-request-available > Time Spent: 3h 10m > Remaining Estimate: 0h > > The retry policy in > [DFSInputStream#refetchLocations|https://github.com/apache/hadoop/blob/trunk/hadoop-hdfs-project/hadoop-hdfs-client/src/main/java/org/apache/hadoop/hdfs/DFSInputStream.java#L1018-L1040] > was first written many years ago. It allows configuration of the base time > window, but subsequent retries double in an un-configurable way. This retry > strategy makes sense in some clusters as it's very conservative and will > avoid DDOSing the namenode in certain systemic failure modes – for example, > if a file is being read by a large hadoop job and the underlying blocks are > moved by the balancer. In this case, enough datanodes would be added to the > deadNodes list and all hadoop tasks would simultaneously try to refetch the > blocks. The 3s doubling with random factor helps break up that stampeding > herd. > However, not all cluster use-cases are created equal, so there are other > cases where a more aggressive initial backoff is preferred. For example in a > low-latency single reader scenario. In this case, if the balancer moves > enough blocks, the reader hits this 3s backoff which is way too long for a > low latency use-case. > One could configure the the window very low (10ms), but then you can hit > other systemic failure modes which would result in readers DDOSing the > namenode again. For example, if blocks went missing due to truly dead > datanodes. In this case, many readers might be refetching locations for > different files with retry backoffs like 10ms, 20ms, 40ms, etc. It takes a > while to backoff enough to avoid impacting the namenode with that strategy. > I suggest adding a configurable multiplier to the backoff strategy so that > operators can tune this as they see fit for their use-case. In the above low > latency case, one could set the base very low (say 2ms) and the multiplier > very high (say 50). This gives an aggressive first retry that very quickly > backs off. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16478) Multiple command processor threads have same name
[
https://issues.apache.org/jira/browse/HDFS-16478?focusedWorklogId=731339&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731339
]
ASF GitHub Bot logged work on HDFS-16478:
-
Author: ASF GitHub Bot
Created on: 23/Feb/22 04:19
Start Date: 23/Feb/22 04:19
Worklog Time Spent: 10m
Work Description: Hexiaoqiao commented on a change in pull request #4016:
URL: https://github.com/apache/hadoop/pull/4016#discussion_r812548069
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/BPServiceActor.java
##
@@ -1378,7 +1378,7 @@ public long monotonicNow() {
private final BlockingQueue queue;
CommandProcessingThread(BPServiceActor actor) {
- super("Command processor");
+ setName("Command processor-" + getId());
Review comment:
Thanks @madrob for your works. I don't think `getId()` will get
additional information.
IMO, it may be better to change like the following?
` super("Command processor for " + nnAddr);`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 731339)
Time Spent: 50m (was: 40m)
> Multiple command processor threads have same name
> -
>
> Key: HDFS-16478
> URL: https://issues.apache.org/jira/browse/HDFS-16478
> Project: Hadoop HDFS
> Issue Type: Task
> Components: datanode
>Reporter: Mike Drob
>Priority: Minor
> Labels: pull-request-available
> Time Spent: 50m
> Remaining Estimate: 0h
>
> When running an in-process MiniDFSCluster with multiple data nodes, the
> command processor threads all share the same name, making them more difficult
> to get debug and logging information from.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16460) [SPS]: Handle failure retries for moving tasks
[ https://issues.apache.org/jira/browse/HDFS-16460?focusedWorklogId=731336&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731336 ] ASF GitHub Bot logged work on HDFS-16460: - Author: ASF GitHub Bot Created on: 23/Feb/22 03:56 Start Date: 23/Feb/22 03:56 Worklog Time Spent: 10m Work Description: tomscut commented on pull request #4001: URL: https://github.com/apache/hadoop/pull/4001#issuecomment-1048427499 Hi @jojochuang @tasanuma @Hexiaoqiao @ferhui , PTAL. Thanks. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 731336) Remaining Estimate: 0h Time Spent: 10m > [SPS]: Handle failure retries for moving tasks > -- > > Key: HDFS-16460 > URL: https://issues.apache.org/jira/browse/HDFS-16460 > Project: Hadoop HDFS > Issue Type: Sub-task >Reporter: tomscut >Assignee: tomscut >Priority: Major > Time Spent: 10m > Remaining Estimate: 0h > > Handle failure retries for moving tasks. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16460) [SPS]: Handle failure retries for moving tasks
[ https://issues.apache.org/jira/browse/HDFS-16460?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDFS-16460: -- Labels: pull-request-available (was: ) > [SPS]: Handle failure retries for moving tasks > -- > > Key: HDFS-16460 > URL: https://issues.apache.org/jira/browse/HDFS-16460 > Project: Hadoop HDFS > Issue Type: Sub-task >Reporter: tomscut >Assignee: tomscut >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > Handle failure retries for moving tasks. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-11041) Unable to unregister FsDatasetState MBean if DataNode is shutdown twice
[
https://issues.apache.org/jira/browse/HDFS-11041?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Wei-Chiu Chuang updated HDFS-11041:
---
Fix Version/s: 2.10.2
3.2.3
3.3.3
> Unable to unregister FsDatasetState MBean if DataNode is shutdown twice
> ---
>
> Key: HDFS-11041
> URL: https://issues.apache.org/jira/browse/HDFS-11041
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: datanode
>Reporter: Wei-Chiu Chuang
>Assignee: Wei-Chiu Chuang
>Priority: Trivial
> Fix For: 3.4.0, 2.10.2, 3.2.3, 3.3.3
>
> Attachments: HDFS-11041.01.patch, HDFS-11041.02.patch,
> HDFS-11041.03.patch
>
>
> I saw error message like the following in some tests
> {noformat}
> 2016-10-21 04:09:03,900 [main] WARN util.MBeans
> (MBeans.java:unregister(114)) - Error unregistering
> Hadoop:service=DataNode,name=FSDatasetState-33cd714c-0b1a-471f-8efe-f431d7d874bc
> javax.management.InstanceNotFoundException:
> Hadoop:service=DataNode,name=FSDatasetState-33cd714c-0b1a-471f-8efe-f431d7d874bc
> at
> com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.getMBean(DefaultMBeanServerInterceptor.java:1095)
> at
> com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.exclusiveUnregisterMBean(DefaultMBeanServerInterceptor.java:427)
> at
> com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.unregisterMBean(DefaultMBeanServerInterceptor.java:415)
> at
> com.sun.jmx.mbeanserver.JmxMBeanServer.unregisterMBean(JmxMBeanServer.java:546)
> at org.apache.hadoop.metrics2.util.MBeans.unregister(MBeans.java:112)
> at
> org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl.shutdown(FsDatasetImpl.java:2127)
> at
> org.apache.hadoop.hdfs.server.datanode.DataNode.shutdown(DataNode.java:2016)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdownDataNodes(MiniDFSCluster.java:1985)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdown(MiniDFSCluster.java:1962)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdown(MiniDFSCluster.java:1936)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdown(MiniDFSCluster.java:1929)
> at
> org.apache.hadoop.hdfs.TestDatanodeReport.testDatanodeReport(TestDatanodeReport.java:144)
> {noformat}
> The test shuts down datanode, and then shutdown cluster, which shuts down the
> a datanode twice. Resetting the FsDatasetSpi reference in DataNode to null
> resolves the issue.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-11041) Unable to unregister FsDatasetState MBean if DataNode is shutdown twice
[
https://issues.apache.org/jira/browse/HDFS-11041?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17496465#comment-17496465
]
Wei-Chiu Chuang commented on HDFS-11041:
Sure thing. Done.
> Unable to unregister FsDatasetState MBean if DataNode is shutdown twice
> ---
>
> Key: HDFS-11041
> URL: https://issues.apache.org/jira/browse/HDFS-11041
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: datanode
>Reporter: Wei-Chiu Chuang
>Assignee: Wei-Chiu Chuang
>Priority: Trivial
> Fix For: 3.4.0, 2.10.2, 3.2.3, 3.3.3
>
> Attachments: HDFS-11041.01.patch, HDFS-11041.02.patch,
> HDFS-11041.03.patch
>
>
> I saw error message like the following in some tests
> {noformat}
> 2016-10-21 04:09:03,900 [main] WARN util.MBeans
> (MBeans.java:unregister(114)) - Error unregistering
> Hadoop:service=DataNode,name=FSDatasetState-33cd714c-0b1a-471f-8efe-f431d7d874bc
> javax.management.InstanceNotFoundException:
> Hadoop:service=DataNode,name=FSDatasetState-33cd714c-0b1a-471f-8efe-f431d7d874bc
> at
> com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.getMBean(DefaultMBeanServerInterceptor.java:1095)
> at
> com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.exclusiveUnregisterMBean(DefaultMBeanServerInterceptor.java:427)
> at
> com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.unregisterMBean(DefaultMBeanServerInterceptor.java:415)
> at
> com.sun.jmx.mbeanserver.JmxMBeanServer.unregisterMBean(JmxMBeanServer.java:546)
> at org.apache.hadoop.metrics2.util.MBeans.unregister(MBeans.java:112)
> at
> org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl.shutdown(FsDatasetImpl.java:2127)
> at
> org.apache.hadoop.hdfs.server.datanode.DataNode.shutdown(DataNode.java:2016)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdownDataNodes(MiniDFSCluster.java:1985)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdown(MiniDFSCluster.java:1962)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdown(MiniDFSCluster.java:1936)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdown(MiniDFSCluster.java:1929)
> at
> org.apache.hadoop.hdfs.TestDatanodeReport.testDatanodeReport(TestDatanodeReport.java:144)
> {noformat}
> The test shuts down datanode, and then shutdown cluster, which shuts down the
> a datanode twice. Resetting the FsDatasetSpi reference in DataNode to null
> resolves the issue.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16478) Multiple command processor threads have same name
[
https://issues.apache.org/jira/browse/HDFS-16478?focusedWorklogId=731332&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731332
]
ASF GitHub Bot logged work on HDFS-16478:
-
Author: ASF GitHub Bot
Created on: 23/Feb/22 03:28
Start Date: 23/Feb/22 03:28
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on pull request #4016:
URL: https://github.com/apache/hadoop/pull/4016#issuecomment-1048418622
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 1m 4s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 1s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| -1 :x: | test4tests | 0m 0s | | The patch doesn't appear to include
any new or modified tests. Please justify why no new tests are needed for this
patch. Also please list what manual steps were performed to verify this patch.
|
_ trunk Compile Tests _ |
| +1 :green_heart: | mvninstall | 37m 17s | | trunk passed |
| +1 :green_heart: | compile | 1m 38s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | compile | 1m 27s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 1m 7s | | trunk passed |
| +1 :green_heart: | mvnsite | 1m 45s | | trunk passed |
| +1 :green_heart: | javadoc | 1m 12s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 1m 43s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 3m 52s | | trunk passed |
| +1 :green_heart: | shadedclient | 30m 48s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 1m 42s | | the patch passed |
| +1 :green_heart: | compile | 1m 47s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javac | 1m 47s | | the patch passed |
| +1 :green_heart: | compile | 1m 35s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 1m 35s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 1m 4s | | the patch passed |
| +1 :green_heart: | mvnsite | 1m 40s | | the patch passed |
| +1 :green_heart: | javadoc | 1m 6s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 1m 33s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 4m 18s | | the patch passed |
| +1 :green_heart: | shadedclient | 32m 17s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 363m 51s | | hadoop-hdfs in the patch
passed. |
| +1 :green_heart: | asflicense | 0m 38s | | The patch does not
generate ASF License warnings. |
| | | 489m 56s | | |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4016/1/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/4016 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell |
| uname | Linux c5f1d2455806 4.15.0-166-generic #174-Ubuntu SMP Wed Dec 8
19:07:44 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / a97f1aeb1ac4930ea43c46be3962e21c20b4227c |
| Default Java | Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Multi-JDK versions |
/usr/lib/jvm/java-11-openjdk-amd64:Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04
/usr/lib/jvm/java-8-openjdk-amd64:Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Test Results |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4016/1/testReport/ |
| Max. process+thread count | 2016 (vs. ulimit of 5500) |
| modules | C: hadoop-hdfs-project/hadoop-hdfs U:
hadoop-hdfs-project/hadoop-hdfs |
| Console output |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4016/1/console |
| versions | git=
[jira] [Work logged] (HDFS-16476) Increase the number of metrics used to record PendingRecoveryBlocks
[
https://issues.apache.org/jira/browse/HDFS-16476?focusedWorklogId=731319&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731319
]
ASF GitHub Bot logged work on HDFS-16476:
-
Author: ASF GitHub Bot
Created on: 23/Feb/22 02:39
Start Date: 23/Feb/22 02:39
Worklog Time Spent: 10m
Work Description: jianghuazhu commented on pull request #4010:
URL: https://github.com/apache/hadoop/pull/4010#issuecomment-1048400030
There are some ci/cd related failures here that don't seem to be related.
Here is an example with some online clusters, obtained by getting the
NameNode's jmx:
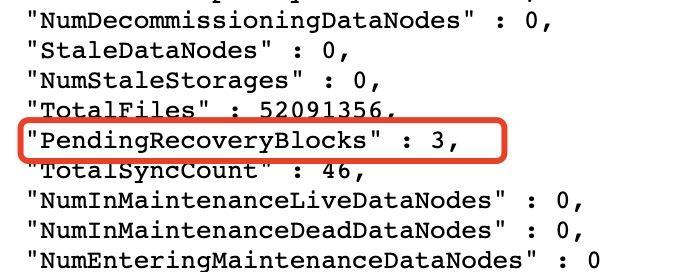
Regarding the display of logarithms, I think the block recovery work is
something between NameNode and DataNode, so in the RBF module, I implemented a
default value. E.g:
public int getPendingRecoveryBlocks() {
return 0;
}
If compatibility with RBF is required in the future, it can be achieved with
minimal code changes.
Would you guys help to review this PR, @ayushtkn @virajjasani .
Thank you very much.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 731319)
Time Spent: 0.5h (was: 20m)
> Increase the number of metrics used to record PendingRecoveryBlocks
> ---
>
> Key: HDFS-16476
> URL: https://issues.apache.org/jira/browse/HDFS-16476
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: metrics, namenode
>Affects Versions: 2.9.2, 3.4.0
>Reporter: JiangHua Zhu
>Assignee: JiangHua Zhu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> The complete process of block recovery is as follows:
> 1. NameNode collects which blocks need to be recovered.
> 2. The NameNode issues instructions to some DataNodes for execution.
> 3. DataNode tells NameNode after execution is complete.
> Now there is no way to know how many blocks are being recovered. The number
> of metrics used to record PendingRecoveryBlocks should be increased, which is
> good for increasing the robustness of the cluster.
> Here are some logs of DataNode execution:
> 2022-02-10 23:51:04,386 [12208592621] - INFO [IPC Server handler 38 on
> 8025:FsDatasetImpl@2687] - initReplicaRecovery: changing replica state for
> blk_ from RBW to RUR
> 2022-02-10 23:51:04,395 [12208592630] - INFO [IPC Server handler 47 on
> 8025:FsDatasetImpl@2708] - updateReplica: BP-:blk_,
> recoveryId=18386356475, length=129869866, replica=ReplicaUnderRecovery,
> blk_, RUR
> Here are some logs that NameNdoe receives after completion:
> 2022-02-22 10:43:58,780 [8193058814] - INFO [IPC Server handler 15 on
> 8021:FSNamesystem@3647] - commitBlockSynchronization(oldBlock=BP-,
> newgenerationstamp=18551926574, newlength=16929, newtargets=[1:1004,
> 2:1004, 3:1004]) successful
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16431) Truncate CallerContext in client side
[ https://issues.apache.org/jira/browse/HDFS-16431?focusedWorklogId=731315&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731315 ] ASF GitHub Bot logged work on HDFS-16431: - Author: ASF GitHub Bot Created on: 23/Feb/22 02:17 Start Date: 23/Feb/22 02:17 Worklog Time Spent: 10m Work Description: smarthanwang commented on pull request #3909: URL: https://github.com/apache/hadoop/pull/3909#issuecomment-1048392253 Hi @jojochuang @sodonnel @Hexiaoqiao @ferhui , could you please help take a look? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 731315) Time Spent: 2h (was: 1h 50m) > Truncate CallerContext in client side > - > > Key: HDFS-16431 > URL: https://issues.apache.org/jira/browse/HDFS-16431 > Project: Hadoop HDFS > Issue Type: Improvement > Components: nn >Reporter: Chengwei Wang >Assignee: Chengwei Wang >Priority: Major > Labels: pull-request-available > Time Spent: 2h > Remaining Estimate: 0h > > The context of CallerContext would be truncated when it exceeds the maximum > allowed length in server side. I think it's better to do check and truncate > in client side to reduce the unnecessary overhead of network and memory for > NN. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16456) EC: Decommission a rack with only on dn will fail when the rack number is equal with replication
[
https://issues.apache.org/jira/browse/HDFS-16456?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17496392#comment-17496392
]
Hadoop QA commented on HDFS-16456:
--
| (x) *{color:red}-1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Logfile || Comment ||
| {color:blue}0{color} | {color:blue} reexec {color} | {color:blue} 0m
48s{color} | {color:blue}{color} | {color:blue} Docker mode activated. {color} |
|| || || || {color:brown} Prechecks {color} || ||
| {color:green}+1{color} | {color:green} dupname {color} | {color:green} 0m
0s{color} | {color:green}{color} | {color:green} No case conflicting files
found. {color} |
| {color:green}+1{color} | {color:green} {color} | {color:green} 0m 0s{color}
| {color:green}test4tests{color} | {color:green} The patch appears to include 2
new or modified test files. {color} |
|| || || || {color:brown} trunk Compile Tests {color} || ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 1m
44s{color} | {color:blue}{color} | {color:blue} Maven dependency ordering for
branch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 21m
7s{color} | {color:green}{color} | {color:green} trunk passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 22m
22s{color} | {color:green}{color} | {color:green} trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 19m
29s{color} | {color:green}{color} | {color:green} trunk passed with JDK Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 3m
31s{color} | {color:green}{color} | {color:green} trunk passed {color} |
| {color:green}+1{color} | {color:green} mvnsite {color} | {color:green} 3m
23s{color} | {color:green}{color} | {color:green} trunk passed {color} |
| {color:green}+1{color} | {color:green} shadedclient {color} | {color:green}
26m 44s{color} | {color:green}{color} | {color:green} branch has no errors when
building and testing our client artifacts. {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 2m
25s{color} | {color:green}{color} | {color:green} trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 3m
28s{color} | {color:green}{color} | {color:green} trunk passed with JDK Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 {color} |
| {color:blue}0{color} | {color:blue} spotbugs {color} | {color:blue} 38m
26s{color} | {color:blue}{color} | {color:blue} Both FindBugs and SpotBugs are
enabled, using SpotBugs. {color} |
| {color:green}+1{color} | {color:green} spotbugs {color} | {color:green} 5m
48s{color} | {color:green}{color} | {color:green} trunk passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} || ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 0m
28s{color} | {color:blue}{color} | {color:blue} Maven dependency ordering for
patch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 2m
15s{color} | {color:green}{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 21m
37s{color} | {color:green}{color} | {color:green} the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 21m
37s{color} | {color:green}{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 19m
34s{color} | {color:green}{color} | {color:green} the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 19m
34s{color} | {color:green}{color} | {color:green} the patch passed {color} |
| {color:orange}-0{color} | {color:orange} checkstyle {color} | {color:orange}
3m 29s{color} |
{color:orange}https://ci-hadoop.apache.org/job/PreCommit-HDFS-Build/762/artifact/out/diff-checkstyle-root.txt{color}
| {color:orange} root: The patch generated 15 new + 155 unchanged - 0 fixed =
170 total (was 155) {color} |
| {color:green}+1{color} | {color:green} mvnsite {color} | {color:green} 3m
21s{color} | {color:green}{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green}{color} | {color:green} The patch has no whitespace
issues. {color} |
| {color:green}+1{color} | {color:green} shadedclient {color} | {color:green}
19m 38s{color} | {color:green}{color} | {color:green} patch has no errors when
building and testing our client artifacts. {color} |
| {color:green}+1{
[jira] [Work logged] (HDFS-16476) Increase the number of metrics used to record PendingRecoveryBlocks
[
https://issues.apache.org/jira/browse/HDFS-16476?focusedWorklogId=731232&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731232
]
ASF GitHub Bot logged work on HDFS-16476:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 22:29
Start Date: 22/Feb/22 22:29
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on pull request #4010:
URL: https://github.com/apache/hadoop/pull/4010#issuecomment-1048273369
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 52s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 0s | | codespell was not available. |
| +0 :ok: | markdownlint | 0m 0s | | markdownlint was not available.
|
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 1 new or modified test files. |
_ trunk Compile Tests _ |
| +0 :ok: | mvndep | 12m 53s | | Maven dependency ordering for branch |
| +1 :green_heart: | mvninstall | 22m 27s | | trunk passed |
| -1 :x: | compile | 15m 45s |
[/branch-compile-root-jdkUbuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4010/1/artifact/out/branch-compile-root-jdkUbuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04.txt)
| root in trunk failed with JDK Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04. |
| -1 :x: | compile | 14m 40s |
[/branch-compile-root-jdkPrivateBuild-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4010/1/artifact/out/branch-compile-root-jdkPrivateBuild-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07.txt)
| root in trunk failed with JDK Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07. |
| +1 :green_heart: | checkstyle | 3m 47s | | trunk passed |
| +1 :green_heart: | mvnsite | 4m 12s | | trunk passed |
| +1 :green_heart: | javadoc | 3m 13s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 4m 32s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 7m 25s | | trunk passed |
| +1 :green_heart: | shadedclient | 21m 23s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +0 :ok: | mvndep | 0m 30s | | Maven dependency ordering for patch |
| +1 :green_heart: | mvninstall | 2m 53s | | the patch passed |
| +1 :green_heart: | compile | 23m 36s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| -1 :x: | javac | 23m 36s |
[/results-compile-javac-root-jdkUbuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4010/1/artifact/out/results-compile-javac-root-jdkUbuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04.txt)
| root-jdkUbuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 generated 188 new + 1628 unchanged - 0
fixed = 1816 total (was 1628) |
| +1 :green_heart: | compile | 20m 46s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| -1 :x: | javac | 20m 46s |
[/results-compile-javac-root-jdkPrivateBuild-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4010/1/artifact/out/results-compile-javac-root-jdkPrivateBuild-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07.txt)
| root-jdkPrivateBuild-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 generated 172 new + 1518
unchanged - 0 fixed = 1690 total (was 1518) |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 3m 37s | | the patch passed |
| +1 :green_heart: | mvnsite | 4m 21s | | the patch passed |
| +1 :green_heart: | javadoc | 3m 22s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 4m 51s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 8m 12s | | the patch passed |
| +1 :green_heart: | shadedclient | 23m 9s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 30m 38s | | hadoop-common in the patch
passed. |
| +1 :green_heart: | unit | 242m 57s | | hadoop-hdfs in the patch
passed. |
| +1
[jira] [Work logged] (HDFS-16478) Multiple command processor threads have same name
[
https://issues.apache.org/jira/browse/HDFS-16478?focusedWorklogId=731202&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731202
]
ASF GitHub Bot logged work on HDFS-16478:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 21:57
Start Date: 22/Feb/22 21:57
Worklog Time Spent: 10m
Work Description: madrob commented on a change in pull request #4016:
URL: https://github.com/apache/hadoop/pull/4016#discussion_r812391433
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/BPServiceActor.java
##
@@ -1378,7 +1378,7 @@ public long monotonicNow() {
private final BlockingQueue queue;
CommandProcessingThread(BPServiceActor actor) {
- super("Command processor");
+ setName("Command processor-" + getId());
Review comment:
Because the thread id is set during construction and not available to us
yet.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 731202)
Time Spent: 0.5h (was: 20m)
> Multiple command processor threads have same name
> -
>
> Key: HDFS-16478
> URL: https://issues.apache.org/jira/browse/HDFS-16478
> Project: Hadoop HDFS
> Issue Type: Task
> Components: datanode
>Reporter: Mike Drob
>Priority: Minor
> Labels: pull-request-available
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> When running an in-process MiniDFSCluster with multiple data nodes, the
> command processor threads all share the same name, making them more difficult
> to get debug and logging information from.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16478) multiple command processor threads have same name
[
https://issues.apache.org/jira/browse/HDFS-16478?focusedWorklogId=731200&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731200
]
ASF GitHub Bot logged work on HDFS-16478:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 21:52
Start Date: 22/Feb/22 21:52
Worklog Time Spent: 10m
Work Description: goiri commented on a change in pull request #4016:
URL: https://github.com/apache/hadoop/pull/4016#discussion_r812388320
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/BPServiceActor.java
##
@@ -1378,7 +1378,7 @@ public long monotonicNow() {
private final BlockingQueue queue;
CommandProcessingThread(BPServiceActor actor) {
- super("Command processor");
+ setName("Command processor-" + getId());
Review comment:
Why not using super()?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 731200)
Time Spent: 20m (was: 10m)
> multiple command processor threads have same name
> -
>
> Key: HDFS-16478
> URL: https://issues.apache.org/jira/browse/HDFS-16478
> Project: Hadoop HDFS
> Issue Type: Task
> Components: datanode
>Reporter: Mike Drob
>Priority: Minor
> Time Spent: 20m
> Remaining Estimate: 0h
>
> When running an in-process MiniDFSCluster with multiple data nodes, the
> command processor threads all share the same name, making them more difficult
> to get debug and logging information from.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16478) Multiple command processor threads have same name
[ https://issues.apache.org/jira/browse/HDFS-16478?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Íñigo Goiri updated HDFS-16478: --- Summary: Multiple command processor threads have same name (was: multiple command processor threads have same name) > Multiple command processor threads have same name > - > > Key: HDFS-16478 > URL: https://issues.apache.org/jira/browse/HDFS-16478 > Project: Hadoop HDFS > Issue Type: Task > Components: datanode >Reporter: Mike Drob >Priority: Minor > Labels: pull-request-available > Time Spent: 20m > Remaining Estimate: 0h > > When running an in-process MiniDFSCluster with multiple data nodes, the > command processor threads all share the same name, making them more difficult > to get debug and logging information from. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16478) multiple command processor threads have same name
[ https://issues.apache.org/jira/browse/HDFS-16478?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDFS-16478: -- Labels: pull-request-available (was: ) > multiple command processor threads have same name > - > > Key: HDFS-16478 > URL: https://issues.apache.org/jira/browse/HDFS-16478 > Project: Hadoop HDFS > Issue Type: Task > Components: datanode >Reporter: Mike Drob >Priority: Minor > Labels: pull-request-available > Time Spent: 20m > Remaining Estimate: 0h > > When running an in-process MiniDFSCluster with multiple data nodes, the > command processor threads all share the same name, making them more difficult > to get debug and logging information from. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16478) multiple command processor threads have same name
[ https://issues.apache.org/jira/browse/HDFS-16478?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Mike Drob updated HDFS-16478: - Labels: (was: pull-request-available) Status: Patch Available (was: Open) PR posted > multiple command processor threads have same name > - > > Key: HDFS-16478 > URL: https://issues.apache.org/jira/browse/HDFS-16478 > Project: Hadoop HDFS > Issue Type: Task > Components: datanode >Reporter: Mike Drob >Priority: Minor > Time Spent: 10m > Remaining Estimate: 0h > > When running an in-process MiniDFSCluster with multiple data nodes, the > command processor threads all share the same name, making them more difficult > to get debug and logging information from. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16478) multiple command processor threads have same name
[ https://issues.apache.org/jira/browse/HDFS-16478?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDFS-16478: -- Labels: pull-request-available (was: ) > multiple command processor threads have same name > - > > Key: HDFS-16478 > URL: https://issues.apache.org/jira/browse/HDFS-16478 > Project: Hadoop HDFS > Issue Type: Task > Components: datanode >Reporter: Mike Drob >Priority: Minor > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > When running an in-process MiniDFSCluster with multiple data nodes, the > command processor threads all share the same name, making them more difficult > to get debug and logging information from. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16478) multiple command processor threads have same name
[ https://issues.apache.org/jira/browse/HDFS-16478?focusedWorklogId=731125&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731125 ] ASF GitHub Bot logged work on HDFS-16478: - Author: ASF GitHub Bot Created on: 22/Feb/22 19:17 Start Date: 22/Feb/22 19:17 Worklog Time Spent: 10m Work Description: madrob opened a new pull request #4016: URL: https://github.com/apache/hadoop/pull/4016 ### Description of PR Provides additional clarity in logs when debugging MiniDFSCluster with multiple in-process DataNodes. ### How was this patch tested? Visual inspection of log output. ### For code changes: - [X] Does the title or this PR starts with the corresponding JIRA issue id (e.g. 'HADOOP-17799. Your PR title ...')? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 731125) Remaining Estimate: 0h Time Spent: 10m > multiple command processor threads have same name > - > > Key: HDFS-16478 > URL: https://issues.apache.org/jira/browse/HDFS-16478 > Project: Hadoop HDFS > Issue Type: Task > Components: datanode >Reporter: Mike Drob >Priority: Minor > Time Spent: 10m > Remaining Estimate: 0h > > When running an in-process MiniDFSCluster with multiple data nodes, the > command processor threads all share the same name, making them more difficult > to get debug and logging information from. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Created] (HDFS-16478) multiple command processor threads have same name
Mike Drob created HDFS-16478: Summary: multiple command processor threads have same name Key: HDFS-16478 URL: https://issues.apache.org/jira/browse/HDFS-16478 Project: Hadoop HDFS Issue Type: Task Components: datanode Reporter: Mike Drob When running an in-process MiniDFSCluster with multiple data nodes, the command processor threads all share the same name, making them more difficult to get debug and logging information from. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16456) EC: Decommission a rack with only on dn will fail when the rack number is equal with replication
[
https://issues.apache.org/jira/browse/HDFS-16456?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17496253#comment-17496253
]
Takanobu Asanuma commented on HDFS-16456:
-
[~caozhiqiang] Thanks for updating the patch quickly.
However, if I understand correctly,
TestBlockPlacementPolicyRackFaultTolerant::testPlacementWithOnlyOneNodeInRackDecommission
in [^HDFS-16456.004.patch] doesn't cover the case what you mentioned in the
description.
{quote}When decommission, after choose targets, verifyBlockPlacement() function
will return the total rack number contains the invalid rack, and
BlockPlacementStatusDefault::isPlacementPolicySatisfied() will return false and
it will also cause decommission fail.
{quote}
Is it possible to reproduce this case in unit tests?
> EC: Decommission a rack with only on dn will fail when the rack number is
> equal with replication
>
>
> Key: HDFS-16456
> URL: https://issues.apache.org/jira/browse/HDFS-16456
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: ec, namenode
>Affects Versions: 3.4.0
>Reporter: caozhiqiang
>Priority: Critical
> Attachments: HDFS-16456.001.patch, HDFS-16456.002.patch,
> HDFS-16456.003.patch, HDFS-16456.004.patch
>
>
> In below scenario, decommission will fail by TOO_MANY_NODES_ON_RACK reason:
> # Enable EC policy, such as RS-6-3-1024k.
> # The rack number in this cluster is equal with or less than the replication
> number(9)
> # A rack only has one DN, and decommission this DN.
> The root cause is in
> BlockPlacementPolicyRackFaultTolerant::getMaxNodesPerRack() function, it will
> give a limit parameter maxNodesPerRack for choose targets. In this scenario,
> the maxNodesPerRack is 1, which means each rack can only be chosen one
> datanode.
> {code:java}
> protected int[] getMaxNodesPerRack(int numOfChosen, int numOfReplicas) {
>...
> // If more replicas than racks, evenly spread the replicas.
> // This calculation rounds up.
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> return new int[] {numOfReplicas, maxNodesPerRack};
> } {code}
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> here will be called, where totalNumOfReplicas=9 and numOfRacks=9
> When we decommission one dn which is only one node in its rack, the
> chooseOnce() in BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder()
> will throw NotEnoughReplicasException, but the exception will not be caught
> and fail to fallback to chooseEvenlyFromRemainingRacks() function.
> When decommission, after choose targets, verifyBlockPlacement() function will
> return the total rack number contains the invalid rack, and
> BlockPlacementStatusDefault::isPlacementPolicySatisfied() will return false
> and it will also cause decommission fail.
> {code:java}
> public BlockPlacementStatus verifyBlockPlacement(DatanodeInfo[] locs,
> int numberOfReplicas) {
> if (locs == null)
> locs = DatanodeDescriptor.EMPTY_ARRAY;
> if (!clusterMap.hasClusterEverBeenMultiRack()) {
> // only one rack
> return new BlockPlacementStatusDefault(1, 1, 1);
> }
> // Count locations on different racks.
> Set racks = new HashSet<>();
> for (DatanodeInfo dn : locs) {
> racks.add(dn.getNetworkLocation());
> }
> return new BlockPlacementStatusDefault(racks.size(), numberOfReplicas,
> clusterMap.getNumOfRacks());
> } {code}
> {code:java}
> public boolean isPlacementPolicySatisfied() {
> return requiredRacks <= currentRacks || currentRacks >= totalRacks;
> }{code}
> According to the above description, we should make the below modify to fix it:
> # In startDecommission() or stopDecommission(), we should also change the
> numOfRacks in class NetworkTopology. Or choose targets may fail for the
> maxNodesPerRack is too small. And even choose targets success,
> isPlacementPolicySatisfied will also return false cause decommission fail.
> # In BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder(), the first
> chooseOnce() function should also be put in try..catch..., or it will not
> fallback to call chooseEvenlyFromRemainingRacks() when throw exception.
> # In verifyBlockPlacement, we need to remove invalid racks from total
> numOfRacks, or isPlacementPolicySatisfied() will return false and cause fail
> to reconstruct data.
>
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16456) EC: Decommission a rack with only on dn will fail when the rack number is equal with replication
[
https://issues.apache.org/jira/browse/HDFS-16456?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17496192#comment-17496192
]
caozhiqiang commented on HDFS-16456:
Hi, [~tasanuma]
* In my opinion, we have to get the number of empty rack to avoid this
situation, and it need to do in network topology.
* I update the UT
TestBlockPlacementPolicyRackFaultTolerant::testPlacementWithOnlyOneNodeInRackDecommission
to see if decommission succeed.
> EC: Decommission a rack with only on dn will fail when the rack number is
> equal with replication
>
>
> Key: HDFS-16456
> URL: https://issues.apache.org/jira/browse/HDFS-16456
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: ec, namenode
>Affects Versions: 3.4.0
>Reporter: caozhiqiang
>Priority: Critical
> Attachments: HDFS-16456.001.patch, HDFS-16456.002.patch,
> HDFS-16456.003.patch, HDFS-16456.004.patch
>
>
> In below scenario, decommission will fail by TOO_MANY_NODES_ON_RACK reason:
> # Enable EC policy, such as RS-6-3-1024k.
> # The rack number in this cluster is equal with or less than the replication
> number(9)
> # A rack only has one DN, and decommission this DN.
> The root cause is in
> BlockPlacementPolicyRackFaultTolerant::getMaxNodesPerRack() function, it will
> give a limit parameter maxNodesPerRack for choose targets. In this scenario,
> the maxNodesPerRack is 1, which means each rack can only be chosen one
> datanode.
> {code:java}
> protected int[] getMaxNodesPerRack(int numOfChosen, int numOfReplicas) {
>...
> // If more replicas than racks, evenly spread the replicas.
> // This calculation rounds up.
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> return new int[] {numOfReplicas, maxNodesPerRack};
> } {code}
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> here will be called, where totalNumOfReplicas=9 and numOfRacks=9
> When we decommission one dn which is only one node in its rack, the
> chooseOnce() in BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder()
> will throw NotEnoughReplicasException, but the exception will not be caught
> and fail to fallback to chooseEvenlyFromRemainingRacks() function.
> When decommission, after choose targets, verifyBlockPlacement() function will
> return the total rack number contains the invalid rack, and
> BlockPlacementStatusDefault::isPlacementPolicySatisfied() will return false
> and it will also cause decommission fail.
> {code:java}
> public BlockPlacementStatus verifyBlockPlacement(DatanodeInfo[] locs,
> int numberOfReplicas) {
> if (locs == null)
> locs = DatanodeDescriptor.EMPTY_ARRAY;
> if (!clusterMap.hasClusterEverBeenMultiRack()) {
> // only one rack
> return new BlockPlacementStatusDefault(1, 1, 1);
> }
> // Count locations on different racks.
> Set racks = new HashSet<>();
> for (DatanodeInfo dn : locs) {
> racks.add(dn.getNetworkLocation());
> }
> return new BlockPlacementStatusDefault(racks.size(), numberOfReplicas,
> clusterMap.getNumOfRacks());
> } {code}
> {code:java}
> public boolean isPlacementPolicySatisfied() {
> return requiredRacks <= currentRacks || currentRacks >= totalRacks;
> }{code}
> According to the above description, we should make the below modify to fix it:
> # In startDecommission() or stopDecommission(), we should also change the
> numOfRacks in class NetworkTopology. Or choose targets may fail for the
> maxNodesPerRack is too small. And even choose targets success,
> isPlacementPolicySatisfied will also return false cause decommission fail.
> # In BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder(), the first
> chooseOnce() function should also be put in try..catch..., or it will not
> fallback to call chooseEvenlyFromRemainingRacks() when throw exception.
> # In verifyBlockPlacement, we need to remove invalid racks from total
> numOfRacks, or isPlacementPolicySatisfied() will return false and cause fail
> to reconstruct data.
>
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16456) EC: Decommission a rack with only on dn will fail when the rack number is equal with replication
[
https://issues.apache.org/jira/browse/HDFS-16456?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
caozhiqiang updated HDFS-16456:
---
Status: Patch Available (was: Open)
> EC: Decommission a rack with only on dn will fail when the rack number is
> equal with replication
>
>
> Key: HDFS-16456
> URL: https://issues.apache.org/jira/browse/HDFS-16456
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: ec, namenode
>Affects Versions: 3.4.0
>Reporter: caozhiqiang
>Priority: Critical
> Attachments: HDFS-16456.001.patch, HDFS-16456.002.patch,
> HDFS-16456.003.patch, HDFS-16456.004.patch
>
>
> In below scenario, decommission will fail by TOO_MANY_NODES_ON_RACK reason:
> # Enable EC policy, such as RS-6-3-1024k.
> # The rack number in this cluster is equal with or less than the replication
> number(9)
> # A rack only has one DN, and decommission this DN.
> The root cause is in
> BlockPlacementPolicyRackFaultTolerant::getMaxNodesPerRack() function, it will
> give a limit parameter maxNodesPerRack for choose targets. In this scenario,
> the maxNodesPerRack is 1, which means each rack can only be chosen one
> datanode.
> {code:java}
> protected int[] getMaxNodesPerRack(int numOfChosen, int numOfReplicas) {
>...
> // If more replicas than racks, evenly spread the replicas.
> // This calculation rounds up.
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> return new int[] {numOfReplicas, maxNodesPerRack};
> } {code}
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> here will be called, where totalNumOfReplicas=9 and numOfRacks=9
> When we decommission one dn which is only one node in its rack, the
> chooseOnce() in BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder()
> will throw NotEnoughReplicasException, but the exception will not be caught
> and fail to fallback to chooseEvenlyFromRemainingRacks() function.
> When decommission, after choose targets, verifyBlockPlacement() function will
> return the total rack number contains the invalid rack, and
> BlockPlacementStatusDefault::isPlacementPolicySatisfied() will return false
> and it will also cause decommission fail.
> {code:java}
> public BlockPlacementStatus verifyBlockPlacement(DatanodeInfo[] locs,
> int numberOfReplicas) {
> if (locs == null)
> locs = DatanodeDescriptor.EMPTY_ARRAY;
> if (!clusterMap.hasClusterEverBeenMultiRack()) {
> // only one rack
> return new BlockPlacementStatusDefault(1, 1, 1);
> }
> // Count locations on different racks.
> Set racks = new HashSet<>();
> for (DatanodeInfo dn : locs) {
> racks.add(dn.getNetworkLocation());
> }
> return new BlockPlacementStatusDefault(racks.size(), numberOfReplicas,
> clusterMap.getNumOfRacks());
> } {code}
> {code:java}
> public boolean isPlacementPolicySatisfied() {
> return requiredRacks <= currentRacks || currentRacks >= totalRacks;
> }{code}
> According to the above description, we should make the below modify to fix it:
> # In startDecommission() or stopDecommission(), we should also change the
> numOfRacks in class NetworkTopology. Or choose targets may fail for the
> maxNodesPerRack is too small. And even choose targets success,
> isPlacementPolicySatisfied will also return false cause decommission fail.
> # In BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder(), the first
> chooseOnce() function should also be put in try..catch..., or it will not
> fallback to call chooseEvenlyFromRemainingRacks() when throw exception.
> # In verifyBlockPlacement, we need to remove invalid racks from total
> numOfRacks, or isPlacementPolicySatisfied() will return false and cause fail
> to reconstruct data.
>
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16456) EC: Decommission a rack with only on dn will fail when the rack number is equal with replication
[
https://issues.apache.org/jira/browse/HDFS-16456?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
caozhiqiang updated HDFS-16456:
---
Status: Open (was: Patch Available)
> EC: Decommission a rack with only on dn will fail when the rack number is
> equal with replication
>
>
> Key: HDFS-16456
> URL: https://issues.apache.org/jira/browse/HDFS-16456
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: ec, namenode
>Affects Versions: 3.4.0
>Reporter: caozhiqiang
>Priority: Critical
> Attachments: HDFS-16456.001.patch, HDFS-16456.002.patch,
> HDFS-16456.003.patch, HDFS-16456.004.patch
>
>
> In below scenario, decommission will fail by TOO_MANY_NODES_ON_RACK reason:
> # Enable EC policy, such as RS-6-3-1024k.
> # The rack number in this cluster is equal with or less than the replication
> number(9)
> # A rack only has one DN, and decommission this DN.
> The root cause is in
> BlockPlacementPolicyRackFaultTolerant::getMaxNodesPerRack() function, it will
> give a limit parameter maxNodesPerRack for choose targets. In this scenario,
> the maxNodesPerRack is 1, which means each rack can only be chosen one
> datanode.
> {code:java}
> protected int[] getMaxNodesPerRack(int numOfChosen, int numOfReplicas) {
>...
> // If more replicas than racks, evenly spread the replicas.
> // This calculation rounds up.
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> return new int[] {numOfReplicas, maxNodesPerRack};
> } {code}
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> here will be called, where totalNumOfReplicas=9 and numOfRacks=9
> When we decommission one dn which is only one node in its rack, the
> chooseOnce() in BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder()
> will throw NotEnoughReplicasException, but the exception will not be caught
> and fail to fallback to chooseEvenlyFromRemainingRacks() function.
> When decommission, after choose targets, verifyBlockPlacement() function will
> return the total rack number contains the invalid rack, and
> BlockPlacementStatusDefault::isPlacementPolicySatisfied() will return false
> and it will also cause decommission fail.
> {code:java}
> public BlockPlacementStatus verifyBlockPlacement(DatanodeInfo[] locs,
> int numberOfReplicas) {
> if (locs == null)
> locs = DatanodeDescriptor.EMPTY_ARRAY;
> if (!clusterMap.hasClusterEverBeenMultiRack()) {
> // only one rack
> return new BlockPlacementStatusDefault(1, 1, 1);
> }
> // Count locations on different racks.
> Set racks = new HashSet<>();
> for (DatanodeInfo dn : locs) {
> racks.add(dn.getNetworkLocation());
> }
> return new BlockPlacementStatusDefault(racks.size(), numberOfReplicas,
> clusterMap.getNumOfRacks());
> } {code}
> {code:java}
> public boolean isPlacementPolicySatisfied() {
> return requiredRacks <= currentRacks || currentRacks >= totalRacks;
> }{code}
> According to the above description, we should make the below modify to fix it:
> # In startDecommission() or stopDecommission(), we should also change the
> numOfRacks in class NetworkTopology. Or choose targets may fail for the
> maxNodesPerRack is too small. And even choose targets success,
> isPlacementPolicySatisfied will also return false cause decommission fail.
> # In BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder(), the first
> chooseOnce() function should also be put in try..catch..., or it will not
> fallback to call chooseEvenlyFromRemainingRacks() when throw exception.
> # In verifyBlockPlacement, we need to remove invalid racks from total
> numOfRacks, or isPlacementPolicySatisfied() will return false and cause fail
> to reconstruct data.
>
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16456) EC: Decommission a rack with only on dn will fail when the rack number is equal with replication
[
https://issues.apache.org/jira/browse/HDFS-16456?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
caozhiqiang updated HDFS-16456:
---
Attachment: HDFS-16456.004.patch
> EC: Decommission a rack with only on dn will fail when the rack number is
> equal with replication
>
>
> Key: HDFS-16456
> URL: https://issues.apache.org/jira/browse/HDFS-16456
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: ec, namenode
>Affects Versions: 3.4.0
>Reporter: caozhiqiang
>Priority: Critical
> Attachments: HDFS-16456.001.patch, HDFS-16456.002.patch,
> HDFS-16456.003.patch, HDFS-16456.004.patch
>
>
> In below scenario, decommission will fail by TOO_MANY_NODES_ON_RACK reason:
> # Enable EC policy, such as RS-6-3-1024k.
> # The rack number in this cluster is equal with or less than the replication
> number(9)
> # A rack only has one DN, and decommission this DN.
> The root cause is in
> BlockPlacementPolicyRackFaultTolerant::getMaxNodesPerRack() function, it will
> give a limit parameter maxNodesPerRack for choose targets. In this scenario,
> the maxNodesPerRack is 1, which means each rack can only be chosen one
> datanode.
> {code:java}
> protected int[] getMaxNodesPerRack(int numOfChosen, int numOfReplicas) {
>...
> // If more replicas than racks, evenly spread the replicas.
> // This calculation rounds up.
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> return new int[] {numOfReplicas, maxNodesPerRack};
> } {code}
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> here will be called, where totalNumOfReplicas=9 and numOfRacks=9
> When we decommission one dn which is only one node in its rack, the
> chooseOnce() in BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder()
> will throw NotEnoughReplicasException, but the exception will not be caught
> and fail to fallback to chooseEvenlyFromRemainingRacks() function.
> When decommission, after choose targets, verifyBlockPlacement() function will
> return the total rack number contains the invalid rack, and
> BlockPlacementStatusDefault::isPlacementPolicySatisfied() will return false
> and it will also cause decommission fail.
> {code:java}
> public BlockPlacementStatus verifyBlockPlacement(DatanodeInfo[] locs,
> int numberOfReplicas) {
> if (locs == null)
> locs = DatanodeDescriptor.EMPTY_ARRAY;
> if (!clusterMap.hasClusterEverBeenMultiRack()) {
> // only one rack
> return new BlockPlacementStatusDefault(1, 1, 1);
> }
> // Count locations on different racks.
> Set racks = new HashSet<>();
> for (DatanodeInfo dn : locs) {
> racks.add(dn.getNetworkLocation());
> }
> return new BlockPlacementStatusDefault(racks.size(), numberOfReplicas,
> clusterMap.getNumOfRacks());
> } {code}
> {code:java}
> public boolean isPlacementPolicySatisfied() {
> return requiredRacks <= currentRacks || currentRacks >= totalRacks;
> }{code}
> According to the above description, we should make the below modify to fix it:
> # In startDecommission() or stopDecommission(), we should also change the
> numOfRacks in class NetworkTopology. Or choose targets may fail for the
> maxNodesPerRack is too small. And even choose targets success,
> isPlacementPolicySatisfied will also return false cause decommission fail.
> # In BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder(), the first
> chooseOnce() function should also be put in try..catch..., or it will not
> fallback to call chooseEvenlyFromRemainingRacks() when throw exception.
> # In verifyBlockPlacement, we need to remove invalid racks from total
> numOfRacks, or isPlacementPolicySatisfied() will return false and cause fail
> to reconstruct data.
>
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16477) [SPS]: Add metric PendingSPSPaths for getting the number of paths to be processed by SPS
[
https://issues.apache.org/jira/browse/HDFS-16477?focusedWorklogId=731047&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-731047
]
ASF GitHub Bot logged work on HDFS-16477:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 16:07
Start Date: 22/Feb/22 16:07
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on pull request #4009:
URL: https://github.com/apache/hadoop/pull/4009#issuecomment-1047953347
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 41s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 0s | | codespell was not available. |
| +0 :ok: | markdownlint | 0m 0s | | markdownlint was not available.
|
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 1 new or modified test files. |
_ trunk Compile Tests _ |
| +0 :ok: | mvndep | 13m 4s | | Maven dependency ordering for branch |
| -1 :x: | mvninstall | 21m 27s |
[/branch-mvninstall-root.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4009/1/artifact/out/branch-mvninstall-root.txt)
| root in trunk failed. |
| -1 :x: | compile | 16m 14s |
[/branch-compile-root-jdkUbuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4009/1/artifact/out/branch-compile-root-jdkUbuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04.txt)
| root in trunk failed with JDK Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04. |
| -1 :x: | compile | 13m 43s |
[/branch-compile-root-jdkPrivateBuild-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4009/1/artifact/out/branch-compile-root-jdkPrivateBuild-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07.txt)
| root in trunk failed with JDK Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07. |
| +1 :green_heart: | checkstyle | 3m 37s | | trunk passed |
| +1 :green_heart: | mvnsite | 3m 20s | | trunk passed |
| +1 :green_heart: | javadoc | 2m 28s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 3m 28s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 5m 56s | | trunk passed |
| +1 :green_heart: | shadedclient | 23m 15s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +0 :ok: | mvndep | 0m 29s | | Maven dependency ordering for patch |
| +1 :green_heart: | mvninstall | 2m 15s | | the patch passed |
| +1 :green_heart: | compile | 21m 59s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| -1 :x: | javac | 21m 59s |
[/results-compile-javac-root-jdkUbuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4009/1/artifact/out/results-compile-javac-root-jdkUbuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04.txt)
| root-jdkUbuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 generated 188 new + 1624 unchanged - 0
fixed = 1812 total (was 1624) |
| +1 :green_heart: | compile | 19m 48s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| -1 :x: | javac | 19m 48s |
[/results-compile-javac-root-jdkPrivateBuild-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4009/1/artifact/out/results-compile-javac-root-jdkPrivateBuild-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07.txt)
| root-jdkPrivateBuild-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 generated 172 new + 1515
unchanged - 0 fixed = 1687 total (was 1515) |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 3m 39s | | the patch passed |
| +1 :green_heart: | mvnsite | 3m 21s | | the patch passed |
| +1 :green_heart: | javadoc | 2m 24s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 3m 31s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 6m 17s | | the patch passed |
| +1 :green_heart: | shadedclient | 25m 18s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 31m 58s |
[jira] [Comment Edited] (HDFS-11041) Unable to unregister FsDatasetState MBean if DataNode is shutdown twice
[
https://issues.apache.org/jira/browse/HDFS-11041?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17496173#comment-17496173
]
Mike Drob edited comment on HDFS-11041 at 2/22/22, 3:30 PM:
[~weichiu] - any chance of a backport to 3.3.x? We see similar failure in Solr
when shutting down our MiniDFSCluster.
was (Author: mdrob):
[~weichiu] - any chance of a backport to 3.3.x?
> Unable to unregister FsDatasetState MBean if DataNode is shutdown twice
> ---
>
> Key: HDFS-11041
> URL: https://issues.apache.org/jira/browse/HDFS-11041
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: datanode
>Reporter: Wei-Chiu Chuang
>Assignee: Wei-Chiu Chuang
>Priority: Trivial
> Fix For: 3.4.0
>
> Attachments: HDFS-11041.01.patch, HDFS-11041.02.patch,
> HDFS-11041.03.patch
>
>
> I saw error message like the following in some tests
> {noformat}
> 2016-10-21 04:09:03,900 [main] WARN util.MBeans
> (MBeans.java:unregister(114)) - Error unregistering
> Hadoop:service=DataNode,name=FSDatasetState-33cd714c-0b1a-471f-8efe-f431d7d874bc
> javax.management.InstanceNotFoundException:
> Hadoop:service=DataNode,name=FSDatasetState-33cd714c-0b1a-471f-8efe-f431d7d874bc
> at
> com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.getMBean(DefaultMBeanServerInterceptor.java:1095)
> at
> com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.exclusiveUnregisterMBean(DefaultMBeanServerInterceptor.java:427)
> at
> com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.unregisterMBean(DefaultMBeanServerInterceptor.java:415)
> at
> com.sun.jmx.mbeanserver.JmxMBeanServer.unregisterMBean(JmxMBeanServer.java:546)
> at org.apache.hadoop.metrics2.util.MBeans.unregister(MBeans.java:112)
> at
> org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl.shutdown(FsDatasetImpl.java:2127)
> at
> org.apache.hadoop.hdfs.server.datanode.DataNode.shutdown(DataNode.java:2016)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdownDataNodes(MiniDFSCluster.java:1985)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdown(MiniDFSCluster.java:1962)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdown(MiniDFSCluster.java:1936)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdown(MiniDFSCluster.java:1929)
> at
> org.apache.hadoop.hdfs.TestDatanodeReport.testDatanodeReport(TestDatanodeReport.java:144)
> {noformat}
> The test shuts down datanode, and then shutdown cluster, which shuts down the
> a datanode twice. Resetting the FsDatasetSpi reference in DataNode to null
> resolves the issue.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-11041) Unable to unregister FsDatasetState MBean if DataNode is shutdown twice
[
https://issues.apache.org/jira/browse/HDFS-11041?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17496173#comment-17496173
]
Mike Drob commented on HDFS-11041:
--
[~weichiu] - any chance of a backport to 3.3.x?
> Unable to unregister FsDatasetState MBean if DataNode is shutdown twice
> ---
>
> Key: HDFS-11041
> URL: https://issues.apache.org/jira/browse/HDFS-11041
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: datanode
>Reporter: Wei-Chiu Chuang
>Assignee: Wei-Chiu Chuang
>Priority: Trivial
> Fix For: 3.4.0
>
> Attachments: HDFS-11041.01.patch, HDFS-11041.02.patch,
> HDFS-11041.03.patch
>
>
> I saw error message like the following in some tests
> {noformat}
> 2016-10-21 04:09:03,900 [main] WARN util.MBeans
> (MBeans.java:unregister(114)) - Error unregistering
> Hadoop:service=DataNode,name=FSDatasetState-33cd714c-0b1a-471f-8efe-f431d7d874bc
> javax.management.InstanceNotFoundException:
> Hadoop:service=DataNode,name=FSDatasetState-33cd714c-0b1a-471f-8efe-f431d7d874bc
> at
> com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.getMBean(DefaultMBeanServerInterceptor.java:1095)
> at
> com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.exclusiveUnregisterMBean(DefaultMBeanServerInterceptor.java:427)
> at
> com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.unregisterMBean(DefaultMBeanServerInterceptor.java:415)
> at
> com.sun.jmx.mbeanserver.JmxMBeanServer.unregisterMBean(JmxMBeanServer.java:546)
> at org.apache.hadoop.metrics2.util.MBeans.unregister(MBeans.java:112)
> at
> org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl.shutdown(FsDatasetImpl.java:2127)
> at
> org.apache.hadoop.hdfs.server.datanode.DataNode.shutdown(DataNode.java:2016)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdownDataNodes(MiniDFSCluster.java:1985)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdown(MiniDFSCluster.java:1962)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdown(MiniDFSCluster.java:1936)
> at
> org.apache.hadoop.hdfs.MiniDFSCluster.shutdown(MiniDFSCluster.java:1929)
> at
> org.apache.hadoop.hdfs.TestDatanodeReport.testDatanodeReport(TestDatanodeReport.java:144)
> {noformat}
> The test shuts down datanode, and then shutdown cluster, which shuts down the
> a datanode twice. Resetting the FsDatasetSpi reference in DataNode to null
> resolves the issue.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16456) EC: Decommission a rack with only on dn will fail when the rack number is equal with replication
[
https://issues.apache.org/jira/browse/HDFS-16456?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17496151#comment-17496151
]
Takanobu Asanuma commented on HDFS-16456:
-
Thanks for reporting the issue and submitting the patch, [~caozhiqiang], and
thanks for the review, [~surendralilhore].
* I also feel that changing network topology just to handle only this case is
too much. If there is no other better way, though, we have to do so.
* I think we need a unit test to see if the decommissioning will fail or
succeed in this situation.
> EC: Decommission a rack with only on dn will fail when the rack number is
> equal with replication
>
>
> Key: HDFS-16456
> URL: https://issues.apache.org/jira/browse/HDFS-16456
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: ec, namenode
>Affects Versions: 3.4.0
>Reporter: caozhiqiang
>Priority: Critical
> Attachments: HDFS-16456.001.patch, HDFS-16456.002.patch,
> HDFS-16456.003.patch
>
>
> In below scenario, decommission will fail by TOO_MANY_NODES_ON_RACK reason:
> # Enable EC policy, such as RS-6-3-1024k.
> # The rack number in this cluster is equal with or less than the replication
> number(9)
> # A rack only has one DN, and decommission this DN.
> The root cause is in
> BlockPlacementPolicyRackFaultTolerant::getMaxNodesPerRack() function, it will
> give a limit parameter maxNodesPerRack for choose targets. In this scenario,
> the maxNodesPerRack is 1, which means each rack can only be chosen one
> datanode.
> {code:java}
> protected int[] getMaxNodesPerRack(int numOfChosen, int numOfReplicas) {
>...
> // If more replicas than racks, evenly spread the replicas.
> // This calculation rounds up.
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> return new int[] {numOfReplicas, maxNodesPerRack};
> } {code}
> int maxNodesPerRack = (totalNumOfReplicas - 1) / numOfRacks + 1;
> here will be called, where totalNumOfReplicas=9 and numOfRacks=9
> When we decommission one dn which is only one node in its rack, the
> chooseOnce() in BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder()
> will throw NotEnoughReplicasException, but the exception will not be caught
> and fail to fallback to chooseEvenlyFromRemainingRacks() function.
> When decommission, after choose targets, verifyBlockPlacement() function will
> return the total rack number contains the invalid rack, and
> BlockPlacementStatusDefault::isPlacementPolicySatisfied() will return false
> and it will also cause decommission fail.
> {code:java}
> public BlockPlacementStatus verifyBlockPlacement(DatanodeInfo[] locs,
> int numberOfReplicas) {
> if (locs == null)
> locs = DatanodeDescriptor.EMPTY_ARRAY;
> if (!clusterMap.hasClusterEverBeenMultiRack()) {
> // only one rack
> return new BlockPlacementStatusDefault(1, 1, 1);
> }
> // Count locations on different racks.
> Set racks = new HashSet<>();
> for (DatanodeInfo dn : locs) {
> racks.add(dn.getNetworkLocation());
> }
> return new BlockPlacementStatusDefault(racks.size(), numberOfReplicas,
> clusterMap.getNumOfRacks());
> } {code}
> {code:java}
> public boolean isPlacementPolicySatisfied() {
> return requiredRacks <= currentRacks || currentRacks >= totalRacks;
> }{code}
> According to the above description, we should make the below modify to fix it:
> # In startDecommission() or stopDecommission(), we should also change the
> numOfRacks in class NetworkTopology. Or choose targets may fail for the
> maxNodesPerRack is too small. And even choose targets success,
> isPlacementPolicySatisfied will also return false cause decommission fail.
> # In BlockPlacementPolicyRackFaultTolerant::chooseTargetInOrder(), the first
> chooseOnce() function should also be put in try..catch..., or it will not
> fallback to call chooseEvenlyFromRemainingRacks() when throw exception.
> # In verifyBlockPlacement, we need to remove invalid racks from total
> numOfRacks, or isPlacementPolicySatisfied() will return false and cause fail
> to reconstruct data.
>
>
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work started] (HDFS-16476) Increase the number of metrics used to record PendingRecoveryBlocks
[ https://issues.apache.org/jira/browse/HDFS-16476?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Work on HDFS-16476 started by JiangHua Zhu. --- > Increase the number of metrics used to record PendingRecoveryBlocks > --- > > Key: HDFS-16476 > URL: https://issues.apache.org/jira/browse/HDFS-16476 > Project: Hadoop HDFS > Issue Type: Improvement > Components: metrics, namenode >Affects Versions: 2.9.2, 3.4.0 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > The complete process of block recovery is as follows: > 1. NameNode collects which blocks need to be recovered. > 2. The NameNode issues instructions to some DataNodes for execution. > 3. DataNode tells NameNode after execution is complete. > Now there is no way to know how many blocks are being recovered. The number > of metrics used to record PendingRecoveryBlocks should be increased, which is > good for increasing the robustness of the cluster. > Here are some logs of DataNode execution: > 2022-02-10 23:51:04,386 [12208592621] - INFO [IPC Server handler 38 on > 8025:FsDatasetImpl@2687] - initReplicaRecovery: changing replica state for > blk_ from RBW to RUR > 2022-02-10 23:51:04,395 [12208592630] - INFO [IPC Server handler 47 on > 8025:FsDatasetImpl@2708] - updateReplica: BP-:blk_, > recoveryId=18386356475, length=129869866, replica=ReplicaUnderRecovery, > blk_, RUR > Here are some logs that NameNdoe receives after completion: > 2022-02-22 10:43:58,780 [8193058814] - INFO [IPC Server handler 15 on > 8021:FSNamesystem@3647] - commitBlockSynchronization(oldBlock=BP-, > newgenerationstamp=18551926574, newlength=16929, newtargets=[1:1004, > 2:1004, 3:1004]) successful -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16476) Increase the number of metrics used to record PendingRecoveryBlocks
[ https://issues.apache.org/jira/browse/HDFS-16476?focusedWorklogId=730910&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730910 ] ASF GitHub Bot logged work on HDFS-16476: - Author: ASF GitHub Bot Created on: 22/Feb/22 13:51 Start Date: 22/Feb/22 13:51 Worklog Time Spent: 10m Work Description: jianghuazhu opened a new pull request #4010: URL: https://github.com/apache/hadoop/pull/4010 ### Description of PR Now we don't know how many blocks are happening or are about to recover, the purpose of this pr is to record them through metrics. Details: HDFS-16476 ### How was this patch tested? When some blocks are recovering or are about to recover, you can view the number through metrics. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 730910) Remaining Estimate: 0h Time Spent: 10m > Increase the number of metrics used to record PendingRecoveryBlocks > --- > > Key: HDFS-16476 > URL: https://issues.apache.org/jira/browse/HDFS-16476 > Project: Hadoop HDFS > Issue Type: Improvement > Components: metrics, namenode >Affects Versions: 2.9.2, 3.4.0 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Time Spent: 10m > Remaining Estimate: 0h > > The complete process of block recovery is as follows: > 1. NameNode collects which blocks need to be recovered. > 2. The NameNode issues instructions to some DataNodes for execution. > 3. DataNode tells NameNode after execution is complete. > Now there is no way to know how many blocks are being recovered. The number > of metrics used to record PendingRecoveryBlocks should be increased, which is > good for increasing the robustness of the cluster. > Here are some logs of DataNode execution: > 2022-02-10 23:51:04,386 [12208592621] - INFO [IPC Server handler 38 on > 8025:FsDatasetImpl@2687] - initReplicaRecovery: changing replica state for > blk_ from RBW to RUR > 2022-02-10 23:51:04,395 [12208592630] - INFO [IPC Server handler 47 on > 8025:FsDatasetImpl@2708] - updateReplica: BP-:blk_, > recoveryId=18386356475, length=129869866, replica=ReplicaUnderRecovery, > blk_, RUR > Here are some logs that NameNdoe receives after completion: > 2022-02-22 10:43:58,780 [8193058814] - INFO [IPC Server handler 15 on > 8021:FSNamesystem@3647] - commitBlockSynchronization(oldBlock=BP-, > newgenerationstamp=18551926574, newlength=16929, newtargets=[1:1004, > 2:1004, 3:1004]) successful -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16476) Increase the number of metrics used to record PendingRecoveryBlocks
[ https://issues.apache.org/jira/browse/HDFS-16476?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDFS-16476: -- Labels: pull-request-available (was: ) > Increase the number of metrics used to record PendingRecoveryBlocks > --- > > Key: HDFS-16476 > URL: https://issues.apache.org/jira/browse/HDFS-16476 > Project: Hadoop HDFS > Issue Type: Improvement > Components: metrics, namenode >Affects Versions: 2.9.2, 3.4.0 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > The complete process of block recovery is as follows: > 1. NameNode collects which blocks need to be recovered. > 2. The NameNode issues instructions to some DataNodes for execution. > 3. DataNode tells NameNode after execution is complete. > Now there is no way to know how many blocks are being recovered. The number > of metrics used to record PendingRecoveryBlocks should be increased, which is > good for increasing the robustness of the cluster. > Here are some logs of DataNode execution: > 2022-02-10 23:51:04,386 [12208592621] - INFO [IPC Server handler 38 on > 8025:FsDatasetImpl@2687] - initReplicaRecovery: changing replica state for > blk_ from RBW to RUR > 2022-02-10 23:51:04,395 [12208592630] - INFO [IPC Server handler 47 on > 8025:FsDatasetImpl@2708] - updateReplica: BP-:blk_, > recoveryId=18386356475, length=129869866, replica=ReplicaUnderRecovery, > blk_, RUR > Here are some logs that NameNdoe receives after completion: > 2022-02-22 10:43:58,780 [8193058814] - INFO [IPC Server handler 15 on > 8021:FSNamesystem@3647] - commitBlockSynchronization(oldBlock=BP-, > newgenerationstamp=18551926574, newlength=16929, newtargets=[1:1004, > 2:1004, 3:1004]) successful -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16155) Allow configurable exponential backoff in DFSInputStream refetchLocations
[ https://issues.apache.org/jira/browse/HDFS-16155?focusedWorklogId=730904&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730904 ] ASF GitHub Bot logged work on HDFS-16155: - Author: ASF GitHub Bot Created on: 22/Feb/22 13:43 Start Date: 22/Feb/22 13:43 Worklog Time Spent: 10m Work Description: bbeaudreault commented on pull request #3271: URL: https://github.com/apache/hadoop/pull/3271#issuecomment-1047810182 @Hexiaoqiao can this be merged? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 730904) Time Spent: 2h 50m (was: 2h 40m) > Allow configurable exponential backoff in DFSInputStream refetchLocations > - > > Key: HDFS-16155 > URL: https://issues.apache.org/jira/browse/HDFS-16155 > Project: Hadoop HDFS > Issue Type: Improvement > Components: dfsclient >Reporter: Bryan Beaudreault >Assignee: Bryan Beaudreault >Priority: Minor > Labels: pull-request-available > Time Spent: 2h 50m > Remaining Estimate: 0h > > The retry policy in > [DFSInputStream#refetchLocations|https://github.com/apache/hadoop/blob/trunk/hadoop-hdfs-project/hadoop-hdfs-client/src/main/java/org/apache/hadoop/hdfs/DFSInputStream.java#L1018-L1040] > was first written many years ago. It allows configuration of the base time > window, but subsequent retries double in an un-configurable way. This retry > strategy makes sense in some clusters as it's very conservative and will > avoid DDOSing the namenode in certain systemic failure modes – for example, > if a file is being read by a large hadoop job and the underlying blocks are > moved by the balancer. In this case, enough datanodes would be added to the > deadNodes list and all hadoop tasks would simultaneously try to refetch the > blocks. The 3s doubling with random factor helps break up that stampeding > herd. > However, not all cluster use-cases are created equal, so there are other > cases where a more aggressive initial backoff is preferred. For example in a > low-latency single reader scenario. In this case, if the balancer moves > enough blocks, the reader hits this 3s backoff which is way too long for a > low latency use-case. > One could configure the the window very low (10ms), but then you can hit > other systemic failure modes which would result in readers DDOSing the > namenode again. For example, if blocks went missing due to truly dead > datanodes. In this case, many readers might be refetching locations for > different files with retry backoffs like 10ms, 20ms, 40ms, etc. It takes a > while to backoff enough to avoid impacting the namenode with that strategy. > I suggest adding a configurable multiplier to the backoff strategy so that > operators can tune this as they see fit for their use-case. In the above low > latency case, one could set the base very low (say 2ms) and the multiplier > very high (say 50). This gives an aggressive first retry that very quickly > backs off. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16475) Cleanup code in the write path
[
https://issues.apache.org/jira/browse/HDFS-16475?focusedWorklogId=730884&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730884
]
ASF GitHub Bot logged work on HDFS-16475:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 13:08
Start Date: 22/Feb/22 13:08
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on pull request #4008:
URL: https://github.com/apache/hadoop/pull/4008#issuecomment-1047779034
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 44s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 0s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| -1 :x: | test4tests | 0m 0s | | The patch doesn't appear to include
any new or modified tests. Please justify why no new tests are needed for this
patch. Also please list what manual steps were performed to verify this patch.
|
_ trunk Compile Tests _ |
| +0 :ok: | mvndep | 12m 40s | | Maven dependency ordering for branch |
| +1 :green_heart: | mvninstall | 22m 40s | | trunk passed |
| +1 :green_heart: | compile | 24m 10s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | compile | 20m 58s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 3m 47s | | trunk passed |
| +1 :green_heart: | mvnsite | 2m 54s | | trunk passed |
| +1 :green_heart: | javadoc | 2m 3s | | trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 2m 33s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 5m 8s | | trunk passed |
| +1 :green_heart: | shadedclient | 22m 25s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +0 :ok: | mvndep | 0m 28s | | Maven dependency ordering for patch |
| +1 :green_heart: | mvninstall | 1m 52s | | the patch passed |
| +1 :green_heart: | compile | 24m 3s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javac | 24m 3s | | the patch passed |
| +1 :green_heart: | compile | 20m 27s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 20m 27s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 3m 34s | | root: The patch generated
0 new + 35 unchanged - 5 fixed = 35 total (was 40) |
| +1 :green_heart: | mvnsite | 2m 45s | | the patch passed |
| +1 :green_heart: | javadoc | 2m 7s | | the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 |
| +1 :green_heart: | javadoc | 2m 36s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 5m 20s | | the patch passed |
| +1 :green_heart: | shadedclient | 22m 36s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 30m 35s | | hadoop-common in the patch
passed. |
| +1 :green_heart: | unit | 2m 41s | | hadoop-hdfs-client in the patch
passed. |
| +1 :green_heart: | asflicense | 0m 56s | | The patch does not
generate ASF License warnings. |
| | | 241m 10s | | |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4008/2/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/4008 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell |
| uname | Linux 908f1f8dbfe1 4.15.0-58-generic #64-Ubuntu SMP Tue Aug 6
11:12:41 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 17914a308dbca3fb7b2dc1e3a23f09d1679780c8 |
| Default Java | Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Multi-JDK versions |
/usr/lib/jvm/java-11-openjdk-amd64:Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04
/usr/lib/jvm/java-8-openjdk-amd64:Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Test Results |
https://ci-hadoop.apache.org/job/h
[jira] [Commented] (HDFS-16456) EC: Decommission a rack with only on dn will fail when the rack number is equal with replication
[
https://issues.apache.org/jira/browse/HDFS-16456?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17496058#comment-17496058
]
Hadoop QA commented on HDFS-16456:
--
| (/) *{color:green}+1 overall{color}* |
\\
\\
|| Vote || Subsystem || Runtime || Logfile || Comment ||
| {color:blue}0{color} | {color:blue} reexec {color} | {color:blue} 0m
47s{color} | {color:blue}{color} | {color:blue} Docker mode activated. {color} |
|| || || || {color:brown} Prechecks {color} || ||
| {color:green}+1{color} | {color:green} dupname {color} | {color:green} 0m
1s{color} | {color:green}{color} | {color:green} No case conflicting files
found. {color} |
| {color:green}+1{color} | {color:green} {color} | {color:green} 0m 0s{color}
| {color:green}test4tests{color} | {color:green} The patch appears to include 2
new or modified test files. {color} |
|| || || || {color:brown} trunk Compile Tests {color} || ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 12m
37s{color} | {color:blue}{color} | {color:blue} Maven dependency ordering for
branch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 21m
40s{color} | {color:green}{color} | {color:green} trunk passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 22m
15s{color} | {color:green}{color} | {color:green} trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 19m
29s{color} | {color:green}{color} | {color:green} trunk passed with JDK Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 {color} |
| {color:green}+1{color} | {color:green} checkstyle {color} | {color:green} 3m
31s{color} | {color:green}{color} | {color:green} trunk passed {color} |
| {color:green}+1{color} | {color:green} mvnsite {color} | {color:green} 3m
24s{color} | {color:green}{color} | {color:green} trunk passed {color} |
| {color:green}+1{color} | {color:green} shadedclient {color} | {color:green}
27m 6s{color} | {color:green}{color} | {color:green} branch has no errors when
building and testing our client artifacts. {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 2m
27s{color} | {color:green}{color} | {color:green} trunk passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 {color} |
| {color:green}+1{color} | {color:green} javadoc {color} | {color:green} 3m
27s{color} | {color:green}{color} | {color:green} trunk passed with JDK Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 {color} |
| {color:blue}0{color} | {color:blue} spotbugs {color} | {color:blue} 39m
0s{color} | {color:blue}{color} | {color:blue} Both FindBugs and SpotBugs are
enabled, using SpotBugs. {color} |
| {color:green}+1{color} | {color:green} spotbugs {color} | {color:green} 5m
57s{color} | {color:green}{color} | {color:green} trunk passed {color} |
|| || || || {color:brown} Patch Compile Tests {color} || ||
| {color:blue}0{color} | {color:blue} mvndep {color} | {color:blue} 0m
27s{color} | {color:blue}{color} | {color:blue} Maven dependency ordering for
patch {color} |
| {color:green}+1{color} | {color:green} mvninstall {color} | {color:green} 2m
12s{color} | {color:green}{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 25m
22s{color} | {color:green}{color} | {color:green} the patch passed with JDK
Ubuntu-11.0.13+8-Ubuntu-0ubuntu1.20.04 {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 25m
22s{color} | {color:green}{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} compile {color} | {color:green} 20m
11s{color} | {color:green}{color} | {color:green} the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 {color} |
| {color:green}+1{color} | {color:green} javac {color} | {color:green} 20m
11s{color} | {color:green}{color} | {color:green} the patch passed {color} |
| {color:orange}-0{color} | {color:orange} checkstyle {color} | {color:orange}
3m 29s{color} |
{color:orange}https://ci-hadoop.apache.org/job/PreCommit-HDFS-Build/761/artifact/out/diff-checkstyle-root.txt{color}
| {color:orange} root: The patch generated 15 new + 155 unchanged - 0 fixed =
170 total (was 155) {color} |
| {color:green}+1{color} | {color:green} mvnsite {color} | {color:green} 3m
22s{color} | {color:green}{color} | {color:green} the patch passed {color} |
| {color:green}+1{color} | {color:green} whitespace {color} | {color:green} 0m
0s{color} | {color:green}{color} | {color:green} The patch has no whitespace
issues. {color} |
| {color:green}+1{color} | {color:green} shadedclient {color} | {color:green}
19m 35s{color} | {color:green}{color} | {color:green} patch has no errors when
building and testing our client artifacts. {color} |
| {color:green}+
[jira] [Work logged] (HDFS-15382) Split FsDatasetImpl from blockpool lock to blockpool volume lock
[
https://issues.apache.org/jira/browse/HDFS-15382?focusedWorklogId=730846&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730846
]
ASF GitHub Bot logged work on HDFS-15382:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 12:14
Start Date: 22/Feb/22 12:14
Worklog Time Spent: 10m
Work Description: MingXiangLi commented on a change in pull request #3941:
URL: https://github.com/apache/hadoop/pull/3941#discussion_r811881764
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/fsdataset/impl/ReplicaMap.java
##
@@ -184,7 +203,7 @@ void mergeAll(ReplicaMap other) {
ReplicaInfo remove(String bpid, Block block) {
checkBlockPool(bpid);
checkBlock(block);
-try (AutoCloseableLock l = writeLock.acquire()) {
+try (AutoCloseDataSetLock l = lockManager.readLock(LockLevel.BLOCK_POOl,
bpid)) {
Review comment:
Now the LightWeightResizableGSet is thread-safe, so most operate in
ReplicaMap just need block pool read.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 730846)
Time Spent: 2.5h (was: 2h 20m)
> Split FsDatasetImpl from blockpool lock to blockpool volume lock
> -
>
> Key: HDFS-15382
> URL: https://issues.apache.org/jira/browse/HDFS-15382
> Project: Hadoop HDFS
> Issue Type: Improvement
>Reporter: Mingxiang Li
>Assignee: Mingxiang Li
>Priority: Major
> Labels: pull-request-available
> Attachments: HDFS-15382-sample.patch, image-2020-06-02-1.png,
> image-2020-06-03-1.png
>
> Time Spent: 2.5h
> Remaining Estimate: 0h
>
> In HDFS-15180 we split lock to blockpool grain size.But when one volume is in
> heavy load and will block other request which in same blockpool but different
> volume.So we split lock to two leval to avoid this happend.And to improve
> datanode performance.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Comment Edited] (HDFS-16460) [SPS]: Handle failure retries for moving tasks
[ https://issues.apache.org/jira/browse/HDFS-16460?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17496056#comment-17496056 ] tomscut edited comment on HDFS-16460 at 2/22/22, 12:14 PM: --- The related PR is [#4001.|https://github.com/apache/hadoop/pull/4001] was (Author: tomscut): The related PR is [#4001|https://github.com/apache/hadoop/pull/4001] > [SPS]: Handle failure retries for moving tasks > -- > > Key: HDFS-16460 > URL: https://issues.apache.org/jira/browse/HDFS-16460 > Project: Hadoop HDFS > Issue Type: Sub-task >Reporter: tomscut >Assignee: tomscut >Priority: Major > > Handle failure retries for moving tasks. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-15382) Split FsDatasetImpl from blockpool lock to blockpool volume lock
[
https://issues.apache.org/jira/browse/HDFS-15382?focusedWorklogId=730847&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730847
]
ASF GitHub Bot logged work on HDFS-15382:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 12:14
Start Date: 22/Feb/22 12:14
Worklog Time Spent: 10m
Work Description: MingXiangLi commented on a change in pull request #3941:
URL: https://github.com/apache/hadoop/pull/3941#discussion_r811881764
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/fsdataset/impl/ReplicaMap.java
##
@@ -184,7 +203,7 @@ void mergeAll(ReplicaMap other) {
ReplicaInfo remove(String bpid, Block block) {
checkBlockPool(bpid);
checkBlock(block);
-try (AutoCloseableLock l = writeLock.acquire()) {
+try (AutoCloseDataSetLock l = lockManager.readLock(LockLevel.BLOCK_POOl,
bpid)) {
Review comment:
Now the LightWeightResizableGSet is thread-safe, so most operate in
ReplicaMap just need block pool read lock.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 730847)
Time Spent: 2h 40m (was: 2.5h)
> Split FsDatasetImpl from blockpool lock to blockpool volume lock
> -
>
> Key: HDFS-15382
> URL: https://issues.apache.org/jira/browse/HDFS-15382
> Project: Hadoop HDFS
> Issue Type: Improvement
>Reporter: Mingxiang Li
>Assignee: Mingxiang Li
>Priority: Major
> Labels: pull-request-available
> Attachments: HDFS-15382-sample.patch, image-2020-06-02-1.png,
> image-2020-06-03-1.png
>
> Time Spent: 2h 40m
> Remaining Estimate: 0h
>
> In HDFS-15180 we split lock to blockpool grain size.But when one volume is in
> heavy load and will block other request which in same blockpool but different
> volume.So we split lock to two leval to avoid this happend.And to improve
> datanode performance.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16460) [SPS]: Handle failure retries for moving tasks
[ https://issues.apache.org/jira/browse/HDFS-16460?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17496056#comment-17496056 ] tomscut commented on HDFS-16460: The related PR is [#4001|https://github.com/apache/hadoop/pull/4001] > [SPS]: Handle failure retries for moving tasks > -- > > Key: HDFS-16460 > URL: https://issues.apache.org/jira/browse/HDFS-16460 > Project: Hadoop HDFS > Issue Type: Sub-task >Reporter: tomscut >Assignee: tomscut >Priority: Major > > Handle failure retries for moving tasks. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16458) [SPS]: Fix bug for unit test of reconfiguring SPS mode
[
https://issues.apache.org/jira/browse/HDFS-16458?focusedWorklogId=730841&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730841
]
ASF GitHub Bot logged work on HDFS-16458:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 12:06
Start Date: 22/Feb/22 12:06
Worklog Time Spent: 10m
Work Description: tomscut commented on pull request #3998:
URL: https://github.com/apache/hadoop/pull/3998#issuecomment-1047729381
> @tomscut BTW, it is better to add the issue num within commit message next
time.:) I will add the issue num when merge this PR.
My bad. Thanks @ferhui for your review. I'll pay attention to this in the
future.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 730841)
Remaining Estimate: 0h
Time Spent: 10m
> [SPS]: Fix bug for unit test of reconfiguring SPS mode
> --
>
> Key: HDFS-16458
> URL: https://issues.apache.org/jira/browse/HDFS-16458
> Project: Hadoop HDFS
> Issue Type: Sub-task
>Reporter: tomscut
>Assignee: tomscut
>Priority: Major
> Time Spent: 10m
> Remaining Estimate: 0h
>
> TestNameNodeReconfigure#verifySPSEnabled was compared with
> itself({*}isSPSRunning{*}) at assertEquals.
> In addition, after an *internal SPS* has been removed, *spsService daemon*
> will not start within StoragePolicySatisfyManager. I think the relevant code
> can be removed to simplify the code.
> IMO, after reconfig SPS mode, we just need to confirm whether the mode is
> correct and whether spsManager is NULL.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16458) [SPS]: Fix bug for unit test of reconfiguring SPS mode
[
https://issues.apache.org/jira/browse/HDFS-16458?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HDFS-16458:
--
Labels: pull-request-available (was: )
> [SPS]: Fix bug for unit test of reconfiguring SPS mode
> --
>
> Key: HDFS-16458
> URL: https://issues.apache.org/jira/browse/HDFS-16458
> Project: Hadoop HDFS
> Issue Type: Sub-task
>Reporter: tomscut
>Assignee: tomscut
>Priority: Major
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> TestNameNodeReconfigure#verifySPSEnabled was compared with
> itself({*}isSPSRunning{*}) at assertEquals.
> In addition, after an *internal SPS* has been removed, *spsService daemon*
> will not start within StoragePolicySatisfyManager. I think the relevant code
> can be removed to simplify the code.
> IMO, after reconfig SPS mode, we just need to confirm whether the mode is
> correct and whether spsManager is NULL.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-15382) Split FsDatasetImpl from blockpool lock to blockpool volume lock
[
https://issues.apache.org/jira/browse/HDFS-15382?focusedWorklogId=730840&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730840
]
ASF GitHub Bot logged work on HDFS-15382:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 12:05
Start Date: 22/Feb/22 12:05
Worklog Time Spent: 10m
Work Description: MingXiangLi commented on a change in pull request #3941:
URL: https://github.com/apache/hadoop/pull/3941#discussion_r811874920
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/test/java/org/apache/hadoop/hdfs/server/datanode/fsdataset/impl/TestFsDatasetImpl.java
##
@@ -232,118 +232,6 @@ public void setUp() throws IOException {
assertEquals(0, dataset.getNumFailedVolumes());
}
- @Test(timeout=1)
Review comment:
this old lock model no longer useful
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 730840)
Time Spent: 2h 20m (was: 2h 10m)
> Split FsDatasetImpl from blockpool lock to blockpool volume lock
> -
>
> Key: HDFS-15382
> URL: https://issues.apache.org/jira/browse/HDFS-15382
> Project: Hadoop HDFS
> Issue Type: Improvement
>Reporter: Mingxiang Li
>Assignee: Mingxiang Li
>Priority: Major
> Labels: pull-request-available
> Attachments: HDFS-15382-sample.patch, image-2020-06-02-1.png,
> image-2020-06-03-1.png
>
> Time Spent: 2h 20m
> Remaining Estimate: 0h
>
> In HDFS-15180 we split lock to blockpool grain size.But when one volume is in
> heavy load and will block other request which in same blockpool but different
> volume.So we split lock to two leval to avoid this happend.And to improve
> datanode performance.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-15382) Split FsDatasetImpl from blockpool lock to blockpool volume lock
[
https://issues.apache.org/jira/browse/HDFS-15382?focusedWorklogId=730839&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730839
]
ASF GitHub Bot logged work on HDFS-15382:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 12:04
Start Date: 22/Feb/22 12:04
Worklog Time Spent: 10m
Work Description: MingXiangLi commented on a change in pull request #3941:
URL: https://github.com/apache/hadoop/pull/3941#discussion_r811873922
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/DiskBalancer.java
##
@@ -504,15 +503,13 @@ private void createWorkPlan(NodePlan plan) throws
DiskBalancerException {
Map storageIDToVolBasePathMap = new HashMap<>();
FsDatasetSpi.FsVolumeReferences references;
try {
- try(AutoCloseableLock lock = this.dataset.acquireDatasetReadLock()) {
-references = this.dataset.getFsVolumeReferences();
-for (int ndx = 0; ndx < references.size(); ndx++) {
- FsVolumeSpi vol = references.get(ndx);
- storageIDToVolBasePathMap.put(vol.getStorageID(),
- vol.getBaseURI().getPath());
-}
-references.close();
+ references = this.dataset.getFsVolumeReferences();
+ for (int ndx = 0; ndx < references.size(); ndx++) {
+FsVolumeSpi vol = references.get(ndx);
+storageIDToVolBasePathMap.put(vol.getStorageID(),
+vol.getBaseURI().getPath());
}
+ references.close();
Review comment:
ok,I will fix this later
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 730839)
Time Spent: 2h 10m (was: 2h)
> Split FsDatasetImpl from blockpool lock to blockpool volume lock
> -
>
> Key: HDFS-15382
> URL: https://issues.apache.org/jira/browse/HDFS-15382
> Project: Hadoop HDFS
> Issue Type: Improvement
>Reporter: Mingxiang Li
>Assignee: Mingxiang Li
>Priority: Major
> Labels: pull-request-available
> Attachments: HDFS-15382-sample.patch, image-2020-06-02-1.png,
> image-2020-06-03-1.png
>
> Time Spent: 2h 10m
> Remaining Estimate: 0h
>
> In HDFS-15180 we split lock to blockpool grain size.But when one volume is in
> heavy load and will block other request which in same blockpool but different
> volume.So we split lock to two leval to avoid this happend.And to improve
> datanode performance.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-15382) Split FsDatasetImpl from blockpool lock to blockpool volume lock
[
https://issues.apache.org/jira/browse/HDFS-15382?focusedWorklogId=730837&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730837
]
ASF GitHub Bot logged work on HDFS-15382:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 12:03
Start Date: 22/Feb/22 12:03
Worklog Time Spent: 10m
Work Description: tomscut commented on a change in pull request #3941:
URL: https://github.com/apache/hadoop/pull/3941#discussion_r811864144
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/fsdataset/impl/FsDatasetImpl.java
##
@@ -1850,7 +1828,8 @@ public ReplicaHandler createTemporary(StorageType
storageType,
ReplicaInfo lastFoundReplicaInfo = null;
boolean isInPipeline = false;
do {
- try (AutoCloseableLock lock = datasetWriteLock.acquire()) {
+ try (AutoCloseableLock lock = lockManager.readLock(LockLevel.BLOCK_POOl,
Review comment:
Here write lock is changed to read lock, is there any problem?
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/fsdataset/impl/ReplicaMap.java
##
@@ -184,7 +203,7 @@ void mergeAll(ReplicaMap other) {
ReplicaInfo remove(String bpid, Block block) {
checkBlockPool(bpid);
checkBlock(block);
-try (AutoCloseableLock l = writeLock.acquire()) {
+try (AutoCloseDataSetLock l = lockManager.readLock(LockLevel.BLOCK_POOl,
bpid)) {
Review comment:
I agree with @Hexiaoqiao . We should keep the read/write lock. Once
`block Pool lock` is introduced, we can discuss whether `write locks` need to
be changed to `read locks` in other JIRA.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 730837)
Time Spent: 2h (was: 1h 50m)
> Split FsDatasetImpl from blockpool lock to blockpool volume lock
> -
>
> Key: HDFS-15382
> URL: https://issues.apache.org/jira/browse/HDFS-15382
> Project: Hadoop HDFS
> Issue Type: Improvement
>Reporter: Mingxiang Li
>Assignee: Mingxiang Li
>Priority: Major
> Labels: pull-request-available
> Attachments: HDFS-15382-sample.patch, image-2020-06-02-1.png,
> image-2020-06-03-1.png
>
> Time Spent: 2h
> Remaining Estimate: 0h
>
> In HDFS-15180 we split lock to blockpool grain size.But when one volume is in
> heavy load and will block other request which in same blockpool but different
> volume.So we split lock to two leval to avoid this happend.And to improve
> datanode performance.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-15382) Split FsDatasetImpl from blockpool lock to blockpool volume lock
[
https://issues.apache.org/jira/browse/HDFS-15382?focusedWorklogId=730836&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730836
]
ASF GitHub Bot logged work on HDFS-15382:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 12:03
Start Date: 22/Feb/22 12:03
Worklog Time Spent: 10m
Work Description: MingXiangLi commented on a change in pull request #3941:
URL: https://github.com/apache/hadoop/pull/3941#discussion_r811872874
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/fsdataset/impl/ReplicaMap.java
##
@@ -117,7 +121,7 @@ ReplicaInfo get(String bpid, long blockId) {
ReplicaInfo add(String bpid, ReplicaInfo replicaInfo) {
checkBlockPool(bpid);
checkBlock(replicaInfo);
-try (AutoCloseableLock l = writeLock.acquire()) {
+try (AutoCloseDataSetLock l = lockManager.readLock(LockLevel.BLOCK_POOl,
bpid)) {
Review comment:
in new version I have change LightWeightResizableGSet to make it
thread-safe.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 730836)
Time Spent: 1h 50m (was: 1h 40m)
> Split FsDatasetImpl from blockpool lock to blockpool volume lock
> -
>
> Key: HDFS-15382
> URL: https://issues.apache.org/jira/browse/HDFS-15382
> Project: Hadoop HDFS
> Issue Type: Improvement
>Reporter: Mingxiang Li
>Assignee: Mingxiang Li
>Priority: Major
> Labels: pull-request-available
> Attachments: HDFS-15382-sample.patch, image-2020-06-02-1.png,
> image-2020-06-03-1.png
>
> Time Spent: 1h 50m
> Remaining Estimate: 0h
>
> In HDFS-15180 we split lock to blockpool grain size.But when one volume is in
> heavy load and will block other request which in same blockpool but different
> volume.So we split lock to two leval to avoid this happend.And to improve
> datanode performance.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-15382) Split FsDatasetImpl from blockpool lock to blockpool volume lock
[
https://issues.apache.org/jira/browse/HDFS-15382?focusedWorklogId=730834&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730834
]
ASF GitHub Bot logged work on HDFS-15382:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 12:00
Start Date: 22/Feb/22 12:00
Worklog Time Spent: 10m
Work Description: MingXiangLi commented on a change in pull request #3941:
URL: https://github.com/apache/hadoop/pull/3941#discussion_r811871088
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/DataNode.java
##
@@ -3230,7 +3235,9 @@ void transferReplicaForPipelineRecovery(final
ExtendedBlock b,
final BlockConstructionStage stage;
//get replica information
-try(AutoCloseableLock lock = data.acquireDatasetReadLock()) {
+
+try(AutoCloseableLock lock = dataSetLockManager.writeLock(
Review comment:
this should be read lock.I write wrong here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 730834)
Time Spent: 1h 40m (was: 1.5h)
> Split FsDatasetImpl from blockpool lock to blockpool volume lock
> -
>
> Key: HDFS-15382
> URL: https://issues.apache.org/jira/browse/HDFS-15382
> Project: Hadoop HDFS
> Issue Type: Improvement
>Reporter: Mingxiang Li
>Assignee: Mingxiang Li
>Priority: Major
> Labels: pull-request-available
> Attachments: HDFS-15382-sample.patch, image-2020-06-02-1.png,
> image-2020-06-03-1.png
>
> Time Spent: 1h 40m
> Remaining Estimate: 0h
>
> In HDFS-15180 we split lock to blockpool grain size.But when one volume is in
> heavy load and will block other request which in same blockpool but different
> volume.So we split lock to two leval to avoid this happend.And to improve
> datanode performance.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-14626) Decommission all nodes hosting last block of open file succeeds unexpectedly
[
https://issues.apache.org/jira/browse/HDFS-14626?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17496014#comment-17496014
]
Stephen O'Donnell commented on HDFS-14626:
--
[~aajisaka] I have not looked into this issue for years now. It does seem like
something which should be fixed, but I have no plans to work on it. Feel free
to take it over if you want to try fixing it.
> Decommission all nodes hosting last block of open file succeeds unexpectedly
> -
>
> Key: HDFS-14626
> URL: https://issues.apache.org/jira/browse/HDFS-14626
> Project: Hadoop HDFS
> Issue Type: Bug
>Affects Versions: 3.3.0
>Reporter: Stephen O'Donnell
>Assignee: Stephen O'Donnell
>Priority: Major
> Attachments: test-to-reproduce.patch
>
>
> I have been investigating scenarios that cause decommission to hang,
> especially around one long standing issue. That is, an open block on the host
> which is being decommissioned can cause the process to never complete.
> Checking the history, there seems to have been at least one change in
> HDFS-5579 which greatly improved the situation, but from reading comments and
> support cases, there still seems to be some scenarios where open blocks on a
> DN host cause the decommission to get stuck.
> No matter what I try, I have not been able to reproduce this, but I think I
> have uncovered another issue that may partly explain why.
> If I do the following, the nodes will decommission without any issues:
> 1. Create a file and write to it so it crosses a block boundary. Then there
> is one complete block and one under construction block. Keep the file open,
> and write a few bytes periodically.
> 2. Now note the nodes which the UC block is currently being written on, and
> decommission them all.
> 3. The decommission should succeed.
> 4. Now attempt to close the open file, and it will fail to close with an
> error like below, probably as decommissioned nodes are not allowed to send
> IBRs:
> {code:java}
> java.io.IOException: Unable to close file because the last block
> BP-646926902-192.168.0.20-1562099323291:blk_1073741827_1003 does not have
> enough number of replicas.
> at
> org.apache.hadoop.hdfs.DFSOutputStream.completeFile(DFSOutputStream.java:968)
> at
> org.apache.hadoop.hdfs.DFSOutputStream.completeFile(DFSOutputStream.java:911)
> at
> org.apache.hadoop.hdfs.DFSOutputStream.closeImpl(DFSOutputStream.java:894)
> at org.apache.hadoop.hdfs.DFSOutputStream.close(DFSOutputStream.java:849)
> at
> org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72)
> at
> org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:101){code}
> Interestingly, if you recommission the nodes without restarting them before
> closing the file, it will close OK, and writes to it can continue even once
> decommission has completed.
> I don't think this is expected - ie decommission should not complete on all
> nodes hosting the last UC block of a file?
> From what I have figured out, I don't think UC blocks are considered in the
> DatanodeAdminManager at all. This is because the original list of blocks it
> cares about, are taken from the Datanode block Iterator, which takes them
> from the DatanodeStorageInfo objects attached to the datanode instance. I
> believe UC blocks don't make it into the DatanodeStoreageInfo until after
> they have been completed and an IBR sent, so the decommission logic never
> considers them.
> What troubles me about this explanation, is how did open files previously
> cause decommission to get stuck if it never checks for them, so I suspect I
> am missing something.
> I will attach a patch with a test case that demonstrates this issue. This
> reproduces on trunk and I also tested on CDH 5.8.1, which is based on the 2.6
> branch, but with a lot of backports.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-15382) Split FsDatasetImpl from blockpool lock to blockpool volume lock
[
https://issues.apache.org/jira/browse/HDFS-15382?focusedWorklogId=730729&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730729
]
ASF GitHub Bot logged work on HDFS-15382:
-
Author: ASF GitHub Bot
Created on: 22/Feb/22 09:45
Start Date: 22/Feb/22 09:45
Worklog Time Spent: 10m
Work Description: jojochuang commented on a change in pull request #3941:
URL: https://github.com/apache/hadoop/pull/3941#discussion_r811729617
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/DataNode.java
##
@@ -3230,7 +3235,9 @@ void transferReplicaForPipelineRecovery(final
ExtendedBlock b,
final BlockConstructionStage stage;
//get replica information
-try(AutoCloseableLock lock = data.acquireDatasetReadLock()) {
+
+try(AutoCloseableLock lock = dataSetLockManager.writeLock(
Review comment:
this was a read lock before. Any idea why it is made a write lock now?
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/DiskBalancer.java
##
@@ -504,15 +503,13 @@ private void createWorkPlan(NodePlan plan) throws
DiskBalancerException {
Map storageIDToVolBasePathMap = new HashMap<>();
FsDatasetSpi.FsVolumeReferences references;
try {
- try(AutoCloseableLock lock = this.dataset.acquireDatasetReadLock()) {
-references = this.dataset.getFsVolumeReferences();
-for (int ndx = 0; ndx < references.size(); ndx++) {
- FsVolumeSpi vol = references.get(ndx);
- storageIDToVolBasePathMap.put(vol.getStorageID(),
- vol.getBaseURI().getPath());
-}
-references.close();
+ references = this.dataset.getFsVolumeReferences();
+ for (int ndx = 0; ndx < references.size(); ndx++) {
+FsVolumeSpi vol = references.get(ndx);
+storageIDToVolBasePathMap.put(vol.getStorageID(),
+vol.getBaseURI().getPath());
}
+ references.close();
Review comment:
It would be better to instantiate the references object in a try .. with
block to ensure it is closed properly even with an exception,
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/fsdataset/impl/ReplicaMap.java
##
@@ -117,7 +121,7 @@ ReplicaInfo get(String bpid, long blockId) {
ReplicaInfo add(String bpid, ReplicaInfo replicaInfo) {
checkBlockPool(bpid);
checkBlock(replicaInfo);
-try (AutoCloseableLock l = writeLock.acquire()) {
+try (AutoCloseDataSetLock l = lockManager.readLock(LockLevel.BLOCK_POOl,
bpid)) {
Review comment:
why is read lock used here?
LightWeightResizableGSet is not thread-safe.
##
File path:
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/fsdataset/impl/FsDatasetImpl.java
##
@@ -602,7 +563,7 @@ public void removeVolumes(
new ArrayList<>(storageLocsToRemove);
Map> blkToInvalidate = new HashMap<>();
List storageToRemove = new ArrayList<>();
-try (AutoCloseableLock lock = datasetWriteLock.acquire()) {
+synchronized (this) {
Review comment:
how about making the entire method synchronized instead?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
Issue Time Tracking
---
Worklog Id: (was: 730729)
Time Spent: 1.5h (was: 1h 20m)
> Split FsDatasetImpl from blockpool lock to blockpool volume lock
> -
>
> Key: HDFS-15382
> URL: https://issues.apache.org/jira/browse/HDFS-15382
> Project: Hadoop HDFS
> Issue Type: Improvement
>Reporter: Mingxiang Li
>Assignee: Mingxiang Li
>Priority: Major
> Labels: pull-request-available
> Attachments: HDFS-15382-sample.patch, image-2020-06-02-1.png,
> image-2020-06-03-1.png
>
> Time Spent: 1.5h
> Remaining Estimate: 0h
>
> In HDFS-15180 we split lock to blockpool grain size.But when one volume is in
> heavy load and will block other request which in same blockpool but different
> volume.So we split lock to two leval to avoid this happend.And to improve
> datanode performance.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16475) Cleanup code in the write path
[ https://issues.apache.org/jira/browse/HDFS-16475?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Kaijie Chen updated HDFS-16475: --- Description: # In DFSOutputStream#newStreamForCreate(), `shouldRetry` is always true at the while loop. Remove this unnecessary variable. # Cleanup code in the write path. was:In DFSOutputStream#newStreamForCreate(), `shouldRetry` is always true at the while loop. Remove this unnecessary varible. Summary: Cleanup code in the write path (was: Remove unnecessary shouldRetry variable in DFSOutputStream) > Cleanup code in the write path > -- > > Key: HDFS-16475 > URL: https://issues.apache.org/jira/browse/HDFS-16475 > Project: Hadoop HDFS > Issue Type: Improvement >Reporter: Kaijie Chen >Priority: Trivial > Labels: pull-request-available > Time Spent: 20m > Remaining Estimate: 0h > > # In DFSOutputStream#newStreamForCreate(), `shouldRetry` is always true at > the while loop. Remove this unnecessary variable. > # Cleanup code in the write path. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-14626) Decommission all nodes hosting last block of open file succeeds unexpectedly
[
https://issues.apache.org/jira/browse/HDFS-14626?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=17495944#comment-17495944
]
Akira Ajisaka commented on HDFS-14626:
--
Hi [~sodonnell], how is this issue going? I think it is a bug, but now I don't
think we can fix it easily.
Currently DatanodeAdminManager does not manage the number of UC blocks for each
DN, so we need to add the mechanism to return the number of UC blocks for DN by
O(1). Maybe we can get approximate value by
DatanodeDescriptor#getBlocksScheduled(), but I'm not sure the value can be used
for decommission.
> Decommission all nodes hosting last block of open file succeeds unexpectedly
> -
>
> Key: HDFS-14626
> URL: https://issues.apache.org/jira/browse/HDFS-14626
> Project: Hadoop HDFS
> Issue Type: Bug
>Affects Versions: 3.3.0
>Reporter: Stephen O'Donnell
>Assignee: Stephen O'Donnell
>Priority: Major
> Attachments: test-to-reproduce.patch
>
>
> I have been investigating scenarios that cause decommission to hang,
> especially around one long standing issue. That is, an open block on the host
> which is being decommissioned can cause the process to never complete.
> Checking the history, there seems to have been at least one change in
> HDFS-5579 which greatly improved the situation, but from reading comments and
> support cases, there still seems to be some scenarios where open blocks on a
> DN host cause the decommission to get stuck.
> No matter what I try, I have not been able to reproduce this, but I think I
> have uncovered another issue that may partly explain why.
> If I do the following, the nodes will decommission without any issues:
> 1. Create a file and write to it so it crosses a block boundary. Then there
> is one complete block and one under construction block. Keep the file open,
> and write a few bytes periodically.
> 2. Now note the nodes which the UC block is currently being written on, and
> decommission them all.
> 3. The decommission should succeed.
> 4. Now attempt to close the open file, and it will fail to close with an
> error like below, probably as decommissioned nodes are not allowed to send
> IBRs:
> {code:java}
> java.io.IOException: Unable to close file because the last block
> BP-646926902-192.168.0.20-1562099323291:blk_1073741827_1003 does not have
> enough number of replicas.
> at
> org.apache.hadoop.hdfs.DFSOutputStream.completeFile(DFSOutputStream.java:968)
> at
> org.apache.hadoop.hdfs.DFSOutputStream.completeFile(DFSOutputStream.java:911)
> at
> org.apache.hadoop.hdfs.DFSOutputStream.closeImpl(DFSOutputStream.java:894)
> at org.apache.hadoop.hdfs.DFSOutputStream.close(DFSOutputStream.java:849)
> at
> org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72)
> at
> org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:101){code}
> Interestingly, if you recommission the nodes without restarting them before
> closing the file, it will close OK, and writes to it can continue even once
> decommission has completed.
> I don't think this is expected - ie decommission should not complete on all
> nodes hosting the last UC block of a file?
> From what I have figured out, I don't think UC blocks are considered in the
> DatanodeAdminManager at all. This is because the original list of blocks it
> cares about, are taken from the Datanode block Iterator, which takes them
> from the DatanodeStorageInfo objects attached to the datanode instance. I
> believe UC blocks don't make it into the DatanodeStoreageInfo until after
> they have been completed and an IBR sent, so the decommission logic never
> considers them.
> What troubles me about this explanation, is how did open files previously
> cause decommission to get stuck if it never checks for them, so I suspect I
> am missing something.
> I will attach a patch with a test case that demonstrates this issue. This
> reproduces on trunk and I also tested on CDH 5.8.1, which is based on the 2.6
> branch, but with a lot of backports.
--
This message was sent by Atlassian Jira
(v8.20.1#820001)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16477) [SPS]: Add metric PendingSPSPaths for getting the number of paths to be processed by SPS
[ https://issues.apache.org/jira/browse/HDFS-16477?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDFS-16477: -- Labels: pull-request-available (was: ) > [SPS]: Add metric PendingSPSPaths for getting the number of paths to be > processed by SPS > > > Key: HDFS-16477 > URL: https://issues.apache.org/jira/browse/HDFS-16477 > Project: Hadoop HDFS > Issue Type: Sub-task >Reporter: tomscut >Assignee: tomscut >Priority: Major > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > Currently we have no idea how many paths are waiting to be processed when > using the SPS feature. We should add metric PendingSPSPaths for getting the > number of paths to be processed by SPS in NameNode. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16477) [SPS]: Add metric PendingSPSPaths for getting the number of paths to be processed by SPS
[ https://issues.apache.org/jira/browse/HDFS-16477?focusedWorklogId=730686&page=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-730686 ] ASF GitHub Bot logged work on HDFS-16477: - Author: ASF GitHub Bot Created on: 22/Feb/22 08:16 Start Date: 22/Feb/22 08:16 Worklog Time Spent: 10m Work Description: tomscut opened a new pull request #4009: URL: https://github.com/apache/hadoop/pull/4009 JIRA: [HDFS-16477](https://issues.apache.org/jira/browse/HDFS-16477). Currently we have no idea how many paths are waiting to be processed when using the SPS feature. We should add metric `PendingSPSPaths` for getting the number of paths to be processed by SPS in NameNode. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: common-issues-unsubscr...@hadoop.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org Issue Time Tracking --- Worklog Id: (was: 730686) Remaining Estimate: 0h Time Spent: 10m > [SPS]: Add metric PendingSPSPaths for getting the number of paths to be > processed by SPS > > > Key: HDFS-16477 > URL: https://issues.apache.org/jira/browse/HDFS-16477 > Project: Hadoop HDFS > Issue Type: Sub-task >Reporter: tomscut >Assignee: tomscut >Priority: Major > Time Spent: 10m > Remaining Estimate: 0h > > Currently we have no idea how many paths are waiting to be processed when > using the SPS feature. We should add metric PendingSPSPaths for getting the > number of paths to be processed by SPS in NameNode. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Created] (HDFS-16477) [SPS]: Add metric PendingSPSPaths for getting the number of paths to be processed by SPS
tomscut created HDFS-16477: -- Summary: [SPS]: Add metric PendingSPSPaths for getting the number of paths to be processed by SPS Key: HDFS-16477 URL: https://issues.apache.org/jira/browse/HDFS-16477 Project: Hadoop HDFS Issue Type: Sub-task Reporter: tomscut Assignee: tomscut Currently we have no idea how many paths are waiting to be processed when using the SPS feature. We should add metric PendingSPSPaths for getting the number of paths to be processed by SPS in NameNode. -- This message was sent by Atlassian Jira (v8.20.1#820001) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org