[GitHub] [carbondata] CarbonDataQA commented on issue #3278: [CARBONDATA-3427] Beautify DAG by showing less text
CarbonDataQA commented on issue #3278: [CARBONDATA-3427] Beautify DAG by showing less text URL: https://github.com/apache/carbondata/pull/3278#issuecomment-501130979 Build Success with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11777/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] kunal642 commented on issue #3274: [CARBONDATA-3398] Fix drop metacache on table having mv datamap
kunal642 commented on issue #3274: [CARBONDATA-3398] Fix drop metacache on table having mv datamap URL: https://github.com/apache/carbondata/pull/3274#issuecomment-501119319 LGTM This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL
CarbonDataQA commented on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL URL: https://github.com/apache/carbondata/pull/3209#issuecomment-501115193 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3710/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL
CarbonDataQA commented on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL URL: https://github.com/apache/carbondata/pull/3209#issuecomment-501112466 Build Failed with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11776/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3278: [CARBONDATA-3427] Beautify DAG by showing less text
CarbonDataQA commented on issue #3278: [CARBONDATA-3427] Beautify DAG by showing less text URL: https://github.com/apache/carbondata/pull/3278#issuecomment-501112468 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3711/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3278: [CARBONDATA-3427] Beautify DAG by showing less text
CarbonDataQA commented on issue #3278: [CARBONDATA-3427] Beautify DAG by showing less text URL: https://github.com/apache/carbondata/pull/3278#issuecomment-501102728 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3506/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] kevinjmh opened a new pull request #3278: [CARBONDATA-3427] Beautify DAG by showing less text
kevinjmh opened a new pull request #3278: [CARBONDATA-3427] Beautify DAG by showing less text URL: https://github.com/apache/carbondata/pull/3278 currently, the DAG of carbon table scan is not showing friendly because it prints schema too. When we do a large query, we often need to drag the scroll to see the DAG. 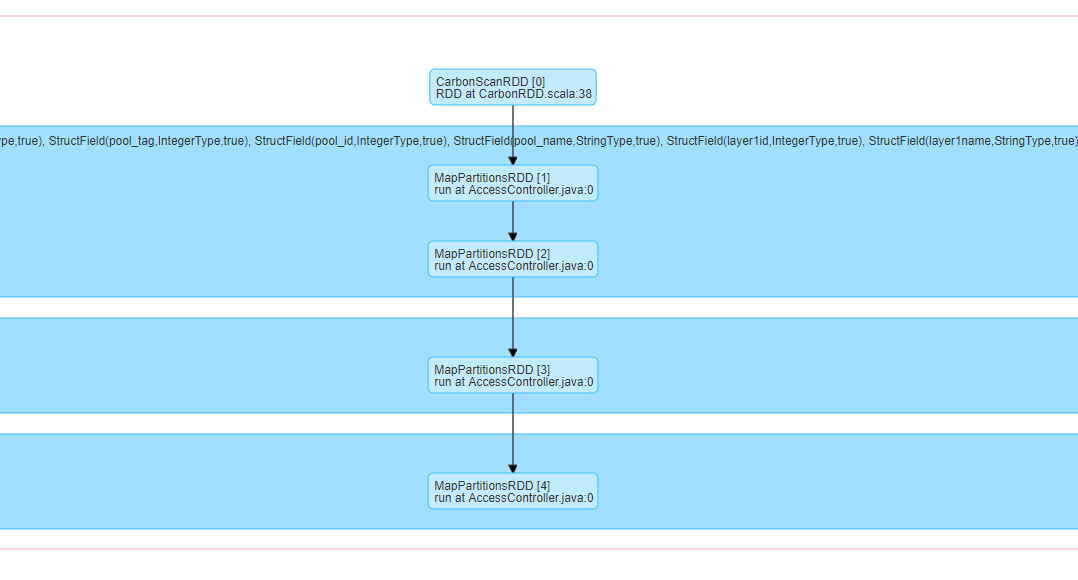 To make it clear as other format on Spark like parquet, we remove the schema info, and it finally looks like below 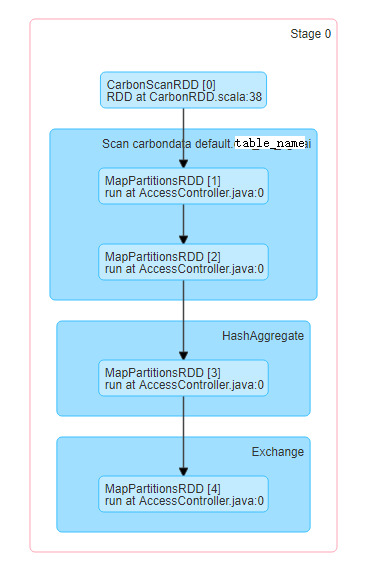 Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (CARBONDATA-3427) Beautify DAG by showing less text
jiangmanhua created CARBONDATA-3427: --- Summary: Beautify DAG by showing less text Key: CARBONDATA-3427 URL: https://issues.apache.org/jira/browse/CARBONDATA-3427 Project: CarbonData Issue Type: Improvement Reporter: jiangmanhua -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [carbondata] CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV
CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV URL: https://github.com/apache/carbondata/pull/3245#issuecomment-500993049 Build Failed with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11775/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV
CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV URL: https://github.com/apache/carbondata/pull/3245#issuecomment-500919062 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3709/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3268: [CARBONDATA-3421] Fix create table without column with properties failed, but throw incorrect exception
CarbonDataQA commented on issue #3268: [CARBONDATA-3421] Fix create table without column with properties failed, but throw incorrect exception URL: https://github.com/apache/carbondata/pull/3268#issuecomment-500917638 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3707/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3268: [CARBONDATA-3421] Fix create table without column with properties failed, but throw incorrect exception
CarbonDataQA commented on issue #3268: [CARBONDATA-3421] Fix create table without column with properties failed, but throw incorrect exception URL: https://github.com/apache/carbondata/pull/3268#issuecomment-500896956 Build Success with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11773/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV
CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV URL: https://github.com/apache/carbondata/pull/3245#issuecomment-500889661 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3505/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV
CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV URL: https://github.com/apache/carbondata/pull/3245#issuecomment-500880901 Build Failed with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11772/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3277: [WIP] Updated alter table DDL to accept upgrade_segments as a compaction type.
CarbonDataQA commented on issue #3277: [WIP] Updated alter table DDL to accept upgrade_segments as a compaction type. URL: https://github.com/apache/carbondata/pull/3277#issuecomment-500874208 Build Failed with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11774/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3277: [WIP] Updated alter table DDL to accept upgrade_segments as a compaction type.
CarbonDataQA commented on issue #3277: [WIP] Updated alter table DDL to accept upgrade_segments as a compaction type. URL: https://github.com/apache/carbondata/pull/3277#issuecomment-500873433 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3708/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3277: [WIP] Updated alter table DDL to accept upgrade_segments as a compaction type.
CarbonDataQA commented on issue #3277: [WIP] Updated alter table DDL to accept upgrade_segments as a compaction type. URL: https://github.com/apache/carbondata/pull/3277#issuecomment-500872327 Build Failed with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3504/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV
CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV URL: https://github.com/apache/carbondata/pull/3245#issuecomment-500867664 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3706/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] kunal642 opened a new pull request #3277: [WIP] Updated alter table DDL to accept upgrade_segments as a compaction type.
kunal642 opened a new pull request #3277: [WIP] Updated alter table DDL to accept upgrade_segments as a compaction type. URL: https://github.com/apache/carbondata/pull/3277 1. Updated alter table DDL to accept upgrade_segments as a compaction type. 2. made legacy segment distribution round-robin based. Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3276: [CARBONDATA-3426] Fix load performance by fixing task distribution issue
CarbonDataQA commented on issue #3276: [CARBONDATA-3426] Fix load performance by fixing task distribution issue URL: https://github.com/apache/carbondata/pull/3276#issuecomment-500863078 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3705/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] jack86596 commented on a change in pull request #3269: [CARBONDATA-3266] Remove redundant warn messages when carbon session is creating.
jack86596 commented on a change in pull request #3269: [CARBONDATA-3266] Remove redundant warn messages when carbon session is creating. URL: https://github.com/apache/carbondata/pull/3269#discussion_r292480016 ## File path: core/src/main/java/org/apache/carbondata/core/util/CarbonProperties.java ## @@ -37,41 +37,6 @@ import org.apache.carbondata.core.metadata.ColumnarFormatVersion; import org.apache.carbondata.core.util.annotations.CarbonProperty; -import static org.apache.carbondata.core.constants.CarbonCommonConstants.BLOCKLET_SIZE; Review comment: For example, when inside the function, BLOCKLET_SIZE is used, then CarbonCommonConstants.BLOCKLET_SIZE is more readable then just BLOCKLET_SIZE. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3268: [CARBONDATA-3421] Fix create table without column with properties failed, but throw incorrect exception
CarbonDataQA commented on issue #3268: [CARBONDATA-3421] Fix create table without column with properties failed, but throw incorrect exception URL: https://github.com/apache/carbondata/pull/3268#issuecomment-500859295 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3502/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] jack86596 commented on a change in pull request #3268: [CARBONDATA-3421] Fix create table without column with properties failed, but throw incorrect exception
jack86596 commented on a change in pull request #3268: [CARBONDATA-3421] Fix
create table without column with properties failed, but throw incorrect
exception
URL: https://github.com/apache/carbondata/pull/3268#discussion_r292471536
##
File path:
integration/spark2/src/main/scala/org/apache/spark/sql/parser/CarbonSparkSqlParserUtil.scala
##
@@ -124,10 +123,14 @@ object CarbonSparkSqlParserUtil {
operationNotAllowed("Streaming is not allowed on partitioned table",
partitionColumns)
}
+if (!external && fields.isEmpty) {
+ throw new MalformedCarbonCommandException("Table schema is not
specified.")
Review comment:
done.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] jack86596 commented on a change in pull request #3268: [CARBONDATA-3421] Fix create table without column with properties failed, but throw incorrect exception
jack86596 commented on a change in pull request #3268: [CARBONDATA-3421] Fix
create table without column with properties failed, but throw incorrect
exception
URL: https://github.com/apache/carbondata/pull/3268#discussion_r292471472
##
File path:
integration/spark2/src/main/scala/org/apache/spark/sql/parser/CarbonSparkSqlParserUtil.scala
##
@@ -124,10 +123,14 @@ object CarbonSparkSqlParserUtil {
operationNotAllowed("Streaming is not allowed on partitioned table",
partitionColumns)
}
+if (!external && fields.isEmpty) {
+ throw new MalformedCarbonCommandException("Table schema is not
specified.")
+}
+
Review comment:
done.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3270: [CARBONDATA-3422] fix missing complex dimensions when prepare the data from raw object
CarbonDataQA commented on issue #3270: [CARBONDATA-3422] fix missing complex dimensions when prepare the data from raw object URL: https://github.com/apache/carbondata/pull/3270#issuecomment-500838844 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3702/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3276: [CARBONDATA-3426] Fix load performance by fixing task distribution issue
CarbonDataQA commented on issue #3276: [CARBONDATA-3426] Fix load performance by fixing task distribution issue URL: https://github.com/apache/carbondata/pull/3276#issuecomment-500838197 Build Success with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11771/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3275: [WIP]Added documentation for mv
CarbonDataQA commented on issue #3275: [WIP]Added documentation for mv URL: https://github.com/apache/carbondata/pull/3275#issuecomment-500836005 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3704/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3276: [CARBONDATA-3426] Fix load performance by fixing task distribution issue
CarbonDataQA commented on issue #3276: [CARBONDATA-3426] Fix load performance by fixing task distribution issue URL: https://github.com/apache/carbondata/pull/3276#issuecomment-500833804 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3500/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV
CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV URL: https://github.com/apache/carbondata/pull/3245#issuecomment-500832519 Build Failed with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3501/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3270: [CARBONDATA-3422] fix missing complex dimensions when prepare the data from raw object
CarbonDataQA commented on issue #3270: [CARBONDATA-3422] fix missing complex dimensions when prepare the data from raw object URL: https://github.com/apache/carbondata/pull/3270#issuecomment-500831323 Build Success with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11768/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL
CarbonDataQA commented on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL URL: https://github.com/apache/carbondata/pull/3209#issuecomment-500831327 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3703/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL
CarbonDataQA commented on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL URL: https://github.com/apache/carbondata/pull/3209#issuecomment-500831324 Build Failed with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11769/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3275: [WIP]Added documentation for mv
CarbonDataQA commented on issue #3275: [WIP]Added documentation for mv URL: https://github.com/apache/carbondata/pull/3275#issuecomment-500829608 Build Failed with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11770/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] kumarvishal09 commented on a change in pull request #3268: [CARBONDATA-3421] Fix create table without column with properties failed, but throw incorrect exception
kumarvishal09 commented on a change in pull request #3268: [CARBONDATA-3421]
Fix create table without column with properties failed, but throw incorrect
exception
URL: https://github.com/apache/carbondata/pull/3268#discussion_r292438361
##
File path:
integration/spark2/src/main/scala/org/apache/spark/sql/parser/CarbonSparkSqlParserUtil.scala
##
@@ -124,10 +123,14 @@ object CarbonSparkSqlParserUtil {
operationNotAllowed("Streaming is not allowed on partitioned table",
partitionColumns)
}
+if (!external && fields.isEmpty) {
+ throw new MalformedCarbonCommandException("Table schema is not
specified.")
Review comment:
please change the error message "Creating table without column(s) is not
supported"
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] kumarvishal09 commented on a change in pull request #3268: [CARBONDATA-3421] Fix create table without column with properties failed, but throw incorrect exception
kumarvishal09 commented on a change in pull request #3268: [CARBONDATA-3421]
Fix create table without column with properties failed, but throw incorrect
exception
URL: https://github.com/apache/carbondata/pull/3268#discussion_r292437760
##
File path:
integration/spark2/src/main/scala/org/apache/spark/sql/parser/CarbonSparkSqlParserUtil.scala
##
@@ -124,10 +123,14 @@ object CarbonSparkSqlParserUtil {
operationNotAllowed("Streaming is not allowed on partitioned table",
partitionColumns)
}
+if (!external && fields.isEmpty) {
+ throw new MalformedCarbonCommandException("Table schema is not
specified.")
+}
+
Review comment:
remove this extra space
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] kumarvishal09 commented on a change in pull request #3269: [CARBONDATA-3266] Remove redundant warn messages when carbon session is creating.
kumarvishal09 commented on a change in pull request #3269: [CARBONDATA-3266] Remove redundant warn messages when carbon session is creating. URL: https://github.com/apache/carbondata/pull/3269#discussion_r292436904 ## File path: core/src/main/java/org/apache/carbondata/core/util/CarbonProperties.java ## @@ -37,41 +37,6 @@ import org.apache.carbondata.core.metadata.ColumnarFormatVersion; import org.apache.carbondata.core.util.annotations.CarbonProperty; -import static org.apache.carbondata.core.constants.CarbonCommonConstants.BLOCKLET_SIZE; Review comment: Why this change is required ?? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3275: [WIP]Added documentation for mv
CarbonDataQA commented on issue #3275: [WIP]Added documentation for mv URL: https://github.com/apache/carbondata/pull/3275#issuecomment-500811169 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3499/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Resolved] (CARBONDATA-3258) Add more test case for mv datamap
[ https://issues.apache.org/jira/browse/CARBONDATA-3258?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] xubo245 resolved CARBONDATA-3258. - Resolution: Fixed > Add more test case for mv datamap > - > > Key: CARBONDATA-3258 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3258 > Project: CarbonData > Issue Type: Test > Components: data-query >Reporter: Chenjian Qiu >Priority: Major > Time Spent: 11h 20m > Remaining Estimate: 0h > > Add more test case for mv datamap -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Resolved] (CARBONDATA-3414) when Insert into partition table fails exception doesn't print reason.
[ https://issues.apache.org/jira/browse/CARBONDATA-3414?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] xubo245 resolved CARBONDATA-3414. - Resolution: Fixed > when Insert into partition table fails exception doesn't print reason. > -- > > Key: CARBONDATA-3414 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3414 > Project: CarbonData > Issue Type: Bug >Reporter: Ajantha Bhat >Priority: Minor > > problem: when Insert into partition table fails, exception doesn't print > reason. > cause: Exception was caught , but error message was not from that exception. > solution: throw the exception directly > > Steps to reproduce: > # Open multiple spark beeline (say 10) > # Create a carbon table with partition > # Insert overwrite to carbon table from all the 10 beeline concurrently > # some insert overwrite will be success and some will fail due to > non-availability of lock even after retry. > # For the failed insert into sql, Exception is just "DataLoadFailure: " no > error reason is printed. > Need to print the valid error reason for the failure. > > > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Resolved] (CARBONDATA-3411) ClearDatamaps logs an exception in SDK
[ https://issues.apache.org/jira/browse/CARBONDATA-3411?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] xubo245 resolved CARBONDATA-3411. - Resolution: Fixed > ClearDatamaps logs an exception in SDK > -- > > Key: CARBONDATA-3411 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3411 > Project: CarbonData > Issue Type: Bug >Reporter: Ajantha Bhat >Priority: Minor > Time Spent: 4h 50m > Remaining Estimate: 0h > > problem: In sdk when datamaps are cleared, below exception is logged > java.io.IOException: File does not exist: > /home/root1/Documents/ab/workspace/carbonFile/carbondata/store/sdk/testWriteFiles/771604793030370/Metadata/schema > at > org.apache.carbondata.core.metadata.schema.SchemaReader.readCarbonTableFromStore(SchemaReader.java:60) > at > org.apache.carbondata.core.metadata.schema.table.CarbonTable.buildFromTablePath(CarbonTable.java:272) > at > org.apache.carbondata.core.datamap.DataMapStoreManager.getCarbonTable(DataMapStoreManager.java:566) > at > org.apache.carbondata.core.datamap.DataMapStoreManager.clearDataMaps(DataMapStoreManager.java:514) > at > org.apache.carbondata.core.datamap.DataMapStoreManager.clearDataMaps(DataMapStoreManager.java:504) > at > org.apache.carbondata.sdk.file.CarbonReaderBuilder.getSplits(CarbonReaderBuilder.java:419) > at > org.apache.carbondata.sdk.file.CarbonReaderTest.testGetSplits(CarbonReaderTest.java:2605) > at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) > at > sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) > at > sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) > at java.lang.reflect.Method.invoke(Method.java:498) > at junit.framework.TestCase.runTest(TestCase.java:176) > at junit.framework.TestCase.runBare(TestCase.java:141) > at junit.framework.TestResult$1.protect(TestResult.java:122) > at junit.framework.TestResult.runProtected(TestResult.java:142) > at junit.framework.TestResult.run(TestResult.java:125) > at junit.framework.TestCase.run(TestCase.java:129) > at junit.framework.TestSuite.runTest(TestSuite.java:255) > at junit.framework.TestSuite.run(TestSuite.java:250) > at > org.junit.internal.runners.JUnit38ClassRunner.run(JUnit38ClassRunner.java:84) > at org.junit.runner.JUnitCore.run(JUnitCore.java:160) > at > com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:68) > at > com.intellij.rt.execution.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:47) > at > com.intellij.rt.execution.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:242) > at com.intellij.rt.execution.junit.JUnitStarter.main(JUnitStarter.java:70) > cause: CarbonTable is required for only launching the job, SDK there is no > need to launch job. so , no need to build a carbon table. > solution: build carbon table only when need to launch job. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [carbondata] asfgit closed pull request #3254: [CARBONDATA-3411] [CARBONDATA-3414] Fix clear datamaps logs an exception in SDK
asfgit closed pull request #3254: [CARBONDATA-3411] [CARBONDATA-3414] Fix clear datamaps logs an exception in SDK URL: https://github.com/apache/carbondata/pull/3254 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] xubo245 commented on issue #3254: [CARBONDATA-3411] [CARBONDATA-3414] Fix clear datamaps logs an exception in SDK
xubo245 commented on issue #3254: [CARBONDATA-3411] [CARBONDATA-3414] Fix clear datamaps logs an exception in SDK URL: https://github.com/apache/carbondata/pull/3254#issuecomment-500804876 LGTM! Thanks for your contribution! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat commented on issue #3276: [CARBONDATA-3426] Fix load performance by fixing task distribution issue
ajantha-bhat commented on issue #3276: [CARBONDATA-3426] Fix load performance by fixing task distribution issue URL: https://github.com/apache/carbondata/pull/3276#issuecomment-500803468 @ravipesala , @kumarvishal09 : please check This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] ajantha-bhat opened a new pull request #3276: [CARBONDATA-3426] Fix load performance by fixing task distribution issue
ajantha-bhat opened a new pull request #3276: [CARBONDATA-3426] Fix load performance by fixing task distribution issue URL: https://github.com/apache/carbondata/pull/3276 **Problem:** Load performance degrade due to task distribution issue. **Cause:** Consider 3 node cluster (host name a,b,c with IP1, IP2, IP3 as ip address), to launch load task, host name is required from NewCarbonDataLoadRDD in getPreferredLocations(). But if the driver is 'a' (IP1), Result is IP1, b,c instead of a,b,c. Hence task was not launching to one executor which is same ip as driver. getLocalhostIPs is modified in current version recently and instead of IP it was returning hostname, hence local ip hostname was removed instead of IP address. solution: Revert the change in getLocalhostIPs as it is not used in any other flow. Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? NA - [ ] Any backward compatibility impacted? NA - [ ] Document update required? NA - [ ] Testing done yes, tested with 17 node spark clusters with huge data. Load performance is same as previous version. [degrade was 30%] - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. NA This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (CARBONDATA-3426) Fix Load performance degrade by fixing task distribution
Ajantha Bhat created CARBONDATA-3426: Summary: Fix Load performance degrade by fixing task distribution Key: CARBONDATA-3426 URL: https://issues.apache.org/jira/browse/CARBONDATA-3426 Project: CarbonData Issue Type: Bug Reporter: Ajantha Bhat Problem: Load performance degrade by fixing task distribution issue. Cause: Consider 3 node cluster (host name a,b,c with IP1, IP2, IP3 as ip address), to launch load task, host name is required from NewCarbonDataLoadRDD in getPreferredLocations(). But if the driver is a (IP1), result is IP1, b,c instead of a,b,c. Hence task was not launching to one executor which is same ip as driver. getLocalhostIPs is modified in current version recently and instead of IP it was returning address, hence local ip hostanme was removed instead of address. solution: Revert the change in getLocalhostIPs as it is not used in any other flow. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3275: [WIP]Added documentation for mv
Indhumathi27 commented on a change in pull request #3275: [WIP]Added
documentation for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292405581
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
+ against the selected datamap instead of the main table. Since the data size
of MV datamap is
+ smaller, user queries are much faster.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create MV tables using the Create DataMap DDL
+
+ ```
+ CREATE DATAMAP agg_sales
+ ON TABLE sales
+ USING "MV"
+ AS
+SELECT country, sex, sum(quantity), avg(price)
+FROM sales
+GROUP BY country, sex
+ ```
+ **NOTE**:
+ * Group by/Filter columns has to be provided in projection list while
creating mv datamap
+ * If only one parent table is involved in mv datamap creation, then
TableProperties of Parent table
+ (if not present in a aggregate function like sum(col)) like SORT_COLUMNS,
SORT_SCOPE, TABLE_BLOCKSIZE,
+ FLAT_FOLDER, LONG_STRING_COLUMNS, LOCAL_DICTIONARY_ENABLE,
LOCAL_DICTIONARY_THRESHOLD,
+ LOCAL_DICTIONARY_INCLUDE, LOCAL_DICTIONARY_EXCLUDE, DICTIONARY_INCLUDE,
DICTIONARY_EXCLUDE,
+ INVERTED_INDEX, NO_INVERTED_INDEX, COLUMN_COMPRESSOR will be inherited to
datamap table
+ * All columns of main table at once cannot participate in mv datamap table
creation
+ * TableProperties can be provided in DMProperties excluding
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3275: [WIP]Added documentation for mv
Indhumathi27 commented on a change in pull request #3275: [WIP]Added
documentation for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292405658
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
+ against the selected datamap instead of the main table. Since the data size
of MV datamap is
+ smaller, user queries are much faster.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create MV tables using the Create DataMap DDL
+
+ ```
+ CREATE DATAMAP agg_sales
+ ON TABLE sales
+ USING "MV"
+ AS
+SELECT country, sex, sum(quantity), avg(price)
+FROM sales
+GROUP BY country, sex
+ ```
+ **NOTE**:
+ * Group by/Filter columns has to be provided in projection list while
creating mv datamap
+ * If only one parent table is involved in mv datamap creation, then
TableProperties of Parent table
+ (if not present in a aggregate function like sum(col)) like SORT_COLUMNS,
SORT_SCOPE, TABLE_BLOCKSIZE,
+ FLAT_FOLDER, LONG_STRING_COLUMNS, LOCAL_DICTIONARY_ENABLE,
LOCAL_DICTIONARY_THRESHOLD,
+ LOCAL_DICTIONARY_INCLUDE, LOCAL_DICTIONARY_EXCLUDE, DICTIONARY_INCLUDE,
DICTIONARY_EXCLUDE,
+ INVERTED_INDEX, NO_INVERTED_INDEX, COLUMN_COMPRESSOR will be inherited to
datamap table
+ * All columns of main table at once cannot participate in mv datamap table
creation
+ * TableProperties can be provided in DMProperties excluding
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3275: [WIP]Added documentation for mv
Indhumathi27 commented on a change in pull request #3275: [WIP]Added
documentation for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292405709
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
+ against the selected datamap instead of the main table. Since the data size
of MV datamap is
+ smaller, user queries are much faster.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create MV tables using the Create DataMap DDL
+
+ ```
+ CREATE DATAMAP agg_sales
+ ON TABLE sales
+ USING "MV"
+ AS
+SELECT country, sex, sum(quantity), avg(price)
+FROM sales
+GROUP BY country, sex
+ ```
+ **NOTE**:
+ * Group by/Filter columns has to be provided in projection list while
creating mv datamap
+ * If only one parent table is involved in mv datamap creation, then
TableProperties of Parent table
+ (if not present in a aggregate function like sum(col)) like SORT_COLUMNS,
SORT_SCOPE, TABLE_BLOCKSIZE,
+ FLAT_FOLDER, LONG_STRING_COLUMNS, LOCAL_DICTIONARY_ENABLE,
LOCAL_DICTIONARY_THRESHOLD,
+ LOCAL_DICTIONARY_INCLUDE, LOCAL_DICTIONARY_EXCLUDE, DICTIONARY_INCLUDE,
DICTIONARY_EXCLUDE,
+ INVERTED_INDEX, NO_INVERTED_INDEX, COLUMN_COMPRESSOR will be inherited to
datamap table
+ * All columns of main table at once cannot participate in mv datamap table
creation
+ * TableProperties can be provided in DMProperties excluding
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3275: [WIP]Added documentation for mv
Indhumathi27 commented on a change in pull request #3275: [WIP]Added
documentation for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292405439
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
Review comment:
done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3275: [WIP]Added documentation for mv
Indhumathi27 commented on a change in pull request #3275: [WIP]Added
documentation for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292405520
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
+ against the selected datamap instead of the main table. Since the data size
of MV datamap is
+ smaller, user queries are much faster.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create MV tables using the Create DataMap DDL
+
+ ```
+ CREATE DATAMAP agg_sales
+ ON TABLE sales
+ USING "MV"
+ AS
+SELECT country, sex, sum(quantity), avg(price)
+FROM sales
+GROUP BY country, sex
+ ```
+ **NOTE**:
+ * Group by/Filter columns has to be provided in projection list while
creating mv datamap
+ * If only one parent table is involved in mv datamap creation, then
TableProperties of Parent table
+ (if not present in a aggregate function like sum(col)) like SORT_COLUMNS,
SORT_SCOPE, TABLE_BLOCKSIZE,
+ FLAT_FOLDER, LONG_STRING_COLUMNS, LOCAL_DICTIONARY_ENABLE,
LOCAL_DICTIONARY_THRESHOLD,
+ LOCAL_DICTIONARY_INCLUDE, LOCAL_DICTIONARY_EXCLUDE, DICTIONARY_INCLUDE,
DICTIONARY_EXCLUDE,
+ INVERTED_INDEX, NO_INVERTED_INDEX, COLUMN_COMPRESSOR will be inherited to
datamap table
+ * All columns of main table at once cannot participate in mv datamap table
creation
+ * TableProperties can be provided in DMProperties excluding
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3275: [WIP]Added documentation for mv
Indhumathi27 commented on a change in pull request #3275: [WIP]Added
documentation for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292405389
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
Review comment:
done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3275: [WIP]Added documentation for mv
Indhumathi27 commented on a change in pull request #3275: [WIP]Added
documentation for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292405264
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
Review comment:
done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3275: [WIP]Added documentation for mv
Indhumathi27 commented on a change in pull request #3275: [WIP]Added
documentation for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292405333
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
Review comment:
done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on a change in pull request #3275: [WIP]Added documentation for mv
Indhumathi27 commented on a change in pull request #3275: [WIP]Added documentation for mv URL: https://github.com/apache/carbondata/pull/3275#discussion_r292405185 ## File path: docs/datamap/datamap-management.md ## @@ -142,6 +139,8 @@ There is a SHOW DATAMAPS command, when this is issued, system will read all data - DataMapProviderName like mv, preaggreagte, timeseries, etc - Associated Table - DataMap Properties +- DataMap status (ENABLED/DISABLED) +- Sync Status(Applicable only for mv datamap) Review comment: done This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3270: [CARBONDATA-3422] fix missing complex dimensions when prepare the data from raw object
CarbonDataQA commented on issue #3270: [CARBONDATA-3422] fix missing complex dimensions when prepare the data from raw object URL: https://github.com/apache/carbondata/pull/3270#issuecomment-500796378 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3498/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] zhxiaoping commented on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL
zhxiaoping commented on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL URL: https://github.com/apache/carbondata/pull/3209#issuecomment-500796210 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv URL: https://github.com/apache/carbondata/pull/3275#discussion_r292304939 ## File path: docs/datamap/mv-datamap-guide.md ## @@ -0,0 +1,265 @@ + + +# CarbonData MV DataMap + +* [Quick Example](#quick-example) +* [MV DataMap](#mv-datamap-introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-mv-tables) +* [Data Management](#data-management-with-mv-tables) + +## Quick example +Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME + +Package carbon jar, and copy assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar to $SPARK_HOME/jars +```shell +mvn clean package -DskipTests -Pspark-2.2 -Pmv +``` + +Start spark-shell in new terminal, type :paste, then copy and run the following code. +```scala + import java.io.File Review comment: is this executed and tested? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation
for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292313140
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
Review comment:
`supports to select the most efficient MV datamap and rewrite the SQL to
query against the selected datamap instead of the main table`**change to**
`helps to select the most efficient MV datamap based on the user query
and rewrite the SQL to select the data from MV datamap instead of main table`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation
for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292316876
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
+ against the selected datamap instead of the main table. Since the data size
of MV datamap is
+ smaller, user queries are much faster.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create MV tables using the Create DataMap DDL
+
+ ```
+ CREATE DATAMAP agg_sales
+ ON TABLE sales
+ USING "MV"
+ AS
+SELECT country, sex, sum(quantity), avg(price)
+FROM sales
+GROUP BY country, sex
+ ```
+ **NOTE**:
+ * Group by/Filter columns has to be provided in projection list while
creating mv datamap
+ * If only one parent table is involved in mv datamap creation, then
TableProperties of Parent table
+ (if not present in a aggregate function like sum(col)) like SORT_COLUMNS,
SORT_SCOPE, TABLE_BLOCKSIZE,
+ FLAT_FOLDER, LONG_STRING_COLUMNS, LOCAL_DICTIONARY_ENABLE,
LOCAL_DICTIONARY_THRESHOLD,
+ LOCAL_DICTIONARY_INCLUDE, LOCAL_DICTIONARY_EXCLUDE, DICTIONARY_INCLUDE,
DICTIONARY_EXCLUDE,
+ INVERTED_INDEX, NO_INVERTED_INDEX, COLUMN_COMPRESSOR will be inherited to
datamap table
+ * All columns of main table at once cannot participate in mv datamap table
creation
+ * TableProperties can be provided in DMProperties excluding
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation
for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292315918
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
+ against the selected datamap instead of the main table. Since the data size
of MV datamap is
+ smaller, user queries are much faster.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create MV tables using the Create DataMap DDL
+
+ ```
+ CREATE DATAMAP agg_sales
+ ON TABLE sales
+ USING "MV"
+ AS
+SELECT country, sex, sum(quantity), avg(price)
+FROM sales
+GROUP BY country, sex
+ ```
+ **NOTE**:
+ * Group by/Filter columns has to be provided in projection list while
creating mv datamap
+ * If only one parent table is involved in mv datamap creation, then
TableProperties of Parent table
+ (if not present in a aggregate function like sum(col)) like SORT_COLUMNS,
SORT_SCOPE, TABLE_BLOCKSIZE,
+ FLAT_FOLDER, LONG_STRING_COLUMNS, LOCAL_DICTIONARY_ENABLE,
LOCAL_DICTIONARY_THRESHOLD,
+ LOCAL_DICTIONARY_INCLUDE, LOCAL_DICTIONARY_EXCLUDE, DICTIONARY_INCLUDE,
DICTIONARY_EXCLUDE,
+ INVERTED_INDEX, NO_INVERTED_INDEX, COLUMN_COMPRESSOR will be inherited to
datamap table
+ * All columns of main table at once cannot participate in mv datamap table
creation
+ * TableProperties can be provided in DMProperties excluding
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation
for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292317125
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
+ against the selected datamap instead of the main table. Since the data size
of MV datamap is
+ smaller, user queries are much faster.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create MV tables using the Create DataMap DDL
+
+ ```
+ CREATE DATAMAP agg_sales
+ ON TABLE sales
+ USING "MV"
+ AS
+SELECT country, sex, sum(quantity), avg(price)
+FROM sales
+GROUP BY country, sex
+ ```
+ **NOTE**:
+ * Group by/Filter columns has to be provided in projection list while
creating mv datamap
+ * If only one parent table is involved in mv datamap creation, then
TableProperties of Parent table
+ (if not present in a aggregate function like sum(col)) like SORT_COLUMNS,
SORT_SCOPE, TABLE_BLOCKSIZE,
+ FLAT_FOLDER, LONG_STRING_COLUMNS, LOCAL_DICTIONARY_ENABLE,
LOCAL_DICTIONARY_THRESHOLD,
+ LOCAL_DICTIONARY_INCLUDE, LOCAL_DICTIONARY_EXCLUDE, DICTIONARY_INCLUDE,
DICTIONARY_EXCLUDE,
+ INVERTED_INDEX, NO_INVERTED_INDEX, COLUMN_COMPRESSOR will be inherited to
datamap table
+ * All columns of main table at once cannot participate in mv datamap table
creation
+ * TableProperties can be provided in DMProperties excluding
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation
for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292314007
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
+ against the selected datamap instead of the main table. Since the data size
of MV datamap is
+ smaller, user queries are much faster.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create MV tables using the Create DataMap DDL
+
+ ```
+ CREATE DATAMAP agg_sales
+ ON TABLE sales
+ USING "MV"
+ AS
+SELECT country, sex, sum(quantity), avg(price)
+FROM sales
+GROUP BY country, sex
+ ```
+ **NOTE**:
+ * Group by/Filter columns has to be provided in projection list while
creating mv datamap
+ * If only one parent table is involved in mv datamap creation, then
TableProperties of Parent table
Review comment:
better to list all the properties mentioned here in list format, instead of
line, follow in both the points and reverify the properties
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv URL: https://github.com/apache/carbondata/pull/3275#discussion_r292304430 ## File path: docs/datamap/datamap-management.md ## @@ -142,6 +139,8 @@ There is a SHOW DATAMAPS command, when this is issued, system will read all data - DataMapProviderName like mv, preaggreagte, timeseries, etc - Associated Table - DataMap Properties +- DataMap status (ENABLED/DISABLED) +- Sync Status(Applicable only for mv datamap) Review comment: may be give more meaningful, or little bit explaination This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation
for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292305932
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
Review comment:
`Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented` change to
`Pre-aggregate datamap supports only aggregation on single table where as MV
datamap is implemented`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation
for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292314507
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
+ against the selected datamap instead of the main table. Since the data size
of MV datamap is
+ smaller, user queries are much faster.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create MV tables using the Create DataMap DDL
+
+ ```
+ CREATE DATAMAP agg_sales
+ ON TABLE sales
+ USING "MV"
+ AS
+SELECT country, sex, sum(quantity), avg(price)
+FROM sales
+GROUP BY country, sex
+ ```
+ **NOTE**:
+ * Group by/Filter columns has to be provided in projection list while
creating mv datamap
+ * If only one parent table is involved in mv datamap creation, then
TableProperties of Parent table
+ (if not present in a aggregate function like sum(col)) like SORT_COLUMNS,
SORT_SCOPE, TABLE_BLOCKSIZE,
+ FLAT_FOLDER, LONG_STRING_COLUMNS, LOCAL_DICTIONARY_ENABLE,
LOCAL_DICTIONARY_THRESHOLD,
+ LOCAL_DICTIONARY_INCLUDE, LOCAL_DICTIONARY_EXCLUDE, DICTIONARY_INCLUDE,
DICTIONARY_EXCLUDE,
+ INVERTED_INDEX, NO_INVERTED_INDEX, COLUMN_COMPRESSOR will be inherited to
datamap table
+ * All columns of main table at once cannot participate in mv datamap table
creation
+ * TableProperties can be provided in DMProperties excluding
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation
for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292315623
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
+ against the selected datamap instead of the main table. Since the data size
of MV datamap is
+ smaller, user queries are much faster.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create MV tables using the Create DataMap DDL
+
+ ```
+ CREATE DATAMAP agg_sales
+ ON TABLE sales
+ USING "MV"
+ AS
+SELECT country, sex, sum(quantity), avg(price)
+FROM sales
+GROUP BY country, sex
+ ```
+ **NOTE**:
+ * Group by/Filter columns has to be provided in projection list while
creating mv datamap
+ * If only one parent table is involved in mv datamap creation, then
TableProperties of Parent table
+ (if not present in a aggregate function like sum(col)) like SORT_COLUMNS,
SORT_SCOPE, TABLE_BLOCKSIZE,
+ FLAT_FOLDER, LONG_STRING_COLUMNS, LOCAL_DICTIONARY_ENABLE,
LOCAL_DICTIONARY_THRESHOLD,
+ LOCAL_DICTIONARY_INCLUDE, LOCAL_DICTIONARY_EXCLUDE, DICTIONARY_INCLUDE,
DICTIONARY_EXCLUDE,
+ INVERTED_INDEX, NO_INVERTED_INDEX, COLUMN_COMPRESSOR will be inherited to
datamap table
+ * All columns of main table at once cannot participate in mv datamap table
creation
+ * TableProperties can be provided in DMProperties excluding
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation
for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292306290
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
Review comment:
`join capabilities also` to `join capabilities`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation
for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292306978
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
Review comment:
`can be lazy or non-lazy datamap` or `can be a lazy or a non-lazy datamap`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation
for mv
URL: https://github.com/apache/carbondata/pull/3275#discussion_r292316351
##
File path: docs/datamap/mv-datamap-guide.md
##
@@ -0,0 +1,265 @@
+
+
+# CarbonData MV DataMap
+
+* [Quick Example](#quick-example)
+* [MV DataMap](#mv-datamap-introduction)
+* [Loading Data](#loading-data)
+* [Querying Data](#querying-data)
+* [Compaction](#compacting-mv-tables)
+* [Data Management](#data-management-with-mv-tables)
+
+## Quick example
+Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME
+
+Package carbon jar, and copy
assembly/target/scala-2.11/carbondata_2.11-x.x.x-SNAPSHOT-shade-hadoop2.7.2.jar
to $SPARK_HOME/jars
+```shell
+mvn clean package -DskipTests -Pspark-2.2 -Pmv
+```
+
+Start spark-shell in new terminal, type :paste, then copy and run the
following code.
+```scala
+ import java.io.File
+ import org.apache.spark.sql.{CarbonEnv, SparkSession}
+ import org.apache.spark.sql.CarbonSession._
+ import org.apache.spark.sql.streaming.{ProcessingTime, StreamingQuery}
+ import org.apache.carbondata.core.util.path.CarbonStorePath
+
+ val warehouse = new File("./warehouse").getCanonicalPath
+ val metastore = new File("./metastore").getCanonicalPath
+
+ val spark = SparkSession
+ .builder()
+ .master("local")
+ .appName("MVDatamapExample")
+ .config("spark.sql.warehouse.dir", warehouse)
+ .getOrCreateCarbonSession(warehouse, metastore)
+
+ spark.sparkContext.setLogLevel("ERROR")
+
+ // drop table if exists previously
+ spark.sql(s"DROP TABLE IF EXISTS sales")
+
+ // Create main table
+ spark.sql(
+ s"""
+ | CREATE TABLE sales (
+ | user_id string,
+ | country string,
+ | quantity int,
+ | price bigint)
+ | STORED AS carbondata
+""".stripMargin)
+
+ // Create mv datamap table on the main table
+ // If main table already have data, following command
+ // will trigger one immediate load to the mv table
+ spark.sql(
+ s"""
+ | CREATE DATAMAP agg_sales
+ | ON TABLE sales
+ | USING "mv"
+ | AS
+ | SELECT country, sum(quantity), avg(price)
+ | FROM sales
+ | GROUP BY country
+""".stripMargin)
+
+ import spark.implicits._
+ import org.apache.spark.sql.SaveMode
+ import scala.util.Random
+
+ // Load data to the main table, it will also
+ // trigger immediate load to mv table in case of non-lazy datamap.
+ val r = new Random()
+ spark.sparkContext.parallelize(1 to 10)
+ .map(x => ("ID." + r.nextInt(10), "country" + x % 8, x % 50, x % 60))
+ .toDF("user_id", "country", "quantity", "price")
+ .write
+ .format("carbondata")
+ .option("tableName", "sales")
+ .option("compress", "true")
+ .mode(SaveMode.Append)
+ .save()
+
+ spark.sql(
+s"""
+ |SELECT country, sum(quantity), avg(price)
+ | from sales GROUP BY country
+ """.stripMargin).show
+
+ spark.stop
+```
+
+## MV DataMap Introduction
+ Pre-aggregate datamap supports only aggregation on single table. MV datamap
was implemented to
+ support projection, projection with filter, aggregation and join
capabilities also. MV tables are
+ created as DataMaps and managed as tables internally by CarbonData. User can
create as many MV
+ datamaps required to improve query performance, provided the storage
requirements and loading
+ speeds are acceptable.
+
+ MV datamap can be lazy or non-lazy datamap. Once MV datamaps are created,
CarbonData's
+ CarbonAnalyzer supports to select the most efficient MV datamap and rewrite
the SQL to query
+ against the selected datamap instead of the main table. Since the data size
of MV datamap is
+ smaller, user queries are much faster.
+
+ For instance, main table called **sales** which is defined as
+
+ ```
+ CREATE TABLE sales (
+order_time timestamp,
+user_id string,
+sex string,
+country string,
+quantity int,
+price bigint)
+ STORED AS carbondata
+ ```
+
+ User can create MV tables using the Create DataMap DDL
+
+ ```
+ CREATE DATAMAP agg_sales
+ ON TABLE sales
+ USING "MV"
+ AS
+SELECT country, sex, sum(quantity), avg(price)
+FROM sales
+GROUP BY country, sex
+ ```
+ **NOTE**:
+ * Group by/Filter columns has to be provided in projection list while
creating mv datamap
+ * If only one parent table is involved in mv datamap creation, then
TableProperties of Parent table
+ (if not present in a aggregate function like sum(col)) like SORT_COLUMNS,
SORT_SCOPE, TABLE_BLOCKSIZE,
+ FLAT_FOLDER, LONG_STRING_COLUMNS, LOCAL_DICTIONARY_ENABLE,
LOCAL_DICTIONARY_THRESHOLD,
+ LOCAL_DICTIONARY_INCLUDE, LOCAL_DICTIONARY_EXCLUDE, DICTIONARY_INCLUDE,
DICTIONARY_EXCLUDE,
+ INVERTED_INDEX, NO_INVERTED_INDEX, COLUMN_COMPRESSOR will be inherited to
datamap table
+ * All columns of main table at once cannot participate in mv datamap table
creation
+ * TableProperties can be provided in DMProperties excluding
[GitHub] [carbondata] akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv
akashrn5 commented on a change in pull request #3275: [WIP]Added documentation for mv URL: https://github.com/apache/carbondata/pull/3275#discussion_r292304791 ## File path: docs/datamap/mv-datamap-guide.md ## @@ -0,0 +1,265 @@ + + +# CarbonData MV DataMap + +* [Quick Example](#quick-example) +* [MV DataMap](#mv-datamap-introduction) +* [Loading Data](#loading-data) +* [Querying Data](#querying-data) +* [Compaction](#compacting-mv-tables) +* [Data Management](#data-management-with-mv-tables) + +## Quick example +Download and unzip spark-2.2.0-bin-hadoop2.7.tgz, and export $SPARK_HOME Review comment: may be here you can create a link to preaggregate doc, instead of copying the same lines This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] lamber-ken commented on issue #3270: [CARBONDATA-3422] fix missing complex dimensions when prepare the data from raw object
lamber-ken commented on issue #3270: [CARBONDATA-3422] fix missing complex dimensions when prepare the data from raw object URL: https://github.com/apache/carbondata/pull/3270#issuecomment-500785878 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV
CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV URL: https://github.com/apache/carbondata/pull/3245#issuecomment-500779882 Build Failed with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3701/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV
CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV URL: https://github.com/apache/carbondata/pull/3245#issuecomment-500779694 Build Failed with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11767/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3275: [WIP]Added documentation for mv
CarbonDataQA commented on issue #3275: [WIP]Added documentation for mv URL: https://github.com/apache/carbondata/pull/3275#issuecomment-500779096 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3699/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3274: [CARBONDATA-3398] Fix drop metacache on table having mv datamap
CarbonDataQA commented on issue #3274: [CARBONDATA-3398] Fix drop metacache on table having mv datamap URL: https://github.com/apache/carbondata/pull/3274#issuecomment-500778410 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3698/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3275: [WIP]Added documentation for mv
CarbonDataQA commented on issue #3275: [WIP]Added documentation for mv URL: https://github.com/apache/carbondata/pull/3275#issuecomment-50087 Build Success with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11765/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV
CarbonDataQA commented on issue #3245: [CARBONDATA-3398] Handled show cache for index server and MV URL: https://github.com/apache/carbondata/pull/3245#issuecomment-500777425 Build Failed with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3497/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] kunal642 commented on a change in pull request #3245: [CARBONDATA-3398] Handled show cache for index server and MV
kunal642 commented on a change in pull request #3245: [CARBONDATA-3398] Handled
show cache for index server and MV
URL: https://github.com/apache/carbondata/pull/3245#discussion_r292374118
##
File path:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/cache/CarbonShowCacheCommand.scala
##
@@ -62,216 +68,397 @@ case class CarbonShowCacheCommand(tableIdentifier:
Option[TableIdentifier],
}
}
- override protected def opName: String = "SHOW CACHE"
+ override def processMetadata(sparkSession: SparkSession): Seq[Row] = {
+if (tableIdentifier.isEmpty) {
+ /**
+ * Assemble result for database
+ */
+ getAllTablesCache(sparkSession)
+} else {
+ /**
+ * Assemble result for table
+ */
+ val carbonTable =
CarbonEnv.getCarbonTable(tableIdentifier.get)(sparkSession)
+ Checker
+.validateTableExists(tableIdentifier.get.database,
tableIdentifier.get.table, sparkSession)
+ val numberOfIndexFiles = CacheUtil.getAllIndexFiles(carbonTable).size
+ val driverRawResults = getTableCacheFromDriver(sparkSession,
carbonTable, numberOfIndexFiles)
+ val indexRawResults = if
(CarbonProperties.getInstance().isDistributedPruningEnabled
+
(tableIdentifier.get.database.getOrElse(sparkSession.catalog.currentDatabase),
+tableIdentifier.get.table)) {
+getTableCacheFromIndexServer(carbonTable,
numberOfIndexFiles)(sparkSession)
+ } else { Seq() }
+ val result = driverRawResults.slice(0, 2) ++
+ driverRawResults.drop(2).map { row =>
+ Row(row.get(0), row.getLong(1) + row.getLong(2),
row.get(3))
+ }
+ val serverResults = indexRawResults.slice(0, 2) ++
+ indexRawResults.drop(2).map { row =>
+Row(row.get(0), row.getLong(1) + row.getLong(2),
row.get(3))
+ }
+ Seq(Row("DRIVER CACHE", "", "")) ++ result.map {
+row =>
+ Row(row.get(0), bytesToDisplaySize(row.getLong(1)), row.get(2))
+ } ++ (serverResults match {
+case Nil => Seq()
+case list =>
+ Seq(Row("---", "---", "---"), Row("INDEX
CACHE", "", "")) ++
+ list.map {
+ row => Row(row.get(0), bytesToDisplaySize(row.getLong(1)),
row.get(2))
+}
+ })
+}
+ }
def getAllTablesCache(sparkSession: SparkSession): Seq[Row] = {
val currentDatabase = sparkSession.sessionState.catalog.getCurrentDatabase
val cache = CacheProvider.getInstance().getCarbonCache
-if (cache == null) {
- Seq(
-Row("ALL", "ALL", 0L, 0L, 0L),
-Row(currentDatabase, "ALL", 0L, 0L, 0L))
-} else {
- var carbonTables = mutable.ArrayBuffer[CarbonTable]()
- sparkSession.sessionState.catalog.listTables(currentDatabase).foreach {
-tableIdent =>
+val isDistributedPruningEnabled = CarbonProperties.getInstance()
+ .isDistributedPruningEnabled("", "")
+if (cache == null && !isDistributedPruningEnabled) {
+ return makeEmptyCacheRows(currentDatabase)
+}
+var carbonTables = mutable.ArrayBuffer[CarbonTable]()
+sparkSession.sessionState.catalog.listTables(currentDatabase).foreach {
+ tableIdent =>
+try {
+ val carbonTable = CarbonEnv.getCarbonTable(tableIdent)(sparkSession)
+ if (!carbonTable.isChildDataMap && !carbonTable.isChildTable) {
+carbonTables += carbonTable
+ }
+} catch {
+ case _: NoSuchTableException =>
+LOGGER.debug("Ignoring non-carbon table " + tableIdent.table)
+}
+}
+val indexServerRows = if (isDistributedPruningEnabled) {
+ carbonTables.flatMap {
+mainTable =>
try {
-val carbonTable =
CarbonEnv.getCarbonTable(tableIdent)(sparkSession)
-if (!carbonTable.isChildDataMap) {
- carbonTables += carbonTable
-}
+makeRows(getTableCacheFromIndexServer(mainTable)(sparkSession),
mainTable)
} catch {
-case ex: NoSuchTableException =>
- LOGGER.debug("Ignoring non-carbon table " + tableIdent.table)
+case ex: UnsupportedOperationException => Seq()
}
}
+} else { Seq() }
- // All tables of current database
- var (dbDatamapSize, dbDictSize) = (0L, 0L)
- val tableList = carbonTables.flatMap {
+val driverRows = if (cache != null) {
+ carbonTables.flatMap {
carbonTable =>
try {
-val tableResult = getTableCache(sparkSession, carbonTable)
-var (indexSize, datamapSize) = (tableResult(0).getLong(1), 0L)
-tableResult.drop(2).foreach {
- row =>
-indexSize += row.getLong(1)
-datamapSize += row.getLong(2)
-}
-val dictSize = tableResult(1).getLong(1)
-
-
[GitHub] [carbondata] kunal642 commented on a change in pull request #3245: [CARBONDATA-3398] Handled show cache for index server and MV
kunal642 commented on a change in pull request #3245: [CARBONDATA-3398] Handled
show cache for index server and MV
URL: https://github.com/apache/carbondata/pull/3245#discussion_r292373470
##
File path:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/cache/CarbonShowCacheCommand.scala
##
@@ -62,216 +68,397 @@ case class CarbonShowCacheCommand(tableIdentifier:
Option[TableIdentifier],
}
}
- override protected def opName: String = "SHOW CACHE"
+ override def processMetadata(sparkSession: SparkSession): Seq[Row] = {
+if (tableIdentifier.isEmpty) {
+ /**
+ * Assemble result for database
+ */
+ getAllTablesCache(sparkSession)
+} else {
+ /**
+ * Assemble result for table
+ */
+ val carbonTable =
CarbonEnv.getCarbonTable(tableIdentifier.get)(sparkSession)
+ Checker
+.validateTableExists(tableIdentifier.get.database,
tableIdentifier.get.table, sparkSession)
+ val numberOfIndexFiles = CacheUtil.getAllIndexFiles(carbonTable).size
+ val driverRawResults = getTableCacheFromDriver(sparkSession,
carbonTable, numberOfIndexFiles)
+ val indexRawResults = if
(CarbonProperties.getInstance().isDistributedPruningEnabled
+
(tableIdentifier.get.database.getOrElse(sparkSession.catalog.currentDatabase),
+tableIdentifier.get.table)) {
+getTableCacheFromIndexServer(carbonTable,
numberOfIndexFiles)(sparkSession)
+ } else { Seq() }
+ val result = driverRawResults.slice(0, 2) ++
+ driverRawResults.drop(2).map { row =>
+ Row(row.get(0), row.getLong(1) + row.getLong(2),
row.get(3))
+ }
+ val serverResults = indexRawResults.slice(0, 2) ++
+ indexRawResults.drop(2).map { row =>
+Row(row.get(0), row.getLong(1) + row.getLong(2),
row.get(3))
+ }
+ Seq(Row("DRIVER CACHE", "", "")) ++ result.map {
+row =>
+ Row(row.get(0), bytesToDisplaySize(row.getLong(1)), row.get(2))
+ } ++ (serverResults match {
+case Nil => Seq()
+case list =>
+ Seq(Row("---", "---", "---"), Row("INDEX
CACHE", "", "")) ++
+ list.map {
+ row => Row(row.get(0), bytesToDisplaySize(row.getLong(1)),
row.get(2))
+}
+ })
+}
+ }
def getAllTablesCache(sparkSession: SparkSession): Seq[Row] = {
val currentDatabase = sparkSession.sessionState.catalog.getCurrentDatabase
val cache = CacheProvider.getInstance().getCarbonCache
-if (cache == null) {
- Seq(
-Row("ALL", "ALL", 0L, 0L, 0L),
-Row(currentDatabase, "ALL", 0L, 0L, 0L))
-} else {
- var carbonTables = mutable.ArrayBuffer[CarbonTable]()
- sparkSession.sessionState.catalog.listTables(currentDatabase).foreach {
-tableIdent =>
+val isDistributedPruningEnabled = CarbonProperties.getInstance()
+ .isDistributedPruningEnabled("", "")
+if (cache == null && !isDistributedPruningEnabled) {
+ return makeEmptyCacheRows(currentDatabase)
+}
+var carbonTables = mutable.ArrayBuffer[CarbonTable]()
+sparkSession.sessionState.catalog.listTables(currentDatabase).foreach {
+ tableIdent =>
+try {
+ val carbonTable = CarbonEnv.getCarbonTable(tableIdent)(sparkSession)
+ if (!carbonTable.isChildDataMap && !carbonTable.isChildTable) {
+carbonTables += carbonTable
+ }
+} catch {
+ case _: NoSuchTableException =>
+LOGGER.debug("Ignoring non-carbon table " + tableIdent.table)
+}
+}
+val indexServerRows = if (isDistributedPruningEnabled) {
+ carbonTables.flatMap {
+mainTable =>
try {
-val carbonTable =
CarbonEnv.getCarbonTable(tableIdent)(sparkSession)
-if (!carbonTable.isChildDataMap) {
- carbonTables += carbonTable
-}
+makeRows(getTableCacheFromIndexServer(mainTable)(sparkSession),
mainTable)
} catch {
-case ex: NoSuchTableException =>
- LOGGER.debug("Ignoring non-carbon table " + tableIdent.table)
+case ex: UnsupportedOperationException => Seq()
}
}
+} else { Seq() }
- // All tables of current database
- var (dbDatamapSize, dbDictSize) = (0L, 0L)
- val tableList = carbonTables.flatMap {
+val driverRows = if (cache != null) {
+ carbonTables.flatMap {
carbonTable =>
try {
-val tableResult = getTableCache(sparkSession, carbonTable)
-var (indexSize, datamapSize) = (tableResult(0).getLong(1), 0L)
-tableResult.drop(2).foreach {
- row =>
-indexSize += row.getLong(1)
-datamapSize += row.getLong(2)
-}
-val dictSize = tableResult(1).getLong(1)
-
-
[GitHub] [carbondata] CarbonDataQA commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's
CarbonDataQA commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's URL: https://github.com/apache/carbondata/pull/3264#issuecomment-500771426 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3700/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's
CarbonDataQA commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's URL: https://github.com/apache/carbondata/pull/3264#issuecomment-500749106 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3496/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's
CarbonDataQA commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's URL: https://github.com/apache/carbondata/pull/3264#issuecomment-500746443 Build Failed with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11766/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's
Indhumathi27 commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's URL: https://github.com/apache/carbondata/pull/3264#issuecomment-500745418 Retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's
CarbonDataQA commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's URL: https://github.com/apache/carbondata/pull/3264#issuecomment-500744719 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3697/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3274: [CARBONDATA-3398] Fix drop metacache on table having mv datamap
CarbonDataQA commented on issue #3274: [CARBONDATA-3398] Fix drop metacache on table having mv datamap URL: https://github.com/apache/carbondata/pull/3274#issuecomment-500742122 Build Success with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11764/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] zhxiaoping removed a comment on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL
zhxiaoping removed a comment on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL URL: https://github.com/apache/carbondata/pull/3209#issuecomment-500734851 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] zhxiaoping commented on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL
zhxiaoping commented on issue #3209: [CARBONDATA-3373] Optimize scenes with in numbers in SQL URL: https://github.com/apache/carbondata/pull/3209#issuecomment-500734851 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3260: [HOTFIX] Fix compatibility issue with page size
CarbonDataQA commented on issue #3260: [HOTFIX] Fix compatibility issue with page size URL: https://github.com/apache/carbondata/pull/3260#issuecomment-500730571 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3693/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3275: [WIP]Added documentation for mv
CarbonDataQA commented on issue #3275: [WIP]Added documentation for mv URL: https://github.com/apache/carbondata/pull/3275#issuecomment-500727839 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3495/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3256: [CARBONDATA-3413] Fix io.netty out of direct memory exception in arrow integration
CarbonDataQA commented on issue #3256: [CARBONDATA-3413] Fix io.netty out of direct memory exception in arrow integration URL: https://github.com/apache/carbondata/pull/3256#issuecomment-500719569 Build Success with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11760/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3254: [CARBONDATA-3411] [CARBONDATA-3414] Fix clear datamaps logs an exception in SDK
CarbonDataQA commented on issue #3254: [CARBONDATA-3411] [CARBONDATA-3414] Fix clear datamaps logs an exception in SDK URL: https://github.com/apache/carbondata/pull/3254#issuecomment-500718563 Build Success with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11761/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3260: [HOTFIX] Fix compatibility issue with page size
CarbonDataQA commented on issue #3260: [HOTFIX] Fix compatibility issue with page size URL: https://github.com/apache/carbondata/pull/3260#issuecomment-500718558 Build Success with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11759/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 opened a new pull request #3275: [WIP]Added documentation for mv
Indhumathi27 opened a new pull request #3275: [WIP]Added documentation for mv URL: https://github.com/apache/carbondata/pull/3275 Added documentation for mv datamap - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3274: [CARBONDATA-3398] Fix drop metacache on table having mv datamap
CarbonDataQA commented on issue #3274: [CARBONDATA-3398] Fix drop metacache on table having mv datamap URL: https://github.com/apache/carbondata/pull/3274#issuecomment-500713844 Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3494/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Created] (CARBONDATA-3425) Add Documentation for MV datamap
Indhumathi Muthumurugesh created CARBONDATA-3425: Summary: Add Documentation for MV datamap Key: CARBONDATA-3425 URL: https://issues.apache.org/jira/browse/CARBONDATA-3425 Project: CarbonData Issue Type: Sub-task Reporter: Indhumathi Muthumurugesh -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [carbondata] CarbonDataQA commented on issue #3256: [CARBONDATA-3413] Fix io.netty out of direct memory exception in arrow integration
CarbonDataQA commented on issue #3256: [CARBONDATA-3413] Fix io.netty out of direct memory exception in arrow integration URL: https://github.com/apache/carbondata/pull/3256#issuecomment-500712231 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3694/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3254: [CARBONDATA-3411] [CARBONDATA-3414] Fix clear datamaps logs an exception in SDK
CarbonDataQA commented on issue #3254: [CARBONDATA-3411] [CARBONDATA-3414] Fix clear datamaps logs an exception in SDK URL: https://github.com/apache/carbondata/pull/3254#issuecomment-500711046 Build Success with Spark 2.2.1, Please check CI http://95.216.28.178:8080/job/ApacheCarbonPRBuilder1/3696/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] Indhumathi27 opened a new pull request #3274: [CARBONDATA-3398] Fix drop metacache on table having mv datamap
Indhumathi27 opened a new pull request #3274: [CARBONDATA-3398] Fix drop metacache on table having mv datamap URL: https://github.com/apache/carbondata/pull/3274 This PR dependent on [PR-3245](https://github.com/apache/carbondata/pull/3245) Fixed drop metacache on table having mv datamap - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [x] Testing done - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's
CarbonDataQA commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's URL: https://github.com/apache/carbondata/pull/3264#issuecomment-500709632 Build Failed with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder2.1/3493/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [carbondata] CarbonDataQA commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's
CarbonDataQA commented on issue #3264: [CARBONDATA-3418] Inherit Column Compressor Property from parent table to its child table's URL: https://github.com/apache/carbondata/pull/3264#issuecomment-500709391 Build Failed with Spark 2.3.2, Please check CI http://136.243.101.176:8080/job/carbondataprbuilder2.3/11763/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services