[GitHub] carbondata pull request #1856: [CARBONDATA-2073][CARBONDATA-1516][Tests] Add...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1856#discussion_r174058314
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/integration/spark/testsuite/timeseries/TestTimeSeriesCreateTable.scala
---
@@ -241,12 +311,12 @@ class TestTimeSeriesCreateTable extends QueryTest
with BeforeAndAfterAll {
assert(e.getMessage.equals("Only one granularity level can be
defined"))
}
- test("test timeseries create table 14: Only one granularity level can be
defined 2") {
-sql("DROP DATAMAP IF EXISTS agg0_second ON TABLE mainTable")
+ test("test timeseries create table 17: Only one granularity level can be
defined 2") {
+sql("DROP DATAMAP IF EXISTS agg0_hour ON TABLE mainTable")
--- End diff --
why change just the name of the table??
---
[GitHub] carbondata pull request #1856: [CARBONDATA-2073][CARBONDATA-1516][Tests] Add...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1856#discussion_r174056762
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/integration/spark/testsuite/timeseries/TestTimeSeriesCreateTable.scala
---
@@ -82,149 +92,209 @@ class TestTimeSeriesCreateTable extends QueryTest
with BeforeAndAfterAll {
""".stripMargin)
}
+ override def afterEach(): Unit = {
+dropDataMaps("mainTable", "agg1_second", "agg1_minute",
+ "agg1_hour", "agg1_day", "agg1_month", "agg1_year")
+ }
+
test("test timeseries create table 1") {
checkExistence(sql("DESCRIBE FORMATTED mainTable_agg0_second"), true,
"maintable_agg0_second")
-sql("drop datamap agg0_second on table mainTable")
+sql("DROP DATAMAP agg0_second ON TABLE mainTable")
--- End diff --
why is this change necessary??
---
[GitHub] carbondata pull request #2042: [CARBONDATA-2236]added sdv test cases for sta...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2042#discussion_r173369924
--- Diff:
integration/spark-common-cluster-test/src/test/scala/org/apache/carbondata/cluster/sdv/generated/StandardPartitionTestCase.scala
---
@@ -0,0 +1,436 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.cluster.sdv.generated
+
+import org.apache.carbondata.core.constants.CarbonCommonConstants
+import org.apache.carbondata.core.util.CarbonProperties
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.common.util._
+import org.scalatest.BeforeAndAfterAll
+
+/**
+ * Test Class for partitionTestCase to verify all scenerios
+ */
+
+class StandardPartitionTestCase extends QueryTest with BeforeAndAfterAll {
+
+ override def beforeAll = {
+CarbonProperties.getInstance()
+ .addProperty(CarbonCommonConstants.CARBON_TIMESTAMP_FORMAT,
"/MM/dd HH:mm:ss")
+ .addProperty(CarbonCommonConstants.CARBON_DATE_FORMAT, "/MM/dd")
+ }
+ //Verify exception if column in partitioned by is already specified in
table schema
+
+ test("Standard-Partition_TC001", Include) {
+intercept[Exception] {
+ sql(s"""drop table if exists uniqdata""")
+ sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double,INTEGER_COLUMN1
int) PARTITIONED BY (INTEGER_COLUMN1 int)STORED BY
'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+}
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition
+ test("Standard-Partition_TC002", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double) PARTITIONED BY
(INTEGER_COLUMN1 int)STORED BY 'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+val df = sql(s"""DESC uniqdata""")
+
assert(df.collect().reverse.head.get(0).toString.toUpperCase.contains("INTEGER_COLUMN1"))
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition with table comment
+
+ test("Standard-Partition_TC003",Include) {
+sql(s"""drop table if exists partition_table""")
+sql(s"""CREATE TABLE partition_table(shortField SHORT, intField INT,
bigintField LONG, doubleField DOUBLE, decimalField DECIMAL(18,2), charField
CHAR(5), floatField FLOAT ) COMMENT 'partition_table' PARTITIONED BY
(stringField STRING) STORED BY 'carbondata'""")
+val df = sql(s"""DESC formatted partition_table""")
+checkExistence(df, true, "partition_table")
+ }
+
+ //Verify WHEN partitioned by is not specified in the DDL, but partition
type,number of partitions and list info are given
+ test("Standard-Partition_TC004", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Doubl
[GitHub] carbondata pull request #2042: [CARBONDATA-2236]added sdv test cases for sta...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2042#discussion_r173369580
--- Diff:
integration/spark-common-cluster-test/src/test/scala/org/apache/carbondata/cluster/sdv/generated/StandardPartitionTestCase.scala
---
@@ -0,0 +1,436 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.cluster.sdv.generated
+
+import org.apache.carbondata.core.constants.CarbonCommonConstants
+import org.apache.carbondata.core.util.CarbonProperties
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.common.util._
+import org.scalatest.BeforeAndAfterAll
+
+/**
+ * Test Class for partitionTestCase to verify all scenerios
+ */
+
+class StandardPartitionTestCase extends QueryTest with BeforeAndAfterAll {
+
+ override def beforeAll = {
+CarbonProperties.getInstance()
+ .addProperty(CarbonCommonConstants.CARBON_TIMESTAMP_FORMAT,
"/MM/dd HH:mm:ss")
+ .addProperty(CarbonCommonConstants.CARBON_DATE_FORMAT, "/MM/dd")
+ }
+ //Verify exception if column in partitioned by is already specified in
table schema
+
+ test("Standard-Partition_TC001", Include) {
+intercept[Exception] {
+ sql(s"""drop table if exists uniqdata""")
+ sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double,INTEGER_COLUMN1
int) PARTITIONED BY (INTEGER_COLUMN1 int)STORED BY
'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+}
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition
+ test("Standard-Partition_TC002", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double) PARTITIONED BY
(INTEGER_COLUMN1 int)STORED BY 'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+val df = sql(s"""DESC uniqdata""")
+
assert(df.collect().reverse.head.get(0).toString.toUpperCase.contains("INTEGER_COLUMN1"))
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition with table comment
+
+ test("Standard-Partition_TC003",Include) {
+sql(s"""drop table if exists partition_table""")
+sql(s"""CREATE TABLE partition_table(shortField SHORT, intField INT,
bigintField LONG, doubleField DOUBLE, decimalField DECIMAL(18,2), charField
CHAR(5), floatField FLOAT ) COMMENT 'partition_table' PARTITIONED BY
(stringField STRING) STORED BY 'carbondata'""")
+val df = sql(s"""DESC formatted partition_table""")
+checkExistence(df, true, "partition_table")
+ }
+
+ //Verify WHEN partitioned by is not specified in the DDL, but partition
type,number of partitions and list info are given
+ test("Standard-Partition_TC004", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Doubl
[GitHub] carbondata pull request #2042: [CARBONDATA-2236]added sdv test cases for sta...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2042#discussion_r173369404
--- Diff:
integration/spark-common-cluster-test/src/test/scala/org/apache/carbondata/cluster/sdv/generated/StandardPartitionTestCase.scala
---
@@ -0,0 +1,436 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.cluster.sdv.generated
+
+import org.apache.carbondata.core.constants.CarbonCommonConstants
+import org.apache.carbondata.core.util.CarbonProperties
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.common.util._
+import org.scalatest.BeforeAndAfterAll
+
+/**
+ * Test Class for partitionTestCase to verify all scenerios
+ */
+
+class StandardPartitionTestCase extends QueryTest with BeforeAndAfterAll {
+
+ override def beforeAll = {
+CarbonProperties.getInstance()
+ .addProperty(CarbonCommonConstants.CARBON_TIMESTAMP_FORMAT,
"/MM/dd HH:mm:ss")
+ .addProperty(CarbonCommonConstants.CARBON_DATE_FORMAT, "/MM/dd")
+ }
+ //Verify exception if column in partitioned by is already specified in
table schema
+
+ test("Standard-Partition_TC001", Include) {
+intercept[Exception] {
+ sql(s"""drop table if exists uniqdata""")
+ sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double,INTEGER_COLUMN1
int) PARTITIONED BY (INTEGER_COLUMN1 int)STORED BY
'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+}
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition
+ test("Standard-Partition_TC002", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double) PARTITIONED BY
(INTEGER_COLUMN1 int)STORED BY 'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+val df = sql(s"""DESC uniqdata""")
+
assert(df.collect().reverse.head.get(0).toString.toUpperCase.contains("INTEGER_COLUMN1"))
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition with table comment
+
+ test("Standard-Partition_TC003",Include) {
+sql(s"""drop table if exists partition_table""")
+sql(s"""CREATE TABLE partition_table(shortField SHORT, intField INT,
bigintField LONG, doubleField DOUBLE, decimalField DECIMAL(18,2), charField
CHAR(5), floatField FLOAT ) COMMENT 'partition_table' PARTITIONED BY
(stringField STRING) STORED BY 'carbondata'""")
+val df = sql(s"""DESC formatted partition_table""")
+checkExistence(df, true, "partition_table")
+ }
+
+ //Verify WHEN partitioned by is not specified in the DDL, but partition
type,number of partitions and list info are given
+ test("Standard-Partition_TC004", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Doubl
[GitHub] carbondata pull request #2042: [CARBONDATA-2236]added sdv test cases for sta...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2042#discussion_r173369982
--- Diff:
integration/spark-common-cluster-test/src/test/scala/org/apache/carbondata/cluster/sdv/generated/StandardPartitionTestCase.scala
---
@@ -0,0 +1,436 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.cluster.sdv.generated
+
+import org.apache.carbondata.core.constants.CarbonCommonConstants
+import org.apache.carbondata.core.util.CarbonProperties
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.common.util._
+import org.scalatest.BeforeAndAfterAll
+
+/**
+ * Test Class for partitionTestCase to verify all scenerios
+ */
+
+class StandardPartitionTestCase extends QueryTest with BeforeAndAfterAll {
+
+ override def beforeAll = {
+CarbonProperties.getInstance()
+ .addProperty(CarbonCommonConstants.CARBON_TIMESTAMP_FORMAT,
"/MM/dd HH:mm:ss")
+ .addProperty(CarbonCommonConstants.CARBON_DATE_FORMAT, "/MM/dd")
+ }
+ //Verify exception if column in partitioned by is already specified in
table schema
+
+ test("Standard-Partition_TC001", Include) {
+intercept[Exception] {
+ sql(s"""drop table if exists uniqdata""")
+ sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double,INTEGER_COLUMN1
int) PARTITIONED BY (INTEGER_COLUMN1 int)STORED BY
'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+}
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition
+ test("Standard-Partition_TC002", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double) PARTITIONED BY
(INTEGER_COLUMN1 int)STORED BY 'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+val df = sql(s"""DESC uniqdata""")
+
assert(df.collect().reverse.head.get(0).toString.toUpperCase.contains("INTEGER_COLUMN1"))
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition with table comment
+
+ test("Standard-Partition_TC003",Include) {
+sql(s"""drop table if exists partition_table""")
+sql(s"""CREATE TABLE partition_table(shortField SHORT, intField INT,
bigintField LONG, doubleField DOUBLE, decimalField DECIMAL(18,2), charField
CHAR(5), floatField FLOAT ) COMMENT 'partition_table' PARTITIONED BY
(stringField STRING) STORED BY 'carbondata'""")
+val df = sql(s"""DESC formatted partition_table""")
+checkExistence(df, true, "partition_table")
+ }
+
+ //Verify WHEN partitioned by is not specified in the DDL, but partition
type,number of partitions and list info are given
+ test("Standard-Partition_TC004", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Doubl
[GitHub] carbondata pull request #2042: [CARBONDATA-2236]added sdv test cases for sta...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2042#discussion_r173367821
--- Diff:
integration/spark-common-cluster-test/src/test/scala/org/apache/carbondata/cluster/sdv/generated/StandardPartitionTestCase.scala
---
@@ -0,0 +1,436 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.cluster.sdv.generated
+
+import org.apache.carbondata.core.constants.CarbonCommonConstants
+import org.apache.carbondata.core.util.CarbonProperties
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.common.util._
+import org.scalatest.BeforeAndAfterAll
+
+/**
+ * Test Class for partitionTestCase to verify all scenerios
+ */
+
+class StandardPartitionTestCase extends QueryTest with BeforeAndAfterAll {
+
+ override def beforeAll = {
+CarbonProperties.getInstance()
+ .addProperty(CarbonCommonConstants.CARBON_TIMESTAMP_FORMAT,
"/MM/dd HH:mm:ss")
+ .addProperty(CarbonCommonConstants.CARBON_DATE_FORMAT, "/MM/dd")
+ }
+ //Verify exception if column in partitioned by is already specified in
table schema
+
+ test("Standard-Partition_TC001", Include) {
+intercept[Exception] {
+ sql(s"""drop table if exists uniqdata""")
+ sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double,INTEGER_COLUMN1
int) PARTITIONED BY (INTEGER_COLUMN1 int)STORED BY
'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+}
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition
+ test("Standard-Partition_TC002", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double) PARTITIONED BY
(INTEGER_COLUMN1 int)STORED BY 'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+val df = sql(s"""DESC uniqdata""")
+
assert(df.collect().reverse.head.get(0).toString.toUpperCase.contains("INTEGER_COLUMN1"))
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition with table comment
+
+ test("Standard-Partition_TC003",Include) {
+sql(s"""drop table if exists partition_table""")
+sql(s"""CREATE TABLE partition_table(shortField SHORT, intField INT,
bigintField LONG, doubleField DOUBLE, decimalField DECIMAL(18,2), charField
CHAR(5), floatField FLOAT ) COMMENT 'partition_table' PARTITIONED BY
(stringField STRING) STORED BY 'carbondata'""")
+val df = sql(s"""DESC formatted partition_table""")
+checkExistence(df, true, "partition_table")
+ }
+
+ //Verify WHEN partitioned by is not specified in the DDL, but partition
type,number of partitions and list info are given
+ test("Standard-Partition_TC004", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Doubl
[GitHub] carbondata pull request #2042: [CARBONDATA-2236]added sdv test cases for sta...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2042#discussion_r173367335
--- Diff:
integration/spark-common-cluster-test/src/test/scala/org/apache/carbondata/cluster/sdv/generated/StandardPartitionTestCase.scala
---
@@ -0,0 +1,436 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.cluster.sdv.generated
+
+import org.apache.carbondata.core.constants.CarbonCommonConstants
+import org.apache.carbondata.core.util.CarbonProperties
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.common.util._
+import org.scalatest.BeforeAndAfterAll
+
+/**
+ * Test Class for partitionTestCase to verify all scenerios
+ */
+
+class StandardPartitionTestCase extends QueryTest with BeforeAndAfterAll {
+
+ override def beforeAll = {
+CarbonProperties.getInstance()
+ .addProperty(CarbonCommonConstants.CARBON_TIMESTAMP_FORMAT,
"/MM/dd HH:mm:ss")
+ .addProperty(CarbonCommonConstants.CARBON_DATE_FORMAT, "/MM/dd")
+ }
+ //Verify exception if column in partitioned by is already specified in
table schema
+
+ test("Standard-Partition_TC001", Include) {
+intercept[Exception] {
+ sql(s"""drop table if exists uniqdata""")
+ sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double,INTEGER_COLUMN1
int) PARTITIONED BY (INTEGER_COLUMN1 int)STORED BY
'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
--- End diff --
remove carbon partition syntax from all test cases
---
[GitHub] carbondata pull request #2042: [CARBONDATA-2236]added sdv test cases for sta...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2042#discussion_r173373691
--- Diff:
integration/spark-common-cluster-test/src/test/scala/org/apache/carbondata/cluster/sdv/generated/StandardPartitionTestCase.scala
---
@@ -0,0 +1,436 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.cluster.sdv.generated
+
+import org.apache.carbondata.core.constants.CarbonCommonConstants
+import org.apache.carbondata.core.util.CarbonProperties
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.common.util._
+import org.scalatest.BeforeAndAfterAll
+
+/**
+ * Test Class for partitionTestCase to verify all scenerios
+ */
+
+class StandardPartitionTestCase extends QueryTest with BeforeAndAfterAll {
+
+ override def beforeAll = {
+CarbonProperties.getInstance()
+ .addProperty(CarbonCommonConstants.CARBON_TIMESTAMP_FORMAT,
"/MM/dd HH:mm:ss")
+ .addProperty(CarbonCommonConstants.CARBON_DATE_FORMAT, "/MM/dd")
+ }
+ //Verify exception if column in partitioned by is already specified in
table schema
+
+ test("Standard-Partition_TC001", Include) {
+intercept[Exception] {
+ sql(s"""drop table if exists uniqdata""")
+ sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double,INTEGER_COLUMN1
int) PARTITIONED BY (INTEGER_COLUMN1 int)STORED BY
'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+}
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition
+ test("Standard-Partition_TC002", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double) PARTITIONED BY
(INTEGER_COLUMN1 int)STORED BY 'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+val df = sql(s"""DESC uniqdata""")
+
assert(df.collect().reverse.head.get(0).toString.toUpperCase.contains("INTEGER_COLUMN1"))
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition with table comment
+
+ test("Standard-Partition_TC003",Include) {
+sql(s"""drop table if exists partition_table""")
+sql(s"""CREATE TABLE partition_table(shortField SHORT, intField INT,
bigintField LONG, doubleField DOUBLE, decimalField DECIMAL(18,2), charField
CHAR(5), floatField FLOAT ) COMMENT 'partition_table' PARTITIONED BY
(stringField STRING) STORED BY 'carbondata'""")
+val df = sql(s"""DESC formatted partition_table""")
+checkExistence(df, true, "partition_table")
+ }
+
+ //Verify WHEN partitioned by is not specified in the DDL, but partition
type,number of partitions and list info are given
+ test("Standard-Partition_TC004", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Doubl
[GitHub] carbondata pull request #2042: [CARBONDATA-2236]added sdv test cases for sta...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2042#discussion_r173367883
--- Diff:
integration/spark-common-cluster-test/src/test/scala/org/apache/carbondata/cluster/sdv/generated/StandardPartitionTestCase.scala
---
@@ -0,0 +1,436 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.cluster.sdv.generated
+
+import org.apache.carbondata.core.constants.CarbonCommonConstants
+import org.apache.carbondata.core.util.CarbonProperties
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.common.util._
+import org.scalatest.BeforeAndAfterAll
+
+/**
+ * Test Class for partitionTestCase to verify all scenerios
+ */
+
+class StandardPartitionTestCase extends QueryTest with BeforeAndAfterAll {
+
+ override def beforeAll = {
+CarbonProperties.getInstance()
+ .addProperty(CarbonCommonConstants.CARBON_TIMESTAMP_FORMAT,
"/MM/dd HH:mm:ss")
+ .addProperty(CarbonCommonConstants.CARBON_DATE_FORMAT, "/MM/dd")
+ }
+ //Verify exception if column in partitioned by is already specified in
table schema
+
+ test("Standard-Partition_TC001", Include) {
+intercept[Exception] {
+ sql(s"""drop table if exists uniqdata""")
--- End diff --
move drop command outside intercept block from all tests
---
[GitHub] carbondata pull request #2042: [CARBONDATA-2236]added sdv test cases for sta...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2042#discussion_r173369434
--- Diff:
integration/spark-common-cluster-test/src/test/scala/org/apache/carbondata/cluster/sdv/generated/StandardPartitionTestCase.scala
---
@@ -0,0 +1,436 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.cluster.sdv.generated
+
+import org.apache.carbondata.core.constants.CarbonCommonConstants
+import org.apache.carbondata.core.util.CarbonProperties
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.common.util._
+import org.scalatest.BeforeAndAfterAll
+
+/**
+ * Test Class for partitionTestCase to verify all scenerios
+ */
+
+class StandardPartitionTestCase extends QueryTest with BeforeAndAfterAll {
+
+ override def beforeAll = {
+CarbonProperties.getInstance()
+ .addProperty(CarbonCommonConstants.CARBON_TIMESTAMP_FORMAT,
"/MM/dd HH:mm:ss")
+ .addProperty(CarbonCommonConstants.CARBON_DATE_FORMAT, "/MM/dd")
+ }
+ //Verify exception if column in partitioned by is already specified in
table schema
+
+ test("Standard-Partition_TC001", Include) {
+intercept[Exception] {
+ sql(s"""drop table if exists uniqdata""")
+ sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double,INTEGER_COLUMN1
int) PARTITIONED BY (INTEGER_COLUMN1 int)STORED BY
'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+}
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition
+ test("Standard-Partition_TC002", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double) PARTITIONED BY
(INTEGER_COLUMN1 int)STORED BY 'org.apache.carbondata.format'
TBLPROPERTIES('PARTITION_TYPE'='List','LIST_INFO'='1,3')""")
+val df = sql(s"""DESC uniqdata""")
+
assert(df.collect().reverse.head.get(0).toString.toUpperCase.contains("INTEGER_COLUMN1"))
+sql(s"""drop table if exists uniqdata""")
+ }
+
+ //Verify table is created with Partition with table comment
+
+ test("Standard-Partition_TC003",Include) {
+sql(s"""drop table if exists partition_table""")
+sql(s"""CREATE TABLE partition_table(shortField SHORT, intField INT,
bigintField LONG, doubleField DOUBLE, decimalField DECIMAL(18,2), charField
CHAR(5), floatField FLOAT ) COMMENT 'partition_table' PARTITIONED BY
(stringField STRING) STORED BY 'carbondata'""")
+val df = sql(s"""DESC formatted partition_table""")
+checkExistence(df, true, "partition_table")
+ }
+
+ //Verify WHEN partitioned by is not specified in the DDL, but partition
type,number of partitions and list info are given
+ test("Standard-Partition_TC004", Include) {
+sql(s"""drop table if exists uniqdata""")
+sql(s"""CREATE TABLE uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Doubl
[GitHub] carbondata issue #2033: [CARBONDATA-2227] Added support to show partition de...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/2033 retest this please ---
[GitHub] carbondata pull request #2033: [CARBONDATA-2227] Added support to show parti...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/2033 [CARBONDATA-2227] Added support to show partition details in describe formatted Added Detailed information in describe formatted command like **partition location** and **partition values**. To see detailed partition information use the DDL below descsribe formatted partition(=) 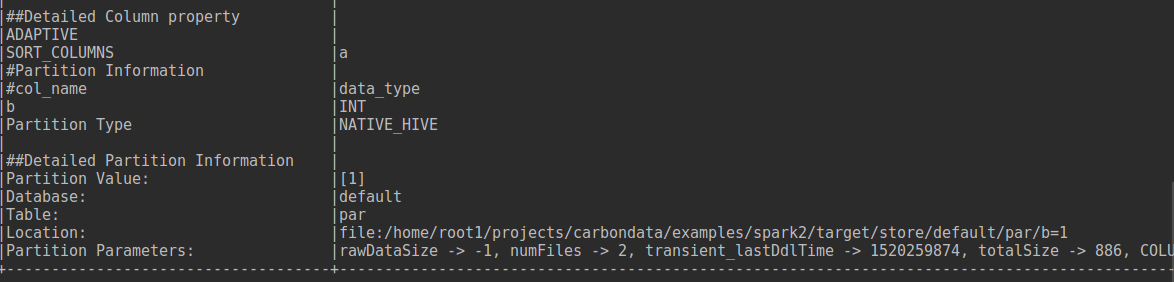 Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata partition_desc_formatted Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2033.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2033 commit 8d1a6c57a56bbd6fc651bd38f8e469aa4e97e96f Author: kunal642 <kunalkapoor642@...> Date: 2018-03-05T15:03:06Z added support to show partition details in describe formatted ---
[GitHub] carbondata issue #2017: [CARBONDATA-2217]fix drop partition for non existing...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/2017 LGTM ---
[GitHub] carbondata issue #1975: [CARBONDATA-2142] [CARBONDATA-1763] Fixed issues whi...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1975 retest this please ---
[GitHub] carbondata issue #1975: [CARBONDATA-2142] [CARBONDATA-1763] Fixed issues whi...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1975 retest this please ---
[GitHub] carbondata pull request #1975: [CARBONDATA-2142] [CARBONDATA-1763] Fixed iss...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1975#discussion_r170174790
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/preaaggregate/PreAggregateUtil.scala
---
@@ -445,11 +443,11 @@ object PreAggregateUtil {
.fromWrapperToExternalTableInfo(wrapperTableInfo, dbName,
tableName)
updateSchemaInfo(carbonTable,
thriftTable)(sparkSession)
- LOGGER.info(s"Parent table updated is successful for table
$dbName.$tableName")
+ LOGGER.info(s"Parent table updated is successful for table" +
+ s"
$dbName.${childSchema.getRelationIdentifier.toString}")
} catch {
case e: Exception =>
LOGGER.error(e, "Pre Aggregate Parent table update failed
reverting changes")
-revertMainTableChanges(dbName, tableName,
numberOfCurrentChild)(sparkSession)
--- End diff --
If updation of the parent table fails then the aggregate table will be
dropped from undoMetadata. There is no need to revert the main table changes
here.
---
[GitHub] carbondata pull request #1980: [CARBONDATA-2103]optimize show tables for fil...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1980#discussion_r168687633
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/table/CarbonShowTablesCommand.scala
---
@@ -44,39 +44,15 @@ private[sql] case class CarbonShowTablesCommand (
databaseName: Option[String],
val db = databaseName.getOrElse(catalog.getCurrentDatabase)
var tables =
tableIdentifierPattern.map(catalog.listTables(db,
_)).getOrElse(catalog.listTables(db))
-tables = filterDataMaps(tables, sparkSession)
+val externalCatalog = sparkSession.sharedState.externalCatalog
+// tables will be filtered for all the dataMaps to show only main
tables
+tables = tables
+ .filter(table => externalCatalog.getTable(db,
table.table).storage.properties
--- End diff --
instead of looping twice we can use collect like this:
tables.collect {
case tableIdent if externalCatalog.getTable(db,
tableIdent.table).storage.properties.getOrElse("isCarbonTableVisibility", true)
=>
val isTemp = catalog.isTemporaryTable(tableIdent)
Row(tableIdent.database.getOrElse("default"), tableIdent.table, isTemp)
case _ =>
Row()
}
---
[GitHub] carbondata pull request #1980: [CARBONDATA-2103]optimize show tables for fil...
Github user kunal642 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/1980#discussion_r168687592 --- Diff: integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/table/CarbonShowTablesCommand.scala --- @@ -44,39 +44,15 @@ private[sql] case class CarbonShowTablesCommand ( databaseName: Option[String], val db = databaseName.getOrElse(catalog.getCurrentDatabase) var tables = tableIdentifierPattern.map(catalog.listTables(db, _)).getOrElse(catalog.listTables(db)) -tables = filterDataMaps(tables, sparkSession) +val externalCatalog = sparkSession.sharedState.externalCatalog --- End diff -- Update the comment "filterDataMaps Method is to Filter the Table." as filterDataMaps is removed ---
[GitHub] carbondata pull request #1980: [CARBONDATA-2103]optimize show tables for fil...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1980#discussion_r168687437
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/table/CarbonShowTablesCommand.scala
---
@@ -44,39 +44,15 @@ private[sql] case class CarbonShowTablesCommand (
databaseName: Option[String],
val db = databaseName.getOrElse(catalog.getCurrentDatabase)
var tables =
tableIdentifierPattern.map(catalog.listTables(db,
_)).getOrElse(catalog.listTables(db))
-tables = filterDataMaps(tables, sparkSession)
+val externalCatalog = sparkSession.sharedState.externalCatalog
+// tables will be filtered for all the dataMaps to show only main
tables
+tables = tables
+ .filter(table => externalCatalog.getTable(db,
table.table).storage.properties
+.getOrElse("isCarbonTableVisibility", true).toString.toBoolean)
tables.map { tableIdent =>
val isTemp = catalog.isTemporaryTable(tableIdent)
Row(tableIdent.database.getOrElse("default"), tableIdent.table,
isTemp)
--- End diff --
instead of looping twice we can use collect like this:
tables.collect {
case tableIdent if externalCatalog.getTable(db,
tableIdent.table).storage.properties.getOrElse("isCarbonTableVisibility", true)
=>
val isTemp = catalog.isTemporaryTable(tableIdent)
Row(tableIdent.database.getOrElse("default"), tableIdent.table,
isTemp)
case _ =>
Row()
}
---
[GitHub] carbondata issue #1981: [Pre-Agg Test] Added SDV TestCase of preaggregate
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1981 retest sdv please ---
[GitHub] carbondata issue #1975: [CARBONDATA-2142] [CARBONDATA-1763] Fixed issues whi...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1975 @ravipesala please review ---
[GitHub] carbondata pull request #1975: [CARBONDATA-2142] [CARBONDATA-1763] Fixed iss...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1975 [CARBONDATA-2142] [CARBONDATA-1763] Fixed issues while creation concurrent datamaps Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [X] Any interfaces changed? - [X] Any backward compatibility impacted? - [X] Document update required? - [X] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [X] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata concurrent_datamap_creation Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1975.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1975 commit 37c0630f93e4d05c7e255fc5b13d277273f65077 Author: kunal642 <kunalkapoor642@...> Date: 2018-02-12T19:23:31Z fixed issues while creation concurrent datamaps ---
[GitHub] carbondata issue #1957: [CARBONDATA-2150] Unwanted updatetable status files ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1957 LGTM ---
[GitHub] carbondata issue #1951: [CARBONDATA-1763] Dropped table if exception thrown ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1951 @ravipesala done ---
[GitHub] carbondata issue #1951: [CARBONDATA-1763] Dropped table if exception thrown ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1951 retest sdv please ---
[GitHub] carbondata issue #1951: [CARBONDATA-1763] Dropped table if exception thrown ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1951 @ravipesala Build success ---
[GitHub] carbondata pull request #1951: [CARBONDATA-1763] Dropped table if exception ...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1951 [CARBONDATA-1763] Dropped table if exception thrown while creation Preaggregate table is not getting dropped when creation fails because 1. Exceptions from undo metadata is not handled 2. If preaggregate table is not registered with main table(main table updation fails) then it is not dropped from metastore. Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata drop_fix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1951.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1951 commit d9628fc31c02dce51dabb8a329626f489b431358 Author: kunal642 <kunalkapoor642@...> Date: 2018-02-08T06:20:23Z dropped table if exception thrown while creation ---
[GitHub] carbondata pull request #1946: [WIP] Refresh fix
Github user kunal642 closed the pull request at: https://github.com/apache/carbondata/pull/1946 ---
[GitHub] carbondata pull request #1946: [WIP] Refresh fix
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1946 [WIP] Refresh fix Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata refresh_fix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1946.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1946 commit cb9fca5063b9a7882d09760ef777a9926ddffea0 Author: kunal642 <kunalkapoor642@...> Date: 2018-02-07T06:46:14Z refresh fix ---
[GitHub] carbondata issue #1914: [CARBONDATA-2122] Corrected bad record path validati...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1914 LGTM ---
[GitHub] carbondata issue #1915: [CARBONDATA-1454]false expression handling and block...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1915 retest please ---
[GitHub] carbondata issue #1910: [CARBONDATA-2112] Fixed bug for select operation on ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1910 LGTM ---
[GitHub] carbondata issue #1910: [CARBONDATA-2112] Fixed bug for select operation on ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1910 @geetikagupta16 can you write the existing problem with the code and the fix that you have done in the description. ---
[GitHub] carbondata pull request #1911: [CARBONDATA-2119] Fixed deserialization issue...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1911 [CARBONDATA-2119] Fixed deserialization issues for carbonLoadModel **Problem:** Load model was not getting de-serialized in the executor due to which 2 different carbon table objects were being created. **Solution:** Reconstruct carbonTable from tableInfo if not already created. Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [X] Any interfaces changed? - [X] Any backward compatibility impacted? - [X] Document update required? - [X] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [X] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata serialization_fix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1911.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1911 commit b69620be62b13a21a41d6c4e30430af288b2b82b Author: kunal642 <kunalkapoor642@...> Date: 2018-02-02T12:07:51Z fixed deserialization issues for carbonLoadModel ---
[GitHub] carbondata issue #1894: [CARBONDATA-2107]Fixed query failure in case if aver...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1894 LGTM ---
[GitHub] carbondata issue #1861: [CARBONDATA-2078][CARBONDATA-1516] Add 'if not exist...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1861 LGTM ---
[GitHub] carbondata pull request #1861: [CARBONDATA-2078][CARBONDATA-1516] Add 'if no...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1861#discussion_r165272350
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/datamap/CarbonCreateDataMapCommand.scala
---
@@ -49,10 +52,22 @@ case class CarbonCreateDataMapCommand(
throw new MalformedCarbonCommandException("Streaming table does not
support creating datamap")
}
val LOGGER =
LogServiceFactory.getLogService(this.getClass.getCanonicalName)
+val dbName = tableIdentifier.database.getOrElse("default")
+val tableName = tableIdentifier.table + "_" + dataMapName
-if (dmClassName.equalsIgnoreCase(PREAGGREGATE.toString) ||
+if (sparkSession.sessionState.catalog.listTables(dbName)
--- End diff --
sparkSession.sessionState.catalog.tableExists(tableIdentifier)
---
[GitHub] carbondata pull request #1861: [CARBONDATA-2078][CARBONDATA-1516] Add 'if no...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1861#discussion_r165271557
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/integration/spark/testsuite/timeseries/TestTimeSeriesCreateTable.scala
---
@@ -319,6 +326,53 @@ class TestTimeSeriesCreateTable extends QueryTest with
BeforeAndAfterAll {
assert(e.getMessage.equals(s"$timeSeries should define time
granularity"))
}
+ test("test timeseries create table 19: should support if not exists") {
+sql("DROP DATAMAP IF EXISTS agg1 ON TABLE mainTable")
+try {
--- End diff --
no need for try block. If any exception if thrown the test case will fail
---
[GitHub] carbondata pull request #1861: [CARBONDATA-2078][CARBONDATA-1516] Add 'if no...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1861#discussion_r165271343
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/integration/spark/testsuite/preaggregate/TestPreAggregateLoad.scala
---
@@ -310,5 +310,99 @@ test("check load and select for avg double datatype") {
checkAnswer(sql("select name,avg(salary) from maintbl group by name"),
rows)
}
+ test("create datamap with 'if not exists' after load data into mainTable
and create datamap") {
--- End diff --
I think no need to add test cases in all the files. One test case in
TestPreAggregateCreateCommand and one in TestTimeseriesCreateTable would be
enough.
---
[GitHub] carbondata pull request #1861: [CARBONDATA-2078][CARBONDATA-1516] Add 'if no...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1861#discussion_r165270563
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/integration/spark/testsuite/timeseries/TestTimeSeriesCreateTable.scala
---
@@ -81,29 +82,29 @@ class TestTimeSeriesCreateTable extends QueryTest with
BeforeAndAfterAll {
""".stripMargin)
}
- test("test timeseries create table Zero") {
+ test("test timeseries create table 1") {
--- End diff --
Please remove unnecessary changes like this
---
[GitHub] carbondata issue #1781: [CARBONDATA-2012] Add support to load pre-aggregate ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1781 retest this please ---
[GitHub] carbondata issue #1850: [CARBONDATA-2069] Restrict create datamap when load ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1850 retest this please ---
[GitHub] carbondata pull request #1844: [CARBONDATA-2061] Check for only valid IN_PRO...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1844#discussion_r163459153
--- Diff:
core/src/main/java/org/apache/carbondata/core/statusmanager/SegmentStatusManager.java
---
@@ -700,11 +708,28 @@ public static Boolean
checkIfAnyLoadInProgressForTable(CarbonTable carbonTable)
SegmentStatus segmentStatus = loaddetail.getSegmentStatus();
if (segmentStatus == SegmentStatus.INSERT_IN_PROGRESS ||
segmentStatus ==
SegmentStatus.INSERT_OVERWRITE_IN_PROGRESS) {
- loadInProgress = true;
+ loadInProgress =
+
checkIfValidLoadInProgress(carbonTable.getAbsoluteTableIdentifier(),
+ loaddetail.getLoadName());
}
}
}
return loadInProgress;
}
+ public static Boolean checkIfValidLoadInProgress(AbsoluteTableIdentifier
absoluteTableIdentifier,
--- End diff --
please add method description
---
[GitHub] carbondata pull request #1844: [CARBONDATA-2061] Check for only valid IN_PRO...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1844#discussion_r163459325
--- Diff:
core/src/main/java/org/apache/carbondata/core/statusmanager/SegmentStatusManager.java
---
@@ -700,11 +708,28 @@ public static Boolean
checkIfAnyLoadInProgressForTable(CarbonTable carbonTable)
SegmentStatus segmentStatus = loaddetail.getSegmentStatus();
if (segmentStatus == SegmentStatus.INSERT_IN_PROGRESS ||
segmentStatus ==
SegmentStatus.INSERT_OVERWRITE_IN_PROGRESS) {
- loadInProgress = true;
+ loadInProgress =
+
checkIfValidLoadInProgress(carbonTable.getAbsoluteTableIdentifier(),
+ loaddetail.getLoadName());
}
}
}
return loadInProgress;
}
+ public static Boolean checkIfValidLoadInProgress(AbsoluteTableIdentifier
absoluteTableIdentifier,
+ String loadId) {
+ICarbonLock segmentLock =
CarbonLockFactory.getCarbonLockObj(absoluteTableIdentifier,
+CarbonTablePath.addSegmentPrefix(loadId) + LockUsage.LOCK);
+try {
+ if (segmentLock.lockWithRetries(1, 5)) {
--- End diff --
return !segmentLock.lockWithRetries(1, 5) directly
---
[GitHub] carbondata pull request #1850: [CARBONDATA-2069] Restrict create datamap whe...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1850 [CARBONDATA-2069] Restrict create datamap when load is in progress **Problem:** 1. Load data into maintable 2. create datamap parallelly preaggregate table will not have any data while data load is successful for main table. This will make the pre-aggregate table inconsistent **Solution:** Restrict creation of pre-aggregate table when load is in progress on main table Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [X] Any interfaces changed? - [X] Any backward compatibility impacted? - [X] Document update required? - [X] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [X] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata restrict_create Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1850.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1850 commit 0e47c0e8841c1e0f1ec0291c18d7c7caea2f58aa Author: kunal642 <kunalkapoor642@...> Date: 2018-01-23T13:22:48Z restrict create datamap when load is in progress ---
[GitHub] carbondata issue #1821: [HOTFIX] Listeners not getting registered to the bus...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1821 retest sdv please ---
[GitHub] carbondata issue #1821: [HOTFIX] Listeners not getting registered to the bus...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1821 @jackylk handled all the review comments. ---
[GitHub] carbondata pull request #1821: [HOTFIX] Listeners not getting registered to ...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1821#discussion_r162052102
--- Diff:
core/src/main/java/org/apache/carbondata/events/OperationListenerBus.java ---
@@ -57,9 +57,9 @@ public OperationListenerBus addListener(Class eventClass,
OperationEventListener operationEventListener) {
String eventType = eventClass.getName();
-List operationEventListeners =
eventMap.get(eventType);
+Set operationEventListeners =
eventMap.get(eventType);
if (null == operationEventListeners) {
- operationEventListeners = new CopyOnWriteArrayList<>();
+ operationEventListeners = new CopyOnWriteArraySet<>();
--- End diff --
1) Changed the code to use addIfAbsent method instead of add. This will
take care of dublicate entries.
2) changed the OperationEventListener interface to abstract class with
equals and hashcode which will compare the class name.
---
[GitHub] carbondata pull request #1821: [WIP]refactored code to support external sess...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1821 [WIP]refactored code to support external session state impl Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata preagg_refactor Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1821.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1821 commit b95da5bed4be937b5d02890f9e279ee59b933fd9 Author: kunal642 <kunalkapoor642@...> Date: 2018-01-17T10:03:25Z refactored code to support external session state impl ---
[GitHub] carbondata issue #1781: [CARBONDATA-2012] Add support to load pre-aggregate ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1781 retest this please ---
[GitHub] carbondata issue #1803: [CARBONDATA-2029]Fixed Pre Aggregate table issue wit...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1803 LGTM ---
[GitHub] carbondata issue #1807: [CARBONDATA-2030]avg with Aggregate table for double...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1807 retest this please ---
[GitHub] carbondata issue #1781: [CARBONDATA-2012] Add support to load pre-aggregate ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1781 retest this please ---
[GitHub] carbondata pull request #1802: [WIP] test
Github user kunal642 closed the pull request at: https://github.com/apache/carbondata/pull/1802 ---
[GitHub] carbondata pull request #1802: [WIP] test
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1802 [WIP] test Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata transaction_preaggregate_support Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1802.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1802 commit ad06aed3924125cf260b515468c49933d091b768 Author: kunal642 <kunalkapoor642@...> Date: 2018-01-15T09:05:56Z added transaction support for preaggregate load ---
[GitHub] carbondata issue #1724: [CARBONDATA-1940][PreAgg] Fixed bug for creation of ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1724 LGTM ---
[GitHub] carbondata issue #1781: [CARBONDATA-2012] Add support to load pre-aggregate ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1781 retest this please ---
[GitHub] carbondata issue #1724: [CARBONDATA-1940][PreAgg] Fixed bug for creation of ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1724 @geetikagupta16 can you squash the commits. ---
[GitHub] carbondata pull request #1781: [CARBONDATA-2012] Add support to load pre-agg...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1781 [CARBONDATA-2012] Add support to load pre-aggregate in one transaction Change the pre-aggregate load process to support load as one transaction for the parent and child tables. Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [X] Any interfaces changed? - [X] Any backward compatibility impacted? - [X] Document update required? - [X] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [X] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata transaction_preaggregate Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1781.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1781 commit b0827b6e1669827e0e73b32467d7bb190c7601b0 Author: kunal642 <kunalkapoor642@...> Date: 2018-01-09T14:06:41Z add support to load pre-aggregate in one transaction ---
[GitHub] carbondata pull request #1758: [CARBONDATA-1978] Handled preaggregate issues...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1758 [CARBONDATA-1978] Handled preaggregate issues with hive metastore During creation of TableInfo from hivemetastore the DataMapSchemas and the columns DataTypes are not converted to the appropriate child classes due to which data types not supported exception is thrown Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [X] Any interfaces changed? No - [X] Any backward compatibility impacted? No - [X] Document update required? No - [X] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata hivemetastore_preagg Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1758.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1758 commit a90f8b5aaeb3c628293164291ee7f2ea591fba12 Author: kunal642 <kunalkapoor642@...> Date: 2018-01-03T13:47:53Z handled preaggregate issues with hive metastore ---
[GitHub] carbondata pull request #1746: [TEST] Enable pre-aggregate tests as NPE in C...
Github user kunal642 closed the pull request at: https://github.com/apache/carbondata/pull/1746 ---
[GitHub] carbondata pull request #1747: [Compatibility] Added changes for backward co...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1747 [Compatibility] Added changes for backward compatibility Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata upgrade_support Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1747.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1747 commit bab3fd7ef50073fa951daf8150f9f98dc6e1c813 Author: kunal642 <kunalkapoor642@...> Date: 2017-11-20T15:06:54Z added changes for backward compatibility ---
[GitHub] carbondata issue #1746: [TEST] Enable pre-aggregate tests as NPE in CI issue...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1746 retest this please ---
[GitHub] carbondata pull request #1746: [TEST] Enable pre-aggregate tests as CI issue...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1746 [TEST] Enable pre-aggregate tests as CI issue is fixed Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata enable_preagg_tests Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1746.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1746 commit 6e47cb226d5eefe45b6a8ec1c01cf84922e611e6 Author: kunal642 <kunalkapoor642@...> Date: 2018-01-02T06:30:09Z Enable pre-aggregate tests as CI issue is fixed ---
[GitHub] carbondata pull request #1722: [CARBONDATA-1755] Fixed bug occuring on concu...
Github user kunal642 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/1722#discussion_r158901669 --- Diff: integration/spark-common-test/src/test/scala/org/apache/carbondata/spark/testsuite/iud/TestInsertUpdateConcurrentTest.scala --- @@ -0,0 +1,84 @@ +package org.apache.carbondata.spark.testsuite.iud --- End diff -- Please add the apache license file header ---
[GitHub] carbondata issue #1725: [CARBONDATA-1941] Documentation added for Lock Retry
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1725 LGTM ---
[GitHub] carbondata issue #1703: [CARBONDATA-1917] While loading, check for stale dic...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1703 retest this please ---
[GitHub] carbondata issue #1712: [CARBONDATA-1931]DataLoad failed for Aggregate table...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1712 retest this please ---
[GitHub] carbondata pull request #1710: [CARBONDATA-1930] Added condition to refer to...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1710 [CARBONDATA-1930] Added condition to refer to parent dictionary if filter is given in aggregate table query **Analysis:** When filter is applied to aggregate query then the query is not accessing the parent table dictionary instead it is trying to search for aggregate table dictionary files. **Solution:** Add check to access parent table dictionary files if aggregate column has parent columns. Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [X] Any interfaces changed? No - [X] Any backward compatibility impacted? No - [X] Document update required? No - [X] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [X] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata aggregate_filter_fix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1710.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1710 commit 8b7570ba2f65c26b9e1ababb01905a907a0c7d00 Author: kunal642 <kunalkapoor642@...> Date: 2017-12-22T07:53:11Z added condition to refer to parent dictionary if filter is given in aggregate table query ---
[GitHub] carbondata pull request #1708: [CARBONDATA-1928] Seperate the properties for...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1708 [CARBONDATA-1928] Seperate the properties for timeout and retries for load flow **Analysis:** Currently the property that is used to configure the lock retry count and the interval between retries is common for all the locks. This will be problematic when the user has configured the retries to 10/20 for concurrent loading. This property will be affecting other lock behaviours also, all other locks would have to retry for 10 times too. **Solution:** 1. Change the name of the "carbon.load.metadata.lock.retries" property to "carbon.concurrent.lock.retries" AND "carbon.concurrent.lock.retry.timeout.sec" 2. introduce a new property for all other locks "carbon.lock.retries" AND "carbon.lock.retry.timeout.sec" Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [X] Any interfaces changed? Property change - [X] Any backward compatibility impacted? Yes - [X] Document update required? Yes - [X] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [X] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata tablestatus_lock_fix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1708.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1708 commit 165d09312d501556b356b4dba660588fb79a8231 Author: kunal642 <kunalkapoor642@...> Date: 2017-12-20T16:43:10Z seperate the properties for timeout and retries for load flow ---
[GitHub] carbondata issue #1692: [CARBONDATA-1777] Added check to refresh table if ca...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1692 retest this please ---
[GitHub] carbondata pull request #1697: [CARBONDATA-1719][Pre-Aggregate][Bug] Fixed b...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1697#discussion_r158041809
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/preaaggregate/PreAggregateListeners.scala
---
@@ -38,7 +40,10 @@ object LoadPostAggregateListener extends
OperationEventListener {
val loadEvent = event.asInstanceOf[LoadTablePreStatusUpdateEvent]
val sparkSession = loadEvent.sparkSession
val carbonLoadModel = loadEvent.carbonLoadModel
-val table = carbonLoadModel.getCarbonDataLoadSchema.getCarbonTable
+val metastore = CarbonEnv.getInstance(sparkSession).carbonMetastore
+carbonLoadModel.getTableName
--- End diff --
i think this was added by mistake.. Please remove
---
[GitHub] carbondata pull request #1692: [CARBONDATA-1777] Added check to update relat...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1692 [CARBONDATA-1777] Added check to update relation if catalog relation is present in plan **Analysis:** In spark 2.2 while doing lookup relation there was no case to handle CatalogRelation due to which the tables were not getting refreshed in different sessions. **Solution:** Add case for CatalogRelation so that the table being referred is refreshed. Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? No - [ ] Any backward compatibility impacted? No - [ ] Document update required? No - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. No You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata table_refresh_fix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1692.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1692 commit 099f9806bb16c6dbaa747316adca02028b323686 Author: kunal642 <kunalkapoor642@...> Date: 2017-12-20T08:35:06Z added check to update relation if catalog relation is present in plan ---
[GitHub] carbondata pull request #1597: WIP test PR
Github user kunal642 closed the pull request at: https://github.com/apache/carbondata/pull/1597 ---
[GitHub] carbondata issue #1521: [CARBONDATA-1743] fix conurrent pre-agg creation and...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1521 @ravipesala Please review ---
[GitHub] carbondata pull request #1653: [CARBONDATA-1893] Data load with multiple QUO...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1653#discussion_r156946110
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/spark/testsuite/dataload/TestLoadDataWithMalformedCarbonCommandException.scala
---
@@ -156,4 +156,40 @@ class TestLoadDataWithMalformedCarbonCommandException
extends QueryTest with Bef
case _: Throwable => assert(false)
}
}
+
+ test("test load data with more than one char in quotechar option") {
+try {
--- End diff --
use intercept[MalformedCarbonCommandException] instead of try catch
---
[GitHub] carbondata pull request #1651: [CARBONDATA-1891] Fixed timeseries table crea...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1651#discussion_r156611792
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/preaaggregate/PreAggregateUtil.scala
---
@@ -514,9 +514,16 @@ object PreAggregateUtil {
CarbonCommonConstants.VALIDATE_CARBON_INPUT_SEGMENTS +
parentCarbonTable.getDatabaseName + "." +
parentCarbonTable.getTableName, validateSegments.toString)
-val headers =
parentCarbonTable.getTableInfo.getDataMapSchemaList.asScala.
-
find(_.getChildSchema.getTableName.equals(dataMapIdentifier.table)).get.getChildSchema.
- getListOfColumns.asScala.map(_.getColumnName).mkString(",")
+val dataMapSchemas =
parentCarbonTable.getTableInfo.getDataMapSchemaList.asScala
+val headers =
dataMapSchemas.find(_.getChildSchema.getTableName.equalsIgnoreCase(
+ dataMapIdentifier.table)) match {
+ case Some(dataMapSchema) =>
+
dataMapSchema.getChildSchema.getListOfColumns.asScala.map(_.getColumnName).mkString(",")
+ case None =>
--- End diff --
This is just to throw a proper exception if ever this condition is met. The
message will tell which aggregate table is not present in the datamap schema
list.
---
[GitHub] carbondata issue #1639: [CARBONDATA-1881] Insert overwrite value for pre-agg...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1639 retest sdv please ---
[GitHub] carbondata pull request #1646: [CARBONDATA-1886] Delete stale segment folder...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1646 [CARBONDATA-1886] Delete stale segment folders on new load **Analysis**: segment folders are not getting deleted if corresponding entry is not available in table status file. **Solution**: Delete stale segment folders if present Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata delete_stale_segments Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1646.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1646 commit 902f13bdcbcd4036e543a86a698d07c4d1d577d5 Author: kunal642 <kunalkapoor...@gmail.com> Date: 2017-12-12T10:55:31Z fixed issue where segment folders are not getting deleted if corresponding entry is not available in table status file ---
[GitHub] carbondata pull request #1622: [CARBONDATA-1865] Refactored code to skip sin...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1622#discussion_r156304089
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/management/CarbonLoadDataCommand.scala
---
@@ -160,7 +160,7 @@ case class CarbonLoadDataCommand(
if (isOverwriteTable) {
LOGGER.info(s"Overwrite of carbon table with $dbName.$tableName
is in progress")
}
-if (carbonLoadModel.getLoadMetadataDetails.isEmpty &&
carbonLoadModel.getUseOnePass &&
+if (carbonLoadModel.getLoadMetadataDetails.size() == 1 &&
carbonLoadModel.getUseOnePass &&
--- End diff --
This if condition can be remove as the high_cardinality check has been
removed.
@manishgupta88 Please suggest
---
[GitHub] carbondata issue #1601: [CARBONDATA-1787] Validation for table properties in...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1601 We will not validate the create tbl properties as the user can define his own properties as well. Please close this ---
[GitHub] carbondata issue #1639: [CARBONDATA-1881] Insert overwrite value for pre-agg...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1639 Retest this please ---
[GitHub] carbondata pull request #1639: [CARBONDATA-1881] Insert overwrite value for ...
GitHub user kunal642 opened a pull request: https://github.com/apache/carbondata/pull/1639 [CARBONDATA-1881] Insert overwrite value for pre-aggregate load was incorrect Analysis: while loading the value for insert overwrite was set to false. Solution: Consider the value of insert overwrite set for maintable for pre-aggregate table loading. Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [X] Any interfaces changed? no - [X] Any backward compatibility impacted? no - [X] Document update required? no - [X] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [X] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kunal642/carbondata insert_overwrite_fix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/1639.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #1639 commit dc077a7b611dad09de2ea8bbb3efcfd8efba6348 Author: kunal642 <kunalkapoor...@gmail.com> Date: 2017-12-11T05:50:43Z insert overwrite value for pre-aggregate load was incorrect ---
[GitHub] carbondata pull request #1601: [CARBONDATA-1787] Validation for table proper...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1601#discussion_r155719835
--- Diff:
integration/spark-common-cluster-test/src/test/scala/org/apache/carbondata/cluster/sdv/generated/V3offheapvectorTestCase.scala
---
@@ -35,7 +35,7 @@ class V3offheapvectorTestCase extends QueryTest with
BeforeAndAfterAll {
//Check query reponse for select * query with no filters
test("V3_01_Query_01_033", Include) {
dropTable("3lakh_uniqdata")
- sql(s"""CREATE TABLE 3lakh_uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, DOJ timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double,INTEGER_COLUMN1
int) STORED BY 'carbondata'
TBLPROPERTIES('table_blocksize'='128','include_dictionary'='BIGINT_COLUMN1,BIGINT_COLUMN2,DECIMAL_COLUMN1,DECIMAL_COLUMN2,Double_COLUMN1,Double_COLUMN2,INTEGER_COLUMN1,CUST_ID')""").collect
+ sql(s"""CREATE TABLE 3lakh_uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, DOJ timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double,INTEGER_COLUMN1
int) STORED BY 'carbondata'
TBLPROPERTIES('table_blocksize'='128','dictionary_include'='BIGINT_COLUMN1,BIGINT_COLUMN2,DECIMAL_COLUMN1,DECIMAL_COLUMN2,Double_COLUMN1,Double_COLUMN2,INTEGER_COLUMN1,CUST_ID')""").collect
--- End diff --
okay
---
[GitHub] carbondata pull request #1601: [CARBONDATA-1787] Validation for table proper...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1601#discussion_r155713651
--- Diff:
integration/spark-common-cluster-test/src/test/scala/org/apache/carbondata/cluster/sdv/generated/V3offheapvectorTestCase.scala
---
@@ -35,7 +35,7 @@ class V3offheapvectorTestCase extends QueryTest with
BeforeAndAfterAll {
//Check query reponse for select * query with no filters
test("V3_01_Query_01_033", Include) {
dropTable("3lakh_uniqdata")
- sql(s"""CREATE TABLE 3lakh_uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, DOJ timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double,INTEGER_COLUMN1
int) STORED BY 'carbondata'
TBLPROPERTIES('table_blocksize'='128','include_dictionary'='BIGINT_COLUMN1,BIGINT_COLUMN2,DECIMAL_COLUMN1,DECIMAL_COLUMN2,Double_COLUMN1,Double_COLUMN2,INTEGER_COLUMN1,CUST_ID')""").collect
+ sql(s"""CREATE TABLE 3lakh_uniqdata (CUST_ID int,CUST_NAME
String,ACTIVE_EMUI_VERSION string, DOB timestamp, DOJ timestamp, BIGINT_COLUMN1
bigint,BIGINT_COLUMN2 bigint,DECIMAL_COLUMN1 decimal(30,10), DECIMAL_COLUMN2
decimal(36,10),Double_COLUMN1 double, Double_COLUMN2 double,INTEGER_COLUMN1
int) STORED BY 'carbondata'
TBLPROPERTIES('table_blocksize'='128','dictionary_include'='BIGINT_COLUMN1,BIGINT_COLUMN2,DECIMAL_COLUMN1,DECIMAL_COLUMN2,Double_COLUMN1,Double_COLUMN2,INTEGER_COLUMN1,CUST_ID')""").collect
--- End diff --
revert the unnecessary changes
---
[GitHub] carbondata pull request #1601: [CARBONDATA-1787] Validation for table proper...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1601#discussion_r155713494
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/parser/CarbonSparkSqlParser.scala
---
@@ -190,7 +191,7 @@ class CarbonHelperSqlAstBuilder(conf: SQLConf, parser:
CarbonSpark2SqlParser)
}
val tableProperties = mutable.Map[String, String]()
-properties.foreach{property => tableProperties.put(property._1,
property._2)}
+validatedProperties.foreach{property =>
tableProperties.put(property._1, property._2)}
--- End diff --
i think we can remove this code. After this we will extract the values so
no point in creating mutable.Map. Can you please confirm this?
---
[GitHub] carbondata pull request #1601: [CARBONDATA-1787] Validation for table proper...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1601#discussion_r155712770
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/parser/CarbonSparkSqlParser.scala
---
@@ -232,6 +233,30 @@ class CarbonHelperSqlAstBuilder(conf: SQLConf, parser:
CarbonSpark2SqlParser)
CarbonCreateTableCommand(tableModel, tablePath)
}
+ private def validateTableProperties(properties: Map[String, String]):
Map[String, String] = {
+var isSupported = true
+val invalidOptions = StringBuilder.newBuilder
+val tableProperties = Seq("DICTIONARY_INCLUDE", "DICTIONARY_EXCLUDE",
"NO_INVERTED_INDEX",
+ "SORT_COLUMNS", "TABLE_BLOCKSIZE", "STREAMING", "SORT_SCOPE",
"COMMENT", "PARTITION_TYPE",
+ "NUM_PARTITIONS", "RANGE_INFO", "LIST_INFO", "BUCKETNUMBER",
"BUCKETCOLUMNS", "TABLENAME")
+val tblProperties: Map[String, String] = properties.filter { property
=>
+ if (!(tableProperties.exists(prop =>
prop.equalsIgnoreCase(property._1))
--- End diff --
we can just iterate over the map and check if any of the properties are
invalid. No need to create new tblProperties.
Instead of filter, use collect to get invalid properties and check if any
property is returned.
---
[GitHub] carbondata issue #1622: [CARBONDATA-1865] Refactored code to skip single-pas...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1622 retest sdv please ---
[GitHub] carbondata issue #1605: [CARBONDATA-1526] [PreAgg] Added support to compact ...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1605 Retest this please ---
[GitHub] carbondata pull request #1605: [CARBONDATA-1526] [PreAgg] Added support to c...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1605#discussion_r155444843
--- Diff:
integration/spark2/src/main/scala/org/apache/carbondata/spark/rdd/Compactor.scala
---
@@ -0,0 +1,63 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.spark.rdd
+
+import java.util.concurrent.ExecutorService
+
+import org.apache.spark.sql.SQLContext
+import org.apache.spark.sql.execution.command.CompactionModel
+
+import org.apache.carbondata.common.logging.{LogService, LogServiceFactory}
+import org.apache.carbondata.core.statusmanager.LoadMetadataDetails
+import org.apache.carbondata.processing.loading.model.CarbonLoadModel
+import org.apache.carbondata.processing.merger.CarbonDataMergerUtil
+import org.apache.carbondata.processing.util.CarbonLoaderUtil
+
+abstract class Compactable(carbonLoadModel: CarbonLoadModel,
--- End diff --
Changed the class name to Compactor
---
[GitHub] carbondata pull request #1605: [CARBONDATA-1526] [PreAgg] Added support to c...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1605#discussion_r155441909
--- Diff:
integration/spark2/src/main/scala/org/apache/carbondata/spark/rdd/CarbonTableCompactor.scala
---
@@ -0,0 +1,129 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.spark.rdd
+
+import java.util
+import java.util.concurrent.{ExecutorService, Future}
+
+import scala.collection.JavaConverters._
+
+import org.apache.spark.sql.SQLContext
+import org.apache.spark.sql.execution.command.{CompactionCallableModel,
CompactionModel}
+
+import org.apache.carbondata.core.constants.CarbonCommonConstants
+import org.apache.carbondata.core.statusmanager.LoadMetadataDetails
+import org.apache.carbondata.processing.loading.model.CarbonLoadModel
+import org.apache.carbondata.processing.merger.{CarbonDataMergerUtil,
CompactionType}
+import org.apache.carbondata.spark.compaction.CompactionCallable
+import org.apache.carbondata.spark.util.CommonUtil
+
+/**
+ * This class is used to perform compaction on carbon table.
+ */
+class CarbonTableCompactor(carbonLoadModel: CarbonLoadModel,
--- End diff --
AggregateDataMapCompactor requires CarbonSession which is not available in
spark-common
---
[GitHub] carbondata issue #1613: [CARBONDATA-1737] [CARBONDATA-1760] [PreAgg] Fixed p...
Github user kunal642 commented on the issue: https://github.com/apache/carbondata/pull/1613 retest this please ---
[GitHub] carbondata pull request #1613: [CARBONDATA-1737] [CARBONDATA-1760] [PreAgg] ...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1613#discussion_r155155362
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/preaaggregate/PreAggregateUtil.scala
---
@@ -493,4 +495,49 @@ object PreAggregateUtil {
updatedPlan
}
+ /**
+ * This method will start load process on the data map
+ */
+ def startDataLoadForDataMap(parentCarbonTable: CarbonTable,
+ dataMapIdentifier: TableIdentifier,
+ queryString: String,
+ segmentToLoad: String,
+ validateSegments: Boolean,
+ sparkSession: SparkSession): Unit = {
+CarbonSession.threadSet(
--- End diff --
This parameter is used to specify the segments to scan in CarbonScanRDD.
Therefore i cannot pass it explicitly. As discussed with @gvramana and
@ravipesala this was only option that was agreed upon.
---
[GitHub] carbondata pull request #1605: [CARBONDATA-1526] [PreAgg] Added support to c...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1605#discussion_r154990944
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/preaaggregate/PreAggregateUtil.scala
---
@@ -493,4 +493,20 @@ object PreAggregateUtil {
updatedPlan
}
+ def createChildSelectQuery(tableSchema: TableSchema): String = {
--- End diff --
This sql is created to select data from the child table that will be
inserted in that table itself. Load UDF would then be added to it and then a
DataFrame would be created.
---
[GitHub] carbondata pull request #1605: [CARBONDATA-1526] [PreAgg] Added support to c...
Github user kunal642 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/1605#discussion_r154990350 --- Diff: processing/src/main/java/org/apache/carbondata/processing/loading/model/CarbonLoadModel.java --- @@ -172,6 +173,16 @@ private boolean isAggLoadRequest; + private CompactionType compactionType = CompactionType.NONE; --- End diff -- i dont think for one parameter it is required to create a new compaction model ---
[GitHub] carbondata pull request #1605: [CARBONDATA-1526] [PreAgg] Added support to c...
Github user kunal642 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/1605#discussion_r154986219 --- Diff: processing/src/main/java/org/apache/carbondata/processing/loading/model/CarbonLoadModel.java --- @@ -172,6 +173,16 @@ private boolean isAggLoadRequest; + private CompactionType compactionType = CompactionType.NONE; --- End diff -- CompactionModel is not available in the LoadCommand while LoadModel is available in both compation and loading commands ---
[GitHub] carbondata pull request #1605: [CARBONDATA-1526] [PreAgg] Added support to c...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1605#discussion_r154984035
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/preaaggregate/PreAggregateListeners.scala
---
@@ -78,6 +89,57 @@ object LoadPostAggregateListener extends
OperationEventListener {
}
}
}
+
+ /**
+ * mark the merged segments as COMPACTED and write load details into
table status.
+ *
+ * @param carbonLoadModel
+ */
+ private def markSegmentsAsCompacted(carbonLoadModel: CarbonLoadModel):
Unit = {
+val loadMetadataDetailsIterator =
carbonLoadModel.getLoadMetadataDetails.iterator()
+while(loadMetadataDetailsIterator.hasNext) {
+ val loadMetaDataDetail = loadMetadataDetailsIterator.next()
+ if (loadMetaDataDetail.getMergedLoadName ==
carbonLoadModel.getSegmentId) {
+loadMetaDataDetail.setSegmentStatus(SegmentStatus.COMPACTED)
+ }
+}
+val carbonTablePath = CarbonStorePath
+
.getCarbonTablePath(carbonLoadModel.getCarbonDataLoadSchema.getCarbonTable
+.getAbsoluteTableIdentifier)
+SegmentStatusManager
+ .writeLoadDetailsIntoFile(carbonTablePath.getTableStatusFilePath,
+carbonLoadModel.getLoadMetadataDetails
+ .toArray(new
Array[LoadMetadataDetails](carbonLoadModel.getLoadMetadataDetails.size)))
+ }
+
+}
+
+object AlterPreAggregateTableCompactionPostEvent extends
OperationEventListener {
+ /**
+ * Called on a specified event occurrence
+ *
+ * @param event
+ * @param operationContext
+ */
+ override def onEvent(event: Event, operationContext: OperationContext):
Unit = {
--- End diff --
added comment
---
[GitHub] carbondata pull request #1605: [CARBONDATA-1526] [PreAgg] Added support to c...
Github user kunal642 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/1605#discussion_r154983970
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/preaaggregate/PreAggregateListeners.scala
---
@@ -78,6 +89,57 @@ object LoadPostAggregateListener extends
OperationEventListener {
}
}
}
+
+ /**
+ * mark the merged segments as COMPACTED and write load details into
table status.
+ *
+ * @param carbonLoadModel
+ */
+ private def markSegmentsAsCompacted(carbonLoadModel: CarbonLoadModel):
Unit = {
+val loadMetadataDetailsIterator =
carbonLoadModel.getLoadMetadataDetails.iterator()
+while(loadMetadataDetailsIterator.hasNext) {
+ val loadMetaDataDetail = loadMetadataDetailsIterator.next()
+ if (loadMetaDataDetail.getMergedLoadName ==
carbonLoadModel.getSegmentId) {
+loadMetaDataDetail.setSegmentStatus(SegmentStatus.COMPACTED)
+ }
+}
+val carbonTablePath = CarbonStorePath
+
.getCarbonTablePath(carbonLoadModel.getCarbonDataLoadSchema.getCarbonTable
+.getAbsoluteTableIdentifier)
+SegmentStatusManager
+ .writeLoadDetailsIntoFile(carbonTablePath.getTableStatusFilePath,
+carbonLoadModel.getLoadMetadataDetails
+ .toArray(new
Array[LoadMetadataDetails](carbonLoadModel.getLoadMetadataDetails.size)))
+ }
+
+}
+
+object AlterPreAggregateTableCompactionPostEvent extends
OperationEventListener {
--- End diff --
changed the name
---
[GitHub] carbondata pull request #1605: [CARBONDATA-1526] [PreAgg] Added support to c...
Github user kunal642 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/1605#discussion_r154983698 --- Diff: integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/management/CarbonLoadDataCommand.scala --- @@ -130,6 +131,9 @@ case class CarbonLoadDataCommand( carbonLoadModel.setFactFilePath(factPath) carbonLoadModel.setAggLoadRequest(internalOptions .getOrElse(CarbonCommonConstants.IS_INTERNAL_LOAD_CALL, "false").toBoolean) + carbonLoadModel --- End diff -- ok ---