[jira] [Work logged] (HDFS-16573) Fix test TestDFSStripedInputStreamWithRandomECPolicy
[ https://issues.apache.org/jira/browse/HDFS-16573?focusedWorklogId=768318=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-768318 ] ASF GitHub Bot logged work on HDFS-16573: - Author: ASF GitHub Bot Created on: 10/May/22 05:31 Start Date: 10/May/22 05:31 Worklog Time Spent: 10m Work Description: cndaimin commented on PR #4291: URL: https://github.com/apache/hadoop/pull/4291#issuecomment-1121949226 > Hi @cndaimin , could you please cherry-pick this to branch-3.3. Thanks. It seems I don't have the access right to branch-3.3, could you help on the cherry-pick? thanks. Issue Time Tracking --- Worklog Id: (was: 768318) Time Spent: 1h 10m (was: 1h) > Fix test TestDFSStripedInputStreamWithRandomECPolicy > > > Key: HDFS-16573 > URL: https://issues.apache.org/jira/browse/HDFS-16573 > Project: Hadoop HDFS > Issue Type: Test > Components: test >Affects Versions: 3.3.2 >Reporter: daimin >Assignee: daimin >Priority: Minor > Labels: pull-request-available > Fix For: 3.4.0 > > Time Spent: 1h 10m > Remaining Estimate: 0h > > TestDFSStripedInputStreamWithRandomECPolicy fails due to test from HDFS-16520 -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-13522) RBF: Support observer node from Router-Based Federation
[
https://issues.apache.org/jira/browse/HDFS-13522?focusedWorklogId=768314=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-768314
]
ASF GitHub Bot logged work on HDFS-13522:
-
Author: ASF GitHub Bot
Created on: 10/May/22 05:21
Start Date: 10/May/22 05:21
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on PR #4127:
URL: https://github.com/apache/hadoop/pull/4127#issuecomment-1121944319
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 39s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 1s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 0s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 12 new or modified test files. |
_ trunk Compile Tests _ |
| +0 :ok: | mvndep | 15m 57s | | Maven dependency ordering for branch |
| +1 :green_heart: | mvninstall | 25m 17s | | trunk passed |
| +1 :green_heart: | compile | 23m 19s | | trunk passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | compile | 20m 42s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 4m 28s | | trunk passed |
| +1 :green_heart: | mvnsite | 7m 40s | | trunk passed |
| -1 :x: | javadoc | 1m 51s |
[/branch-javadoc-hadoop-common-project_hadoop-common-jdkPrivateBuild-11.0.15+10-Ubuntu-0ubuntu0.20.04.1.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4127/7/artifact/out/branch-javadoc-hadoop-common-project_hadoop-common-jdkPrivateBuild-11.0.15+10-Ubuntu-0ubuntu0.20.04.1.txt)
| hadoop-common in trunk failed with JDK Private
Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1. |
| +1 :green_heart: | javadoc | 7m 34s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 12m 18s | | trunk passed |
| +1 :green_heart: | shadedclient | 22m 33s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +0 :ok: | mvndep | 0m 30s | | Maven dependency ordering for patch |
| +1 :green_heart: | mvninstall | 4m 10s | | the patch passed |
| +1 :green_heart: | compile | 22m 23s | | the patch passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javac | 22m 23s | | the patch passed |
| +1 :green_heart: | compile | 20m 35s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 20m 35s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| -0 :warning: | checkstyle | 4m 16s |
[/results-checkstyle-root.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4127/7/artifact/out/results-checkstyle-root.txt)
| root: The patch generated 6 new + 340 unchanged - 1 fixed = 346 total (was
341) |
| +1 :green_heart: | mvnsite | 7m 30s | | the patch passed |
| +1 :green_heart: | xml | 0m 2s | | The patch has no ill-formed XML
file. |
| -1 :x: | javadoc | 1m 42s |
[/patch-javadoc-hadoop-common-project_hadoop-common-jdkPrivateBuild-11.0.15+10-Ubuntu-0ubuntu0.20.04.1.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4127/7/artifact/out/patch-javadoc-hadoop-common-project_hadoop-common-jdkPrivateBuild-11.0.15+10-Ubuntu-0ubuntu0.20.04.1.txt)
| hadoop-common in the patch failed with JDK Private
Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1. |
| +1 :green_heart: | javadoc | 7m 46s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 12m 53s | | the patch passed |
| +1 :green_heart: | shadedclient | 22m 57s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 18m 35s | | hadoop-common in the patch
passed. |
| +1 :green_heart: | unit | 3m 19s | | hadoop-hdfs-client in the patch
passed. |
| -1 :x: | unit | 261m 6s |
[/patch-unit-hadoop-hdfs-project_hadoop-hdfs.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4127/7/artifact/out/patch-unit-hadoop-hdfs-project_hadoop-hdfs.txt)
| hadoop-hdfs in the patch passed. |
| -1 :x: | unit | 23m 38s |
[jira] [Updated] (HDFS-16575) [SPS]: Should use real replication num instead getReplication from namenode
[
https://issues.apache.org/jira/browse/HDFS-16575?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HDFS-16575:
--
Labels: pull-request-available (was: )
> [SPS]: Should use real replication num instead getReplication from namenode
> ---
>
> Key: HDFS-16575
> URL: https://issues.apache.org/jira/browse/HDFS-16575
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: qinyuren
>Priority: Major
> Labels: pull-request-available
> Attachments: image-2022-05-10-11-21-13-627.png,
> image-2022-05-10-11-21-31-987.png
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> The SPS may have misjudged in the following scenario:
> # Create a file with one block and this block have 3 replication with
> {color:#de350b}DISK{color} type [DISK, DISK, DISK].
> # Set this file with {color:#de350b}ALL_SSD{color} storage policy.
> # The replication of this file may become [DISK, DISK,
> {color:#de350b}SSD{color}, DISK] with {color:#de350b}decommission{color}.
> # Set this file with {color:#de350b}HOT{color} storage policy and satisfy
> storage policy on this file.
> # The replication finally look like [DISK, DISK, SSD] not [DISK, DISK,
> DISK] after decommissioned node offline.
> The reason is that SPS get the block replications by
> FileStatus.getReplication() which is not the real num of the block.
> !image-2022-05-10-11-21-13-627.png|width=432,height=76!
> So this block will be ignored, because it have 3 replications with DISK type
> already ( one replication in a decommissioning node)
> !image-2022-05-10-11-21-31-987.png|width=334,height=179!
> I think we can use blockInfo.getLocations().length to count the replication
> of block instead of FileStatus.getReplication().
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16575) [SPS]: Should use real replication num instead getReplication from namenode
[
https://issues.apache.org/jira/browse/HDFS-16575?focusedWorklogId=768305=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-768305
]
ASF GitHub Bot logged work on HDFS-16575:
-
Author: ASF GitHub Bot
Created on: 10/May/22 04:09
Start Date: 10/May/22 04:09
Worklog Time Spent: 10m
Work Description: liubingxing opened a new pull request, #4295:
URL: https://github.com/apache/hadoop/pull/4295
The SPS may have misjudged in the following scenario:
1. Create a file with one block and this block have 3 replication with
**DISK** type [DISK, DISK, DISK].
2. Set this file with **ALL_SSD** storage policy.
3. The replication of this file may become [DISK, DISK, **SSD**, DISK] with
**decommission**.
4. Set this file with **HOT** storage policy and satisfy storage policy on
this file.
5. The replication finally look like [DISK, DISK, SSD] not [DISK, DISK,
DISK] after decommissioned node offline.
6. The reason is that SPS get the block replications by
FileStatus.getReplication() which is not the real num of the block.

So this block will be ignored, because it have 3 replications with DISK type
already ( one replication in a decommissioning node)
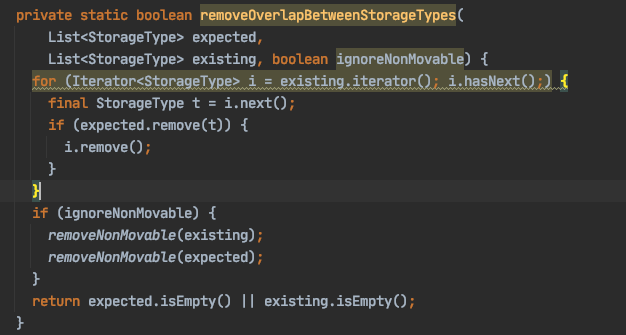
I think we can use blockInfo.getLocations().length to count the replication
of block instead of FileStatus.getReplication().
Issue Time Tracking
---
Worklog Id: (was: 768305)
Remaining Estimate: 0h
Time Spent: 10m
> [SPS]: Should use real replication num instead getReplication from namenode
> ---
>
> Key: HDFS-16575
> URL: https://issues.apache.org/jira/browse/HDFS-16575
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: qinyuren
>Priority: Major
> Attachments: image-2022-05-10-11-21-13-627.png,
> image-2022-05-10-11-21-31-987.png
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> The SPS may have misjudged in the following scenario:
> # Create a file with one block and this block have 3 replication with
> {color:#de350b}DISK{color} type [DISK, DISK, DISK].
> # Set this file with {color:#de350b}ALL_SSD{color} storage policy.
> # The replication of this file may become [DISK, DISK,
> {color:#de350b}SSD{color}, DISK] with {color:#de350b}decommission{color}.
> # Set this file with {color:#de350b}HOT{color} storage policy and satisfy
> storage policy on this file.
> # The replication finally look like [DISK, DISK, SSD] not [DISK, DISK,
> DISK] after decommissioned node offline.
> The reason is that SPS get the block replications by
> FileStatus.getReplication() which is not the real num of the block.
> !image-2022-05-10-11-21-13-627.png|width=432,height=76!
> So this block will be ignored, because it have 3 replications with DISK type
> already ( one replication in a decommissioning node)
> !image-2022-05-10-11-21-31-987.png|width=334,height=179!
> I think we can use blockInfo.getLocations().length to count the replication
> of block instead of FileStatus.getReplication().
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16575) [SPS]: Should use real replication num instead getReplication from namenode
[
https://issues.apache.org/jira/browse/HDFS-16575?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
qinyuren updated HDFS-16575:
Description:
The SPS may have misjudged in the following scenario:
# Create a file with one block and this block have 3 replication with
{color:#de350b}DISK{color} type [DISK, DISK, DISK].
# Set this file with {color:#de350b}ALL_SSD{color} storage policy.
# The replication of this file may become [DISK, DISK,
{color:#de350b}SSD{color}, DISK] with {color:#de350b}decommission{color}.
# Set this file with {color:#de350b}HOT{color} storage policy and satisfy
storage policy on this file.
# The replication finally look like [DISK, DISK, SSD] not [DISK, DISK, DISK]
after decommissioned node offline.
The reason is that SPS get the block replications by
FileStatus.getReplication() which is not the real num of the block.
!image-2022-05-10-11-21-13-627.png|width=432,height=76!
So this block will be ignored, because it have 3 replications with DISK type
already ( one replication in a decommissioning node)
!image-2022-05-10-11-21-31-987.png|width=334,height=179!
I think we can use blockInfo.getLocations().length to count the replication of
block instead of FileStatus.getReplication().
was:
# create a file with one block and this block have 3 replication with
{color:#de350b}DISK{color} type [DISK, DISK, DISK].
# Set this file with {color:#de350b}ALL_SSD{color} storage policy.
# The replication of this file may become [DISK, DISK,
{color:#de350b}SSD{color}, DISK] with {color:#de350b}decommission{color}.
# Set this file with {color:#de350b}HOT{color} storage policy and satisfy
storage policy on this file.
# The replication finally look like [DISK, DISK, SSD] not [DISK, DISK, DISK]
after decommissioned node offline.
The reason is that SPS get the block replications by
FileStatus.getReplication() which is not the real num of the block.
!image-2022-05-10-11-21-13-627.png|width=432,height=76!
So this block will be ignored, because it have 3 replications with DISK type (
one replication in a decommissioning node)
!image-2022-05-10-11-21-31-987.png|width=334,height=179!
> [SPS]: Should use real replication num instead getReplication from namenode
> ---
>
> Key: HDFS-16575
> URL: https://issues.apache.org/jira/browse/HDFS-16575
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: qinyuren
>Priority: Major
> Attachments: image-2022-05-10-11-21-13-627.png,
> image-2022-05-10-11-21-31-987.png
>
>
> The SPS may have misjudged in the following scenario:
> # Create a file with one block and this block have 3 replication with
> {color:#de350b}DISK{color} type [DISK, DISK, DISK].
> # Set this file with {color:#de350b}ALL_SSD{color} storage policy.
> # The replication of this file may become [DISK, DISK,
> {color:#de350b}SSD{color}, DISK] with {color:#de350b}decommission{color}.
> # Set this file with {color:#de350b}HOT{color} storage policy and satisfy
> storage policy on this file.
> # The replication finally look like [DISK, DISK, SSD] not [DISK, DISK,
> DISK] after decommissioned node offline.
> The reason is that SPS get the block replications by
> FileStatus.getReplication() which is not the real num of the block.
> !image-2022-05-10-11-21-13-627.png|width=432,height=76!
> So this block will be ignored, because it have 3 replications with DISK type
> already ( one replication in a decommissioning node)
> !image-2022-05-10-11-21-31-987.png|width=334,height=179!
> I think we can use blockInfo.getLocations().length to count the replication
> of block instead of FileStatus.getReplication().
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16575) [SPS]: Should use real replication num instead getReplication from namenode
[
https://issues.apache.org/jira/browse/HDFS-16575?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
qinyuren updated HDFS-16575:
Description:
# create a file with one block and this block have 3 replication with
{color:#de350b}DISK{color} type [DISK, DISK, DISK].
# Set this file with {color:#de350b}ALL_SSD{color} storage policy.
# The replication of this file may become [DISK, DISK,
{color:#de350b}SSD{color}, DISK] with {color:#de350b}decommission{color}.
# Set this file with {color:#de350b}HOT{color} storage policy and satisfy
storage policy on this file.
# The replication finally look like [DISK, DISK, SSD] not [DISK, DISK, DISK]
after decommissioned node offline.
The reason is that SPS get the block replications by
FileStatus.getReplication() which is not the real num of the block.
!image-2022-05-10-11-21-13-627.png|width=432,height=76!
So this block will be ignored, because it have 3 replications with DISK type (
one replication in a decommissioning node)
!image-2022-05-10-11-21-31-987.png|width=334,height=179!
> [SPS]: Should use real replication num instead getReplication from namenode
> ---
>
> Key: HDFS-16575
> URL: https://issues.apache.org/jira/browse/HDFS-16575
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: qinyuren
>Priority: Major
> Attachments: image-2022-05-10-11-21-13-627.png,
> image-2022-05-10-11-21-31-987.png
>
>
> # create a file with one block and this block have 3 replication with
> {color:#de350b}DISK{color} type [DISK, DISK, DISK].
> # Set this file with {color:#de350b}ALL_SSD{color} storage policy.
> # The replication of this file may become [DISK, DISK,
> {color:#de350b}SSD{color}, DISK] with {color:#de350b}decommission{color}.
> # Set this file with {color:#de350b}HOT{color} storage policy and satisfy
> storage policy on this file.
> # The replication finally look like [DISK, DISK, SSD] not [DISK, DISK,
> DISK] after decommissioned node offline.
> The reason is that SPS get the block replications by
> FileStatus.getReplication() which is not the real num of the block.
> !image-2022-05-10-11-21-13-627.png|width=432,height=76!
> So this block will be ignored, because it have 3 replications with DISK type
> ( one replication in a decommissioning node)
> !image-2022-05-10-11-21-31-987.png|width=334,height=179!
>
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16575) [SPS]: Should use real replication num instead getReplication from namenode
[ https://issues.apache.org/jira/browse/HDFS-16575?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] qinyuren updated HDFS-16575: Attachment: image-2022-05-10-11-21-31-987.png > [SPS]: Should use real replication num instead getReplication from namenode > --- > > Key: HDFS-16575 > URL: https://issues.apache.org/jira/browse/HDFS-16575 > Project: Hadoop HDFS > Issue Type: Bug >Reporter: qinyuren >Priority: Major > Attachments: image-2022-05-10-11-21-13-627.png, > image-2022-05-10-11-21-31-987.png > > -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16575) [SPS]: Should use real replication num instead getReplication from namenode
[ https://issues.apache.org/jira/browse/HDFS-16575?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] qinyuren updated HDFS-16575: Attachment: image-2022-05-10-11-21-13-627.png > [SPS]: Should use real replication num instead getReplication from namenode > --- > > Key: HDFS-16575 > URL: https://issues.apache.org/jira/browse/HDFS-16575 > Project: Hadoop HDFS > Issue Type: Bug >Reporter: qinyuren >Priority: Major > Attachments: image-2022-05-10-11-21-13-627.png, > image-2022-05-10-11-21-31-987.png > > -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Created] (HDFS-16575) [SPS]: Should use real replication num instead getReplication from namenode
qinyuren created HDFS-16575: --- Summary: [SPS]: Should use real replication num instead getReplication from namenode Key: HDFS-16575 URL: https://issues.apache.org/jira/browse/HDFS-16575 Project: Hadoop HDFS Issue Type: Bug Reporter: qinyuren -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16574) Reduces the time it takes once to hold FSNamesystem write lock to remove blocks associated with dead datanodes
[
https://issues.apache.org/jira/browse/HDFS-16574?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17534089#comment-17534089
]
ZhiWei Shi commented on HDFS-16574:
---
I'm testing it.
> Reduces the time it takes once to hold FSNamesystem write lock to remove
> blocks associated with dead datanodes
> --
>
> Key: HDFS-16574
> URL: https://issues.apache.org/jira/browse/HDFS-16574
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: namenode
>Reporter: ZhiWei Shi
>Assignee: ZhiWei Shi
>Priority: Major
>
> In {{{}BlockManager.{}}}removeBlocksAssociatedTo(final DatanodeStorageInfo
> storageInfo)
> {code:java}
> /** Remove the blocks associated to the given datanode. */
> void removeBlocksAssociatedTo(final DatanodeDescriptor node) {
> providedStorageMap.removeDatanode(node);
> final Iterator it = node.getBlockIterator();
> while(it.hasNext()) {
> removeStoredBlock(it.next(), node);
> }
> // Remove all pending DN messages referencing this DN.
> pendingDNMessages.removeAllMessagesForDatanode(node);
> node.resetBlocks();
> invalidateBlocks.remove(node);
> }
> {code}
> it holds FSNamesystem write lock to remove all blocks associated with a dead
> data node,which can take a lot of time when the datanode has a large number
> of blocks. eg :49.2s for 22.30M blocks,7.9s for 2.84M blocks.
> {code:java}
> # ${ip-1} has 22304612 blocks
> 2022-05-08 13:43:35,864 INFO org.apache.hadoop.net.NetworkTopology: Removing
> a node: /default-rack/${ip-1}:800
> 2022-05-08 13:43:35,864 INFO
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem: FSNamesystem write lock
> held for 49184 ms via
> java.lang.Thread.getStackTrace(Thread.java:1552)
> org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1021)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:263)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:220)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1579)
> org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager.heartbeatCheck(HeartbeatManager.java:409)
> org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager$Monitor.run(HeartbeatManager.java:436)
> java.lang.Thread.run(Thread.java:745)
> Number of suppressed write-lock reports: 0
> Longest write-lock held interval: 49184
> # ${ip-2} has 22304612 blocks
> 2022-05-08 08:11:55,559 INFO org.apache.hadoop.net.NetworkTopology: Removing
> a node: /default-rack/${ip-2}:800
> 2022-05-08 08:11:55,560 INFO
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem: FSNamesystem write lock
> held for 7925 ms via
> java.lang.Thread.getStackTrace(Thread.java:1552)
> org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1021)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:263)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:220)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1579)
> org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager.heartbeatCheck(HeartbeatManager.java:409)
> org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager$Monitor.run(HeartbeatManager.java:436)
> java.lang.Thread.run(Thread.java:745)
> Number of suppressed write-lock reports: 0
> Longest write-lock held interval: 7925{code}
> This whill block all RPC requests that require FSNamesystem lock,and cannot
> process HealthMonitor request from zkfc in time,which eventually leads to
> namenode failover
> {code:java}
> 2022-05-08 13:43:32,279 WARN org.apache.hadoop.ha.HealthMonitor:
> Transport-level exception trying to monitor health of NameNode at
> hd044.corp.yodao.com/10.108.162.60:8000: java.net.SocketTimeoutException:
> 45000 millis timeout while waiting for channel to be ready for read. ch :
> java.nio.channels.SocketChannel[connected local=/10.108.162.60:16861
> remote=hd044.corp.yodao.com/10.108.162.60:8000] Call From
> hd044.corp.yodao.com/10.108.162.60 to hd044.corp.yodao.com:8000 failed on
> socket timeout exception: java.net.SocketTimeoutException: 45000 millis
> timeout while waiting for channel to be ready for read. ch :
> java.nio.channels.SocketChannel[connected local=/10.108.162.60:16861
> remote=hd044.corp.yodao.com/10.108.162.60:8000]; For more details see:
> http://wiki.apache.org/hadoop/SocketTimeout
> 2022-05-08 13:43:32,283 INFO org.apache.hadoop.ha.HealthMonitor: Entering
> state SERVICE_NOT_RESPONDING
> 2022-05-08 13:43:32,283 INFO org.apache.hadoop.ha.ZKFailoverController: Local
> service NameNode at
[jira] [Updated] (HDFS-16574) Reduces the time it takes once to hold FSNamesystem write lock to remove blocks associated with dead datanodes
[
https://issues.apache.org/jira/browse/HDFS-16574?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ZhiWei Shi updated HDFS-16574:
--
Description:
In {{{}BlockManager.{}}}removeBlocksAssociatedTo(final DatanodeStorageInfo
storageInfo)
{code:java}
/** Remove the blocks associated to the given datanode. */
void removeBlocksAssociatedTo(final DatanodeDescriptor node) {
providedStorageMap.removeDatanode(node);
final Iterator it = node.getBlockIterator();
while(it.hasNext()) {
removeStoredBlock(it.next(), node);
}
// Remove all pending DN messages referencing this DN.
pendingDNMessages.removeAllMessagesForDatanode(node);
node.resetBlocks();
invalidateBlocks.remove(node);
}
{code}
it holds FSNamesystem write lock to remove all blocks associated with a dead
data node,which can take a lot of time when the datanode has a large number of
blocks. eg :49.2s for 22.30M blocks,7.9s for 2.84M blocks.
{code:java}
# ${ip-1} has 22304612 blocks
2022-05-08 13:43:35,864 INFO org.apache.hadoop.net.NetworkTopology: Removing a
node: /default-rack/${ip-1}:800
2022-05-08 13:43:35,864 INFO
org.apache.hadoop.hdfs.server.namenode.FSNamesystem: FSNamesystem write lock
held for 49184 ms via
java.lang.Thread.getStackTrace(Thread.java:1552)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1021)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:263)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:220)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1579)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager.heartbeatCheck(HeartbeatManager.java:409)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager$Monitor.run(HeartbeatManager.java:436)
java.lang.Thread.run(Thread.java:745)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 49184
# ${ip-2} has 22304612 blocks
2022-05-08 08:11:55,559 INFO org.apache.hadoop.net.NetworkTopology: Removing a
node: /default-rack/${ip-2}:800
2022-05-08 08:11:55,560 INFO
org.apache.hadoop.hdfs.server.namenode.FSNamesystem: FSNamesystem write lock
held for 7925 ms via
java.lang.Thread.getStackTrace(Thread.java:1552)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1021)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:263)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:220)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1579)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager.heartbeatCheck(HeartbeatManager.java:409)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager$Monitor.run(HeartbeatManager.java:436)
java.lang.Thread.run(Thread.java:745)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 7925{code}
This whill block all RPC requests that require FSNamesystem lock,and cannot
process HealthMonitor request from zkfc in time,which eventually leads to
namenode failover
{code:java}
2022-05-08 13:43:32,279 WARN org.apache.hadoop.ha.HealthMonitor:
Transport-level exception trying to monitor health of NameNode at
hd044.corp.yodao.com/10.108.162.60:8000: java.net.SocketTimeoutException: 45000
millis timeout while waiting for channel to be ready for read. ch :
java.nio.channels.SocketChannel[connected local=/10.108.162.60:16861
remote=hd044.corp.yodao.com/10.108.162.60:8000] Call From
hd044.corp.yodao.com/10.108.162.60 to hd044.corp.yodao.com:8000 failed on
socket timeout exception: java.net.SocketTimeoutException: 45000 millis timeout
while waiting for channel to be ready for read. ch :
java.nio.channels.SocketChannel[connected local=/10.108.162.60:16861
remote=hd044.corp.yodao.com/10.108.162.60:8000]; For more details see:
http://wiki.apache.org/hadoop/SocketTimeout
2022-05-08 13:43:32,283 INFO org.apache.hadoop.ha.HealthMonitor: Entering state
SERVICE_NOT_RESPONDING
2022-05-08 13:43:32,283 INFO org.apache.hadoop.ha.ZKFailoverController: Local
service NameNode at hd044.corp.yodao.com/10.108.162.60:8000 entered state:
SERVICE_NOT_RESPONDING
2022-05-08 13:43:32,922 INFO
org.apache.hadoop.hdfs.tools.DFSZKFailoverController: -- Local NN thread dump --
Process Thread Dump:
..
Thread 100 (IPC Server handler 0 on 8000):
State: WAITING
Blocked count: 14895292
Waited count: 210385351
Waiting on java.util.concurrent.locks.ReentrantReadWriteLock$FairSync@5723ab57
Stack:
sun.misc.Unsafe.park(Native Method)
java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
[jira] [Updated] (HDFS-16574) Reduces the time it takes once to hold FSNamesystem write lock to remove blocks associated with dead datanodes
[
https://issues.apache.org/jira/browse/HDFS-16574?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ZhiWei Shi updated HDFS-16574:
--
Summary: Reduces the time it takes once to hold FSNamesystem write lock to
remove blocks associated with dead datanodes (was: Reduces the time it takes
once to hold FSNamesystem write lock to remove blocks associated with dead data
nodes)
> Reduces the time it takes once to hold FSNamesystem write lock to remove
> blocks associated with dead datanodes
> --
>
> Key: HDFS-16574
> URL: https://issues.apache.org/jira/browse/HDFS-16574
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: namenode
>Reporter: ZhiWei Shi
>Assignee: ZhiWei Shi
>Priority: Major
>
> In {{{}BlockManager.{}}}removeBlocksAssociatedTo(final DatanodeStorageInfo
> storageInfo)
> {code:java}
> /** Remove the blocks associated to the given datanode. */
> void removeBlocksAssociatedTo(final DatanodeDescriptor node) {
> providedStorageMap.removeDatanode(node);
> final Iterator it = node.getBlockIterator();
> while(it.hasNext()) {
> removeStoredBlock(it.next(), node);
> }
> // Remove all pending DN messages referencing this DN.
> pendingDNMessages.removeAllMessagesForDatanode(node);
> node.resetBlocks();
> invalidateBlocks.remove(node);
> }
> {code}
> it holds FSNamesystem write lock to remove all blocks associated with a dead
> data node,which can take a lot of time when the datanode has a large number
> of blocks. eg :49.2s for 22.30M blocks,7.9s for 2.84M blocks.
> {code:java}
> # ${ip-1} has 22304612 blocks
> 2022-05-08 13:43:35,864 INFO org.apache.hadoop.net.NetworkTopology: Removing
> a node: /default-rack/${ip-1}:800
> 2022-05-08 13:43:35,864 INFO
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem: FSNamesystem write lock
> held for 49184 ms via
> java.lang.Thread.getStackTrace(Thread.java:1552)
> org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1021)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:263)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:220)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1579)
> org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager.heartbeatCheck(HeartbeatManager.java:409)
> org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager$Monitor.run(HeartbeatManager.java:436)
> java.lang.Thread.run(Thread.java:745)
> Number of suppressed write-lock reports: 0
> Longest write-lock held interval: 49184
> # ${ip-2} has 22304612 blocks
> 2022-05-08 08:11:55,559 INFO org.apache.hadoop.net.NetworkTopology: Removing
> a node: /default-rack/${ip-2}:800
> 2022-05-08 08:11:55,560 INFO
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem: FSNamesystem write lock
> held for 7925 ms via
> java.lang.Thread.getStackTrace(Thread.java:1552)
> org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1021)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:263)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:220)
> org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1579)
> org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager.heartbeatCheck(HeartbeatManager.java:409)
> org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager$Monitor.run(HeartbeatManager.java:436)
> java.lang.Thread.run(Thread.java:745)
> Number of suppressed write-lock reports: 0
> Longest write-lock held interval: 7925{code}
> This whill block all RPC requests that require FSNamesystem lock,and cannot
> process HealthMonitor request from zkfc in time,which eventually leads to
> namenode failover
> {code:java}
> 2022-05-08 13:43:32,279 WARN org.apache.hadoop.ha.HealthMonitor:
> Transport-level exception trying to monitor health of NameNode at
> hd044.corp.yodao.com/10.108.162.60:8000: java.net.SocketTimeoutException:
> 45000 millis timeout while waiting for channel to be ready for read. ch :
> java.nio.channels.SocketChannel[connected local=/10.108.162.60:16861
> remote=hd044.corp.yodao.com/10.108.162.60:8000] Call From
> hd044.corp.yodao.com/10.108.162.60 to hd044.corp.yodao.com:8000 failed on
> socket timeout exception: java.net.SocketTimeoutException: 45000 millis
> timeout while waiting for channel to be ready for read. ch :
> java.nio.channels.SocketChannel[connected local=/10.108.162.60:16861
> remote=hd044.corp.yodao.com/10.108.162.60:8000]; For more details see:
> http://wiki.apache.org/hadoop/SocketTimeout
> 2022-05-08 13:43:32,283 INFO
[jira] [Work logged] (HDFS-16568) dfsadmin -reconfig option to start/query reconfig on all live datanodes
[ https://issues.apache.org/jira/browse/HDFS-16568?focusedWorklogId=768249=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-768249 ] ASF GitHub Bot logged work on HDFS-16568: - Author: ASF GitHub Bot Created on: 10/May/22 00:21 Start Date: 10/May/22 00:21 Worklog Time Spent: 10m Work Description: tomscut commented on PR #4264: URL: https://github.com/apache/hadoop/pull/4264#issuecomment-1121708660 @cndaimin fixed the failed unit test on HDFS-16573. I retriggered the jenkins. Issue Time Tracking --- Worklog Id: (was: 768249) Time Spent: 4h 10m (was: 4h) > dfsadmin -reconfig option to start/query reconfig on all live datanodes > --- > > Key: HDFS-16568 > URL: https://issues.apache.org/jira/browse/HDFS-16568 > Project: Hadoop HDFS > Issue Type: New Feature >Reporter: Viraj Jasani >Assignee: Viraj Jasani >Priority: Major > Labels: pull-request-available > Time Spent: 4h 10m > Remaining Estimate: 0h > > DFSAdmin provides option to initiate or query the status of reconfiguration > operation on only specific host based on host:port provided by user. It would > be good to provide an ability to initiate such operations in bulk, on all > live datanodes. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16573) Fix test TestDFSStripedInputStreamWithRandomECPolicy
[ https://issues.apache.org/jira/browse/HDFS-16573?focusedWorklogId=768242=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-768242 ] ASF GitHub Bot logged work on HDFS-16573: - Author: ASF GitHub Bot Created on: 10/May/22 00:13 Start Date: 10/May/22 00:13 Worklog Time Spent: 10m Work Description: tomscut commented on PR #4291: URL: https://github.com/apache/hadoop/pull/4291#issuecomment-1121704096 Hi @cndaimin , could you please cherry-pick this to branch-3.3. Thanks. Issue Time Tracking --- Worklog Id: (was: 768242) Time Spent: 1h (was: 50m) > Fix test TestDFSStripedInputStreamWithRandomECPolicy > > > Key: HDFS-16573 > URL: https://issues.apache.org/jira/browse/HDFS-16573 > Project: Hadoop HDFS > Issue Type: Test > Components: test >Affects Versions: 3.3.2 >Reporter: daimin >Assignee: daimin >Priority: Minor > Labels: pull-request-available > Fix For: 3.4.0 > > Time Spent: 1h > Remaining Estimate: 0h > > TestDFSStripedInputStreamWithRandomECPolicy fails due to test from HDFS-16520 -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16573) Fix test TestDFSStripedInputStreamWithRandomECPolicy
[ https://issues.apache.org/jira/browse/HDFS-16573?focusedWorklogId=768238=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-768238 ] ASF GitHub Bot logged work on HDFS-16573: - Author: ASF GitHub Bot Created on: 10/May/22 00:02 Start Date: 10/May/22 00:02 Worklog Time Spent: 10m Work Description: tomscut commented on PR #4291: URL: https://github.com/apache/hadoop/pull/4291#issuecomment-1121698181 Thanks @cndaimin for fixing this. Issue Time Tracking --- Worklog Id: (was: 768238) Time Spent: 50m (was: 40m) > Fix test TestDFSStripedInputStreamWithRandomECPolicy > > > Key: HDFS-16573 > URL: https://issues.apache.org/jira/browse/HDFS-16573 > Project: Hadoop HDFS > Issue Type: Test > Components: test >Affects Versions: 3.3.2 >Reporter: daimin >Assignee: daimin >Priority: Minor > Labels: pull-request-available > Fix For: 3.4.0 > > Time Spent: 50m > Remaining Estimate: 0h > > TestDFSStripedInputStreamWithRandomECPolicy fails due to test from HDFS-16520 -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDFS-16573) Fix test TestDFSStripedInputStreamWithRandomECPolicy
[ https://issues.apache.org/jira/browse/HDFS-16573?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Tao Li resolved HDFS-16573. --- Fix Version/s: 3.4.0 Resolution: Resolved > Fix test TestDFSStripedInputStreamWithRandomECPolicy > > > Key: HDFS-16573 > URL: https://issues.apache.org/jira/browse/HDFS-16573 > Project: Hadoop HDFS > Issue Type: Test > Components: test >Affects Versions: 3.3.2 >Reporter: daimin >Assignee: daimin >Priority: Minor > Labels: pull-request-available > Fix For: 3.4.0 > > Time Spent: 40m > Remaining Estimate: 0h > > TestDFSStripedInputStreamWithRandomECPolicy fails due to test from HDFS-16520 -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16573) Fix test TestDFSStripedInputStreamWithRandomECPolicy
[ https://issues.apache.org/jira/browse/HDFS-16573?focusedWorklogId=768237=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-768237 ] ASF GitHub Bot logged work on HDFS-16573: - Author: ASF GitHub Bot Created on: 10/May/22 00:01 Start Date: 10/May/22 00:01 Worklog Time Spent: 10m Work Description: tomscut merged PR #4291: URL: https://github.com/apache/hadoop/pull/4291 Issue Time Tracking --- Worklog Id: (was: 768237) Time Spent: 40m (was: 0.5h) > Fix test TestDFSStripedInputStreamWithRandomECPolicy > > > Key: HDFS-16573 > URL: https://issues.apache.org/jira/browse/HDFS-16573 > Project: Hadoop HDFS > Issue Type: Test > Components: test >Affects Versions: 3.3.2 >Reporter: daimin >Assignee: daimin >Priority: Minor > Labels: pull-request-available > Time Spent: 40m > Remaining Estimate: 0h > > TestDFSStripedInputStreamWithRandomECPolicy fails due to test from HDFS-16520 -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16570) RBF: The router using MultipleDestinationMountTableResolver remove Multiple subcluster data under the mount point failed
[
https://issues.apache.org/jira/browse/HDFS-16570?focusedWorklogId=768158=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-768158
]
ASF GitHub Bot logged work on HDFS-16570:
-
Author: ASF GitHub Bot
Created on: 09/May/22 20:05
Start Date: 09/May/22 20:05
Worklog Time Spent: 10m
Work Description: ayushtkn commented on PR #4269:
URL: https://github.com/apache/hadoop/pull/4269#issuecomment-1121524023
Thanx @zhangxiping1 I wasn't aware of HDFS-16024. @goiri / @ferhui would
have better idea about this change.
BTW. I am still amazed did we allow router to access paths not configured as
part of mount points, that seems to break the contract that router should talk
via mount table only. I need to explore this bit a more
Issue Time Tracking
---
Worklog Id: (was: 768158)
Time Spent: 50m (was: 40m)
> RBF: The router using MultipleDestinationMountTableResolver remove Multiple
> subcluster data under the mount point failed
>
>
> Key: HDFS-16570
> URL: https://issues.apache.org/jira/browse/HDFS-16570
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: rbf
>Reporter: Xiping Zhang
>Priority: Major
> Labels: pull-request-available
> Time Spent: 50m
> Remaining Estimate: 0h
>
> Please look at the following example :
> hadoop>{color:#FF}hdfs dfsrouteradmin -add /home/data ns0,ns1 /home/data
> -order RANDOM{color}
> Successfully removed mount point /home/data
> hadoop>{color:#FF}hdfs dfsrouteradmin -ls{color}
> Mount Table Entries:
> Source Destinations Owner
> Group Mode Quota/Usage
> /home/data ns0->/home/data,ns1->/home/data zhangxiping
> Administrators rwxr-xr-x [NsQuota: -/-, SsQuota: -/-]
> hadoop>{color:#FF}hdfs dfs -touch
> hdfs://ns0/home/data/test/fileNs0.txt{color}
> hadoop>{color:#FF}hdfs dfs -touch
> hdfs://ns1/home/data/test/fileNs1.txt{color}
> hadoop>{color:#FF}hdfs dfs -ls
> hdfs://ns0/home/data/test/fileNs0.txt{color}
> {-}rw-r{-}{-}r{-}- 3 zhangxiping supergroup 0 2022-05-06 18:01
> hdfs://ns0/home/data/test/fileNs0.txt
> hadoop>{color:#FF}hdfs dfs -ls
> hdfs://ns1/home/data/test/fileNs1.txt{color}
> {-}rw-r{-}{-}r{-}- 3 zhangxiping supergroup 0 2022-05-06 18:01
> hdfs://ns1/home/data/test/fileNs1.txt
> hadoop>{color:#FF}hdfs dfs -ls
> hdfs://127.0.0.1:40250/home/data/test{color}
> Found 2 items
> {-}rw-r{-}{-}r{-}- 3 zhangxiping supergroup 0 2022-05-06 18:01
> hdfs://127.0.0.1:40250/home/data/test/fileNs0.txt
> {-}rw-r{-}{-}r{-}- 3 zhangxiping supergroup 0 2022-05-06 18:01
> hdfs://127.0.0.1:40250/home/data/test/fileNs1.txt
> hadoop>{color:#FF}hdfs dfs -rm -r
> hdfs://127.0.0.1:40250/home/data/test{color}
> rm: Failed to move to trash: hdfs://127.0.0.1:40250/home/data/test: rename
> destination parent /user/zhangxiping/.Trash/Current/home/data/test not found.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16465) Remove redundant strings.h inclusions
[
https://issues.apache.org/jira/browse/HDFS-16465?focusedWorklogId=768138=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-768138
]
ASF GitHub Bot logged work on HDFS-16465:
-
Author: ASF GitHub Bot
Created on: 09/May/22 19:45
Start Date: 09/May/22 19:45
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on PR #4279:
URL: https://github.com/apache/hadoop/pull/4279#issuecomment-1121506763
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 55s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 0s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 1 new or modified test files. |
_ trunk Compile Tests _ |
| -1 :x: | mvninstall | 7m 49s |
[/branch-mvninstall-root.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4279/2/artifact/out/branch-mvninstall-root.txt)
| root in trunk failed. |
| -1 :x: | compile | 0m 30s |
[/branch-compile-hadoop-hdfs-project_hadoop-hdfs-native-client.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4279/2/artifact/out/branch-compile-hadoop-hdfs-project_hadoop-hdfs-native-client.txt)
| hadoop-hdfs-native-client in trunk failed. |
| +1 :green_heart: | mvnsite | 0m 57s | | trunk passed |
| +1 :green_heart: | shadedclient | 33m 28s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 0m 24s | | the patch passed |
| +1 :green_heart: | compile | 3m 43s | | the patch passed |
| -1 :x: | cc | 3m 43s |
[/results-compile-cc-hadoop-hdfs-project_hadoop-hdfs-native-client.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4279/2/artifact/out/results-compile-cc-hadoop-hdfs-project_hadoop-hdfs-native-client.txt)
| hadoop-hdfs-project_hadoop-hdfs-native-client generated 8 new + 0 unchanged
- 0 fixed = 8 total (was 0) |
| +1 :green_heart: | golang | 3m 43s | | the patch passed |
| +1 :green_heart: | javac | 3m 43s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | mvnsite | 0m 27s | | the patch passed |
| +1 :green_heart: | shadedclient | 18m 39s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 32m 48s | | hadoop-hdfs-native-client in
the patch passed. |
| +1 :green_heart: | asflicense | 0m 52s | | The patch does not
generate ASF License warnings. |
| | | 94m 8s | | |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4279/2/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/4279 |
| Optional Tests | dupname asflicense compile cc mvnsite javac unit
codespell golang |
| uname | Linux 9fa670c9ac6e 4.15.0-112-generic #113-Ubuntu SMP Thu Jul 9
23:41:39 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / de69ef6ea83dfe8a9ac5199e5722c2026c1470cc |
| Default Java | Red Hat, Inc.-1.8.0_322-b06 |
| Test Results |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4279/2/testReport/ |
| Max. process+thread count | 549 (vs. ulimit of 5500) |
| modules | C: hadoop-hdfs-project/hadoop-hdfs-native-client U:
hadoop-hdfs-project/hadoop-hdfs-native-client |
| Console output |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4279/2/console |
| versions | git=2.9.5 maven=3.6.3 |
| Powered by | Apache Yetus 0.14.0-SNAPSHOT https://yetus.apache.org |
This message was automatically generated.
Issue Time Tracking
---
Worklog Id: (was: 768138)
Time Spent: 1h 20m (was: 1h 10m)
> Remove redundant strings.h inclusions
> -
>
> Key: HDFS-16465
> URL: https://issues.apache.org/jira/browse/HDFS-16465
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: libhdfs++
>Affects Versions: 3.4.0
> Environment: Windows 10
>Reporter: Gautham Banasandra
>Assignee: Gautham Banasandra
>Priority: Major
> Labels:
[jira] [Work logged] (HDFS-16561) Handle error returned by strtol
[ https://issues.apache.org/jira/browse/HDFS-16561?focusedWorklogId=768066=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-768066 ] ASF GitHub Bot logged work on HDFS-16561: - Author: ASF GitHub Bot Created on: 09/May/22 17:48 Start Date: 09/May/22 17:48 Worklog Time Spent: 10m Work Description: GauthamBanasandra commented on PR #4287: URL: https://github.com/apache/hadoop/pull/4287#issuecomment-1121397514 Hi @rishabh1704, Thanks for your contribution to Hadoop. Could you please fix the issue reported by the CI? Issue Time Tracking --- Worklog Id: (was: 768066) Time Spent: 0.5h (was: 20m) > Handle error returned by strtol > --- > > Key: HDFS-16561 > URL: https://issues.apache.org/jira/browse/HDFS-16561 > Project: Hadoop HDFS > Issue Type: Bug > Components: libhdfs++ >Affects Versions: 3.4.0 >Reporter: Gautham Banasandra >Assignee: Gautham Banasandra >Priority: Major > Labels: pull-request-available > Time Spent: 0.5h > Remaining Estimate: 0h > > *strtol* is used in > [hdfs-chmod.cc|https://github.com/apache/hadoop/blob/6dddbd42edd57cc26279c678756386a47c040af5/hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfspp/tools/hdfs-chmod/hdfs-chmod.cc#L144]. > The call to strtol could error out when an invalid input is provided. Need > to handle the error given out by strtol. > Tasks to do - > 1. Detect the error returned by strtol. The [strtol documentation > |https://en.cppreference.com/w/cpp/string/byte/strtol]explains how to do so. > 2. Return false to the caller if the error is detected. > 3. Extend > [this|https://github.com/apache/hadoop/blob/6dddbd42edd57cc26279c678756386a47c040af5/hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfspp/tests/tools/hdfs-chmod-mock.cc] > unit test and add a case which exercises this by passing an invalid input. > Please refer to this PR to get more context on how this unit test is written > - https://github.com/apache/hadoop/pull/3588. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16574) Reduces the time it takes once to hold FSNamesystem write lock to remove blocks associated with dead data nodes
[
https://issues.apache.org/jira/browse/HDFS-16574?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ZhiWei Shi updated HDFS-16574:
--
Description:
In {{{}BlockManager.{}}}removeBlocksAssociatedTo(final DatanodeStorageInfo
storageInfo)
{code:java}
/** Remove the blocks associated to the given datanode. */
void removeBlocksAssociatedTo(final DatanodeDescriptor node) {
providedStorageMap.removeDatanode(node);
final Iterator it = node.getBlockIterator();
while(it.hasNext()) {
removeStoredBlock(it.next(), node);
}
// Remove all pending DN messages referencing this DN.
pendingDNMessages.removeAllMessagesForDatanode(node);
node.resetBlocks();
invalidateBlocks.remove(node);
}
{code}
it holds FSNamesystem write lock to remove all blocks associated with a dead
data node,which can take a lot of time when the datanode has a large number of
blocks. eg :49.2s for 22.30M blocks,7.9s for 2.84M blocks.
{code:java}
# ${ip-1} has 22304612 blocks
2022-05-08 13:43:35,864 INFO org.apache.hadoop.net.NetworkTopology: Removing a
node: /default-rack/${ip-1}:800
2022-05-08 13:43:35,864 INFO
org.apache.hadoop.hdfs.server.namenode.FSNamesystem: FSNamesystem write lock
held for 49184 ms via
java.lang.Thread.getStackTrace(Thread.java:1552)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1021)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:263)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:220)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1579)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager.heartbeatCheck(HeartbeatManager.java:409)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager$Monitor.run(HeartbeatManager.java:436)
java.lang.Thread.run(Thread.java:745)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 49184
# ${ip-2} has 22304612 blocks
2022-05-08 08:11:55,559 INFO org.apache.hadoop.net.NetworkTopology: Removing a
node: /default-rack/${ip-2}:800
2022-05-08 08:11:55,560 INFO
org.apache.hadoop.hdfs.server.namenode.FSNamesystem: FSNamesystem write lock
held for 7925 ms via
java.lang.Thread.getStackTrace(Thread.java:1552)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1021)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:263)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:220)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1579)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager.heartbeatCheck(HeartbeatManager.java:409)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager$Monitor.run(HeartbeatManager.java:436)
java.lang.Thread.run(Thread.java:745)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 7925{code}
This whill block all RPC requests that require FSNamesystem lock,and cannot
process HealthMonitor request from zkfc in time,which eventually leads to
namenode failover
{code:java}
2022-05-08 13:43:32,279 WARN org.apache.hadoop.ha.HealthMonitor:
Transport-level exception trying to monitor health of NameNode at
hd044.corp.yodao.com/10.108.162.60:8000: java.net.SocketTimeoutException: 45000
millis timeout while waiting for channel to be ready for read. ch :
java.nio.channels.SocketChannel[connected local=/10.108.162.60:16861
remote=hd044.corp.yodao.com/10.108.162.60:8000] Call From
hd044.corp.yodao.com/10.108.162.60 to hd044.corp.yodao.com:8000 failed on
socket timeout exception: java.net.SocketTimeoutException: 45000 millis timeout
while waiting for channel to be ready for read. ch :
java.nio.channels.SocketChannel[connected local=/10.108.162.60:16861
remote=hd044.corp.yodao.com/10.108.162.60:8000]; For more details see:
http://wiki.apache.org/hadoop/SocketTimeout
2022-05-08 13:43:32,283 INFO org.apache.hadoop.ha.HealthMonitor: Entering state
SERVICE_NOT_RESPONDING
2022-05-08 13:43:32,283 INFO org.apache.hadoop.ha.ZKFailoverController: Local
service NameNode at hd044.corp.yodao.com/10.108.162.60:8000 entered state:
SERVICE_NOT_RESPONDING
2022-05-08 13:43:32,922 INFO
org.apache.hadoop.hdfs.tools.DFSZKFailoverController: -- Local NN thread dump --
Process Thread Dump:
..
Thread 100 (IPC Server handler 0 on 8000):
State: WAITING
Blocked count: 14895292
Waited count: 210385351
Waiting on java.util.concurrent.locks.ReentrantReadWriteLock$FairSync@5723ab57
Stack:
sun.misc.Unsafe.park(Native Method)
java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
[jira] [Updated] (HDFS-16574) Reduces the time it takes once to hold FSNamesystem write lock to remove blocks associated with dead data nodes
[
https://issues.apache.org/jira/browse/HDFS-16574?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ZhiWei Shi updated HDFS-16574:
--
Description:
In {{{}BlockManager.{}}}removeBlocksAssociatedTo(final DatanodeStorageInfo
storageInfo)
{code:java}
/** Remove the blocks associated to the given datanode. */
void removeBlocksAssociatedTo(final DatanodeDescriptor node) {
providedStorageMap.removeDatanode(node);
final Iterator it = node.getBlockIterator();
while(it.hasNext()) {
removeStoredBlock(it.next(), node);
}
// Remove all pending DN messages referencing this DN.
pendingDNMessages.removeAllMessagesForDatanode(node);
node.resetBlocks();
invalidateBlocks.remove(node);
}
{code}
it holds FSNamesystem write lock to remove all blocks associated with a dead
data node,which can take a lot of time when the datanode has a large number of
blocks. eg :49.2s for 22.30M blocks,7.9s for 2.84M blocks.
{code:java}
# ${ip-1} has 22304612 blocks
2022-05-08 13:43:35,864 INFO org.apache.hadoop.net.NetworkTopology: Removing a
node: /default-rack/${ip-1}:800
2022-05-08 13:43:35,864 INFO
org.apache.hadoop.hdfs.server.namenode.FSNamesystem: FSNamesystem write lock
held for 49184 ms via
java.lang.Thread.getStackTrace(Thread.java:1552)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1021)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:263)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:220)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1579)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager.heartbeatCheck(HeartbeatManager.java:409)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager$Monitor.run(HeartbeatManager.java:436)
java.lang.Thread.run(Thread.java:745)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 49184
# ${ip-2} has 22304612 blocks
2022-05-08 08:11:55,559 INFO org.apache.hadoop.net.NetworkTopology: Removing a
node: /default-rack/${ip-2}:800
2022-05-08 08:11:55,560 INFO
org.apache.hadoop.hdfs.server.namenode.FSNamesystem: FSNamesystem write lock
held for 7925 ms via
java.lang.Thread.getStackTrace(Thread.java:1552)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1021)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:263)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:220)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1579)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager.heartbeatCheck(HeartbeatManager.java:409)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager$Monitor.run(HeartbeatManager.java:436)
java.lang.Thread.run(Thread.java:745)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 7925{code}
This whill block all RPC requests that require FSNamesystem lock,and cannot
process health check requests in time,which eventually leads to namenode
failover
{code:java}
2022-05-08 13:43:32,279 WARN org.apache.hadoop.ha.HealthMonitor:
Transport-level exception trying to monitor health of NameNode at
hd044.corp.yodao.com/10.108.162.60:8000: java.net.SocketTimeoutException: 45000
millis timeout while waiting for channel to be ready for read. ch :
java.nio.channels.SocketChannel[connected local=/10.108.162.60:16861
remote=hd044.corp.yodao.com/10.108.162.60:8000] Call From
hd044.corp.yodao.com/10.108.162.60 to hd044.corp.yodao.com:8000 failed on
socket timeout exception: java.net.SocketTimeoutException: 45000 millis timeout
while waiting for channel to be ready for read. ch :
java.nio.channels.SocketChannel[connected local=/10.108.162.60:16861
remote=hd044.corp.yodao.com/10.108.162.60:8000]; For more details see:
http://wiki.apache.org/hadoop/SocketTimeout
2022-05-08 13:43:32,283 INFO org.apache.hadoop.ha.HealthMonitor: Entering state
SERVICE_NOT_RESPONDING
2022-05-08 13:43:32,283 INFO org.apache.hadoop.ha.ZKFailoverController: Local
service NameNode at hd044.corp.yodao.com/10.108.162.60:8000 entered state:
SERVICE_NOT_RESPONDING
2022-05-08 13:43:32,922 INFO
org.apache.hadoop.hdfs.tools.DFSZKFailoverController: -- Local NN thread dump --
Process Thread Dump:
..
Thread 100 (IPC Server handler 0 on 8000):
State: WAITING
Blocked count: 14895292
Waited count: 210385351
Waiting on java.util.concurrent.locks.ReentrantReadWriteLock$FairSync@5723ab57
Stack:
sun.misc.Unsafe.park(Native Method)
java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:836)
java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireShared(AbstractQueuedSynchronizer.java:967)
[jira] [Created] (HDFS-16574) Reduces the time it takes once to hold FSNamesystem write lock to remove blocks associated with dead data nodes
ZhiWei Shi created HDFS-16574:
-
Summary: Reduces the time it takes once to hold FSNamesystem write
lock to remove blocks associated with dead data nodes
Key: HDFS-16574
URL: https://issues.apache.org/jira/browse/HDFS-16574
Project: Hadoop HDFS
Issue Type: Improvement
Components: namenode
Reporter: ZhiWei Shi
Assignee: ZhiWei Shi
In {{{}BlockManager.{}}}removeBlocksAssociatedTo(final DatanodeStorageInfo
storageInfo)
{code:java}
/** Remove the blocks associated to the given datanode. */
void removeBlocksAssociatedTo(final DatanodeDescriptor node) {
providedStorageMap.removeDatanode(node);
final Iterator it = node.getBlockIterator();
while(it.hasNext()) {
removeStoredBlock(it.next(), node);
}
// Remove all pending DN messages referencing this DN.
pendingDNMessages.removeAllMessagesForDatanode(node);
node.resetBlocks();
invalidateBlocks.remove(node);
}
{code}
it holds FSNamesystem write lock to remove all blocks associated with a dead
data node,which can take a lot of time when the datanode has a large number of
blocks. eg :49.2s for 22.30M blocks,7.9s for 2.84M blocks.
{code:java}
# ${ip-1} has 22304612 blocks
2022-05-08 13:43:35,864 INFO org.apache.hadoop.net.NetworkTopology: Removing a
node: /default-rack/${ip-1}:800
2022-05-08 13:43:35,864 INFO
org.apache.hadoop.hdfs.server.namenode.FSNamesystem: FSNamesystem write lock
held for 49184 ms via
java.lang.Thread.getStackTrace(Thread.java:1552)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1021)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:263)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:220)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1579)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager.heartbeatCheck(HeartbeatManager.java:409)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager$Monitor.run(HeartbeatManager.java:436)
java.lang.Thread.run(Thread.java:745)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 49184
# ${ip-2} has 22304612 blocks
2022-05-08 08:11:55,559 INFO org.apache.hadoop.net.NetworkTopology: Removing a
node: /default-rack/${ip-2}:800
2022-05-08 08:11:55,560 INFO
org.apache.hadoop.hdfs.server.namenode.FSNamesystem: FSNamesystem write lock
held for 7925 ms via
java.lang.Thread.getStackTrace(Thread.java:1552)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:1021)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:263)
org.apache.hadoop.hdfs.server.namenode.FSNamesystemLock.writeUnlock(FSNamesystemLock.java:220)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1579)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager.heartbeatCheck(HeartbeatManager.java:409)
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager$Monitor.run(HeartbeatManager.java:436)
java.lang.Thread.run(Thread.java:745)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 7925{code}
This whill block all RPC requests that require FSNamesystem lock,and cannot
process health check requests in time,which eventually leads to namenode
failover
{code:java}
2022-05-08 13:43:32,279 WARN org.apache.hadoop.ha.HealthMonitor:
Transport-level exception trying to monitor health of NameNode at
hd044.corp.yodao.com/10.108.162.60:8000: java.net.SocketTimeoutException: 45000
millis timeout while waiting for channel to be ready for read. ch :
java.nio.channels.SocketChannel[connected local=/10.108.162.60:16861
remote=hd044.corp.yodao.com/10.108.162.60:8000] Call From
hd044.corp.yodao.com/10.108.162.60 to hd044.corp.yodao.com:8000 failed on
socket timeout exception: java.net.SocketTimeoutException: 45000 millis timeout
while waiting for channel to be ready for read. ch :
java.nio.channels.SocketChannel[connected local=/10.108.162.60:16861
remote=hd044.corp.yodao.com/10.108.162.60:8000]; For more details see:
http://wiki.apache.org/hadoop/SocketTimeout
2022-05-08 13:43:32,283 INFO org.apache.hadoop.ha.HealthMonitor: Entering state
SERVICE_NOT_RESPONDING
2022-05-08 13:43:32,283 INFO org.apache.hadoop.ha.ZKFailoverController: Local
service NameNode at hd044.corp.yodao.com/10.108.162.60:8000 entered state:
SERVICE_NOT_RESPONDING
2022-05-08 13:43:32,922 INFO
org.apache.hadoop.hdfs.tools.DFSZKFailoverController: -- Local NN thread dump --
Process Thread Dump:
..
Thread 100 (IPC Server handler 0 on 8000):
State: WAITING
Blocked count: 14895292
Waited count: 210385351
Waiting on java.util.concurrent.locks.ReentrantReadWriteLock$FairSync@5723ab57
Stack:
sun.misc.Unsafe.park(Native Method)
[jira] [Work logged] (HDFS-16573) Fix test TestDFSStripedInputStreamWithRandomECPolicy
[
https://issues.apache.org/jira/browse/HDFS-16573?focusedWorklogId=767997=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-767997
]
ASF GitHub Bot logged work on HDFS-16573:
-
Author: ASF GitHub Bot
Created on: 09/May/22 16:21
Start Date: 09/May/22 16:21
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on PR #4291:
URL: https://github.com/apache/hadoop/pull/4291#issuecomment-1121311156
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 48s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 1s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 1 new or modified test files. |
_ trunk Compile Tests _ |
| +1 :green_heart: | mvninstall | 41m 27s | | trunk passed |
| +1 :green_heart: | compile | 1m 41s | | trunk passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | compile | 1m 29s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 1m 19s | | trunk passed |
| +1 :green_heart: | mvnsite | 1m 41s | | trunk passed |
| +1 :green_heart: | javadoc | 1m 18s | | trunk passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javadoc | 1m 40s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 3m 47s | | trunk passed |
| +1 :green_heart: | shadedclient | 26m 1s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 1m 23s | | the patch passed |
| +1 :green_heart: | compile | 1m 30s | | the patch passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javac | 1m 30s | | the patch passed |
| +1 :green_heart: | compile | 1m 21s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 1m 21s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 1m 0s | | the patch passed |
| +1 :green_heart: | mvnsite | 1m 27s | | the patch passed |
| +1 :green_heart: | javadoc | 1m 0s | | the patch passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javadoc | 1m 31s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 3m 34s | | the patch passed |
| +1 :green_heart: | shadedclient | 25m 33s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| -1 :x: | unit | 260m 15s |
[/patch-unit-hadoop-hdfs-project_hadoop-hdfs.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4291/1/artifact/out/patch-unit-hadoop-hdfs-project_hadoop-hdfs.txt)
| hadoop-hdfs in the patch passed. |
| +0 :ok: | asflicense | 0m 51s | | ASF License check generated no
output? |
| | | 377m 48s | | |
| Reason | Tests |
|---:|:--|
| Failed junit tests | hadoop.hdfs.server.namenode.ha.TestHAAppend |
| | hadoop.hdfs.server.namenode.ha.TestFailureToReadEdits |
| | hadoop.hdfs.server.namenode.ha.TestPipelinesFailover |
| | hadoop.hdfs.server.namenode.ha.TestBootstrapStandbyWithQJM |
| | hadoop.hdfs.server.namenode.ha.TestHASafeMode |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4291/1/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/4291 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell |
| uname | Linux f42a0ff33f68 4.15.0-175-generic #184-Ubuntu SMP Thu Mar 24
17:48:36 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 360bbd8ad5ee53c64f70755d2a1529e6e9c7cb8a |
| Default Java | Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Multi-JDK versions | /usr/lib/jvm/java-11-openjdk-amd64:Private
Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1
[jira] [Work logged] (HDFS-16572) Fix typo in readme of hadoop-project-dist
[ https://issues.apache.org/jira/browse/HDFS-16572?focusedWorklogId=767980=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-767980 ] ASF GitHub Bot logged work on HDFS-16572: - Author: ASF GitHub Bot Created on: 09/May/22 15:54 Start Date: 09/May/22 15:54 Worklog Time Spent: 10m Work Description: steveloughran commented on PR #4288: URL: https://github.com/apache/hadoop/pull/4288#issuecomment-1121280366 ok. don't try and do a "fix everything" patch as it will be too traumatic to backport. getting rid of the main complaints is good. we always have problems with different java versions being fussy about what they accept Issue Time Tracking --- Worklog Id: (was: 767980) Time Spent: 50m (was: 40m) > Fix typo in readme of hadoop-project-dist > - > > Key: HDFS-16572 > URL: https://issues.apache.org/jira/browse/HDFS-16572 > Project: Hadoop HDFS > Issue Type: Bug >Affects Versions: 3.4.0 >Reporter: Gautham Banasandra >Assignee: Gautham Banasandra >Priority: Trivial > Labels: pull-request-available > Time Spent: 50m > Remaining Estimate: 0h > > Change *not* to *no*. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16573) Fix test TestDFSStripedInputStreamWithRandomECPolicy
[ https://issues.apache.org/jira/browse/HDFS-16573?focusedWorklogId=767846=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-767846 ] ASF GitHub Bot logged work on HDFS-16573: - Author: ASF GitHub Bot Created on: 09/May/22 10:05 Start Date: 09/May/22 10:05 Worklog Time Spent: 10m Work Description: cndaimin commented on PR #4291: URL: https://github.com/apache/hadoop/pull/4291#issuecomment-1120901344 @tomscut I have fixed the failed test. Could you please take a look on this? Thanks. Issue Time Tracking --- Worklog Id: (was: 767846) Time Spent: 20m (was: 10m) > Fix test TestDFSStripedInputStreamWithRandomECPolicy > > > Key: HDFS-16573 > URL: https://issues.apache.org/jira/browse/HDFS-16573 > Project: Hadoop HDFS > Issue Type: Test > Components: test >Affects Versions: 3.3.2 >Reporter: daimin >Assignee: daimin >Priority: Minor > Labels: pull-request-available > Time Spent: 20m > Remaining Estimate: 0h > > TestDFSStripedInputStreamWithRandomECPolicy fails due to test from HDFS-16520 -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16573) Fix test TestDFSStripedInputStreamWithRandomECPolicy
[ https://issues.apache.org/jira/browse/HDFS-16573?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] ASF GitHub Bot updated HDFS-16573: -- Labels: pull-request-available (was: ) > Fix test TestDFSStripedInputStreamWithRandomECPolicy > > > Key: HDFS-16573 > URL: https://issues.apache.org/jira/browse/HDFS-16573 > Project: Hadoop HDFS > Issue Type: Test > Components: test >Affects Versions: 3.3.2 >Reporter: daimin >Assignee: daimin >Priority: Minor > Labels: pull-request-available > Time Spent: 10m > Remaining Estimate: 0h > > TestDFSStripedInputStreamWithRandomECPolicy fails due to test from HDFS-16520 -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16573) Fix test TestDFSStripedInputStreamWithRandomECPolicy
[ https://issues.apache.org/jira/browse/HDFS-16573?focusedWorklogId=767845=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-767845 ] ASF GitHub Bot logged work on HDFS-16573: - Author: ASF GitHub Bot Created on: 09/May/22 10:02 Start Date: 09/May/22 10:02 Worklog Time Spent: 10m Work Description: cndaimin opened a new pull request, #4291: URL: https://github.com/apache/hadoop/pull/4291 TestDFSStripedInputStreamWithRandomECPolicy fails due to test from [HDFS-16520](https://issues.apache.org/jira/browse/HDFS-16520) Issue Time Tracking --- Worklog Id: (was: 767845) Remaining Estimate: 0h Time Spent: 10m > Fix test TestDFSStripedInputStreamWithRandomECPolicy > > > Key: HDFS-16573 > URL: https://issues.apache.org/jira/browse/HDFS-16573 > Project: Hadoop HDFS > Issue Type: Test > Components: test >Affects Versions: 3.3.2 >Reporter: daimin >Assignee: daimin >Priority: Minor > Time Spent: 10m > Remaining Estimate: 0h > > TestDFSStripedInputStreamWithRandomECPolicy fails due to test from HDFS-16520 -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Created] (HDFS-16573) Fix test TestDFSStripedInputStreamWithRandomECPolicy
daimin created HDFS-16573: - Summary: Fix test TestDFSStripedInputStreamWithRandomECPolicy Key: HDFS-16573 URL: https://issues.apache.org/jira/browse/HDFS-16573 Project: Hadoop HDFS Issue Type: Test Components: test Affects Versions: 3.3.2 Reporter: daimin Assignee: daimin TestDFSStripedInputStreamWithRandomECPolicy fails due to test from HDFS-16520 -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-14750) RBF: Improved isolation for downstream name nodes. {Dynamic}
[
https://issues.apache.org/jira/browse/HDFS-14750?focusedWorklogId=767843=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-767843
]
ASF GitHub Bot logged work on HDFS-14750:
-
Author: ASF GitHub Bot
Created on: 09/May/22 09:33
Start Date: 09/May/22 09:33
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on PR #4199:
URL: https://github.com/apache/hadoop/pull/4199#issuecomment-1120872757
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 1m 0s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 1s | | codespell was not available. |
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 1 new or modified test files. |
_ trunk Compile Tests _ |
| +1 :green_heart: | mvninstall | 41m 31s | | trunk passed |
| +1 :green_heart: | compile | 0m 53s | | trunk passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | compile | 0m 47s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 0m 42s | | trunk passed |
| +1 :green_heart: | mvnsite | 0m 53s | | trunk passed |
| +1 :green_heart: | javadoc | 1m 0s | | trunk passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javadoc | 1m 5s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 1m 41s | | trunk passed |
| +1 :green_heart: | shadedclient | 24m 5s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 0m 38s | | the patch passed |
| +1 :green_heart: | compile | 0m 42s | | the patch passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javac | 0m 42s | | the patch passed |
| +1 :green_heart: | compile | 0m 36s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 0m 36s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 0m 22s | | the patch passed |
| +1 :green_heart: | mvnsite | 0m 39s | | the patch passed |
| +1 :green_heart: | xml | 0m 1s | | The patch has no ill-formed XML
file. |
| +1 :green_heart: | javadoc | 0m 38s | | the patch passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javadoc | 0m 54s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 1m 27s | | the patch passed |
| +1 :green_heart: | shadedclient | 23m 31s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| -1 :x: | unit | 31m 48s |
[/patch-unit-hadoop-hdfs-project_hadoop-hdfs-rbf.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4199/3/artifact/out/patch-unit-hadoop-hdfs-project_hadoop-hdfs-rbf.txt)
| hadoop-hdfs-rbf in the patch passed. |
| +1 :green_heart: | asflicense | 0m 43s | | The patch does not
generate ASF License warnings. |
| | | 137m 16s | | |
| Reason | Tests |
|---:|:--|
| Failed junit tests |
hadoop.hdfs.server.federation.security.TestRouterSecurityManager |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4199/3/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/4199 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell xml |
| uname | Linux 979564f749bf 4.15.0-175-generic #184-Ubuntu SMP Thu Mar 24
17:48:36 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 80aa59d44cbdb3ef5df9d2f799d771f95198e990 |
| Default Java | Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Multi-JDK versions | /usr/lib/jvm/java-11-openjdk-amd64:Private
Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1
/usr/lib/jvm/java-8-openjdk-amd64:Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Test Results |
[jira] [Work logged] (HDFS-16568) dfsadmin -reconfig option to start/query reconfig on all live datanodes
[ https://issues.apache.org/jira/browse/HDFS-16568?focusedWorklogId=767841=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-767841 ] ASF GitHub Bot logged work on HDFS-16568: - Author: ASF GitHub Bot Created on: 09/May/22 09:32 Start Date: 09/May/22 09:32 Worklog Time Spent: 10m Work Description: cndaimin commented on PR #4264: URL: https://github.com/apache/hadoop/pull/4264#issuecomment-1120870910 > Hi @cndaimin , could you please help take a look at this failed unit test `hadoop.hdfs.TestDFSStripedInputStreamWithRandomECPolicy`. Thank you. Yes, it's my mistake, I will submit a PR to fix it immediately. Sorry for that. Issue Time Tracking --- Worklog Id: (was: 767841) Time Spent: 4h (was: 3h 50m) > dfsadmin -reconfig option to start/query reconfig on all live datanodes > --- > > Key: HDFS-16568 > URL: https://issues.apache.org/jira/browse/HDFS-16568 > Project: Hadoop HDFS > Issue Type: New Feature >Reporter: Viraj Jasani >Assignee: Viraj Jasani >Priority: Major > Labels: pull-request-available > Time Spent: 4h > Remaining Estimate: 0h > > DFSAdmin provides option to initiate or query the status of reconfiguration > operation on only specific host based on host:port provided by user. It would > be good to provide an ability to initiate such operations in bulk, on all > live datanodes. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-15057) NFS: Error 'E72: Close error on swap file' occur when vi a file
[ https://issues.apache.org/jira/browse/HDFS-15057?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17533658#comment-17533658 ] vinutha umashankar commented on HDFS-15057: --- Hi, Can you please let me know how this issue can be resolved? Thank you in advance. Regards, Vinutha U > NFS: Error 'E72: Close error on swap file' occur when vi a file > --- > > Key: HDFS-15057 > URL: https://issues.apache.org/jira/browse/HDFS-15057 > Project: Hadoop HDFS > Issue Type: Bug > Components: nfs >Affects Versions: 3.2.1 >Reporter: WangZhichao >Priority: Major > > 10.43.183.108 is nfs-hdfs-gateway > HQxDAP-161 is nfs-hdfs-client > Steps are as follows: > [root@HQxDAP-161 mnt]# mount -t nfs -o vers=3,proto=tcp,nolock > 10.43.183.108:/ /mnt/test > [root@HQxDAP-161 mnt]# cd /mnt/test > [root@HQxDAP-161 test]# ls > 1.txt > [root@HQxDAP-161 test]# vi 1.txt > E72: Close error on swap file[root@HQxDAP-161 test]# -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16568) dfsadmin -reconfig option to start/query reconfig on all live datanodes
[
https://issues.apache.org/jira/browse/HDFS-16568?focusedWorklogId=767799=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-767799
]
ASF GitHub Bot logged work on HDFS-16568:
-
Author: ASF GitHub Bot
Created on: 09/May/22 06:42
Start Date: 09/May/22 06:42
Worklog Time Spent: 10m
Work Description: virajjasani commented on code in PR #4264:
URL: https://github.com/apache/hadoop/pull/4264#discussion_r866455501
##
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/tools/DFSAdmin.java:
##
@@ -1915,12 +1919,57 @@ public int reconfig(String[] argv, int i) throws
IOException {
}
int startReconfiguration(final String nodeThpe, final String address)
- throws IOException {
-return startReconfiguration(nodeThpe, address, System.out, System.err);
+ throws IOException, InterruptedException {
+return startReconfigurationUtil(nodeThpe, address, System.out, System.err);
+ }
+
+ int startReconfigurationUtil(final String nodeType, final String address,
final PrintStream out,
+ final PrintStream err) throws IOException, InterruptedException {
+if (!"livenodes".equals(address)) {
+ return startReconfiguration(nodeType, address, out, err);
+}
+if (!"datanode".equals(nodeType)) {
+ err.println("Only datanode type supports reconfiguration in bulk.");
+ return 1;
+}
+ExecutorService executorService = Executors.newFixedThreadPool(5);
Review Comment:
I thought of doing the same initially, but then I realized that allowing
users to provide threadpool size might be bit complicated for admin/user (i.e.
bit more headache for user) as they would have to learn about where this size
is going to be used internally, hence I kept it as 5 as it seemed reasonable
for even bigger clusters. Does this sound good?
If you have strong preference, will be happy to do it :)
Issue Time Tracking
---
Worklog Id: (was: 767799)
Time Spent: 3h 50m (was: 3h 40m)
> dfsadmin -reconfig option to start/query reconfig on all live datanodes
> ---
>
> Key: HDFS-16568
> URL: https://issues.apache.org/jira/browse/HDFS-16568
> Project: Hadoop HDFS
> Issue Type: New Feature
>Reporter: Viraj Jasani
>Assignee: Viraj Jasani
>Priority: Major
> Labels: pull-request-available
> Time Spent: 3h 50m
> Remaining Estimate: 0h
>
> DFSAdmin provides option to initiate or query the status of reconfiguration
> operation on only specific host based on host:port provided by user. It would
> be good to provide an ability to initiate such operations in bulk, on all
> live datanodes.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16570) RBF: The router using MultipleDestinationMountTableResolver remove Multiple subcluster data under the mount point failed
[
https://issues.apache.org/jira/browse/HDFS-16570?focusedWorklogId=767792=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-767792
]
ASF GitHub Bot logged work on HDFS-16570:
-
Author: ASF GitHub Bot
Created on: 09/May/22 06:04
Start Date: 09/May/22 06:04
Worklog Time Spent: 10m
Work Description: zhangxiping1 commented on PR #4269:
URL: https://github.com/apache/hadoop/pull/4269#issuecomment-1120678133
@ayushtkn Thanks for replying. This question is due to this feature
[HDFS-16024](https://issues.apache.org/jira/browse/HDFS-16024),It doesn't need
to mount the user‘s Trash Path anymore. Failed test cases have no connection to
the submitted code.
Issue Time Tracking
---
Worklog Id: (was: 767792)
Time Spent: 40m (was: 0.5h)
> RBF: The router using MultipleDestinationMountTableResolver remove Multiple
> subcluster data under the mount point failed
>
>
> Key: HDFS-16570
> URL: https://issues.apache.org/jira/browse/HDFS-16570
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: rbf
>Reporter: Xiping Zhang
>Priority: Major
> Labels: pull-request-available
> Time Spent: 40m
> Remaining Estimate: 0h
>
> Please look at the following example :
> hadoop>{color:#FF}hdfs dfsrouteradmin -add /home/data ns0,ns1 /home/data
> -order RANDOM{color}
> Successfully removed mount point /home/data
> hadoop>{color:#FF}hdfs dfsrouteradmin -ls{color}
> Mount Table Entries:
> Source Destinations Owner
> Group Mode Quota/Usage
> /home/data ns0->/home/data,ns1->/home/data zhangxiping
> Administrators rwxr-xr-x [NsQuota: -/-, SsQuota: -/-]
> hadoop>{color:#FF}hdfs dfs -touch
> hdfs://ns0/home/data/test/fileNs0.txt{color}
> hadoop>{color:#FF}hdfs dfs -touch
> hdfs://ns1/home/data/test/fileNs1.txt{color}
> hadoop>{color:#FF}hdfs dfs -ls
> hdfs://ns0/home/data/test/fileNs0.txt{color}
> {-}rw-r{-}{-}r{-}- 3 zhangxiping supergroup 0 2022-05-06 18:01
> hdfs://ns0/home/data/test/fileNs0.txt
> hadoop>{color:#FF}hdfs dfs -ls
> hdfs://ns1/home/data/test/fileNs1.txt{color}
> {-}rw-r{-}{-}r{-}- 3 zhangxiping supergroup 0 2022-05-06 18:01
> hdfs://ns1/home/data/test/fileNs1.txt
> hadoop>{color:#FF}hdfs dfs -ls
> hdfs://127.0.0.1:40250/home/data/test{color}
> Found 2 items
> {-}rw-r{-}{-}r{-}- 3 zhangxiping supergroup 0 2022-05-06 18:01
> hdfs://127.0.0.1:40250/home/data/test/fileNs0.txt
> {-}rw-r{-}{-}r{-}- 3 zhangxiping supergroup 0 2022-05-06 18:01
> hdfs://127.0.0.1:40250/home/data/test/fileNs1.txt
> hadoop>{color:#FF}hdfs dfs -rm -r
> hdfs://127.0.0.1:40250/home/data/test{color}
> rm: Failed to move to trash: hdfs://127.0.0.1:40250/home/data/test: rename
> destination parent /user/zhangxiping/.Trash/Current/home/data/test not found.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org